文章目錄
- 參考資料
- 一 AI Agent
- 二 ReAct
- 三 LangGraph實現ReAct代理
- 3.1 SerperAPI實時聯網搜索
- 3.2 ReAct實現
參考資料
- entic RAG 架構的基本原理與應用入門
一 AI Agent
- AI Agent 整個過程是一個動態循環。Agent不斷從環境中學習,通過其行動影響環境,然后根據環境的反饋繼續調整其行動和策略。這種模式特別適用于那些需要理解和生成自然語言的應用場景,如聊天機器人、自動翻譯系統或其他形式的自動化客戶支持。
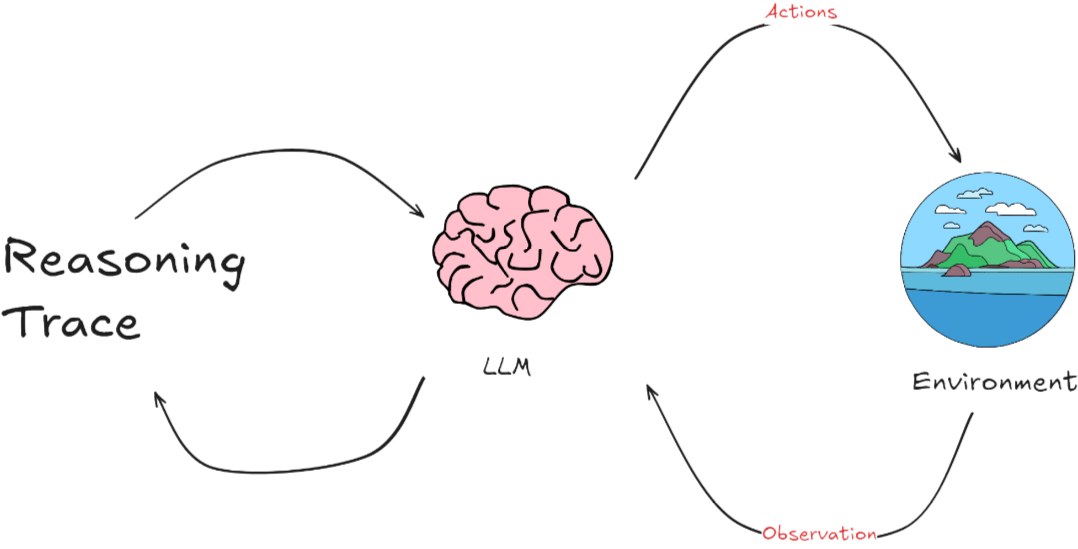
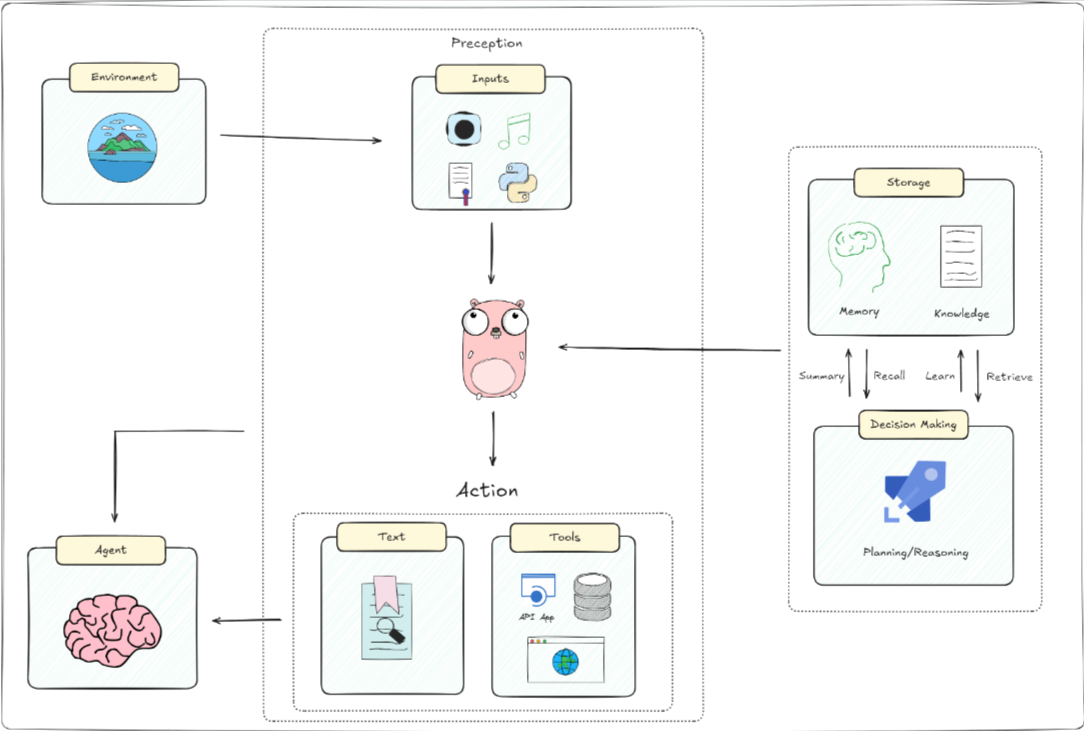
一個人工智能代理的基本架構,包括它與環境的互動、感知輸入、大腦處理及其決策過程。具體來說:
- 環境(Environment): AI代理接收來自其周圍環境的信息。環境可以是一個網站、數據庫或任何其他類型的系統。
- 感知(Perception): 即輸入。AI代理通過多種方式感知環境,如視覺(圖像)、聽覺(聲音)、文本(文字信息)和其他傳感器輸入(如位置、溫度等)。這些輸入幫助代理理解當前的環境狀態。
- 大腦(Brain):
- 存儲(Storage):
- 記憶(Memory):存儲先前的經驗和數據,類似于人類的記憶。
- 知識(Knowledge):包括事實、信息和代理用于決策的程序。
- 決策制定(Decision Making):總結(Summary)、回憶(Recall)、學習(Learn)、檢索(Retrieve):這些功能幫助AI在需要時回顧和利用存儲的知識。
- 規劃/推理(Planning/Reasoning):基于當前輸入和存儲的知識,制定行動計劃。
- 行動(Action):代理基于其感知和決策過程產生響應或行動。這可以是物理動作、發送API請求、生成文本或其他形式的輸出。
二 ReAct
- ReAct 代理可以處理順序的多部分查詢,同時通過將路由、查詢規劃和工具使用組合到單個實體中來維護狀態(在內存中)。通過交叉推理和行動,ReAct 使智能體能夠動態地在產生想法和特定于任務的行動之間交替。
- ReAct:Synergizing Reasoning and Acting in Language Models
- ReAct 框架有兩個過程,由 Reason 和 Act 結合而來。從本質上講,這種方法的靈感來自于人類如何通過和諧地結合思維和行動來執行任務。
- Reason基于一種推理技術——思想鏈(CoT)。 CoT是一種提示工程,通過將輸入分解為多個邏輯思維步驟,幫助大語言模型執行推理并解決復雜問題。這使得大模型能夠按順序規劃和解決任務的每個部分,從而更準確地獲得最終結果。
- 分解問題:當面對復雜的任務時,CoT 方法不是通過單個步驟解決它,而是將任務分解為更小的步驟,每個步驟解決不同方面的問題。
- 順序思維:思維鏈中的每一步都建立在上一步的結果之上。這樣,模型就能從頭到尾構造出一條邏輯推理鏈。
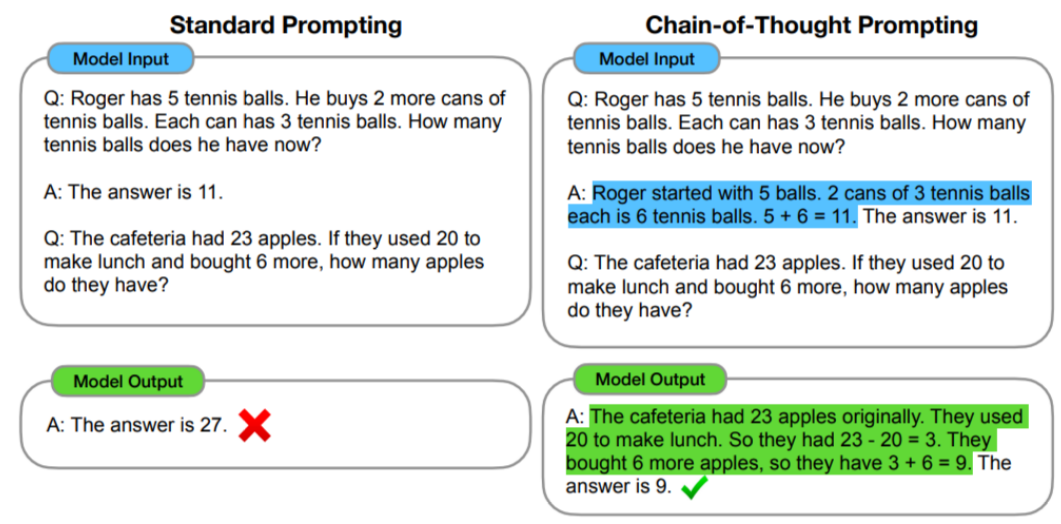
- 在 CoT 提示工程的限定下,大模型仍然會產生幻覺。因為經過長期的使用,大家發現在推理的中間階段會產生不正確的答案或上下游的傳播錯誤,所以,Google DeepMind 團隊開發了ReAct的技術來彌補這一點。
- ReAct 采用的是 思想-行動-觀察循環的思路,其中代理根據先前的觀察進行推理以決定行動。這個迭代過程使其能夠根據其行動的結果來調整和完善其方法。
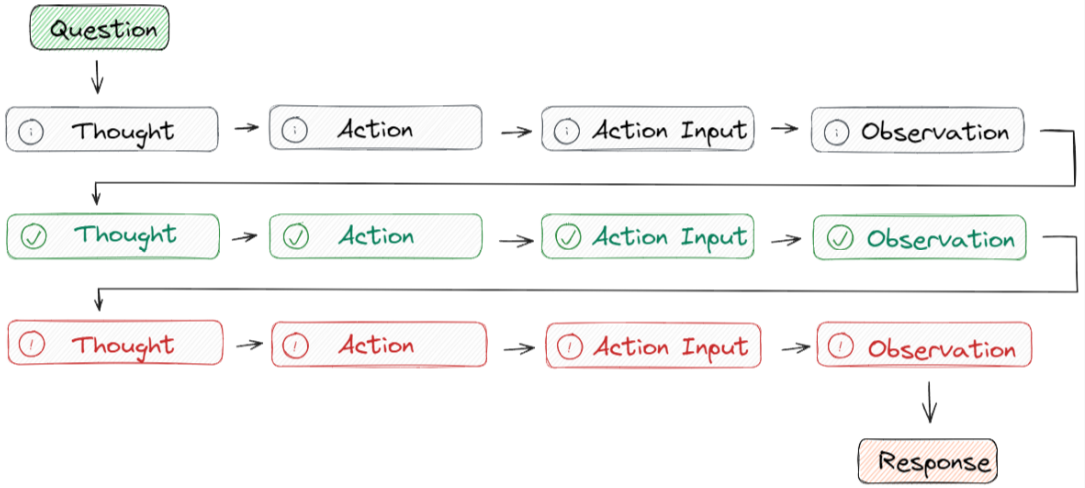
- Question指的是用戶請求的任務或需要解決的問題。
- Thought用來確定要采取的行動并向大模型展示如何創建/維護/調整行動計劃。
- Action Input是用來讓大模型與外部環境(例如搜索引擎、維基百科)的實時交互,包括具有預定義范圍的API。
- Observation是會觀察執行操作結果的輸出,重復此過程直至任務完成。
三 LangGraph實現ReAct代理
3.1 SerperAPI實時聯網搜索
- Serper一個高性能的Google搜索APl,提供快速且成本效益高的方式訪問Google搜索結果。在目前的應用落地產品中廣泛被用于增強聊天機器人、進行搜索引擎優化(SEO)分析和簡化金融科技項目等多種場景。該API具備:執行實時搜索、自定義查詢位置、快速訪問Google的搜索引擎結果等優勢。
- 新用戶注冊具有2500次免費搜索額度,可以在Playground中自定義搜索配置。
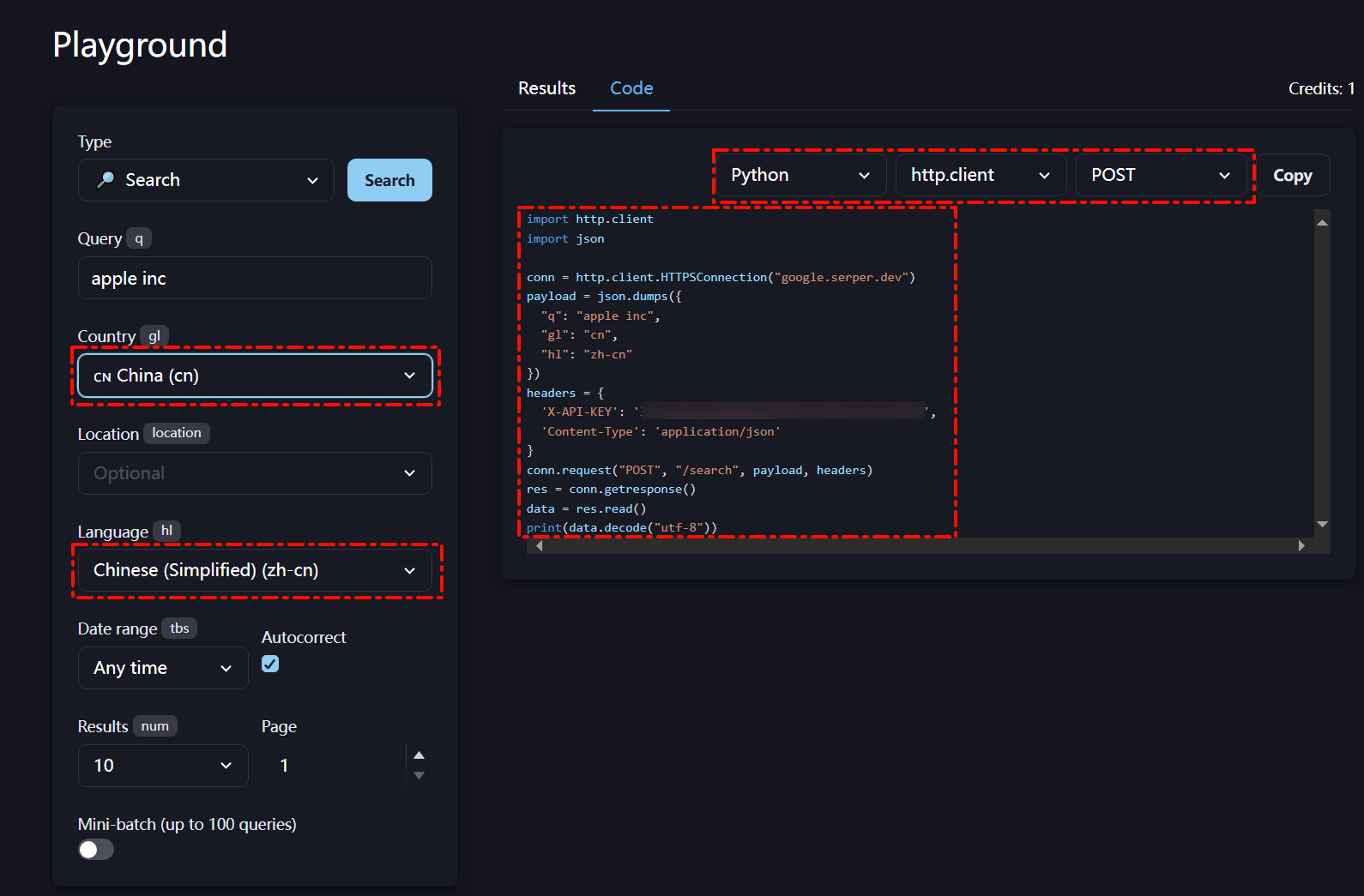
- 簡單測試用例
import http.client
import jsonconn = http.client.HTTPSConnection("google.serper.dev")
payload = json.dumps({"q": "通義千問最新模型","gl": "cn","hl": "ny"
})
headers = {'X-API-KEY': 'xxx','Content-Type': 'application/json'
}
conn.request("POST", "/search", payload, headers)
res = conn.getresponse()
data = res.read()
#print(data.decode("utf-8"))
data=json.loads(data.decode("utf-8"))# 將返回的JSON字符串轉換為字典
3.2 ReAct實現
- OpenAI 中轉API key平臺
- LLM Model使用gpt-4o
from typing import (Annotated,Sequence,TypedDict)
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
from langchain_core.tools import tool
from typing import Union, Optional
from pydantic import BaseModel, Field
import json
import http.clientclass AgentState(TypedDict):"""代理狀態"""messages: Annotated[Sequence[BaseMessage], add_messages]class SearchQuery(BaseModel):"""SearchQuery 數據模型"""query: str = Field(description="Questions for networking queries")# 參數 args_schema=SearchQuery 表示使用 SearchQuery 模型來驗證函數的輸入參數
@tool(args_schema = SearchQuery)
def fetch_real_time_info(query):"""獲取互聯網實時信息工具函數"""conn = http.client.HTTPSConnection("google.serper.dev")payload = json.dumps({"q": query,"gl": "cn","hl": "ny"})headers = {'X-API-KEY': 'xxx','Content-Type': 'application/json'}conn.request("POST", "/search", payload, headers)res = conn.getresponse()data = res.read()#print(data.decode("utf-8"))data=json.loads(data.decode("utf-8"))# 將返回的JSON字符串轉換為字典 if 'organic' in data:return json.dumps(data['organic'], ensure_ascii=False) # 返回'organic'部分的JSON字符串else:return json.dumps({"error": "No organic results found"}, ensure_ascii=False) # 如果沒有'organic'鍵,返回錯誤信息#fetch_real_time_info.invoke({"query": "通義千問最新模型"})#----------------------------
import os
from langchain_openai import ChatOpenAI
api_key="hk-xxx"
base_url="https://api.openai-hk.com/v1"# 臨時設置環境變量
os.environ["OPENAI_API_KEY"] = api_key
os.environ["OPENAI_BASE_URL"] = base_url
# 實例化模型
llm = ChatOpenAI(api_key=api_key,base_url=base_url,model="gpt-4o"
)# 綁定工具
tools = [fetch_real_time_info]
model = llm.bind_tools(tools) # ----------------------------
import json
from langchain_core.messages import ToolMessage, SystemMessage, HumanMessage
from langchain_core.runnables import RunnableConfigtools_by_name = {tool.name: tool for tool in tools}# 定義工具節點
def tool_node(state: AgentState):outputs = []for tool_call in state["messages"][-1].tool_calls:tool_result = tools_by_name[tool_call["name"]].invoke(tool_call["args"])outputs.append(ToolMessage(content=json.dumps(tool_result),name=tool_call["name"],tool_call_id=tool_call["id"],))return {"messages": outputs}# 定義問答模型
def call_model(state: AgentState,):system_prompt = SystemMessage("你是一個智能助手,請盡全力回答用戶的問題")response = model.invoke([system_prompt] + state["messages"])return {"messages": [response]}# 定義路由節點
def should_continue(state: AgentState):messages = state["messages"]last_message = messages[-1]if not last_message.tool_calls:return "end"else:return "continue"# -----------------------------------
from langgraph.graph import StateGraph, END
from IPython.display import Image, display
# 定義一個圖結構
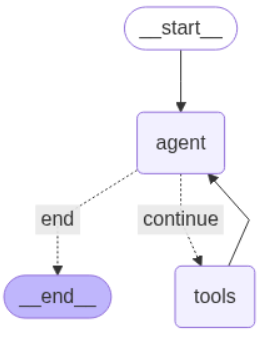
workflow = StateGraph(AgentState)# 在圖結構中添加節點
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)# 設置啟動點是 agent
workflow.set_entry_point("agent")# 添加路由邊
workflow.add_conditional_edges("agent",should_continue,{"continue": "tools","end": END,},
)
# 添加返回邊
workflow.add_edge("tools", "agent")
# 編譯圖
graph = workflow.compile()
display(Image(graph.get_graph().draw_mermaid_png()))# 打印問答的流
def print_stream(stream):"""打印消息流的工具函數,支持兩種消息格式:1. 元組(tuple)形式的原始消息 2. 具有 pretty_print() 方法的對象 參數:stream: 可迭代的消息流,每個元素應包含 "messages" 列表 """for s in stream: # 遍歷消息流中的每個元素message = s["messages"][-1] # 獲取當前元素中 messages 列表的最后一個消息 if isinstance(message, tuple): # 如果消息是元組類型print(message) # 直接打印原始元組 else: # 其他情況message.pretty_print() # 調用對象的格式化打印方法 inputs = {"messages": [("user", "如何看待通義千問最新模型?")]}
print_stream(graph.stream(inputs, stream_mode="values"))
================================ Human Message =================================
如何看待通義千問最新模型?
================================== Ai Message ==================================
Tool Calls:
fetch_real_time_info (call_b85QNErx5VwN3KXtaDTQQbbe)
Call ID: call_b85QNErx5VwN3KXtaDTQQbbe
Args:
query: 通義千問最新模型 發布
================================= Tool Message =================================
Name: fetch_real_time_info
“[{xxx}]”
================================== Ai Message ==================================
對于阿里巴巴云最新發布的通義千問模型(Qwen3),這次更新帶來了許多重要的變化和提升。以下是一些關鍵點:
-
版本升級: 通義千問的Qwen3版本及其子系列已經得到了顯著提升。最新的Qwen3-Coder系列具有卓越的代碼生成能力,被認為在開源模型中達到SOTA(State Of The Art)效果。
-
強化的核心: Qwen3系列核心的235B旗艦版本進行了同步重磅升級,其模型的通用能力顯著領先于之前的版本。這表明模型在處理復雜任務時能夠更高效地應對并提供更精確的結果。
-
多模態支持: 在不同應用場合的適應能力上,Qwen3還推出了加強互動環境的能力,使其在工具調優和環境交互中表現優異,使用戶能夠實現更加自主的任務操作。
更多詳細信息可以訪問阿里云官網。


![[Qt]QString隱式拷貝](http://pic.xiahunao.cn/[Qt]QString隱式拷貝)


elasticsearch-華為云CCE無狀態負載部署)



)
---從DeepseekR1-1.5B到Qwen-2.5-1.5B蒸餾)

)
)



)

