文章目錄
- FlowRAM:用區域感知與流匹配加速高精度機器人操作策略學習
- 一、問題出在哪里?
- 方法部分:從結構到機制,詳解 FlowRAM 的內部設計邏輯
- 1. 動態半徑調度器:自適應注意力機制在 3D 感知中的實現
- 2. 多模態編碼器與序列融合模塊(Mamba)
- 3. 條件流匹配策略生成器:一步式動作生成如何實現?
- 4. 推理流程:從噪聲動作到最終執行動作
- 5. 總結方法特點與優勢
- 三、實驗驗證:任務泛化 + 高精度執行雙優
- 多任務泛化能力
- 高精度任務性能
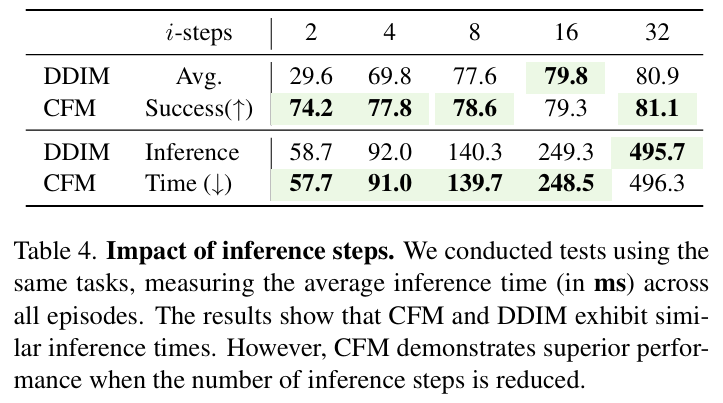
- 推理速度分析
- 四、真實機器人實驗
- 五、總結與展望

FlowRAM:用區域感知與流匹配加速高精度機器人操作策略學習
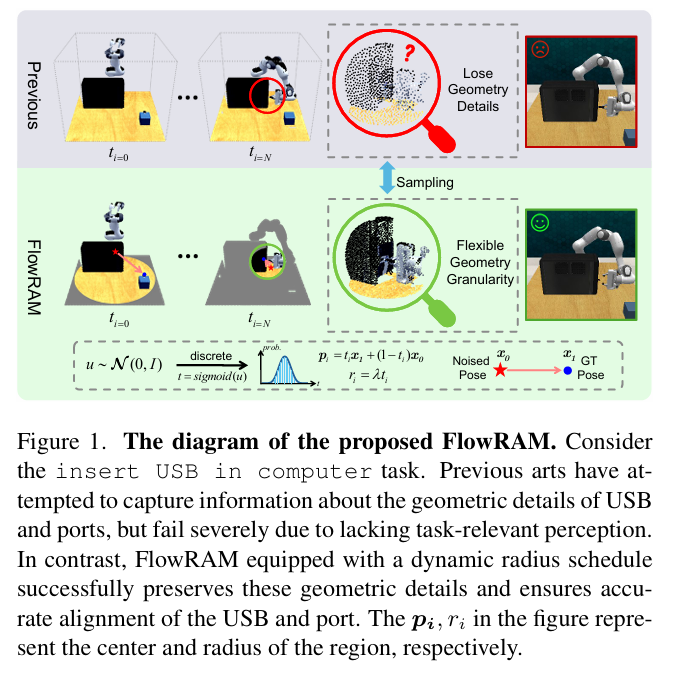
在機器人操作任務中,“又快又準”一直是關鍵挑戰,尤其是在需要亞毫米級精度的插拔、擰螺絲等場景中。然而,當下流行的策略學習范式(如擴散模型)雖然在生成多模態動作方面表現優秀,卻面臨計算效率低、任務感知不精確等痛點。
我們在最近的研究中提出了一個全新的框架 FlowRAM(Flow-based Region-Aware Mamba),融合了條件流匹配(Conditional Flow Matching, CFM)和區域感知機制,打破擴散式方法低效、粗感知的壁壘,在 RLBench 多任務和高精度任務上均取得了SOTA 性能。本博客將系統介紹 FlowRAM 的設計思路、關鍵模塊與實驗表現。
一、問題出在哪里?
現有方法面臨以下兩大瓶頸:
- 低效率的推理過程:擴散模型在推理階段需進行幾十到上百次去噪采樣,推理速度慢,難以滿足實時機器人控制需求;
- 感知不聚焦:很多方法使用全局感知機制(如 voxel grid、FPS),導致模型無法準確識別并關注于任務關鍵區域(如 USB 插口的位置或螺孔的細節),限制了高精度執行能力。
為解決這些問題,我們設計了 FlowRAM,一個結合“精細局部感知”與“流式一跳生成”的通用策略學習框架。
很好,下面我將進一步擴展博客中“方法部分”的內容,使其從介紹性的“三大模塊概覽”深化為具備工程/算法視角的逐層細化分析,適用于具備一定技術背景的讀者或論文審閱者。該部分將拆解為五個子節,內容將涵蓋架構設計邏輯、每個組件的技術實現、參數如何動態調度,以及為什么選擇 CFM 和 Mamba 的理論與實踐優勢。
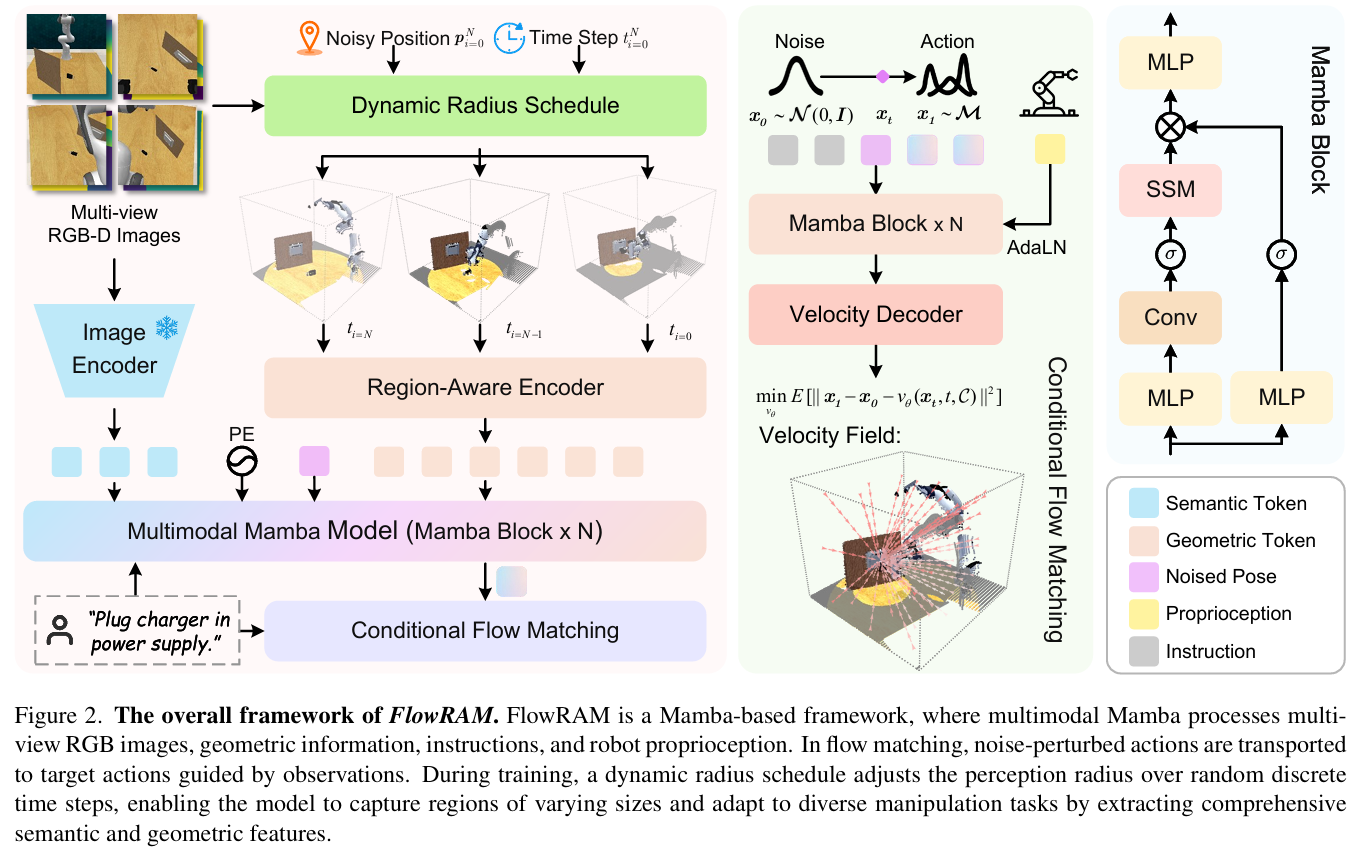
方法部分:從結構到機制,詳解 FlowRAM 的內部設計邏輯
FlowRAM 是一個具備區域感知能力的生成式策略學習框架,融合了現代狀態空間建模(Mamba)和條件流匹配(Conditional Flow Matching, CFM)兩大技術范式,目標是在空間上對操作區域進行高精度建模,在時間上實現高效動作生成。
我們將從以下幾個方面展開:
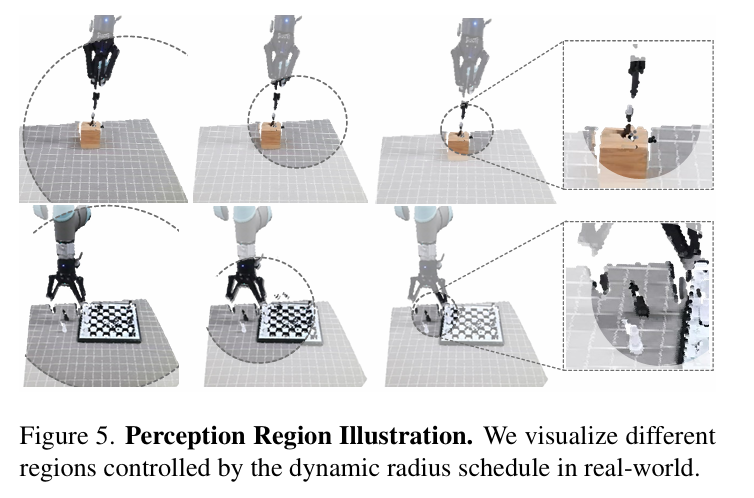
1. 動態半徑調度器:自適應注意力機制在 3D 感知中的實現
在傳統點云策略中,如 Act3D 使用的是全局 Farthest Point Sampling(FPS),每次采樣的都是整個場景中的關鍵點,造成了以下問題:
- 感知資源被浪費在無關區域;
- 與操作目標相關的精細幾何結構(如插口、蓋子邊緣)被稀釋或錯過;
- 在存在遮擋、局部物體形變等情況下缺乏魯棒性。
為此,FlowRAM 提出了一種 Dynamic Radius Schedule (DRS) 感知調度機制,其基本思想是:
隨著時間步的推進(即從粗到細的推理過程),感知區域的半徑從大逐步收縮,使模型逐步聚焦于當前關鍵動作的目標區域。
公式化表示為:
ri=(1?i/N)?(r0?rmin)+rminr_i = (1 - i/N) \cdot (r_0 - r_{min}) + r_{min} ri?=(1?i/N)?(r0??rmin?)+rmin?
- $i$ 表示當前的時間步;
- $N$ 為總步數;
- $r_i$ 為第 $i$ 步的感知半徑;
- $r_0$ 與 $r_{min}$ 分別為起始與最小半徑。
該機制本質上模擬了“空間注意力自焦點化”的過程,讓模型逐漸從粗糙感知過渡到精確定位。
此外,我們為每個時間步定義了一個 mask 區域 $M_i = {(p_i, r_i)}$,其中 $p_i$ 為當前時間步的擾動位姿位置,作為圓心;最終的點云采樣僅在這個動態球形區域中進行。
2. 多模態編碼器與序列融合模塊(Mamba)
FlowRAM 在感知編碼階段采用的是以下多模態輸入:
- 點云輸入:使用 PointMamba(基于 SSM 的 PointNet 變體)提取局部幾何特征;
- RGB 圖像輸入:多視角圖像經由 CLIP + FPN 編碼器提取語義;
- 語言輸入:任務指令經由 CLIP-Text 模塊得到句向量;
- 機器人狀態輸入:包括夾爪狀態、擾動初始動作 pose,線性投影后合并進入 token 序列。
所有特征統一嵌入至維度為 $C$ 的向量空間,并拼接成:
Fin=concat(Fgeo,Frgb,Ftext,Fopen)F_{in} = \text{concat}(F_{geo}, F_{rgb}, F_{text}, F_{open}) Fin?=concat(Fgeo?,Frgb?,Ftext?,Fopen?)
接下來,FlowRAM 使用 多層 Mamba 塊 對該多模態 token 序列進行時序建模,其形式如下:
H_1 = LN(F_{in})H_2 = SSM(\text{SiLU}(Conv1D(Linear(H_1))))F_{out} = Linear(H_2 \odot \text{SiLU}(Linear(H_1)))
該模塊實現了:
- 低復雜度(線性而非平方);
- 狀態保持(不同模態 token 保留上下文記憶);
- 高效融合(融合語義與幾何 token 時的注意力壓縮);
最終,$F_{out}$ 被送入動作生成模塊作為條件特征。
3. 條件流匹配策略生成器:一步式動作生成如何實現?
傳統的 Diffusion Policy 在推理階段必須通過 50-100 步的逐步去噪流程才能得到動作,而 FlowRAM 使用 Conditional Flow Matching (CFM),直接回歸目標關鍵幀動作的矢量場導向路徑,一次完成。
基本公式如下:
- 插值路徑為:$x_t = t x_1 + (1 - t) x_0$
- 流速場為:$u(x_t) = \frac{d x_t}{dt} = x_1 - x_0$
- 學習目標為最小化速度場殘差:
LCFM=Ex0,x1,t[∥x1?x0?vθ(xt,t,C)∥2]\mathcal{L}_{\text{CFM}} = \mathbb{E}_{x_0, x_1, t} \left[\|x_1 - x_0 - v_\theta(x_t, t, C)\|^2\right] LCFM?=Ex0?,x1?,t?[∥x1??x0??vθ?(xt?,t,C)∥2]
其中 $C$ 為條件信息(即 Mamba 編碼的多模態特征)。
我們用一個帶有 AdaLN 的 SSM 模型作為 $v_\theta$,輸入為 $x_t$, $t$, 和條件 $C$,輸出為預測的矢量場速度。
此外,為了預測夾爪開閉狀態,我們增加了一個 Binary Classifier,監督損失為交叉熵:
Lopen=?xlog?x^?(1?x)log?(1?x^)\mathcal{L}_{\text{open}} = -x \log \hat{x} - (1 - x) \log (1 - \hat{x}) Lopen?=?xlogx^?(1?x)log(1?x^)
最終訓練目標為:
Ltotal=λ1LCFM+λ2Lopen\mathcal{L}_{\text{total}} = \lambda_{1} \mathcal{L}_{\text{CFM}} + \lambda_{2} \mathcal{L}_{\text{open}} Ltotal?=λ1?LCFM?+λ2?Lopen?
4. 推理流程:從噪聲動作到最終執行動作
推理過程非常高效:
- 從高斯分布中采樣初始動作 $x_0$;
- 通過 DRS 確定當前時間步的感知半徑,提取關鍵區域點云;
- 使用 Mamba 提取融合特征 $C$;
- 用如下歐拉積分方式前向演化:
xt+Δt=xt+vθ(xt,t,C)?Δtx_{t + \Delta t} = x_t + v_\theta(x_t, t, C) \cdot \Delta t xt+Δt?=xt?+vθ?(xt?,t,C)?Δt
- 重復上步 2-4 次,便可得到目標關鍵幀動作 $x_1$,平均推理時間 < 92ms。
5. 總結方法特點與優勢
| 維度 | FlowRAM 優勢 |
|---|---|
| 感知方式 | 動態注意區域,多尺度幾何采樣 |
| 模態融合 | Mamba 結構替代 Transformer,復雜度線性 |
| 動作生成 | CFM 替代 Diffusion,速度更快,效果更穩定 |
| 通用性 | 可適配語言、RGB-D、點云、proprioception 多模態輸入 |
| 可部署性 | 已在真實機器人 UR5 上部署成功 |
三、實驗驗證:任務泛化 + 高精度執行雙優
我們在 RLBench 上進行了系統評估,包括:
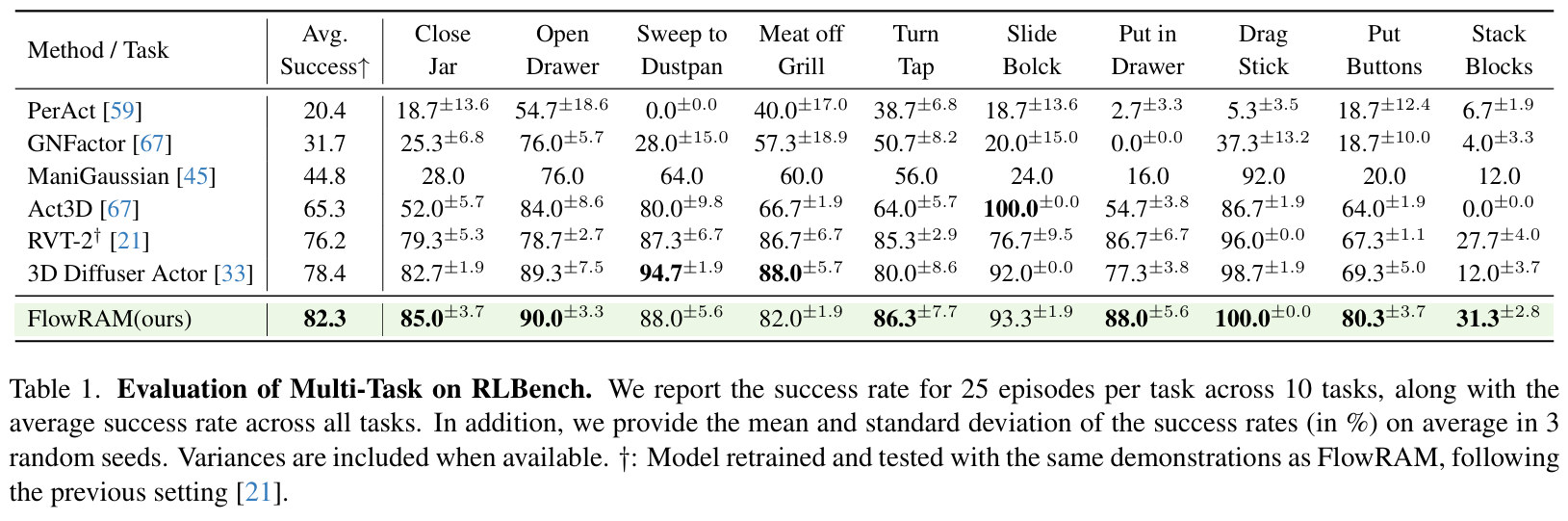
多任務泛化能力
在 10 個標準任務上,FlowRAM 平均成功率達到 82.3%,比現有 SOTA 方法(如 RVT-2、3D Diffuser Actor)高出近 4%。在復雜任務(如 Stack Blocks)中更是超出對手近 19%。
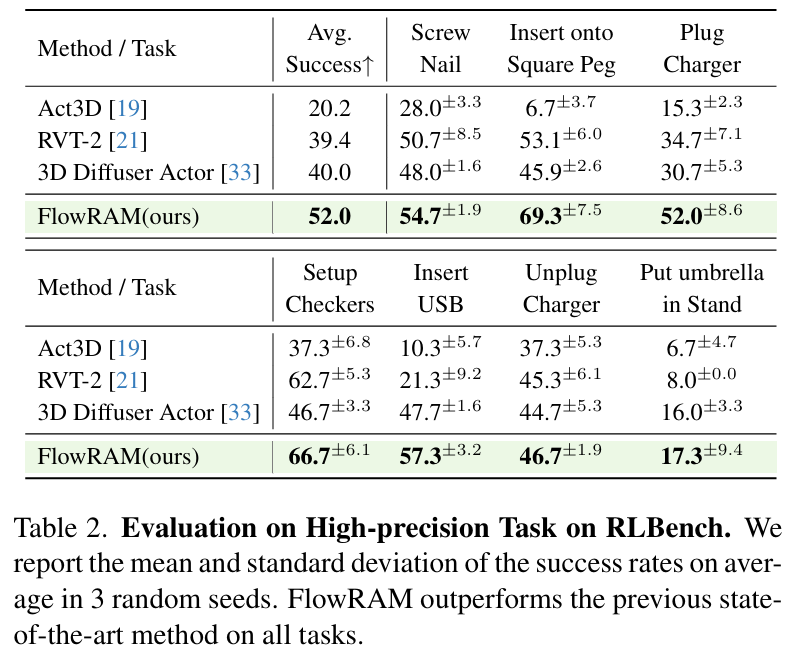
高精度任務性能
我們在 RLBench 中挑選了 7 個對幾何精度極度敏感的任務,如插 USB、擰螺絲等。在這些任務中,FlowRAM 平均成功率高達 52.0%,相比基線模型大幅領先:
- Insert USB:FlowRAM 成功率 57.3%,RVT-2 僅 21.3%
- Screw Nail:FlowRAM 54.7%,其他方法均低于 50%
推理速度分析
在相同精度下,FlowRAM(CFM)僅需 2~4 步即可生成動作,遠優于 DDIM、DDPM 等擴散模型(需要 50~100 步)。如下圖所示,速度與精度雙優:
四、真實機器人實驗
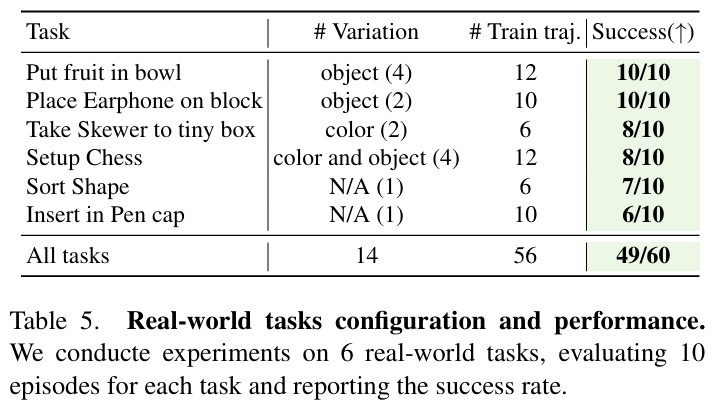
我們將 FlowRAM 部署于真實 UR5 機械臂,配合 Robotiq 夾爪與 Azure Kinect 相機,在 6 個語言條件下的真實任務中表現出色。平均成功率達 81.7%,驗證了該方法在少量示范下的實用性和魯棒性。
任務包括:
- 插入筆帽
- 果盤分類
- 耳機擺放
- 棋盤布置等
五、總結與展望
FlowRAM 提供了一種融合區域感知與高效生成的新范式,專為機器人操作中的高精度任務設計。其關鍵優勢包括:
- 感知局部細節而非全局冗余
- 快速生成動作而非多輪迭代
- 高性能與低推理成本并存
未來,我們希望將 FlowRAM 推向更復雜的現實環境,如多機器人協作、非剛體操作以及開源多模態數據集適配。我們也歡迎社區同行一起探索流匹配范式下的策略生成與視覺感知新邊界。
📌 如你感興趣,歡迎閱讀我們完整論文:FlowRAM: Grounding Flow Matching Policy with Region-Aware Mamba,或與我們團隊聯系交流合作。
📦 代碼已開源:歡迎訪問我們的 GitHub 倉庫,如果對你有幫助,別忘了點個 star ? 支持我們!
Milvus可視化工具)

)




)
|Input Embedding 對輸入進行特征嵌入)









)
