環境說明:
現在有一套redis cluster,部署是3主機6實例架構部署。需要采集對應的指標,滿足異常監控告警,性能分析所需。
環境準備
以下環境需要提前部署完成。
redis cluser
prometheus
alertmanager
grafna
redis_exporter部署
我們部署采用docker composer 進行安裝。
采用的redis_exporter為:https://github.com/oliver006/redis_exporter
redis-exporter:image: docker.m.daocloud.io/oliver006/redis_exporter:v1.74.0-alpinecommand:- '--redis.addr=redis://redisIP:7001'- '--redis.password=redisPassword'- '--is-cluster'ports:- "9121:9121"
上面參數,只需要指定--is-cluster,然后指明集群中一個節點,即可獲取所有節點的數據。
prometheus采集配置:
添加prometheus的監控項:
- job_name: 'redis_sjzt_prod'http_sd_configs:- url: http://redisExporterIP:9121/discover-cluster-nodesrefresh_interval: 10mmetrics_path: /scraperelabel_configs:- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: redisExporter:9121
指標查看:
可以看到 prometheus的target中已經存在對應的采集項,并且有集群的所有節點。

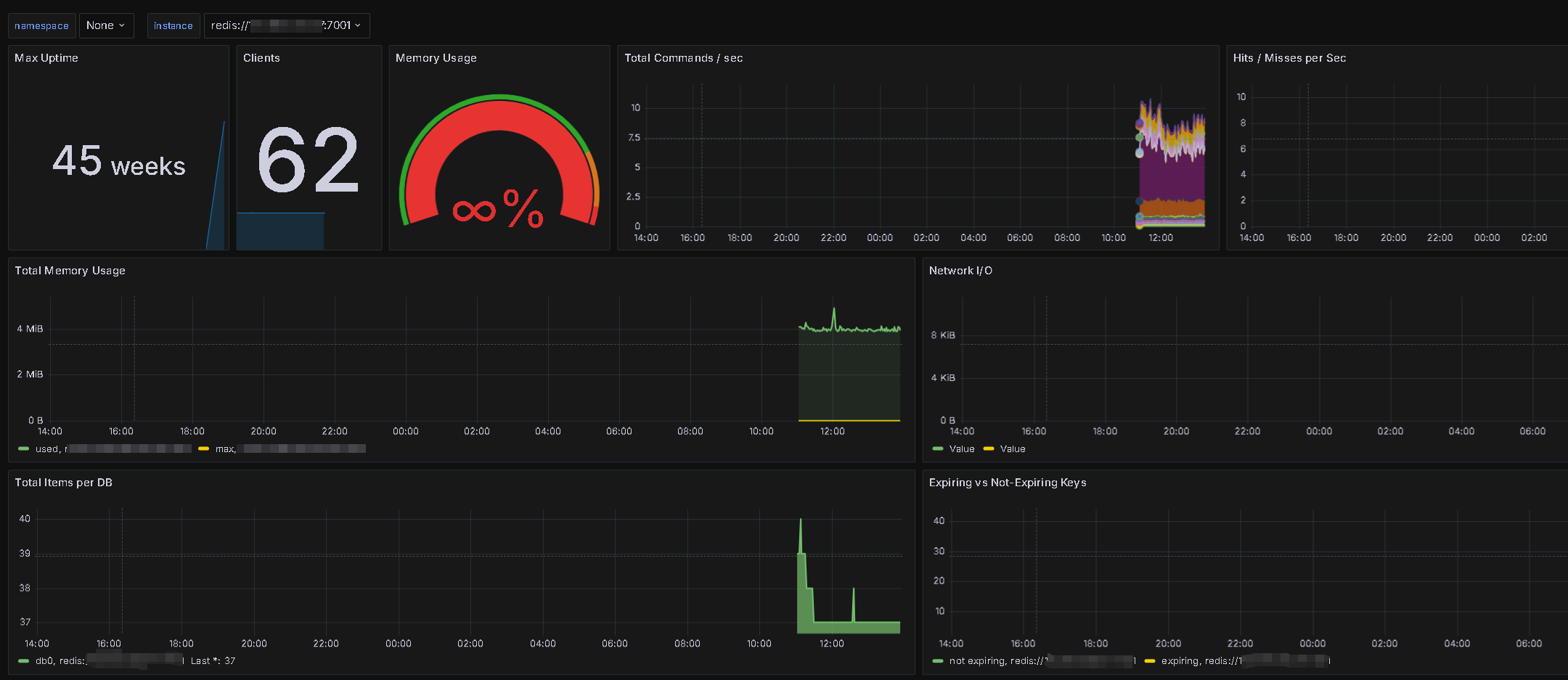
大屏展示:
監控模板:https://grafana.com/grafana/dashboards/763-redis-dashboard-for-prometheus-redis-exporter-1-x/
下載后直接導入,選擇對應的數據源即可。
告警:
現在創建對應的報警規則,實現異常時通知到alertmanager。
使用的告警規則為:https://raw.githubusercontent.com/samber/awesome-prometheus-alerts/master/dist/rules/redis/oliver006-redis-exporter.yml
下載后,加入到prometheus中。
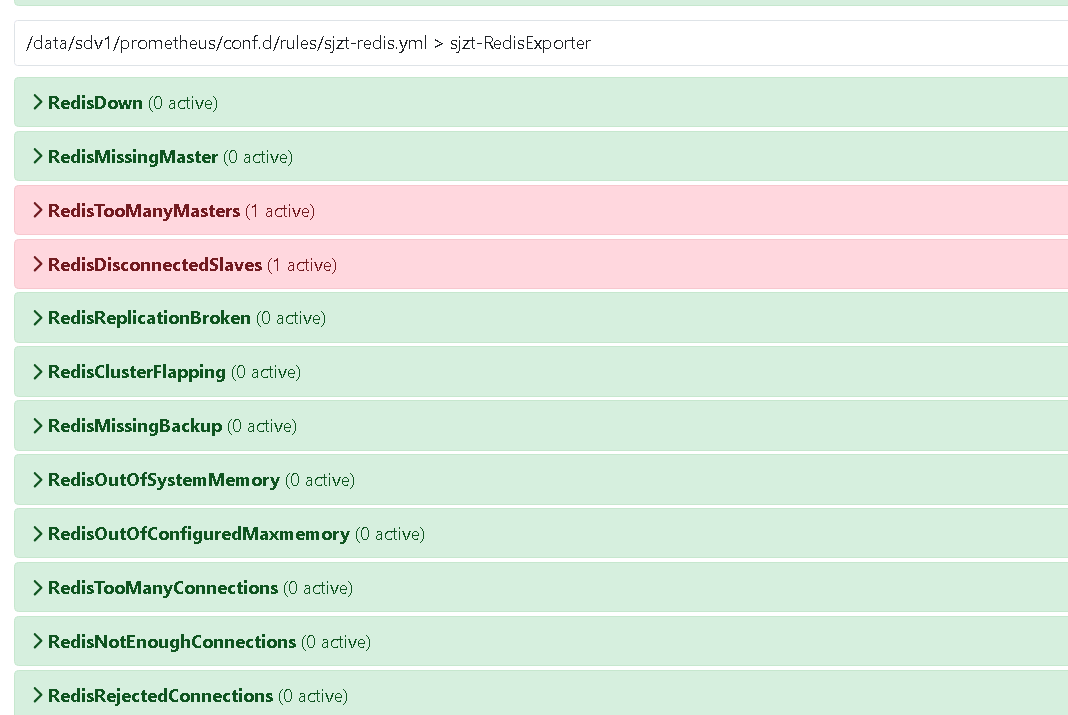
但是因為我們是集群,所以需要修改一些報警規則實現。刪除兩個不適用的報警規則RedisTooManyMasters和RedisDisconnectedSlaves 。修改后內容如下:
vim redis.yml
groups:
- name: Oliver006RedisExporterrules:- alert: RedisDownexpr: 'redis_up == 0'for: 0mlabels:severity: criticalannotations:summary: Redis down (instance {{ $labels.instance }})description: "Redis instance is down\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisMissingMasterexpr: '(count(redis_instance_info{role="master"}) or vector(0)) < 1'for: 0mlabels:severity: criticalannotations:summary: Redis missing master (instance {{ $labels.instance }})description: "Redis cluster has no node marked as master.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisReplicationBrokenexpr: 'delta(redis_connected_slaves[1m]) < 0'for: 0mlabels:severity: criticalannotations:summary: Redis replication broken (instance {{ $labels.instance }})description: "Redis instance lost a slave\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisClusterFlappingexpr: 'changes(redis_connected_slaves[1m]) > 1'for: 2mlabels:severity: criticalannotations:summary: Redis cluster flapping (instance {{ $labels.instance }})description: "Changes have been detected in Redis replica connection. This can occur when replica nodes lose connection to the master and reconnect (a.k.a flapping).\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisMissingBackupexpr: 'time() - redis_rdb_last_save_timestamp_seconds > 60 * 60 * 24'for: 0mlabels:severity: criticalannotations:summary: Redis missing backup (instance {{ $labels.instance }})description: "Redis has not been backuped for 24 hours\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisOutOfSystemMemoryexpr: 'redis_memory_used_bytes / redis_total_system_memory_bytes * 100 > 90'for: 2mlabels:severity: warningannotations:summary: Redis out of system memory (instance {{ $labels.instance }})description: "Redis is running out of system memory (> 90%)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisOutOfConfiguredMaxmemoryexpr: 'redis_memory_used_bytes / redis_memory_max_bytes * 100 > 90 and on(instance) redis_memory_max_bytes > 0'for: 2mlabels:severity: warningannotations:summary: Redis out of configured maxmemory (instance {{ $labels.instance }})description: "Redis is running out of configured maxmemory (> 90%)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisTooManyConnectionsexpr: 'redis_connected_clients / redis_config_maxclients * 100 > 90'for: 2mlabels:severity: warningannotations:summary: Redis too many connections (instance {{ $labels.instance }})description: "Redis is running out of connections (> 90% used)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisNotEnoughConnectionsexpr: 'redis_connected_clients < 5'for: 2mlabels:severity: warningannotations:summary: Redis not enough connections (instance {{ $labels.instance }})description: "Redis instance should have more connections (> 5)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: RedisRejectedConnectionsexpr: 'increase(redis_rejected_connections_total[1m]) > 0'for: 0mlabels:severity: criticalannotations:summary: Redis rejected connections (instance {{ $labels.instance }})description: "Some connections to Redis has been rejected\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
重新加載prometheus的配置
curl -X POST http://localhost:9090/-/reload
檢查對應的報警項是否已經添加進去了。訪問prometheus 點擊Alerts。進行查看如下所示:
說明:監控指標需要按照實際項目需要進行仔細考慮。以上只是參考。
)
)



)



)


)
)

異常深度攻堅:從底層原理到架構級防御,老司機的實戰經驗)
 視頻教程 - 主頁-評論用戶時間占比環形餅狀圖實現)


