

7月15日,國產數據庫廠商中電科金倉(北京)科技股份有限公司(以下簡稱“電科金倉”)在北京舉行了一場技術發布會,集中發布四款核心產品:AI時代的融合數據庫KES V9 2025、企業級統一管控平臺KEMCC、數據庫一體機(云數據庫AI版)以及企業級智能海量數據集成平臺KFS Ultra,并同步舉行了“金蘭組織2.0”啟動儀式。
如果放在過去幾年,這場發布會可能被歸入“信創替代”的常規范疇。但這一次,電科金倉試圖講述的不再是“我們也能做、我們可以兼容”,而是“我們能不能定義下一代數據庫形態”。
整個發布會貫穿了三個關鍵詞:“融合”“AI”“平臺能力”。這背后的核心邏輯是清晰的:在“去IOE”與“兼容Oracle”的紅利漸近尾聲之際,國產數據庫廠商開始面對一個更加復雜、也更具挑戰性的市場命題——如何在大模型時代支撐非結構化數據、高維向量檢索和復雜語義計算的新需求?
正如我國數據庫學科帶頭人王珊教授所說,數據庫內核與AI能力的深度結合,已成為釋放數據核心價值的關鍵路徑,正催生著更智能、更自適應、更能應對復雜挑戰的新一代數據庫形態。這不僅是一個技術問題,更是產業方向選擇的問題。而電科金倉,作為國產數據庫廠商中的代表性玩家,選擇了用“融合數據庫”體系作為回應。
本文將試圖厘清三個核心問題:
- “融合數據庫”究竟意味著什么?它與傳統數據庫有何本質差異?
- 電科金倉的產品和技術體系是否真正構成了“融合能力”?它和“功能疊加”有何不同?
- 在AI深度嵌入企業業務的當下,這種融合路線是否能成為國產數據庫的新錨點?
?
十年前,中國數據庫行業的關鍵詞是“去IOE”與“國產替代”。在國家自主可控政策推動下,以政府、電信、金融、能源等關鍵領域為代表,信息系統加速從Oracle、IBM DB2等國外數據庫向國產方案遷移。在這一背景下,一批國產數據庫廠商迅速崛起,其主要任務是完成“可用、可控、兼容”的目標:對上層業務保持接口一致性,對底層系統實現穩定承載。
金倉數據庫正是在這一階段建立了其在國產數據庫行業的核心位置。憑借與Oracle高度兼容的技術路線、平滑遷移工具鏈以及在關鍵系統中的穩定表現,金倉數據庫產品廣泛應用于金融、電信、能源、交通、醫療、制造等多個重點行業,累計部署超100萬套。多個行業數據顯示,當前國產數據庫在政府行業的滲透率已經較高,在金融、能源、電信等領域也實現規模化部署。
然而,隨著“信創替代”階段性任務逐步完成,國產數據庫行業開始進入一個更具挑戰性的“后信創時代”。這一階段的核心問題不再是“是否兼容、替代Oracle”,而是能否適配AI驅動下的新一代數據需求和系統形態。
以大模型為代表的新型AI應用快速普及,數據模型不斷增加:從結構化數據擴展至非結構化文本、圖像、音頻、視頻;從二維表格拓展至高維向量、知識圖譜與時序流。隨之而來的,是更復雜的查詢負載、更動態的部署形態、更高并發與低延遲的性能要求,以及對模型推理與語義理解能力的數據庫原生支持。
與此同時,傳統數據庫產品“分門別類”的技術架構開始顯露疲態:關系型數據庫難以適配圖數據與向量索引,專用數據庫難以統一管控與調度,數據孤島與工具鏈碎片化問題愈發嚴重。
也就是說,當數據庫面對的不只是“存數據、查數據”,而是作為整個AI工作流的數據中樞時,其產品能力、架構底層、生態整合模式,都需要重構。
在這樣的背景下,“融合數據庫”成為國產數據庫廠商所普遍關注的下一階段技術路徑。它不僅是一個產品概念,更是一種架構性、體系化的戰略選擇:打破不同數據模型、查詢語法、運行環境、運維體系之間的壁壘,構建一個面向未來的數據處理基礎設施平臺。
對于國產數據庫而言,這不僅是一條技術演進路線,也是一個新的戰略方向。
“融合數據庫”不是產品組合的宣傳術語,而是一種架構層面的內生能力。電科金倉不是通過多個產品之間的拼接來構建所謂“融合能力”,而是選擇把這一理念深度注入到其核心產品——KES V9 2025融合數據庫引擎之中。
這是一款真正意義上的“底座級產品”,承載了電科金倉對下一代數據庫形態的理解,也代表了國產數據庫從“平替時代”向“范式定義”的躍遷嘗試。
電科金倉提出的“五個一體化”融合理念,就落地于KES V9 2025的設計之中:
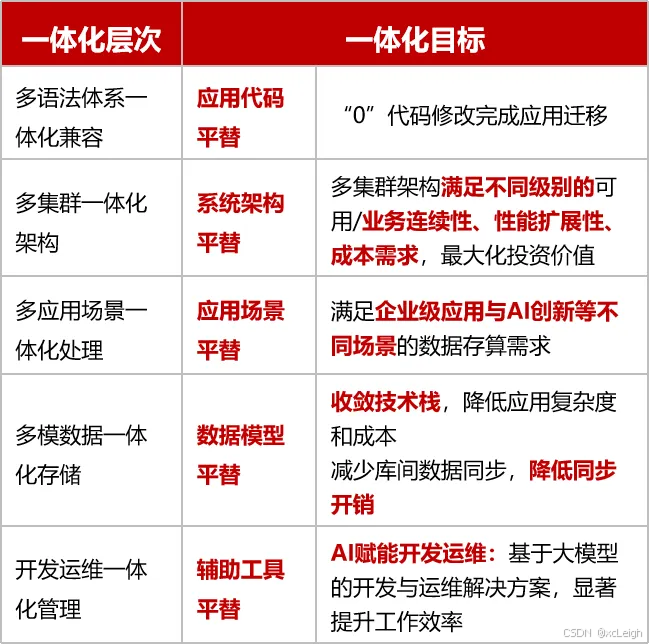
數據模型一體化:原生支持結構化、文檔、圖、時序、向量等五大主流數據模型,在同一個引擎中實現統一存儲與查詢;
語法兼容一體化:在異構兼容方面,KES V9 2025除覆蓋Oracle、MySQL常用功能外,還新增了SQL Server和Sybase兼容模式,覆蓋率分別達到99%與95%,大幅降低用戶切換門檻;
部署形態一體化:支持集中式、分布式、讀寫分離、RAC等多種形態的靈活部署,滿足從核心業務系統到邊緣節點的多樣化需求;
開發運維一體化:打通監控、調優、自愈、巡檢等全生命周期運維能力,構建面向大規模集群的運維支撐體系;
應用場景一體化:從傳統政務、金融等核心業務場景,到AI原生場景如語義檢索、RAG問答等,均實現適配與優化。
更重要的是,這一切并非功能模塊的拼裝,而是通過內核級架構重構實現的“融合內生性” —— 多模數據無需切換引擎、查詢無需跨系統協調、部署與運維無需分別建設。這使得KES V9 2025成為支撐“融合數據庫”愿景的真正技術載體。
需要指出的是,電科金倉不是為了融合而融合,融合數據庫是為了更好地支撐多場景下的應用、更好地滿足市場上涌現的新需求,尤其是為AI的規模化商用奠定堅實基礎。
圍繞“AI for DB”和“DB for AI”兩個維度,電科金倉打造了深入融合AI能力的產品體系,此次發布的四款產品均融入了AI能力,并構建起一套支撐AI應用與賦能數據庫管理的完整能力矩陣。
☆KES V9 2025:智能融合主引擎
該產品在多數據模型融合上,新增了對鍵值、文檔、向量數據模型支持,滿足AI場景等新型業務需求,通過單條SQL就能完成跨模型復雜檢索。在系統管理上,通過融合AI技術的智能優化器、全診斷過程支撐及SQL映射應急機制,實現從性能問題感知到自治優化的完整鏈路,大幅降低人工管理成本。
☆云數據庫一體機(AI版):交付即智能
該一體機搭載“的盧運維智能體”,創新引入AI交互式運維模式,用戶通過自然語言即可驅動數據庫進行自治運維操作,通過AI驅動SQL優化,讓數據庫越用越快,并可通過AI實現告警自動處置閉環,故障預警準確率高達98%以上,大幅提升了運維效率與易用性。
AI版一體機可在分鐘級完成部署,實現“開箱即用、自主運行”的交付體驗。
☆KFS Ultra:打通數據流動的“動脈系統”
融合的前提是數據的廣泛接入與調度。KFS Ultra作為金倉“數據動脈”,支持結構化、半結構化、非結構化數據的統一同步與管理。KFS Ultra還創新引入“掣電融合數據復制引”,日吞吐量可達千億級。該產品通過AI智能算力調度,有效消除卡頓延遲,保障業務持續流暢運行。同時內置“K寶”智能助手,提供覆蓋部署、優化、診斷的AI運維支持。
☆KEMCC:讓數據庫管理走向智能化
KEMCC作為融合體系的“管控大腦”,覆蓋從部署到運維的整個生命周期管理。它提供集中式監控、自動巡檢、優化建議輸出,并內嵌AI輔助決策能力,支撐大規模、多實例數據庫資產的統一調度。
在接受媒體采訪時,電科金倉指出,這四款產品不是獨立存在,而是面向AI應用構成“融合數據庫平臺”的四個維度:KES是內核,KFS是數據流動層,KEMCC是管控層,一體機是交付層,共同形成從底層到交付的全棧一體化平臺。
此外,融合不是單靠數據庫廠商自身能完成的。此次發布會上,電科金倉同步宣布品牌升級,正式推出“數據庫平替用金倉”的新口號,意圖強化其在國產數據庫替代與智能化演進中的雙重角色。
電科金倉在發布會上同步推出了“金蘭組織2.0”計劃,在1.0階段基礎上,金蘭組織2.0不僅“破圈”聚合政產學研多方力量,還提出將影響力由中國拓展至全球,以共建技術生態、共享創新成果為目標,打造國產數據庫走向國際的新平臺。

這種協同體系,某種程度上是對Oracle+NVIDIA、Snowflake+OpenAI等國外組合形態的國產對標。
電科金倉透露,目前其融合數據庫已在大量客戶場景中部署了AI場景的向量能力,涵蓋金融知識問答、交通圖像查詢、政務語義搜索等典型RAG應用場景。
過去幾十年,數據庫作為信息系統的“后端模塊”,其核心使命是存儲、組織與查詢結構化數據。在這一范式下,SQL語言、關系模型、事務機制構成了現代數據庫的基礎邏輯,也塑造了像Oracle、MySQL這樣的經典技術形態。
但AI時代的到來打破了這一認知邊界。
1. 數據庫需要被重新發明一次
大模型不僅在重寫前端應用邏輯,也在倒逼后端數據系統徹底重構:
- 輸入不再是清晰的字段,而是模糊的語義;
- 數據不再僅是表格,而是圖譜、文檔、視頻、向量;
- 查詢不再是規則匹配,而是理解意圖后的智能召回。
這意味著,數據庫不僅要處理數據,還要理解數據、參與計算、驅動推理。
電科金倉的“融合數據庫”路線正是在這種背景下做出的回應。它不是某個單點技術的演進,而是一種底層架構與產品角色的集體重寫——從“兼容Oracle”轉向“AI雙向賦能”;從“功能堆疊”轉向“內核融合”;從“數據庫工具”轉向“數據基礎設施平臺”。
這條路徑的特別之處在于,它標志著國產數據庫廠商第一次在新一代技術范式轉型中實現了“同步起跑”。
過去,在關系型數據庫時代,中國廠商普遍追趕國外技術標準;在NoSQL和NewSQL浪潮中,受限于應用規模和場景契合度,多數廠商沒有進入主舞臺。而今天,AI對數據庫提出的全新要求,讓所有廠商都必須重新開始。而國產廠商,終于站在了同一起跑線上。
電科金倉選擇從平臺視角構建融合數據庫,不再滿足于“能用”“替代”,而是試圖抓住“AI時代的結構性重構機會”,以“融合”作為切入點,對下一代數據庫形態下注。這既是一次嘗試,也是一種突破。
“數據庫需要被重新發明一次”——AI不是加功能,而是改底座。而電科金倉為代表的國產數據庫廠商,正在嘗試拿回定義權。
2. 格局未定,誰都有機會登頂
數據庫行業正在經歷一次罕見的結構性重塑期。例如,Oracle正在重構其AI支撐能力,重新定義Exadata與OCI的位置;MongoDB早已放下“文檔數據庫”的標簽,全力投入AI for DB與向量檢索;Snowflake則不斷將自己延展為數據云平臺,與OpenAI展開深度集成。
這一切都說明:傳統數據庫巨頭也必須進化才能在AI時代存活。
而對于國產數據庫廠商而言,這是歷史性機遇。以往,無論是事務模型、查詢引擎還是集群架構,國產廠商都要從追趕開始;但今天,向量計算、知識索引、語義檢索、RAG中樞,這些新能力沒有明確標準,也沒有絕對領先者。
這是一個“技術范式重啟”的時代,第一次給予了國產廠商與全球同行“同步構建”的機會。
在這一波技術遷移中,電科金倉的動作已足夠快——它不是唯一的探索者,但它是少數“明確提出融合、快速落地產品、形成體系閉環”的玩家之一。
這不僅是一次產品迭代,更是一場產業角色的轉換。過去它是“國產替代者”,未來它可能成為“架構重構者”。在新一輪數據庫形態變革中,電科金倉選擇的“融合數據庫平臺”路線,既是基礎能力的升級,也是一種未來圖景的表達。
至于它能否成為中國版的“Oracle+Snowflake”,這一判斷需要交給時間。但可以確定的是,它已經踏出了至關重要的第一步:不再問“我們能否替代”,而是問“我們能否定義”。
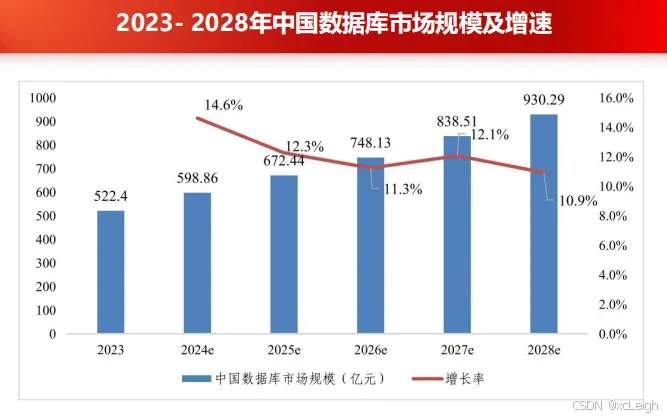
電科金倉董事長仲愷指出,數據庫作為數字中國建設的核心支撐,正成為激活新質生產力的關鍵引擎。因此,隨著數字經濟、新質生產力的快速發展,國產數據庫有廣闊的市場前景。據中國通信標準化協會大數據技術標準推進委員會 (CCSA TC601) 發布的《數據庫發展研究報告(2024年)》,預計到2028年,中國數據庫市場總規模將達到930.29億元,市場年復合增長率 (CAGR) 為12.23%。
可謂天地寬闊,任君翱翔。天時、地利、人和,時代給了我們一次難得的機會,希望國產數據庫廠商不要浪費了。
來源: 數據猿


設計原則之合成復用原則)
)

)


)





list的使用)




