PostgreSQL is a powerful, open source object-relational database system with over 30 years of active development that has earned it a strong reputation for reliability, feature robustness, and performance.
PostgreSQL是一個功能強大的開源對象關系數據庫系統,經過30多年的積極開發,在可靠性,功能強大和性能方面贏得了極高的聲譽。
Why use Postgres?
為什么要使用Postgres?
Postgres has a lot of capability. Built using an object-relational model, it supports complex structures and a breadth of built-in and user-defined data types. It provides extensive data capacity and is trusted for its data integrity.
Postgres具有很多功能。 它使用對象關系模型構建,支持復雜的結構以及內置和用戶定義的數據類型的范圍。 它提供了廣泛的數據容量,并因其數據完整性而受到信賴。
It comes with many features aimed to help developers build applications, administrators to protect data integrity and build fault-tolerant environments, and help you manage your data no matter how big or small the dataset.
它具有許多功能,旨在幫助開發人員構建應用程序,幫助管理員保護數據完整性和構建容錯環境,并幫助您管理數據(無論數據集大小)。
We will be using the famous Titanic dataset from Kaggle to predict whether the people aboard were likely to survive the sinkage of the world’s greatest ship or not.
我們將使用來自Kaggle的著名的《泰坦尼克號》數據集來預測船上的人們是否有可能幸免于世界上最偉大的船只的沉沒。
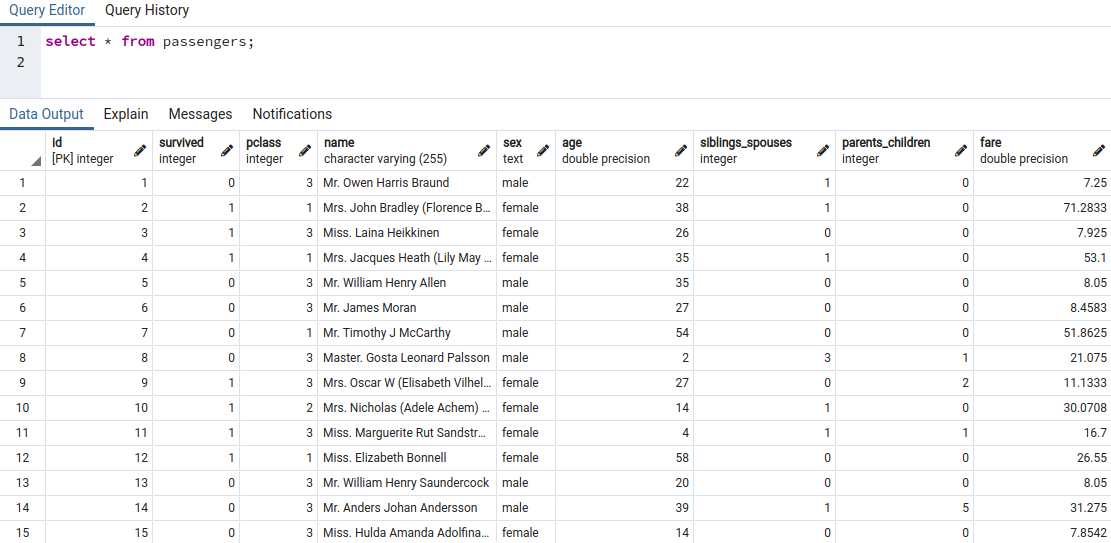
In the first step make sure the you have valid Postgres credentials, a created database with the data already imported. Check the Kaggle website to downloads the csv files: https://www.kaggle.com/c/titanic/data. The data should look something like this:
第一步,請確保您具有有效的Postgres憑據,即已導入數據的已創建數據庫。 檢查Kaggle網站以下載csv文件: https : //www.kaggle.com/c/titanic/data 。 數據應如下所示:
We’ll first import the proper libraries. Make sure you pip install them. I’m using a local jupyter environment. Apart from the obvious ones, psycopg2 and sqlalchemy are crucial for creating a connection to postgres. Just pip install them as well. :)
我們將首先導入適當的庫。 確保您點安裝它們。 我正在使用本地jupyter環境。 除了顯而易見的以外,psycopg2和sqlalchemy對于創建與postgres的連接至關重要。 只需點安裝它們。 :)
Next, we’ll be using a create_engine form sqlalchemy. It’s too simple to use.
接下來,我們將使用sqlalchemy形式的create_engine。 使用起來太簡單了。

Replace <enter yours> with your own credentials. The default port is 5432 and username is ‘postgres’. If the code prints ‘Connected to database’ you have succesfully made a connection to your postgres database.
用您自己的憑據替換<enter yours>。 默認端口為5432,用戶名為“ postgres”。 如果代碼顯示“已連接到數據庫”,則說明您已成功連接到Postgres數據庫。
Next, let’s convert the query result set to a pandas dataframe.
接下來,讓我們將查詢結果集轉換為pandas數據框。


As you can see the dataframe has 887 rows and 9 columns with the first being id.
如您所見,數據框具有887行和9列,第一個是id。
In the next section, let’s try to figure out if any data is directly associated with the survival rate. We’ll take if sex, passenger class and having a family has anything to do with their chance of surviving.
在下一節中,讓我們嘗試確定是否有任何數據與生存率直接相關。 我們將考慮性別,旅客階層和家庭是否與他們生存的機會有關。

As you can see, 74% of women aboard survived and only 19% of men did. Passenger class also has an enormous affect. Having siblings or spouses is not correlated. Let’s take a look at a visual correlation between age and survival.
如您所見,船上74%的女性得以幸存,只有19%的男性得以幸存。 客運等級也有巨大影響。 有兄弟姐妹或配偶不相關。 讓我們看一下年齡和生存率之間的視覺關聯。

There is a significant ammount of toddlers that died in the accident. Most of passengers were middle-aged.
事故中有大量嬰兒喪生。 大多數乘客是中年人。
Since computers like numbers more than words I have converted sex into a binary classifier.
由于計算機比數字更喜歡數字,因此我已將性別轉換為二進制分類器。

The data still remains the same.
數據仍然保持不變。
Finally, let’s dive into preprocessing for classification.
最后,讓我們深入進行分類預處理。

I used sklearn’s train_test_split to create a training and test dataset.
我使用sklearn的train_test_split創建了訓練和測試數據集。
We have to drop the ‘survived’ column in the train set otherwise the data serves no purpose.
我們必須在訓練集中刪除“幸存”列,否則數據沒有任何作用。
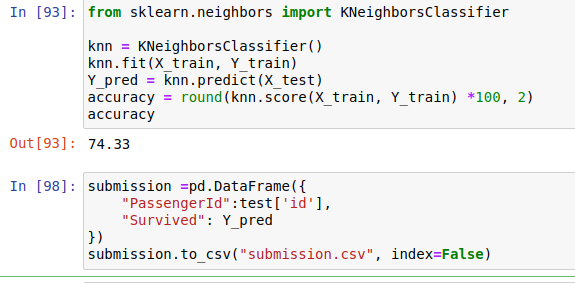
Finally, we fit the training data and got the accuracy of 74.33 which is not great. But not bad either. Let’s save the predicted values to a csv file called ‘submission.csv’. It will only have two values: passengerId and a boolean indicating survival.
最后,我們擬合了訓練數據并獲得了74.33的準確度,這并不是一個很好的結果。 但也不錯。 讓我們將預測值保存到一個名為“ submission.csv”的csv文件中。 它只有兩個值:passengerId和一個表示生存期的布爾值。
Summary:
摘要:
- use postgres as transactional database management system for data pipelines 使用postgres作為數據管道的事務數據庫管理系統
- have fun manipulating data with pandas and visualisation libraries such as matplotlib and seaborn. 使用熊貓和可視化庫(例如matplotlib和seaborn)來處理數據很有趣。
- make predictions using the machine learning algorithms provided to you by scikit-learn and tensorflow. 使用scikit-learn和tensorflow提供給您的機器學習算法進行預測。
Thanks ;)
謝謝 ;)
翻譯自: https://medium.com/@cvetko.tim/titanic-dataset-with-postgres-and-jupyter-notebook-69073c4a67e6
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389387.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389387.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389387.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Django學習--數據庫同步操作技巧

《20天吃透Pytorch》Pytorch自動微分機制學習

React 新 Context API 在前端狀態管理的實踐

機器學習模型 非線性模型_機器學習模型說明

5分鐘內完成胸部CT掃描機器學習

Pytorch高階API示范——線性回歸模型

vue 上傳圖片限制大小和格式

作業要求 20181023-3 每周例行報告

算命數據_未來的數據科學家或算命精神向導

openai-gpt_為什么到處都看到GPT-3?

Pytorch高階API示范——DNN二分類模型


puppet puppet模塊、file模塊

數據可視化及其重要性:Python

熊貓數據集_熊貓邁向數據科學的第三部分

Pytorch有關張量的各種操作
)
mongodb安裝失敗與解決方法(附安裝教程)
![【洛谷算法題】P1046-[NOIP2005 普及組] 陶陶摘蘋果【入門2分支結構】Java題解](http://pic.xiahunao.cn/【洛谷算法題】P1046-[NOIP2005 普及組] 陶陶摘蘋果【入門2分支結構】Java題解)
【洛谷算法題】P1046-[NOIP2005 普及組] 陶陶摘蘋果【入門2分支結構】Java題解
)
web性能優化(理論)
