zookeeper集群中服務器被劃分為以下四種狀態:
- LOOKING:尋找Leader狀態。處于該狀態的服務器會認為集群中沒有Leader,需要進行Leader選舉;
- FOLLOWING:跟隨著狀態,說明當前服務器角色為Follower;
- LEADING:領導者狀態,表明當前服務器角色為Leader;
- OBSERVING:觀察者狀態,表明當前服務器角色為Observer。
Leader選舉的觸發時機
- 集群啟動,這個時候需要選舉出新的Leader;
- Leader服務器宕機;
第一次啟動Leader選舉
假設想在的有三臺機器搭建集群:
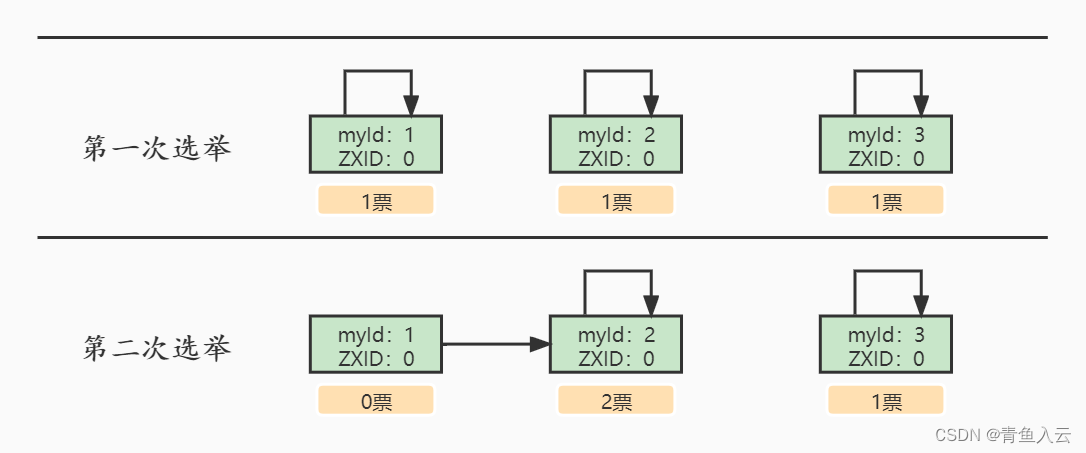
- 每個Server發出一個投票投給自己。當server1啟動的時候,為Looking狀態,對應的myid記為1,ZXID為0,他先投自己一票,此時他的投票為(1,0);然后需要把自己的選票發給集群中的其他機器。
- server2這個時候也啟動了,也是Looking狀態,也先投自己一票,也就是(2,0),然后需要把自己的選票發給集群中的其他機器。
- 接受來自各個服務器的投票。集群的每個服務器收到投票后,首先判斷該投票是否有效,如檢查是否是本輪投票、是否來自LOOKING狀態的服務器;
- 處理投票。針對每一個投票,服務器都需要將別人的投票和自己的投票進行PK,PK的規則如下:
- 優先檢查ZXID。ZXID比較大的服務器優先作為Leader;
- 如果ZXID相同,那么就比較myid。myid較大的服務器作為Leader服務器。
對于Server1而言,它的投票是(1, 0),接收Server2的投票為(2, 0),首先會比較兩者的ZXID,均為0,再比較myid,此時Server2的myid最大,于是更新自己的投票為(2, 0),然后重新投票,對于Server2而言,其無須更新自己的投票,只是再次向集群中所有機器發出上一次投票信息即可。
- 統計投票。每次投票后,服務器都會統計投票信息,判斷是否已經過半機器接收到相同的投票信息,對于Server1、Server2而言,都統計出集群中已經有兩臺機器接受了(2, 0)的投票信息,此時便認為已經選出了Leader。
- 改變服務器狀態。一旦確定了Leader,每個服務器都會更新自己的狀態,如果是Follower,那么就變更為FOLLOWING,如果是Leader,就變更為LEADING。
- 這個時候Server3啟動了, 發現集群中已經有了Leader,就建立連接并把自己的狀態置為Following。
非第一次啟動Leader選舉
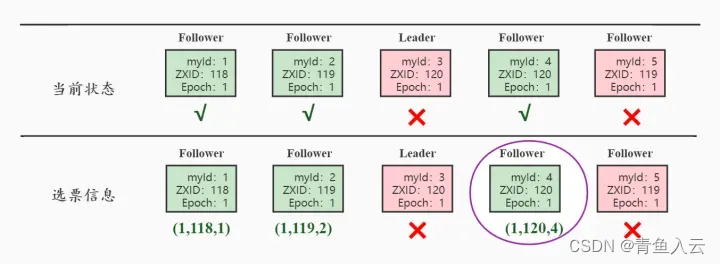
在zookeeper運行期間,即便有新服務器加入,也不會影響到Leader,新加入的服務器會將原有的Leader服務器視為Leader,進行同步。但是一旦Leader宕機了,那么整個集群就將暫停對外服務,進行新一輪Leader的選舉,其過程和啟動時期的Leader選舉過程基本一致。假設正在運行的有Server1、Server2、Server3三臺服務器,當前Leader是Server2,若某一時刻Leader掛了,此時便開始Leader選舉。這里我們假設server3為原本的Leader,其余四臺均為Follower,某一時刻server3和server5都宕機了,那么選舉過程如下:
- 變更狀態。Leader宕機后,余下的非Observer服務器都會將自己的服務器狀態變更為LOOKING,然后開始進行Leader選舉流程;
- 每個Server會發出一個投票。在這個過程中,需要生成投票信息(Epoch,ZXID,myid),對應的server1,server2,server4的選票信息如上圖,;其中Leader選舉的規則是
- EPOCH大的直接勝出
- EPOCH相同,事務大的勝出
- 事務ID相同,服務器ID大的勝出
之后各個Looking狀態的服務器會交換信息,最終會多數選舉server4,也就更改為(1,120,4)的選票信息。
- 接收來自各個服務器的投票。與啟動時過程相同;
- 處理投票;
- 統計投票;
- 改變服務器的狀態,此時server4成為新的Leader。







-基于BiLSTM-CRF的醫學命名實體識別研究(下)模型構建)

是什么?)









