Being a sneakerhead is a culture on its own and has its own industry. Every month Biggest brands introduce few select Limited Edition Sneakers which are sold in the markets according to Lottery System called ‘Raffle’. Which have created a new market of its own, where people who able to win the Sneakers from the Lottery system want to Sell at higher prices to the people who wished for the shoes more. One can find many websites like stockx.com, goat.com to resell untouched Limited Edition sneakers.
成為運動鞋者本身就是一種文化,并且擁有自己的行業。 每個月,最大的品牌都會推出極少數的限量版運動鞋,根據抽獎系統“ Raffle”的規定,這些運動鞋會在市場上出售。 這就創造了一個自己的新市場,那些能夠從彩票系統中贏得運動鞋的人們希望以更高的價格賣給那些希望獲得更多鞋子的人們。 您可以找到許多網站,例如stockx.com ,山羊網站(comat.com)來轉售未經修飾的限量版運動鞋。
But the problem with reselling the Sneakers is, that every Limited edition sneaker is not a success, and cannot return big profits. One has to study the “hype”, “popularity” which model is a hot topic and is in discussion more than others, and if one can find that well, can gain even up to 300% profits.
但是轉售Sneakers的問題在于,每一款限量版運動鞋都不會成功,也無法獲得豐厚的利潤。 人們必須研究“炒作”,“受歡迎程度”,該模型是一個熱門話題,并且比其他人更受討論,如果能找到一個很好的例子,則可以獲得多達300%的利潤。
I found a way to discover that “hype” or popularity of certain models by doing Instagram Analysis, and studying the hashtags related to the Sneakers, and find out which Sneaker is a unicorn.
我找到了一種方法,可以通過進行Instagram分析并研究與運動鞋相關的標簽來發現某些模型的“炒作”或受歡迎程度,并找出哪個運動鞋是獨角獸。
數據抓取和準備數據 (Data Scraping and Preparing the data)
Instagram Api doesn't let you study about likes and comments on other profiles,so instead of using Instagram Api, I used Data scraping. To scrape data from Instagram you will need a hash query like this.
Instagram Api不允許您研究其他個人資料上的喜歡和評論,因此我沒有使用Instagram Api,而是使用數據抓取。 要從Instagram抓取數據,您將需要像這樣的哈希查詢。
url='https://www.instagram.com/graphql/query/?query_hash=c769cb6c71b24c8a86590b22402fda50&variables=%7B%22tag_name%22%3A%22azareth%22%2C%22first%22%3A2%2C%22after%22%3A%22QVFCVDVxVUdMLWlnTlBaQjNtcUktUkR4M2dSUS1lSzkzdGVkSkUyMFB1aXRadkE1RzFINHdzTmprY1Yxd0ZnemZQSFJ5Q1hXMm9KZGdLeXJuLWRScXlqMA%3D%3D%22%7D' As you can see keyword azareth , that is my Hashtag. You can simply change that keyword to any hashtag you want to get the data from.
如您所見,關鍵字azareth就是我的標簽 。 您可以簡單地將該關鍵字更改為要從中獲取數據的任何主題標簽。
Let us select some hashtags for Air Jordan 1 “Fearless” Sneakers #airjordanfearless,#fearless,#jordanbluefearless,#fearlessjordan,#aj1fearless,#ajonefearless,#airjordanonefearless
讓我們為Air Jordan 1“ Fearless”運動鞋選擇一些標簽,#airjordanfearless,#fearless,#jordanbluefearless,#fearlessjordan,#aj1fearless,#ajonefearless,#airjordanonefearless
#Creating a dataframe with columns hashtags
airjordanfearless = ["airjordanfearless","fearless","jordanbluefearless","fearlessjordan","aj1fearless","ajonefearless","airjordanonefearless"]
airjordanfearless=pd.DataFrame(airjordanfearless)
airjordanfearless.columns=["hashtag"]
#Creating a Coloumn of URL in order to place respective urls of the hashtags
url='https://www.instagram.com/graphql/query/?query_hash=c769cb6c71b24c8a86590b22402fda50&variables=%7B%22tag_name%22%3A%22azareth%22%2C%22first%22%3A2%2C%22after%22%3A%22QVFCVDVxVUdMLWlnTlBaQjNtcUktUkR4M2dSUS1lSzkzdGVkSkUyMFB1aXRadkE1RzFINHdzTmprY1Yxd0ZnemZQSFJ5Q1hXMm9KZGdLeXJuLWRScXlqMA%3D%3D%22%7D'
airjordanfearless["url"]= url
#code to replace the hashtag in the query URL
airjordanfearless['url'] = airjordanfearless['hashtag'].apply(lambda x : url.replace('azareth',x.lower()))After we have a Dataframe, Its time to see what we can do with the Instagram hash query. We can find Total Likes, Total Comments, Total posts related to a certain hashtag and these parameters can help us predict the “hype” and “popularity” of the sneakers.
有了Dataframe之后,該該看看該如何處理Instagram哈希查詢了。 我們可以找到總喜歡,總評論,與某個標簽相關的總帖子 ,而這些參數可以幫助我們預測運動鞋的“炒作”和“受歡迎程度”。
We will need urlib and requests libraries to open the URL and retrieve certain values we require like Total Likes, Total Comments, or even images themselves.
我們將需要urlib并請求庫來打開URL并檢索我們需要的某些值,例如“總喜歡”,“總評論”,甚至是圖像本身。
import urllib.request
import requests#opening the url and reading it to decode and search for parametrs edge_media_preview_like,edge_media_to_comment,edge_hashtag_to_mediaairjordanfearless['totalikes'] = airjordanfearless['url'].apply(lambda x :(urllib.request.urlopen(x).read().decode('UTF-8').rfind("edge_media_preview_like")))
airjordanfearless['totalcomments'] = airjordanfearless['url'].apply(lambda x :(urllib.request.urlopen(x).read().decode('UTF-8').rfind("edge_media_to_comment")))
airjordanfearless['totalposts'] = airjordanfearless['url'].apply(lambda x :(urllib.request.urlopen(x).read().decode('UTF-8').rfind("edge_hashtag_to_media")))
airjordanfearless['releaseprice'] = 160
airjordanfearless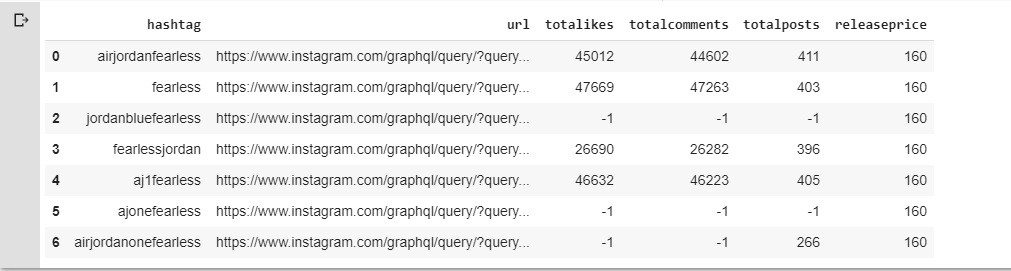
In order to create train data, I made similar data frames of some selected sneakers -Yeezy700 Azareth,Nike X Sacai Blazar,Puma Ralph Sampson OG,Nike SB Dunk X Civilist , Nike Space Hippie Collection.
為了創建火車數據,我對一些選定的運動鞋(Yeezy700 Azareth,Nike X Sacai Blazar,Puma Ralph Sampson OG,Nike SB Dunk X Civilist和Nike Space Hippie Collection)進行了類似的數據制作。
I took mean Values of Total Likes , comments and posts of all hashtags of each Sneakers to create Training Data.Max Resale prices of the following Sneakers were taken from goat.com.
我以平均總喜歡值,評論和每個運動鞋的所有標簽的帖子來創建培訓數據。以下運動鞋的最高轉售價來自山羊網站。
traindata = {'name': ['yeezyazareth','airjordanfearless','sacainikeblazar' ,'pumaralphsamson' ,'nikedunkcivilist' ,'nikespacehippie'],'likes': [yeezyazareth.totalikes.mean(),airjordanfearless.totalikes.mean(),sacainikeblazar.totalikes.mean(),pumaralphsamson.totalikes.mean(),nikedunkcivilist.totalikes.mean(),nikespacehippie.totalikes.mean()],'comment': [yeezyazareth.totalcomments.mean(),airjordanfearless.totalcomments.mean(),sacainikeblazar.totalcomments.mean(),pumaralphsamson.totalcomments.mean(),nikedunkcivilist.totalcomments.mean(),nikespacehippie.totalcomments.mean()],'post': [yeezyazareth.totalposts.mean(),airjordanfearless.totalposts.mean(),sacainikeblazar.totalposts.mean(),pumaralphsamson.totalposts.mean(),nikedunkcivilist.totalposts.mean(),nikespacehippie.totalposts.mean()],'releaseprice': [yeezyazareth.releaseprice[1],airjordanfearless.releaseprice[1],sacainikeblazar.releaseprice[1],pumaralphsamson.releaseprice[1],nikedunkcivilist.releaseprice[1],nikespacehippie.releaseprice[1]],'maxresaleprice': [361,333,298,115,1000,330], #maxresaleprice data taken from goat.com'popular':[1,1,1,0,2,1]}df = pd.DataFrame (traindata, columns = ['name','likes','comment','post','releaseprice','maxresaleprice','popular'])
df
數據培訓和ANN模型構建 (Data Training and ANN Model Building)
DATA TRAINING
資料訓練
1- The hash query gives most recent photos from Instagram for certain hashtags, so it reduces the possibility of having any old-model sneakers photos into the data, this validates, as “HYPE” or “popularity” of a certain sneaker is possibly estimated from the most recent photos, so we can know which sneakers are in Talk and hot right now and have could more resale values.
1-哈希查詢可提供來自Instagram最新照片中的特定標簽,因此可以減少將任何舊款運動鞋照片納入數據的可能性,這可以驗證,因為可能會估計某個運動鞋的“ HYPE”或“人氣”從最近的照片中,我們可以知道哪些運動鞋現在處于Talk和熱門狀態,并且可能具有更多的轉售價值。
2- For any possibility of Hashtags overlaps over photos,(which is quite possible) I talk mean counts of TOTAL LIKES/COMMENTS and POSTS to train data and to predict resale prices.
2-對于標簽在照片上重疊的任何可能性(這很有可能),我說的是“總數” /“評論”和“帖子”的均值,以訓練數據并預測轉售價格。
3- To validate the model instead of splitting data to Train or test we can simply put hashtags into x_test of the recent release of a sneaker and compare our predictions with actual ongoing resale price.
3-為了驗證模型,而不是將數據分割以進行訓練或測試,我們可以簡單地將標簽添加到運動鞋最新版本的x_test中,然后將我們的預測與實際的持續轉售價格進行比較。
Artificial Neural Network
人工神經網絡
For X , I took variable “likes”, “comment”, “post”, “releaseprice” and for Y/Labels I used the “maxretailprices” in order to make the model learn itself to place weight differently in neurons from getting data from the x variables and reach to “maxretailprices” /y data, and find a pattern between Likes and comments and number of posts on Instagram to Max retail prices.
對于X,我采用了變量“喜歡”,“評論”,“發布”,“發行價格”,對于Y / Label,我使用了“最大零售價格”,以使模型從從獲取數據中學習到如何在神經元中放置不同的權重x變量并到??達“ maxretailprices” / y數據,并在“頂”和“評論”之間以及在Instagram上的帖子數量到最大零售價格之間找到一種模式。
The reason being, more likes, comments, and Posts on Instagram related to a particular Sneakers will reflect its hype, popularity among Instagram users, and Model can find accurate weights to determine the relation between
原因是,與某個特定運動鞋相關的更多喜歡,評論和Instagram上的帖子將反映其炒作,在Instagram用戶中的流行度,并且Model可以找到準確的權重來確定兩者之間的關系。
x = df[["likes","comment","post","releaseprice"]]
x=np.asarray(x)
y=np.asarray(df.maxresaleprice)
yModel Tuning
模型調整
Learning Rate — I selected Low learning rate of 0.001 , in order to let model find weights and make gradients without overshooting the minima.
學習率 —我選擇了0.001的低學習率,以使模型找到權重并進行漸變而不會超出最小值。
Loss method- I selected MSE as a loss method, as I am trying to find relations between the variable so it is a type of regression
損失法 -我選擇MSE作為損失法,因為我試圖查找變量之間的關系,因此它是一種回歸類型
Activation Method -Relu was the best option, as it turns all negative values to 0 (being Instagram showing -1 values for 0) and places the exact value if higher then 0)
激活方法 -Relu是最好的選擇,因為它將所有負值都變為0(Instagram表示0的值為-1),如果大于0則放置確切的值)
Layers and Neurons- I played with Neurons and layers to find the best combination where gradients do not blow up , and minimizes loss at best, and able to find patterns and weights better with 50 epochs.
圖層和神經元 -我與神經元和圖層一起使用,以找到梯度不爆破的最佳組合,并最大程度地減少了損失,并能夠在50個歷元時更好地找到樣式和權重。
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.models import Sequential
import tensorflow as tf
model= Sequential()model.add(Dense(10,input_shape=[4,], activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(1, activation='relu'))
mse = tf.keras.losses.MeanSquaredError()model.compile('Adam',loss=mse)
model.optimizer.lr =0.001model.fit(x,y,epochs=50, batch_size=10, verbose=1)結果 (RESULTS)
I did not create big enough train data in order to split data between train and test. So in order to Verify results, I simply created an x_test data frame of some recent releases like the way I shown you and compared the predictions of my model with Resale prices with goat.com.Here is an example with Nike dunk LOW sb Black with resale price on goat.com 326 Euros
我沒有創建足夠大的火車數據來在火車和測試之間分配數據。 因此,為了驗證結果,我只是創建了一些最新版本的x_test數據框(如我向您展示的方式),然后將其模型的預測與山羊皮.com的轉售價格進行了比較。以下是Nike dunk LOW sb Black與出售價格goat.com 326歐元


For, complete jupyter notebook and code, you can view my repository over github.com — https://github.com/Alexamannn/Instagram-analysis-to-predict-Sneaker-resale-prices-with-ANN
對于完整的Jupyter筆記本和代碼,您可以在github.com上查看我的存儲庫— https://github.com/Alexamannn/Instagram-analysis-to-predict-Sneaker-resale-prices-with-ANN
翻譯自: https://medium.com/analytics-vidhya/instagram-analysis-to-predict-limited-edition-sneakers-resale-price-with-ann-5838cbecfab3
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389560.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389560.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389560.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
與下采樣(縮小圖像))
opencv:用最鄰近插值和雙線性插值法實現上采樣(放大圖像)與下采樣(縮小圖像)

CSS魔法堂:那個被我們忽略的outline

初創公司怎么做銷售數據分析_初創公司與Faang公司的數據科學

opencv:灰色和彩色圖像的像素直方圖及直方圖均值化的實現與展示

mysql.sock問題
)
交換機的基本原理配置(一)
填充與Vaild(有效)填充)
opencv:卷積涉及的基礎概念,Sobel邊緣檢測代碼實現及Same(相同)填充與Vaild(有效)填充

機器學習股票_使用概率機器學習來改善您的股票交易

BZOJ 2818 Gcd
)
LeetCode387-字符串中的第一個唯一字符(查找,自定義數據結構)

r psm傾向性匹配_南瓜香料指標psm如何規劃季節性廣告

主成分分析:PCA的思想及鳶尾花實例實現

兩家大型網貸平臺竟在借款人審核問題上“偷懶”?

解決 Alfred 每次開機都提示請求通訊錄權限的問題

【轉】DCOM遠程調用權限設置

opencv:邊緣檢測之Laplacian算子思想及實現

使用機器學習預測天氣_如何使用機器學習預測著陸

laravel 導出插件

國外 廣告牌_廣告牌下一首流行歌曲的分析和預測,第1部分
