文章目錄
- 色彩空間轉換
- 目標
- 色彩空間轉換
- 目標追蹤
- 如何確定要追蹤的HSV值?
- 練習
- 圖像的幾何變換
- 目標
- 變換
- 縮放
- 翻譯
- 旋轉
- 仿射變換
- 透視變換
- 其他資源
- 圖像閾值處理
- 目標
- 簡單閾值化
- 自適應閾值化
- 大津二值化法
- Otsu二值化算法原理
- 其他資源
- 練習
- 圖像平滑處理
- 目標
- 二維卷積(圖像濾波)
- 圖像模糊(圖像平滑)
- 1、均值濾波
- 2、高斯模糊
- 3、中值模糊
- 4、雙邊濾波
- 額外資源
- 形態學變換
- 目標
- 理論基礎
- 1、腐蝕操作
- 2、膨脹
- 3、開運算
- 4、閉合操作
- 5、形態學梯度
- 6、高帽變換
- 7、黑帽變換
- 結構元素
- 附加資源
- 圖像梯度
- 目標
- 理論
- 1、Sobel 與 Scharr 導數算子
- 2、拉普拉斯導數
- 代碼
- 一個重要問題!
- Canny邊緣檢測
- 目標
- 理論
- OpenCV 中的 Canny 邊緣檢測
- 其他資源
- 練習
- 圖像金字塔
- 目標
- 理論基礎
- 使用金字塔進行圖像融合
- 附加資源
- OpenCV 中的輪廓
- OpenCV中的直方圖
- OpenCV 中的圖像變換
- 模板匹配
- 目標
- 理論
- OpenCV 中的模板匹配
- 多目標模板匹配
- 霍夫線變換
- 目標
- 理論
- OpenCV中的霍夫變換
- 概率霍夫變換
- 附加資源
- 霍夫圓變換
- 目標
- 理論
- 使用分水嶺算法進行圖像分割
- 目標
- 理論基礎
- 代碼
- 其他資源
- 練習
- 使用GrabCut算法進行交互式前景提取
- 目標
- 理論基礎
- 演示
- 練習
色彩空間轉換
https://docs.opencv.org/4.x/df/d9d/tutorial_py_colorspaces.html
目標
- 在本教程中,您將學習如何將圖像從一種色彩空間轉換到另一種色彩空間,例如 BGR ?\leftrightarrow? 灰度、BGR ?\leftrightarrow? HSV 等。
- 此外,我們將創建一個應用程序來提取視頻中的彩色對象
- 您將學習以下函數:
cv.cvtColor()、cv.inRange()等。
色彩空間轉換
OpenCV 提供了超過 150 種色彩空間轉換方法。但我們主要關注其中最常用的兩種:BGR ?\leftrightarrow? 灰度 和 BGR ?\leftrightarrow? HSV。
進行色彩轉換時,我們使用函數 cv.cvtColor(input_image, flag),其中 flag 參數決定轉換類型。
對于 BGR \(\rightarrow) 灰度轉換,我們使用標志位 cv.COLOR_BGR2GRAY](https://docs.opencv.org/4.x/d8/d01/group__imgproc__color__conversions.html#gga4e0972be5de079fed4e3a10e24ef5ef0a353a4b8db9040165db4dacb5bcefb6ea "在RGB/BGR與灰度之間轉換,色彩空間轉換")。類似地,對于 BGR \\(\\rightarrow\) HSV 轉換,我們使用標志位 [cv.COLOR_BGR2HSV。要獲取其他標志位,只需在 Python 終端中運行以下命令:
>>> import cv2 as cv
>>> flags = [i for i in dir(cv) if i.startswith('COLOR_')]
>>> print( flags )
對于HSV色彩空間,色調(hue)的范圍是[0,179],飽和度(saturation)的范圍是[0,255],明度(value)的范圍是[0,255]。不同軟件采用不同的標度范圍,因此若需將OpenCV的數值與其他軟件進行對比,必須對這些范圍進行歸一化處理。
目標追蹤
既然我們已經知道如何將BGR圖像轉換為HSV色彩空間,接下來可以利用這一技術來提取特定顏色的目標物體。在HSV色彩空間中,顏色表示比BGR空間更為直觀。在本案例中,我們將嘗試提取藍色目標物體。具體方法如下:
- 獲取視頻的每一幀畫面
- 將圖像從BGR色彩空間轉換到HSV色彩空間
- 對HSV圖像進行藍色閾值處理
- 單獨提取藍色目標物體后,即可對該圖像進行任意操作
下方是帶有詳細注釋的代碼實現:
import cv2 as cv
import numpy as npcap = cv.VideoCapture(0)while(1):# Take each frame_, frame = cap.read()# Convert BGR to HSVhsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)# define range of blue color in HSVlower_blue = np.array([110,50,50])upper_blue = np.array([130,255,255])# Threshold the HSV image to get only blue colorsmask = cv.inRange(hsv, lower_blue, upper_blue)# Bitwise-AND mask and original imageres = cv.bitwise_and(frame,frame, mask= mask)cv.imshow('frame',frame)cv.imshow('mask',mask)cv.imshow('res',res)k = cv.waitKey(5) & 0xFFif k == 27:breakcv.destroyAllWindows()
下圖展示了藍色物體的追蹤效果:

注意:圖像中存在一些噪點,我們將在后續章節中學習如何消除它們。
這是物體追蹤中最簡單的方法。一旦掌握了輪廓函數的使用,你可以實現許多功能,例如找到物體的質心并用它來追蹤物體、通過在攝像頭前移動手部來繪制圖形等有趣的操作。
如何確定要追蹤的HSV值?
這是一個在stackoverflow.com上常見的問題。解決方法非常簡單,你可以使用相同的函數cv.cvtColor()`。你不需要傳入圖像,只需傳入所需的BGR值即可。例如,要查找綠色的HSV值,可以在Python終端中嘗試以下命令:
>>> green = np.uint8([[[0,255,0 ]]])
>>> hsv_green = cv.cvtColor(green,cv.COLOR_BGR2HSV)
>>> print( hsv_green )
[[[ 60 255 255]]]
現在,您將[H-10, 100,100]和[H+10, 255, 255]分別作為下限和上限。除了這種方法,您還可以使用GIMP等圖像編輯工具或任何在線轉換器來查找這些值,但別忘了調整HSV范圍。
練習
1、嘗試找到一種方法同時提取多個彩色物體,例如一次性提取紅色、藍色和綠色物體。
生成于 2025年4月30日 星期三 23:08:42,適用于 OpenCV,由 doxygen 1.12.0 生成
圖像的幾何變換
https://docs.opencv.org/4.x/da/d6e/tutorial_py_geometric_transformations.html
目標
- 學習如何對圖像應用不同的幾何變換,如平移、旋轉、仿射變換等。
- 你將了解以下函數:
cv.getPerspectiveTransform
變換
OpenCV 提供了兩個變換函數:cv.warpAffine 和 cv.warpPerspective,通過它們可以實現各種類型的變換。cv.warpAffine 接收一個 2x3 的變換矩陣作為輸入,而 cv.warpPerspective 則需要一個 3x3 的變換矩陣。
縮放
縮放即調整圖像尺寸。OpenCV提供了 cv.resize() 函數實現這一功能。您既可以手動指定目標尺寸,也可以設置縮放比例系數。該操作支持多種插值方法:
- 縮小圖像時推薦使用
cv.INTER_AREA - 放大圖像建議選擇
cv.INTER_CUBIC(速度較慢)或cv.INTER_LINEAR
默認情況下,所有縮放操作均采用 cv.INTER_LINEAR 插值方法。您可以通過以下任一方式調整輸入圖像尺寸:
import numpy as np
import cv2 as cvimg = cv.imread('messi5.jpg')
assert img is not None, "file could not be read, check with os.path.exists()"res = cv.resize(img,None,fx=2, fy=2, interpolation = cv.INTER_CUBIC)#ORheight, width = img.shape[:2]
res = cv.resize(img,(2*width, 2*height), interpolation = cv.INTER_CUBIC)
翻譯
平移是指改變物體的位置。如果已知物體在(x,y)方向的位移量\((t_x,t_y)\),可以按以下方式構建變換矩陣\(\textbf{M}\):
111111 111
你可以將其轉換為np.float32類型的Numpy數組,并傳入**cv.warpAffine()**函數。以下示例展示了(100,50)位移量的實現:
import numpy as np
import cv2 as cvimg = cv.imread('messi5.jpg', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
rows,cols = img.shapeM = np.float32([[1,0,100],[0,1,50]])
dst = [cv.warpAffine`](https://docs.opencv.org/4.x/da/d54/group__imgproc__transform.html#ga0203d9ee5fcd28d40dbc4a1ea4451983)(img,M,(cols,rows))cv.imshow('img',dst)
cv.waitKey((0)
cv.destroyAllWindows()
警告
cv.warpAffine() 函數的第三個參數是輸出圖像的尺寸,其格式應為 (寬度, 高度)。請注意:寬度 = 列數,高度 = 行數。
效果如下圖所示:

旋轉
圖像旋轉角度 \(\theta\) 可通過以下形式的變換矩陣實現:
\[M = \begin{bmatrix} cos\theta & -sin\theta \\ sin\theta & cos\theta \end{bmatrix}\]
但 OpenCV 提供了可調整旋轉中心的縮放旋轉功能,允許在任意指定位置進行旋轉。修正后的變換矩陣為:
\[\begin{bmatrix} \alpha & \beta & (1- \alpha ) \cdot center.x - \beta \cdot center.y \\ - \beta & \alpha & \beta \cdot center.x + (1- \alpha ) \cdot center.y \end{bmatrix}\]
其中:
\[\begin{array}{l} \alpha = scale \cdot \cos \theta , \\ \beta = scale \cdot \sin \theta \end{array}\]
OpenCV 提供了 cv.getRotationMatrix2D 函數來計算該變換矩陣。參考以下示例,該示例將圖像繞中心旋轉90度且不進行縮放。
img = cv.imread('messi5.jpg', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
rows,cols = img.shape# cols-1 and rows-1 are the coordinate limits.
M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,1)
dst = cv.warpAffine(img,M,(cols,rows))
查看結果:

仿射變換
在仿射變換中,原始圖像中的所有平行線在輸出圖像中仍保持平行。要計算變換矩陣,我們需要從輸入圖像中選取三個點及其在輸出圖像中的對應位置。然后 cv.getAffineTransform 會生成一個2x3矩陣,該矩陣將被傳遞給 cv.warpAffine。
查看以下示例,并注意我選擇的點(這些點已用綠色標記):
img = cv.imread('drawing.png')
assert img is not None, "file could not be read, check with os.path.exists()"
rows,cols,ch = img.shapepts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])M = cv.getAffineTransform(pts1,pts2)dst = cv.warpAffine(img,M,(cols,rows))plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()
查看結果:
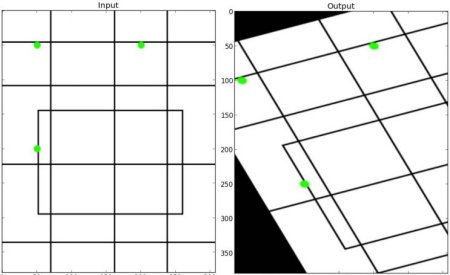
透視變換
要實現透視變換,需要一個3x3的變換矩陣。即使在變換后,直線仍將保持直線狀態。要找到這個變換矩陣,需要在輸入圖像上指定4個點及其在輸出圖像中對應的位置。這4個點中有3個不能共線。然后可以通過函數 cv.getPerspectiveTransform 求得變換矩陣。接著使用這個3x3變換矩陣應用 cv.warpPerspective。
參考以下代碼:
img = cv.imread('sudoku.png')
assert img is not None, "file could not be read, check with os.path.exists()"
rows,cols,ch = img.shapepts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])M = cv.getPerspectiveTransform(pts1,pts2)dst = cv.warpPerspective(img,M,(300,300))plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()
Result:
其他資源
1、《計算機視覺:算法與應用》,Richard Szeliski
由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,適用于 OpenCV
圖像閾值處理
https://docs.opencv.org/4.x/d7/d4d/tutorial_py_thresholding.html
目標
- 本教程中,您將學習簡單閾值處理、自適應閾值處理以及大津閾值法。
- 您將掌握函數
cv.threshold和cv.adaptiveThreshold的使用方法。
簡單閾值化
這里的原理非常直接。對于每個像素,都應用相同的閾值。如果像素值小于或等于閾值,則將其設為0,否則設為最大值。函數 cv.threshold 用于實現閾值化處理。第一個參數是源圖像,必須是灰度圖像。第二個參數是用于分類像素值的閾值。第三個參數是當像素值超過閾值時賦予的最大值。OpenCV 提供了不同類型的閾值化方法,通過函數的第四個參數指定。上文描述的基本閾值化通過類型 cv.THRESH_BINARY 實現。所有簡單閾值化類型包括:
cv.THRESH_BINARYcv.THRESH_BINARY_INVcv.THRESH_TRUNCcv.THRESH_TOZEROcv.THRESH_TOZERO_INV
具體差異請參閱各類型的文檔說明。
該方法返回兩個輸出值:第一個是實際使用的閾值,第二個輸出是經過閾值處理的圖像。
以下代碼演示了不同簡單閾值化類型的比較效果:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as pltimg = cv.imread('gradient.png', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)
ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)
ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)
ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]for i in range(6):plt.subplot(2,3,i+1),plt.imshow(images[i],'gray',vmin=0,vmax=255)plt.title(titles[i])plt.xticks([]),plt.yticks([])plt.show()
注意:要繪制多張圖像,我們使用了 plt.subplot() 函數。更多詳情請查閱 matplotlib 文檔。
代碼運行結果如下:

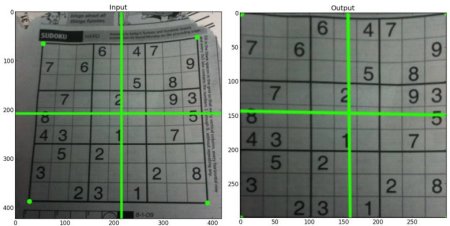
自適應閾值化
在前一節中,我們使用單一全局值作為閾值。但這可能不適用于所有情況,例如當圖像不同區域存在不同光照條件時。此時,自適應閾值化就能發揮作用。該算法會根據像素周圍的小區域來確定其閾值。因此,同一圖像的不同區域會獲得不同閾值,從而在光照不均的圖像上取得更好效果。
除了前文所述的參數外,方法 cv.adaptiveThreshold` 還接收三個輸入參數:
adaptiveMethod 決定閾值計算方式:
- cv.ADAPTIVE_THRESH_MEAN_C`:閾值為鄰域平均值減去常數 C
- cv.ADAPTIVE_THRESH_GAUSSIAN_C`:閾值為鄰域值的高斯加權和減去常數 C
blockSize 決定鄰域區域的大小,C 是從鄰域像素均值或加權和中減去的常數。
以下代碼對比了全局閾值化和自適應閾值化在光照不均圖像上的效果:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as pltimg = cv.imread('sudoku.png', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
img = cv.medianBlur(img,5)ret,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
th2 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_MEAN_C,\cv.THRESH_BINARY,11,2)
th3 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,\cv.THRESH_BINARY,11,2)titles = ['Original Image', 'Global Thresholding (v = 127)','Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, th1, th2, th3]for i in range(4):plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')plt.title(titles[i])plt.xticks([]),plt.yticks([])
plt.show()
Result:

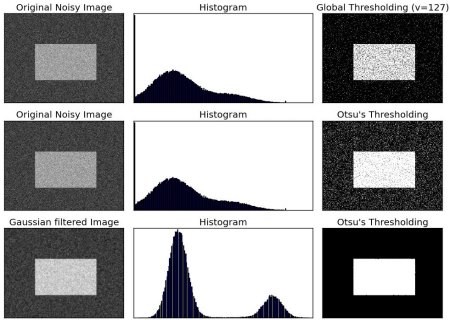
大津二值化法
在全局閾值處理中,我們通常隨意選擇一個值作為閾值。而大津法則無需手動選擇,能夠自動確定最佳閾值。
設想一張僅包含兩種不同像素值的圖像(雙峰圖像),其直方圖會呈現兩個明顯的波峰。理想的閾值應位于這兩個波峰之間的谷底。大津法正是通過分析圖像直方圖,計算出最優的全局閾值。
具體實現時,需要使用 cv.threshold() 函數,并額外傳入 cv.THRESH_OTSU 標志。此時可以隨意指定初始閾值參數,算法會自動計算最優閾值并通過第一個返回值輸出。
參考以下示例:輸入圖像含有噪聲。第一種情況采用固定閾值127進行全局二值化;第二種情況直接應用大津閾值法;第三種情況先用5x5高斯核濾波去噪,再執行大津閾值處理。注意觀察噪聲過濾如何顯著改善二值化效果。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as pltimg = cv.imread('noisy2.png', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"# global thresholding
ret1,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)# Otsu's thresholding
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)# Otsu's thresholding after Gaussian filtering
blur = cv.GaussianBlur(img,(5,5),0)
ret3,th3 = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)# plot all the images and their histograms
images = [img, 0, th1,img, 0, th2,blur, 0, th3]
titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)','Original Noisy Image','Histogram',"Otsu's Thresholding",'Gaussian filtered Image','Histogram',"Otsu's Thresholding"]for i in range(3):plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show()
Result:
Otsu二值化算法原理
本節通過Python實現演示Otsu二值化的實際工作原理。若不感興趣可直接跳過。
針對雙峰圖像,Otsu算法的核心是尋找使加權類內方差最小化的閾值(t),其數學關系表示為:
\[\sigma_w^2(t) = q_1(t)\sigma_12(t)+q_2(t)\sigma_22(t)\]
其中
\[q_1(t) = \sum_{i=1}^{t} P(i) \quad \& \quad q_2(t) = \sum_{i=t+1}^{I} P(i)\]
\[\mu_1(t) = \sum_{i=1}^{t} \frac{iP(i)}{q_1(t)} \quad \& \quad \mu_2(t) = \sum_{i=t+1}^{I} \frac{iP(i)}{q_2(t)}\]
\[\sigma_1^2(t) = \sum_{i=1}^{t} [i-\mu_1(t)]^2 \frac{P(i)}{q_1(t)} \quad \& \quad \sigma_2^2(t) = \sum_{i=t+1}^{I} [i-\mu_2(t)]^2 \frac{P(i)}{q_2(t)}\]
該算法實質是尋找位于雙峰之間的t值,使得兩個類別的方差都達到最小。Python實現代碼如下:
img = cv.imread('noisy2.png', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
blur = cv.GaussianBlur(img,(5,5),0)# find normalized_histogram, and its cumulative distribution function
hist = cv.calcHist([blur],[0],None,[256],[0,256])
hist_norm = hist.ravel()/hist.sum()
Q = hist_norm.cumsum()bins = np.arange(256)fn_min = np.inf
thresh = -1for i in range(1,256):p1,p2 = np.hsplit(hist_norm,[i]) # probabilitiesq1,q2 = Q[i],Q[255]-Q[i] # cum sum of classesif q1 < 1.e-6 or q2 < 1.e-6:continueb1,b2 = np.hsplit(bins,[i]) # weights# finding means and variancesm1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2# calculates the minimization functionfn = v1*q1 + v2*q2if fn < fn_min:fn_min = fnthresh = i# find otsu's threshold value with OpenCV function
ret, otsu = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
print( "{} {}".format(thresh,ret) )
其他資源
1、《數字圖像處理》,Rafael C. Gonzalez
練習
1、Otsu二值化算法存在一些可優化的地方。你可以搜索并實現這些優化方法。
由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,用于 OpenCV
圖像平滑處理
https://docs.opencv.org/4.x/d4/d13/tutorial_py_filtering.html
目標
學習如何:
- 使用各種低通濾波器對圖像進行模糊處理
- 將自定義濾波器應用于圖像(二維卷積)
二維卷積(圖像濾波)
與一維信號類似,圖像也可以通過各類低通濾波器(LPF)、高通濾波器(HPF)等進行濾波處理。低通濾波器可用于消除噪聲、模糊圖像等,而高通濾波器則有助于檢測圖像邊緣。
OpenCV提供了 cv.filter2D() 函數來實現內核與圖像的卷積運算。例如,我們可以對圖像嘗試平均濾波器。一個5x5的平均濾波器內核如下所示:
\[K = \frac{1}{25} \begin{bmatrix} 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 \end{bmatrix}\]
該運算的工作原理是:將內核覆蓋在某個像素上,對內核覆蓋的25個像素值求和后取平均值,并用該平均值替換中心像素值。此操作將在圖像所有像素上重復執行。請嘗試以下代碼并觀察效果:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('opencv_logo.png')
assert img is not None, "file could not be read, check with os.path.exists()"kernel = np.ones((5,5),np.float32)/25
dst = cv.filter2D(img,-1,kernel)plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(dst),plt.title('Averaging')
plt.xticks([]), plt.yticks([])
plt.show()
Result:

圖像模糊(圖像平滑)
圖像模糊是通過將圖像與低通濾波器核進行卷積實現的。這種方法能有效去除噪聲,實際上它會移除圖像中的高頻內容(例如噪聲、邊緣)。因此在此操作中邊緣會略微模糊(也存在不模糊邊緣的模糊技術)。OpenCV提供了四種主要的模糊技術類型。
1、均值濾波
通過對圖像進行歸一化盒式濾波卷積實現。該方法會計算核區域內所有像素的平均值,并用該值替換中心元素。可通過函數 cv.blur() 或 cv.boxFilter() 實現。關于卷積核的更多細節請查閱文檔。需要指定核的寬度和高度,3x3歸一化盒式濾波核如下所示:
\[K = \frac{1}{9} \begin{bmatrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{bmatrix}\]
注意:若需使用非歸一化盒式濾波,請調用 cv.boxFilter() 并傳入參數 normalize=False。
下方演示了使用5x5核的示例效果:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as pltimg = cv.imread('opencv-logo-white.png')
assert img is not None, "file could not be read, check with os.path.exists()"blur = cv.blur(img,(5,5))plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
**
Result:

**
2、高斯模糊
在這種方法中,我們使用高斯核代替了盒式濾波器。該操作通過函數 cv.GaussianBlur() 實現。需要指定核的寬度和高度,這兩個值必須是正奇數。同時還需分別指定X和Y方向的標準差sigmaX和sigmaY。如果僅指定sigmaX,則sigmaY將與sigmaX取值相同。若兩者都設為零,則會根據核尺寸自動計算標準差。高斯模糊能高效消除圖像中的高斯噪聲。
如需創建高斯核,可以使用函數 cv.getGaussianKernel()。
上述代碼可修改為高斯模糊實現:
blur = cv.GaussianBlur(img,(5,5),0)
**
Result:

**
3、中值模糊
這里,函數 cv.medianBlur() 會計算核區域內所有像素的中值,并將中心元素替換為該中值。這種方法對圖像中的椒鹽噪聲特別有效。有趣的是,在上述濾波器中,中心元素是一個新計算的值,可能是圖像中的某個像素值或新生成的值。但在中值模糊中,中心元素總是被圖像中的某個像素值替換,從而有效降低噪聲。其核大小應為正奇數。
在本演示中,我給原始圖像添加了50%的噪聲并應用中值模糊。效果如下:
median = cv.medianBlur(img,5)
**
Result:

**
4、雙邊濾波
cv.bilateralFilter() 在去除噪聲的同時能有效保持邊緣銳利,但運算速度比其他濾波器慢。我們已知高斯濾波器會取像素周圍鄰域并計算其高斯加權平均值。這種高斯濾波器僅基于空間距離函數,即在濾波時只考慮鄰近像素,而不考慮像素間是否具有相近的強度值,也不區分像素是否屬于邊緣。因此它會導致邊緣模糊,而這并非我們期望的效果。
雙邊濾波同樣采用基于空間距離的高斯濾波器,但額外引入了一個基于像素差異的高斯濾波器。空間距離的高斯函數確保只有鄰近像素參與模糊計算,而強度差異的高斯函數則保證僅那些與中心像素強度相近的像素才會被納入模糊計算。因此當邊緣像素存在較大強度差異時,該算法能有效保留邊緣特征。
以下示例演示了雙邊濾波的使用方法(具體參數說明請參閱文檔)。
blur = cv.bilateralFilter(img,9,75,75)
結果:

可以看到,表面紋理已經消失,但邊緣仍然保留完好。
額外資源
1、關于雙邊濾波的詳細信息
由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,適用于 OpenCV
形態學變換
https://docs.opencv.org/4.x/d9/d61/tutorial_py_morphological_ops.html
目標
在本章中,
- 我們將學習不同的形態學操作,如腐蝕、膨脹、開運算、閉運算等。
- 我們將了解以下函數:
cv.erode()、
cv.dilate()、
cv.morphologyEx()等。
理論基礎
形態學變換是基于圖像形狀的一些簡單操作,通常應用于二值圖像。這類操作需要兩個輸入參數:原始圖像和被稱為結構元素(structuring element)或內核(kernel)的矩陣,后者決定了運算的性質。最基礎的形態學操作是腐蝕(Erosion)和膨脹(Dilation),其衍生形式如開運算(Opening)、閉運算(Closing)、梯度運算(Gradient)等也具有重要意義。我們將借助下圖逐一講解這些操作:

1、腐蝕操作
腐蝕的基本概念類似于土壤侵蝕,它會逐漸侵蝕前景物體的邊界(通常保持前景為白色)。那么它的作用是什么呢?內核在圖像上滑動(如同二維卷積運算)。原始圖像中的像素點(值為1或0)只有當內核覆蓋下的所有像素都為1時,才會被判定為1,否則該像素會被腐蝕(置為0)。
這意味著,根據內核尺寸的不同,所有靠近邊界的像素都將被舍棄。因此前景物體的厚度或尺寸會減小,或者說圖像中的白色區域會縮減。該操作能有效去除細小白色噪點(如我們在色彩空間章節所見),也可用于分離相連的物體。
這里我將使用一個5x5的全1內核作為示例,讓我們看看實際效果:
import cv2 as cv
import numpy as npimg = cv.imread('j.png', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
kernel = np.ones((5,5),np.uint8)
erosion = cv.erode(img,kernel,iterations = 1)
Result:

2、膨脹
膨脹與腐蝕正好相反。在此操作中,只要內核下至少有一個像素為’1’,該像素元素就會被置為’1’。因此它會增加圖像中的白色區域,或者說前景物體的尺寸會增大。通常在去噪等場景中,腐蝕后會進行膨脹操作。因為腐蝕雖然能消除白色噪點,但同時也會縮小目標物體。通過膨脹處理,由于噪點已被清除不會再現,而目標物體的區域會得到恢復。該操作也適用于連接物體的斷裂部分。
dilation = cv.dilate(img,kernel,iterations = 1)
Result:

3、開運算
開運算實際上是先腐蝕后膨脹的另一種說法。正如前文所述,它在去除噪聲方面非常有效。這里我們使用函數 cv.morphologyEx()。
opening = cv.morphologyEx(img, cv.MORPH_OPEN, kernel)
Result:

4、閉合操作
閉合是開操作的逆過程,先膨脹后腐蝕。該操作適用于消除前景物體內部的小孔洞或物體上的小黑點。
closing = cv.morphologyEx(img, cv.MORPH_CLOSE, kernel)
Result:

5、形態學梯度
它是圖像膨脹與腐蝕之間的差異。
結果將呈現為物體的輪廓。
gradient = cv.morphologyEx(img, cv.MORPH_GRADIENT, kernel)
Result:
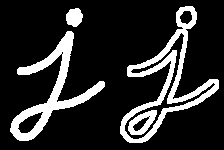
6、高帽變換
這是輸入圖像與圖像開運算之間的差異。以下示例使用9x9核進行處理。
tophat = cv.morphologyEx(img, cv.MORPH_TOPHAT, kernel)
Result:
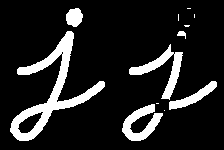
7、黑帽變換
黑帽變換是指輸入圖像的閉運算結果與原輸入圖像之間的差異。
blackhat = cv.morphologyEx(img, cv.MORPH_BLACKHAT, kernel)
Result:
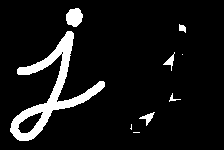
結構元素
在前面的示例中,我們借助Numpy手動創建了一個結構元素。它是矩形形狀的。但在某些情況下,可能需要橢圓形/圓形的核。為此,OpenCV提供了一個函數 cv.getStructuringElement()。只需傳入核的形狀和大小,就能獲得所需的核。
# Rectangular Kernel
>>> cv.getStructuringElement(cv.MORPH_RECT,(5,5))
array([[1, 1, 1, 1, 1],[1, 1, 1, 1, 1],[1, 1, 1, 1, 1],[1, 1, 1, 1, 1],[1, 1, 1, 1, 1]], dtype=uint8)# Elliptical Kernel
>>> cv.getStructuringElement(cv.MORPH_ELLIPSE,(5,5))
array([[0, 0, 1, 0, 0],[1, 1, 1, 1, 1],[1, 1, 1, 1, 1],[1, 1, 1, 1, 1],[0, 0, 1, 0, 0]], dtype=uint8)# Cross-shaped Kernel
>>> cv.getStructuringElement(cv.MORPH_CROSS,(5,5))
array([[0, 0, 1, 0, 0],[0, 0, 1, 0, 0],[1, 1, 1, 1, 1],[0, 0, 1, 0, 0],[0, 0, 1, 0, 0]], dtype=uint8)# Diamond-shaped Kernel
>>> cv.getStructuringElement(cv.MORPH_DIAMOND,(5,5))
array([[0, 0, 1, 0, 0],[0, 1, 1, 1, 0],[1, 1, 1, 1, 1],[0, 1, 1, 1, 0],[0, 0, 1, 0, 0]], dtype=uint8)
附加資源
1、形態學操作 - HIPR2 網站
生成于 2025年4月30日 星期三 23:08:42,使用 doxygen 1.12.0 為 OpenCV 生成
圖像梯度
https://docs.opencv.org/4.x/d5/d0f/tutorial_py_gradients.html
目標
在本章中,我們將學習:
- 如何查找圖像梯度、邊緣等特征
- 我們將了解以下函數:
cv.Sobel()cv.Scharr()cv.Laplacian()
理論
OpenCV 提供了三種類型的梯度濾波器(或稱高通濾波器):Sobel、Scharr 和 Laplacian。我們將逐一探討它們。
1、Sobel 與 Scharr 導數算子
Sobel 算子是一種結合了高斯平滑與微分運算的算子,因此對噪聲具有更強的抵抗能力。您可以通過參數 yorder 和 xorder 分別指定求導方向(垂直或水平)。此外,還可以通過 ksize 參數指定核的大小。當 ksize = -1 時,將使用 3x3 的 Scharr 濾波器,其效果優于 3x3 的 Sobel 濾波器。具體使用的核函數請參閱相關文檔。
2、拉普拉斯導數
它通過關系式 \(\Delta src = \frac{\partial ^2{src}}{\partial x^2} + \frac{\partial ^2{src}}{\partial y^2}\) 計算圖像的拉普拉斯算子,其中每個導數都是使用 Sobel 導數求得的。如果 ksize = 1,則使用以下核進行濾波:
\[kernel = \begin{bmatrix} 0 & 1 & 0 \\ 1 & -4 & 1 \\ 0 & 1 & 0 \end{bmatrix}\]
代碼
下方代碼以單一圖表展示所有算子。所有卷積核尺寸均為5x5。通過將輸出圖像深度設為-1,可獲得np.uint8類型的結果。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('dave.jpg', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"laplacian = cv.Laplacian(img,cv.CV_64F)
sobelx = cv.Sobel(img,cv.CV_64F,1,0,ksize=5)
sobely = cv.Sobel(img,cv.CV_64F,0,1,ksize=5)plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'), plt.xticks([]), plt.yticks([])plt.show()
Result:

一個重要問題!
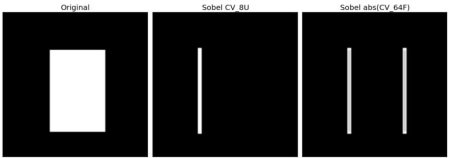
在上一個示例中,輸出數據類型是 cv.CV_8U 或 np.uint8,但這存在一個小問題。黑到白的過渡被視為正斜率(具有正值),而白到黑的過渡被視為負斜率(具有負值)。因此,當將數據轉換為 np.uint8 時,所有負斜率都會變為零。簡單來說,你會丟失這部分邊緣信息。
如果要同時檢測兩種邊緣,更好的選擇是將輸出數據類型保持為更高精度的形式,例如 cv.CV_16S、cv.CV_64F 等,取其絕對值后再轉換回 cv.CV_8U。下面的代碼展示了水平 Sobel 濾波器執行此過程的結果差異。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('box.png', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"# Output dtype = cv.CV_8U
sobelx8u = cv.Sobel(img,cv.CV_8U,1,0,ksize=5)# Output dtype = cv.CV_64F. Then take its absolute and convert to cv.CV_8U
sobelx64f = cv.Sobel(img,cv.CV_64F,1,0,ksize=5)
abs_sobel64f = np.absolute(sobelx64f)
sobel_8u = np.uint8(abs_sobel64f)plt.subplot(1,3,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(1,3,2),plt.imshow(sobelx8u,cmap = 'gray')
plt.title('Sobel CV_8U'), plt.xticks([]), plt.yticks([])
plt.subplot(1,3,3),plt.imshow(sobel_8u,cmap = 'gray')
plt.title('Sobel abs(CV_64F)'), plt.xticks([]), plt.yticks([])plt.show()
檢查以下結果:
Canny邊緣檢測
https://docs.opencv.org/4.x/da/d22/tutorial_py_canny.html
目標
在本章中,我們將學習以下內容:
- Canny邊緣檢測的概念
- 相關的OpenCV函數:
cv.Canny()
理論
Canny邊緣檢測是一種流行的邊緣檢測算法,由John F. Canny開發。該算法包含多個處理階段,我們將逐步解析每個階段。
-
噪聲抑制
由于邊緣檢測容易受到圖像噪聲的影響,首先需要使用5x5高斯濾波器去除噪聲。我們在之前的章節中已經介紹過這種方法。 -
計算圖像強度梯度
平滑后的圖像分別與水平和垂直方向的Sobel核進行卷積,得到水平方向(\(G_x\))和垂直方向(\(G_y\))的一階導數。通過這兩個圖像,可以計算每個像素的邊緣梯度和方向:
梯度方向始終垂直于邊緣,并被量化為代表垂直、水平及兩個對角線方向的四個角度之一。
- 非極大值抑制
獲得梯度幅值和方向后,對圖像進行全掃描以去除可能不構成邊緣的雜散像素。具體操作是:檢查每個像素在其梯度方向鄰域內是否為局部最大值。參考下圖:
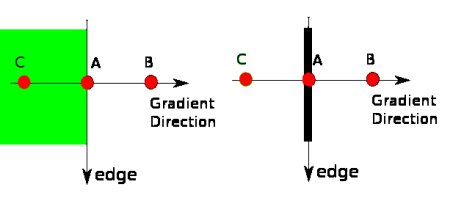
圖中點A位于垂直方向的邊緣上,梯度方向與邊緣垂直。點B和C位于梯度方向上。通過比較點A與B、C的梯度值,若點A是局部最大值則保留,否則被抑制(置零)。最終得到的是具有"細邊緣"的二值圖像。
- 滯后閾值處理
此階段用于判別真實邊緣。需要設置兩個閾值minVal和maxVal:
- 梯度值大于maxVal的像素確定為邊緣
- 低于minVal的像素直接舍棄
- 介于兩者之間的像素,若與"確定邊緣"像素相連則保留,否則舍棄。見下圖:
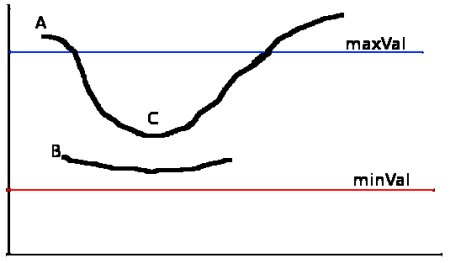
邊緣A超過maxVal被判定為"確定邊緣"。邊緣C雖低于maxVal,但由于連接邊緣A而被保留,從而獲得完整曲線。而邊緣B雖高于minVal且與C同區域,但因未連接任何"確定邊緣"被舍棄。因此合理選擇minVal和maxVal至關重要。此階段還能基于"邊緣是長線"的假設去除小像素噪聲。
最終我們得到的是圖像中清晰的強邊緣輪廓。
OpenCV 中的 Canny 邊緣檢測
OpenCV 將所有上述功能整合到單一函數 cv.Canny() 中。下面介紹其使用方法:
第一個參數是輸入圖像。第二和第三個參數分別對應 minVal 和 maxVal。第四個參數 aperture_size 是用于計算圖像梯度的 Sobel 核尺寸,默認值為 3。最后一個參數 L2gradient 用于指定梯度幅值的計算方式:若設為 True 則采用上文提到的更精確公式;若為 False 則使用以下函數:
Edge_Gradient(G)=∣Gx∣+∣Gy∣)Edge\_Gradient(G) = |G_x| + |G_y| )Edge_Gradient(G)=∣Gx?∣+∣Gy?∣)
默認值為 False。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('messi5.jpg', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
edges = cv.Canny(img,100,200)plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])plt.show()
查看下方結果:

其他資源
1、維基百科上的 Canny邊緣檢測器
2、Bill Green 2002年編寫的 Canny邊緣檢測教程
練習
1、編寫一個小型應用程序,通過兩個滑動條調整閾值參數來實現Canny邊緣檢測。這樣可以幫助你理解閾值參數的影響效果。
由doxygen 1.12.0生成于2025年4月30日星期三23:08:42,用于OpenCV
圖像金字塔
https://docs.opencv.org/4.x/dc/dff/tutorial_py_pyramids.html
目標
在本章中,
- 我們將學習圖像金字塔
- 使用圖像金字塔技術創建一種新水果"Orapple"
- 了解以下函數:
cv.pyrUp()、cv.pyrDown()
理論基礎
通常情況下,我們習慣于處理固定尺寸的圖像。但在某些場景下,需要以不同分辨率處理(同一張)圖像。例如在圖像中搜索特定目標(如人臉)時,我們無法預知目標在圖像中的具體尺寸。此時,就需要生成同一圖像的多分辨率版本,并在所有版本中進行目標搜索。這種由不同分辨率圖像組成的集合稱為圖像金字塔(當把這些圖像按分辨率從高到低堆疊排列時,其形狀類似金字塔)。
圖像金字塔主要分為兩類:1) 高斯金字塔 和 2) 拉普拉斯金字塔
在高斯金字塔中,較高層級(低分辨率)的圖像是通過移除較低層級(高分辨率)圖像中連續的行和列形成的。然后,較高層級中的每個像素值由底層5個像素通過高斯加權計算得到。通過這種方式,一個\(M \times N\)的圖像會降采樣為\(M/2 \times N/2\),面積縮減為原始圖像的四分之一,這個過程稱為一個"八度"(Octave)。隨著金字塔層級的上升(即分辨率降低),這個模式會持續進行。反之在圖像擴展時,每個層級的面積會變為原來的四倍。我們可以使用 cv.pyrDown() 和 cv.pyrUp() 函數來構建高斯金字塔。
img = cv.imread('messi5.jpg')
assert img is not None, "file could not be read, check with os.path.exists()"
lower_reso = cv.pyrDown(higher_reso)

現在你可以使用 cv.pyrUp() 函數來下采樣圖像金字塔。
higher_reso2 = cv.pyrUp(lower_reso)
與原圖進行對比:

拉普拉斯金字塔(Laplacian Pyramids)由高斯金字塔生成,OpenCV并未提供專門函數。拉普拉斯金字塔圖像呈現邊緣特征,其大部分元素值為零,常用于圖像壓縮。每一層拉普拉斯金字塔由對應層高斯金字塔與其上層擴展版本的差值構成。下圖展示了經對比度調整后的三層拉普拉斯金字塔效果(便于觀察內容):

使用金字塔進行圖像融合
金字塔的一個應用是圖像融合。例如,在圖像拼接時,你需要將兩張圖像疊加在一起,但由于圖像間的不連續性,效果可能不理想。這種情況下,使用金字塔進行圖像融合可以實現無縫過渡,同時保留圖像中的大部分數據。
一個經典的例子是橙子和蘋果的圖像融合。現在看看效果,就能理解我的意思:

請查閱附加資源中的第一個參考,那里有關于圖像融合、拉普拉斯金字塔等的完整圖示說明。簡單來說,步驟如下:
- 加載蘋果和橙子的兩張圖像
- 為蘋果和橙子構建高斯金字塔(本例中金字塔層數為6)
- 從高斯金字塔中獲取它們的拉普拉斯金字塔
- 在拉普拉斯金字塔的每一層,將蘋果的左半部分和橙子的右半部分拼接
- 最后從這個拼接后的圖像金字塔重建原始圖像
以下是完整代碼。(為簡單起見,每個步驟分開執行,可能會占用更多內存。如需優化可自行調整)
import cv2 as cv
import numpy as np,sysA = cv.imread('apple.jpg')
B = cv.imread('orange.jpg')
assert A is not None, "file could not be read, check with os.path.exists()"
assert B is not None, "file could not be read, check with os.path.exists()"# generate Gaussian pyramid for A
G = A.copy()
gpA = [G]
for i in range(6):G = cv.pyrDown(G)gpA.append(G)# generate Gaussian pyramid for B
G = B.copy()
gpB = [G]
for i in range(6):G = cv.pyrDown(G)gpB.append(G)# generate Laplacian Pyramid for A
lpA = [gpA[5]]
for i in range(5,0,-1):GE =cv.pyrUp(gpA[i])L = cv.subtract(gpA[i-1],GE)lpA.append(L)# generate Laplacian Pyramid for B
lpB = [gpB[5]]
for i in range(5,0,-1):GE =cv.pyrUp(gpB[i])L = cv.subtract(gpB[i-1],GE)lpB.append(L)# Now add left and right halves of images in each level
LS = []
for la,lb in zip(lpA,lpB):rows,cols,dpt = la.shapels = np.hstack((la[:,0:cols//2], lb[:,cols//2:]))LS.append(ls)# now reconstruct
ls_ = LS[0]
for i in range(1,6):ls_ =cv.pyrUp(ls_)ls_ = cv.add(ls_, LS[i])# image with direct connecting each half
real = np.hstack((A[:,:cols//2],B[:,cols//2:])) cv.imwrite('Pyramid_blending2.jpg',ls_)
cv.imwrite('Direct_blending.jpg',real)附加資源
1、圖像融合
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 為 OpenCV 創建
OpenCV 中的輪廓
https://docs.opencv.org/4.x/d3/d05/tutorial_py_table_of_contents_contours.html
- 輪廓:入門指南
學習如何查找和繪制輪廓
- 輪廓特征
學習輪廓的不同特征,如面積、周長、外接矩形等
- 輪廓屬性
學習輪廓的不同屬性,如堅實度、平均強度等
- 輪廓:更多功能
學習如何查找凸性缺陷、點多邊形測試、匹配不同形狀等
- 輪廓層級
了解輪廓層級結構
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 為 OpenCV 生成
OpenCV中的直方圖
https://docs.opencv.org/4.x/de/db2/tutorial_py_table_of_contents_histograms.html
- 直方圖 - 1:查找、繪制、分析!!!
學習直方圖的基礎知識
- 直方圖 - 2:直方圖均衡化
學習如何通過直方圖均衡化來提升圖像的對比度
- 直方圖 - 3:二維直方圖
學習如何查找并繪制二維直方圖
- 直方圖 - 4:直方圖反向投影
學習使用直方圖反向投影技術來分割彩色物體
生成于 2025年4月30日 星期三 23:08:42,適用于 OpenCV,由 doxygen 1.12.0 生成
OpenCV 中的圖像變換
https://docs.opencv.org/4.x/dd/dc4/tutorial_py_table_of_contents_transforms.html
- 傅里葉變換` 學習如何獲取圖像的傅里葉變換
生成于 2025年4月30日 星期三 23:08:43 由 doxygen 1.12.0 為 OpenCV 生成
模板匹配
https://docs.opencv.org/4.x/d4/dc6/tutorial_py_template_matching.html
目標
在本章中,你將學習:
- 如何使用模板匹配在圖像中查找對象
- 了解以下函數:
cv.matchTemplate()
cv.minMaxLoc()
(注:保留所有代碼函數名及鏈接原格式,僅翻譯描述性文本部分)
理論
模板匹配是一種在較大圖像中搜索并定位模板圖像位置的方法。OpenCV為此提供了**cv.matchTemplate()**函數。該函數的工作原理是:將模板圖像在輸入圖像上滑動(類似于二維卷積操作),并比較模板圖像與輸入圖像對應區域的相似度。OpenCV實現了多種比較方法(具體細節可查閱文檔)。函數會返回一個灰度圖像,其中每個像素值表示該像素鄰域與模板的匹配程度。
若輸入圖像的尺寸為(WxH),模板圖像的尺寸為(wxh),則輸出圖像的尺寸將為(W-w+1, H-h+1)。獲取結果后,可通過**cv.minMaxLoc()**函數定位最大值/最小值的位置。將該位置作為矩形的左上角坐標,并以(w,h)作為矩形的寬高,此矩形即為模板匹配的目標區域。
注意:若使用cv.TM_SQDIFF作為比較方法,則最小值表示最佳匹配。
OpenCV 中的模板匹配
這里我們以在梅西照片中搜索他的臉部為例。我創建了如下模板:

我們將嘗試所有比較方法,以便觀察它們的結果差異:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as pltimg = cv.imread('messi5.jpg', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
img2 = img.copy()
template = cv.imread('template.jpg', cv.IMREAD_GRAYSCALE)
assert template is not None, "file could not be read, check with os.path.exists()"
w, h = template.shape[::-1]# All the 6 methods for comparison in a list
methods = ['TM_CCOEFF', 'TM_CCOEFF_NORMED', 'TM_CCORR','TM_CCORR_NORMED', 'TM_SQDIFF', 'TM_SQDIFF_NORMED']for meth in methods:img = img2.copy()method = getattr(cv, meth)# Apply template Matchingres = cv.matchTemplate(img,template,method)min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimumif method in [cv.TM_SQDIFF, cv.TM_SQDIFF_NORMED]:top_left = min_locelse:top_left = max_locbottom_right = (top_left[0] + w, top_left[1] + h)cv.rectangle(img,top_left, bottom_right, 255, 2)plt.subplot(121),plt.imshow(res,cmap = 'gray')plt.title('Matching Result'), plt.xticks([]), plt.yticks([])plt.subplot(122),plt.imshow(img,cmap = 'gray')plt.title('Detected Point'), plt.xticks([]), plt.yticks([])plt.suptitle(meth)plt.show()
查看以下結果:
- cv.TM_CCOEFF`

- cv.TM_CCOEFF_NORMED`

- cv.TM_CCORR`

- cv.TM_CCORR_NORMED`

- cv.TM_SQDIFF`

- cv.TM_SQDIFF_NORMED`

可以看到,使用 cv.TM_CCORR 得到的結果并不如預期理想。
多目標模板匹配
在前一節中,我們在圖像中搜索梅西的面部(該圖像中僅出現一次)。假設您要搜索具有多個出現位置的目標對象,cv.minMaxLoc() 將無法提供所有位置信息。這種情況下,我們需要使用閾值處理技術。在本示例中,我們將使用著名游戲 Mario 的截圖,并嘗試找出其中的金幣。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as pltimg_rgb = cv.imread('mario.png')
assert img_rgb is not None, "file could not be read, check with os.path.exists()"
img_gray = cv.cvtColor(img_rgb, cv.COLOR_BGR2GRAY)
template = cv.imread('mario_coin.png', cv.IMREAD_GRAYSCALE)
assert template is not None, "file could not be read, check with os.path.exists()"
w, h = template.shape[::-1]res = cv.matchTemplate(img_gray,template,cv.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):cv.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)cv.imwrite('res.png',img_rgb)
結果:
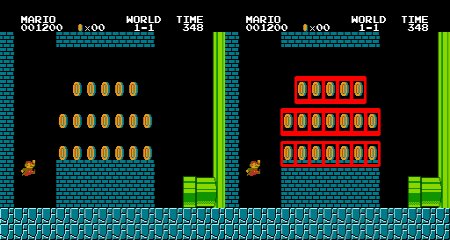
生成于2025年4月30日 星期三 23:08:42,使用doxygen 1.12.0為OpenCV生成
霍夫線變換
https://docs.opencv.org/4.x/d6/d10/tutorial_py_houghlines.html
目標
在本章中,
- 我們將理解霍夫變換的概念
- 學習如何使用它來檢測圖像中的直線
- 了解以下函數:
cv.HoughLines()、cv.HoughLinesP()
理論
霍夫變換是一種流行的形狀檢測技術,只要能用數學形式表示該形狀即可使用。即使形狀有斷裂或輕微變形,它也能檢測出來。我們將以直線為例說明其工作原理。
直線可以用方程 \(y = mx+c\) 表示,也可以用參數形式 \(\rho = x \cos \theta + y \sin \theta\) 表示。其中,\(\rho\) 是原點到直線的垂直距離,\(\theta\) 是該垂直線與水平軸按逆時針方向測量的夾角(具體方向取決于坐標系表示方式,OpenCV 采用此表示法)。如下圖所示:
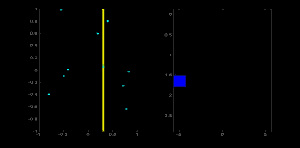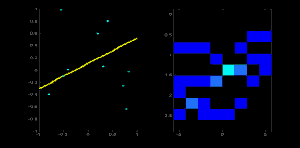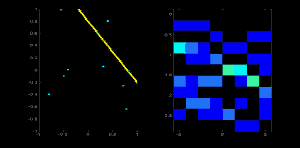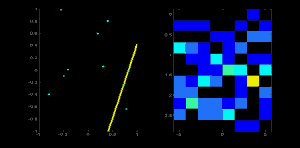
若直線穿過原點下方,則 \(\rho\) 為正且角度小于 180 度;若直線穿過原點上方,則角度仍取小于 180 度的值,但 \(\rho\) 為負。垂直線的角度為 0 度,水平線為 90 度。
霍夫變換檢測直線的過程如下:每條直線都可由參數對 \((\rho, \theta)\) 表示。算法首先創建一個初始值為 0 的二維數組(累加器)來存儲這兩個參數。數組的行表示 \(\rho\),列表示 \(\theta\)。數組大小取決于精度需求:若角度精度為 1 度,則需要 180 列;\(\rho\) 的最大可能值為圖像對角線長度,因此行數可取圖像對角線長度(以像素為單位)。
以 100x100 圖像中部的水平線為例:
- 取直線上第一個點,已知其 (x,y) 坐標。將 \(\theta = 0,1,2,…,180\) 代入直線方程計算對應的 \(\rho\),并在累加器的 \((\rho, \theta)\) 對應單元格中累加 1。此時單元格 (50,90) 的值變為 1。
- 對直線上第二個點重復上述過程,單元格 (50,90) 的值變為 2。此過程本質是對 \((\rho, \theta)\) 進行投票。
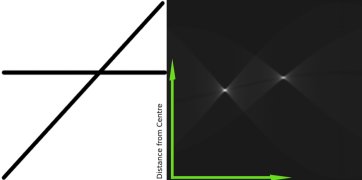
- 對直線上所有點處理后,單元格 (50,90) 將獲得最多投票數。搜索累加器中最大值即可確定圖像中存在一條距原點 50 像素、角度 90 度的直線。下圖動畫直觀展示了該過程(圖像來源:Amos Storkey):
這就是霍夫變換檢測直線的原理。其實現簡單,讀者甚至可用 NumPy 自行實現。下圖展示了累加器效果,亮點位置代表圖像中可能直線的參數(圖像來源:維基百科):
OpenCV中的霍夫變換
上述所有解釋內容都被封裝在OpenCV函數 cv.HoughLines() 中。
該函數直接返回一個 :math:(ρ, θ) 值數組。其中 \(ρ\) 以像素為單位,\(θ\) 以弧度為單位。第一個參數輸入圖像必須是二值圖像,因此在應用霍夫變換前需要先進行閾值處理或使用Canny邊緣檢測。第二和第三個參數分別是 \(ρ\) 和 \(θ\) 的精度。第四個參數是閾值,表示檢測為直線所需的最小投票數。請注意,投票數取決于直線上的點數,因此這個閾值實際上代表應該被檢測到的最小直線長度。
import cv2 as cv
import numpy as npimg = cv.imread('sudoku.png'))
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
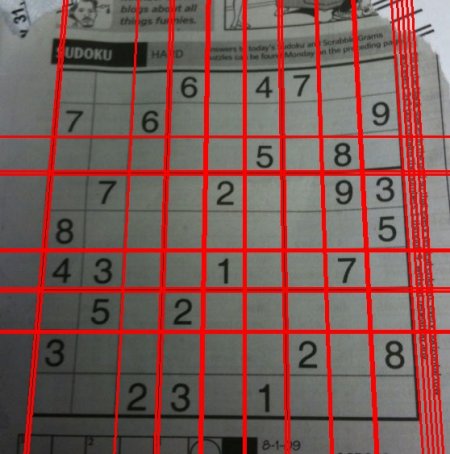
edges = cv.Canny(gray,50,150,apertureSize = 3)lines = cv.HoughLines(edges,1,np.pi/180,200)
for line in lines:rho,theta = line[0]a = np.cos(theta)b = np.sin(theta)x0 = a*rhoy0 = b*rhox1 = int(x0 + 1000*(-b))y1 = int(y0 + 1000*(a))x2 = int(x0 - 1000*(-b))y2 = int(y0 - 1000*(a))cv.line(img,(x1,y1),(x2,y2),(0,0,255),2)cv.imwrite('houghlines3.jpg',img)
檢查以下結果:
概率霍夫變換
在霍夫變換中,即使對于只有兩個參數的直線檢測,也需要大量計算。概率霍夫變換是對傳統霍夫變換的優化改進。該方法不會考慮所有點,而是僅隨機選取足以進行直線檢測的點子集。我們只需適當降低閾值即可。下圖展示了霍夫空間中的傳統霍夫變換與概率霍夫變換對比效果。(圖片來源:Franck Bettinger的主頁)
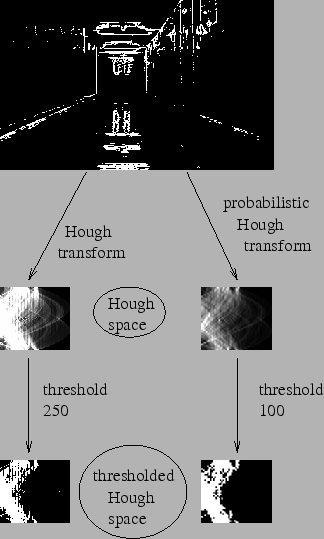
OpenCV的實現基于Matas, J.、Galambos, C.和Kittler, J.V.提出的《使用漸進式概率霍夫變換的魯棒直線檢測》論文[186]。使用的函數是**cv.HoughLinesP()**,該函數新增了兩個參數:
- minLineLength - 線段最小長度,短于此值的線段將被舍棄
- maxLineGap - 允許將間斷線段視為同一直線的最大間距
最大的優勢在于該函數直接返回線段的兩個端點坐標。而傳統方法僅能獲取直線參數,還需自行計算所有對應點。新方法使整個過程變得直觀而簡單。
import cv2 as cv
import numpy as npimg = cv.imread('sudoku.png'))
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
edges = cv.Canny(gray,50,150,apertureSize = 3)
lines = cv.HoughLinesP(edges,1,np.pi/180,100,minLineLength=100,maxLineGap=10)
for line in lines:x1,y1,x2,y2 = line[0]cv.line(img,(x1,y1),(x2,y2),(0,255,0),2)cv.imwrite('houghlines5.jpg',img)
查看下方結果:

附加資源
1、維基百科上的霍夫變換
由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,適用于 OpenCV
霍夫圓變換
https://docs.opencv.org/4.x/da/d53/tutorial_py_houghcircles.html
目標
在本章中,
- 我們將學習使用霍夫變換在圖像中檢測圓形。
- 將了解以下函數:
cv.HoughCircles()
理論
圓的數學表達式為 \((x-x_{center})^2 + (y - y_{center})^2 = r^2\),其中 \((x_{center},y_{center})\) 表示圓心坐標,\(r\) 表示圓的半徑。從方程可以看出有三個參數,因此霍夫變換需要一個三維累加器,這會非常低效。為此,OpenCV 采用了一種更巧妙的方法——霍夫梯度法,該方法利用了邊緣的梯度信息。
這里我們使用的函數是 cv.HoughCircles()。該函數包含多個參數,文檔中已有詳細說明。下面我們直接進入代碼部分。
import numpy as np
import cv2 as cvimg = cv.imread('opencv-logo-white.png', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
img = cv.medianBlur(img,5)
cimg = cv.cvtColor(img,cv.COLOR_GRAY2BGR)circles = cv.HoughCircles(img,cv.HOUGH_GRADIENT,1,20, param1=50,param2=30,minRadius=0,maxRadius=0)circles = np.uint16(np.around(circles))
for i in circles[0,:]:# draw the outer circlecv.circle(cimg,(i[0],i[1]),i[2],(0,255,0),2)# draw the center of the circlecv.circle(cimg,(i[0],i[1]),2,(0,0,255),3)cv.imshow('detected circles',cimg)
cv.waitKey((0)
cv.destroyAllWindows()
結果如下所示:

生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 為 OpenCV 生成
使用分水嶺算法進行圖像分割
https://docs.opencv.org/4.x/d3/db4/tutorial_py_watershed.html
目標
在本章中,
- 我們將學習使用基于標記的分水嶺算法進行圖像分割
- 我們將了解:
cv.watershed()
理論基礎
任何灰度圖像都可以視為一個地形表面,其中高亮度區域代表山峰和丘陵,低亮度區域代表山谷。想象你開始用不同顏色的水(標簽)填充每個孤立的山谷(局部最小值)。隨著水位上升,根據附近山峰(梯度)的不同,來自不同山谷的水(顯然顏色不同)將開始合并。為了防止這種情況,你需要在水的匯合處建造屏障。持續進行注水和建造屏障的過程,直到所有山峰都被水淹沒。此時,你所創建的屏障就形成了最終的分割結果。這就是分水嶺算法背后的"哲學思想"。你可以訪問CMM網頁上的分水嶺專題,通過動畫演示加深理解。
然而,由于圖像中的噪聲或其他不規則因素,這種方法會產生過度分割的結果。因此OpenCV實現了一種基于標記的分水嶺算法,允許你指定哪些山谷點需要合并、哪些不需要。這是一種交互式圖像分割技術。具體操作是:為我們已知的目標對象分配不同標簽——用某種顏色(或亮度值)標記確定屬于前景/對象的區域,用另一種顏色標記確定屬于背景/非對象的區域,最后用0標記不確定區域。這些標記就是我們的初始信息。應用分水嶺算法后,算法會根據我們提供的標簽更新標記結果,而對象邊界會被賦予-1值。
代碼
下面我們將通過一個示例來展示如何結合距離變換與分水嶺算法分割相互接觸的物體。
以這張硬幣圖像為例,可以看到硬幣之間相互接觸。即使進行閾值處理,它們仍會保持接觸狀態。

我們首先需要獲取硬幣的近似估計區域。為此,可以采用Otsu二值化方法。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('coins.png')
assert img is not None, "file could not be read, check with os.path.exists()"
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(gray,0,255,cv.THRESH_BINARY_INV+cv.THRESH_OTSU)
結果:

現在我們需要去除圖像中的細小白色噪點。為此可以使用形態學開運算。而要消除物體內部的小孔洞,則可以采用形態學閉運算。至此,我們可以確定:靠近物體中心的區域是前景,遠離物體的區域是背景。唯一不確定的是硬幣邊緣的邊界區域。
接下來需要提取確定屬于硬幣的區域。腐蝕操作會去除邊界像素,因此保留下來的區域必定是硬幣。這種方法在物體互不接觸時有效,但由于當前硬幣存在接觸情況,更好的方案是通過距離變換并設置合適閾值。接著需要確定絕對不屬于硬幣的區域,這里對結果進行膨脹處理。膨脹操作會將物體邊界擴展到背景區域,從而確保結果中所有背景區域都是真實的背景(因為邊界區域已被移除)。
參見下圖:
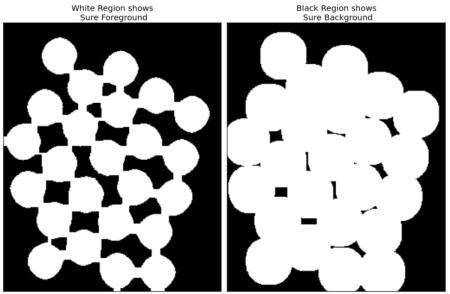
剩余區域是我們無法確定屬于硬幣還是背景的部分,這正是分水嶺算法需要處理的區域。這些區域通常位于硬幣邊界處,即前景與背景交匯的位置(或不同硬幣的交界處),我們稱之為邊界區域。該區域可通過從確定背景區域(sure_bg)中減去確定前景區域(sure_fg)獲得。
# noise removal
kernel = np.ones((3,3),np.uint8)
opening = cv.morphologyEx(thresh,cv.MORPH_OPEN,kernel, iterations = 2)# sure background area
sure_bg = cv.dilate(opening,kernel,iterations=3)# Finding sure foreground area
dist_transform = cv.distanceTransform(opening,cv.DIST_L2,5)
ret, sure_fg = cv.threshold(dist_transform,0.7*dist_transform.max(),255,0)# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv.subtract(sure_bg,sure_fg)
觀察結果。在閾值化后的圖像中,我們獲得了若干明確屬于硬幣且已分離的區域。(某些情況下,您可能僅關注前景分割而非分離相互接觸的物體。此時無需使用距離變換,僅用腐蝕操作即可。腐蝕只是另一種提取確定前景區域的方法。)

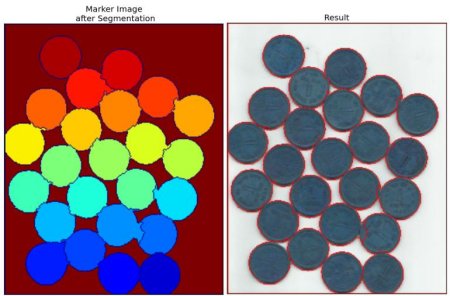
現在我們已經明確識別出硬幣區域、背景區域等。因此我們創建一個標記數組(該數組與原始圖像尺寸相同,但采用int32數據類型)并對其中區域進行標注。已確認的區域(無論前景或背景)會被標記為不同的正整數,而不確定區域則保持為零值。這里我們使用 cv.connectedComponents(),該函數會將圖像背景標記為0,其他物體則從1開始依次標記。
但需注意:若背景被標記為0,分水嶺算法會將其視為未知區域。因此我們需要用不同整數值標記背景,而將真正的不確定區域(由unknown定義)標記為0。
# Marker labelling
ret, markers = cv.connectedComponents(sure_fg)# Add one to all labels so that sure background is not 0, but 1
markers = markers+1# Now, mark the region of unknown with zero
markers[unknown==255] = 0
查看下方結果。對于部分硬幣,它們接觸的區域被正確分割,而另一些則未能實現。
其他資源
1、關于分水嶺變換的CMM頁面
練習
1、OpenCV示例中提供了一個關于分水嶺分割的交互式示例watershed.py。運行它,體驗它,然后學習它。
本文檔由doxygen 1.12.0生成于2025年4月30日周三23:08:43,針對OpenCV項目
使用GrabCut算法進行交互式前景提取
https://docs.opencv.org/4.x/d8/d83/tutorial_py_grabcut.html
目標
在本章中
- 我們將學習使用GrabCut算法提取圖像中的前景
- 我們將為此創建一個交互式應用程序
理論基礎
GrabCut算法由微軟研究院劍橋分院的Carsten Rother、Vladimir Kolmogorov和Andrew Blake聯合提出,相關論文為"GrabCut": interactive foreground extraction using iterated graph cuts。該算法的設計初衷是實現用戶交互最少的前景提取方案。
從用戶視角看,算法工作流程如下:首先用戶在目標前景區域外圍繪制矩形框(需確保前景完全位于矩形內部)。隨后算法通過迭代分割獲得最優結果。但某些情況下分割效果可能不理想,例如將部分前景誤判為背景或反之。此時用戶可通過精細修正——在圖像錯誤區域繪制筆觸:白色筆觸表示"此處應為前景",黑色筆觸則表示"此處應為背景"。通過這種交互指導,算法在下次迭代中會生成更準確的結果。
如下圖所示:先用藍色矩形框選球員和足球,隨后通過白色(前景標記)和黑色(背景標記)筆觸進行修正,最終獲得理想分割效果。

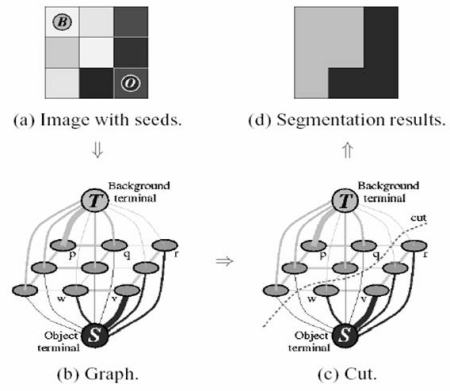
后臺處理流程解析:
- 用戶輸入矩形框后,框外區域均視為確定背景(因此需確保矩形包含所有目標物體),框內區域初始狀態為待定。用戶后續標注的前景/背景區域將作為硬標簽,在迭代過程中保持不變。
- 系統根據輸入數據進行初始標記,確定前景與背景像素(硬標簽)。
- 采用高斯混合模型(GMM)分別建模前景和背景的像素分布。
- GMM根據標注數據學習并建立新的像素分布模型,基于顏色統計特征將待定像素歸類為可能前景或可能背景(類似聚類過程)。
- 構建像素分布圖:圖中節點代表像素,額外添加源節點和匯節點。所有前景像素連接源節點,背景像素連接匯節點。
- 像素與源/匯節點間邊的權重由像素屬于前景/背景的概率決定;像素間邊的權重取決于邊緣信息或像素相似度——顏色差異越大則邊權重越低。
- 應用最小割算法分割圖結構:以最小代價函數將圖切割為分離源節點和匯節點的兩部分,代價函數即所有被切割邊的權重總和。切割后,連接源節點的像素歸為前景,連接匯節點的歸為背景。
- 重復上述過程直至分類結果收斂。
下圖直觀展示了該流程(圖像來源:http://www.cs.ru.ac.za/research/g02m1682/)
演示
現在我們來學習使用OpenCV實現GrabCut算法。OpenCV提供了**cv.grabCut()**函數,首先了解其參數:
- img - 輸入圖像
- mask - 掩碼圖像,用于指定哪些區域屬于背景、前景或可能的背景/前景等。通過以下標志實現:
cv.GC_BGD、cv.GC_FGD、cv.GC_PR_BGD、cv.GC_PR_FGD,或直接在圖像中用0、1、2、3表示 - rect - 包含前景對象的矩形坐標,格式為(x,y,w,h)
- bdgModel、fgdModel - 算法內部使用的數組,創建兩個(1,65)大小的np.float64類型零數組即可
- iterCount - 算法運行的迭代次數
- mode - 可選**
cv.GC_INIT_WITH_RECT或cv.GC_INIT_WITH_MASK**或組合模式,決定使用矩形初始化還是掩碼微調
首先演示矩形模式。我們加載圖像并創建相似的掩碼圖像,初始化fgdModel和bgdModel數組,設置矩形參數。這些步驟都很直觀。讓算法運行5次迭代,由于使用矩形初始化,模式應設為**cv.GC_INIT_WITH_RECT**。
運行grabcut后,算法會修改掩碼圖像。在新掩碼中,像素將被標記為上述四種背景/前景標志。我們將所有0像素和2像素設為0(背景),所有1像素和3像素設為1(前景),最終掩碼就準備好了。只需將其與輸入圖像相乘,即可得到分割結果。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('messi5.jpg')
assert img is not None, "file could not be read, check with os.path.exists()"
mask = np.zeros(img.shape[:2],np.uint8)bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)rect = (50,50,450,290)
cv.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv.GC_INIT_WITH_RECT)mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]plt.imshow(img),plt.colorbar(),plt.show()
查看以下結果:

糟糕,梅西的頭發不見了。誰喜歡沒有頭發的梅西呢? 我們需要把它恢復回來。因此,我們將用1像素(確定前景)進行精細修飾。同時,畫面中出現了一些我們不想要的地面部分和標志。我們需要移除它們。為此,我們用0像素(確定背景)進行修飾。于是,我們按照上述方式修改了之前得到的掩膜結果。
實際上,我做了以下操作:在繪圖應用中打開輸入圖像,并添加一個新圖層。使用畫筆工具,在新圖層上用白色標記遺漏的前景(如頭發、鞋子、球等),用黑色標記不需要的背景(如標志、地面等)。然后用灰色填充剩余的背景區域。接著在OpenCV中加載這個掩膜圖像,并根據新添加的掩膜值編輯原始掩膜圖像。查看以下代碼:
# newmask is the mask image I manually labelled
newmask = cv.imread('newmask.png', cv.IMREAD_GRAYSCALE)
assert newmask is not None, "file could not be read, check with os.path.exists()"# wherever it is marked white (sure foreground), change mask=1
# wherever it is marked black (sure background), change mask=0
mask[newmask == 0] = 0
mask[newmask == 255] = 1mask, bgdModel, fgdModel = cv.grabCut(img,mask,None,bgdModel,fgdModel,5,cv.GC_INIT_WITH_MASK)mask = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()
查看下方結果:

就是這樣。在這里,你無需以矩形模式初始化,可以直接進入掩碼模式。只需在掩碼圖像中用2像素或3像素(可能背景/前景)標記矩形區域,然后像第二個示例那樣用1像素標記確定前景。最后直接以掩碼模式應用grabCut函數即可。
練習
1、OpenCV示例中包含一個grabcut.py示例,這是一個使用GrabCut算法的交互式工具。請查看該示例。同時觀看這個YouTube視頻了解如何使用它。
2、你可以將其改造成一個交互式示例:通過鼠標繪制矩形和描邊,創建軌跡條來調整描邊寬度等。
生成于2025年4月30日 星期三 23:08:42,由doxygen 1.12.0為OpenCV生成







和 JavaScript 的關系)











