基本概念
cuda stream表示GPU的一個操作隊列,操作在隊列中按照一定的順序執行,也可以向流中添加一定的操作如核函數的啟動、內存的復制、事件的啟動和結束等
一個流中的不同操作有著嚴格的順序,但是不同流之間沒有任何限制
cuda stream中排隊的操作和主機都是異步的,所以排隊的過程中并不耽誤主機的執行
cuda stream的類型
cuda stream 是一種kernel外部級別的并行,包含兩種類型的流:
null stream 和 non-null stream
未定義、默認情況下使用的null stream,創建和釋放都是自動的;而non-null stream的整個過程都是需要人為定義和管理的
cuda stream的特性和范疇
基于cuda stream的異步內核啟動和數據傳輸支持以下類型的并發
- · 重疊主機和設備的計算
- · 重疊主機計算和主機設備數據傳輸
- · 重疊主機設備數據傳輸和設備計算
- · 并發多個設備計算,多個GPU
不支持并發: - · 主機端的頁鎖內存申請,cudaMallocHost
- · cudaMalloc
- · cudaMemset
- · 兩個地址向同一個設備地址的數據傳輸
- · null stream
cuda stream基本流程
cudaSteam_t steam;
cudaError_t cudaStreamCreate(&steam);
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count, cudaMemcpyKind kind, cudaStream_t stream);
kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list);
cudaError_t cudaStreamDestroy(cudaStream_t stream);
使用cuda stream加速應用程序的原理
如圖所示,假如要進行一個超大矩陣A和B的求和運算,可以將矩陣分為四份,將原始流中串行執行的數據傳輸、計算、結果傳輸過程使用四個stream來重疊一部分數據傳輸和設備計算,從而達到減少整體耗時的目的。
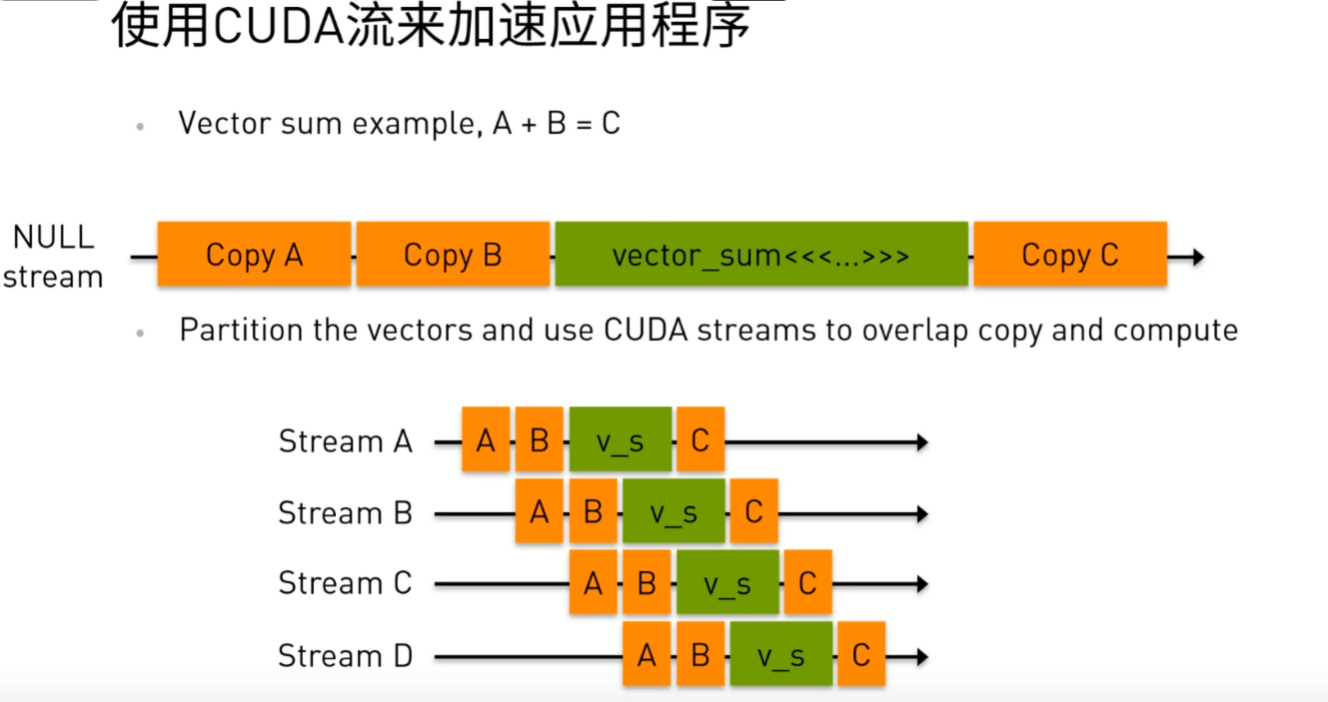
對應的代碼如下
for (int i = 0; i < nstreams; i++) {int offset = i * eles_per_stream;cudaMemcpyAsync(&d_A[offset], &h_A[offset], eles_per_stream * sizeof(int), cudaMemcpyHostToDevice, streams[i]);cudaMemcpyAsync(&d_B[offset], &h_B[offset], eles_per_stream * sizeof(int), cudaMemcpyHostToDevice, streams[i]);......vector_sum<<<... , streams[i]>>>(d_A + offset, d_B + offset, d_C + offset);cudaMemcpyAsync(&h_C[offset], &d_C[offset], eles_per_stream * sizeof(int), cudaMemcpyDeviceToHost, streams[i]);
}for (int i = 0; i < nstreams; i++)cudaStreamSynchronize(streams[i]);
其他注意點
使用cuda stream時,kernel調用的第三個參數是共享內存的配置,當使用靜態共享內存(如 shared unsigned char s_data[BLOCK_HEIGHT + 10][BLOCK_WIDTH + 10];)時,不需要在核函數調用的第三個參數中設置共享內存大小。因為靜態共享內存在編譯時就已經確定了大小,定義時直接指定了固定大小(如 [BLOCK_HEIGHT + 10][BLOCK_WIDTH + 10]),編譯器會自動為其分配內存,無需運行時指定。核函數參數中共享內存設置的作用:核函數調用的第三個參數(如 <<<grid, block, shared_size>>>)僅用于動態共享內存,動態共享內存需要在運行時指定大小,格式為 extern shared type var[];
兩者的區別:
靜態共享內存:編譯時確定大小,定義時顯式指定維度
動態共享內存:運行時確定大小,使用 extern 關鍵字聲明
// 1. 靜態共享內存(無需設置第三個參數)
__global__ void staticSharedKernel() {__shared__ unsigned char s_data[BLOCK_HEIGHT + 10][BLOCK_WIDTH + 10];// ...
}// 調用方式(無需第三個參數)
staticSharedKernel<<<gridDim, blockDim, 0, stream>>>(...);// 2. 動態共享內存(需要設置第三個參數)
__global__ void dynamicSharedKernel(int kernelSize) {extern __shared__ unsigned char s_data[]; // 不指定大小// ...
}// 調用方式(需要指定大小)
size_t sharedSize = (BLOCK_WIDTH + 2*half) * (BLOCK_HEIGHT + 2*half) * sizeof(unsigned char);
dynamicSharedKernel<<<gridDim, blockDim, sharedSize, stream>>>(kernelSize);

頂級父類與它的重要方法equals())
實現時間序列預測:從數據到閉環預測全解析)


)




(按鍵設置及中斷設置)

IMX6ULL 按鍵控制(輪詢 + 中斷)優化工程)


![[MySQL]Order By:排序的藝術](http://pic.xiahunao.cn/[MySQL]Order By:排序的藝術)



日志瀏覽)