數據倉庫深度探索系列 | 開篇:開啟數倉建設新征程
在當今信息技術飛速發展的背景下,企業面臨著數據量的爆炸式增長。企業不僅要高效管理海量數據,還需從中提取關鍵信息以支持復雜決策。數據倉庫已從單純的數據存儲工具,演變為支持復雜查詢、報告生成和深度數據分析的必備工具,成為企業信息化戰略的核心部分。建設數據倉庫涉及需求分析、數據抽取、轉換和加載(ETL)、數據建模等環節,需要企業明確業務目標、制定技術路線圖,同時加強跨部門協作和項目管理。
 關注三倍鏡和我們一起探索
關注三倍鏡和我們一起探索
大家好呀!我們是三倍鏡團隊,專注于為企業提供專業、前沿的數據解決方案。在數字化浪潮席卷全球的今天,數據已成為企業發展的核心資產,而數據倉庫作為數據管理的關鍵基礎設施,其重要性不言而喻。
從本期開始,我們隆重推出“數據倉庫深度探索系列”文章。本系列將全方位、多角度深入剖析數據倉庫的建設、應用與優化,旨在助力企業構建一個高效的數據倉庫體系。通過這一系列的探索,我們將幫助企業充分挖掘數據的潛在價值,實現數據驅動下的精細化運營管理。
具體來說,我們將從以下幾個關鍵板塊進行深度探索:
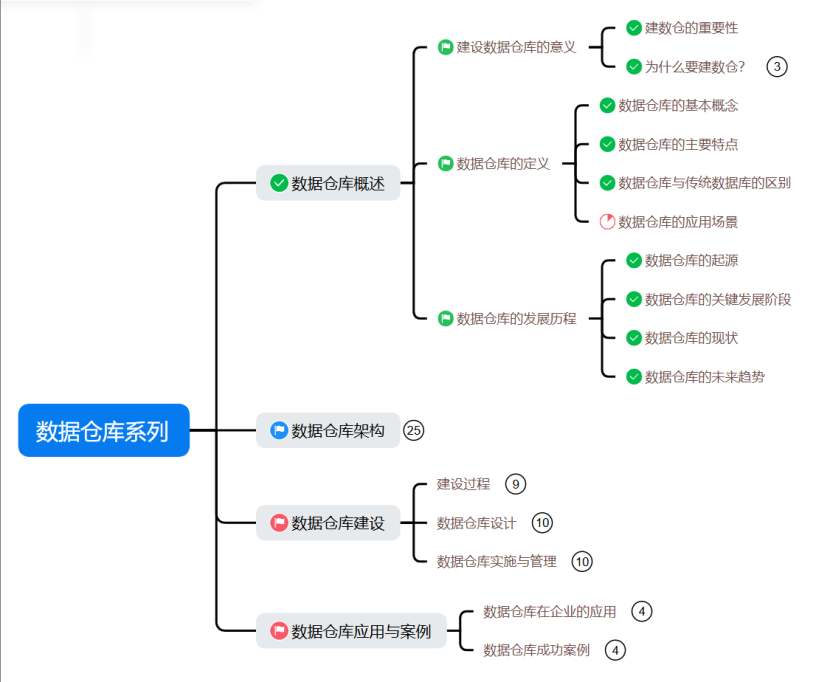
1.數據倉庫概述:包括數據倉庫的定義、特點、與傳統數據庫的區別、應用場景以及發展歷程等,幫助讀者建立對數據倉庫的全面認識。
2.數據倉庫架構:深入解析數據倉庫的架構設計,包括不同架構類型的選擇、數據模型的構建等,為數據倉庫的搭建提供理論支持。
3.數據倉庫建設:詳細介紹數據倉庫的建設過程,包括數據倉庫的設計、實施與管理,確保數據倉庫的高效構建和運行。
4.數據倉庫應用與案例:通過分析數據倉庫在企業中的實際應用案例,展示數據倉庫如何助力企業各業務線降本提效,為業務決策提供有力支持。
 通過這一系列的深度探索,我們期望能夠幫助企業在數字化轉型的浪潮中乘風破浪,實現數據價值的最大化,推動企業的持續發展和創新。敬請期待我們的系列文章,一起開啟數據倉庫的深度探索之旅。
通過這一系列的深度探索,我們期望能夠幫助企業在數字化轉型的浪潮中乘風破浪,實現數據價值的最大化,推動企業的持續發展和創新。敬請期待我們的系列文章,一起開啟數據倉庫的深度探索之旅。
建設數據倉庫的意義
數據倉庫的重要性
 提供全面視角:數據倉庫整合不同業務系統的數據,將分散、不同格式的數據整合成統一視圖,為決策者呈現企業運營全景,助力其深入了解企業狀況。
提供全面視角:數據倉庫整合不同業務系統的數據,將分散、不同格式的數據整合成統一視圖,為決策者呈現企業運營全景,助力其深入了解企業狀況。
支持戰略決策:數據倉庫的數據可用于分析預測業務趨勢,通過挖掘數據,企業能把握市場需求、客戶行為和競爭動態,從而制定精準戰略和業務計劃,增強市場競爭力。
提升業務效率:數據倉庫通過數據分析幫助企業優化業務流程,發現潛在問題和機會,改進業務流程。同時,自動化數據整合和報告功能,減輕人工負擔,提升工作效率。
支持業務智能:數據倉庫提供數據挖掘、可視化、預測分析等業務智能功能,助力企業洞察趨勢和模式,做出更優決策,為企業創造競爭優勢。
為什么要建數據倉庫?
 支持復雜的數據分析需求:企業業務和數據量的增長使傳統數據庫難以滿足分析需求。數據倉庫通過集成多源數據,提供統一視圖和強大查詢能力,支持多維度分析、數據挖掘和預測分析,助力企業深入了解市場、客戶和運營,為戰略決策和業務優化提供支持。
支持復雜的數據分析需求:企業業務和數據量的增長使傳統數據庫難以滿足分析需求。數據倉庫通過集成多源數據,提供統一視圖和強大查詢能力,支持多維度分析、數據挖掘和預測分析,助力企業深入了解市場、客戶和運營,為戰略決策和業務優化提供支持。
 提高數據質量和一致性:企業日常運營中數據分散易導致冗余、不一致和錯誤。數據倉庫借助ETL過程清洗、轉換和整合數據,保障一致性和準確性。同時,它具備數據質量監控和校驗機制,及時糾正問題,提升數據質量。
提高數據質量和一致性:企業日常運營中數據分散易導致冗余、不一致和錯誤。數據倉庫借助ETL過程清洗、轉換和整合數據,保障一致性和準確性。同時,它具備數據質量監控和校驗機制,及時糾正問題,提升數據質量。
 降低數據管理成本:數據倉庫集中存儲管理數據,避免重復采集和存儲,降低管理成本。它還提供統一訪問接口和查詢工具,簡化流程,提高效率。
降低數據管理成本:數據倉庫集中存儲管理數據,避免重復采集和存儲,降低管理成本。它還提供統一訪問接口和查詢工具,簡化流程,提高效率。
 支持企業決策制定:數據倉庫是企業決策的重要支撐工具。通過數據分析和挖掘功能,企業可以深入了解市場趨勢、客戶需求和內部運營情況,為戰略決策和業務優化提供支持。同時,數據倉庫支持多種數據可視化工具,直觀呈現分析結果,幫助用戶更好地理解數據和做出決策。
支持企業決策制定:數據倉庫是企業決策的重要支撐工具。通過數據分析和挖掘功能,企業可以深入了解市場趨勢、客戶需求和內部運營情況,為戰略決策和業務優化提供支持。同時,數據倉庫支持多種數據可視化工具,直觀呈現分析結果,幫助用戶更好地理解數據和做出決策。
 提升企業競爭力:在市場競爭中,企業需不斷創新和優化業務模式。數據倉庫提供全面的數據支持和強大的分析能力,幫助企業發現新商機和潛在風險,為創新和發展提供支持。它還能優化業務流程、提高運營效率、降低成本,從而提升企業競爭力。
提升企業競爭力:在市場競爭中,企業需不斷創新和優化業務模式。數據倉庫提供全面的數據支持和強大的分析能力,幫助企業發現新商機和潛在風險,為創新和發展提供支持。它還能優化業務流程、提高運營效率、降低成本,從而提升企業競爭力。
 保障數據安全性和可靠性:數據安全性和可靠性至關重要。數據倉庫采用加密、備份和恢復等技術,確保數據在存儲和傳輸中的安全。同時提供訪問控制和審計機制,防止未授權訪問和數據泄露。
保障數據安全性和可靠性:數據安全性和可靠性至關重要。數據倉庫采用加密、備份和恢復等技術,確保數據在存儲和傳輸中的安全。同時提供訪問控制和審計機制,防止未授權訪問和數據泄露。
總之,建設數據倉庫對企業發展具有重要意義。它幫助企業滿足復雜數據分析需求,提高數據質量,降低成本,支持決策,提升競爭力,保障數據安全。企業應重視數據倉庫的建設與管理,不斷優化體系,以實現可持續和創新發展。
數據倉庫是什么?
 定義
定義
數據倉庫之父比爾·恩門(Bill Inmon)在1991年出版的(Building the Data Warehouse)(《建立數據倉庫》)一書中所提出的定義被廣泛接受,數據倉庫是一個面向主題的(Subject Oriented)、集成的(Integrate)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的數據集合,用于支持管理決策。
特點
面向主題:數據倉庫將企業信息系統的數據進行高層次的綜合與歸并,形成主題。每個主題對應特定的分析決策,實現數據的抽象與分析利用。
集成性:數據倉庫集成企業級數據,確保其一致性、完整性、有效性與精確性。它通過抽取、清理、加工、匯總和整理原有分散數據庫的數據,消除源數據中的不一致性,提供統一、準確的全局信息。
相對穩定:數據倉庫的數據主要供決策分析使用,以查詢為主,極少進行修改和刪除。數據一旦進入,通常會被長期保留,只需定期加載和刷新。
反映歷史變化:數據倉庫包含豐富的歷史信息,記錄企業從過去某一時點到現在的各個階段數據。借助這些數據,可深入分析企業的發展歷程,并對未來趨勢做出精準預測。
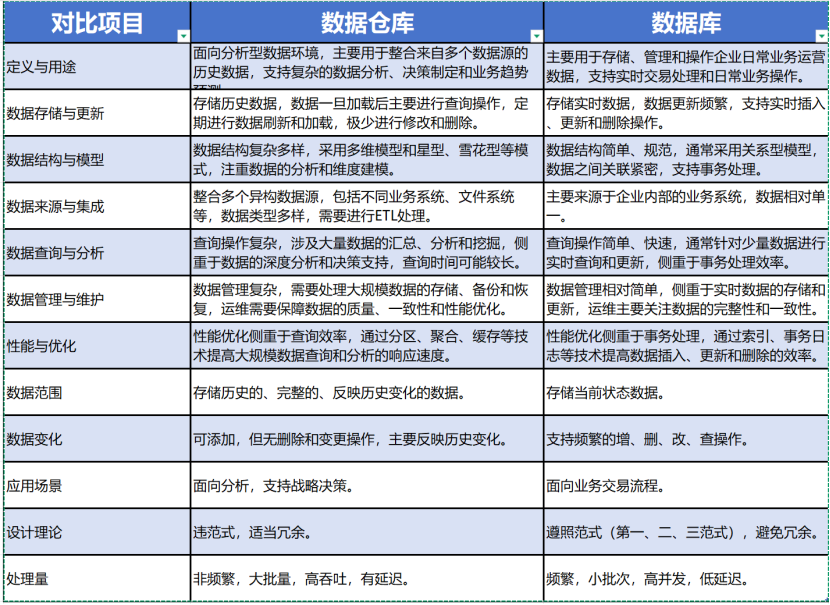
數據倉庫與數據庫的區別
 數據倉庫的發展歷程
數據倉庫的發展歷程
 20世紀70年代:數據倉庫技術萌芽,隨著企業數據需求增加,傳統數據庫和文件系統難滿足復雜分析需求,人們開始研究構建以分析為導向的存儲系統。
20世紀70年代:數據倉庫技術萌芽,隨著企業數據需求增加,傳統數據庫和文件系統難滿足復雜分析需求,人們開始研究構建以分析為導向的存儲系統。
 20世紀80年代:1988年,IBM研究員Barry Devlin和Paul Murphy提出“商業數據倉庫”概念,旨在整合企業各部門數據用于管理決策。早期數據倉庫主要依賴關系型數據庫管理系統,如Oracle和IBM DB2,通過ETL過程整合數據,但存在構建成本高、ETL過程復雜、實時性不足等問題。
20世紀80年代:1988年,IBM研究員Barry Devlin和Paul Murphy提出“商業數據倉庫”概念,旨在整合企業各部門數據用于管理決策。早期數據倉庫主要依賴關系型數據庫管理系統,如Oracle和IBM DB2,通過ETL過程整合數據,但存在構建成本高、ETL過程復雜、實時性不足等問題。
 20世紀90年代:1990年代,Bill Inmon提出數據倉庫概念后,相關技術迅速發展。此階段數據倉庫技術關注數據存儲和管理,解決數據一致性和共享問題,通過整合不同業務系統的數據,為企業提供統一數據視圖。同時,ETL工具普及,Inmon和Kimball提出的不同數據倉庫設計方法論也在此時形成。
20世紀90年代:1990年代,Bill Inmon提出數據倉庫概念后,相關技術迅速發展。此階段數據倉庫技術關注數據存儲和管理,解決數據一致性和共享問題,通過整合不同業務系統的數據,為企業提供統一數據視圖。同時,ETL工具普及,Inmon和Kimball提出的不同數據倉庫設計方法論也在此時形成。
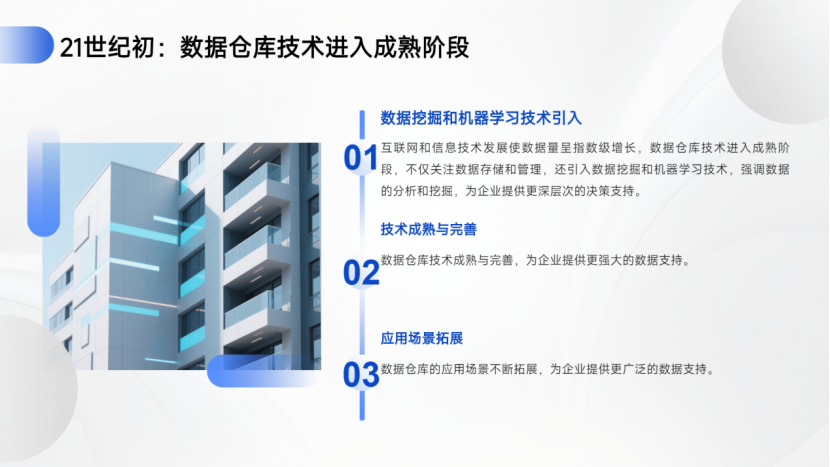 21世紀初:互聯網和信息技術發展使數據量呈指數級增長,數據倉庫技術進入成熟階段,不僅關注數據存儲和管理,還引入數據挖掘和機器學習技術,強調數據的分析和挖掘,為企業提供更深層次的決策支持。
21世紀初:互聯網和信息技術發展使數據量呈指數級增長,數據倉庫技術進入成熟階段,不僅關注數據存儲和管理,還引入數據挖掘和機器學習技術,強調數據的分析和挖掘,為企業提供更深層次的決策支持。
 2010年代:隨著移動互聯網、物聯網的發展,數據量劇增且類型多樣化,大數據技術應運而生。Hadoop、Spark等分布式處理框架出現,使得數據倉庫能夠處理海量數據和實時數據。同時,云數據倉庫如Amazon Redshift、Google BigQuery等開始嶄露頭角,提供了更靈活的擴展能力和更低的成本。
2010年代:隨著移動互聯網、物聯網的發展,數據量劇增且類型多樣化,大數據技術應運而生。Hadoop、Spark等分布式處理框架出現,使得數據倉庫能夠處理海量數據和實時數據。同時,云數據倉庫如Amazon Redshift、Google BigQuery等開始嶄露頭角,提供了更靈活的擴展能力和更低的成本。
 當前及未來:如今,數據倉庫技術已步入智能化階段,與大數據、云計算、人工智能等技術融合,能夠自動處理和分析海量數據,提供精準高效的決策支持。其應用場景不斷拓展,產品也在相互借鑒融合,未來將朝著智能化、融合化的方向發展,成為企業數據資產管理和價值創造的核心引擎。
當前及未來:如今,數據倉庫技術已步入智能化階段,與大數據、云計算、人工智能等技術融合,能夠自動處理和分析海量數據,提供精準高效的決策支持。其應用場景不斷拓展,產品也在相互借鑒融合,未來將朝著智能化、融合化的方向發展,成為企業數據資產管理和價值創造的核心引擎。
| 敬請關注本系列后續內容,與我們一同深入數據倉庫的世界,探索其無限可能!

)



)


)
)

異常深度攻堅:從底層原理到架構級防御,老司機的實戰經驗)
 視頻教程 - 主頁-評論用戶時間占比環形餅狀圖實現)






