📢博客主頁:https://blog.csdn.net/2301_779549673
📢博客倉庫:https://gitee.com/JohnKingW/linux_test/tree/master/lesson
📢歡迎點贊 👍 收藏 ?留言 📝 如有錯誤敬請指正!
📢本文由 JohnKi 原創,首發于 CSDN🙉
📢未來很長,值得我們全力奔赴更美好的生活?


文章目錄
- 🏳??🌈一、頁的大小可以設置嗎?
- 🏳??🌈二、頁都有哪些分類? 我們需要重點學習哪種頁?
- 🏳??🌈三、頁頭和頁尾具體包含了哪些信息?
- 3.1 頁頭 - File Header
- 3.2 頁尾-File Trailer
- 3.3 什么是 LSN
- 3.4 除了頁頭和頁尾,數據頁中還有哪些信息?
- 3.5 頁主體中包含哪些信息?
- 🏳??🌈四、數據行有哪些信息組成?
- 4.1 數據行是如何組織在一起的?
- 4.2 怎么標識新頁中的第一行和最后一行?
- 4.3 當向一個新頁插入數據時是如何執行的?
- 🏳??🌈五、如果要查詢的數據在某一個頁中,如何定位它在頁中的位置,一條條遍歷嗎?
- 5.1 一條條遍歷的查詢效率高不高?
- 5.2 如何提高頁內的查詢效率?頁目錄
- 🏳??🌈六、關于事務、索引這些信息在頁中怎么記錄?
- 🏳??🌈七、數據頁的完整結構是什么樣的?
- 👥總結
11111111
11111111
11111111
11111111
**** 11111111
頁 在 MySQL 運行的過程中起到了非常重要的作用,為了能發揮更好的性能,可以結合自己系統的業務場景和數據大小,對頁相關的系統變量進行調整,頁的大小就是一個非常重要的調整項。同時關于頁的結構也要有所了解,以后介紹的索引原理也是基于頁實現的。
首先來看關于頁的幾個問題。
🏳??🌈一、頁的大小可以設置嗎?
- 前面介紹了每個數據頁默認為
16KB,是操作系統"數據塊"4KB的整數倍,那么只要保證頁的大小是操作系統"數據塊"大小的整數倍是不是也可以呢,答案是肯定的。 - MySQL提供了一個專門的系統變量來控制頁的大小,可以通過系統變量
innodb_page_size進行調整與查看,在調整頁大小的時候需要保證設置的值是操作系統"數據塊"4KB的整數倍,從而保證通過操作系統和磁盤交互時"數據塊"的完整性,不被分割或浪費,所以規定了innodb_page_size可以設置的值,分別是4096、8192、16384、3276865536,對應4KB、8KB、16KB、32KB、64KB。
解答問題
可以通過系統變量
innodb_page_size進行調整與查看,但要保證設置的值是操作系統"數據塊"4KB的整數倍,MySQL規定innodb_page_size可以設置的值,分別是 40968192、16384、65536,對應4KB、32768、8KB、16KB、32KB、64KB
🏳??🌈二、頁都有哪些分類? 我們需要重點學習哪種頁?
- InnoDB在不同的使用場景定義多種不同類型的頁,常用的有數據頁、
Undo Log頁、Change Buffer頁、Extent Descriptor(XDES)頁、InnoDB段信息頁等,每種頁的數據結構都不相同,其中最需要我們關注的就是數據頁 - 由于 InnoDB 中有個概念叫 “索引即數據”,所以也叫做索引頁。
- 不論哪種類型的頁都具有
頁頭(File Header)和頁尾(File Trailer)兩個信息
🏳??🌈三、頁頭和頁尾具體包含了哪些信息?
頁頭 和 頁尾 中包含的是 用來描述文件相關的信息,如下圖所示
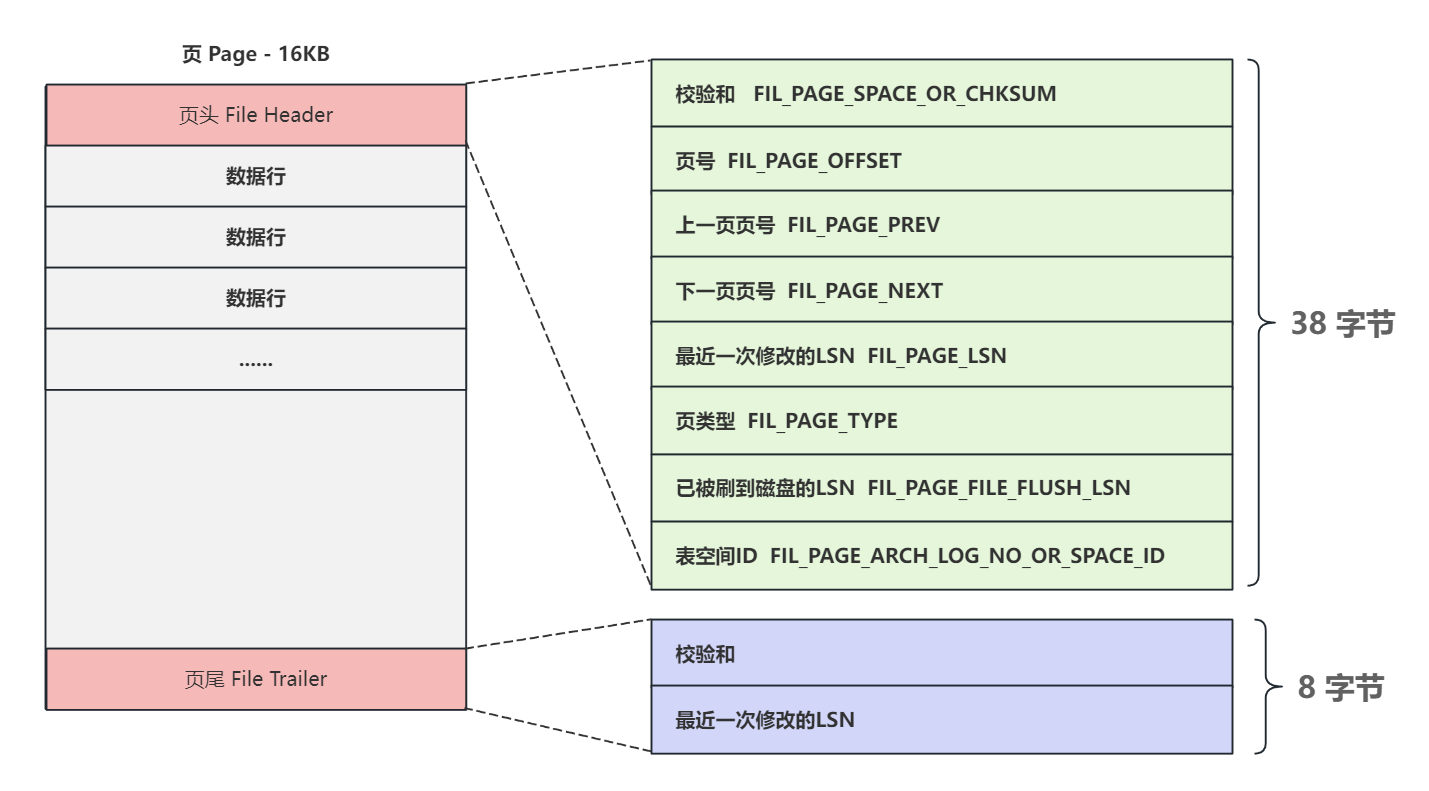

3.1 頁頭 - File Header
- 頁號:
FIL_PAGE_OFFSET占用4Byte,相當于頁的身份證號,通過這個長度可以計算出每個InnoDB表中最多可以擁有 2(4*8)-1約42億 個頁,表空間第一個頁編號從0開始,之后的頁號分別是1,2,3…依此類推,具體頁的偏移量計算公式為:頁號 * 每頁大小; 那么按照每個頁默認16KB大小計算,一個表空間最大容量為2(4*8)*16KB= 64TB,這也是InnoDB表空間最大容量是64T的原因; - 上一頁頁號:
FIL_PAGE PREV - 下一頁頁號:
FIL_PAGE_NEXT多個頁通過這兩個信息組成雙向鏈表,即使不同的頁地址不連續,也可以通過鏈表連接 - 表空間ID:
FIL PAGE_ARCH_LOG_NO_OR_SPACE_ID,當前頁屬于哪個表空間 - 頁類型:
FIL_PAGE_TYPE,數據頁對應的頁類型是 FIL_PAGEINDEX=0x45BF - 最近一次修改的LSN:
FIL_PAGE_LSN,占用8Byte - 已被刷到磁盤的LSN:
FIL_PAGE_FILE_FLUSH_LSN,占用8Byte - 校驗和:
FILPAGELSPACE_OR_CHKSUM,用于頁的完整性校驗
3.2 頁尾-File Trailer
- 近一次修改的LSN
- 校驗和: 對應頁頭中的校驗和
如果在數據傳輸的過程中數據丟失或異常中斷,導致一個數據頁不完整 就可以通過 頁頭 和 頁尾 的 校驗和 進行驗證,驗證算法默認使用 CRC32
3.3 什么是 LSN
LSN: 是"Log Sequence Number"的縮寫,表示日志序號。用 一個任意的、不斷增加的值 表示日志中記錄的操作對應的時間點,用 8字節的無符號長整形 表示,后面會詳細介紹如何生成LSN的值
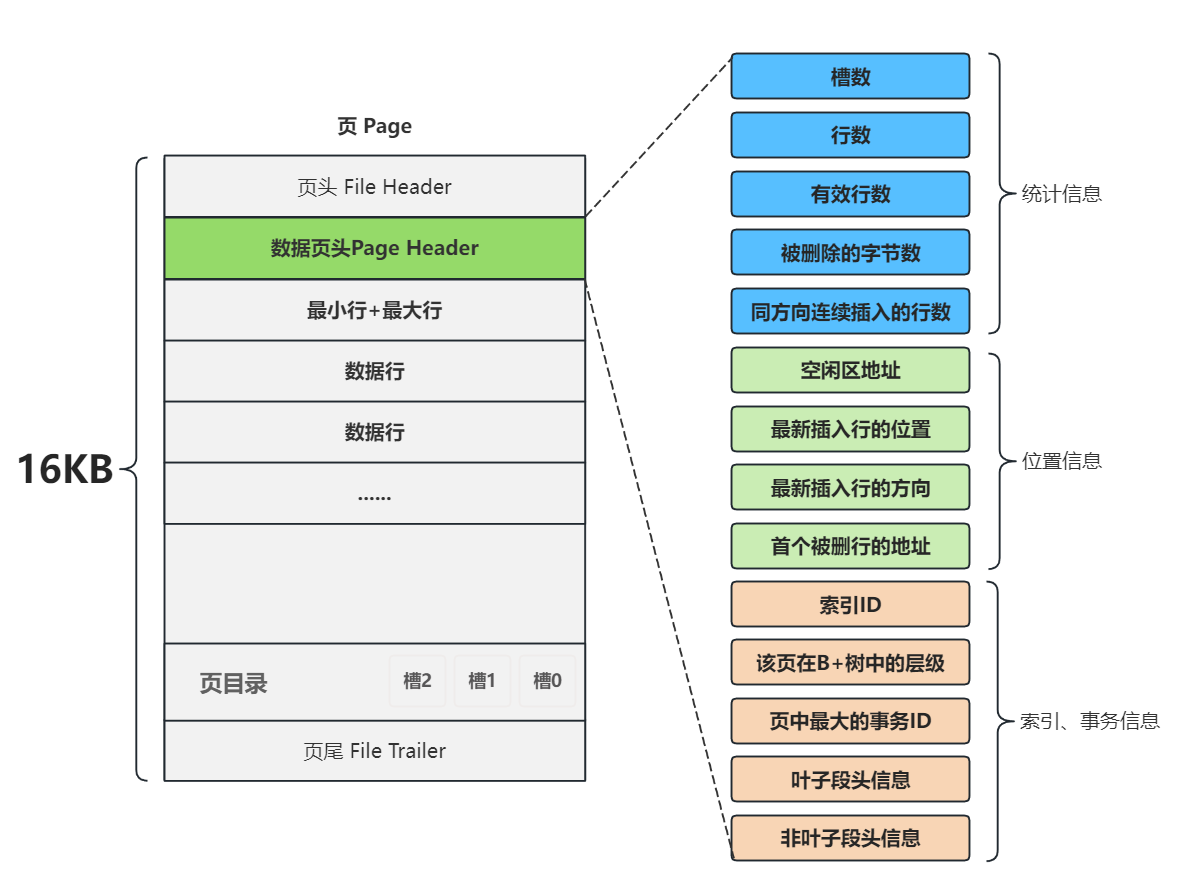
3.4 除了頁頭和頁尾,數據頁中還有哪些信息?
頁頭和頁尾中的各個字段描述了當前頁的類型以及在文件系統中的位置,也就是說通過頁頭可以找到對應的頁。數據頁的主要功能是保存數據,在一個數據頁中,除了頁頭與頁尾占用的46個字節之外的空間都用來存儲真正的數據,也就是 數據行
數據行會與表里的數據行一一對應,基于這一特性MySQL也被稱為"行式數據庫”,也可以把除了頁頭頁尾的區域稱為頁主體。
3.5 頁主體中包含哪些信息?
頁主體中的信息都是和數據相關的,
- 其中包括剛才提到了
數據行 - 還有為了提高查詢效率的頁目錄
Page Directory - 為了方便操作和管理數據頁的數據頁頭
Page Header
這又是三個非常重要的概念,接下來我們逐個討論。
🏳??🌈四、數據行有哪些信息組成?
數據行主要存儲真實數據,為了方便數據的管理與描述,InnoDB在每個數據行中還添加了一些額外(管理)信息,于是每一個 DYNAMIC 數據行都可以劃分為兩部分,一部分存儲額外信息,一部分存儲真實數據
額外信息部分包含 變長字段長度列表 和 NULL值列表 兩個大小不確定的區域,以及固定占5字節及40BIT的頭信息區域
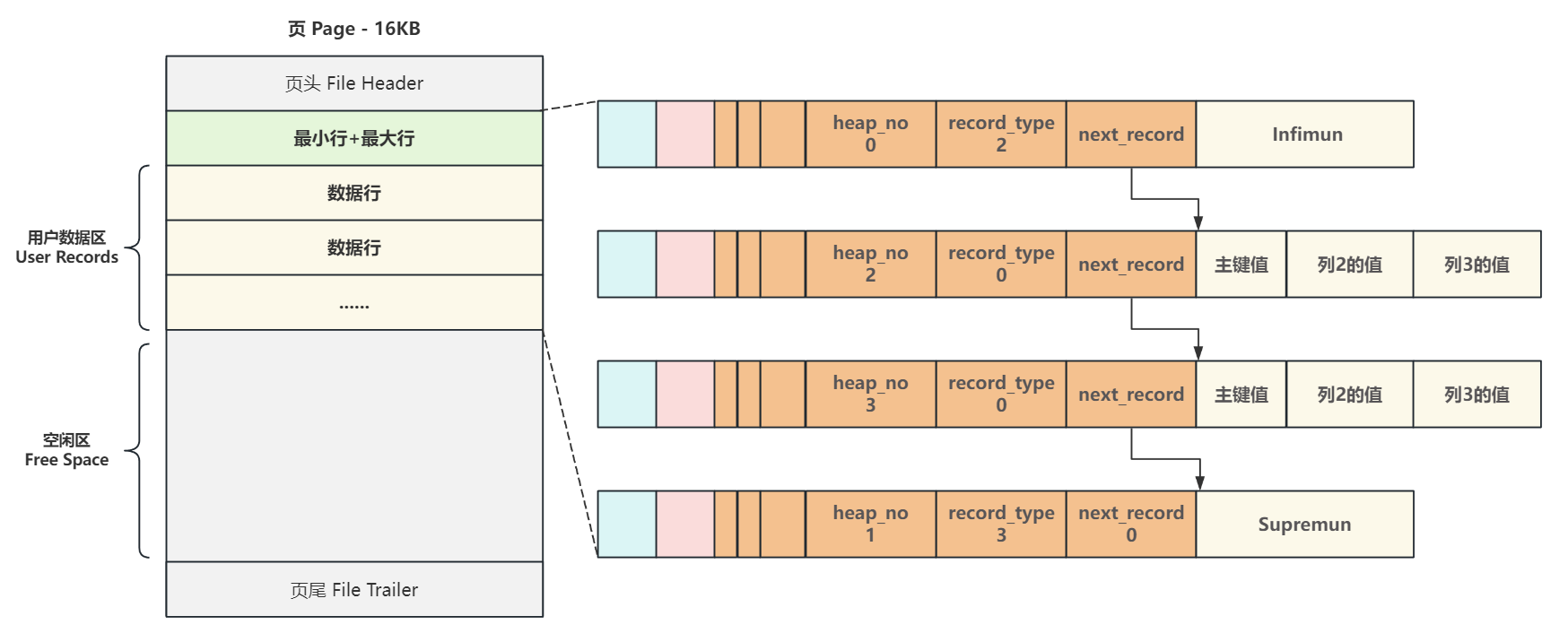
頭信息 中存儲了行的基本信息,包括行在 頁內的位置heap_no、行類型 record_type 、下一行的地址偏移量 next_record 等6項信息,
如下圖所示:
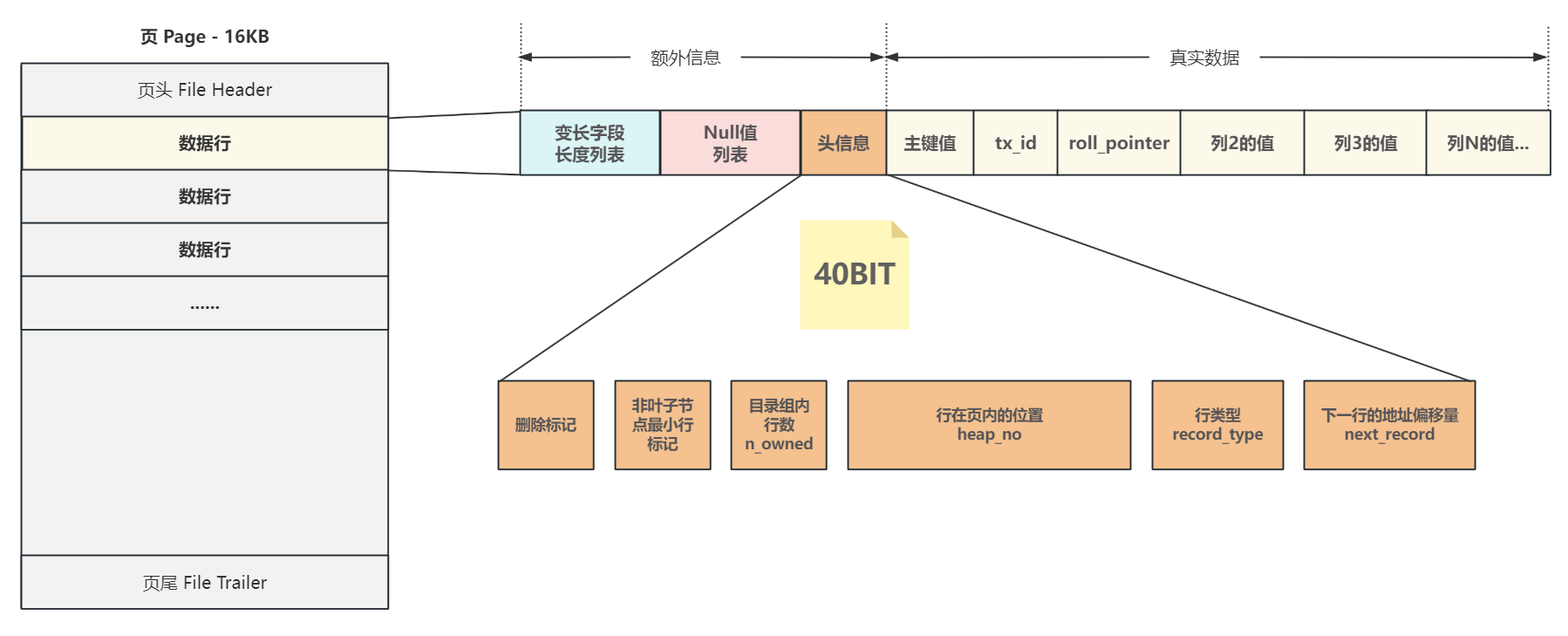
總結
- 數據行可以劃分為兩部分,一部分存儲
額外信息,一部分存儲真實數據 - 額外信息部分 包含
變長字段長度列表和NULL值列表兩個大小不確定的區域,以及固定占5字節的頭信息區域
4.1 數據行是如何組織在一起的?
數據行通過下一行的地址偏移量,即 next_record 將頁內所有數據行組成了一個單向鏈表
這里要注意的是,地址偏移量 指向的是 下一行中真實數據的起始地址,這樣做的好處是,向右是真實數據,向左就是頭信息,而無需額外的長度計算,如圖所示:
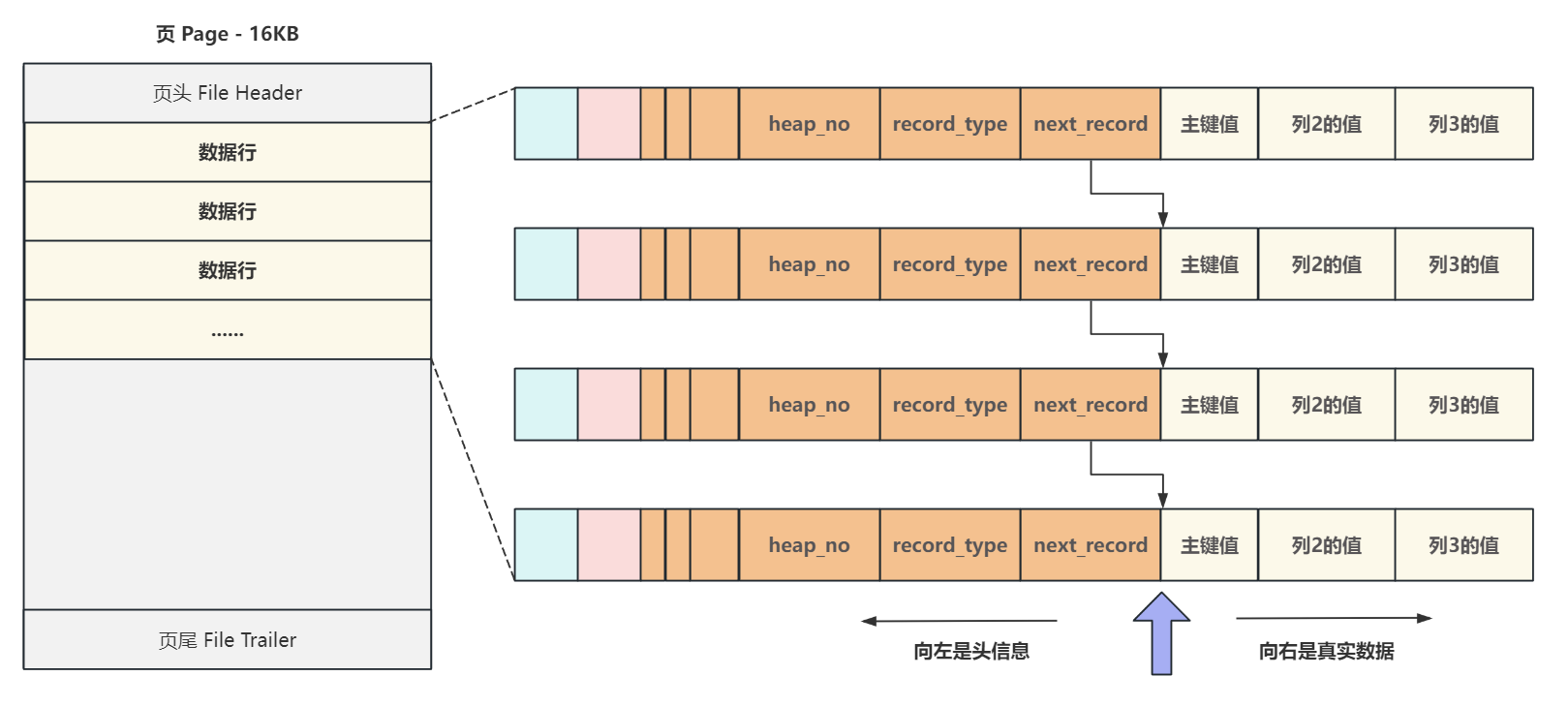

4.2 怎么標識新頁中的第一行和最后一行?
了解了行的基本結構和組織方式之后,那么當遍歷頁中的行時,從哪里開始到哪里結束呢?
為了解決這個問題,每當創建一個新頁,都會自動分配兩個行,
- 一個是行類型為2的
最小行Infimun, heap_no 位置固定為0號 - 一個是行類型為3的
最大行Supremun, heap_no 位置固定為1號
這兩個行并不存儲任何真實信息,而是做為數據行鏈表的頭和尾
雖然不存儲真實數據,但它們的數據結構和真實數據行完全一致,只不過數據區域存儲的是代表它們身份的固定字符串 Infimun 和 Supremun,新頁中沒有數據時,最小行 Infimun 的 next record 直接連接最大行 Supremun,最大行不連接任何行,它的 next_record 為 0
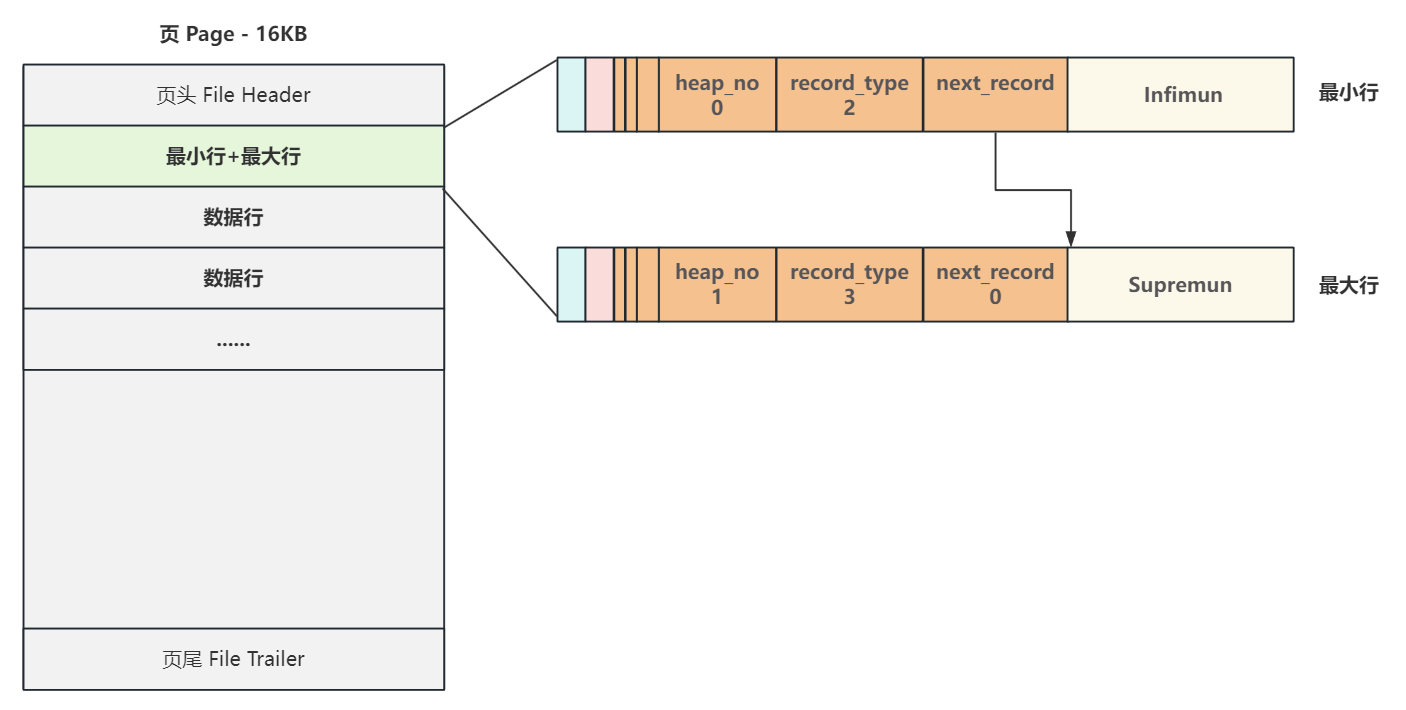
4.3 當向一個新頁插入數據時是如何執行的?
當向一個新頁插入數據時,heap_no 會 從2號開始遞增,表示當前記錄在頁面堆中的相對位置;
- 如果是真實數據則
record_type為0 - 如果是索引目錄(B+樹非葉節點)數據則
record_type為1
再將 Infimun 連接第一個數據行,最后一行真實數據行連接 Supremun ,這樣數據行就構建成了一個單向鏈表
更多的行數據插入后,會按照主鍵從小到大的順序進行鏈接;
為了使頁的結構更加清晰,通常
- 將頁中有數據行的區域稱為
用戶數據區 userRecords - 把未被數據行占用的區域稱為
空閑區Free Space
如下圖所示:
🏳??🌈五、如果要查詢的數據在某一個頁中,如何定位它在頁中的位置,一條條遍歷嗎?
當然不是,InnoDB使用了另一種方式,更高效的查詢數據,下面我們分析一下。
5.1 一條條遍歷的查詢效率高不高?
從頭開始遍歷是一個最簡單的方法,也可以實現數據的查找,當按主鍵或索引查找某條數據時,從頭行 infimun 開始,沿著鏈表順序逐個比對查找,但一個頁有16KB,通常會存在數百行數據,每次都要遍歷數百行,無法滿足高效查詢。
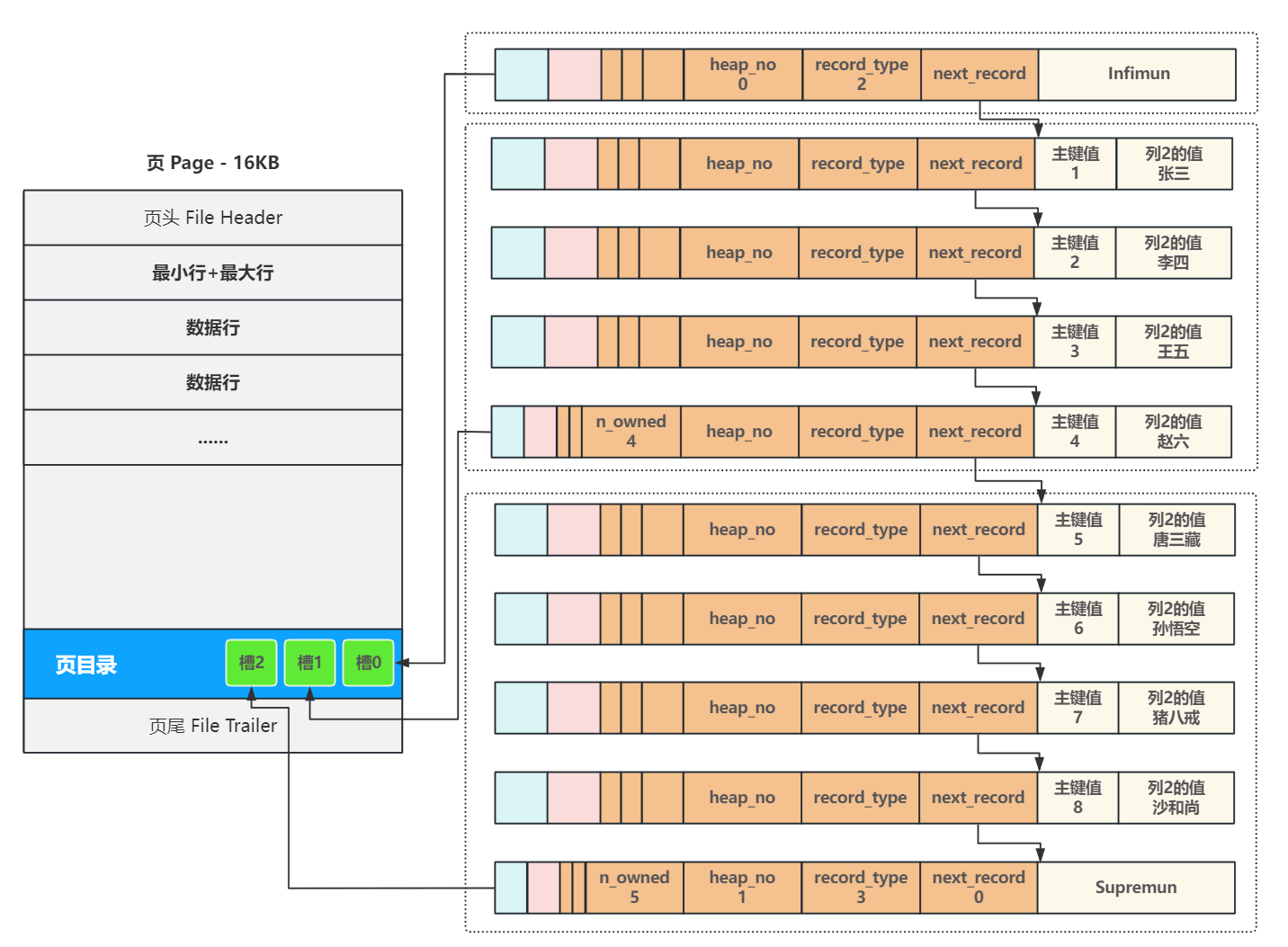
5.2 如何提高頁內的查詢效率?頁目錄
為了提高查詢效率,InnoDB 采用 二分查找 來解決查詢效率問題。
具體實現方式是,在每一個頁中加入一個叫做 頁目錄 Page Directory 的結構,將頁內包括頭行、尾行在內的所有行進行分組,約定頭行單獨為一組,其他每個組最多8條數據,同時把每個組最后一行在頁中的地址,按主鍵從小到大的順序記錄在頁目錄中
頁目錄中的每一個位置稱為一個槽,每個槽都對應了一個分組,這樣在插入數據行完成鏈接后,一旦最后一個分組中的數據行超過分組的上限8個時,就會分裂出一個新的分組,為了快速判斷每個分組是否達到了8個的上限,在每個分組最后一行中用 n_owned 記錄了這個分組內的行數,與此同時在頁目錄中創建一個新的槽,后續插入的行都遵守這個規則;
后續在查詢某行時,就可以通過二分查找,先找到對應的槽,然后在槽內最多8個數據行中進行遍歷即可,從而大幅提高了查詢效率;
例如要查找主鍵為6的行,先比對槽中記錄的主鍵值,定位到最后一個槽2,再從最后一個槽中的第一條記錄遍歷,第二條記錄就是我們要查詢的目標行。
🏳??🌈六、關于事務、索引這些信息在頁中怎么記錄?
🏳??🌈七、數據頁的完整結構是什么樣的?
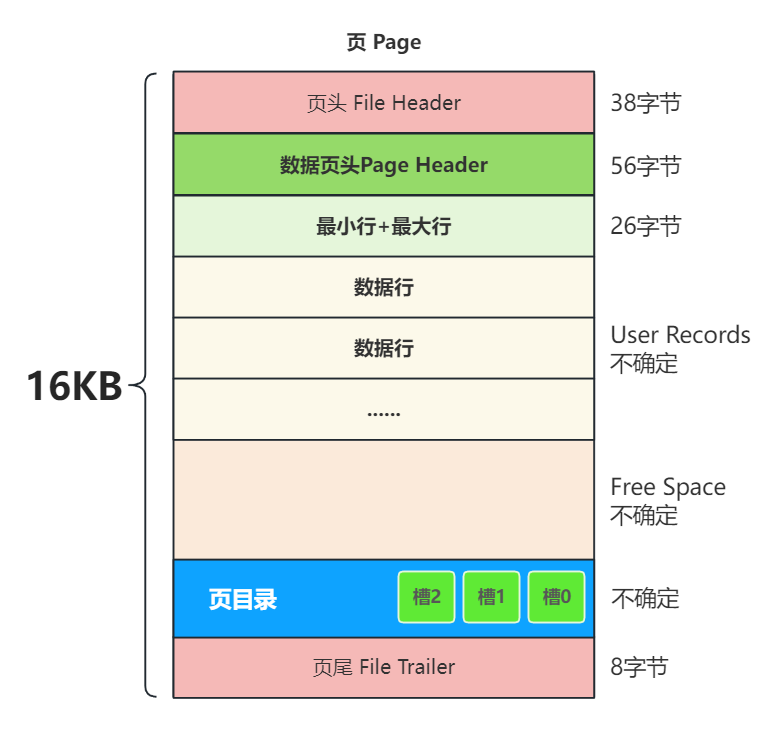
這個問題是對頁結構的總結性描述,這里也用一張圖就可以明確的表示出頁結構的整體信息
注意: 這里講的是 InnoDB 的數據頁結構,和 MyISAM 的頁結構有所不同
👥總結
本篇博文對 【MySQL】頁結構詳解:頁的大小、分類、頭尾信息、數據行、查詢、記錄及數據頁的完整結構 做了一個較為詳細的介紹,不知道對你有沒有幫助呢
覺得博主寫得還不錯的三連支持下吧!會繼續努力的~

)













)



