????????當自然語言處理領域因Transformer而煥發新生時,計算機視覺卻長期困于卷積神經網絡的架構桎梏。直到ViT(Vision Transformer)的橫空出世,才真正打破了視覺與語言之間的壁壘。它不僅是技術的革新,更是范式革命的開始:圖像不再是像素的矩陣,而是視覺詞匯的序列。隨后,MAE以掩碼重建的巧思將自監督學習推向新高度,而Swin Transformer則以分層結構與滑動窗口的智慧,讓Transformer在視覺任務中既高效又強大。這篇筆記將帶你深入這三篇里程碑論文的核心,揭示它們如何共同構建了一個通向通用智能的多模態未來。
????????
????????本筆記系統精讀了三篇計算機視覺領域的革命性論文:ViT、MAE和Swin Transformer。它們分別解決了Transformer在視覺任務中的三大核心挑戰:架構適配、自監督預訓練和計算效率與層次建模。
-
ViT(Vision Transformer)?首次將純Transformer應用于圖像分類,通過將圖像分割為塊(Patch)序列并直接輸入Encoder,證明了在大規模數據上Transformer可超越CNN。其關鍵突破在于摒棄了卷積的歸納偏置(局部性、平移等變性),僅依靠注意力機制實現全局建模,為多模態統一奠定了基礎。
-
MAE(Masked Autoencoder)?借鑒BERT的掩碼語言模型思想,但針對視覺信號的高冗余度,提出高比例掩碼(如75%)和不對稱編解碼架構。編碼器僅處理可見塊,輕量解碼器重建像素,顯著降低了預訓練成本并學習了高質量表征,證明了自監督在視覺領域的巨大潛力。
-
Swin Transformer?通過分層結構(模擬CNN的多尺度特征)和移動窗口自注意力(將計算復雜度從平方降為線性),解決了ViT在高分辨率圖像(如檢測、分割)上的計算瓶頸。其滑動窗口機制既保留了全局建模能力,又實現了高效計算,成為通用視覺主干網絡的標桿。
????????這三項工作標志著視覺領域已從CNN時代邁入Transformer時代,其核心思想——序列化建模、自監督學習、層次化設計——不僅推動了視覺技術的發展,更為視覺與語言的統一建模提供了關鍵路徑。未來的多模態智能系統,必將構建于此基礎之上。
目錄
1. ViT - CV版的Transformer
1.1?摘要 + 導言 + 結論
1.2?架構
1.3?Experiments 實驗結果
2. MAE - CV版的BERT
2.1?摘要 + 導言
2.2 Approach 方法
操作流程
2.3 Experiments 實驗結果
3. Swin Transformer? ViT結合CNN(分層結構+滑動窗口)
3.1?摘要 + 導言 + 結論
3.2?Method 方法
3.2.1?Overall Architecture
3.2.2?Shifted Window based Self-Attention 滑動窗口自注意力
3.3 Experiments 實驗結果
1. ViT - CV版的Transformer
ViT論文逐段精讀【論文精讀】
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
將圖像視為由“單詞”(patches)組成的“句子”。具體做法是把一張圖像分割成固定大小的圖像塊(例如16x16像素),每個圖像塊就類似于自然語言處理(NLP)中的一個單詞 token。然后將這些圖像塊組成的序列直接輸入標準的Transformer架構(具體是Transformer Encoder)進行圖像分類。
1.1?摘要 + 導言 + 結論
Transformer、注意力機制在NLP大火,但在CV領域 注意力機制只是用于CNN架構中的組件改變,本文將純Transformer應用于圖像塊序列。在基準數據集(ImageNet、CIFAR-100、VTAB等)表現很好 并訓練計算資源顯著減少。
一個224*224的圖片 5w個像素點 如果把每個像素點拉直作為一個獨立單元,算注意力是 n^2復雜度,就太高了。可以把16*16的圖像作為 一個單元;一共14*14 = 196個單元。
ViT 是很好的挖坑之作 未來很多用Transformer做CV。Transformer 在?NLP和CV上都適用 為后來多模態 打通CV和NLP。
1.2?架構
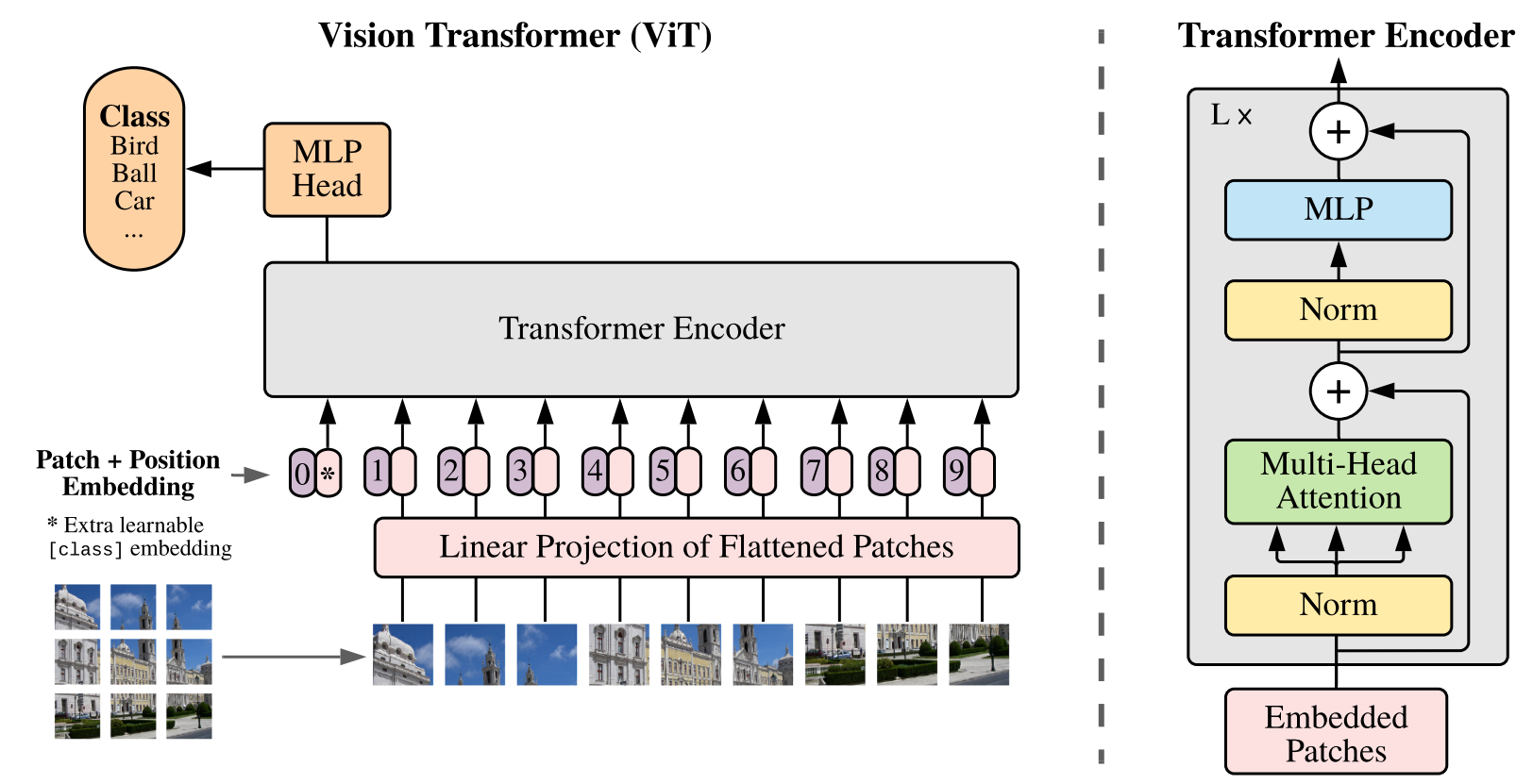
Patch:單個圖片 224*224*3 分成 14*14=196個 16*16*3=768;
embedding 乘上一個 768*d 的矩陣;(196*768) * (768*d) -> 196*d
在最開頭加上一個分類字符 [cls](similar to BERT's [class] token) 即變成197*d
因為和別的位置兩兩自注意力,這個[cls]實則包含了其他位置的所有信息;把這個送個MLP分類。
CNN inductive biases 歸納偏置:
- 局部性:假設圖像中有意義的特征(如邊緣、紋理、角落)通常由相鄰的像素組成,而非相距甚遠的像素。因此,卷積核只關注一個小窗口(如3x3)內的局部信息。
- 平移等變性:意味著一個物體在圖像中移動后,其對應的特征也會在特征圖中發生同樣的移動。卷積操作在任何位置都是共享參數的,它不關心特征具體在圖像的哪個位置。
- 空間層次結構:復雜的、全局的特征(如一張臉)是由簡單的、局部的特征(如眼睛、鼻子、嘴巴)逐步組合而成的。通過池化層(Pooling Layers)?和逐步增加感受野的卷積層堆疊來實現。
而ViT 沒有使用歸納偏置 而是:
-
Patch Extraction:將一張圖像簡單地切割成一系列固定大小的圖像塊(Patches),然后將每個塊展平成一個向量。這可以看作是模型唯一需要做的關于“圖像是2D網格”的假設。
-
學習添加位置編碼:由于Transformer本身是置換不變(Permutation-Invariant)的(即不關心輸入序列的順序),ViT需要顯式地添加位置編碼(Position Embedding)?來告訴模型“每個圖像塊在原始圖像中的位置信息”。這個位置關系不是硬編碼的規律,而是需要模型從數據中學習的參數。
-
送入標準Transformer編碼器:之后的過程就和處理一堆單詞沒有任何區別了。自注意力機制是全局的——從第一層開始,每個塊(token)就可以和圖像中任何位置的塊進行交互和集成信息。它沒有“局部性”的假設,也沒有通過卷積來強制實現“平移等變性”。
1.3?Experiments 實驗結果
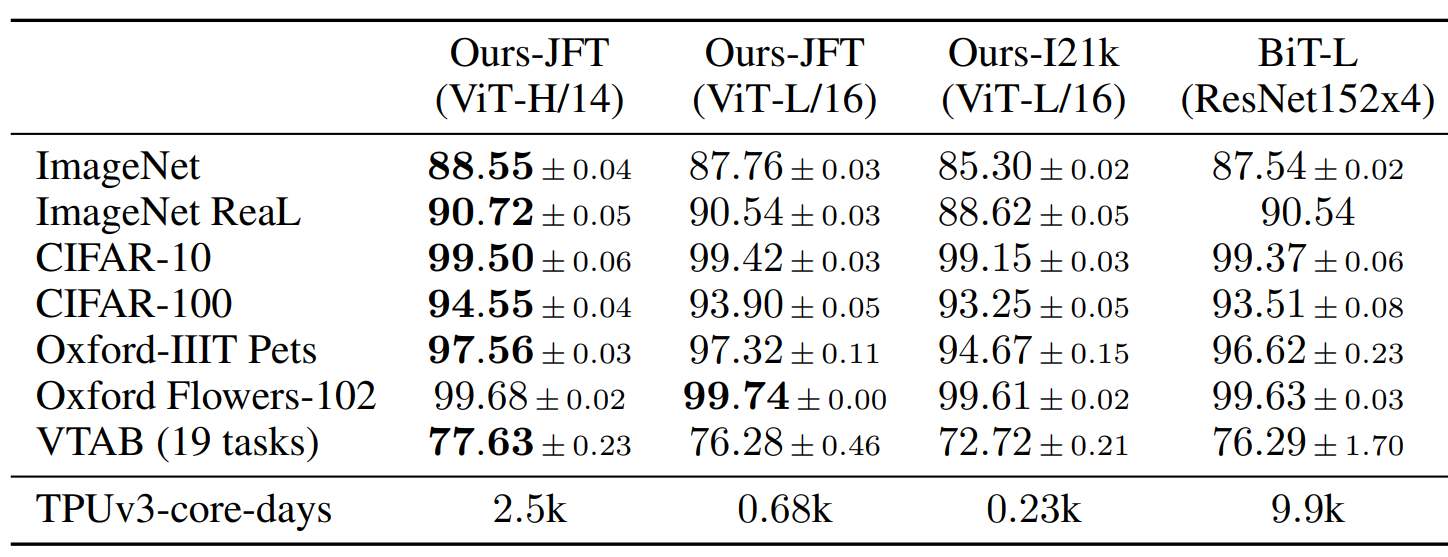
不同大小的ViT 和 BiT-L(ResNet152x4)比,訓練時間大大縮短,并且最大的ViT 結果全面超過了。
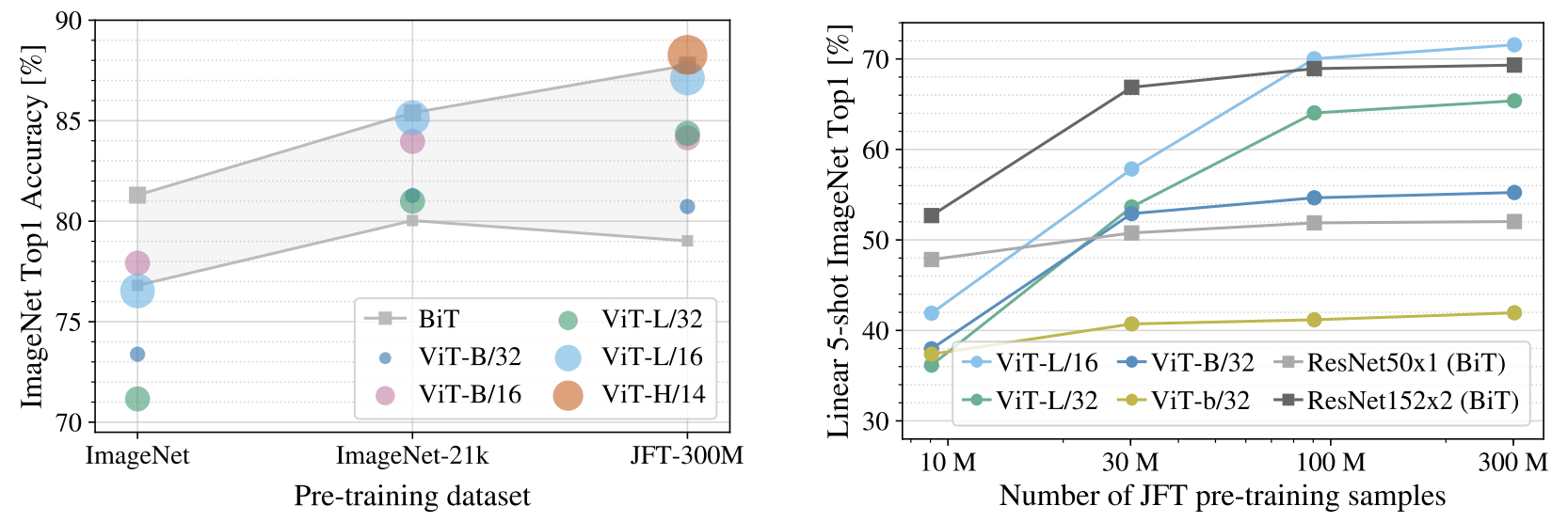
在多大的訓練集上效果比較好呢? 灰色的線 BiT代表不同大小的殘差神經網絡(灰色部分可看做對比的ReSNet的水平)。
不同大小的彩色圓點 代表不同大小的ViT。? 小規模比不上殘差神經網絡,大規模上效果好。
驗證注意力機制的有效性:

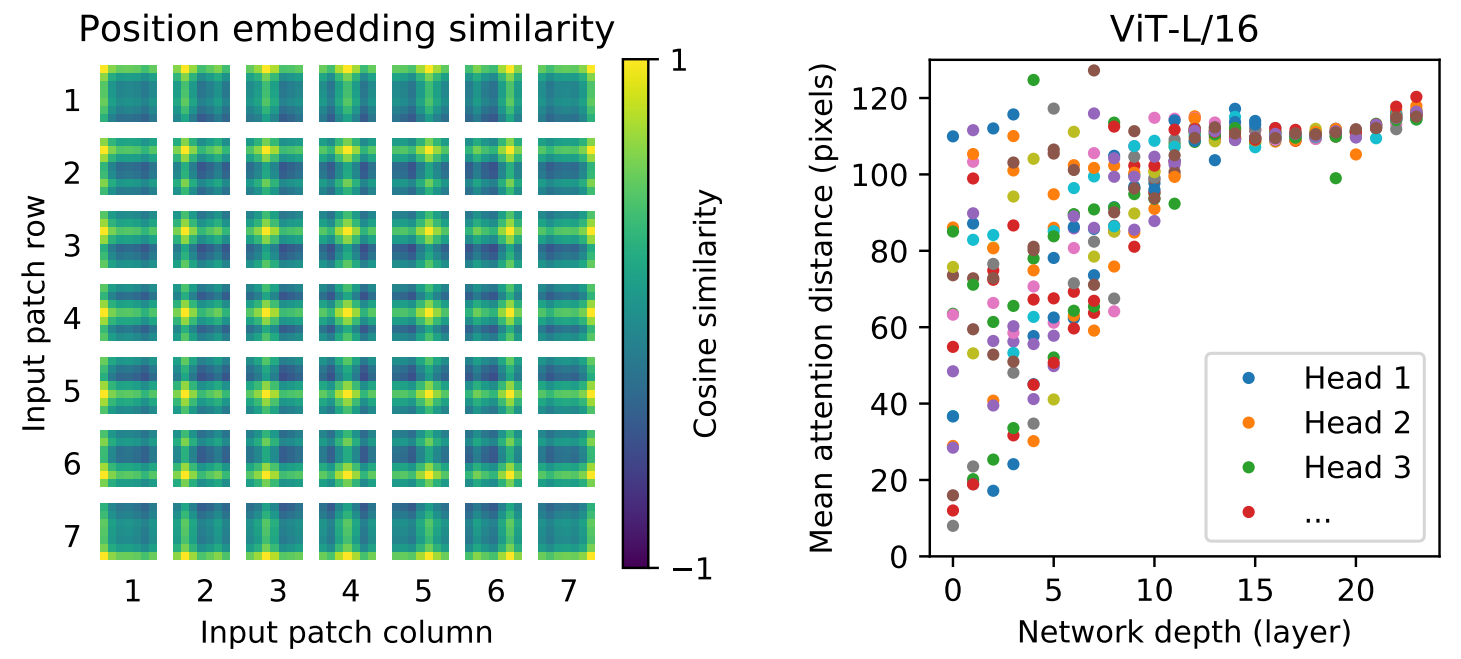
左圖:標注出Attention 對應的位置
中圖:位置編碼 黃點代表相似度高的 可以看出已經學到對應的位置了。
右圖:證明Attention 在最開始 depth比較淺的時候 就可以有比較高的pixels 注意到全局(CNN最初只能注意局部)
2. MAE - CV版的BERT
MAE 論文逐段精讀【論文精讀】
Masked Autoencoders Are Scalable Vision Learners
2.1?摘要 + 導言
????????掩碼自編碼器(MAE)是可擴展的計算機視覺自監督學習器。我們的MAE方法非常簡單:隨機掩碼輸入圖像塊并重建缺失像素。該方法基于兩個核心設計:其一,我們設計了非對稱的編碼器-解碼器架構,其中編碼器僅處理可見圖像塊(不含掩碼標記),同時配備輕量級解碼器,根據潛在表征和掩碼標記重建原始圖像;其二,我們發現對輸入圖像實施高比例掩碼(如75%)能產生具有挑戰性且意義豐富的自監督任務,在提升精度的同時讓編碼器僅處理少量圖像塊(如25%),使總體預訓練時間減少3倍以上并降低內存消耗,從而輕松將MAE擴展至大型模型。這兩種設計的結合使我們能夠高效訓練大規模模型。
????????標記數據稀缺 -> 自監督;自編碼方法在視覺領域的進展仍落后于NLP,痛點:
? ? ? ? (i)ViT 為 CV補上了架構的鴻溝([cls] 嵌入 這些)????????
????????(ii)信息密度差異:語言是人類產生的高度語義化和信息密集的信號。當訓練模型僅預測句子中少量缺失詞時,該任務就能引發復雜的語言理解。相反,圖像是具有強烈空間冗余的自然信號——例如,無需對部件、物體和場景進行高層理解,僅憑相鄰圖像塊即可重建缺失區域。為克服這種差異并促進學習有用特征,我們證明一種簡單策略在計算機視覺中非常有效:對隨機圖像塊實施極高比例的掩碼。該策略大幅降低冗余度,創建了需要超越低級圖像統計的整體理解能力的挑戰性自監督任務。(圖像冗余多 所以要相對語言 多掩碼)
????????(iii)解碼器作用差異:將潛在表征映射回輸入的自編碼器解碼器,在文本與圖像重建中扮演不同角色。在視覺領域,解碼器重建像素,因此其輸出語義級別低于常見識別任務。這與語言領域形成鮮明對比——解碼器預測的缺失詞包含豐富語義信息。雖然BERT的解碼器可以非常簡單(如MLP),但我們發現對于圖像而言,解碼器設計對決定學習到的潛在表征的語義水平起著關鍵作用。(圖像解碼器需要比語言的更復雜)
????????
例子:左為masked;中為MAE復原的;右為圖像本來的

2.2 Approach 方法
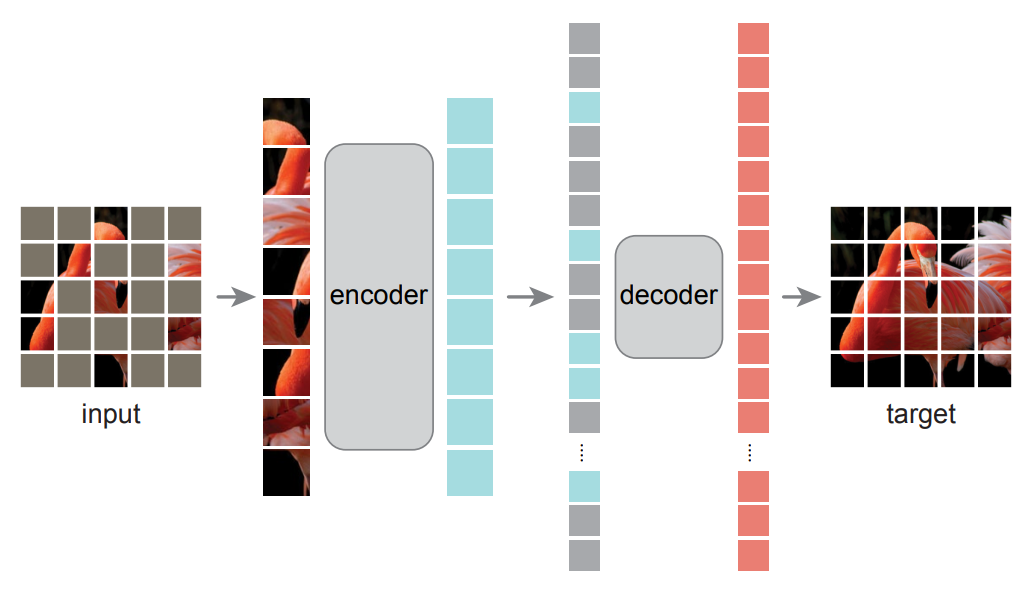
掩碼:挑一個小子集作為基礎 其他都掩碼掉 (高度稀疏的輸入 -> 高效編碼器)
編碼器:對未掩碼的小部分塊?進入類似ViT的結構;
解碼器(僅用于預訓練)可以看到未被掩碼的,也可以看到masked的(用一個 共享的 可學習的向量表示)
損失函數:計算像素空間中原圖與重建圖像在掩碼區域上的均方誤差(MSE)
對每個圖像塊歸一化后 訓練效果更好。
操作流程
1. 線性投影添加位置編碼
2.?隨機打亂,按比例移除 列表后半部分,前部分給編碼器
3.?編碼后,掩碼列表補全到列表后方,并對完整列表進行逆亂序操作(把2 隨機打亂 變換回去)再進行解碼
2.3 Experiments 實驗結果
ViT-Large 原始與加正則化;baseline MAE
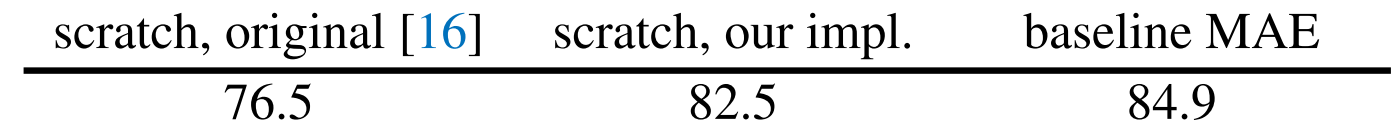
encoder、decoder深度? mask的比例和采樣方式、重建目標、數據增強的一些參數比較。
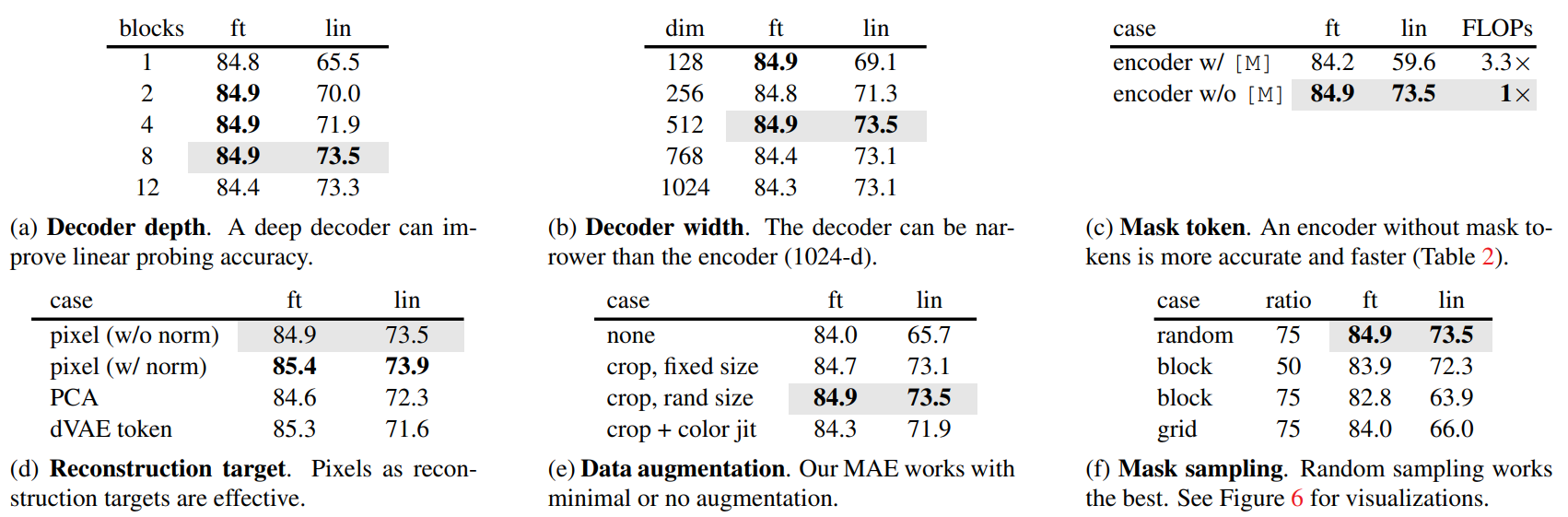
很好的性質 輪數越多效果越好
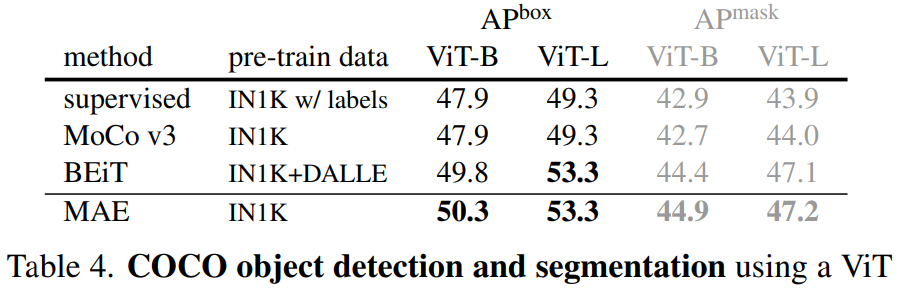
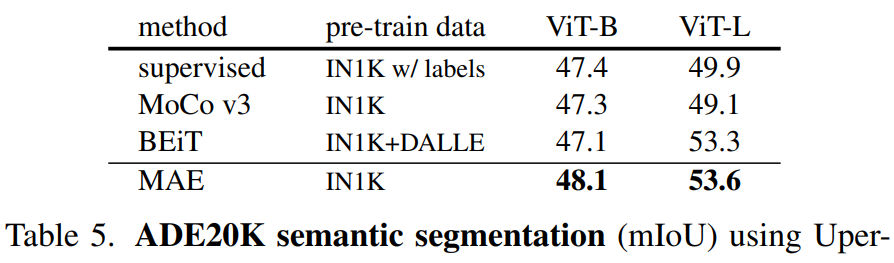
遷移學習 在別的CV任務上的能力:
目標檢測COCO? 語義分割ADE20K
3. Swin Transformer? ViT結合CNN(分層結構+滑動窗口)
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer論文精讀【論文精讀】
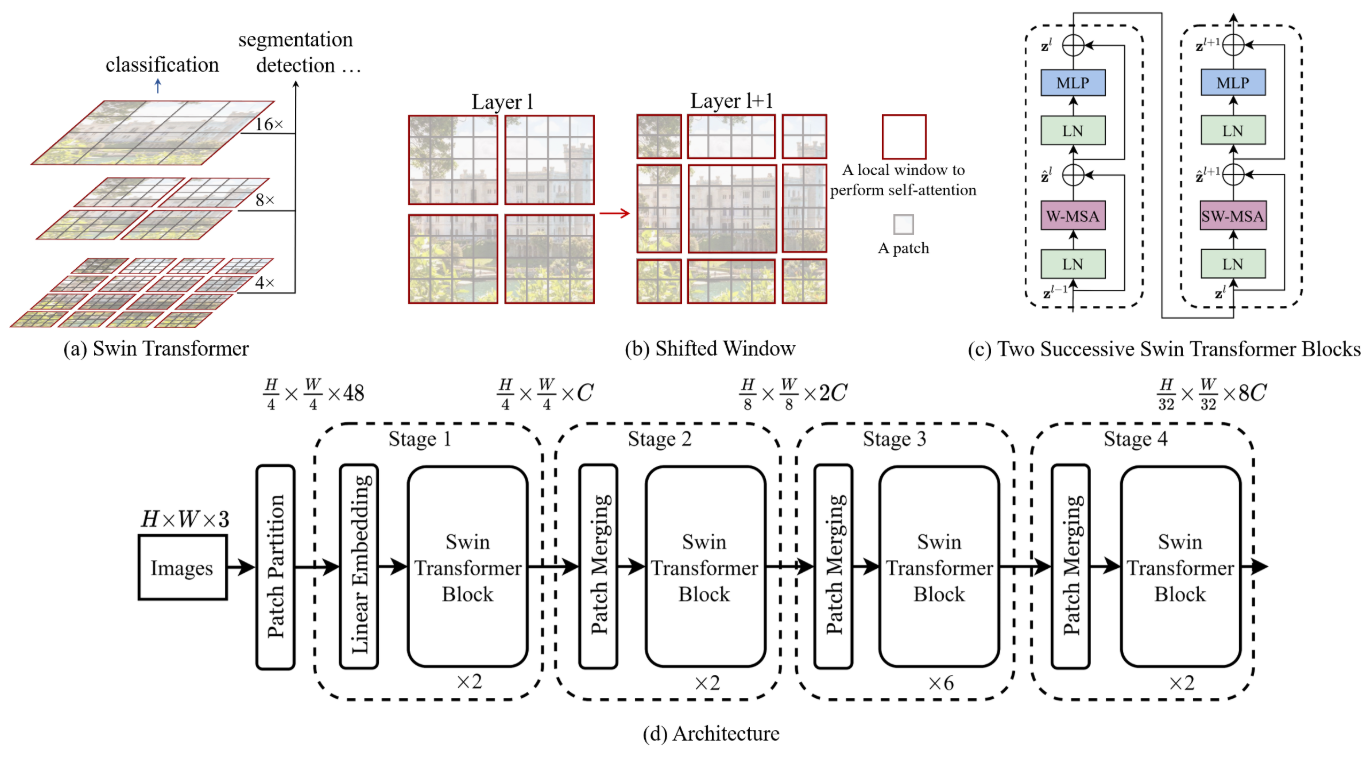
3.1?摘要 + 導言 + 結論
目標提出 Swin Transformer 作為 general-purpose backbone?for computer vision?計算機視覺的通用主干網絡
NLP中的Transformer用于視覺領域存在兩大難題:
-
尺度變化大:圖像中的物體(視覺實體)大小可以千差萬別(如一張圖里既有巨大的天空又有微小的飛鳥)。
-
分辨率過高:圖像由大量像素組成,而文本中的單詞數量相對少得多。Transformer的自注意力機制計算復雜度是序列長度的平方,直接處理圖像像素會導致計算量無法承受。
我們通過兩個關鍵創新來解決上述挑戰:分層結構?和?移動窗口。
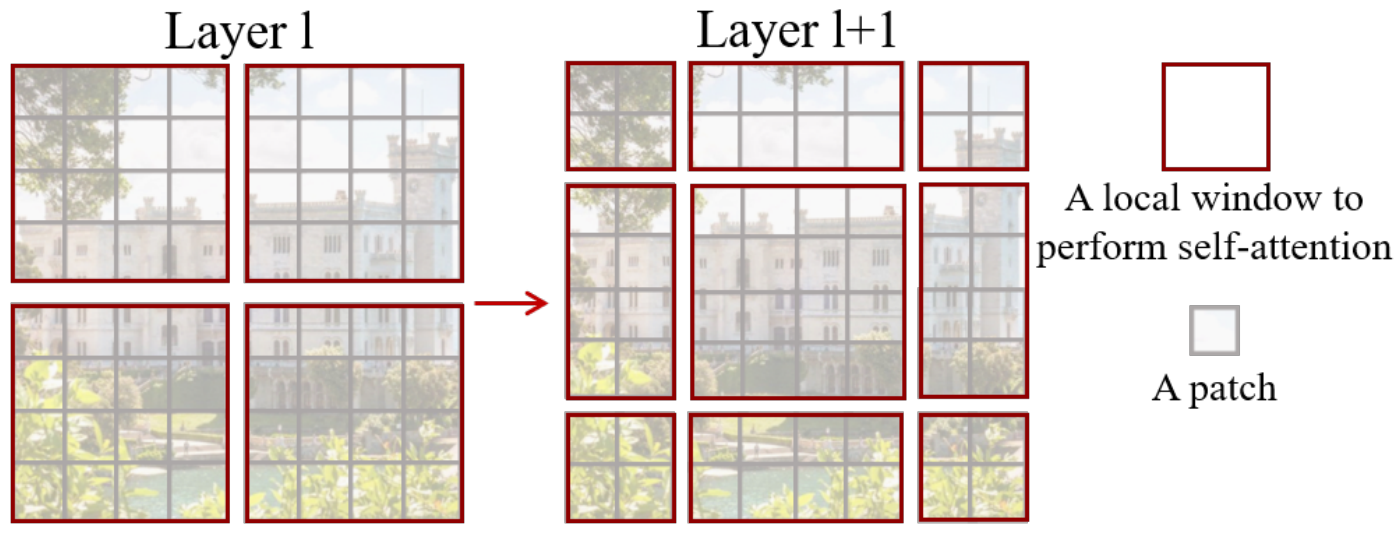
移動窗口 (Shifted Windows):
-
效率: 將自注意力計算限制在不重疊的局部窗口內。例如,將圖像分成許多小塊,只計算每個小塊內部像素之間的關系。這極大地降低了計算復雜度。
-
連接性:?移動窗口的機制使得在下一層中,窗口的邊界會發生偏移,從而讓不同窗口之間的像素能夠進行交互cross-window connection,獲取全局信息。如果不平移的話 一個patch只能看到內部而看不到全局,上例每次往右下方平移兩格。
分層結構 (Hierarchical Architecture):
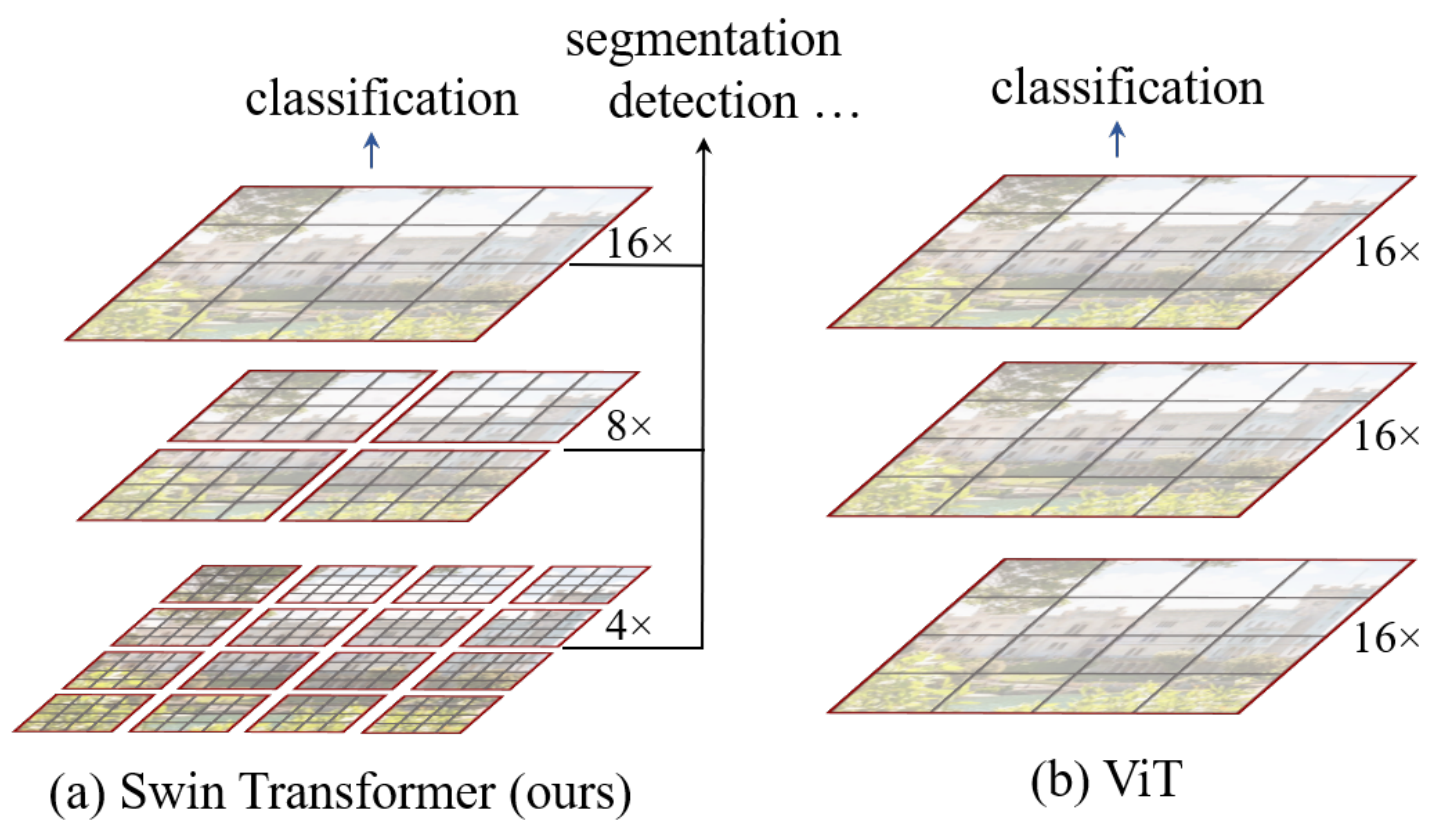
-
多尺度建模: 像CNN一樣,隨著網絡加深,逐漸合并merge patches(起到CNN中pooling的作用),形成特征圖(如?
16x16?->?8x8?->?4x4)。這使其能夠靈活處理不同尺度的物體。 -
線性復雜度: 得益于局部窗口注意力,其計算復雜度與圖像大小呈線性關系,而不是平方關系,使其能處理高分辨率圖像,降低計算復雜度。
最終目標:CV NLP大一統,多模態模型發展 unified modeling of vision and language signals.
后續研究 這個滑動窗口自注意力是否可以用到CV上。
3.2?Method 方法
3.2.1?Overall Architecture
模擬CNN過程的Transformer。分為不同的幾個階段stage。
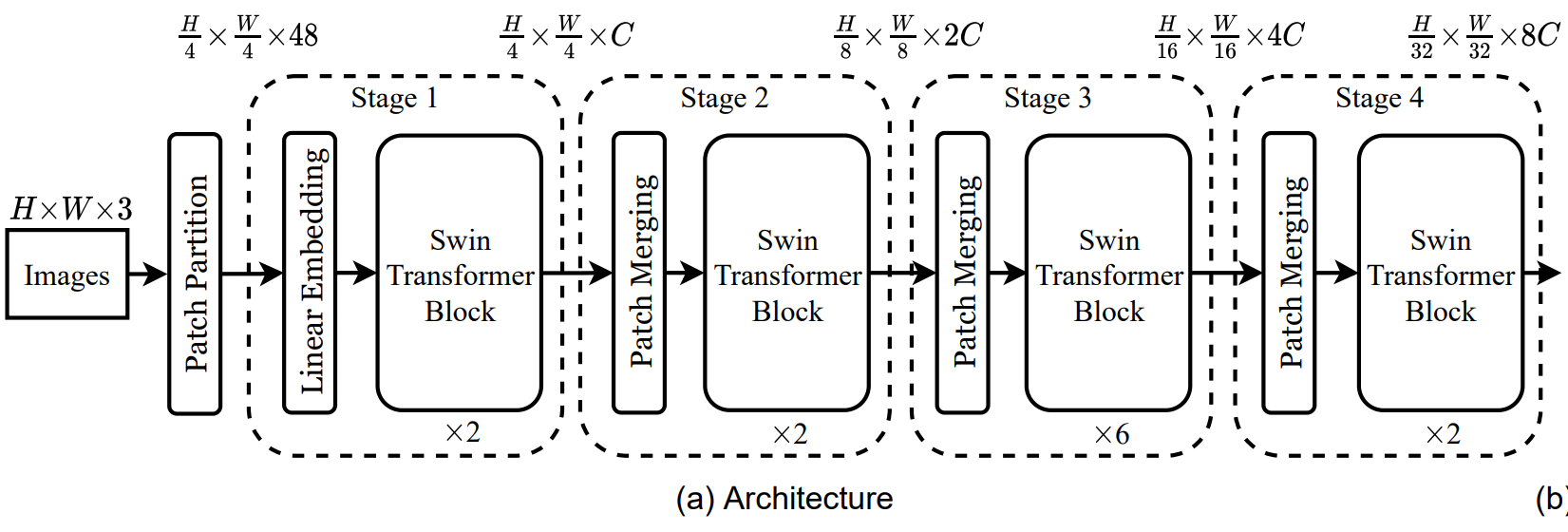
后面都設 H=W=224=14*16 的情況
最初patch劃分為 4*4;4*4*3=48? ? 變成56*56*48
Linear Embedding 把48放縮為C? ? 56*56拉直為3136;即為3136*C
3136 相比于ViT中 14*14=196的情況 太長了,需要進行窗口自注意力(經過 Swin Transformer Block 尺度不變)
patch merging操作(類似池化)? 行列數減半,通道數翻4倍 再用1*1卷積 變成翻2倍。

3.2.2?Shifted Window based Self-Attention 滑動窗口自注意力
密集預測 / 高分辨率圖像 全局自注意力 平方級別復雜度太高。
比如說 第一層 56*56*96 切成小塊 M*M的 比如取M=7? ? ?那么就在這8*8的小塊 每個小窗口里算注意力。
原來全局算MSA h*w*c原矩陣 3次乘以c*c的矩陣 得到三個h*w*c 的 q,k,v矩陣,復雜度為3*h*w*c^2
q*k 為 hw*c?*?c*hw 得到矩陣 A(hw*hw)?復雜度為 (hw)^2*c? ? ? ?A*v 復雜度也為?(hw)^2*c
最后 乘以c*c進行投影 復雜度為 h*w*c^2;上面幾項總和就為一式。

若窗口大小變成 M*M 把式子1 的所有h=w=M;一共窗口數目為 h*w/m/m
最后得到式子2的結果 關于h*w大小成正比而不是平方。
基于窗口 雖然減小了計算量 但達不到全局算注意力的效果了 于是引入shifted 移動窗口。
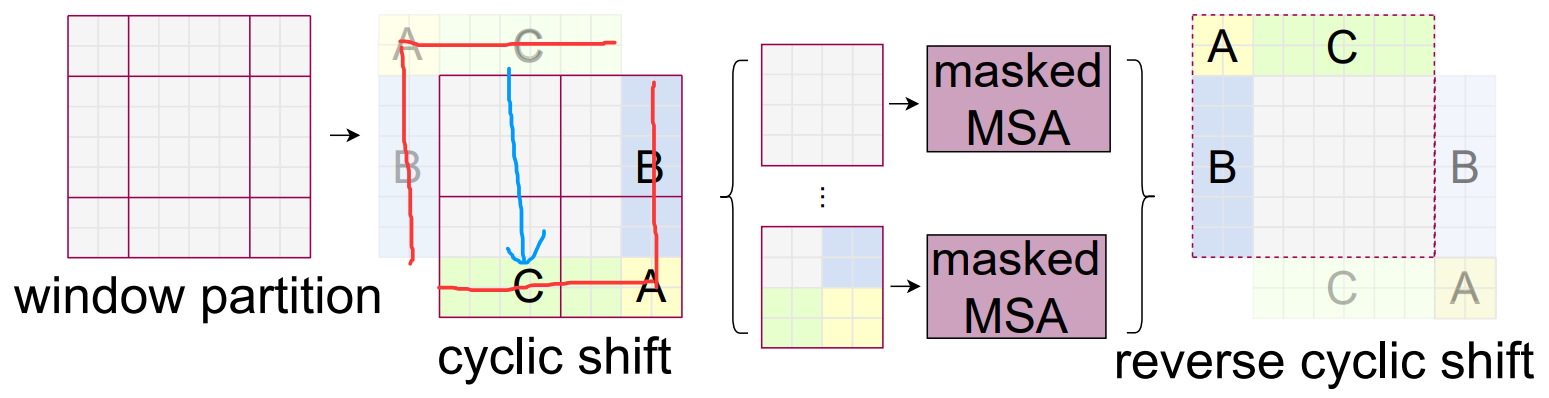
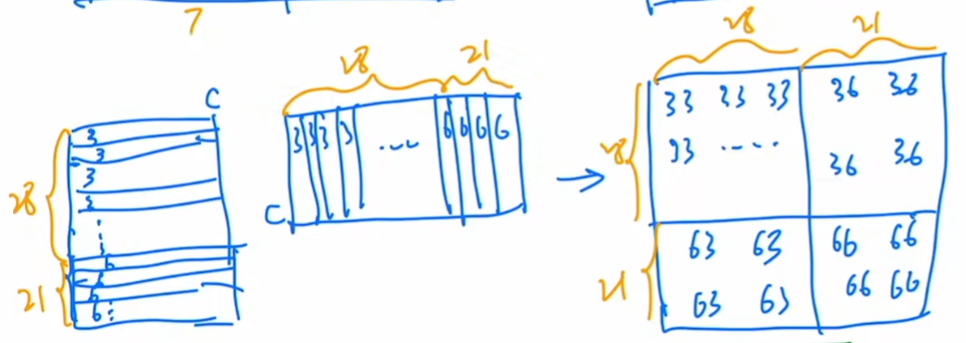
原來是四塊的 我平移之后變成了大小不一的九塊 不方便算注意力。
于是把左上角的塊 移動到右下角 還是拼成了4塊。
但不能直接算注意力 比如C之前的位置是在上面(天空)移到下面和(地面)拼在一起了,這兩個距離很遠的塊本來不應該在一起算注意力的,所以還要通過掩碼的方式 再進行反向移動還原。
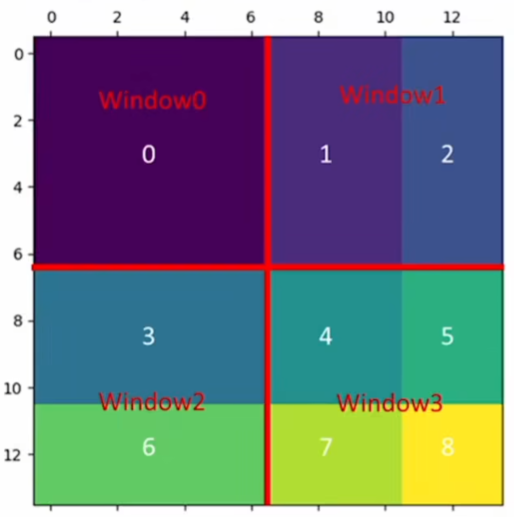
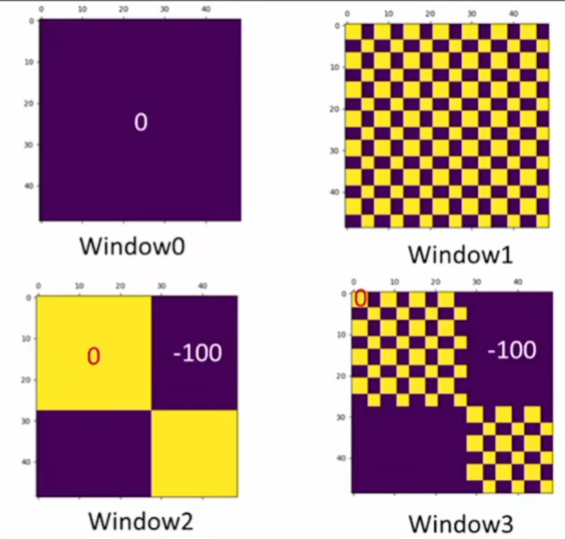
比如 3 6那邊應該3、6分別單獨算自注意力;把3 6拉直為向量 結果應該是上面一段一些3 下面一段一些6。再轉置 算注意力 相當于不要左下和右上的部分 分別減去100,再做softmax。別的部分同理。
?
3.3 Experiments 實驗結果
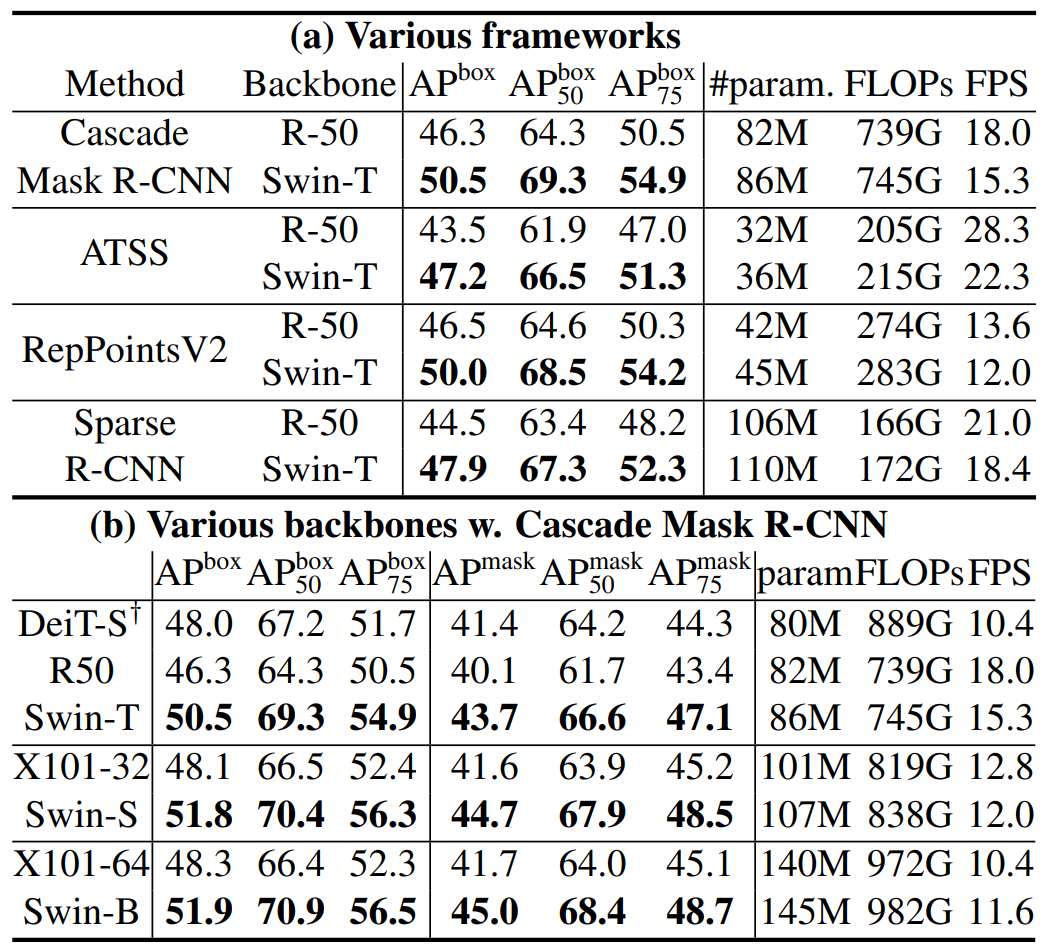
??不同大小的架構 Tiny Small Base Large
主要超參數有C的大小和 每個stage中Block的個數,
并且與對應參數量的殘差網絡進行對比(因為也是四個stage的塊)

從 framework架構上 Swin-T全方位碾壓R-50;Swin-S全方位碾壓X-101-32
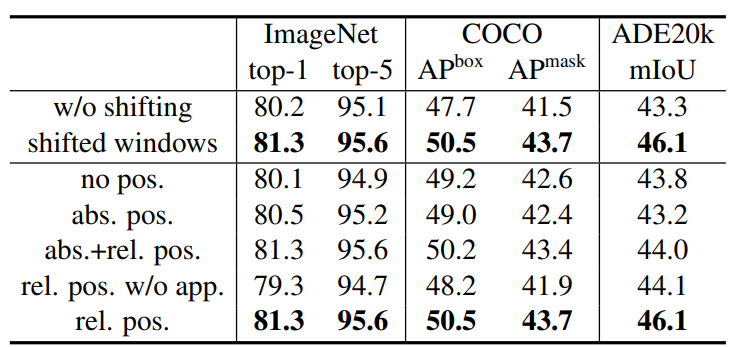
展示移動窗口和相對位置編碼的作用;在ImageNet圖像分類 COCO目標檢測 ADE20k語義分割上




)
![[Maven 基礎課程]第一個 Maven 項目](http://pic.xiahunao.cn/[Maven 基礎課程]第一個 Maven 項目)




)



——2 環境搭建與入門)


)

