
近年來,工業異常檢測(Anomaly Detection)在智能制造、質量監控等領域扮演著越來越重要的角色。傳統方法通常依賴大量正常樣本進行訓練,而在實際生產中,異常樣本稀少甚至不存在,能否僅憑少量正常樣本就實現精準的異常檢測,成為了一項重要挑戰。
PromptAD?方法首次將提示學習(Prompt Learning)?引入單類別異常檢測任務中,僅使用正常樣本就能自動學習有效的提示詞,在多個標準數據集上取得了領先性能。
少樣本異常檢測的難點
異常檢測本質上是一個單類別分類(One-Class Classification, OCC)?問題:訓練時只有正常樣本,測試時則需要識別出異常。
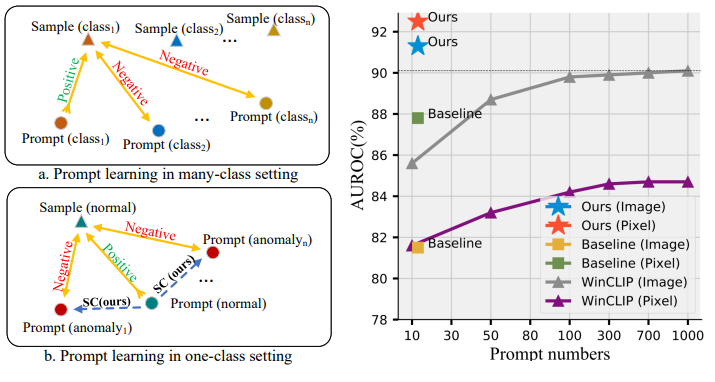
現有的基于視覺-語言模型(如CLIP)的方法(例如WinCLIP)雖然效果顯著,但依賴大量人工設計的提示詞(Prompt Ensemble),需要組合成百上千個文本提示才能達到理想效果。這不僅費時費力,還難以自動化部署。
更遺憾的是,傳統的多類別提示學習方法(如CoOp)在異常檢測任務上表現不佳,因為它們缺乏負樣本(異常樣本)的對比信息。
總結而言異常樣本太少、異常千奇百怪、人工成本高。
PromptAD創新方案
PromptAD 之所以能夠在 “只看正常樣本” 的情況下依舊精準檢測異常,關鍵在于它提出了三大創新:
語義拼接(Semantic Concatenation,SC)
在小樣本異常檢測中,訓練集通常只包含正常樣本,沒有異常樣本可供學習。
而傳統的 Prompt 學習依賴“對比學習”(Contrastive Learning):正常和異常要互相對比,模型才能學會區分。
但如果沒有異常樣本,這個“對比”就無法進行。
核心思路
研究者提出了一種巧妙的方法:通過語言構造虛擬異常。
給正常的提示詞加上“異常后綴”,從而生成異常提示詞。
舉例:
正常提示詞:“a photo of cable”(一張電纜的照片)
異常提示詞:“a photo of cable with flaw”(一張有缺陷的電纜照片)
這樣,哪怕沒有真實異常圖像,模型也能通過這些“虛擬異常描述”來建立對比關系,從而學會區分正常和異常。
技術細節
手工異常后綴(MAP):利用數據集里的標簽信息(如?crack、stain、hole?等),拼接成異常提示詞。
可學習異常后綴(LAP):在手工后綴之外,再增加一組可學習的“異常符號”,不斷訓練,讓模型自己去探索更豐富的異常語義。
結果:正常提示詞(NP)與異常提示詞(MAP/LAP)共同參與訓練,形成有效的對比學習。
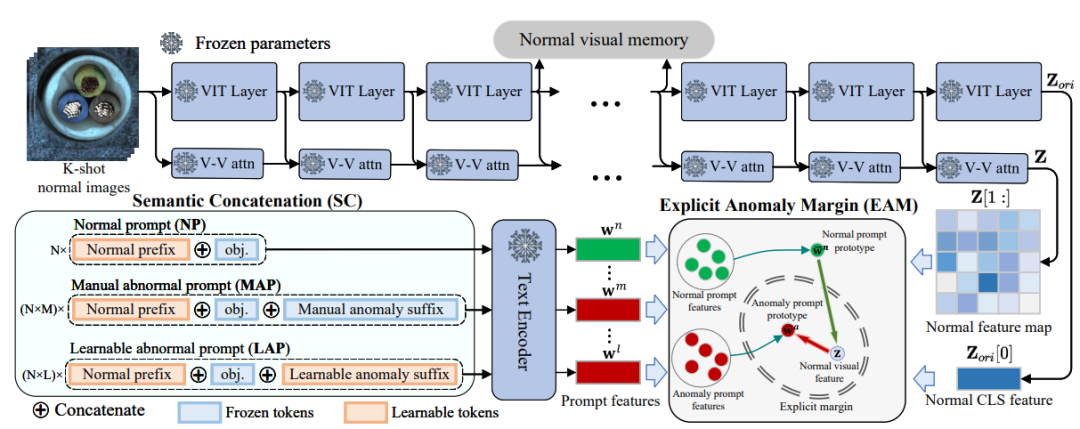
顯式異常邊界(Explicit Anomaly Margin,EAM)
即使通過語義拼接生成了異常提示詞,仍然有一個問題:
這些異常提示詞并不來自真實異常樣本,模型無法自動判斷“正常”和“異常”之間該保持多大的差距。
核心思路
研究者提出了顯式異常邊界的概念:
在訓練過程中,引入一個超參數,強制約束:
正常樣本與正常提示詞的距離要比正常樣本與異常提示詞的距離更小。
換句話說,在特征空間里畫一條“安全邊界”,讓正常與異常的分布明顯分開。
技術細節
使用了正則化損失函數,使得模型在學習時不斷維持這個邊界。
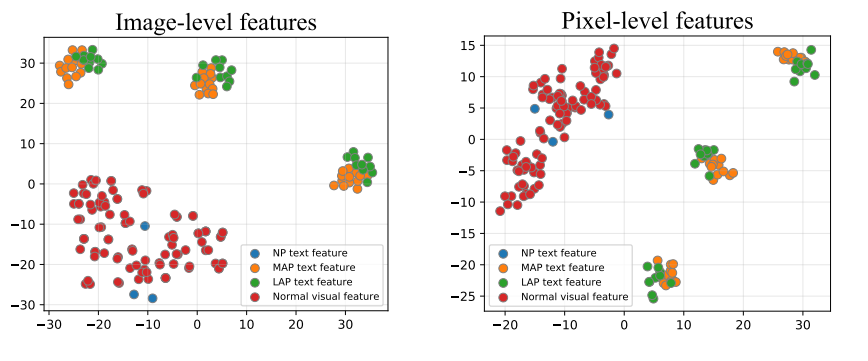
為了讓可學習的異常提示(LAP)更貼近真實語義,還引入了一個“對齊機制”,讓 LAP 的分布與 MAP 保持一致。
雙重檢測機制:Prompt + Vision
異常檢測既需要整體判斷(這張圖是否異常?),又需要局部定位(異常具體在哪?)。
單靠?Prompt?引導(語義信息)或單靠圖像特征(視覺信息)都不夠全面。
核心思路
PromptAD?結合了兩種機制:
Prompt-guided AD (PAD)
利用語義信息(Prompt)來判斷正常 vs 異常。
擅長 圖像級別 的分類。
Vision-guided AD (VAD)
在訓練階段記憶“正常樣本”的局部特征,在測試時對比差異。
擅長像素級別的定位。
融合
兩者結果通過調和平均進行融合,既保證整體判斷,又能精確圈出異常區域。
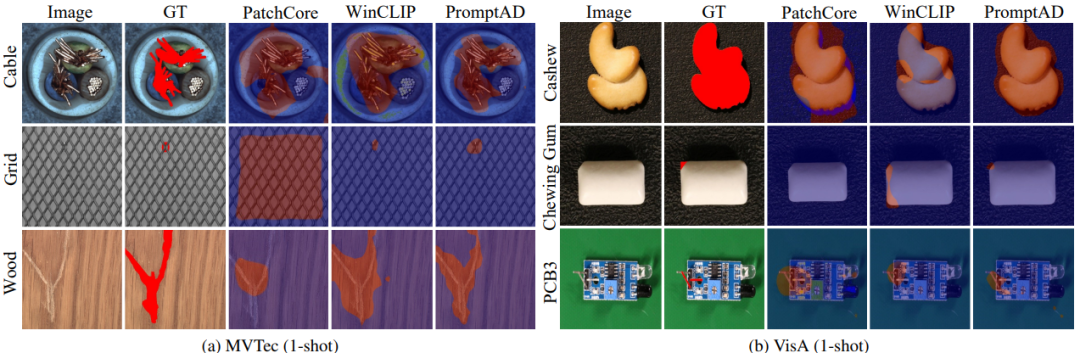
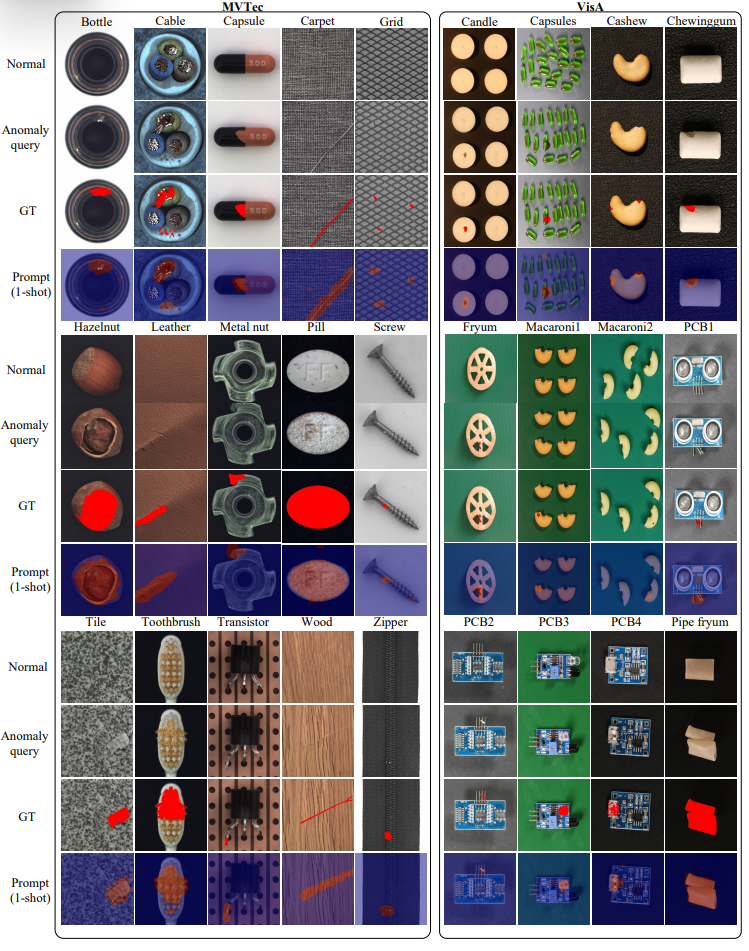
效果如何?
團隊在兩個經典工業數據集(MVTec 和 VisA)上做了測試:
在 11/12 個少樣本場景中拿下第一。
在 僅有 1 張正常樣本的條件下,PromptAD 圖像級檢測 AUROC 達 94.6%,比 WinCLIP 提高了 1.3%。
在 4 張樣本條件下,AUROC 達 96.6%,幾乎接近全監督方法的表現。







頂級父類與它的重要方法equals())
實現時間序列預測:從數據到閉環預測全解析)


)




(按鍵設置及中斷設置)

IMX6ULL 按鍵控制(輪詢 + 中斷)優化工程)

