火種 ctf
Originally published at https://www.linkedin.com on March 27, 2020 (data up to date as of March 20, 2020).
最初于 2020年3月27日 在 https://www.linkedin.com 上 發布 (數據截至2020年3月20日)。
Day 3 of social distancing.
社會疏離的第三天。
As I sit on my couch scrolling through my Instagram feed to see yet another drawing of an orange — apparently the latest Instagram challenge to pass the time — I was starting to get… bored. Who would’ve thought that an INTP like myself would succumb to boredom in day 3 of social distancing?
當我坐在沙發上滾動查看我的Instagram提要時,看到另一幅橙色的圖畫(顯然是Instagram最新挑戰),我開始感到…… 無聊 。 誰會想到像我這樣的INTP會在社交疏遠的第三天屈服于無聊?
With no cool restaurants to explore, no plans with friends to hang out, no gyms to go to anytime soon — why not start a project to pass the time?
沒有很酷的餐廳可供探索,沒有與朋友閑逛的計劃,沒有健身房可供短期使用-為什么不啟動一個打發時間的項目?
But, what project? I know I wanted to do something that would allow me to gain insight on some aspect of my life, and what’s more relevant to a 20 year old’s life than dating? In today’s ultra-digital world, dating has become synonymous with Tinder. I mean, how else are we supposed to meet and connect with people nowadays? Through physical and social communities like friends, mutuals, school, and work as has literally been the case for hundreds of generations prior? Nope, that’s crazy.
但是,什么項目? 我知道我想做些能讓我對生活的某些方面有深入了解的事情,與20歲的生活比約會更重要的是什么? 在當今的超數字世界中,約會已成為Tinder的代名詞。 我的意思是,我們今天應該如何與其他人見面并建立聯系? 通過像朋友,互助,學校和工作這樣的物質和社會社區,幾百代人以前確實是這樣? 不,那太瘋狂了 。
Tinder allows us to connect with people within our communities that we would never have met otherwise — for better or for worse. And as with many social media apps, Tinder allows you to request your own personal data.
Tinder使我們能夠與社區中的人們保持聯系,否則我們將再也見不到,無論好壞。 與許多社交媒體應用程序一樣,Tinder允許您請求自己的個人數據。
And so I did.
所以我做到了。
火種數據 (Tinder Data)
The requested Tinder data was in JSON format, and follows this simplified structure:
請求的Tinder數據為JSON格式,并遵循以下簡化結構:
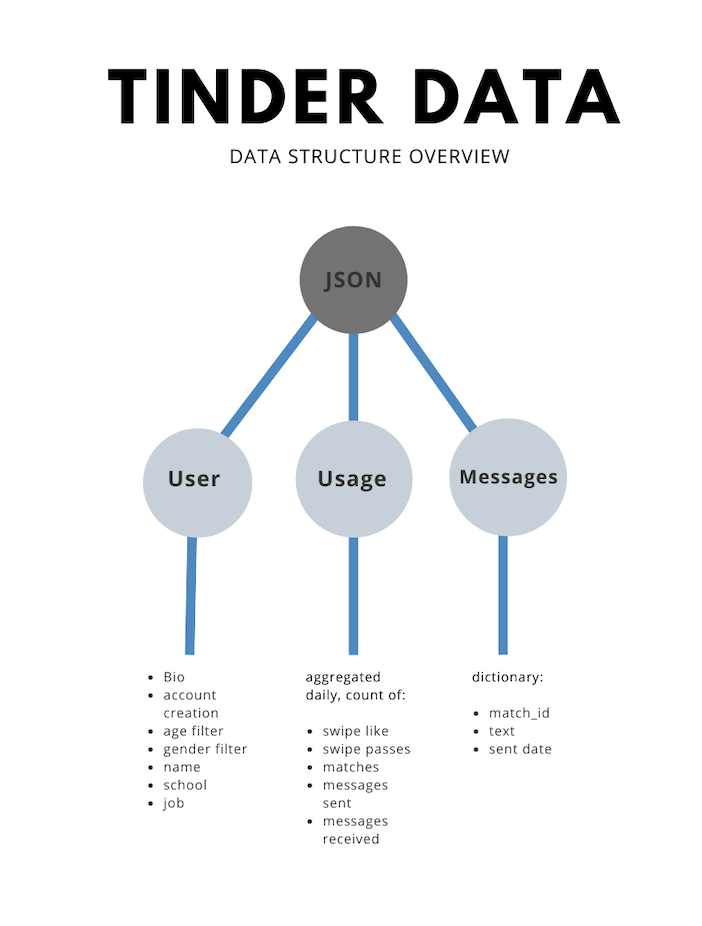
Reading in the data into Python with the following script:
使用以下腳本將數據讀入Python:
import json with open('data.json') as json_file:
data ?= json.load(json_file)Now, the first problem was taking this data structure and converting it to one that I could easily traverse through to analyze. Because Usage is simply a count aggregated daily, it was natural to convert this into a standard tabular data structure with rows as dates and columns as the aforementioned features.
現在,第一個問題是采用這種數據結構并將其轉換為我可以輕松遍歷以進行分析的結構。 由于“用法”只是每天匯總的計數,因此很自然地將其轉換為標準的表格數據結構,其中行作為日期,列作為上述功能。
import pandas as pd
df = pd.DataFrame(list(data['Usage']['app_opens'].keys())) for x in list(data['Usage'].keys()):
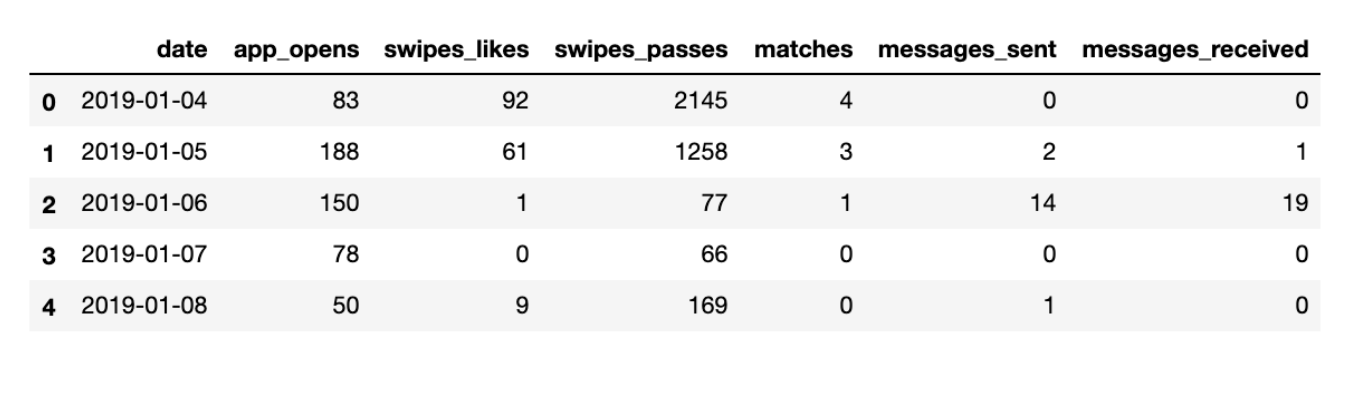
df[x]= list(data['Usage'][x].values())Here’s the first five rows of the data frame — aka my first 5 days on Tinder:
這是數據框的前五行,也就是我在Tinder上的前五天:
With the Messages, however, I wanted to explore other alternatives. Since an individual message can be viewed as an object with attributes text and sent date, I defined a Message Class/Object, and stored these in a dictionary where the key indicated the unique match ID.
但是,對于“消息”,我想探索其他替代方法。 由于可以將一條單獨的消息視為具有屬性文本和發送日期的對象,因此我定義了一個消息類別/對象,并將它們存儲在字典中,其中的鍵表示唯一的匹配ID。
class Message:
'''Fields: Text (Str)
Date (Datetime)'''
def __init__(self, text, date):
self.text = text
self.date = date
def __repr__(self):
message_rep = "{}: {}"
return message_rep.format(self.date, self.text)
message_dict={}
for x in data['Messages']:
match_id=x['match_id'].split()[-1]
sent = []
for messages in x['messages']:
sent_date = " ".join(messages['sent_date'].split()[0:-1])[:-3]
sent.append(Message(messages['message'].lower(),sent_date))
message_dict[match_id]=sentNow, we need more Python to parse through the messages to derive basic insights. Here’s an excerpt containing the basic idea:
現在,我們需要更多的Python來解析消息以得出基本見解。 以下是包含基本思想的摘錄:
day_count, time_count, emoji_count = {}, {}, {}
day_time, date_count, word_count = {}, {}, {}
for matches in message_dict:
messages = message_dict[matches]
for msg in messages:
date=msg.date.split(" ")
day=date[0][:-1]
time = date[-1][:2]+':00'
dt="-".join(date[1:4])
words=msg.text.split(" ")
check_lst = [[day, day_count], [time, time_count],
[day_time, day_time],[dt, date_count],
[words, word_count]]
i=0
while i < 4:
x=check_lst[i]
key=x[0]
dictionary = x[1]
if key not in dictionary.keys():
dictionary[key]=1
i=i+1
else:
dictionary[key]=dictionary[key]+1
i=i+1
for x in words:
t = str.maketrans(dict.fromkeys(string.punctuation))
x = x.translate(t)
stripped = list(x)
for char in stripped:
if char in emojis:
if char not in emoji_count.keys():
emoji_count[char]=1
else:
emoji_count[char]=emoji_count[char]+1分析與見解 (Analysis & Insights)
Quick stats as of March 20th 2020:
截至2020年3月20日的快速統計數據:
- 10,083 total app opens 共有10,083個應用打開
- Swiped right on 3,331 profiles, with a daily max of 92 on January 4 2019 在3,331個配置文件上向右滑動,2019年1月4日每天最多92個
- Swiped left on 38,132 profiles, with daily max of 2,145 profiles on January 4 2019 向左滑動38,132個配置文件,2019年1月4日每天最多2,145個配置文件
- 349 matches, with daily max of 12 matches on March 18 2020 349場比賽,2020年3月18日每天最多12場比賽
- 1,164 total messages sent 共發送1,164條消息
- 1,289 total messages received 共收到1,289條消息
- 125 unique conversations 125個獨特的對話
- 32 social media/number exchanges 32個社交媒體/號碼交換
- 16 meet ups 16個聚會
- countless dollars spent on bubble tea 花在泡沫茶上的錢不計其數
Traversing through my sent messages, we get the following word cluster:
遍歷我發送的消息,我們得到以下單詞簇:

Looking at my top words:
看我的熱門話:
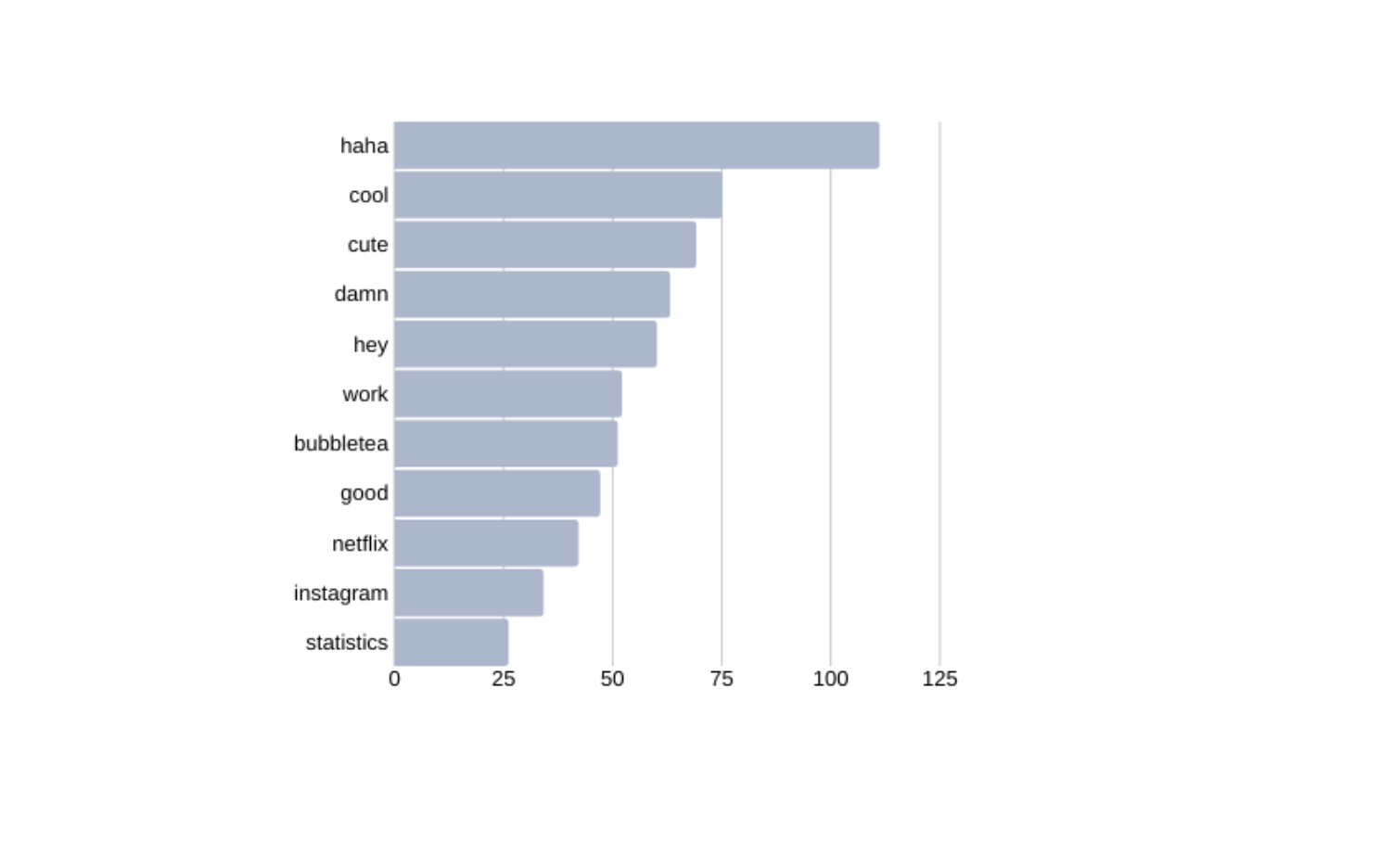
“damn you’re cute wanna grab bubbletea ? haha”
“該死的你很可愛,想去買泡泡茶嗎? 哈哈”
Interesting. Seems fairly normal in the context of Tinder. Now, I’m curious as to why statistics is one of my top words…
有趣。 在Tinder的上下文中似乎很正常。 現在,我很好奇為什么統計是我的熱門詞匯之一……
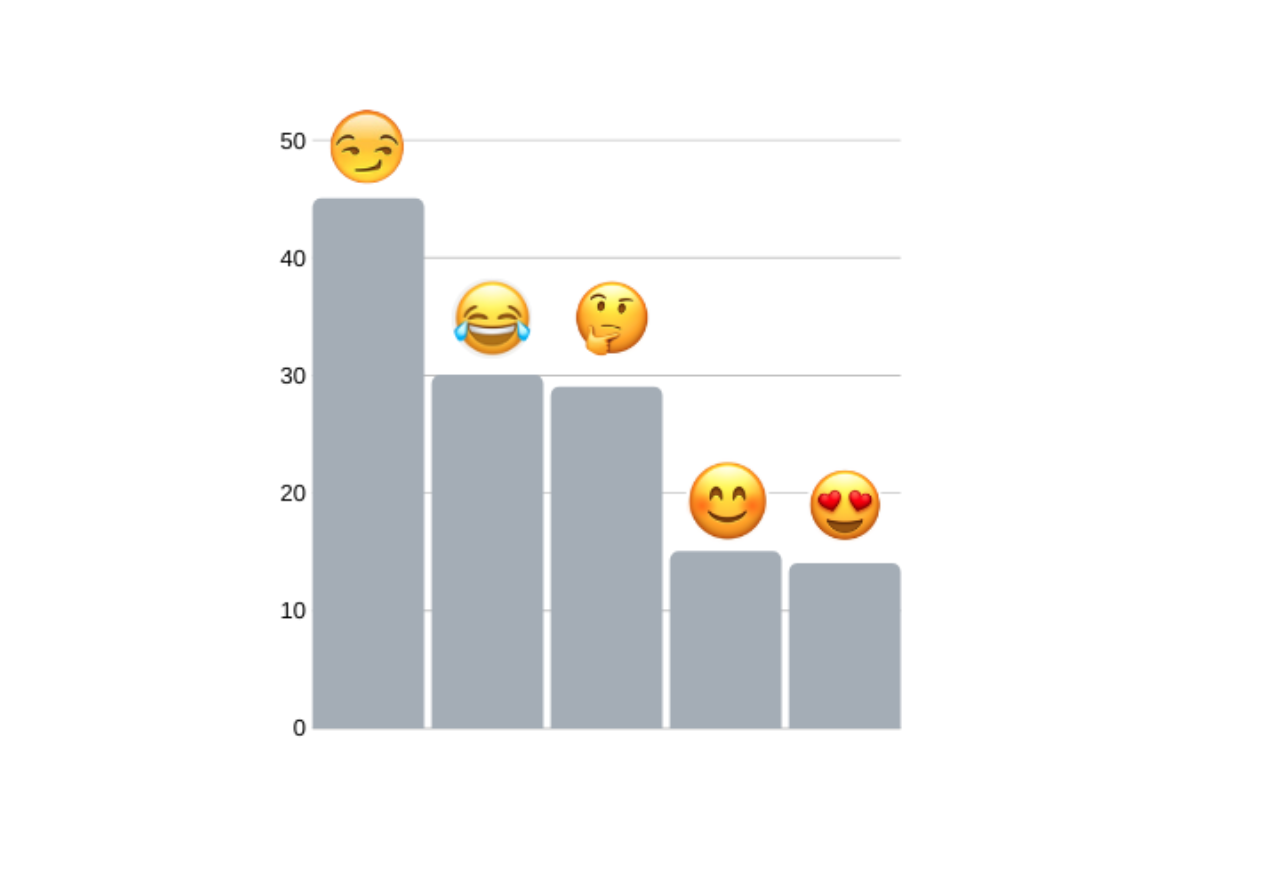
Now, among the messages sent, about 4% of these were emojis. Evidently, emojis are well integrated into digital messaging. Here are my top 5 sent emojis:
現在,在發送的消息中,其中約4%是表情符號。 顯然,表情符號已很好地集成到數字消息中。 這是我發送的前5個表情符號:
Moreover, data indicates that 15% of my sent messages had only 6 words — with 38% of my sent messages falling between the 5–7 word count range.
此外,數據表明,我發送的郵件中有15%僅包含6個單詞-我發送的郵件中有38%位于5-7個字數范圍內。
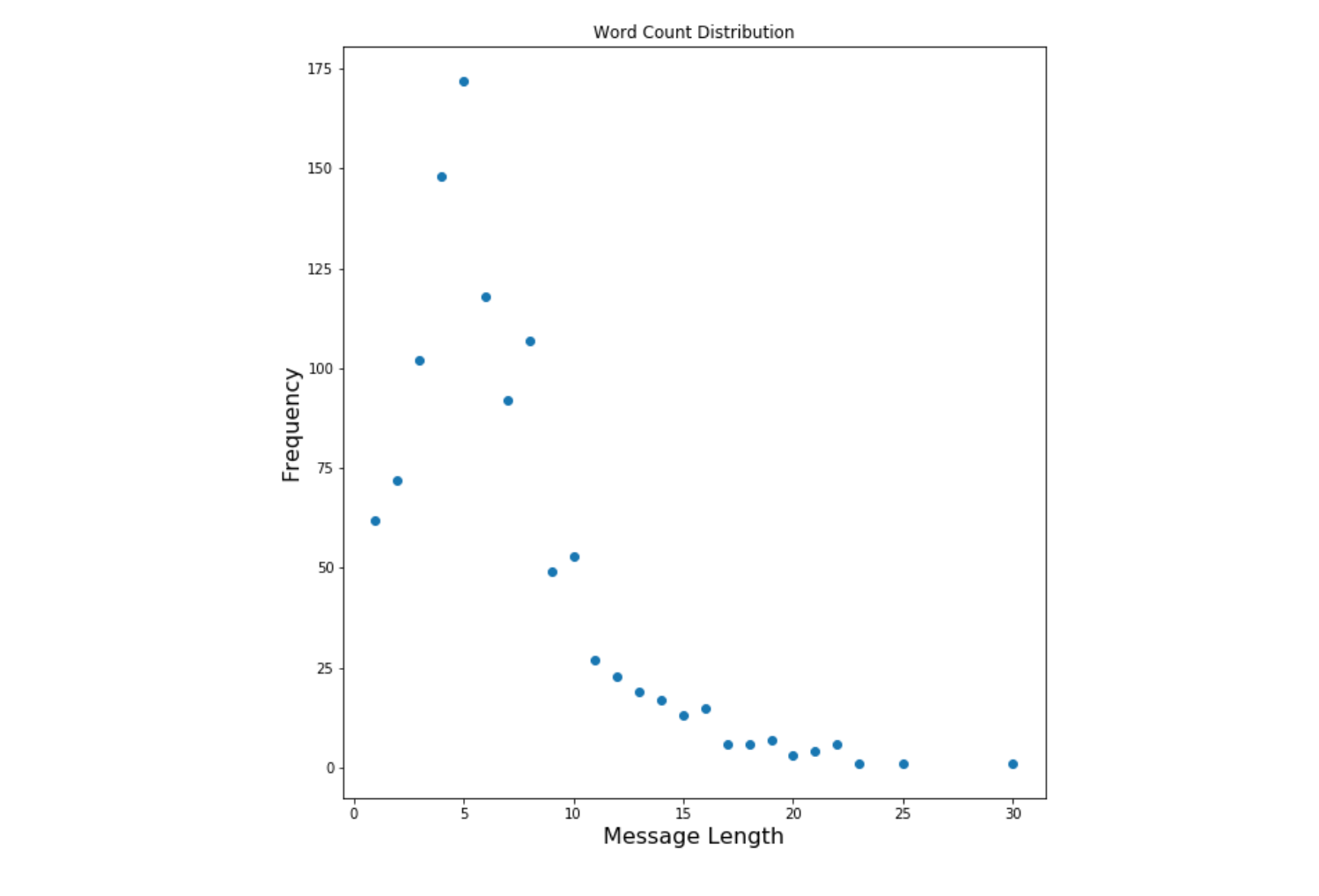
Looking at the distribution of conversation length measured in days, we see a left-skewed distribution — with 67% of conversations having tenure of less than one day.
查看以天為單位的會話長度分布,我們看到一個左偏分布-67%的會話的任期少于一天。

Among these single day conversations, a majority of them are dead-end: in other words, no messages were sent after my initial recorded message.
在這些單日對話中,大多數對話都是死胡同:換句話說,在我最初記錄的消息之后沒有發送任何消息。

Now, before hammering down on my one-liners, there is a slight caveat: because I only have data on my sent messages, I used my first and last message within a match as a proxy for conversation length. As such, it is unclear which participant actually ended the conversation. So these ‘no responses’ could have been messages that I didn’t follow up on.
現在,在敲定單行代碼之前,有一點警告:由于我的發送消息中只有數據,因此我將比賽中的第一條和最后一條消息用作對話長度的代理。 因此,不清楚哪個參與者實際結束了對話。 因此,這些“沒有回應”可能是我沒有跟進的消息。
In fact, looking at the count of messages sent versus received indicates that my messages are generally answered — at least when aggregating on the monthly level. So maybe my one liners are somewhat effective — sureeee.
實際上,查看已發送消息與已接收消息的數量表明,我的消息通常得到答復-至少在按月匯總時會得到答復。 因此,也許我的一支班輪比較有效- 保證人 。
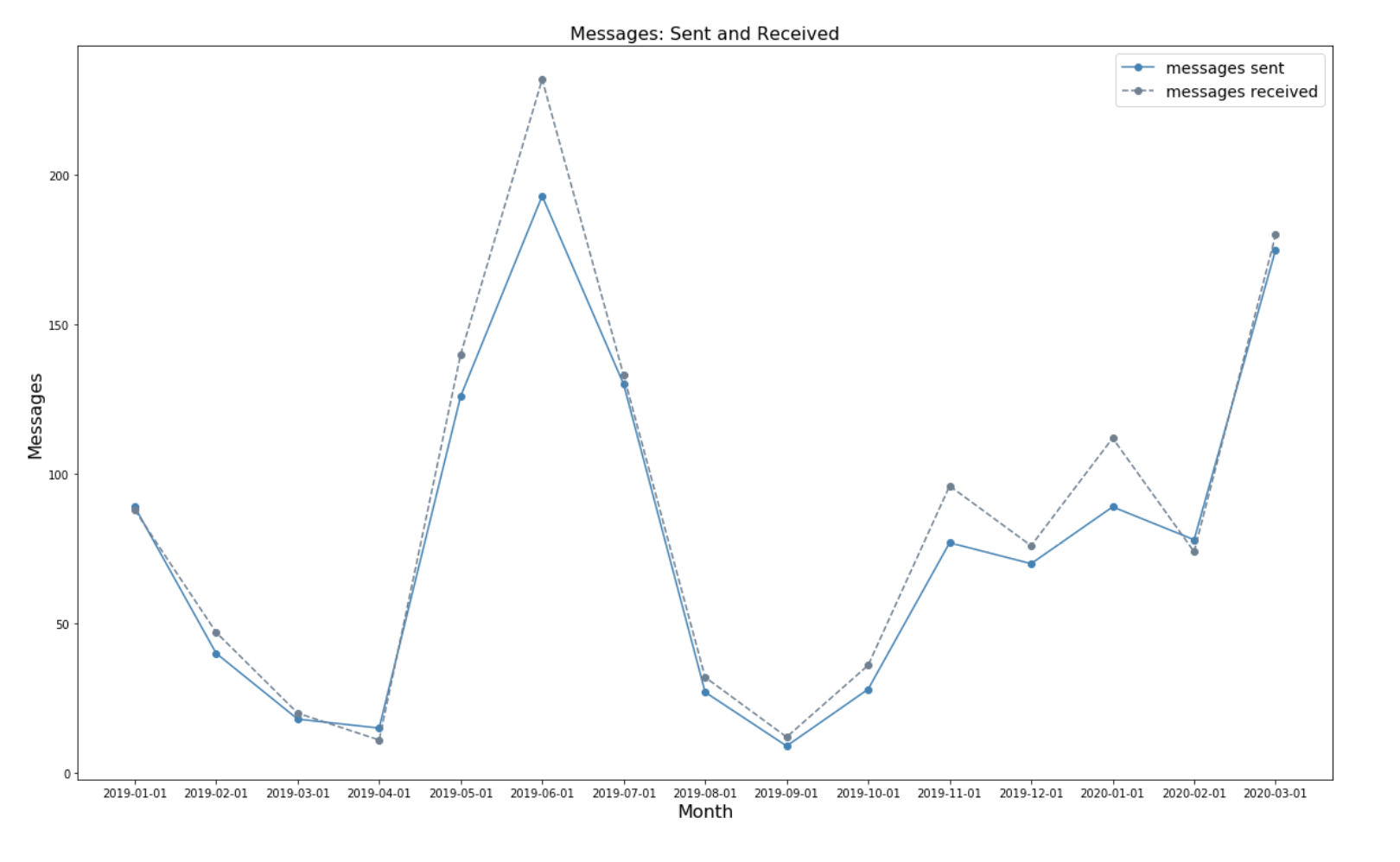
When are these messages actually sent out?
這些消息何時真正發出?
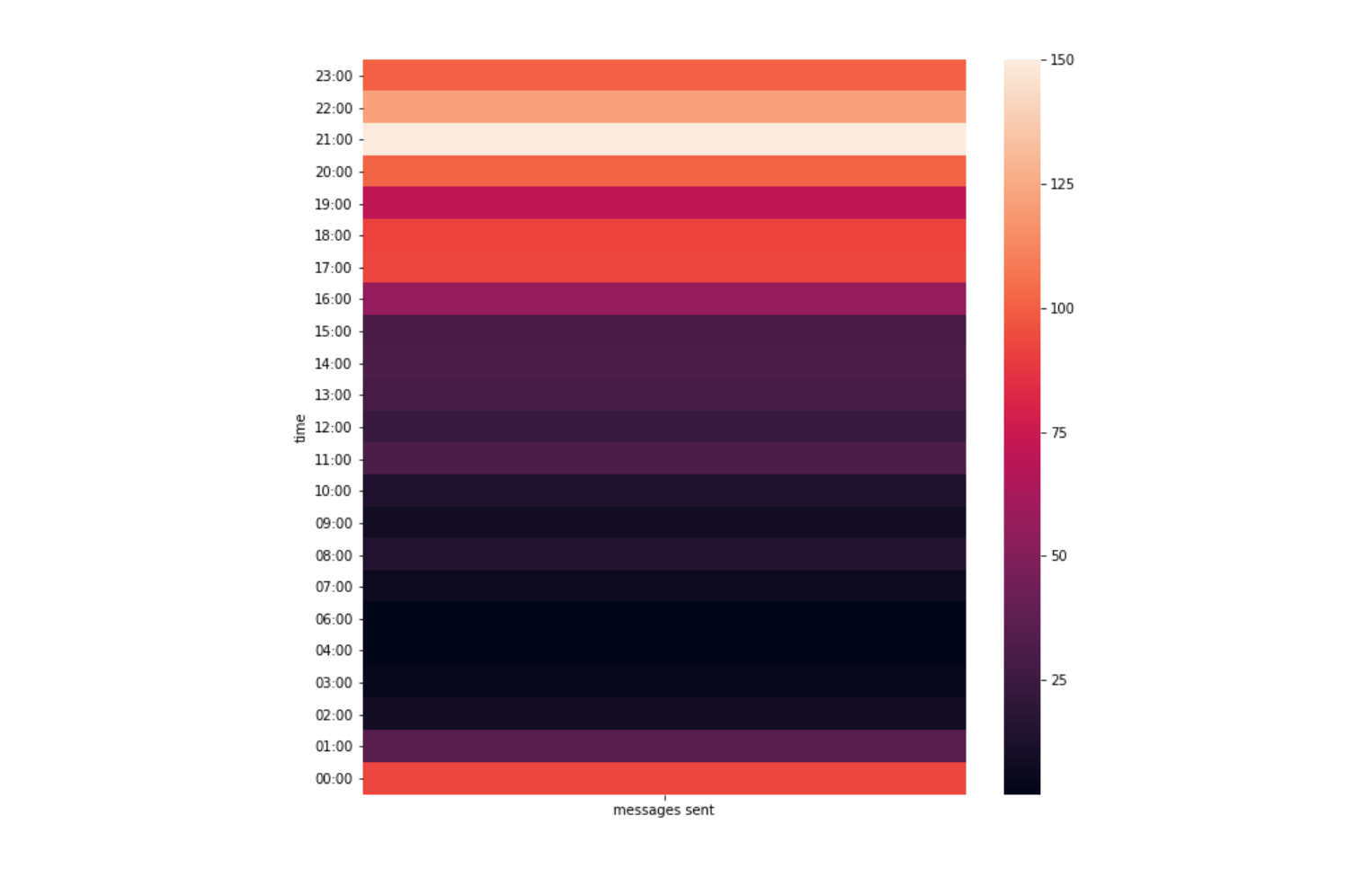
Data indicates that peak messaging time occurs at 9 pm.
數據表明高峰消息傳遞時間發生在晚上9點。
Cool — but these insights are only applicable once a match has actually occurred. We all know that 90% of Tinder consists of swiping.
很酷-但這些見解僅在實際發生匹配后才適用。 我們都知道90%的Tinder是刷卡。
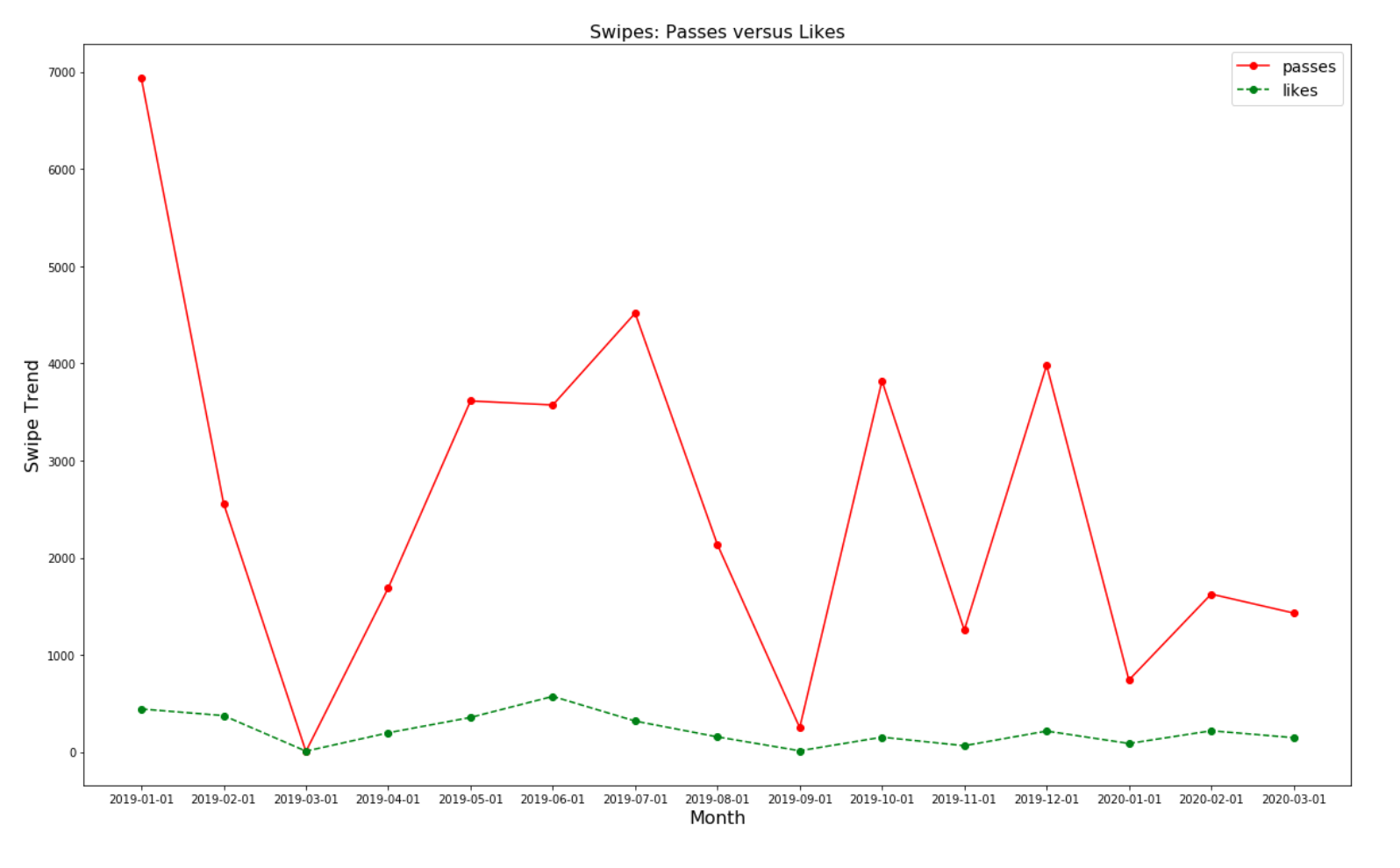
It’s interesting to see that 18% of total swipes were done in my first month of Tinder.
有趣的是,在Tinder的第一個月中,刷卡總數就達到了18%。
Defining match rate as the proportion of matches to swipe rights, we see that my match rate generally hovers at around 12.5% — with the highest match rate of 45% in March 2019 despite its low matches.
將匹配率定義為匹配權與滑動權的比例,我們看到我的匹配率通常徘徊在12.5%左右,盡管匹配率較低,但2019年3月的最高匹配率為45%。

Assuming independence in swipes and holding the probability of a match fixed, we can think of each swipe right as a Bernoulli trial — where a successful outcome is a match.
假設刷卡獨立,并且將比賽的可能性固定不變,那么我們可以將每次刷卡都視為一次伯努利試驗-成功的結果就是一場比賽。
Mathematically, we have a random variable, Y, that follows a binomial distribution:
在數學上,我們有一個隨機變量Y,它遵循二項式分布:
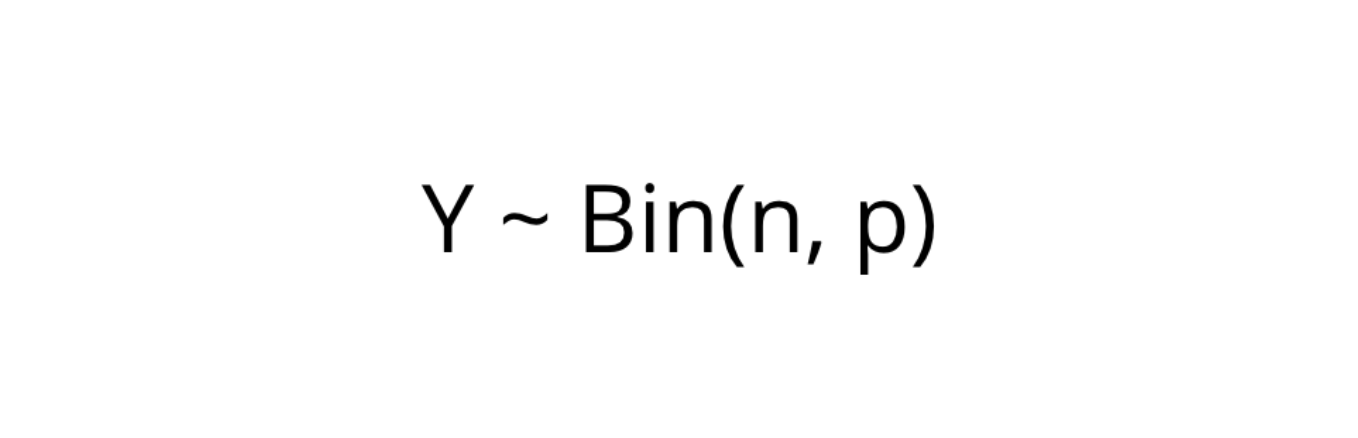
Or in our context:
或在我們的上下文中:

Given my Tinder data and assuming a fixed probability of success (p), the maximum likelihood estimate of the parameter p is simply the estimated match rate.
給定我的Tinder數據,并假設成功的概率為固定值(p),則參數p的最大似然估計值就是估計的匹配率。

Holding the number of my received swipe rights constant, we can construct the following cumulative binomial probability distributions:
在我收到的刷卡權利數量不變的情況下,我們可以構建以下累積二項式概率分布:

The figure above shows the probability of at least one match given a fixed probability of success, p. We can see that the probability of at least one match increases with the number of swipe rights. In other words, a match is inevitable as you swipe right — this is, of course, holding the number of received swipe rights constant. This resulting convergence is a consequence of the Law of Large Numbers.
上圖顯示了在給定固定成功概率p的情況下至少一場比賽的概率。 我們可以看到,至少一項匹配的可能性隨刷卡權限的數量而增加。 換句話說,當您向右滑動時,匹配是不可避免的-當然,這將使接收到的滑動權限的數量保持恒定。 最終的收斂是大數定律的結果。
Given my current swiping behaviour (p=0.10), it would take at least 30 swipes to get at least one match — emphasis on at least: meaning the number of matches could range from 1 to the number of swipe rights inclusive.
考慮到我目前的滑動行為(p = 0.10),至少需要進行30次滑動才能獲得至少一場比賽- 至少要強調:意味著比賽次數的范圍可以從1到包括滑動次數在內。

Holding the number of my received swipe rights constant, a quick way to increase the probability of at least one match is to increase the number of swipe rights given. However, more doesn’t necessarily mean better: the trade-off between quality and quantity is more nuanced, so I’ll leave it at that.
保持我收到的刷卡權利數量不變,一種增加至少一場比賽的可能性的快速方法是增加所給定的刷卡權利數量。 但是,更多并不一定意味著更好:質量和數量之間的權衡更加細微,因此我將保留它。
A natural question that follows is how many of these matches actually lead to coffee or bubble tea? Data indicates a 12.8% conversion rate among my engaged matches. A 95% confidence interval estimate indicates a lower bound of 7% and an upper bound of 19% — the 6% margin of error could be telling of external factors, such as proximity, that could affect one’s interest to meet up.
隨之而來的自然問題是,這些匹配中有多少實際上產生了咖啡或泡泡茶? 數據顯示我參與的比賽中的轉化率為12.8%。 95%的置信區間估計值指示下限為7%,上限為19%-6%的誤差幅度可能表示外界因素(例如接近程度)可能會影響一個人滿足興趣的外部因素。
Now, assuming independence among engaged matches and that each person is equally open to meet up, we can think of this as yet again another Bernoulli trial — where a successful outcome is a meet up.
現在,假設參與比賽的獨立性,并且每個人都同樣愿意聚會,我們可以將其視為伯努利的又一次審判-成功的結局就是聚會。

Given my Tinder data and assuming a fixed probability of success (p), the maximum likelihood estimate of the parameter p is simply the estimated conversion rate.
給定我的Tinder數據并假設成功的概率為固定值(p),則參數p的最大似然估計值就是估計的轉換率。
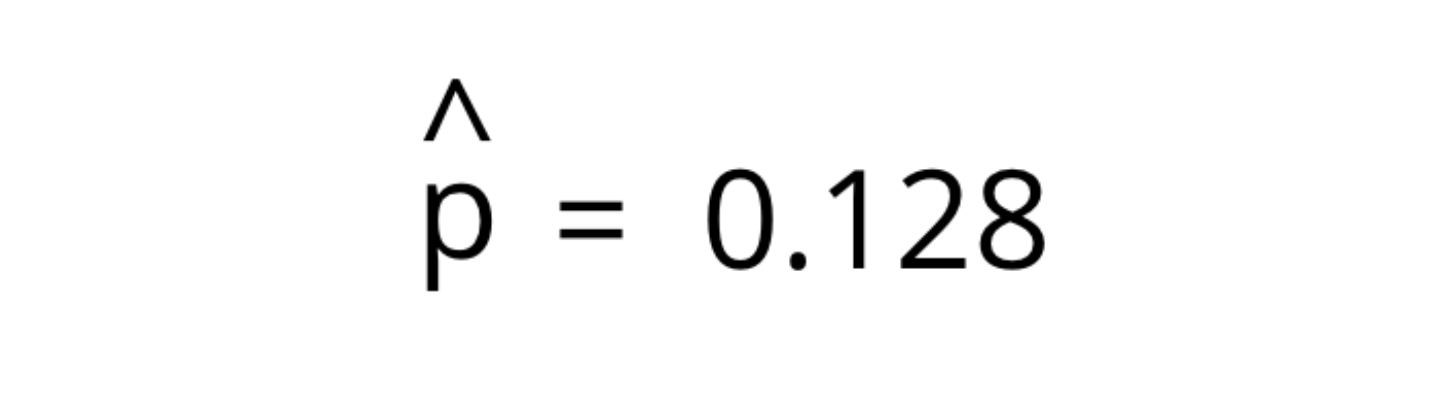
With these assumptions, we can make inferences on future outcomes such as calculating the probability of getting x number of meet ups — in other words, Prob(meet up = x | p = 0.128).
有了這些假設,我們就可以推斷出未來的結果,例如計算獲得x次見面的概率—換句話說,Prob(見面= x | p = 0.128)。
Pretty cool.
很酷
This is especially useful when it comes to allocating budgets for dates. Personally, first dates for me are around the $10 — $20 ball park — though, the variance on that is somewhat high. Assuming that I allocate $35 per month on dates and each date is $15, we can run simulations with 100 engaged matches over 6 months:
在分配日期預算時,這特別有用。 就我個人而言,第一次約會大約是10美元(20美元球場),但是,這方面的差異有些大。 假設我每月在日期上分配$ 35,每個日期為$ 15,我們可以在6個月內進行100次參與式比賽的模擬:

Since the number of engaged matches is large (n=100), the binomial distribution can be approximated by a Gaussian probability density. This resulting convergence in distribution is a consequence of the Central Limit Theorem.
由于參與比賽的數量很大(n = 100),因此可以通過高斯概率密度來近似二項式分布。 分布的最終收斂是中央極限定理的結果。
The probability of a deficit can be calculated as the area under the curve to the left of the red dotted line. Hence we can calculate this probability easily using the Gaussian approximation:
赤字的概率可以計算為紅色虛線左側曲線下方的面積。 因此,我們可以使用高斯近似輕松地計算該概率:

Since the budget remaining is a linear function of meet ups — which we estimate through a Gaussian random variable — then, the budget remaining also follows a Gaussian distribution:
由于剩余預算是滿足率的線性函數(我們通過高斯隨機變量估算),因此,剩余預算也遵循高斯分布:

With these assumptions, the probability of a deficit is 0.3594. Yikes — this is somewhat concerning given that I’m on a student budget.
根據這些假設,出現赤字的概率為0.3594。 Yikes-考慮到我的學生預算有限,這有點令人擔憂。
So, it’s probably not financially viable to message 100 matches over 6 months given my current conversion rate. To stay on budget, I either: decrease the number of messaged matches or decrease my conversion rate. Hmm, tough call — I’d have to go with the former.
因此,考慮到我目前的轉化率,在6個月內發送100個匹配消息可能在財務上不可行。 為了節省預算,我要么:減少信息匹配的次數,要么降低轉化率。 嗯,艱難的舉動-我不得不跟前一個去。
Tweaking the parameters in the binomial simulation we get the following results:
在二項式仿真中調整參數可獲得以下結果:
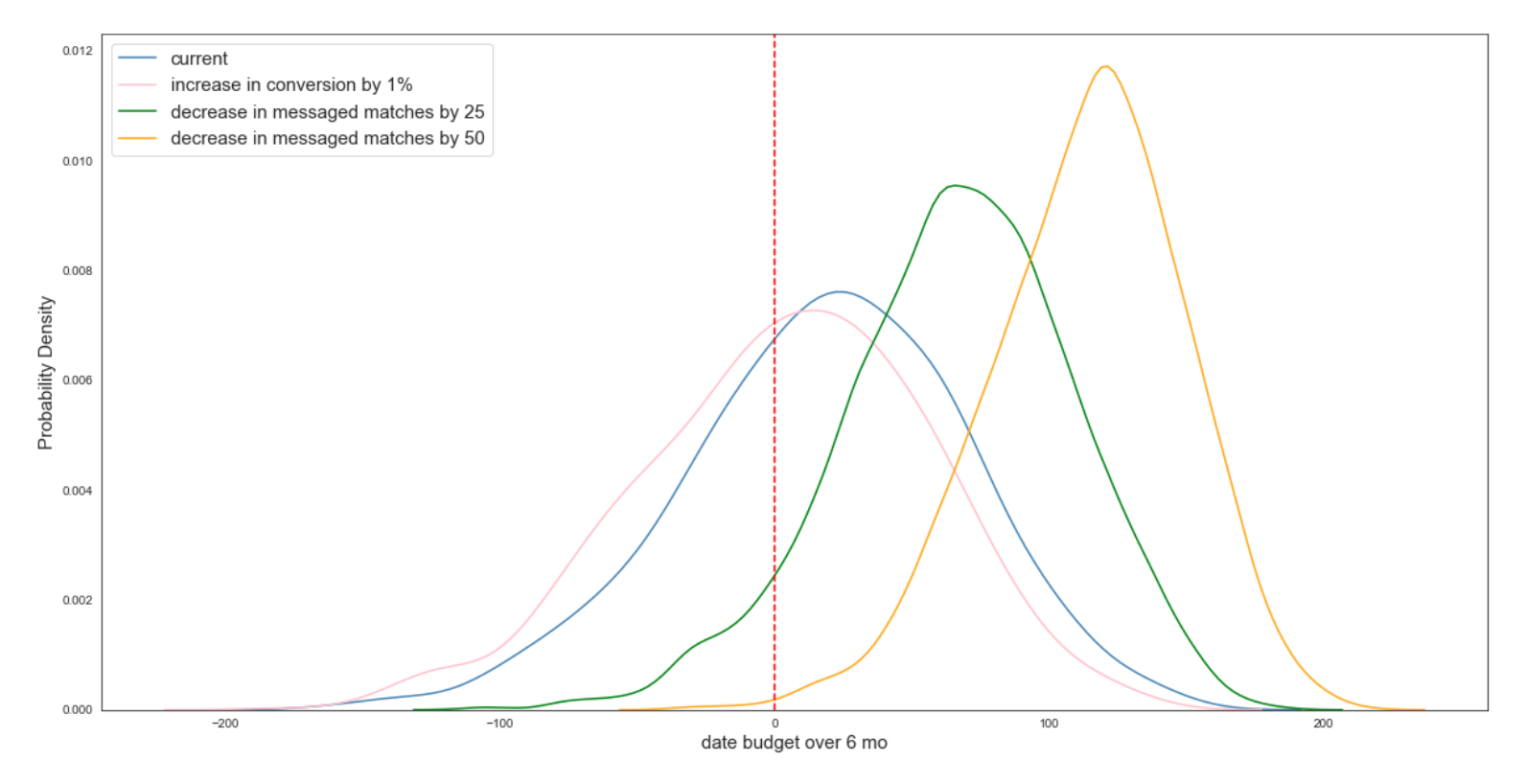
Now, the probability of going over budget when I reduce my engagement to 75 matches is 0.06 (green density) — much better. Having said that, I also don’t want to end up with a big surplus since that would imply little to no dates (yellow). Hence, I should engage with 75 to 85 matches over the course of 6 months to fully utilize my budget.
現在,當我將參與度降低到75場比賽時,超出預算的可能性為0.06(綠色密度),好得多。 話雖如此,我也不想結余很多,因為那意味著很少甚至沒有約會(黃色)。 因此,我應該在6個月的時間內進行75到85場比賽,以充分利用我的預算。
Cool. Now I have some new insights about my current Tinder behaviour — however, by no means is this analysis exhaustive. If you happen to have Python installed and have your own personal Tinder data — or if you just want to look at the back-end logic of the Python functions used in this analysis — feel free to check out the code that I wrote for this project:
涼。 現在,我對當前的Tinder行為有了一些新見解-但是,該分析絕不是詳盡無遺的。 如果您恰好安裝了Python并擁有自己的個人Tinder數據-或僅想查看此分析中使用的Python函數的后端邏輯-請隨時查看我為該項目編寫的代碼:
https://github.com/dionbanno/dion_creates
https://github.com/dionbanno/dion_creates
對進一步項目的建議: (Recommendations for further projects:)
- Can we perform A/B testing on certain key words and phrases to see if they increase the probability of a response/meet up? 我們可以對某些關鍵詞和短語進行A / B測試,以查看它們是否增加了回應/見面的可能性?
- It would be cool to have a repository of individual Tinder data classified per user attribute such as location, gender, age, etc. and doing a regression analysis to see if certain user attributes affect success 擁有按用戶屬性(例如位置,性別,年齡等)分類的單個Tinder數據存儲庫,并進行回歸分析以查看某些用戶屬性是否影響成功,這將很酷。
最后的話 (Final words)
Data from this analysis indicates that 64% of matches go un-messaged. So shoot your shot. Go ignite those matches — who knows? It might be worth while.
來自該分析的數據表明,有64%的匹配未發送消息。 因此,射擊。 點燃那些比賽-誰知道? 也許值得。
Feel free to leave your comments, and connect with me on LinkedIn. I’d also be curious to know — what metrics would you have chosen to analyze, and how?
隨時發表您的評論,并在LinkedIn上與我聯系。 我也很想知道-您將選擇分析哪些指標,以及如何選擇?
翻譯自: https://medium.com/swlh/analyzing-my-tinder-data-3b4f05a4a34f
火種 ctf
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389404.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389404.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389404.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

莫煩Matplotlib可視化第五章動畫代碼學習

data studio_面向營銷人員的Data Studio —報表指南

人流量統計系統介紹_統計介紹

pyhive 連接 Hive 時錯誤

樂高ev3 讀取外部數據_數據就是新樂高


分析citibike數據eda

jvm感知docker容器參數

Flask之flask-script 指定端口
和下采樣(縮小圖像)(最鄰近插值和雙線性插值的理解和實現))
上采樣(放大圖像)和下采樣(縮小圖像)(最鄰近插值和雙線性插值的理解和實現)

r語言繪制雷達圖_用r繪制雷達蜘蛛圖

java 分裂數字_分裂的補充:超越數字,打印物理可視化

Java 集合 之 Vector

前端電子書單大分享~~~
)
結構化數據建模——titanic數據集的模型建立和訓練(Pytorch版)

比賽,幸福度_幸福與生活滿意度

帶有postgres和jupyter筆記本的Titanic數據集

Django學習--數據庫同步操作技巧

《20天吃透Pytorch》Pytorch自動微分機制學習
