今天學了第一個基于Pytorch框架的NLP任務:
判斷文本中是否出現指定字
思路:(注意:這是基于字的算法)
任務:判斷文本中是否出現“xyz”,出現其中之一即可
訓練部分:
一,我們要先設計一個模型去訓練數據。
這個Pytorch的模型:
首先通過embedding層:將字符轉化為離散數值(矩陣)
通過線性層:設置網絡的連接層,進行映射
通過dropout層:將一部分輸入設為0(可去掉)
通過激活層:sigmoid激活
通過一個pooling層:降維,將矩陣->向量
通過另一個輸出線性層:使輸出是一維(1或0)
通過一個激活層*:sigmoid激活。
二,設置一個函數:這個函數能將設定的字符變成字符集,將每一個字符設定一個代號,比如說:“我愛你”-> 我:1,愛:2,你:3。當出現"你愛我"時,計算機接受的是:3,2,1。這樣方便計算機處理字符。
三,因為我們沒有訓練樣本和測試樣本,所以我們要自己生成一些隨機樣本。通過random.choice在字符集中隨機順序輸出字符作為輸入,并將輸入中含有"xyz"的樣本的輸出值為“1”,反之為“0”
四,設置一個函數,將隨機得到的樣本,放入數據集中(列表),便于運算。
五,設置測試函數:隨機建立一些樣本,根據樣本的輸出來設定有多少個正樣本,多少個負樣本,再將預測的樣本輸出來與樣本輸出對比,得到正確率。
六,最后的main函數:按照訓練輪數和訓練組數,通過BP反向傳播更新權重進行訓練。然后調取測試函數得到acc等數據。將loss和acc的數值繪制下來,保存模型和詞表。
預測部分
將保存的詞表和模型加載進來,將輸入的字符轉化為列表,然后進入模型forward函數進行預測,最后打印出結果。
代碼實現:
import torch
import torch.nn as nn
import numpy as np
import random
import json
import matplotlib.pyplot as plt"""
基于pytorch的網絡編寫
實現一個網絡完成一個簡單nlp任務
判斷文本中是否有某些特定字符出現
"""class TorchModel(nn.Module):def __init__(self, input_dim, sentence_length, vocab):super(TorchModel, self).__init__()self.embedding = nn.Embedding(len(vocab) + 1, input_dim) #embedding層:將字符轉化為離散數值self.layer = nn.Linear(input_dim, input_dim) #對輸入數據做線性變換self.classify = nn.Linear(input_dim, 1) #映射到一維self.pool = nn.AvgPool1d(sentence_length) #pooling層:降維self.activation = torch.sigmoid #sigmoid做激活函數self.dropout = nn.Dropout(0.1) #一部分輸入為0self.loss = nn.functional.mse_loss #loss采用均方差損失#當輸入真實標簽,返回loss值;無真實標簽,返回預測值def forward(self, x, y=None):x = self.embedding(x)#輸入維度:(batch_size, sen_len)輸出維度:(batch_size, sen_len, input_dim)將文本->矩陣x = self.layer(x)#輸入維度:(batch_size, sen_len, input_dim)輸出維度:(batch_size, sen_len, input_dim)x = self.dropout(x)#輸入維度:(batch_size, sen_len, input_dim)輸出維度:(batch_size, sen_len, input_dim)x = self.activation(x)#輸入維度:(batch_size, sen_len, input_dim)輸出維度:(batch_size, sen_len, input_dim)x = self.pool(x.transpose(1,2)).squeeze()#輸入維度:(batch_size, sen_len, input_dim)輸出維度:(batch_size, input_dim)將矩陣->向量x = self.classify(x)#輸入維度:(batch_size, input_dim)輸出維度:(batch_size, 1)y_pred = self.activation(x)#輸入維度:(batch_size, 1)輸出維度:(batch_size, 1)if y is not None:return self.loss(y_pred, y)else:return y_pred#字符集隨便挑了一些漢字,實際上還可以擴充
#為每個漢字生成一個標號
#{"不":1, "東":2, "個":3...}
#不東個->[1,2,3]
def build_vocab():chars = "不東個么買五你兒幾發可同名呢方人上額旅法xyz" #隨便設置一個字符集vocab = {}for index, char in enumerate(chars):vocab[char] = index + 1 #每個字對應一個序號,+1是序號從1開始vocab['unk'] = len(vocab)+1 #不在表中的值設為前一個+1return vocab#隨機生成一個樣本
#從所有字中選取sentence_length個字
#如果vocab中的xyz出現在樣本中,則為正樣本
#反之為負樣本
def build_sample(vocab, sentence_length):#將vacab轉化為字表,隨機從字表選取sentence_length個字,可能重復x = [random.choice(list(vocab.keys())) for _ in range(sentence_length)]#指定哪些字必須在正樣本出現if set("xyz") & set(x): #若xyz與x中的字符相匹配,則為1,為正樣本y = 1else:y = 0x = [vocab.get(word,vocab['unk']) for word in x] #將字轉換成序號return x, y#建立數據集
#輸入需要的樣本數量。需要多少生成多少
def build_dataset(sample_length,vocab, sentence_length):dataset_x = []dataset_y = []for i in range(sample_length):x, y = build_sample(vocab, sentence_length)dataset_x.append(x)dataset_y.append([y])return torch.LongTensor(dataset_x), torch.FloatTensor(dataset_y)#建立模型
def build_model(vocab, char_dim, sentence_length):model = TorchModel(char_dim, sentence_length, vocab)return model#測試代碼
#用來測試每輪模型的準確率
def evaluate(model, vocab, sample_length):model.eval()x, y = build_dataset(200, vocab, sample_length)#建立200個用于測試的樣本(因為測試樣本是隨機生成的,所以不存在過擬合)print("本次預測集中共有%d個正樣本,%d個負樣本"%(sum(y), 200 - sum(y)))correct, wrong = 0, 0with torch.no_grad():y_pred = model(x) #調用Pytorch模型預測for y_p, y_t in zip(y_pred, y): #與真實標簽進行對比if float(y_p) < 0.5 and int(y_t) == 0:correct += 1 #負樣本判斷正確elif float(y_p) >= 0.5 and int(y_t) == 1:correct += 1 #正樣本判斷正確else:wrong += 1print("正確預測個數:%d, 正確率:%f"%(correct, correct/(correct+wrong)))return correct/(correct+wrong)def main():epoch_num = 10 #訓練輪數batch_size = 20 #每次訓練樣本個數train_sample = 1000 #每輪訓練總共訓練的樣本總數char_dim = 20 #每個字的維度sentence_length = 10 #樣本文本長度vocab = build_vocab() #建立字表model = build_model(vocab, char_dim, sentence_length) #建立模型optim = torch.optim.Adam(model.parameters(), lr=0.005) #建立優化器log = []for epoch in range(epoch_num):model.train()watch_loss = []for batch in range(int(train_sample / batch_size)):x, y = build_dataset(batch_size, vocab, sentence_length) #每次訓練構建一組訓練樣本optim.zero_grad() #梯度歸零loss = model(x, y) #計算losswatch_loss.append(loss.item()) #將loss存下來,方便畫圖loss.backward() #計算梯度optim.step() #更新權重print("=========\n第%d輪平均loss:%f" % (epoch + 1, np.mean(watch_loss)))acc = evaluate(model, vocab, sentence_length) #測試本輪模型結果log.append([acc, np.mean(watch_loss)])plt.plot(range(len(log)), [l[0] for l in log]) #畫acc曲線:藍色的plt.plot(range(len(log)), [l[1] for l in log]) #畫loss曲線:黃色的plt.show()#保存模型torch.save(model.state_dict(), "model.pth")writer = open("vocab.json", "w", encoding="utf8")#保存詞表writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))writer.close()return#最終預測
def predict(model_path, vocab_path, input_strings):char_dim = 20 # 每個字的維度sentence_length = 10 # 樣本文本長度vocab = json.load(open(vocab_path, "r", encoding="utf8"))model = build_model(vocab, char_dim, sentence_length) #建立模型model.load_state_dict(torch.load(model_path)) #將模型文件加載進來x = []for input_string in input_strings: #轉化輸入x.append([vocab[char] for char in input_string])model.eval() #在torch中預測注意這個:停止dropoutwith torch.no_grad(): #在torch中預測注意這個:停止梯度result = model.forward(torch.LongTensor(x)) #根據自己設計的函數定義,只輸入x就會輸出預測值for i, input_string in enumerate(input_strings):print(round(float(result[i])), input_string, result[i])#round(float(result))是將預測結果四舍五入得到0或1的預測值if __name__ == "__main__":main()#如果是進行預測,將下面兩行解除注釋,將main()注釋掉,即可調用最終預測函數進行預測# test_strings = ["個么買不東五你兒x發", "不東東么兒幾買五你發", "不東個么買五你個么買", "不z個五么買你兒幾發"]# predict("model.pth", "vocab.json", test_strings)
運行結果展示:
訓練部分:

(藍色是acc曲線,黃色是loss曲線)
預測部分:
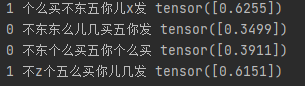
一些補充:
一:model.eval()或者model.train()的作用
如果模型中有BN層(Batch Normalization)和Dropout,需要在訓練時添加model.train(),在測試時添加model.eval()。其中model.train()是保證BN層用每一批數據的均值和方差,而model.eval()是保證BN用全部訓練數據的均值和方差;而對于Dropout,model.train()是隨機取一部分網絡連接來訓練更新參數,而model.eval()是利用到了所有網絡連接。
二:Pytorch模型中用了兩次激活函數
在每一個網絡層后使用一個激活層是一種比較常見的模型搭建方式,但不是必要的。這個只是舉例,去掉也是可行的。在具體任務中,帶著好還是不帶好也跟數據和任務本身有關,沒有確定答案(如果在代碼 中把第一個激活層注釋掉 反而性能更好)
三:對x = self.pool(x.transpose(1,2)).squeeze()代碼的解讀
通過shape方法我們能知道,在pool前,x的維度輸出是[20,10,20],代表20個10×20的矩陣,代表著[這一批的個數,樣本文本長度,輸入維度],transpose(1,2)是將x中行和列調換(轉置),然后通過pooling層將[20,20,10]->[20,20,1],最后通過squeeze()進行降維變成[20,20]。
(池化層的作用及理解)
四:embedding層的理解
embedding層并不是單純的單詞映射,而是將單詞表中每個單詞的數值與權重相乘。在第一次時有默認權重,然后在接下來的訓練中,embedding層的權重與分類權重一起經過訓練。
方法源碼解析(二))
)

python在anaconda安裝opencv庫及skimage庫(scikit_image庫)諸多問題解決辦法)



)

![歸 [拾葉集]](http://pic.xiahunao.cn/歸 [拾葉集])

與下采樣(縮小圖像))




)
填充與Vaild(有效)填充)

