Redis的性能管理;
redis的數據保存在內存中
redis-cli info memory
redis內存使用info memory命令參數解析
used_memory:236026888? ? ?由 Redis 分配器分配的內存總量,包含了redis進程內部的開銷和數據占用的內存,以字節(byte)為單位
used_memory_rss:274280448? ? ?redis向操作系統申請的內存大小
used_memory_peak:458320936? ?redis的內存消耗峰值(以字節為單位)
內存碎片率:
used_memory_rss/used_memory系統已經分配給了redis,但是redis未能夠有效利用的內存
如何查看內存碎片率:
redis-cli info memory | grep ratio

allocator frag ratio:1.19
分配碎片的比例,redis 主進程調度時產生的內存,比例越小,值越高,內存的浪費越多
allocator rss ratio:7.15
分配器占用物理內存的比例,告訴你主進程調度執行時占用了多少物理內存
rss overhead ratio:0.31
rss是向系統申請的內存空間,Redis占用物理空間額外的開銷比例,比例越低好,redis實際占用的物理內存和向系統申請的內存月接近,額外的開銷越低
mem_fragmentation ratio:3.33
內存碎片的比例,越低越好,內存的使用率越高
如何自動清理碎片:
vim /etc/redis/6379.conf
.....
activedefrag yes?
#最后一行添加


如何手動清理碎片:
redis-cli memory purge

設置redis的內存最大閾值:
一但到達閾值,會自動清理碎片,開啟key的回收機制
vim /etc/redis/6379.conf
........
#568行添加
maxmemory 1gb
![]()

key的回收策略
vim /etc/redis/6379.conf
.......
#598行添加如下(一般保留最后一個策略,根據需求添加):
maxmemory-policy volatile-lru:使用redis內資的lru算法,把已經設置了過期時間的鍵值對對中淘汰數據,移除最少使用的鍵值對。對已經設置了過期時間的鍵值對
maxmemory-policy?volatile-ttl:已經設置了時間的鍵值對,從當中挑選一個即將過期的鍵值對,針對有設置過期時間的鍵值對
maxmemory-policy-volatile-random:從已經設置了過期時間的鍵值對當中,挑選數據隨機淘汰鍵值對。對設置時間的鍵值對進行隨機移除
mllkey-lru:lru算法當中,對所有的鍵值對進行淘汰,移除最少使用的鍵值對,針對所有的鍵值對
allkeys-random:從所有鍵值對中任意選擇鍵值對進行淘汰
maxmemory-policy noeciction:禁止鍵值對回收,(不刪除任何鍵值對,直到Redis內存塞滿了)

在工作中一定要 給redis占用內存設置閾值
面試:
redis占用 內存的效率問題如何解決
1 日常巡檢中。對redis 占用內存情況做監控
2? 設置redis占用系統內存的閾值,避免占用系統全部內存
3? 內存碎片清理,手動.自動清理
4? 配置合適的Key的回收機制
Redis的報錯問題:
1 雪崩:
緩存雪崩,大量的應用請求無法在redis緩沖中處理,會把所有的請求發送到后臺數據庫,數據庫的壓力會大,數據庫本身并發能力差,一旦高并發,數據庫會崩潰
redis集群大面積故障,Redis緩存中,大量數據同時過期,大量的請求無法得到處理。Redis實例宕機
1.1解決方案:
事前:高可用架構,防止整個緩存故障, ,主從復制,和哨兵模式,Redis集群。
事中:在國內用的比較多的方式,hystrix,熔斷,限流三個手段來降低雪崩發生之后的損失,數據庫不死即可,慢可以,但是不能沒有響應
事后,Redis備份。快速緩存預熱
2? redis的緩存擊穿(重要)
主要是熱點數據緩存過期,或者刪除,多個請求并發訪問熱點數據,請求轉發到數據庫,導致數據庫的性能下降,經常請求的緩存數據,最好設置為永不過期
3 Redis的緩存穿透
緩存中沒有數據,數據庫也沒有對應的數據,但是有用戶一直發起這個請求,而且請求的數據是很大,一般是被黑客利用
Redis的主從復制
主從復制的作用:
是redis實現高可用的基礎,哨兵模式和集群都是在主從復制的基礎之上實現高可用,主從復制實現數據的多機備份,以及讀寫分離(主服務器負責寫,從服務器只讀)
缺陷:故障無法自動恢復,需要人工干預,寫操作的負載均衡
主從復制的工作原理:
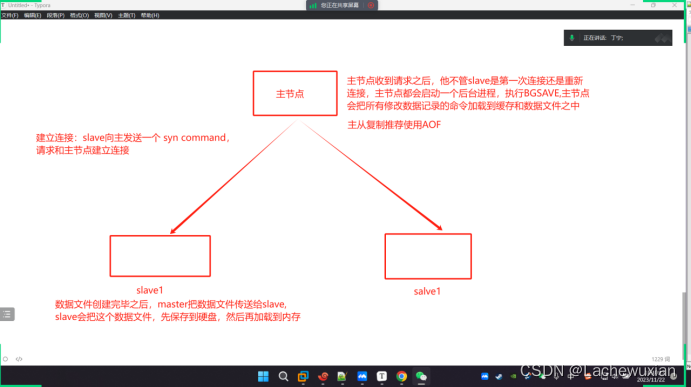
主節點從節點組成,數據復制是單向,只能從主節點到從節點
1 主節點:主節點收到請求之后,他不管slave是第一次連接還是重新連接,主節點都會啟動一個后臺進程,執行bgsave主節點會把所有修改數據記錄的命令加載到緩存和數據文件之中,
主從復制推薦使用AOF
建立連接:slave向主發送一個syn command,請求和主節點建立連接
數據文件創建完畢之后,master把數據文件傳送到salve,slave 會把這個數據文件,先保存到硬盤,然后在加載到內存
實驗架構:
192.168.233.7 主
192.168.233.8 從
192.168.233.9 從
依賴環境 Redis 先準備好
主:




![]()
從1 和從2


![]()
![]()


查看日志是否建好

驗證是否主從
同時登錄redis ,主寫入? 從節點無法寫


哨兵模式
先有主從,再有哨兵,再主從復制的基礎之上,實現主節點故障的自動切換,
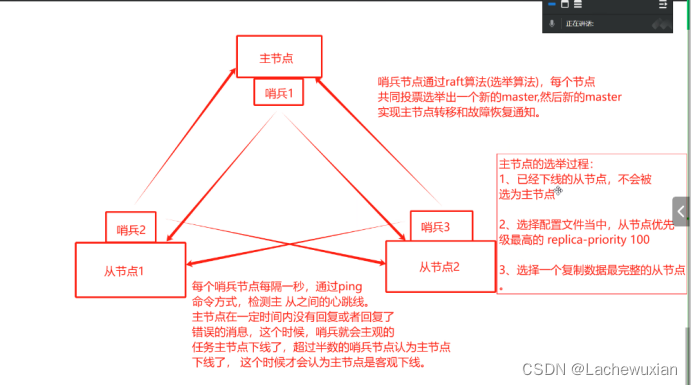
哨兵模式的原理:
哨兵是一個分布式系統,用于在主從結構之間,對每臺redis的服務器進行監控,主節點出現故障時,從節點通過投票的方式選擇一個新的master 哨兵模式也需要至少三個節點,
哨兵模式的結構:
哨兵節點:監控節點,不存儲數據
數據節點:主從節點,都是數據節點
主節點的選舉過程:
1 已經下線的從節點,不會被選為主節點
2? 選擇配置文件當中,從節點優先級最高的replica-priority 100
3? 選擇一個復制數據最完整的從節點
哨兵節點通過raft算法(選舉算法),每個節點共同投票選舉出一個新的master,然后新的master實現主節點轉移和故障恢復通知
每個哨兵節點每隔一秒,通過ping命令方式,檢測主從之間的心跳線,主節點在一定時間內沒有回復或者恢復了錯誤的信息,這個時候哨兵就會主觀的判斷主節點下線了,超過半數的節點哨兵認為主節點下線了,這個時候才會認為主節點是客觀下線
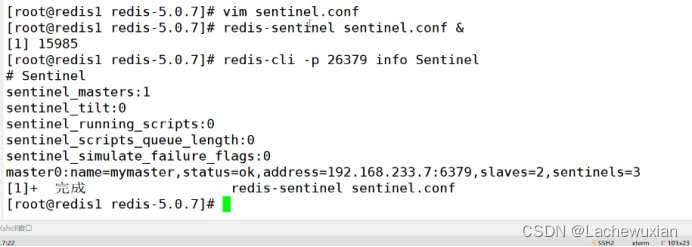
主:






sentinel monitor mymaster 192.168.233.7 6379 2?
#指向表示至少需要2臺服務器認為主已經下線,才會進行主從切換。

從1和從2:





啟動配置文件 先啟動再啟動從,挨個執行一遍

查看狀態信息
日志查看從節點的信息
Redis 集群:
Redis3.0引入的分布式存儲方案
工作模式:
集群有多個node節點組成,Redis數據分布在這些節點上,在集群之中,分為主節點和從節點
集群模式中 主從一一對應,數據寫的讀取和主從模式一樣,主負責寫,從模式只能寫,集群模式自帶哨兵模式,可以自動實現故障切換,但是故障切換中,整個集群不能使用,切換完畢之后集群會立刻恢復
集群模式是按照數據分片劃分:
1 數據分片:是集群的核心功能,每個主都要提供讀寫的功能,但是數據一一對應寫入對應的從節點,在集群模式中,可以容忍數據的不完整
2 高可用 :集群的主要目的
數據分片的實現過程:
redis集群引入了 哈希槽的概念
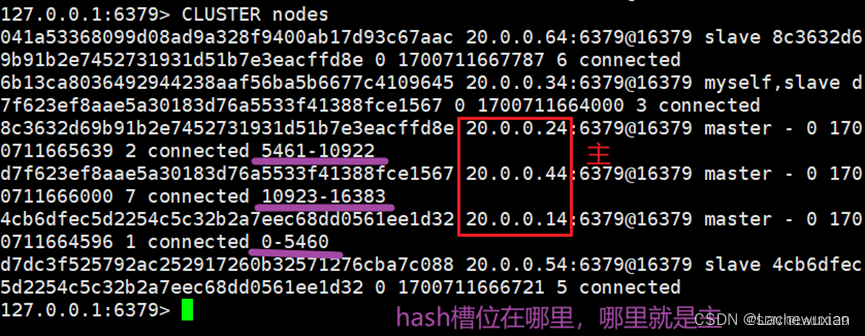
redis集群當中16384個哈希槽位(0-16384)
根據集群當中主節點從節點,分配哈希槽位,每個主從節點只負責一部分的
哈希槽位是連續的哈希槽位,如果出現不連續的哈希值,或者哈希槽位沒有被分配,集群將會報錯
主宕機之后,主節點原來負責的哈爺槽位將會不可用,需要從節點代替主節點繼續負責原有的哈希操作。保證集群正常工作,故障切換的過程中,會提示集群不可用。切換完成,集群恢復繼續工作。
每次讀寫都涉及到哈希槽位,Keyt通過crc16驗證之后,對16384取余數,余數值決定數據放入哪個哈希槽位,通過這個值去找到對應的槽位所在的節點,然后直接跳轉到這個節點
集群的流程:
1 ?集群自帶主從和哨兵模式,
2 ?每個主從是互相隔的可以容忍數據的不完整,目的:高可用
3 ?哈希槽位為決定每個節點的讀寫槽位,在創建Key時,系統已經分配好了指定槽位
4 如果是出現MOVED不是報錯,是提醒客戶端取分配好的槽位節點,獲取數據

實驗
實驗需求:需要6臺裝有redis的虛擬機
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 六臺redis服務器都配置
vim /etc/redis/6379.conf
*****************************************************************************************
?
1、默認監聽所有網卡-----70行
bind 0.0.0.0
?
2、關閉保護模式-----89行
protect-mode no
?
3、開啟守護進程,以獨立進程啟動-----137行
daemonize yes
?
4、開啟AOF持久化-----700行
appendonly yes
?
5、開啟集群功能-----833行
cluster-enabled yes
?
6、集群名稱文件設置-----841行
cluster-config-file nodes-6003.conf
?
7、集群超時時間設置-----847行(15000毫秒)
cluster-node-timeout 15000
?
*****************************************************************************************
?
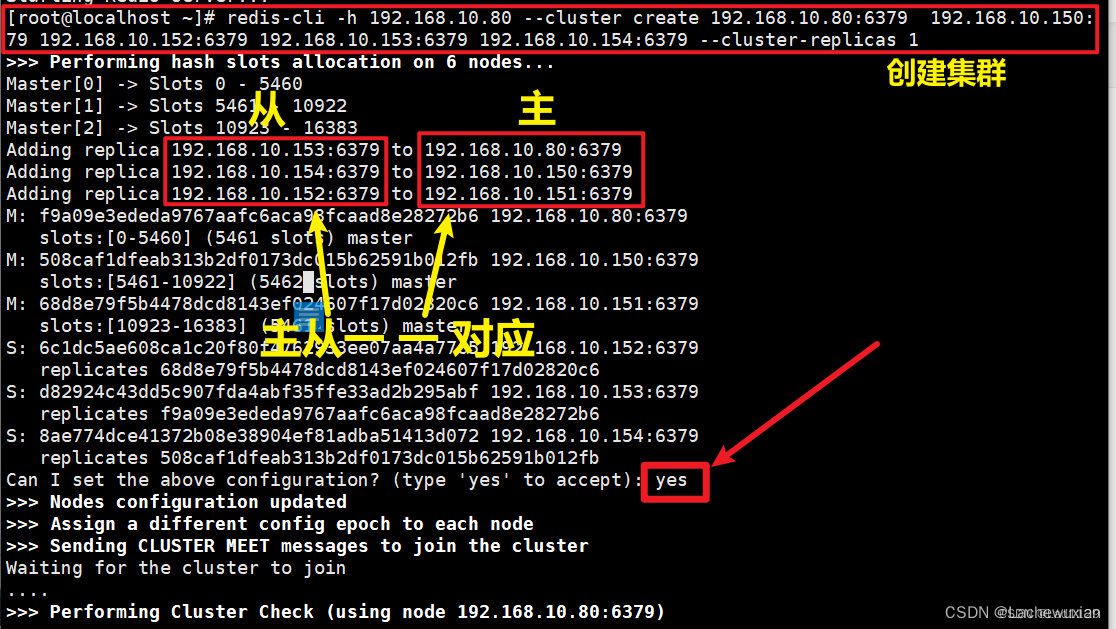
創建集群:redis-cli -h 所在服務器ip --cluster create ip地址:6379 --cluster-replicas 1
?
此時在192.168.10.80主機創建
redis-cli -h 192.168.10.80 --cluster create 192.168.10.80:6379 ?192.168.10.150:6379 179 192.168.10.152:6379 192.168.10.153:6379 192.168.10.154:6379 --cluster-replicas 1
?
[root@localhost ~]# redis-cli -h 192.168.10.80 --cluster create 192.168.10.80:6379 ?192.168.79 192.168.10.152:6379 192.168.10.153:6379 192.168.10.154:6379 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.10.153:6379 to 192.168.10.80:6379
Adding replica 192.168.10.154:6379 to 192.168.10.150:6379
Adding replica 192.168.10.152:6379 to 192.168.10.151:6379
M: f9a09e3ededa9767aafc6aca98fcaad8e28272b6 192.168.10.80:6379
? ?slots:[0-5460] (5461 slots) master
M: 508caf1dfeab313b2df0173dc015b62591b012fb 192.168.10.150:6379
? ?slots:[5461-10922] (5462 slots) master
M: 68d8e79f5b4478dcd8143ef024607f17d02820c6 192.168.10.151:6379
? ?slots:[10923-16383] (5461 slots) master
S: 6c1dc5ae608ca1c20f80f4762933ee07aa4a77c5 192.168.10.152:6379
? ?replicates 68d8e79f5b4478dcd8143ef024607f17d02820c6
S: d82924c43dd5c907fda4abf35ffe33ad2b295abf 192.168.10.153:6379
? ?replicates f9a09e3ededa9767aafc6aca98fcaad8e28272b6
S: 8ae774dce41372b08e38904ef81adba51413d072 192.168.10.154:6379
? ?replicates 508caf1dfeab313b2df0173dc015b62591b012fb
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
....
>>> Performing Cluster Check (using node 192.168.10.80:6379)
M: f9a09e3ededa9767aafc6aca98fcaad8e28272b6 192.168.10.80:6379
? ?slots:[0-5460] (5461 slots) master
? ?1 additional replica(s)
S: 8ae774dce41372b08e38904ef81adba51413d072 192.168.10.154:6379
? ?slots: (0 slots) slave
? ?replicates 508caf1dfeab313b2df0173dc015b62591b012fb
S: 6c1dc5ae608ca1c20f80f4762933ee07aa4a77c5 192.168.10.152:6379
? ?slots: (0 slots) slave
? ?replicates 68d8e79f5b4478dcd8143ef024607f17d02820c6
M: 68d8e79f5b4478dcd8143ef024607f17d02820c6 192.168.10.151:6379
? ?slots:[10923-16383] (5461 slots) master
? ?1 additional replica(s)
S: d82924c43dd5c907fda4abf35ffe33ad2b295abf 192.168.10.153:6379
? ?slots: (0 slots) slave
? ?replicates f9a09e3ededa9767aafc6aca98fcaad8e28272b6
M: 508caf1dfeab313b2df0173dc015b62591b012fb 192.168.10.150:6379
? ?slots:[5461-10922] (5462 slots) master
? ?1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@localhost ~]#?
查看hash槽位CLUSTER nodes



驗證從節點不能讀

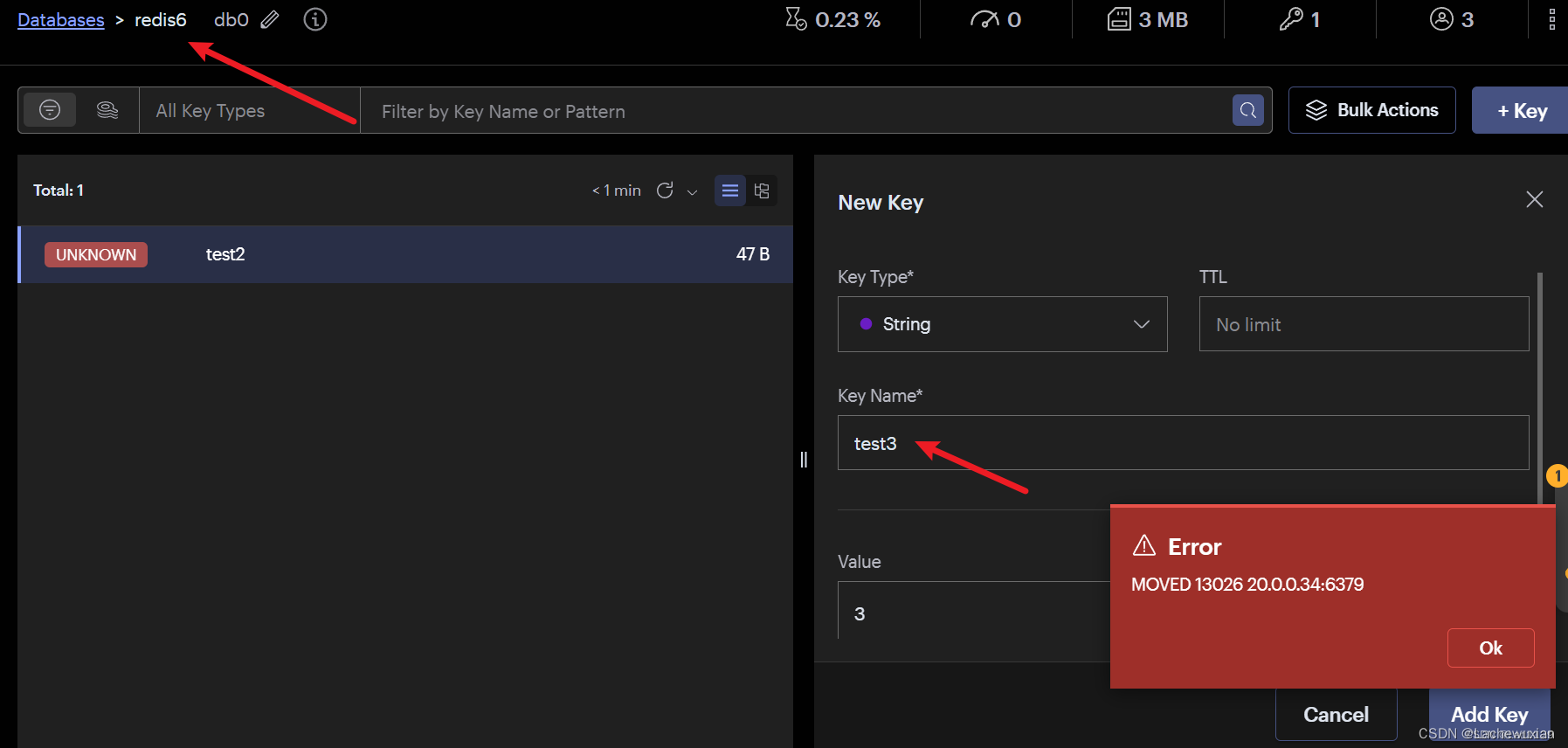
此處error不是報錯,表明客戶端嘗試讀取鍵值對test1,但是實際槽位在4768,因此集群要求客戶端移動到4768槽位所在的主機節點獲取數據
(2)驗證從節點能不能寫。不能

(3)驗證分配hash槽位后,不在相應的hash槽位上的主節點能不能寫。不能,只能到指定節點上操作
主

從
模擬故障
任意一臺主服務器故障
主20.0.0.34——redis3故障,從20.0.0.44——redis4成為新主

?monitor 查看哨兵的ping命令
監控redis實時工作日志,檢測主從節點之間的心跳線
主

從




-進程創建)





)

)







