支撐阻力指標
Note from Towards Data Science’s editors: While we allow independent authors to publish articles in accordance with our rules and guidelines, we do not endorse each author’s contribution. You should not rely on an author’s works without seeking professional advice. See our Reader Terms for details.
Towards Data Science編輯的注意事項: 盡管我們允許獨立作者按照我們的 規則和指南 發表文章 ,但我們不認可每位作者的貢獻。 您不應在未征求專業意見的情況下依賴作者的作品。 有關 詳細信息, 請參見我們的 閱讀器條款 。
Support and resistance are some of the most talked-about concepts when it comes to technical analysis. Support and resistance are used as price barriers, in which the price “bounces” off of. In this article, I will use the K-means clustering algorithm to find these different support and resistance channels, and trade with these insights.
在技??術分析中,支撐和阻力是最受關注的概念。 支撐和阻力被用作價格壁壘,價格從中反彈。 在本文中,我將使用K-means聚類算法找到這些不同的支撐和阻力通道,并利用這些見解進行交易。
支撐和阻力: (Support and Resistance:)
To understand how best to implement something, we should first understand the thing that we want to implement.
要了解如何最好地實現某件事,我們應該首先了解我們想要實現的那件事。

Support and Resistance, are two lines that are drawn on a graph, to form a channel, in which the price exists within.
支撐線和阻力線是在圖形上繪制的兩條線,形成價格存在于其中的通道。
Support and resistance are resultant of a security not being able to decrease or increase anymore, due to pressure from sellers or buyers. A good rule of thumb is that the more times a price is deflected against a support or resistance line, the less likely it will work again.
支持和阻力是由于賣方或買方的壓力導致證券不再能夠減少或增加的結果。 一條好的經驗法則是,價格相對于支撐線或阻力線偏轉的次數越多,其再次發揮作用的可能性就越小。
Support and resistance give good insight into entry points and selling points, as the support and resistance lines are theoretically the lowest and highest points for that limited time period.
支撐位和阻力位可以很好地了解切入點和賣出點,因為理論上,支撐位和阻力位是該有限時間段內的最低和最高點。
Downsides of the support and resistance strategy is that it works for an unknown period of time, and the lines are subjective and are therefore subject to human error.
支持和抵抗策略的缺點是,它在未知的時間段內都可以正常工作,并且線路是主觀的,因此容易遭受人為錯誤的影響。
程序概念: (Program Concept:)
The K-means clustering algorithm, finds different sections of the time series data, and groups them into a defined number of groups. This number (K) can be optimized. The highest and lowest value of each group is then defined as the support and resistance values for the cluster.
K-均值聚類算法,查找時間序列數據的不同部分,并將其分組為定義的組數。 此數字(K)可以優化。 然后將每個組的最高和最低值定義為群集的支撐和阻力值。
Now that we know how the program is intended, let’s try to recreate it in Python!
現在我們知道了程序的意圖,讓我們嘗試在Python中重新創建它!
代碼: (The Code:)
import yfinance
df = yfinance.download('AAPL','2013-1-1','2020-1-1')
X = np.array(df['Close'])This script is to access data for the Apple stock price. For this example, we are implementing the support and resistance only on the closing price.
該腳本用于訪問Apple股票價格的數據。 對于此示例,我們僅對收盤價實施支撐和阻力。
from sklearn.cluster import KMeans
import numpy as np
from kneed import DataGenerator, KneeLocator
sum_of_squared_distances = []
K = range(1,15)
for k in K:
km = KMeans(n_clusters=k)
km = km.fit(X.reshape(-1,1))
sum_of_squared_distances.append(km.inertia_)
kn = KneeLocator(K, sum_of_squared_distances,S=1.0, curve="convex", direction="decreasing")
kn.plot_knee()
# plt.plot(sum_of_squared_distances)This script is to test the different values of K to find the best value:
該腳本用于測試K的不同值以找到最佳值:

The K-value of 2 creates support and resistance lines that will never be reached for a long time.
K值2會創建支撐線和阻力線,這些支撐線和阻力線將永遠不會達到。

A K-value of 9 creates support and resistance that are far too common and make it difficult to make predictions.
K值為9時會產生太常見的支撐和阻力,因此很難進行預測。
Therefore, we have to find the best value of K, calculated by the elbow point when comparing variance between K values. The elbow point is the biggest improvement, given a certain movement.
因此,當比較K值之間的方差時,我們必須找到由彎頭計算出的K的最佳值。 給定一定的移動量,肘點是最大的改善。
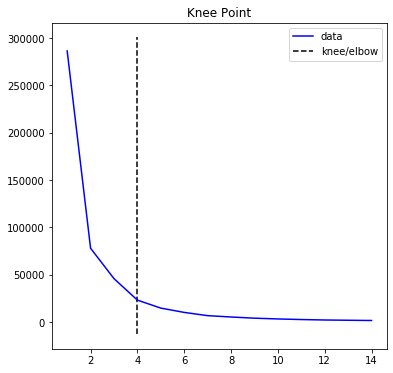
Based on the kneed library, the elbow point is at 4. This means that the optimum K value is 4.
根據膝蓋庫,肘點為4。這意味著最佳K值為4。
kmeans = KMeans(n_clusters= kn.knee).fit(X.reshape(-1,1))
c = kmeans.predict(X.reshape(-1,1))
minmax = []
for i in range(kn.knee):
minmax.append([-np.inf,np.inf])
for i in range(len(X)):
cluster = c[i]
if X[i] > minmax[cluster][0]:
minmax[cluster][0] = X[i]
if X[i] < minmax[cluster][1]:
minmax[cluster][1] = X[i]This script finds the minimum and maximum value for the points that reside in each cluster. These, when plotted, become the support and resistance lines.
該腳本查找每個群集中的點的最小值和最大值。 當繪制這些線時,它們將成為支撐線和阻力線。
from matplotlib import pyplot as plt
for i in range(len(X)):
colors = ['b','g','r','c','m','y','k','w']
c = kmeans.predict(X[i].reshape(-1,1))[0]
color = colors[c]
plt.scatter(i,X[i],c = color,s = 1)for i in range(len(minmax)):
plt.hlines(minmax[i][0],xmin = 0,xmax = len(X),colors = 'g')
plt.hlines(minmax[i][1],xmin = 0,xmax = len(X),colors = 'r')This script plots the support and resistance, along with the actual graph of the prices, which are color coded based on the cluster. Unfortunately, I think that the colors are limited, meaning that there is a limited K value in which the data can be color coded.
該腳本繪制了支撐和阻力以及價格的實際圖形,這些圖形根據集群進行了顏色編碼。 不幸的是,我認為顏色是有限的,這意味著可以對數據進行顏色編碼的K值有限。
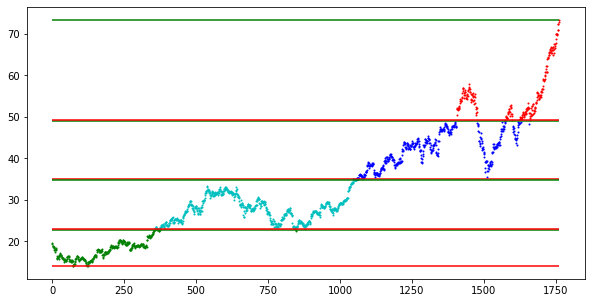
This is the result of the program, a set of support and resistance lines. Keep in mind that the lines are most accurate, when the values fall back into the channel. Additionally, the final resistance line would be the least accurate ,as it takes the last value into account, without considering any other values.
這是程序的結果,是一組支撐線和阻力線。 請記住,當值回落到通道中時,線條最準確。 另外,最終的阻力線將是最不準確的,因為它將最后一個值考慮在內,而不考慮任何其他值。
感謝您閱讀我的文章! (Thank you for reading my article!)
翻譯自: https://towardsdatascience.com/using-k-means-clustering-to-create-support-and-resistance-b13fdeeba12
支撐阻力指標
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389568.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389568.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389568.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
python在anaconda安裝opencv庫及skimage庫(scikit_image庫)諸多問題解決辦法)
高版本(3.9版本)python在anaconda安裝opencv庫及skimage庫(scikit_image庫)諸多問題解決辦法

python 實現斐波那契數列

單機安裝ZooKeeper

均線交易策略的回測 r_使用r創建交易策略并進行回測
)
opencv入門課程:彩色圖像灰度化和二值化(采用skimage庫和opencv庫兩種方法)

SVN中Revert changes from this revision 跟Revert to this revision
![歸 [拾葉集]](http://pic.xiahunao.cn/歸 [拾葉集])

instagram分析以預測與安的限量版運動鞋轉售價格
與下采樣(縮小圖像))
opencv:用最鄰近插值和雙線性插值法實現上采樣(放大圖像)與下采樣(縮小圖像)

CSS魔法堂:那個被我們忽略的outline

初創公司怎么做銷售數據分析_初創公司與Faang公司的數據科學

opencv:灰色和彩色圖像的像素直方圖及直方圖均值化的實現與展示

mysql.sock問題
)
交換機的基本原理配置(一)
填充與Vaild(有效)填充)
opencv:卷積涉及的基礎概念,Sobel邊緣檢測代碼實現及Same(相同)填充與Vaild(有效)填充

機器學習股票_使用概率機器學習來改善您的股票交易

BZOJ 2818 Gcd
)
LeetCode387-字符串中的第一個唯一字符(查找,自定義數據結構)

r psm傾向性匹配_南瓜香料指標psm如何規劃季節性廣告
