1.模版編譯原理
當我們在代碼中使用了一個模板,觸發了一個實例化過程時,編譯器就會用模板的實參(Arguments)去替換(Substitute)模板的形參(Parameters),生成對應的代碼。同時,編譯器會根據一定規則選擇一個位置,將生成的代碼插入到這個位置中,這個位置被稱為 POI(point of instantiation)。由于要做替換才能生成具體的代碼,因此 C++ 要求模板的定義對它的 POI 一定要是可見的。換句話說,在同一個翻譯單元(Translation Unit)中,編譯器一定要能看到模板的定義,才能對其進行替換,完成實例化。
2.包含模型
因此最常見的做法是,我們會將模板定義在頭文件中,然后再源文件中?#include?頭文件來獲取該模板的定義。這就是模板編程中的包含模型(Inclusion Model)。
所以我們一般情況下,對于模版會把定義放在頭文件中。但是這樣操作會帶來缺點。這個也對應著顯示實例化的優點。
現在的一些 C++ 庫,整個項目中就只有頭文件,沒有源文件,庫的邏輯全部由模板實現在頭文件中。而且這種做法似乎越來越流行,在 GitHub 和 boost 中能看到很多很多。我想原因一個是 C++ 缺乏一個官方的 package manager,這樣發布的軟件包更易使用(include就行了);另一個就是模板實例化的這種要求,使得包含模型成為泛型編程中組織代碼最容易的方式。
但包含模型也有自身的問題。在一個翻譯單元(Translation Unit)中,同一個模板實例只會被實例化一次。也就是對同一個模板傳入相同的實參,編譯器會先檢查是否已實例化過,如果是則使用之前實例化的結果。但在不同的翻譯單元中,相同實參的模板會被實例化多次,從而產生多個相同的類型、函數和變量
這帶來兩個問題:
2.1 鏈接時的重定義問題
如果不加以處理,這些相同的實體會被鏈接器認為是重定義的符號,這違反了ODR(One Definition Rule)。對這個問題的主流解決方案是為模板實例化生成的實體添加特殊標記,鏈接器在鏈接時對有標記的符號做特殊處理。例如在 GNU 體系下,模板實例化生成的符號都被標記為弱符號(Weak Symbol)。不需要我們參與,連接器已經為我們解決了這個問題。
對于普通的函數和類,連接器是不會處理的。會報重定義的錯誤。
同時這個因為每一個編譯單元都有實例化,會帶來代碼膨脹。
2.2 編譯時長的問題
同一個模板傳入相同實參在不同的編譯單元下被實例化了多次,這是不必要的,浪費了編譯的時間。
3.分離模型
就是將聲明放在頭文件,實現放在.cpp中,并對其進行顯示實例化,為什么要進行顯示實例化,我在后面會詳細的介紹。
顯示實例化有如下的優點:
1. 降低編譯器構建的時間
2.降低代碼膨脹
3.針對發布lib,可以隱藏頭文件
當然缺點也很明顯,你要用到哪個模版類型,你提前事先都得很清楚,并且隨著代碼的累加,你都要動態的維護。
4.驗證前面說的結論
1.如果在翻譯單元的編譯期間,能夠看到模版的定義,就會在當前單元進行實例化。
也就是這個是一個多余的動作,就是能看見就順便實例化了,調用函數正常。
2.如果在當前翻譯單元看不到模版的定義,則只會調用這個函數,也就是認為聲明在這個.h文件中,定義不在,鏈接的時候再去找。
3.正常的編譯期就會生成對成員函數的調用,只是能看到模版的定義時,在本翻譯單元的時候,才會進行實例化。如果在本翻譯單元沒有定義,則會在鏈接階段再去找定義。
4.只要是實例化一定是在編譯階段,只是在你這個單元是否可見。
以上說的這幾點,主要是針對包含模型和分離模型的對比來說的。
下面我們看下具體的例子。
我們先來解釋第一句話:
//1.如果在翻譯單元的編譯期間,能夠看到模版的定義,就會在當前單元進行實例化。
//也就是這個是一個多余的動作,就是能看見就順便實例化了,調用函數正常。
//我們定義寫一個main.cpp,再寫一個function_template.h,然后在function_template.h中寫一個實現的函數模版
// main.cpp
#include <iostream>
//#include "zhang.h"
#include "function_template.h"
int main() {int aa = 12;//Zhang temp;int num = system_latency_get_hardware_time(aa);std::cout<<num<<std::endl;return 0;
}
//function_template.h
template <typename Message>
int system_latency_get_hardware_time(const Message& message) {int a = 16;int b = 17;return a+b;
}
// 編譯指令如下:
g++ -std=c++17 main.cpp -o main
// 編譯通過,執行./main
33
// 我們再來看下,分步操作會怎么樣,我先生成匯編代碼.
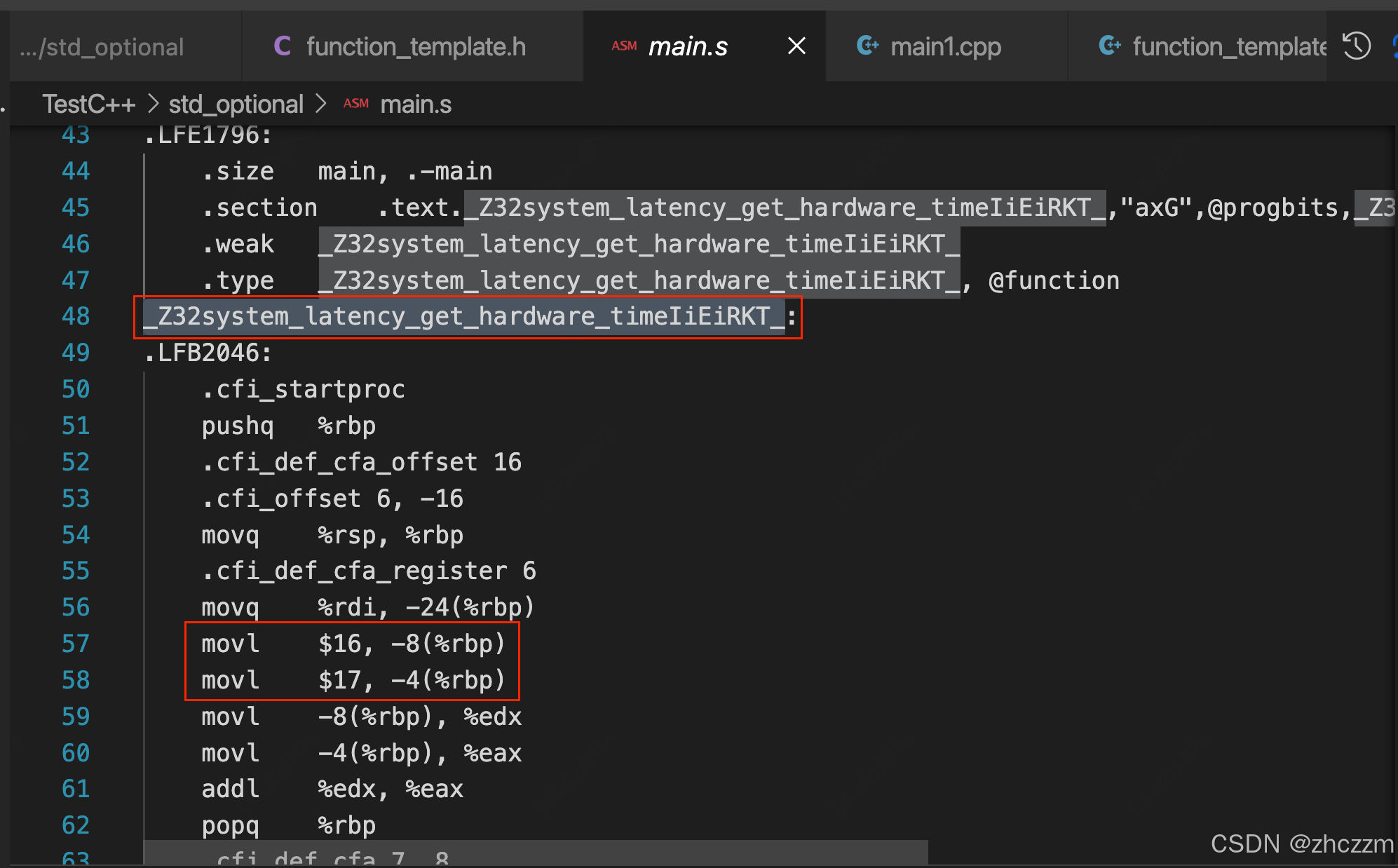
g++ -std=c++17 -S main.cpp -o main.s查看對應的匯編代碼,發現在匯編里已經出現了 system_latency_get_hardware_time
的定義
//我們修改 function_template.h的代碼
// function_template.h
template <typename Message>
int system_latency_get_hardware_time(const Message& message);
// 然后再進行匯編操作
g++ -std=c++17 -S main.cpp -o main.s這個時候我們匯編不會報錯,正如我們第二點所說.
2.如果在當前翻譯單元看不到模版的定義,則只會調用這個函數,也就是認為聲明在這個.h文件中,定義不在,鏈接的時候再去找。
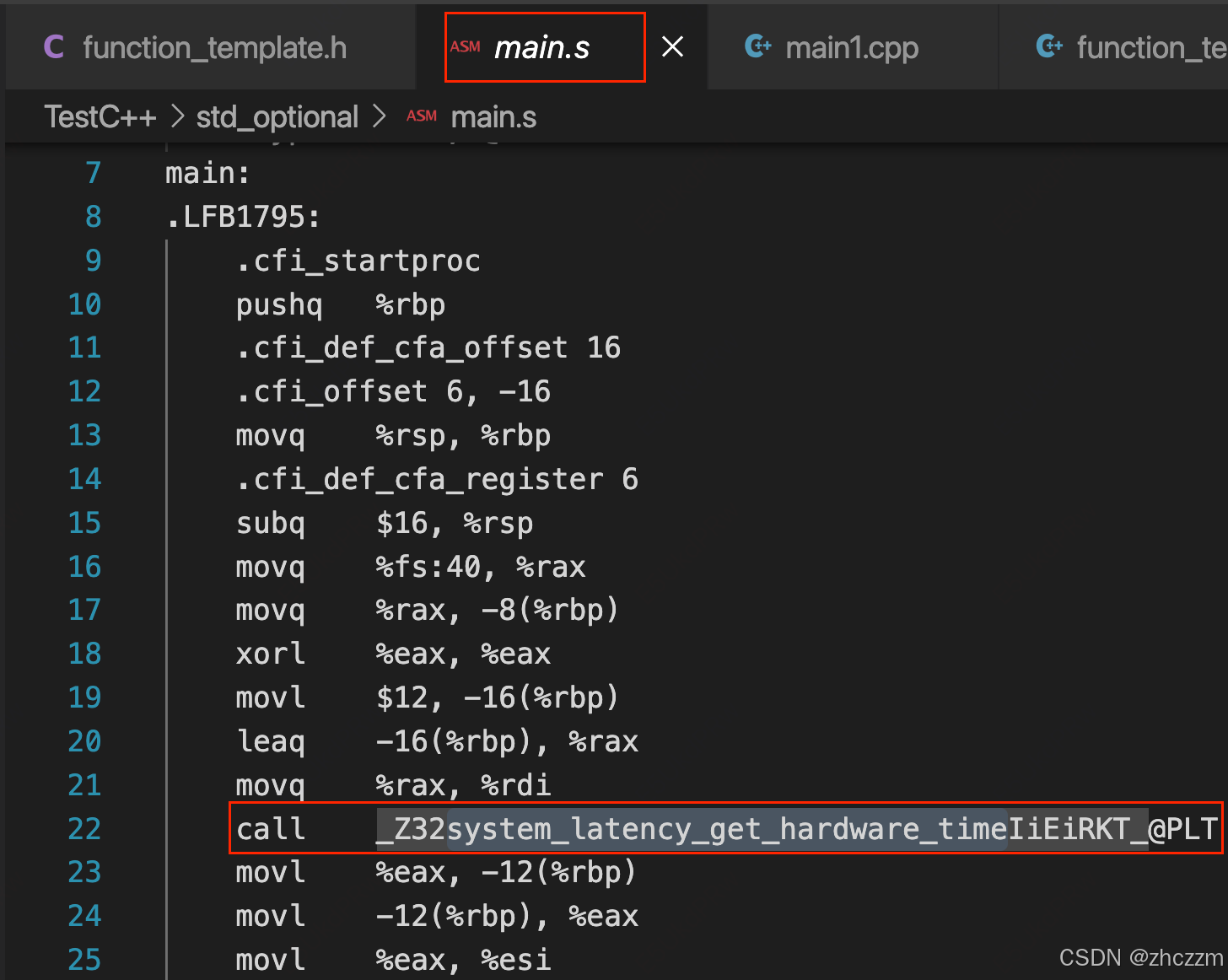
關于這個函數搜索只能找到這一條數據。
而我們現在繼續向下,鏈接會怎么樣,應該會報鏈接錯誤,我們試試.
// 為了少打幾個指令,直接進行一步
g++ -std=c++17 main.cpp -o main
這個時候,在鏈接的時候,就會報錯g++ -std=c++17 main.cpp -o main
/tmp/ccgzva3Q.o: In function `main':
main.cpp:(.text+0x26): undefined reference to `int system_latency_get_hardware_time<int>(int const&)'
collect2: error: ld returned 1 exit status這個錯誤,我們是可以接受的,因為我們確實沒有定義.
那我們想把,模版的定義,放到.cpp中可以嗎?
// 在剛才的基礎上
// function_template.h
template <typename Message>
int system_latency_get_hardware_time(const Message& message);
// add function_template.cpp
#include "function_template.h"
template <typename Message>
int system_latency_get_hardware_time(const Message& message) {int a = 16;int b = 17;return a+b;
}
// 然后我在編譯代碼的時候,鏈接下function_template.cpp是不是就可以了呢?
// g++ -std=c++17 main.cpp function_template.cpp -o main
/tmp/ccsWDsr1.o: In function `main':
main.cpp:(.text+0x26): undefined reference to `int system_latency_get_hardware_time<int>(int const&)'
collect2: error: ld returned 1 exit status我們發現還是不行,這個其實很好理解,因為在 另外一個編譯單元(一個cpp文件就是一個編譯單元), function_template.cpp中,這個不會生成這個函數,因為模版沒有被實例話,那么方法來了,我們來進行下顯示的實例話。
// function_template.cpp
#include "function_template.h"
template <typename Message>
int system_latency_get_hardware_time(const Message& message) {int a = 16;int b = 17;return a+b;
}
// 顯示實例話 這個必須放在定義的后面,在.h和.cpp里無所謂.
template int system_latency_get_hardware_time<int> (const int&);再進行編譯,g++ -std=c++17 main.cpp function_template.cpp -o main
我們發現可以編譯通過了,說明在 function_template.cpp中,會生成這個函數,那么我們沒有給函數體,函數體是誰呢?很顯然是是使用 primary template的函數體,因為執行程序的輸出是 33.
到現在為止,1,2,3,4 點我都解釋清楚了。
這里要主要一個細節,就是類模版的全特化和函數模版的全特化還有些不同,類模版如果全特化以后,還需要進行實例化才能生成代碼,但是函數模版的全特化后,不需要實例化了,直接可以生成代碼,具體可以參考我的下一篇博文?深入淺出之STL源碼分析5_模版實例化與全特化-CSDN博客

)





)











