數據分析中的統計概率
Data Science is a hot topic nowadays. Organizations consider data scientists to be the Crème de la crème. Everyone in the industry is talking about the potential of data science and what data scientists can bring in their BigTech and FinTech organizations. It’s attractive to be a data scientist.
數據科學是當今的熱門話題。 組織認為數據科學家是Crèmede lacrème 。 行業中的每個人都在談論數據科學的潛力以及數據科學家可以在其BigTech和FinTech組織中帶來什么。 成為一名數據科學家很有吸引力。
This article will outline everything we need to know to become an expert in the Data Science field.
本文將概述成為數據科學領域專家所需的一切。
During tough times, data scientists are required even more because it’s crucial to be able to work on projects that cut costs and generate revenue. Data science projects have been possible mainly because of the advanced computing power, data availability, and cheap storage costs.
在艱難時期,甚至需要更多的數據科學家,因為至關重要的是能夠開展削減成本和創收項目。 數據科學項目之所以成為可能,主要是因為其先進的計算能力,數據可用性和廉價的存儲成本。
A quantitative analyst, software engineer, business analyst, tester, machine learning engineer, support, DevOps, project manager to a sales executive can all work within the data science field.
定量分析師,軟件工程師,業務分析師,測試人員,機器學習工程師,支持人員,DevOps,銷售經理的項目經理都可以在數據科學領域工作。
文章目的 (Article Aim)
These are the four sections of this article:
這些是本文的四個部分:
- Data Scientists — The Magicians 數據科學家—魔術師
- Essential Skills Of Expert Data Scientists 專家數據科學家的基本技能
- Data Science Project Stages 數據科學項目階段
- Data Science Common Pitfalls 數據科學的常見陷阱
- Data Science Best Practices 數據科學最佳實踐
This article will provide an understanding of what data science is and how it works. I will also outline the skills that we need to become a successful data scientist. Furthermore, the article will outline the 10 stages of a successful data science project. The article will then mention the biggest problems we face in data science model-building projects along with the best practices that I recommend everyone to be familiar with.
本文將提供對什么是數據科學及其如何工作的理解。 我還將概述成為一名成功的數據科學家所需的技能。 此外,本文還將概述成功的數據科學項目的10個階段。 然后,本文將提及我們在數據科學模型構建項目中面臨的最大問題,以及我建議大家都熟悉的最佳實踐。
I will also highlight the skills that are required to become an expert data scientist. At times, it’s difficult to write everything down but I will be attempting to provide all of the information which I recommend to the aspiring data scientists.
我還將重點介紹成為專家數據科學家所需的技能。 有時很難將所有內容記下來,但我將嘗試向有抱負的數據科學家提供所有我推薦的信息。
1.數據科學家-魔術師 (1. Data Scientists — The Magicians)
Expert data scientists can use their advanced programming skills, their superior statistical modeling know-how, domain knowledge, and intuition to come up with project ideas that are inventive in nature, can cut costs, and generate substantial revenue for the business.
專家數據科學家可以利用其先進的編程技能,卓越的統計建模專業知識,領域知識和直覺來提出本質上具有創造性,可以削減成本并為企業帶來可觀收入的項目創意。
All we need to do is to find the term Data Science in Google Trends to visualise how popular the field is. The interest has grown over time and it is still growing:
我們需要做的就是在Google趨勢中找到術語“ 數據科學” ,以可視化該領域的受歡迎程度。 隨著時間的流逝,人們的興趣不斷增長,并且還在不斷增長:
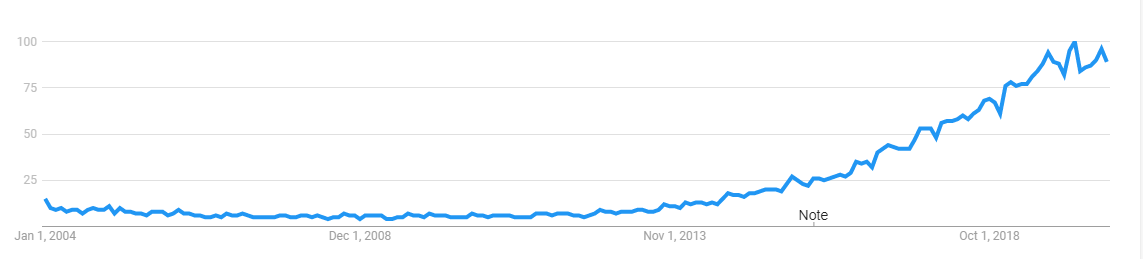
Data Science projects can solve problems that were once considered impossible to solve.
數據科學項目可以解決曾經被認為無法解決的問題。
Data science-focused solutions have pushed technology to a higher level. We are seeing solutions that are attempting to model volatility, prices, and entities’ behavior. Many companies have implemented fantastic data science applications that are not limited to the FinTech or BigTech only.
以數據科學為中心的解決方案將技術推向更高的水平。 我們看到的解決方案正在嘗試對波動性,價格和實體行為進行建模。 許多公司已經實現了出色的數據科學應用程序,這些應用程序不僅限于FinTech或BigTech。
In my view, the umbrella of data science requires individuals with a diverse set of skills; from development, analysis to DevOps skills.
我認為,數據科學的保護傘要求個人具備多種技能。 從開發,分析到DevOps技能。
2.專家數據科學家的基本技能 (2. Essential Skills Of Expert Data Scientists)
It’s necessary to have the right foundation to be a successful expert data scientist.
要成為一名成功的專家數據科學家,必須有正確的基礎。
First thing first, the subject of data science is a branch of computer science and statistics. Hence it involves one to acquire computer science and statistical knowledge. There are no two ways about it. Although the more knowledge the better but we can’t learn everything all at once. Some of the areas are more important than the others. This article will only focus on the must-know skills.
首先,數據科學是計算機科學和統計學的一個分支。 因此,它涉及到獲得計算機科學和統計知識。 關于它,沒有兩種方法。 盡管知識越多越好,但是我們無法一次學習所有內容。 一些領域比其他領域更重要。 本文僅關注必備知識。
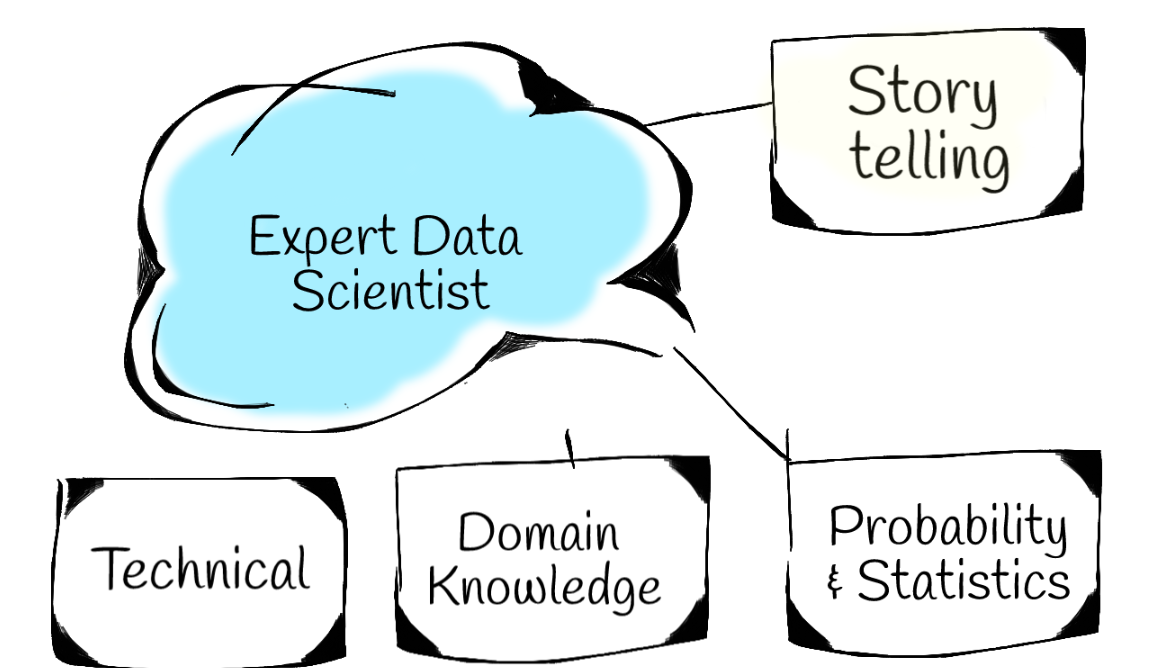
In this section, I will aim to outline the required skills. In my view, there are only 4 main skills.
在本節中,我將概述所需的技能。 我認為只有4種主要技能。
1.領域知識 (1. Domain Knowledge)
Before we can invent a solution, we need to understand the problem. Understanding the problem requires knowing the domain really well.
在我們提出解決方案之前,我們需要了解問題。 理解問題需要真正了解領域。
The must-know skills of this section are:
本節必須具備的技能:
- Understanding the current problems and solutions within the domain to highlight the inefficiencies 了解領域內的當前問題和解決方案以突出顯示低效率
- Solid understanding of how users work 對用戶的工作方式有扎實的了解
- How revenue is generated and where the cost can be saved 如何產生收入以及可以在哪里節省成本
- An understanding of who the decision-makers are and what the pain-points are 了解誰是決策者以及痛點是什么
The users of the domain are the best teachers of that domain. It takes years to become an expert in a domain. And in my view, the best way to understand the domain is to code a data science application for the users that solves the most painful problem within the domain.
該域的用戶是該域的最佳老師。 成為領域專家需要花費數年時間。 在我看來,了解該領域的最好方法是為用戶編寫一個數據科學應用程序,以解決該領域內最痛苦的問題。
2.講故事 (2. Story Telling)
I can’t emphasise enough that the most important skill for a data scientist is the ability to tell and then sell a story. The must-know skills within story-telling are:
我不能足夠強調,數據科學家最重要的技能是講述和出售故事的能力。 講故事時必須知道的技能是:
- Being imaginative 富有想象力
- Open to experiment 開放實驗
- Confidently articulating ideas clearly and concisely to the point 清晰,簡潔,自信地表達觀點
- Having the power of persuasion 具有說服力
- Being confident to seek guidance from the domain experts 有信心尋求領域專家的指導
- Presenting the data and methodology 展示數據和方法
Most importantly, the key ingredient is genuinely believing in your idea.
最重要的是,關鍵要素是真正相信您的想法。
Therefore, the most important skill is essentially a soft-skill. And believe me, given the right training, all of us can master it.
因此,最重要的技能本質上是軟技能。 相信我,只要接受正確的培訓,我們所有人都可以掌握它。
The story should concisely and clearly explain the problem that the proposed data science solution is intending to solve. The decision-makers should be able to determine that the problem does exist and the proposed solution can help them cut costs and generate further revenue.
這個故事應該簡潔明了地說明所提出的數據科學解決方案打算解決的問題。 決策者應該能夠確定問題確實存在,并且所提出的解決方案可以幫助他們削減成本并產生更多收入。
Without storytelling, it’s nearly impossible to get projects funded by the business, and without projects, data scientists’ skills can end up rotting.
如果沒有講故事的話,就幾乎不可能獲得由企業資助的項目,而沒有項目的話,數據科學家的技能就可能最終敗壞。
The usual questions that the stakeholders enquire about are around the timelines which are heavily dependent on the required data. Therefore, it’s crucial to help them understand what those required data sets are and where to fetch them.
利益相關者詢問的常見問題圍繞時間軸,這些時間軸很大程度上取決于所需的數據。 因此,至關重要的是幫助他們了解那些必需的數據集是什么以及從何處獲取它們。
During the project lifecycle, the solution is usually presented to several users. Hence one should be able to confidently present his/her ideas.
在項目生命周期中,解決方案通常提供給多個用戶。 因此,一個人應該能夠自信地提出自己的想法。
Therefore, the key skill is the ability to tell a story of your data science project and pitch it with the right detail to the target audience.
因此,關鍵技能是能夠講述您的數據科學項目的故事并向目標受眾介紹正確細節的能力。
3.技術能力: (3. Technical Skills:)
We need to be able to prepare a prototype at a minimum and later productionise it into a production-quality software.
我們需要能夠至少準備一個原型,然后將其生產成具有生產質量的軟件。
The must-know technical skills are the ability to:
必須知道的技術技能是能夠:
- Create classes, functions, call external APIs, and a thorough understanding of the data structures. 創建類,函數,調用外部API,并對數據結構有透徹的了解。
- Expertise in loading and saving data from various sources via programming (SQL + Python) 擅長通過編程(SQL + Python)從各種來源加載和保存數據
- Ability to write functions to transform data into the appropriate format 能夠編寫將數據轉換為適當格式的函數
It’s obvious that an understanding of designing scalable technological solutions using micro-services architecture, with the knowledge of continuous integration and deployment is important but I am intentionally avoiding the mention of these skills for now and I am only concentrating on the must-know skills. Again, the more knowledge the better but here, let’s concentrate on the must-know only.
顯然,了解具有微服務體系結構的可伸縮技術解決方案的設計以及持續集成和部署的知識很重要,但是我有意暫時避免提及這些技能,而我只專注于必須了解的技能。 同樣,知識越多越好,但是在這里,讓我們僅關注必須知道的內容。
Although we can use R programming language and I have written articles on R but I recommend and prefer to use the Python programming language. Python has started to become the De-facto of choice for Data Scientists. Plus, there is huge community support. I have yet to find a question on Python that has not been answered already.
盡管我們可以使用R編程語言,并且我已經撰寫了有關R的文章,但是我還是建議并喜歡使用Python編程語言。 Python已開始成為數據科學家的首選事實。 另外,社區提供了巨大的支持。 我尚未找到關于Python的問題,但尚未得到解答。
Google trends shows that the popularity of Python is ever increasing:
Google的趨勢表明,Python的流行程度正在不斷提高:
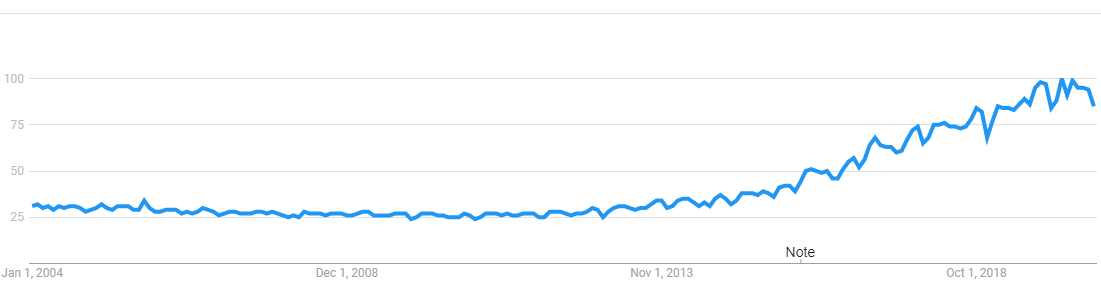
Therefore the first key skill within the technology section is to have a solid grip on the Python programming language.
因此,技術部分的首要關鍵技能是牢固掌握Python編程語言。
I highly recommend reading this article:
我強烈建議您閱讀本文:
It’s a known fact that data scientists spend a large amount of their time designing solutions to gather data. Most of the data is either text-based or numerical?in?nature. Plus the datasets are usually unstructured. There is an unlimited number of Python packages available and it’s near-to-impossible to learn about all of them. There are 3 packages that I always recommend everyone: Pandas, Numpy and Sci-kit Learn.
眾所周知,數據科學家花費大量時間來設計解決方案以收集數據。 本質上,大多數數據是基于文本的或數字的。 另外,數據集通常是非結構化的。 有無數個可用的Python軟件包,要了解所有這些軟件包幾乎是不可能的。 我總是向所有人推薦3種軟件包:Pandas,Numpy和Sci-kit Learn。
Numpy is a widely used package within the data science ecosystem. It is extremely efficient and fast at number crunching. Numpy allows us to deal with arrays and matrices.
Numpy是數據科學生態系統中廣泛使用的軟件包。 它在數字運算方面非常高效且快速。 Numpy使我們能夠處理數組和矩陣。
It’s important to understand how to:
了解如何進行以下操作很重要:
- Create collections such as arrays and matrices. 創建集合,例如數組和矩陣。
- How to transpose matrices 如何轉置矩陣
- Perform statistical calculations along with saving the results. 執行統計計算并保存結果。
I highly recommend this article. It is sufficient to understand Numpy:
我強烈推薦這篇文章。 理解Numpy就足夠了:
Finally, as most of our time is spent on playing with data, we rely heavily on databases and Excel spreadsheets to reveal the hidden secrets and trends within the data sets.
最后,由于我們大部分時間都花在處理數據上,因此我們嚴重依賴數據庫和Excel電子表格來揭示數據集中隱藏的秘密和趨勢。
To find those patterns, I recommend the readers to learn the Pandas library. Within Pandas features, it’s essential to understand:
為了找到這些模式,我建議讀者學習熊貓庫。 在熊貓功能中,必須了解以下內容:
- What a dataframe is 什么是數據框
- How to load data into a dataframe 如何將數據加載到數據框中
- How to query a data frame 如何查詢數據框
- How to join and filter dataframes 如何加入和過濾數據框
- Manipulate dates, fill the missing values along with performing statistical calculations. 處理日期,填充缺失值以及執行統計計算。
I recommend this article that explains just that:
我推薦這篇文章,解釋一下:
As long as we can manipulate and transform data into the appropriate structures, we can use Python to call any machine learning library. I recommend everyone to read on the interfaces to the Scikit-learn library.
只要我們可以操縱數據并將其轉換為適當的結構,就可以使用Python調用任何機器學習庫。 我建議大家閱讀Scikit學習庫的接口。
4.統計和概率技巧 (4. Statistics And Probability Skills)
Calling the machine learning models is technical in nature but explaining and enhancing the models requires the knowledge of probability and statistics.
調用機器學習模型本質上是技術性的,但是解釋和增強模型需要概率和統計知識。
Let’s not see machine learning models as black-boxes as we’ll have to explain the workings to the stakeholders, team-members and improve on the accuracy in the future.
讓我們不要將機器學習模型視為黑盒,因為我們將不得不向利益相關者,團隊成員解釋工作原理,并在將來提高準確性。
The must-know skills within the statistics and probability section are:
“統計和概率”部分中必須掌握的技能是:
- Probability distributions 概率分布
- Sampling techniques 采樣技術
- Simulation techniques 仿真技術
- Calculation of the moments 力矩的計算
- Thorough understanding of accuracy measures and loss functions 透徹了解準確性指標和損失函數
- Regression and Bayesian models understanding 回歸和貝葉斯模型理解
- Time series knowledge 時間序列知識
Once we have the data, it’s important to understand the underlying characteristics of the data. Therefore, I recommend everyone to understand statistics and probability. In particular, the key is to get a good grip on the various probability distributions, what they are, how sampling works, how we can generate/simulate data sets, and perform hypothesis?analysis.
一旦有了數據,了解數據的基本特征就很重要。 因此,我建議大家了解統計數據和概率。 特別是,關鍵是要牢牢把握各種概率分布,它們是什么,采樣如何工作,我們如何生成/模擬數據集以及執行假設分析。
Unless we understand the area of statistics, the machine learning models can appear to be a black-box. If we acknowledge how statistics and probability work then we can understand the models and explain them confidently.
除非我們了解統計領域,否則機器學習模型可能看起來像一個黑匣子。 如果我們承認統計數據和概率的工作原理,那么我們可以理解模型并自信地解釋它們。
There are two must-read articles that I recommend everyone to read to get a solid grip on Statistics and Probability.
我建議大家閱讀兩篇必讀的文章,以扎實地掌握“統計和概率”。
The first article will explain the key concepts of Probability:
第一篇文章將解釋概率的關鍵概念:
The second article provides an overview of the Statistical inference techniques:
第二篇文章概述了統計推斷技術:
Although the knowledge of neural networks, activation functions, couplas, Monte-Carlo simulations, and Ito calculus is important, I want to concentrate on the must-know statistical and probability skills.
盡管神經網絡,激活函數,偶合算,蒙特卡洛模擬和伊托演算的知識很重要,但我還是要專注于必知的統計和概率技能。
As we start working on more projects, we can look into advanced/expert level architecture and programming skills, understand how deep learning models work and how to deploy and monitor data science applications but it’s necessary to get the foundations right.
當我們開始從事更多項目時,我們可以研究高級/專家級的體系結構和編程技能,了解深度學習模型的工作原理以及如何部署和監視數據科學應用程序,但是有必要打好基礎。
3.數據科學項目階段 (3. Data Science Project Stages)
Let’s start by understanding what a successful data science project entails.
讓我們首先了解成功的數據科學項目意味著什么。
We can slice and dice a data science project in a million ways but in a nutshell, there are 10 key stages.
我們可以用一百萬種方式對數據科學項目進行切片和切塊,但概括地說,有10個關鍵階段。
I will explain each of the stage below.
我將在下面解釋每個階段。
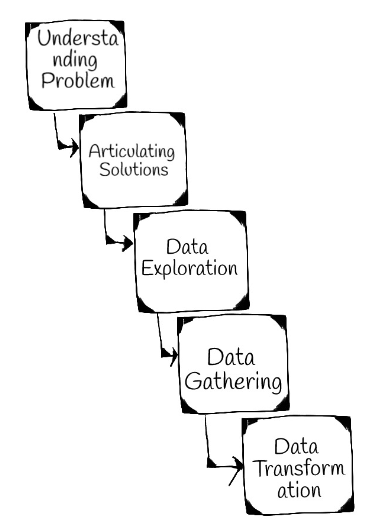
1.了解問題 (1. Understanding The Problem)
This is the first stage of a data science project. It requires acquiring an understanding of the target business domain.
這是數據科學項目的第一階段。 它需要了解目標業務領域。
It involves data scientists to communicate with business owners, analysts, and team members. The current processes in the domain are first understood to discover whether there are any inefficiencies and whether the solutions already exist within the domain. The key is to present the problem and the solution to the users earlier on.
它涉及數據科學家與業務所有者,分析師和團隊成員進行溝通。 首先要了解域中的當前過程,以發現域中是否存在任何效率低下以及解決方案是否已經存在。 關鍵是盡早向用戶介紹問題和解決方案。
2.闡明解決方案 (2. Articulating The Solutions)
The chosen solution(s) are then presented clearly to the decision-makers. The inputs, outputs, interactions, and cost of the project is decided.
然后將所選解決方案清楚地呈現給決策者。 確定項目的投入,產出,相互作用和成本。
This skill at times takes a long time to master because it requires sales and analysis skills. One needs to understand the domain extremely well and sell the idea to the decision-makers.
有時,此技能需要很長時間才能掌握,因為它需要銷售和分析技能。 人們需要非常了解該領域,并將其推銷給決策者。
The key is to evaluate the conceptual soundness, write down, and agree on all of the assumptions and benchmark results. Always choose a benchmark process. It could be the current process and the aim is to produce a solution that is superior to the current benchmark process. Benchmark processes are usually known and understood by the users. Always keep a record of how the benchmark solution works?as?it?will?help?in?comparing?the?new?solutions.
關鍵是評估概念的穩健性,寫下并在所有假設和基準結果上達成一致。 始終選擇基準測試流程。 可能是當前流程,目的是提供一種優于當前基準流程的解決方案。 基準過程通常是用戶已知和理解的。 始終記錄基準解決方案的工作方式,因為這將有助于比較新解決方案。
It’s important to mention the assumptions, note them down, and get users validation as the output of the application will depend on these assumptions.
重要的是要提及這些假設,將其記錄下來,并讓用戶驗證,因為應用程序的輸出將取決于這些假設。
3.數據探索 (3. Data Exploration)
Now that the problem statement is determined, this step requires exploring the data that is required?in?the?project. It involves finding the source of the data along with the required quantity, such as the number of records or timeline for the historic data?and?where?we?can?source?it?from.
現在已經確定了問題陳述,此步驟需要探索項目中所需的數據。 它涉及查找數據源以及所需數量,例如歷史數據的記錄數或時間表以及我們從何處獲取數據。
Consequently, it requires business and quantitative analytical skills.
因此,它需要業務和定量分析技能。
4.數據收集 (4. Data Gathering)
This stage is all about interfacing with the data teams and sourcing the required data. It requires building tools using advanced programming techniques to gather the data and saving the data into a repository such as files or databases. The data can be extracted via web service calls, databases, files, etc.
這個階段就是與數據團隊進行交互并采購所需的數據。 它需要使用高級編程技術構建工具來收集數據并將數據保存到文件或數據庫等存儲庫中。 可以通過Web服務調用,數據庫,文件等提取數據。
This requires technical skills to call the APIs and saving them in the appropriate data structures. I also recommend everyone to get a solid understanding of the SELECT SQL statements.
這需要技術技能來調用API并將其保存在適當的數據結構中。 我還建議大家對SELECT SQL語句有深入的了解。
5.數據轉換 (5. Data Transformation)
This stage requires going over each feature and understanding how we need to fill the missing values, which cleaning steps we need to perform, whether we need to manipulate the dates, if we need to standarise or normalise the data, and/or create new features from the existing features.
此階段需要遍歷每個功能,并了解我們如何填充缺失值,需要執行哪些清理步驟,是否需要操縱日期,是否需要對數據進行標準化或標準化和/或創建新功能從現有功能。
This stage requires understanding data statistical probability distributions.
此階段需要了解數據統計概率分布。
6.模型選擇與評估 (6. Model Selection and Evaluation)
This stage requires feeding the data to the statistical machine learning models so that they can interpret the data, train themselves, and output the results. Then we need to tune the parameters of the selected models to obtain the highest accuracy. This stage requires an understanding of statistical models and accuracy measures. There are a large number of models available, each with their benefits and drawbacks.
此階段需要將數據提供給統計機器學習模型,以便他們可以解釋數據,進行自我訓練并輸出結果。 然后,我們需要調整所選模型的參數以獲得最高的精度。 此階段需要了解統計模型和準確性度量。 有大量可用的模型,每種模型都有其優點和缺點。
Most of the machine learning models have been implemented in Python and they are publicly available
大多數機器學習模型已經用Python實現,并且可以公開獲得
The key is to be able to know which model to call, with what parameters, and how to measure its accuracy.
關鍵是能夠知道調用哪個模型,使用哪些參數以及如何測量其準確性。
It’s crucial to split the input data into three parts:
將輸入數據分為三部分至關重要:
- Train — which is used to train the model 訓練—用于訓練模型
- Test — that is used to test the accuracy of the trained model 測試-用于測試訓練模型的準確性
- Validation — used to enhance the model accuracy once the model hyper-parameters are fine-tuned 驗證-用于微調模型超參數后,用于增強模型準確性
I highly recommend this article. It explains the end-to-end machine learning process in an intuitive manner:
我強烈推薦這篇文章。 它以直觀的方式說明了端到端的機器學習過程:
It is also advisable to choose a simple model first which can give you your expected results. This model is known as the benchmark model. Regression models are traditionally good benchmark models.
最好先選擇一個簡單的模型,它可以為您提供預期的結果。 該模型稱為基準模型。 回歸模型通常是良好的基準模型。
The regression models are simple and can reveal errors in your data sets at earlier stages. Remember overfitting is a problem and the more complex the models, the harder it is to explain the outcomes to the users. Therefore, always look into simpler models first and then apply regularisation to prevent over-fitting. We should also utilise boosting and bagging techniques as they can overweight observations based on their frequency and improve model predictivity ability. Once we have exhausted the simple models, only then we should look into advanced models, such as the deep learning models.
回歸模型很簡單,可以在早期階段揭示數據集中的錯誤。 請記住,過度擬合是一個問題,模型越復雜,向用戶解釋結果的難度就越大。 因此,請始終先研究較簡單的模型,然后再應用正則化以防止過度擬合。 我們還應該利用增強和裝袋技術,因為它們可以根據頻率增加觀測值并提高模型的預測能力。 一旦我們用完了簡單的模型,只有到那時,我們才應該研究高級模型,例如深度學習模型。
To understand how neural networks work, read this article:
要了解神經網絡如何工作,請閱讀本文:
7.測試應用 (7. Testing Application)
This stage requires testing the current code to ensure it works as expected to eliminate any model risk. We have to have a good understanding of testing and DevOps skills to be able to implement continuous integration build plans that can run with every check-in.
此階段需要測試當前代碼,以確保其按預期工作,以消除任何模型風險。 我們必須對測試和DevOps技能有充分的了解,才能實施可在每次簽入時運行的持續集成構建計劃。
The build plans should perform a check-out of the code, run all of the tests, prepare a code coverage report, and produce the required artifacts. Our tests should involve feeding the application the unexpected data?too. We should stress and performance test the application and ensure all of the integration points work. The key is to build unit, integration, and smoke tests in your solution. I also recommend building a behavior-driven testing framework?which?ensures?that?the?application?is?built?as?per?the?user requirements. I have used behave Python package and I recommend it to everyone.
構建計劃應執行代碼檢出,運行所有測試,準備代碼覆蓋率報告并生成所需的工件。 我們的測試也應包括向應用程序提供意外的數據。 我們應該對應用程序進行壓力測試和性能測試,并確保所有集成點都能正常工作。 關鍵是在解決方案中進行單元測試,集成測試和冒煙測試。 我還建議構建一個行為驅動的測試框架,以確保根據用戶要求構建應用程序。 我已經使用了behave Python包,并向所有人推薦。
8.部署和監視應用程序 (8. Deployment And Monitoring Application)
This stage involves deploying the code to an environment where the users can test and use the application. The process needs to run without any human intervention. This involves DevOps skills to implement continuous deployment. It should take the artifacts and deploy the solution. The process should run a smoke test and notify the users that the application is deployed successfully so that everything is automated.
此階段涉及將代碼部署到用戶可以測試和使用應用程序的環境。 該過程無需任何人工干預即可運行。 這涉及DevOps技能以實現連續部署。 它應該采用工件并部署解決方案。 該過程應運行冒煙測試,并通知用戶該應用程序已成功部署,從而使一切自動化。
We are often required to use microservices architecture within containers to deploy the solution horizontally across servers.
我們經常需要在容器內使用微服務架構,以在服務器之間水平部署解決方案。
Once the solution is up, we need to monitor it to ensure it’s up and running without any issues. We should log all of the errors and implement heart-beat endpoints that we can call to ensure that the application is running successfully.
解決方案啟動后,我們需要對其進行監視以確保其正常運行。 我們應該記錄所有錯誤并實現可調用的心跳端點,以確保應用程序成功運行。
Data science projects are not one-off projects. They require continuous monitoring of the acquired data sets, problems, and solutions to ensure that the current system works as desired.
數據科學項目不是一次性項目。 他們需要對所獲取的數據集,問題和解決方案進行連續監控,以確保當前系統能夠按需運行。
I highly recommend this article that aims to explain the Microservices architecture from the basics:
我強烈推薦這篇旨在從基礎知識解釋微服務架構的文章:
9.申請結果介紹 (9. Application Results Presentation)
We are now ready to present the results. We might want to build a web user interface or use reporting tools such as Tablaue amongst other tools to present the charts and data sets to the users.
我們現在準備介紹結果。 我們可能想構建一個Web用戶界面,或者使用諸如Tablaue之類的報告工具以及其他工具來向用戶展示圖表和數據集。
It comes back to the domain and story-telling skills.
回到領域和講故事的技巧。
10.回測應用 (10. Backtesting Application)
Lastly, it’s crucial to back-test the application. Once the model is live, we want to ensure that it is always working as we expect it to work. One way of validating the model is to feed it historical data and validate the results quantitatively and qualitatively.
最后,對應用程序進行回測試至關重要。 模型上線后,我們要確保它始終能夠按預期工作。 驗證模型的一種方法是提供其歷史數據并定量和定性地驗證結果。
The current project becomes the benchmark for the next phases. The next phases might involve changing data sets, models, or just fine tuning the hyper-parameters.
當前項目成為下一階段的基準。 下一階段可能涉及更改數據集,模型,或僅微調超參數。
It’s scarce to find one person who can work on all of the stages independently but these super-stars do exist in the industry and they are the expert data scientists. It takes many years of hard work to gain all of the required skills and yes it is possible with the right projects and enough time. It is absolutely fine to be more confident in one stage than the other but the key is to have a good enough understanding of each of the stage.
幾乎沒有人可以獨立完成所有階段的工作,但是這些超級明星確實存在于行業中,而且他們是專家數據科學家。 要獲得所有必需的技能,需要花費很多年的辛勤工作,是的,只有正確的項目和足夠的時間才有可能。 在一個階段比另一個階段更自信是完全可以的,但是關鍵是要對每個階段都有足夠的了解。
4.數據科學的常見陷阱 (4. Data Science Common Pitfalls)
Whilst working on data science projects, it’s important to remember common pitfalls.
在從事數據科學項目時,重要的是要記住常見的陷阱。
This section will provide an overview of the pitfalls.
本節將概述這些陷阱。

輸入數據錯誤 (Bad input data)
Ensure your input data is of good quality otherwise, you will end up spending a lot of time in producing a solution that won’t benefit the users.
確保您的輸入數據質量良好,否則,您最終將花費大量時間來制作對用戶無益的解決方案。
參數錯誤 (Bad parameters)
A model is essentially a set of functions. The parameters of the functions are often calibrated and decided based on intuition and knowledge. It’s important to ensure that the parameters are right and the data that is passed in the parameters is good.
模型本質上是一組功能。 通常根據直覺和知識來校準和確定功能的參數。 確保參數正確并且在參數中傳遞的數據正確是很重要的。
錯誤的假設 (Wrong assumptions)
It is important to get the assumptions about the data and the model along with its parameters verified. Wrong assumptions can end up wasting a lot of time and resources.
獲得有關數據和模型的假設以及經過驗證的參數非常重要。 錯誤的假設最終會浪費大量時間和資源。
型號選擇錯誤 (The wrong choice of models)
Sometimes we choose the wrong model and feed it the right data set to solve the right problem. Expectedly, the application produces invalid results. Some models are good to solve only particular problems. Therefore, do ensure that the chosen model is appropriate for the problem you are attempting to solve.
有時,我們選擇了錯誤的模型并提供了正確的數據集以解決正確的問題。 預期該應用程序將產生無效結果。 有些模型僅能解決特定問題。 因此,請確保選擇的模型適合您要解決的問題。
編程錯誤 (Programming errors)
Data science projects require a lot of coding at times. The errors can be introduced into the projects whilst implementing incorrect mappings, data structures, functions, and general coding bugs. The key is to build unit, integration, and smoke tests in your solution. I also recommend building a behavior-driven testing framework.
數據科學項目有時需要大量編碼。 可以在實施不正確的映射,數據結構,功能和常規編碼錯誤的同時將錯誤引入項目中。 關鍵是在解決方案中進行單元測試,集成測試和冒煙測試。 我還建議建立一個行為驅動的測試框架。
A software engineer/analyst/manager or anyone can all become an expert data scientist as long as they continously work on the data science stages
只要軟件工程師/分析師/經理或任何人持續從事數據科學階段的工作,他們都可以成為專家數據科學家
5.數據科學最佳實踐 (5. Data Science Best Practices)
Lastly, I wanted to outline the best practices of data science projects.
最后,我想概述數據科學項目的最佳實踐。
- Be aware of the pros and cons of the models. Not all models can solve all of the problems. If you have chosen smoothing techniques then ensure you understand the decay factors and whether the methodology is valid. Always choose a simple benchmark model and present the results to the end-users earlier on. Plus split the data into Train, Test, and Validation set. 注意模型的優缺點。 并非所有模型都能解決所有問題。 如果選擇了平滑技術,請確保您了解衰減因子以及該方法是否有效。 始終選擇一個簡單的基準模型,并盡早將結果提供給最終用戶。 另外,將數據分為訓練,測試和驗證集。
- Always build a benchmark model and show the results to the domain experts. Test the project on expected inputs to ensure the results are expected. This will clarify most of the issues with the assumptions and input data sets. 始終構建基準模型并將結果顯示給領域專家。 在預期輸入上測試項目,以確保預期結果。 這將闡明與假設和輸入數據集有關的大多數問題。
- Test the project on unexpected inputs to ensure the results are not unexpected. Stress-testing the projects is extremely important. 在意外的輸入上測試項目,以確保結果不會意外。 對項目進行壓力測試非常重要。
- Performance test the application. It is essential to ensure it can handle large data sets and requests. Build CI/CD plans at the start. 性能測試應用程序。 確保它可以處理大型數據集和請求至關重要。 首先要構建CI / CD計劃。
- Always backtest your model on historic data. It’s important to feed in the historic data to count the number of exceptions that are encountered. As history does not repeat itself, the key is to remember that backtesting can validate the assumptions which were set when the project was implemented. Hence, always backtest the model. 始終根據歷史數據對模型進行回測。 饋入歷史數據以計算遇到的異常數非常重要。 由于歷史不會重演,因此關鍵是要記住,回測可以驗證項目實施時設定的假設。 因此,請始終對模型進行回測。
- Document and evaluate the soundness of the proposed methodology and monitor the application. Ensure the business users of the domain are involved at earlier stages and throughout the various stages of the project. Constantly monitor the application to ensure that it’s responsive and working as expected. 記錄并評估所提議方法的合理性,并監視應用程序。 確保域的業務用戶參與項目的早期階段和整個階段。 不斷監視應用程序,以確保其響應和正常運行。
摘要 (Summary)

Data science is an extremely popular subject nowadays. This article outlined the skills we need to acquire to become a successful expert data scientist. It then provided an overview of the biggest problems we face in data science model-building projects along with the best practices.
數據科學是當今極為流行的學科。 本文概述了成為一名成功的專家數據科學家所需的技能。 然后概述了我們在數據科學模型構建項目中面臨的最大問題以及最佳實踐。
With time, we can start gathering more data such as running the code in parallel or building containers to launch the applications or simulating the data to forecast models. However, the key point here was to outline the must-know skills.
隨著時間的流逝,我們可以開始收集更多數據,例如并行運行代碼或構建容器以啟動應用程序或將數據模擬為預測模型。 但是,這里的重點是概述必須知道的技能。
Let me know what your thoughts are.
讓我知道你的想法。
翻譯自: https://towardsdatascience.com/understanding-statistics-and-probability-becoming-an-expert-data-scientist-b178e4175642
數據分析中的統計概率
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389468.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389468.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389468.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Keras框架:Mobilenet網絡代碼實現

clipboard 在 vue 中的使用

數據驅動開發_開發數據驅動的股票市場投資方法

前端之sublime text配置

python 時間序列預測_使用Python進行動手時間序列預測

keras框架:目標檢測Faster-RCNN思想及代碼
有偏見)
算法偏見是什么_算法可能會使任何人(包括您)有偏見

大數據筆記-0907

Tensorflow框架:目標檢測Yolo思想

線性回歸非線性回歸_了解線性回歸

樸素貝葉斯和貝葉斯估計_貝葉斯估計收入增長的方法

numpy統計分布顯示

python數據結構:進制轉化探索

Keras框架:人臉檢測-mtcnn思想及代碼

python中格式化字符串_Python中所有字符串格式化的指南

Javassist實現JDK動態代理

數據圖表可視化_數據可視化如何選擇正確的圖表第1部分

Keras框架:實例分割Mask R-CNN算法實現及實現

機器學習 缺陷檢測_球檢測-體育中的機器學習。
