Linux : 多線程【線程概念】
- (一)線程概念
- 線程是什么
- 用戶層的線程
- linux中PID與LWP的關系
- (二) 進程地址空間頁表
- (三) 線程總結
- 線程的優點
- 線程的缺點
- 線程異常
- 線程用途
(一)線程概念
線程是什么
- 在一個程序里的一個執行路線就叫做線程(thread)。更準確的定義是:線程是“一個進程內部的控制序列”。
- 一切進程至少都有一個執行線程。
- 線程在進程內部運行,本質是在進程地址空間內運行。
- 在Linux系統中,在CPU眼中,看到的PCB都要比傳統的進程更輕量化。
- 透過進程虛擬地址空間,可以看到進程的大部分資源,將進程資源合理分配給每個執行流,就形成了線程執行流。
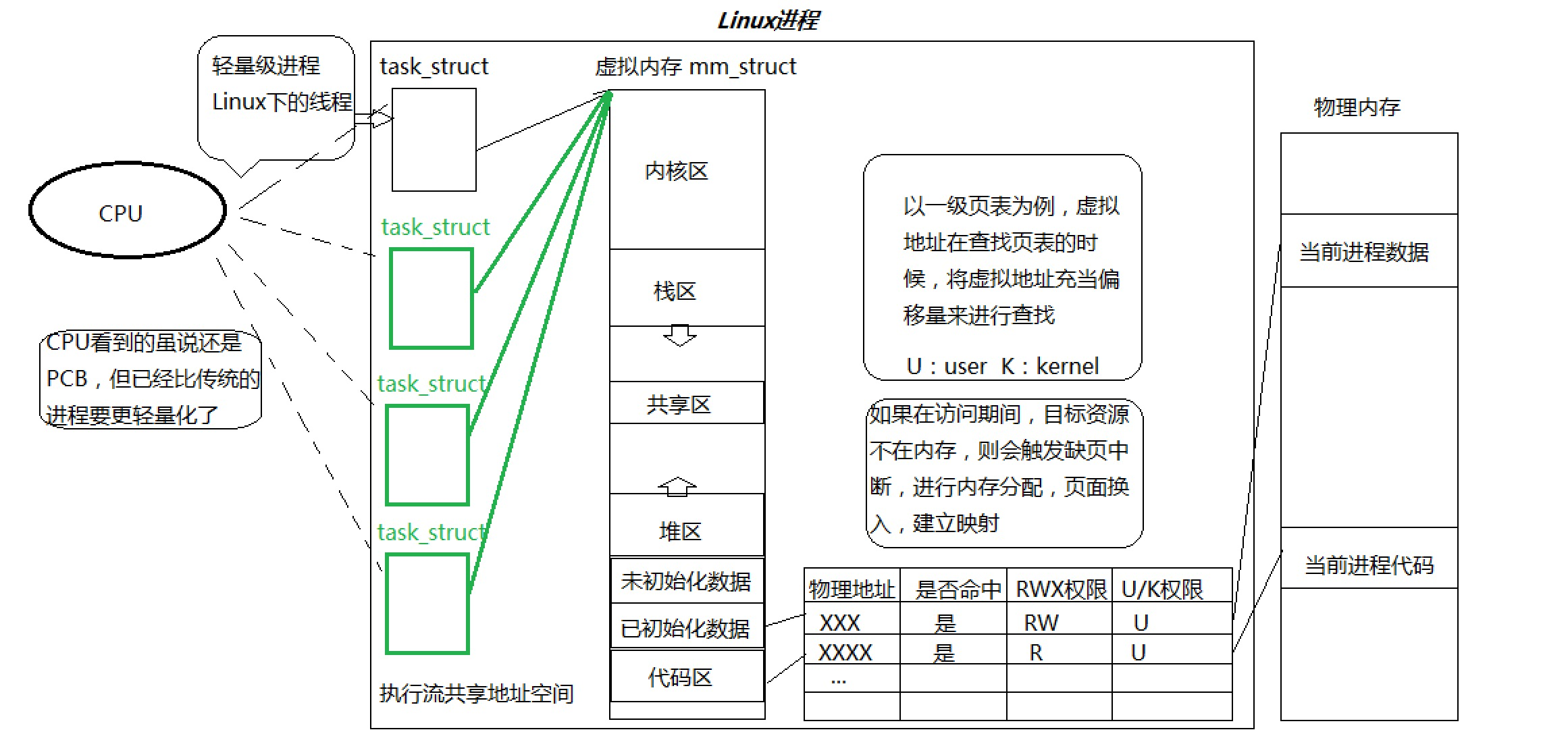
進程是資源分配的基本單位,線程是cpu執行調度的基本單位。一個進程創造不僅只有task_struck(PCB)還有頁表、進程地址空間等等。而一個線程的創建只有task_struct并且沿用進程的地址空間和頁表等,所以線程的創建十分輕量。
- 一個線程都是當前進程里面的一個執行流
- 線程在進程內部運行,本質就是線程在進程地址空間內運行,也就是說曾經這個進程申請的所有資源,幾乎都是被所有線程共享的。
cpu是通過task_struct來執行調度,而一個進程中是可以有多個線程即執行流的,所以線程的執行粒度是比進程細(即線程是執行進程的一部分代碼)
用戶層的線程
進程和線程是如此的相似,那么究竟是如何創建線程的呢??
實際上在Linux中沒有真正意義的線程,那么也就絕對沒有真正意義上的線程相關的系統調用
想要用好線程就必須要對線程做管理,進程已經有一套進程的管理模式了,而描述線程的控制塊和描述進程的控制塊是類似的,那么再對線程做一套管理算法等等就十分繁瑣,因此Linux并沒有重新為線程設計數據結構,而是直接復用了進程控制塊,所以我們說Linux中的所有執行流都叫做輕量級進程。
(在windows系統中真正實現了線程,因此Windows操作系統系統的實現邏輯一定比Linux操作系統的實現邏輯要復雜得多。)
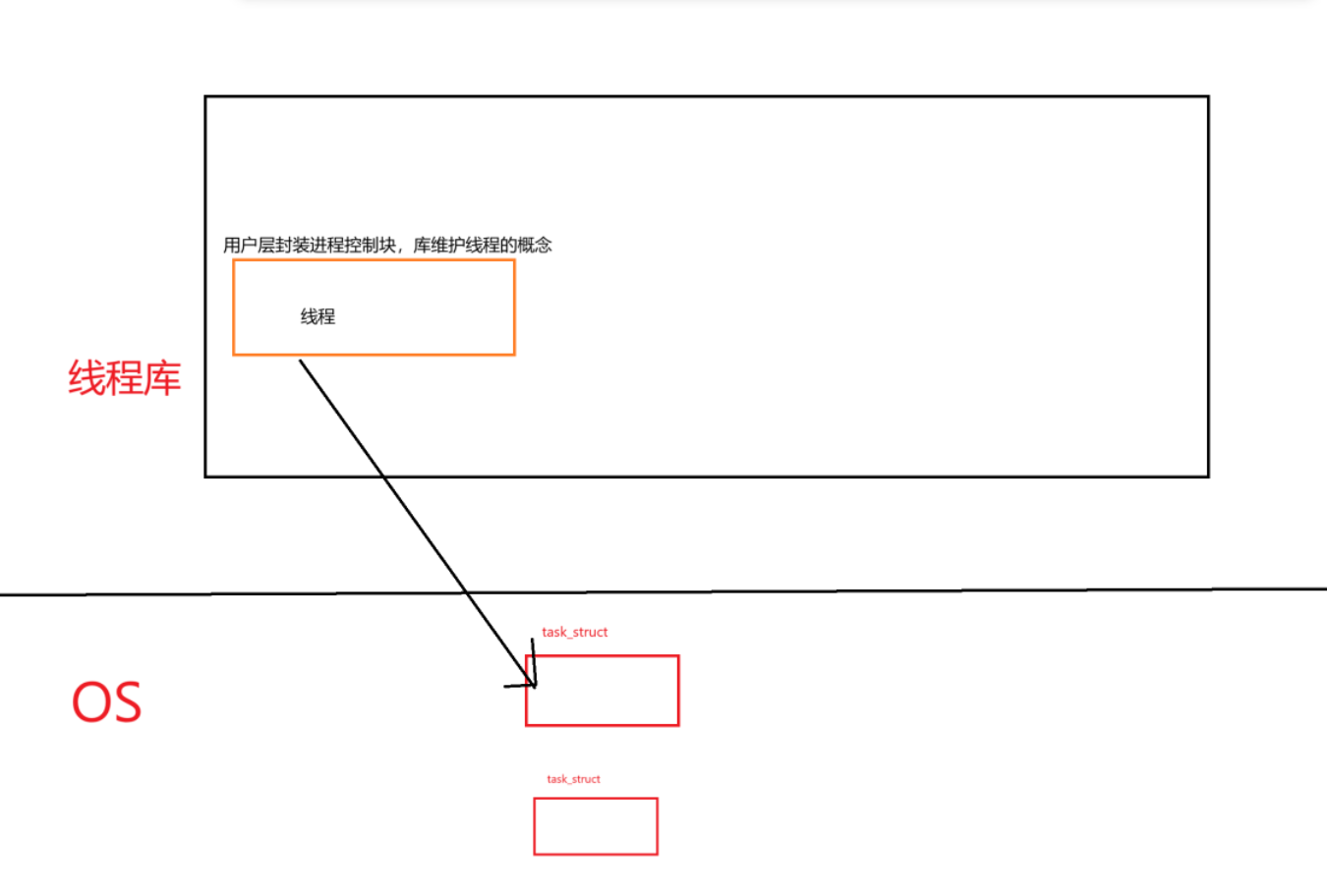
在linux操作系統沒有線程的概念,但是我們用戶卻需要一個真正的線程的概念,所以原生線程庫pthread由此誕生。原生線程庫實際就是對輕量級進程的系統調用進行了封裝,在用戶層模擬實現了一套線程相關的接口。因此對于我們來講,在Linux下學習線程實際上就是學習在用戶層模擬實現的這一套接口,而并非操作系統的接口。
linux中PID與LWP的關系
進程是由操作系統將程序運行所需地址空間、映射關系、代碼和數據打包后的資源包,而 線程/輕量級線程/執行流 則是利用資源完成任務的基本單位
- 進程是承擔系統資源分配的實體
- 線程是 CPU 運行的基本單位
實際上 進程 = 線程 + 虛擬地址空間 + 映射關系 + 代碼和數據,這才是一個完整的概念
使用 ps -aL指令查看所有的線程

LWP就是我們的輕量級進程也就是線程,每一個線程都有自己的LWP號,而線程組成線程組,我們用pid來描述這個線程組,也就是我們常說的一個進程的pid。
(二) 進程地址空間頁表
在 32 位系統中,存在 2^32 個地址(一個內存單元大小是 1byte),意味著虛擬地址空間 的大小為 4GB。
通常將這32位分為 10、10、12
- 第一個10: 虛擬地址中的前 10 個比特位,用于尋址 二級頁表
- 第二個10:虛擬地址中間的 10 個比特位,用于尋找 頁框起始地址
- 第三個12:虛擬地址中的后 12 個比特位,用于定位 具體地址(偏移量)
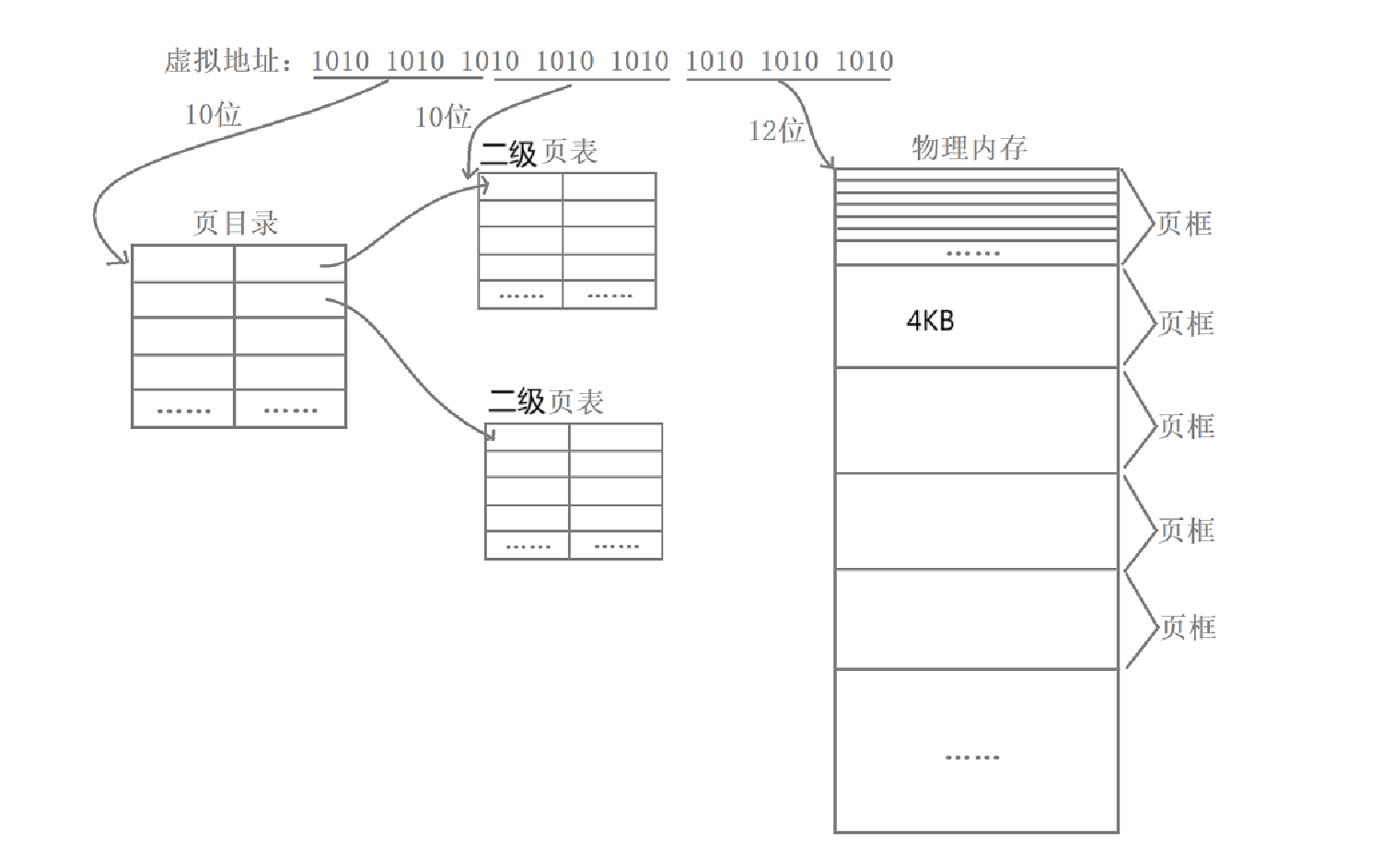
- 選擇虛擬地址的前10個比特位在頁目錄當中進行查找,找到對應的二級頁表。
- 再選擇虛擬地址的10個比特位在對應的頁表當中進行查找,找到物理內存中對應頁框的起始地址(一個頁框4KB)。
- 最后將虛擬地址中剩下的12個比特位作為偏移量從對應頁框的起始地址處向后進行偏移,找到物理內存中某一個對應的字節數據。
說明:
- 物理內存實際是被劃分成一個個4KB大小的頁框的,而磁盤上的程序也是被劃分成一個個4KB大小的頁幀的,當內存和磁盤進行數據交換時也就是以4KB大小為單位進行加載和保存的。
- 4KB實際上就是2的12次方個字節,也就是說一個頁框中有2的12次方個字節,而訪問內存的基本大小是1字節,因此一個頁框中就有2的12次方個地址,于是我們就可以將剩下的12個比特位作為偏移量,從頁框的起始地址處開始向后進行偏移,從而找到物理內存中某一個對應字節數據。
上面所說的所有映射過程,都是由**MMU(MemoryManagementUnit)**這個硬件完成的,該硬件是集成在CPU內的。頁表是一種軟件映射,MMU是一種硬件映射,所以計算機進行虛擬地址到物理地址的轉化采用的是軟硬件結合的方式。
注意:32位計算機下是二級頁表,64位平臺下用的是多級頁表。
當引發異常操作時,操作系統能在 查頁表 階段就進行攔截,而不是等到真正影響到 物理內存 時才報錯.
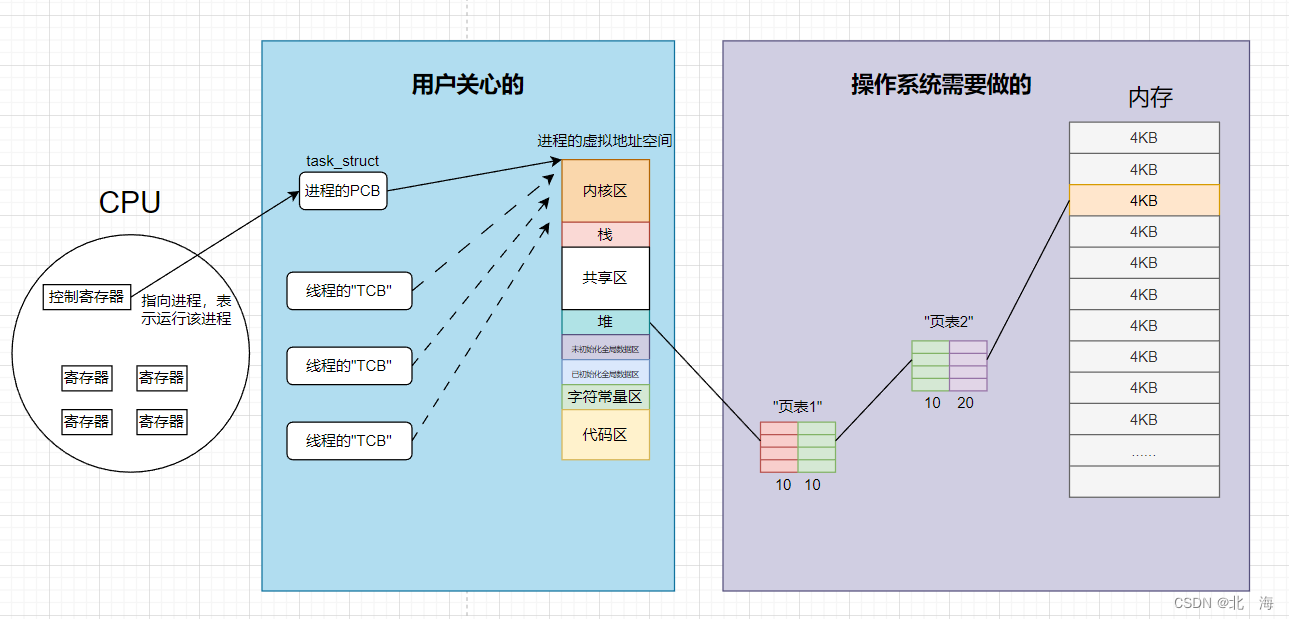
頁表是有權限的,所以當我們在進行修改一個常量字符串的時候,虛擬地址必須經過頁表映射找到對應的物理內存,但在頁表開始對應的時候發現其權限是只讀此時你要對其進行修改就會在MMU內部觸發硬件錯誤,操作系統在識別到是哪一個進程導致的之后,就會給該進程發送信號對其進行終止。
(三) 線程總結
線程的優點
- 創建一個新線程的代價要比創建一個新進程小得多
- 與進程之間的切換相比,線程之間的切換需要操作系統做的工作要少很多
- 線程占用的資源要比進程少很多
- 能充分利用多處理器的可并行數量
- 在等待慢速I/O操作結束的同時,程序可執行其他的計算任務
- 計算密集型應用,為了能在多處理器系統上運行,將計算分解到多個線程中實現
- I/O密集型應用,為了提高性能,將I/O操作重疊。線程可以同時等待不同的I/O操作。
注釋:
計算密集型:執行流的大部分任務,主要以計算為主。比如加密解密、大數據查找等。
IO密集型:執行流的大部分任務,主要以IO為主。比如刷磁盤、訪問數據庫、訪問網絡等。
線程的缺點
- 性能損失:一個很少被外部事件阻塞的計算密集型線程往往無法與共它線程共享同一個處理器。如果計算密集型線程的數量比可用的處理器多,那么可能會有較大的性能損失,這里的性能損失指的是增加了額外的同步和調度開銷,而可用的資源不變。
- 健壯性降低:編寫多線程需要更全面更深入的考慮,在一個多線程程序里,因時間分配上的細微偏差或者因共享了不該共享的變量而造成不良影響的可能性是很大的,換句話說線程之間是缺乏保護的。
- 缺乏訪問控制:
進程是訪問控制的基本粒度,在一個線程中調用某些OS函數會對整個進程造成影響。 - 編程難度提高:
編寫與調試一個多線程程序比單線程程序困難得多。
線程異常
- 單個線程如果出現除零,野指針問題導致線程崩潰,進程也會隨著崩潰
- 線程是進程的執行分支,線程出異常,就類似進程出異常,進而觸發信號機制,終止進程,進程終止,該進程內的所有線程也就隨即退出
線程用途
- 合理的使用多線程,能提高CPU密集型程序的執行效率
- 合理的使用多線程,能提高IO密集型程序的用戶體驗(如生活中我們一邊寫代碼一邊下載開發工具,就是多線程運行的一種表現)

)

















