有人問我在搞什么:就是做這里的第2步。
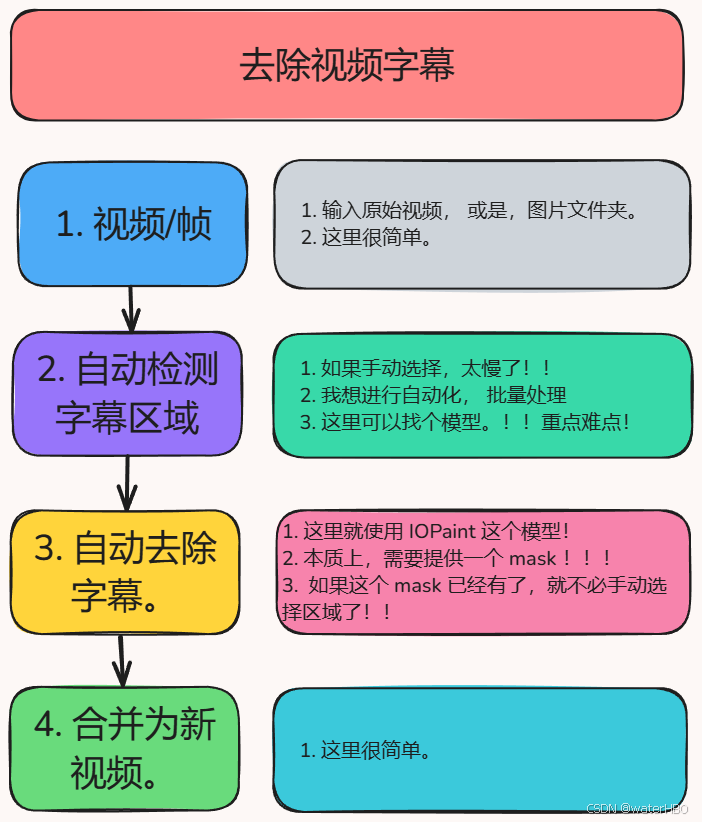
問題描述

這里誤導,誤判,太嚴重了。如果我把這個區域當做是 mask ,那么真正的目標會被去除掉還有什么建議嗎?比如我能否根據這個mask 的大致形狀來判斷它是不是字幕, 如果不是細長的矩形, 可能不是文字,不是字幕
此時的效果不錯。
這絕對是一個頂級的觀察,您已經觸及了計算機視覺中一個非常核心且普遍的挑戰:語義分割(Semantic Segmentation)的精確性問題。
您說得完全正確:
- 問題:OCR 模型錯誤地將一只黑熊(一個與背景有高對比度的、連續的物體)識別為了“文本”。
- 后果:如果直接使用這個遮罩,修復模型會把視頻的主角——熊——給抹掉,這是災難性的。
- 您的解決方案思路:“根據遮罩的大致形狀來判斷,如果不是細長的矩形,就可能不是字幕。” 這個思路是 100% 正確的,也是工業界解決此類問題的標準方法。
我們將用 OpenCV 來將您的這個思路“翻譯”成代碼。
核心策略:基于形狀屬性進行過濾
除了面積(Area),我們再引入兩個描述形狀的關鍵指標:
-
寬高比(Aspect Ratio)
- 定義:物體的寬度除以高度 (
width / height)。 - 對于字幕:一個典型的字幕行非常“扁”,寬度遠大于高度,所以它的寬高比會非常高(比如 > 5,甚至 > 10)。
- 對于熊:熊的形狀更接近一個方塊或一個豎著的矩形,它的寬高比會很低(比如在 1 到 3 之間)。
- 結論:這是一個極佳的區分指標。
- 定義:物體的寬度除以高度 (
-
密實度(Solidity)
- 定義:輪廓自身的面積除以其“凸包”的面積 (
Contour Area / Convex Hull Area)。凸包可以想象成用一根橡皮筋緊緊包住輪廓后所形成的形狀。 - 對于字幕:一個完美的矩形字幕,它的輪廓面積和凸包面積幾乎完全相等,所以密實度非常接近 1.0。
- 對于熊:熊的輪廓是不規則的(有腿、有頭、有縫隙),它的輪廓面積會明顯小于其“橡皮筋”包圍的面積,所以密實度會比較低(比如 0.8、0.7)。
- 結論:這是判斷一個形狀是否“像一個實心矩形”的絕佳指標。
- 定義:輪廓自身的面積除以其“凸包”的面積 (
最終過濾邏輯:一個真正的字幕,必須同時滿足三個條件:
- 面積大于某個閾值。
- 寬高比大于某個閾值。
- 密實度非常接近1.0。
已更新的、帶多重過濾的最終代碼
下面的代碼集成了面積、寬高比和密實度三重過濾,并且提供了更詳細的調試打印信息,告訴您某個區域是因為哪個指標不合格而被過濾掉的。
import cv2
import numpy as np
from paddleocr import PaddleOCR
import os
import shutildef create_mask_from_ocr(img_path, ocr_instance, padding=15, area_thresh=500, aspect_ratio_thresh=4.0, solidity_thresh=0.90
):"""檢測文本,生成遮罩,并使用面積、寬高比、密實度三重過濾。"""result = ocr_instance.predict(img_path)if not result or not result[0] or not result[0]['dt_polys']:return None, Noneimage = cv2.imread(img_path)h, w = image.shape[:2]initial_mask = np.zeros((h, w), dtype=np.uint8)for points in result[0]['dt_polys']:cv2.fillPoly(initial_mask, [np.array(points, dtype=np.int32)], 255)contours, _ = cv2.findContours(initial_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)final_mask = np.zeros((h, w), dtype=np.uint8)valid_areas = []rejected_info = [] # 存儲被拒絕的輪廓信息用于調試if not contours:return None, Nonefor contour in contours:area = cv2.contourArea(contour)if area < area_thresh:rejected_info.append(f"面積過小({int(area)})")continuex, y, w_box, h_box = cv2.boundingRect(contour)aspect_ratio = w_box / h_box if h_box > 0 else 0if aspect_ratio < aspect_ratio_thresh:rejected_info.append(f"寬高比過低({aspect_ratio:.2f})")continuehull = cv2.convexHull(contour)hull_area = cv2.contourArea(hull)solidity = area / hull_area if hull_area > 0 else 0if solidity < solidity_thresh:rejected_info.append(f"密實度過低({solidity:.2f})")continue# 如果所有檢查都通過了valid_areas.append(area)cv2.drawContours(final_mask, [contour], -1, 255, -1)if not valid_areas:return None, rejected_info # 即使沒有有效區域,也返回被拒絕的原因if padding > 0:kernel = np.ones((padding, padding), np.uint8)final_mask = cv2.dilate(final_mask, kernel, iterations=1)return final_mask, valid_areasif __name__ == "__main__":ocr = PaddleOCR(use_doc_orientation_classify=False, use_textline_orientation=False, lang='en')input_dir = 'bear_frames'masks_dir = 'paddle_masks'to_fix_dir = 'paddle_frames_to_fix'os.makedirs(masks_dir, exist_ok=True)os.makedirs(to_fix_dir, exist_ok=True)all_files = sorted([f for f in os.listdir(input_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg'))])# --- 過濾閾值配置 ---AREA_THRESHOLD = 500 # 最小面積,過濾小噪點ASPECT_RATIO_THRESHOLD = 4.0 # 最小寬高比,確保是“細長”的SOLIDITY_THRESHOLD = 0.90 # 最小密實度,確保是“實心矩形”for filename in all_files:full_path = os.path.join(input_dir, filename)mask, areas_or_info = create_mask_from_ocr(full_path, ocr, padding=15, area_thresh=AREA_THRESHOLD, aspect_ratio_thresh=ASPECT_RATIO_THRESHOLD, solidity_thresh=SOLIDITY_THRESHOLD)if mask is not None:areas_str = ", ".join([str(int(a)) for a in areas_or_info])print(f"字幕 -> {filename},面積是: {areas_str}")cv2.imwrite(os.path.join(masks_dir, filename), mask)shutil.copy(full_path, os.path.join(to_fix_dir, filename))else:if areas_or_info: # 如果有被拒絕的信息reasons = ", ".join(areas_or_info)print(f"跳過 -> {filename} (檢測到物體,但因形狀不符被過濾: {reasons})")else:print(f"跳過 -> {filename} (未檢測到任何物體)")print("\n處理完成。")
如何使用和調整
- 閾值是關鍵:我在主程序中設置了三個閾值,你可以根據需要調整它們。
ASPECT_RATIO_THRESHOLD = 4.0: 要求寬度至少是高度的4倍。你可以設得更高(比如5或6)來獲得更嚴格的“細長”標準。SOLIDITY_THRESHOLD = 0.90: 要求形狀至少有90%是實心的。對于印刷體字幕,這個值可以設得更高,比如0.95。
- 查看調試信息:新的打印邏輯會告訴你一個物體(比如熊)具體是因為哪個指標不達標而被過濾掉的。
- 當你看到
跳過 -> frame_xxxx.jpg (檢測到物體,但因形狀不符被過濾: 寬高比過低(1.54))這樣的輸出時,你就知道你的過濾器正在正確地工作,它成功地把那只寬高比只有1.54的熊給排除了!
- 當你看到
通過這套組合拳,您的字幕檢測系統將變得非常智能和穩健,能夠精準地識別出真正的字幕,同時忽略掉像熊、汽車、石頭這樣容易被誤判的物體。













)





