目錄
一、python學習中兩大法寶函數
1、dir()
2、help()
二、PyTorch讀取數據集
1、Dataset類
(1)作用和基本原理
(2)常見用法
(3)自定義 Dataset 示例
2、Dataloader類
(1)作用和基本原理
(2)常見用法
(3)使用示例
3、實際案例分析
(1)數據集格式介紹
三、Tensorboard的使用
1、使用Tensorboard追蹤標量
(1)add_scalar參數說明
(2)add_scalar使用步驟
2、使用Tensorboard追蹤圖像
(1)add_image參數說明
(2)add_image使用步驟
四、transforms的使用
1、transforms 常用類
2、使用 transforms.Compose 組合多個轉換
3、transforms 的?ToTensor 類
(1)為什么在pytorch中要把數據類型轉化為?tensor?
(2)transforms 的?ToTensor 類的使用
4、transforms中的常用類
(1)ToTensor
(3)Resize
(4)RandomCrop
(2)Normalize
(5)RandomHorizontalFlip
(6)RandomVerticalFlip
(7)ColorJitter
(8)RandomRotation
(9)Grayscale
(10)RandomAffine
(11)RandomPerspective
(12)RandomErasing
(13)ToPILImage
(14)Compose
(15)Lambda
(16)FiveCrop
(17)Pad
五、 torchvision 中的 datasets
1、先來一個案例
2、torchvision.datasets 中常見數據集說明
(1)CIFAR10 和 CIFAR100
(2)MNIST
(3)ImageNet
(4)COCO (Common Objects in Context)
(5)LSUN (Large Scale Scene Understanding)
(6)FashionMNIST
(7)CelebA (CelebFaces Attributes)
(8)SVHN (Street View House Numbers)
(9)VOC (PASCAL Visual Object Classes)
(10)Kinetics
(11)總結
六、DataLoader的使用
1、DataLoader介紹
2、案例分析
(1)查看?DataLoader 輸出的數據類型
(2)將每個批都用 tensorboard 顯示
七、Pytorch中神經網絡模型搭建相關的python API?
(1)torch.nn 和?torch.nn.functional
(2)torch.nn.Module的使用
(3)torch.nn.functional.conv2d函數的使用
(4)torch.nn.Conv2d卷積層的使用
(5)torch.nn.MaxPool2d池化層的使用
(6)激活函數,非線性層
(7)線性層的使用
(8)實戰模型搭建及 nn.Sequential 的使用
(9)使用 tensorboard 完成模型的可視化
八、損失函數
(1)L1損失
(2)L2損失
(3)交叉熵損失
(4)案例
九、反向傳播與優化算法
十、現有網絡模型的使用和修改
十一、模型的保存與加載
十二、完整的模型訓練方式
十三、如何將上述模型轉到 GPU 上進行訓練
1、方法一
2、方法二
十四、模型驗證流程
一、python學習中兩大法寶函數
1、dir()
功能:打開頂層的類,或者包,查看里邊的子方法或包
例子:dir(torch):返回的是 PyTorch 的核心模塊(torch)中的方法、類和屬性。
2、help()
功能:提供說明書
例子:help(torch):會顯示關于 PyTorch torch 模塊的幫助文檔。這個文檔通常包括模塊的簡介、常用功能、方法、類等。
二、PyTorch讀取數據集
主要涉及兩個類:Dataset 和 Dataloader
1、Dataset類
????????每個 Dataset 對象都表示一個數據集,負責提供數據和標簽。可以從 PyTorch 提供的許多現成的數據集類中繼承,或者自己實現一個自定義的 Dataset。
(1)作用和基本原理
-
主要職責:定義如何讀取單個數據樣本。
-
基本接口:
-
__len__:返回數據集樣本總數。 -
__getitem__:通過索引返回一個數據樣本,通常包括數據本身和對應的標簽。
-
(2)常見用法
-
繼承
torch.utils.data.Dataset:用戶可以繼承該類并重寫__len__和__getitem__方法,實現對自定義數據格式的支持。 -
內置數據集:PyTorch 提供了很多內置的數據集,如
torchvision.datasets.MNIST、CIFAR10等,這些數據集已經封裝好了數據讀取邏輯。
(3)自定義 Dataset 示例
import torch
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self, data, labels, transform=None):self.data = dataself.labels = labelsself.transform = transformdef __len__(self):return len(self.data)def __getitem__(self, index):sample, label = self.data[index], self.labels[index]# 若有需要,可進行數據轉換if self.transform:sample = self.transform(sample)return sample, label# 示例數據
data = [i for i in range(100)]
labels = [i % 2 for i in range(100)]
dataset = MyDataset(data, labels)
在這個示例中,我們定義了一個簡單的數據集,用來說明如何實現 __len__ 和 __getitem__ 方法。
2、Dataloader類
? ?DataLoader 是 PyTorch 中用于批量加載數據的工具。它可以將數據集分割成小批次(batch),并在訓練時自動迭代這些小批次。
(1)作用和基本原理
-
主要職責:封裝 Dataset 并進行批處理、打亂數據、并行加載以及內存優化(如 pin_memory)等操作。
-
接口參數:
-
batch_size:每個 batch 的樣本數。 -
shuffle:是否在每個 epoch 開始前打亂數據。 -
num_workers:使用多少個子進程來加載數據,默認是 0(即在主進程中加載)。 -
collate_fn:用于將一個 batch 的樣本組合成一個 mini-batch,可以自定義數據如何拼接。
-
(2)常見用法
-
批處理:DataLoader 會根據
batch_size自動將樣本組合成一個 batch,方便輸入到模型中。 -
數據打亂:通過
shuffle=True可以保證每個 epoch 的數據順序不同,有助于模型訓練的穩定性和泛化性。 -
多進程加載:設置
num_workers>0后,DataLoader 會使用多個子進程來加速數據加載,尤其在數據預處理比較復雜時效果顯著。
(3)使用示例
from torch.utils.data import DataLoader# 創建 DataLoader
dataloader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=4)# 迭代數據
for batch_idx, (inputs, targets) in enumerate(dataloader):# 這里可以將 inputs 和 targets 輸入模型print(f"Batch {batch_idx}: inputs {inputs}, targets {targets}")
通過這個示例,可以看出 DataLoader 如何簡化數據加載和批處理過程。
3、實際案例分析
(1)數據集格式介紹
常見的數據集文件格式為:
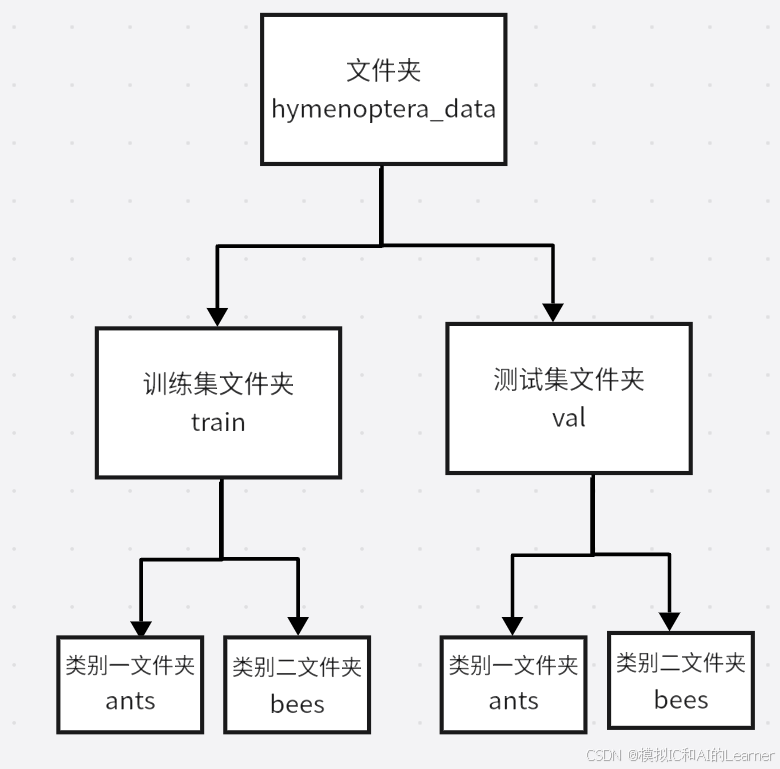
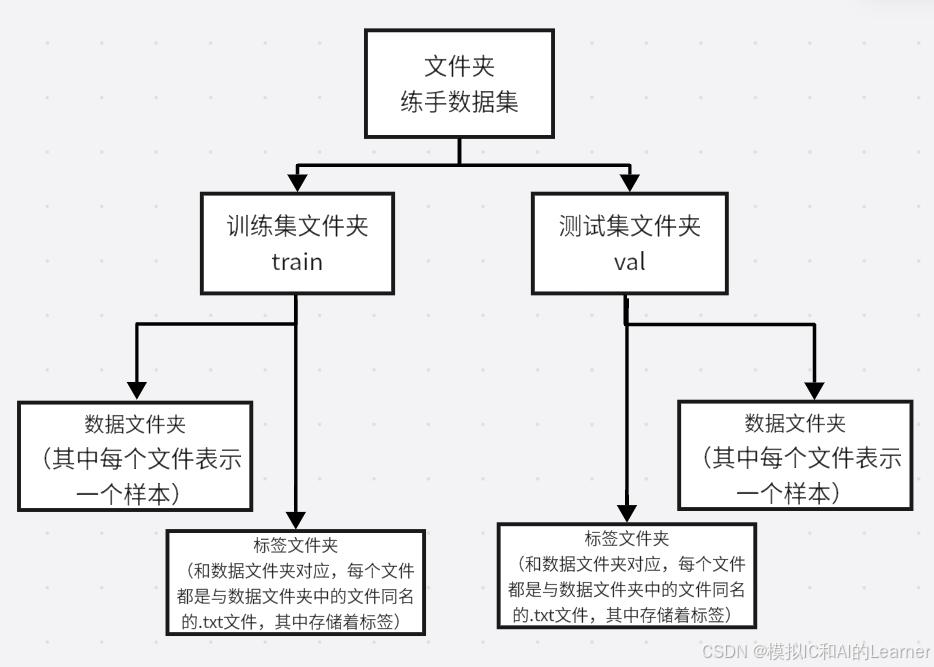
在這個案例中,數據集的格式為第一種:
下面為繼承Dataset的類MyData
import torch
import os
from torch.utils.data import Dataset
from PIL import Imageclass MyData(Dataset):def __init__(self, root_dir, label_dir):self.root_dir = root_dirself.label_dir = label_dirself.path = os.path.join(self.root_dir, self.label_dir)self.img_path = os.listdir(self.path)def __getitem__(self, idx):img_name = self.img_path[idx]img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)img = Image.open(img_item_path)label = self.label_dirreturn img, labeldef __len__(self):return len(self.img_path)實例化一個對象:
root_dir = "/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train"
ants_label_dir = "ants"
ants_dataset = MyData(root_dir,ants_label_dir)img, label = ants_dataset[0]import matplotlib.pyplot as plt
# 使用 matplotlib 顯示圖像
plt.imshow(img)
plt.axis('off') # 關閉坐標軸
plt.show()可見這個MyData類的功能是僅將訓練集中的一個類別進行了實現,下面將訓練集兩個類都實現:
root_dir = "/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)train_dataset = ants_dataset + bees_datasetimg, label = train_dataset[0]import matplotlib.pyplot as plt
# 使用 matplotlib 顯示圖像
plt.imshow(img)
plt.axis('off') # 關閉坐標軸
plt.show()三、Tensorboard的使用
????????這里主要介紹 Tensorboard 中的類?SummaryWriter ,其功能是將 PyTorch 的訓練過程中的數據(如損失值、準確率、模型權重、圖像等)寫入到事件文件中,供 TensorBoard 可視化使用。允許用戶通過在訓練中添加不同的可視化元素來跟蹤和分析模型的訓練過程。這里主要介紹?SummaryWriter 類中的兩個方法:
- add_scalar:在訓練過程中,可以記錄標量(如損失值、準確率等)并將它們寫入 TensorBoard。
- add_image:可以將圖像數據(如輸入圖像、模型生成的圖像等)寫入 TensorBoard。
1、使用Tensorboard追蹤標量
(1)add_scalar參數說明
add_scalar(tag, scalar_value, global_step=None, walltime=None)
1. tag(必需)
-
類型:
str -
說明: 數據的標簽,通常是你希望記錄的標量的名稱。這個標簽將用于 TensorBoard 中的圖表名稱。例如,
'Loss/train'或'Accuracy/test'。 -
示例:
'Loss/train'、'Accuracy/test'
2. scalar_value(必需)
-
類型:
float或int -
說明: 要記錄的標量值。通常是一個單一的數值,例如模型的損失值或準確率。
-
示例:
0.5(損失值),0.75(準確率)
3. global_step(可選)
-
類型:
int或None -
說明: 用于標記標量值的全局步數(如 epoch 或 batch 的編號)。它用于指定該標量值對應的訓練步驟,TensorBoard 會根據此步數來顯示數據的變化。通常,你會將
global_step設置為當前 epoch 或 batch 數。 -
默認值:
None,表示沒有指定步驟。 -
示例:
epoch或batch編號,例如global_step=epoch。
4. walltime(可選)
-
類型:
float或None -
說明: 用于指定記錄的時間戳(單位為秒)。如果你不指定,
SummaryWriter會自動使用當前的時間戳。這對于同步時間序列數據非常有用,但通常不需要手動設置。 -
默認值:
None,表示使用當前時間。
返回值
-
返回值: 無,
add_scalar方法是一個副作用方法,只會將數據寫入事件文件中。
(2)add_scalar使用步驟
導入SummaryWriter類:
from torch.utils.tensorboard import SummaryWriter初始化SummaryWriter:
writer = SummaryWriter('logs')????????注:參數"logs"表示將事件寫入logs文件夾中
add_scalar的使用:
writer.add_scalar('Loss/train', loss, epoch)
writer.add_scalar('Accuracy/train', accuracy, epoch)? ? ? ? 注:第一個參數是圖像的標題,第二個參數是要可視化的標量,即圖像的y軸,第三個參數是圖像的x軸。
關閉:
writer.close()啟動 TensorBoard窗口:
# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs代碼放一塊的小案例為:
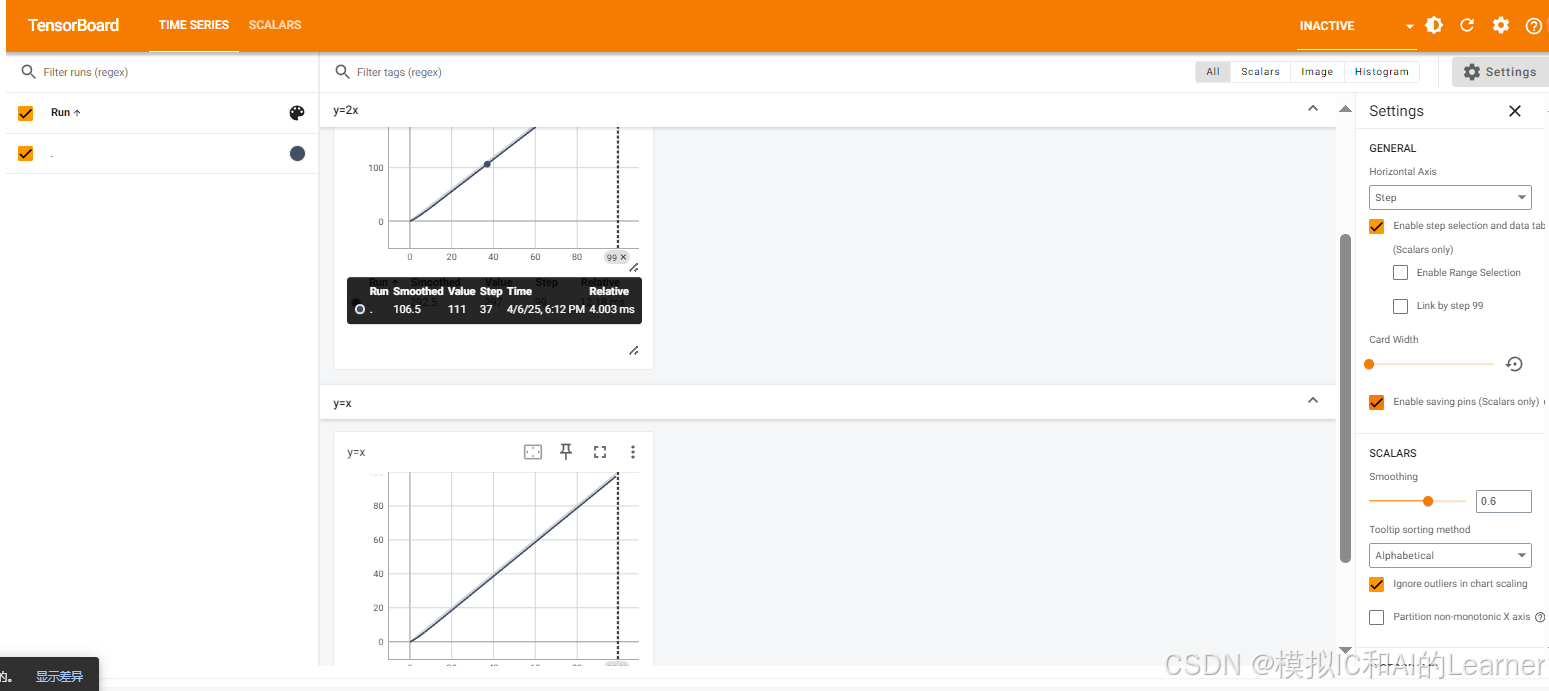
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter('logs')for i in range(100):writer.add_scalar("y=x",i,i)writer.add_scalar("y=2x",2*i,i)writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs結果:
2、使用Tensorboard追蹤圖像
(1)add_image參數說明
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
1. tag(必需)
-
類型:
str -
說明: 圖像的標簽,通常是你希望在 TensorBoard 中顯示的圖像名稱。這個標簽用于在 TensorBoard 中標識圖像,通常是一個字符串,例如
'Image/sample'。 -
示例:
'Image/train_input','Model_output'
2. img_tensor(必需)
-
類型:
Tensor(PyTorch tensor) -
說明: 你要記錄的圖像數據,必須是一個 PyTorch tensor(也可以是numpy.array)。這個 tensor 應該具有以下形狀之一:
-
(C, H, W):適用于單張圖像,其中C是通道數(例如 3 表示 RGB),H是高度,W是寬度。 -
(B, C, H, W):適用于一批圖像,其中B是批次大小,C是通道數,H是高度,W是寬度。
圖像數據的值應該在 [0, 1] 或 [-1, 1] 范圍內。如果數據值不在此范圍內,TensorBoard 可能無法正確顯示圖像。
-
-
示例:
img_tensor = torch.rand(3, 64, 64)(生成一張隨機圖像,3 通道,64x64 像素)
3. global_step(可選)
-
類型:
int或None -
說明: 用于標記圖像記錄的全局步驟(通常是 epoch 或 batch 編號)。TensorBoard 會根據此步驟顯示圖像。例如,你可以使用
global_step=epoch來記錄每個 epoch 的圖像,或者使用global_step=batch來記錄每個 batch 的圖像。 -
默認值:
None,表示沒有指定步驟。 -
示例:
global_step=epoch
4. walltime(可選)
-
類型:
float或None -
說明: 用于指定記錄的時間戳(單位為秒)。如果你不指定,
SummaryWriter會自動使用當前時間戳。通常情況下,除非有特殊需求,否則不需要手動設置。 -
默認值:
None,表示使用當前時間。
5. dataformats(可選)
-
類型:
str -
說明: 用于指定圖像數據的格式。它指定了輸入 tensor 的維度順序。通常有兩種格式:
-
'CHW':圖像數據格式為 (C, H, W),其中 C 是通道數,H 是高度,W 是寬度。常用于單張圖像。 -
'NHWC':圖像數據格式為 (N, H, W, C),其中 N 是批次大小,H 是高度,W 是寬度,C 是通道數。常用于一批圖像。
如果你傳入的是一張圖像,通常使用
'CHW'格式;如果傳入的是一批圖像,通常使用'NHWC'格式。 -
-
默認值:
'CHW' -
示例:
'CHW'或'NHWC'
返回值
-
返回值: 無,
add_image是一個副作用方法,數據被寫入事件文件中,不會返回任何內容。
(2)add_image使用步驟
導入SummaryWriter類:
from torch.utils.tensorboard import SummaryWriter初始化SummaryWriter:
writer = SummaryWriter('logs')????????注:參數"logs"表示將事件寫入logs文件夾中
add_image的使用:
????????加載圖片:
image_path = "/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train/ants/0013035.jpg"
from PIL import Image
img = Image.open(image_path)
print(type(img))
# 輸出為:<class 'PIL.JpegImagePlugin.JpegImageFile'>? ? ? ? 輸出的img類型不符合?add_image?傳入參數的類型,需要將 img 類型轉為?PyTorch tensor(或是numpy.array),下面代碼將 img 轉為了numpy.array,如果要用PyTorch tensor類型可使用transforms中的ToTensor類進行轉化。
# 將img轉為numpy類型
import numpy as np
img_array = np.array(img)
print(type(img_array))
# 輸出為:<class 'numpy.ndarray'>接下來調用?add_image:
writer.add_image("test",img_array,1,dataformats='HWC')writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs結果為:
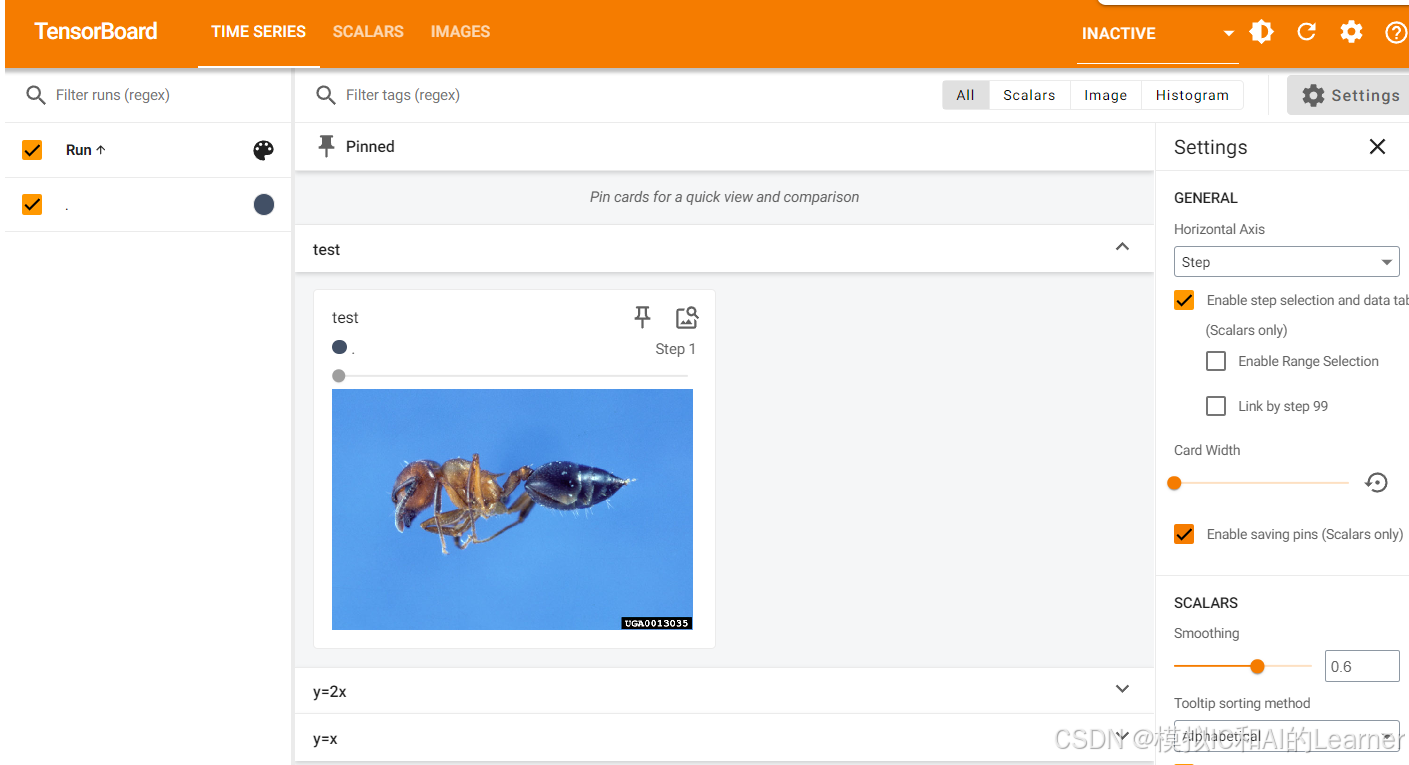
????????當在同一個標題下傳入TensorBoard 多個圖像時(設置不同序號,即第三個參數),可拖動進度條查看圖像的漸變過程。當改變標題時,會另開一個圖像窗口。
四、transforms的使用
是一個對圖像數據進行處理的工具箱,其中有很多有關圖像處理的類。
????????在 PyTorch 中,torchvision.transforms 提供了許多圖像處理的常用操作,能夠在數據預處理過程中自動對圖像進行轉換。常見的用途包括圖像增強、歸一化、裁剪、旋轉、調整大小等。這些轉換操作可以幫助你在訓練神經網絡時處理圖像數據。
1、transforms 常用類
-
Resize:調整圖像的大小。 -
CenterCrop:對圖像進行中心裁剪。 -
RandomCrop:隨機裁剪圖像。 -
RandomHorizontalFlip:隨機水平翻轉圖像。 -
ToTensor:將圖像轉換為 PyTorch Tensor(同時將像素值從 [0, 255] 轉換為 [0, 1] 的范圍)。 -
Normalize:對圖像進行歸一化處理。 -
ColorJitter:隨機調整圖像的亮度、對比度、飽和度和色調。 -
RandomRotation:隨機旋轉圖像。
2、使用 transforms.Compose 組合多個轉換
transforms.Compose 是一個非常方便的工具,它可以將多個圖像處理操作按順序組合成一個管道,從而在數據加載時一次性應用所有轉換。
import torch
from torchvision import transforms
from PIL import Image# 加載一個示例圖像
img = Image.open('sample_image.jpg')# 定義一個轉換組合
transform = transforms.Compose([transforms.Resize((128, 128)), # 調整圖像大小transforms.RandomHorizontalFlip(), # 隨機水平翻轉transforms.ToTensor(), # 轉換為 Tensortransforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 歸一化
])# 應用轉換
img_tensor = transform(img)print(img_tensor.shape) # 打印轉換后的圖像大小
3、transforms 的?ToTensor 類
(1)為什么在pytorch中要把數據類型轉化為?tensor?
tensor數據類型的數據有很多屬性和方法(如梯度、設備、形狀、維度等),便于在神經網絡中使用。
import torch
tensor = torch.tensor([1.0, 2.0, 3.0])
print(dir(tensor)) # 輸出: 輸出為:
['dtype','device','shape','dim()','requires_grad','grad','is_cuda','is_leaf','is_floating_point()',.......]
查看某tensor變量的屬性:
import torch# 創建一個示例張量
tensor = torch.randn(3, 4, 5, device='cuda', requires_grad=True)# 查看屬性函數
print(f"張量的設備: {tensor.device}") # 輸出: cuda:0
print(f"張量的形狀: {tensor.shape}") # 輸出: torch.Size([3, 4, 5])
print(f"張量的維度數: {tensor.ndimension()}") # 輸出: 3
print(f"是否需要梯度計算: {tensor.requires_grad}") # 輸出: True
print(f"張量的類型: {tensor.dtype}") # 輸出: torch.float32
print(f"是否在 GPU 上: {tensor.is_cuda}") # 輸出: True
print(f"是否為葉子節點: {tensor.is_leaf}") # 輸出: True
print(f"張量的元素個數: {tensor.numel()}") # 輸出: 60
(2)transforms 的?ToTensor 類的使用
功能:將兩種非 tensor 類型的圖像數據轉化為 tensor 類型
下面是其使用示例:
# 掛載 Google Drive以實現數據集的獲取,
from google.colab import drive
drive.mount('/content/drive')from PIL import Image
from torchvision import transforms
#python的用法 -》 tensor數據類型img_path = "/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train/ants/0013035.jpg"
# 使用Image讀取到的類型是<class 'PIL.JpegImagePlugin.JpegImageFile'>
img = Image.open(img_path) # transforms該如何使用,以其中的ToTensor類為例# 使用ToTensor類將"<class 'PIL.JpegImagePlugin.JpegImageFile'>"類型的圖像數據轉化為Tensor類型
tensor_trans = transforms.ToTensor()
tensor_img_1 = tensor_trans(img)
print(tensor_img)
print("-------------------------------------------------------------------------------------------------------------")# 使用ToTensor類將"<class 'numpy.ndarray'>"類型的圖像數據轉化為Tensor類型
import cv2
# 使用cv2讀取到的類型是<class 'numpy.ndarray'>
cv_img = cv2.imread(img_path)
tensor_trans = transforms.ToTensor()
tensor_img_2 = tensor_trans(cv_img)
print(tensor_img_2)
print("-------------------------------------------------------------------------------------------------------------")4、transforms中的常用類
遇到一個transforms中的常用類應該關注的點:
- 關注輸入與輸出類型
- 多看官方文檔:eg:help(
transforms.ToTensor)
幾個類的使用方法案例:
# 掛載 Google Drive以實現數據集的獲取,
from google.colab import drive
drive.mount('/content/drive')from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms# 創建 SummaryWriter 對象,指定日志文件夾
writer = SummaryWriter("logs")
# 打開圖像
img = Image.open("/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train/ants/0013035.jpg")
print(img)# 將圖像轉換為 Tensor
trans_to_tensor = transforms.ToTensor()
img_tensor = trans_to_tensor(img)
# 在 TensorBoard 中添加 ToTensor 圖像
writer.add_image("ToTensor", img_tensor)
# 打印轉換后的圖像的第一個通道的第一個像素值
print(img_tensor[0][0][0])# 對圖像進行歸一化處理 Normalize
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
# 打印歸一化后的圖像的第一個通道的第一個像素值
print(img_norm[0][0][0])
# 在 TensorBoard 中添加 Normalize 圖像
writer.add_image("Normalize", img_norm)# 類Resize的使用
print(img.size)
trans_resize = transforms.Resize((256, 256))
# 使用 Resize 轉換圖像 -> 輸入和輸出的圖像類型都為 PIL
img_resize = trans_resize(img)
# 將 PIL 圖像轉換為 Tensor -> img_resize tensor
img_resize = trans_to_tensor(img_resize)
# 上一步的原因是下面這一步add_image的輸入只接受tensor或np.darray類型的圖像
writer.add_image("Resize", img_resize, 0)
print(img_resize.shape)# 類 Compose 和 Resize(只傳入一個參數) 的使用
trans_resize_2 = transforms.Resize(256) #一個參數不會改變圖像的寬長比
# 使用 Compose 將多個轉換結合起來
trans_compose = transforms.Compose([trans_resize_2, trans_to_tensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
print(img_resize_2.shape)#隨機裁剪
# RandomCrop
# 參數為一個序列的話是指定裁剪的大小,參數為一個int類型數字的話是裁剪為正方形
trans_random = transforms.RandomCrop(256)
# 使用 RandomCrop 轉換圖像 -> 輸入和輸出的圖像類型都為 PIL
trans_compose_2 = transforms.Compose([trans_random, trans_to_tensor])
# 生成 10 張隨機裁剪的圖像
for i in range(10):img_crop = trans_compose_2(img)writer.add_image("RandomCrop", img_crop, i)# 關閉 writer
writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs(1)ToTensor
(3)Resize
(4)RandomCrop
-
功能:將 PIL 圖像或
numpy.ndarray轉換為 PyTorch 的張量。張量的值范圍會從 [0, 255] 轉換為 [0.0, 1.0]。 -
示例:
from torchvision import transforms from PIL import Imageimg = Image.open("image.jpg") transform = transforms.ToTensor() img_tensor = transform(img)(2)
Normalize -
功能:對圖像的每個通道進行標準化,使其具有指定的均值和標準差。
-
要點:輸入只能是 tensor image 類型,不能是?PIL Image,輸出是 tensor image 類型。
-
示例:
transform = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) img_normalized = transform(img_tensor) -
功能:調整圖像的大小。可以指定新的寬度和高度,或者只指定一個邊長,按比例調整。
-
要點:輸入和輸出的圖像類型都為 PIL?Image,輸入參數是序列的話代表的是裁剪后的圖像的尺寸,如果輸入是一個 int 類型數字的話,裁剪不會改變寬長比。
-
示例:
transform = transforms.Resize((256, 256)) img_resized = transform(img) -
功能:隨機裁剪圖像的一個區域。可以指定裁剪后的大小。
-
要點:輸入和輸出的圖像類型都為 PIL?Image,輸入參數是序列的話代表的是裁剪后的圖像的尺寸,如果輸入是一個 int 類型數字的話,裁剪后為正方形(這點和
Resize不一樣)。 -
示例
transform = transforms.RandomCrop(256) img_cropped = transform(img)
(5)RandomHorizontalFlip
-
功能:隨機水平翻轉圖像,通常用于數據增強。
-
示例:
transform = transforms.RandomHorizontalFlip(p=0.5) # p 表示翻轉的概率 img_flipped = transform(img)
(6)RandomVerticalFlip
-
功能:隨機垂直翻轉圖像,通常用于數據增強。
-
示例:
transform = transforms.RandomVerticalFlip(p=0.5) img_flipped = transform(img)
(7)ColorJitter
-
功能:隨機改變圖像的亮度、對比度、飽和度和色調,常用于數據增強。
-
示例:
transform = transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2) img_jittered = transform(img)
(8)RandomRotation
-
功能:隨機旋轉圖像一定角度范圍內的角度。
-
示例:
transform = transforms.RandomRotation(30) # 旋轉范圍在 -30 到 30 度之間 img_rotated = transform(img)
(9)Grayscale
-
功能:將圖像轉換為灰度圖像,可以指定輸出的通道數。
-
示例:
transform = transforms.Grayscale(num_output_channels=1) img_gray = transform(img)
(10)RandomAffine
-
功能:對圖像應用隨機的仿射變換,包括平移、縮放、旋轉等操作。
-
示例:
transform = transforms.RandomAffine(degrees=30, translate=(0.1, 0.1)) img_affine = transform(img)
(11)RandomPerspective
-
功能:應用隨機的透視變換,常用于增強圖像的多樣性。
-
示例:
transform = transforms.RandomPerspective(distortion_scale=0.5, p=1.0, interpolation=3) img_perspective = transform(img)
(12)RandomErasing
-
功能:隨機擦除圖像的一部分,通常用于數據增強。
-
示例:
transform = transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3)) img_erased = transform(img)
(13)ToPILImage
-
功能:將 PyTorch 張量轉換回 PIL 圖像。
-
示例:
transform = transforms.ToPILImage() img_pil = transform(img_tensor)
(14)Compose
-
功能:將多個圖像轉換操作組合在一起,使得可以按順序執行多個操作。常用于組合多個預處理步驟。
-
示例:
transform = transforms.Compose([transforms.Resize(256),transforms.RandomCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) img_transformed = transform(img)
(15)Lambda
-
功能:對圖像應用一個自定義的轉換函數。
-
示例:
transform = transforms.Lambda(lambda x: x / 255.0) img_normalized = transform(img_tensor)
(16)FiveCrop
-
功能:將圖像裁剪為四個角的裁剪區域和中心裁剪區域。
-
示例:
transform = transforms.FiveCrop(224) img_crops = transform(img)
(17)Pad
-
功能:對圖像進行填充,添加指定的像素寬度或指定的填充模式。
-
示例:
transform = transforms.Pad(10) # 為圖像四周填充 10 像素 img_padded = transform(img)
五、 torchvision 中的 datasets
1、先來一個案例
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform = dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform = dataset_transform, download=True)'''
print(test_set[0])
print(test_set.classes)img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])import matplotlib.pyplot as plt
# 使用 matplotlib 顯示圖像
plt.imshow(img)
plt.axis('off') # 關閉坐標軸
plt.show()'''writer = SummaryWriter("logs")
for i in range(10):img, target = test_set[i]writer.add_image("test_set", img, i)# 關閉 writer
writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs2、torchvision.datasets 中常見數據集說明
? ?torchvision.datasets 是 PyTorch 中一個重要的模塊,提供了各種常用的標準數據集。通過這個模塊,用戶可以輕松地加載和處理圖像數據集,尤其是用于圖像分類、目標檢測、分割等任務。datasets 模塊中的數據集大多都經過了處理,包含了下載、預處理和轉換等功能。
以下是一些常見的 torchvision.datasets 數據集及其簡要介紹:
(1)CIFAR10 和 CIFAR100
-
功能:這兩個數據集是廣泛用于圖像分類任務的小型數據集。
-
CIFAR-10:包含 10 個類別,每個類別 6,000 張 32x32 的彩色圖像。
-
CIFAR-100:包含 100 個類別,每個類別 600 張圖像,圖像的尺寸為 32x32。
-
用法:
from torchvision import datasets, transforms# 進行數據預處理(例如將圖像轉換為張量并標準化) transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ])# 加載 CIFAR10 數據集 train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
(2)MNIST
-
功能:MNIST 是一個經典的手寫數字數據集,包含 28x28 像素的灰度圖像,分為 10 類(0-9)。
-
用法:
from torchvision import datasets, transforms# 定義數據轉換 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])# 下載訓練集和測試集 train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
(3)ImageNet
-
功能:ImageNet 是一個包含超過 1400 萬張圖像和 1000 個類別的大型數據集。它廣泛應用于圖像分類任務,并且是計算機視覺領域的標準數據集之一。
-
用法:
from torchvision import datasets, transforms# 數據預處理 transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ])# 加載 ImageNet 數據集 train_dataset = datasets.ImageNet(root='./data', split='train', download=True, transform=transform) val_dataset = datasets.ImageNet(root='./data', split='val', download=True, transform=transform)
(4)COCO (Common Objects in Context)
-
功能:COCO 是一個大型圖像數據集,包含了 80 類常見物體,并提供了目標檢測、實例分割、人體關鍵點檢測等標注。它適用于更復雜的計算機視覺任務。
-
用法:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor()])# 加載 COCO 數據集 coco_train = datasets.CocoDetection(root='./data', annFile='./data/annotations/instances_train2017.json', transform=transform) coco_val = datasets.CocoDetection(root='./data', annFile='./data/annotations/instances_val2017.json', transform=transform)
(5)LSUN (Large Scale Scene Understanding)
-
功能:LSUN 是一個面向場景理解的大型數據集,包含了多個不同場景類別的圖像。適用于圖像分類和生成模型任務。
-
用法:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor()])# 加載 LSUN 數據集 lsun_train = datasets.LSUN(root='./data', classes=['train'], transform=transform)
(6)FashionMNIST
-
功能:FashionMNIST 是一個包含 28x28 灰度圖像的數據集,用于服裝分類任務。與 MNIST 類似,但其分類對象為衣物和配飾。
-
用法:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform) test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
(7)CelebA (CelebFaces Attributes)
-
功能:CelebA 是一個包含 20 多萬張名人面孔的圖像數據集,廣泛用于人臉識別、面部屬性預測等任務。每張圖像有 40 個屬性標簽(如是否有胡子、是否戴眼鏡等)。
-
用法:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor()])# 加載 CelebA 數據集 celebA = datasets.CelebA(root='./data', split='train', download=True, transform=transform)
(8)SVHN (Street View House Numbers)
-
功能:SVHN 是一個由街景圖像中提取的數字數據集,目標是對數字進行分類。它的圖像大小是 32x32 像素,包含了較為復雜的背景。
-
用法:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])# 下載和加載 SVHN 數據集 train_dataset = datasets.SVHN(root='./data', split='train', download=True, transform=transform) test_dataset = datasets.SVHN(root='./data', split='test', download=True, transform=transform)
(9)VOC (PASCAL Visual Object Classes)
-
功能:PASCAL VOC 是一個包含多種物體類別的圖像數據集,廣泛用于目標檢測、語義分割等任務。它包含 20 個物體類別,并且每個類別都有對應的標注數據。
-
用法:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor()])# 加載 PASCAL VOC 數據集 voc_train = datasets.VOCDetection(root='./data', year='2012', image_set='train', download=True, transform=transform)
(10)Kinetics
-
功能:Kinetics 是一個視頻數據集,包含了許多動作分類的視頻。適用于動作識別和視頻分析任務。
-
用法:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor()])# 加載 Kinetics 數據集 kinetics_train = datasets.Kinetics400(root='./data', split='train', download=True, transform=transform)
(11)總結
torchvision.datasets 提供了廣泛的常用數據集,涵蓋了從簡單的圖像分類(如 MNIST 和 CIFAR)到更復雜的圖像識別、目標檢測和視頻分析(如 COCO 和 Kinetics)等任務。使用 torchvision.datasets,用戶可以方便地下載和處理數據集,并進行標準化、裁剪、翻轉等常見的圖像預處理操作。通過這些數據集,用戶可以快速啟動并實驗各種計算機視覺任務。
六、DataLoader的使用
1、DataLoader介紹
在 PyTorch 中,DataLoader 是一個非常重要的工具,用于加載數據集,并且提供了批量加載、數據打亂、并行處理等功能。通過 DataLoader,我們可以更高效地加載訓練和測試數據,尤其是在深度學習模型的訓練過程中。
DataLoader 的基本作用:
DataLoader 用于從數據集(例如 torchvision.datasets 提供的數據集或自定義數據集)中按批次加載數據,并返回每個批次的數據。這使得我們在訓練模型時能夠輕松地處理大規模數據集。
DataLoader 構造函數參數
DataLoader 的常用參數如下:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0,worker_init_fn=None)
1. dataset:
-
這個參數指定了數據集,可以是任何繼承自
torch.utils.data.Dataset類的對象。DataLoader將從這個數據集對象中獲取數據。 -
示例:
train_dataset、test_dataset或自定義的數據集類。
2. batch_size:
-
每個批次包含的樣本數量。通常,批量大小取決于系統的內存限制和訓練的需求。
-
示例:
batch_size=32表示每次加載 32 張圖像。
注意:較大的批量大小通常能加速訓練,但需要更多的內存。較小的批量大小則會降低內存占用,但可能會減慢訓練速度。
3. shuffle:
-
如果設置為
True,每個epoch結束后會打亂數據集中的數據。通常在訓練時使用此參數以提高模型的泛化能力。 -
示例:
shuffle=True用于訓練集,以確保每次訓練時數據順序不同。
4. sampler 和 batch_sampler:
-
這兩個參數允許用戶定義如何抽樣數據。
sampler是一種自定義的方式,決定數據的順序,而batch_sampler則決定如何組合這些數據成批次。 -
通常情況下,用戶不需要直接使用這兩個參數。
5. num_workers:
-
定義用于加載數據的子進程數量。
num_workers設置為大于 0 的數字時,DataLoader將使用多進程加載數據。設置為 0 時,數據將通過主進程加載。 -
提高
num_workers可以加速數據加載,但也可能增加系統的 CPU 負載。通常在具有多個 CPU 核心的機器上會設置為更高的數字。 -
示例:
num_workers=4表示使用 4 個子進程來加載數據。
6. collate_fn:
-
collate_fn是一個函數,用于將多個樣本組合成一個批次。默認情況下,DataLoader會簡單地將一個批次的數據堆疊在一起。然而,如果你的數據樣本是復雜的(例如不同大小的圖像或多模態數據),你可能需要自定義一個collate_fn來處理批次的組合。 -
示例:對于不同大小的圖像,可以使用
collate_fn來處理不同的尺寸。
7. pin_memory:
-
如果設置為
True,DataLoader會將數據加載到 page-locked memory(鎖頁內存)中,通常能加速將數據從 CPU 傳輸到 GPU。 -
在使用 GPU 時,通常建議將
pin_memory設置為True,以提高數據傳輸效率。
8. drop_last:
-
如果設置為
True,則會丟棄最后一個批次,如果該批次的樣本數小于指定的batch_size。通常,在使用固定大小的批次進行訓練時使用此選項。 -
示例:
drop_last=True將刪除最后一個小于batch_size的批次。
9. timeout:
-
這個參數指定了等待數據加載的最大時間(以秒為單位)。如果超時,則會拋出錯誤。
-
示例:
timeout=60表示在 60 秒內沒有加載數據就會拋出超時錯誤。
10. worker_init_fn:
-
用于在每個工作進程啟動時進行初始化,通常用于設置種子或其他初始化操作。
-
示例:
worker_init_fn=set_seed用于設置每個工作進程的隨機種子。
2、案例分析
(1)查看?DataLoader 輸出的數據類型
import torchvision
from torch.utils.data import DataLoadertest_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)# 測試數據集中獲取一張圖像和目標標簽
img, target = test_data[0]
print(img.shape)
print(target)for data in test_loader:imgs, targets = data# DataLoader后 imgs和targets 都會加一維print(imgs.shape)print(targets)
輸出為:
torch.Size([4, 3, 32, 32])
tensor([2, 1, 4, 3])
torch.Size([4, 3, 32, 32])
tensor([1, 9, 1, 5])
torch.Size([4, 3, 32, 32])
tensor([0, 3, 9, 2])
torch.Size([4, 3, 32, 32])
tensor([0, 5, 1, 2])
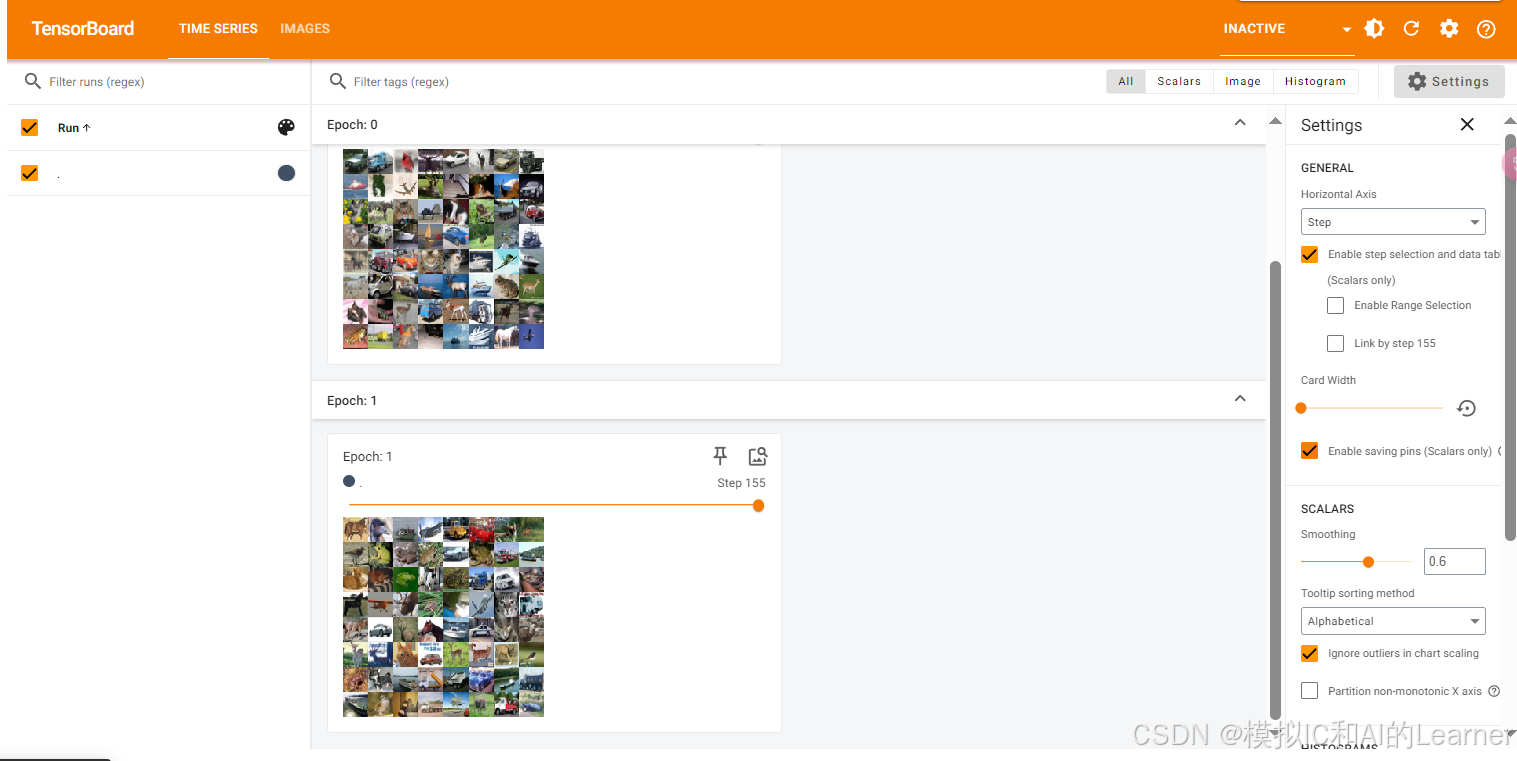
......(2)將每個批都用 tensorboard 顯示
# 通過tensorboard將每個批次的圖像都畫出來import torchvision
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWritertest_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)# 測試數據集中獲取一張圖像和目標標簽
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter("logs")
for epoch in range(2):step = 0for data in test_loader:imgs, targets = datawriter.add_images("Epoch: {}".format(epoch), imgs, step )step += 1writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs
輸出為:
七、Pytorch中神經網絡模型搭建相關的python API?
(1)torch.nn 和?torch.nn.functional
- torch.nn 中包含了所有與神經網絡相關的類,“nn”就是“神經網絡”的英文首字母。
- torch.nn.functional 相比于 torch.nn ,其中的內容更底層,包含很多神經網絡相關的函數,即 torch.nn 相當于?torch.nn.functional 的再封裝。
(2)torch.nn.Module的使用
torch.nn中第一個就是 Module(是一個類),它是神經網絡的框架,所有自己的神經網絡的框架都要繼承它。
下面的程序是一個簡單的神經網絡框架:
# pytorch 中,有關神經網絡的類都在torch.nn中
# torch.nn中第一個就是 Module,它是神經網絡的框架,所有自己的神經網絡的框架都要繼承它。
# import torch
from torch import nnclass Tudui(nn.Module):def __init__(self):super().__init__()def forward(self, input):output = input + 1return outputtudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)(3)torch.nn.functional.conv2d函數的使用
注意conv2d是個函數,和Conv2d不同(Conv2d是一個類,表示卷積層)
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)函數的參數介紹:
-
input – 輸入張量,形狀為 (minibatch, in_channels, iH, iW)
-
weight – 卷積核,形狀為 (out_channels, in_channels // groups, kH, kW)
-
bias – 可選的偏置張量,形狀為 (out_channels)。默認值為 None
-
stride – 卷積核的步幅。可以是單一數字或元組 (sH, sW)。默認值為 1
-
padding – 輸入張量的隱式填充。可以是字符串 {'valid', 'same'},單一數字或元組 (padH, padW)。默認值為 0,padding='valid' 表示無填充;padding='same' 會對輸入進行填充,以保證輸出與輸入形狀相同。然而,該模式不支持步幅大于 1 的情況。
警告: 對于
padding='same',如果weight的長度是偶數,并且dilation在任何維度上是奇數,那么可能需要內部執行pad()操作,從而降低性能。 -
dilation – 卷積核元素之間的間距。可以是單一數字或元組 (dH, dW)。默認值為 1
下面是函數conv2d實現卷積操作的例子:
# 二維卷積操作 conv2d 的使用
# 注意conv2d是個函數,和Conv2d不同(Conv2d是一個類,表示卷積層)import torch
import torch.nn.functional as Finput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]])kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]])# Reshape the input and kernel to fit convolution dimensions
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))# input的四個維度分別為(minibatch,in_channels,iH,iW)
# kernel的四個維度分別為(out_channels, in_channels/groups ,kH,kW)
print(input.shape)
print(kernel.shape)# Perform 2D convolution# 卷積的跨度stride=1
output = F.conv2d(input, kernel, stride=1)
print(output)# 卷積的跨度stride=2
output2 = F.conv2d(input, kernel, stride=2)
print(output2)# 卷積的填充 padding=1,(填充的是0)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
輸出為:
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12, 12],[18, 16, 16],[13, 9, 3]]]])
tensor([[[[10, 12],[13, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],[ 5, 10, 12, 12, 6],[ 7, 18, 16, 16, 8],[11, 13, 9, 3, 4],[14, 13, 9, 7, 4]]]])(4)torch.nn.Conv2d卷積層的使用
Conv2d 和 torch.nn.functional 中的 conv2d 不同,Conv2d 是一個類,將表示一個卷積層。
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)Conv2d 類的參數介紹:
-
in_channels (int) – 輸入圖像中的通道數
-
out_channels (int) – 卷積操作后產生的通道數
-
kernel_size (int 或 tuple) – 卷積核的大小
-
stride (int 或 tuple, optional) – 卷積的步幅。默認值:1
-
padding (int, tuple 或 str, optional) – 填充,添加到輸入的四個邊的填充量。默認值:0
-
dilation (int 或 tuple, optional) – 卷積核元素之間的間距。默認值:1
-
groups (int, optional) – 輸入通道與輸出通道之間的分組數。默認值:1
-
bias (bool, optional) – 如果為 True,將可學習的偏置添加到輸出。默認值:True
-
padding_mode (size,可選) – 填充模式:'zeros'、'reflect'、'replicate' 或 'circular'。默認值:'zeros'
下面是類Conv2d實現卷積層的例子:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
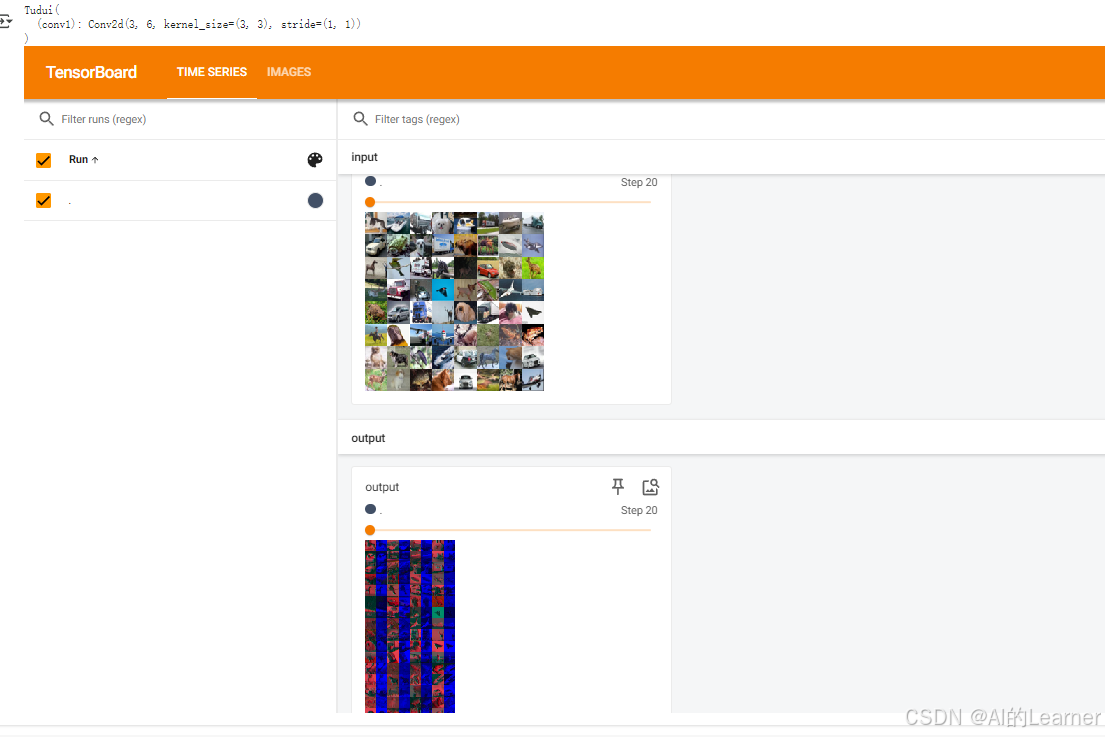
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True)dataloader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return xtudui = Tudui()
print(tudui)writer = SummaryWriter("../content/logs")step = 0
for data in dataloader:imgs,targets = dataoutput = tudui(imgs)# print(imgs.shape) #這句輸出為:torch.Size([64, 3, 32, 32])# print(output.shape) #這句輸出為:torch.Size([64, 6, 30, 30])writer.add_images("input",imgs,step)output = torch.reshape(output,(-1,3,30,30)) # 變換后的形狀第一維設置-1表示不確定,其實在這里是128writer.add_images("output",output,step)step = step + 1writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs輸出為:
(5)torch.nn.MaxPool2d池化層的使用
和 Conv2d 一樣,MaxPool2d 是一個類,將表示一個最大池化層。
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)MaxPool2d 類的參數介紹:
-
kernel_size (Union[int, Tuple[int, int]]) – 用于池化操作的窗口大小
-
stride (Union[int, Tuple[int, int]], optional) – 窗口的步幅。默認值是
kernel_size -
padding (Union[int, Tuple[int, int]], optional) – 在池化操作的兩側添加的隱式負無窮大填充。
-
dilation (Union[int, Tuple[int, int]], optional) – 一個控制窗口中元素步幅的參數。
-
return_indices (bool, optional) – 如果為
True,將返回最大值的索引以及輸出值。對torch.nn.MaxUnpool2d有用,即通常用于后續的反池化操作。 -
ceil_mode (bool, optional) – 當為
True時,使用向上取整 (ceil) 而不是向下取整 (floor) 來計算輸出形狀。
下面是兩個使用池化層的例子,一個是簡單的池化層使用示例,第二個是池化層對圖片的使用:
# 池化層 MaxPool2d 的使用
# 基礎示例import torch
from torch import nn
from torch.nn import MaxPool2dinput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]],dtype = torch.float32)input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)# 如果ceil_mode=False,則池化的輸出為tensor([[[[2]]]]),只有一個數,因為不足以完成池化的邊緣被舍去了 def forward(self, input):output = self.maxpool1(input)return outputtudui = Tudui()
output = tudui(input)
print(output)'''
輸出為torch.Size([1, 1, 5, 5])
tensor([[[[2, 3],[5, 1]]]])
'''# 池化層 MaxPool2d 的使用
# 項目示例import torch
from torch import nn
from torch.nn import MaxPool2d
import torchvision
from torch.utils.data import DataLoader
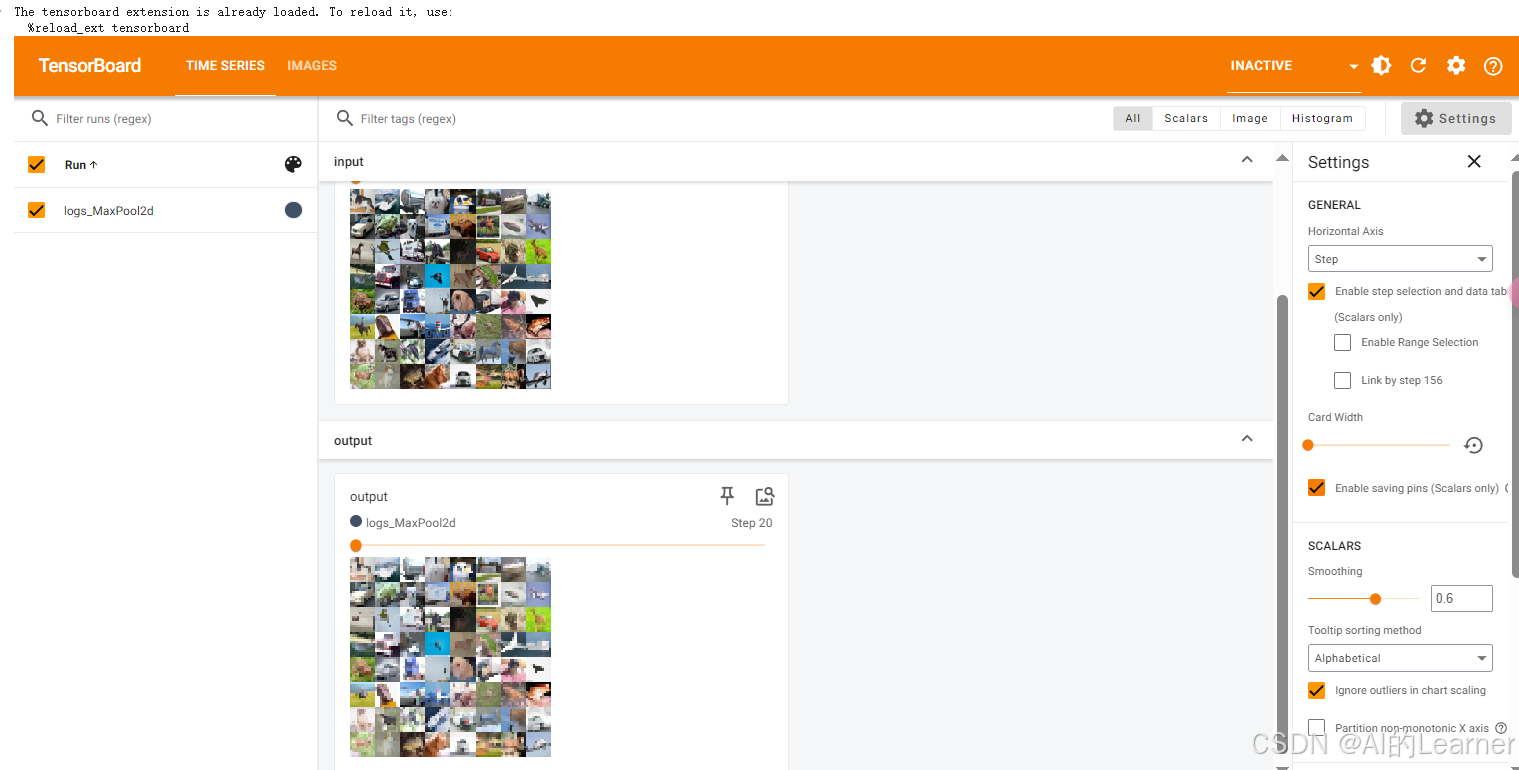
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True)dataloader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)# 如果ceil_mode=False,則池化的輸出為tensor([[[[2]]]]),只有一個數,因為不足以完成池化的邊緣被舍去了 def forward(self, input):output = self.maxpool1(input)return outputtudui = Tudui()writer = SummaryWriter("../content/logs/logs_MaxPool2d")
step = 0for data in dataloader:imgs, targets = datawriter.add_images("input", imgs, step)output = tudui(imgs)writer.add_images("output", output, step)step = step + 1writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs輸出為:
(6)激活函數,非線性層
以 torch.nn.ReLU 為例。
參數介紹:
-
inplace (bool) – 可選擇是否在原地執行操作。默認值:
False。若為True,則直接改變原輸入的值,若為False,原輸入值不變,返回輸出值。
下面是兩個使用激活層的例子,一個是簡單的激活層使用示例(ReLU),第二個是激活層對圖片的使用(Sigmoid):
# ReLU層的使用
# 基礎示例import torch
from torch import nn
from torch.nn import ReLUinput = torch.tensor([[1, -0.5], [-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.relu1 = ReLU()def forward(self, input):output = self.relu1(input)return outputtudui = Tudui()
output = tudui(input)
print(output)'''
輸出為:
torch.Size([1, 1, 2, 2])
tensor([[[[1., 0.],[0., 3.]]]])
'''# ReLU層的使用
# 項目示例import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
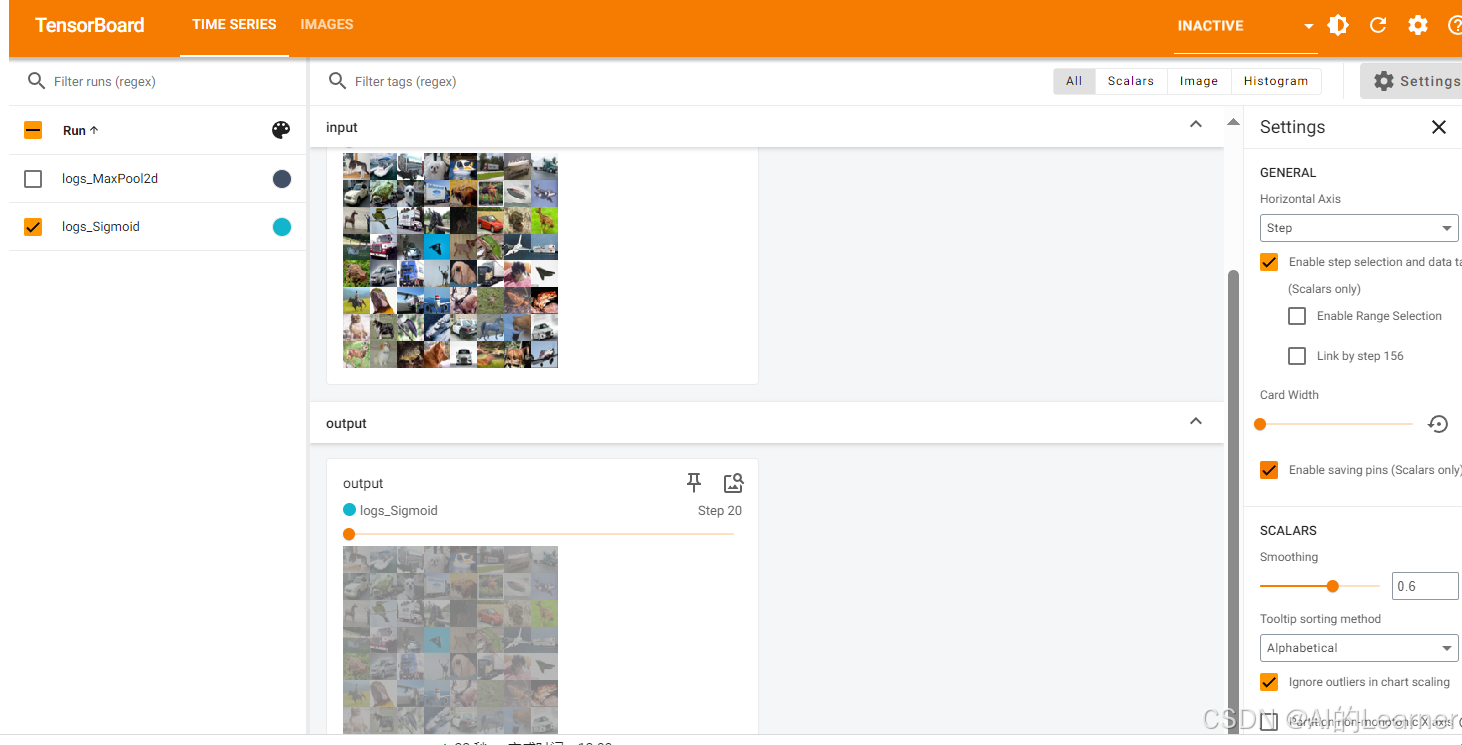
dataloader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.relu1 = ReLU()self.sigmoid1 = Sigmoid()def forward(self, input):output = self.sigmoid1(input)return outputtudui = Tudui()writer = SummaryWriter("../content/logs/logs_Sigmoid")
step = 0
for data in dataloader:imgs, targets = datawriter.add_images("input", imgs, global_step=step)output = tudui(imgs)writer.add_images("output", output, step)step += 1writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs輸出為:
(7)線性層的使用
torch.nn.Linear(in_features,?out_features,?bias=True,?device=None,?dtype=None)參數介紹:
-
in_features (int):每個輸入樣本的大小。
-
out_features (int):每個輸出樣本的大小。
-
bias (bool):如果設置為
False,該層將不學習加性偏置。默認值為True。
下面是使用線性層的例子:
# 線性層 Linear 的使用import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True
)dataloader = DataLoader(dataset, batch_size=64, drop_last=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.linear1 = Linear(196608, 10)def forward(self, input):output = self.linear1(input)return outputtudui = Tudui()for data in dataloader:imgs, targets = dataprint(imgs.shape)output = torch.reshape(imgs, (1, 1, 1, -1))# 上面這句代碼可以用torch.flatten()來代替,如 output = torch.flatten(imags)print(output.shape)output = tudui(output)print(output.shape)(8)實戰模型搭建及 nn.Sequential 的使用
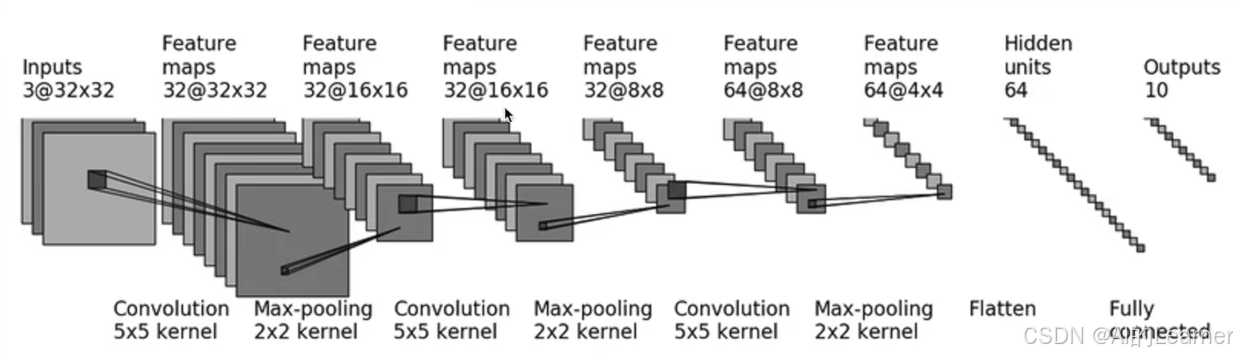
模型為:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linearclass Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.conv1 = Conv2d(3, 32, 5, padding=2)self.maxpool1 = MaxPool2d(2)self.conv2 = Conv2d(32, 32, 5, padding=2)self.maxpool2 = MaxPool2d(2)self.conv3 = Conv2d(32, 64, 5, padding=2)self.maxpool3 = MaxPool2d(2)self.flatten = Flatten()self.linear1 = Linear(1024, 64)self.linear2 = Linear(64, 10)def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)return x# 實例化模型
tudui = Tudui()
print(tudui)# 測試輸入
input = torch.ones((64, 3, 32, 32)) # 批次大小 64,3 通道,32x32 圖像
output = tudui(input)
print(output.shape)
下面使用?nn.Sequential 簡化上面的代碼:
# 使用 Sequential 完成上面的實戰import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequentialclass Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return x# 實例化模型
tudui = Tudui()
print(tudui)# 測試輸入
input = torch.ones((64, 3, 32, 32)) # 批次大小 64,3 通道,32x32 圖像
output = tudui(input)
print(output.shape)(9)使用 tensorboard 完成模型的可視化
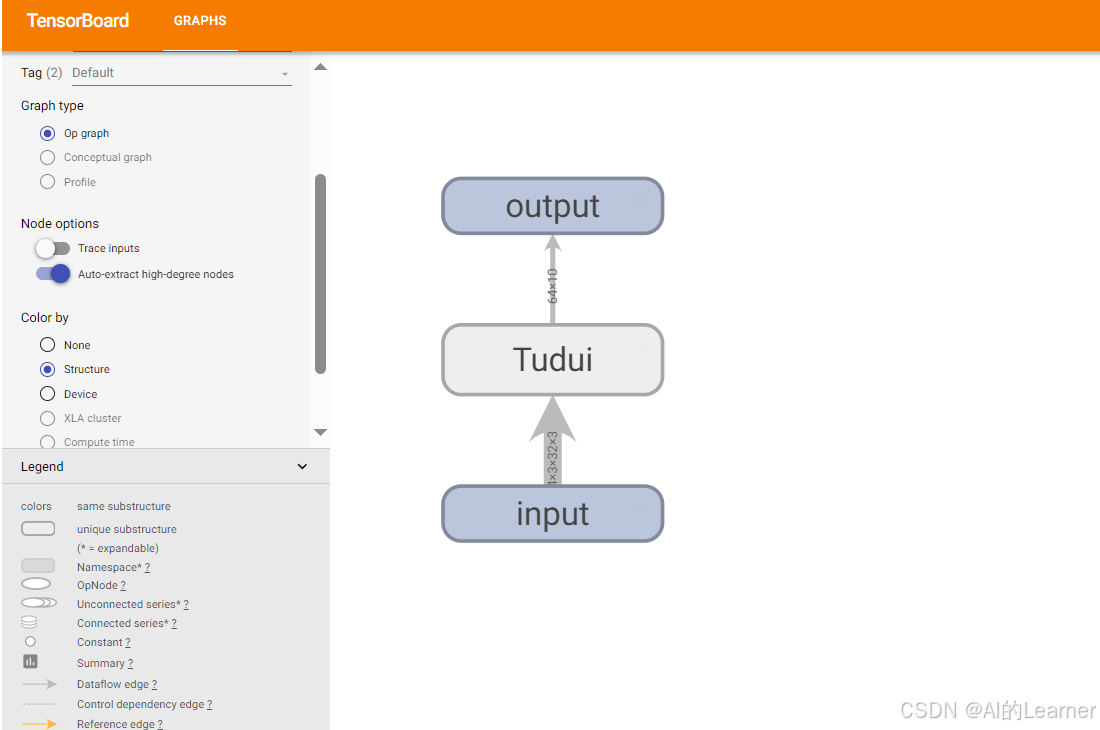
tensorboard.SummaryWriter 中的?add_graph 可實現對模型的可視化,即畫出模型的框圖
# 使用 tensorboard 完成模型的可視化
# 下面使用 add_graph 將上面的模型可視化
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("../content/logs/add_graph")
writer.add_graph(tudui,input)
writer.close()# 6. 啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs
輸出為:
八、損失函數
在這里介紹 L1損失、L2損失(均方損失MES)、交叉熵損失。
pytorch 中的損失函數計算的類不僅計算得到了損失,在其中還隱藏著一個寶貝,就是梯度grad,便于后續優化時更新參數。loss.backward():這句話調用后就直接計算了權重的梯度
(1)L1損失
torch.nn.L1Loss(size_average=None,?reduce=None,?reduction='mean')參數說明:
reduction:默認為'mean',表示批次中損失的平均;若為'sum',為批次損失的和,不平均。
使用示例:
loss = nn.L1Loss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward() # 這一步是計算梯度(2)L2損失
torch.nn.MSELoss(size_average=None,?reduce=None,?reduction='mean')使用示例:
loss = nn.MSELoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()(3)交叉熵損失
torch.nn.CrossEntropyLoss(weight=None,?size_average=None,?ignore_index=-100,?reduce=None,?reduction='mean',?label_smoothing=0.0)使用示例:
# Example of target with class indices
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
output.backward()
# Example of target with class probabilities
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5).softmax(dim=1)
output = loss(input, target)
output.backward()(4)案例
# 損失函數import torch
from torch.nn import L1Loss
from torch import nninputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))loss = L1Loss(reduction='sum')
result = loss(inputs, targets)loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)print(result)
print(result_mse)x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))# 1代表批次中只有一個樣本,3代表分類任務共有三類
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
九、反向傳播與優化算法
????????在計算完損失后,可以直接調用?loss.backward() 來計算梯度,然后就可以根據這個梯度對參數進行優化了,首先要構建優化器。
優化器在 torch.optim 中。
下面是一個反向傳播與優化算法的案例:
# 使用 Sequential 完成上面的實戰import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
import torchvision
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1, drop_last=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for eooch in range(20):running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)result_loss = loss(outputs,targets)optim.zero_grad()result_loss.backward() # 這句話調用后就直接計算了權重的梯度optim.step()running_loss = running_loss + result_lossprint(running_loss)
十、現有網絡模型的使用和修改
在這部分以 vgg16 模型為例。
????????vgg16模型是基于數據集 ImageNet 訓練的模型,在調用模型是,可通過參數pretrained來確定是否要使用預訓練的參數,該模型適合ImageNet數據集,因此分類數量為1000類,模型框架為:該模型為看起來清晰分為三個子模塊:features、avgpool、classifier 。
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)????????下面是對該模型進行修改,改為10個類別輸出,有兩種方式,一種方式是在原模型最后加一層從1000到10的線性層,另一種方式是將原模型最后一個線性層的輸出1000通道改為10通道。
import torchvision
# train_data = torchvision.datasets.ImageNet("../data_image_net", split='train', download=True,
# transform=torchvision.transforms.ToTensor())# 該數據集現已無法下載,但可在網上找到資源from torch import nn# 下面比較觀察不使用預訓練參數和使用預訓練參數的情況
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)print('非預訓練模型:',vgg16_false)
print('預訓練模型:',vgg16_true)
print('----------------------------------------------------------------------------------------------------------------------------------------')
train_data = torchvision.datasets.CIFAR10('../data', train=True, transform=torchvision.transforms.ToTensor(),download=True)# 在模型后面加個線性層
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
# 上面這句話若寫為 vgg16_true.add_module('add_linear', nn.Linear(1000, 10)),則修改后的一層將不會加到模型子模塊classifier中,而是單獨一個模塊print(vgg16_true)# 將模型最后一個線性層改為10通道輸出
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
十一、模型的保存與加載
兩種模型保存與加載的方式:
- 保存方式一,該方法保存的是:模型結構+模型參數
- 保存方式二,該方法保存的只有模型參數,是以字典方式保存的
import torch
import torchvisionvgg16 = torchvision.models.vgg16(pretrained=False)# 保存方式一,該方法保存的是:模型結構+模型參數
torch.save(vgg16,"vgg16_method1.pth")# 保存方式二,該方法保存的只有模型參數,是以字典方式保存的
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
- 加載方式一,對應保存方式一
- 加載方式二,對應保存方式二
# 加載方式一,對應保存方式一
load_model_1 = torch.load("vgg16_method1.pth", weights_only=False)
print(load_model_1)# 加載方式二,對應保存方式二
load_model_2 = torch.load("vgg16_method2.pth")
print(load_model_2) # 這樣的方式得到的只是一個字典,不是模型,要想得到模型,可以添加如下操作
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(load_model_2)
print(vgg16)十二、完整的模型訓練方式
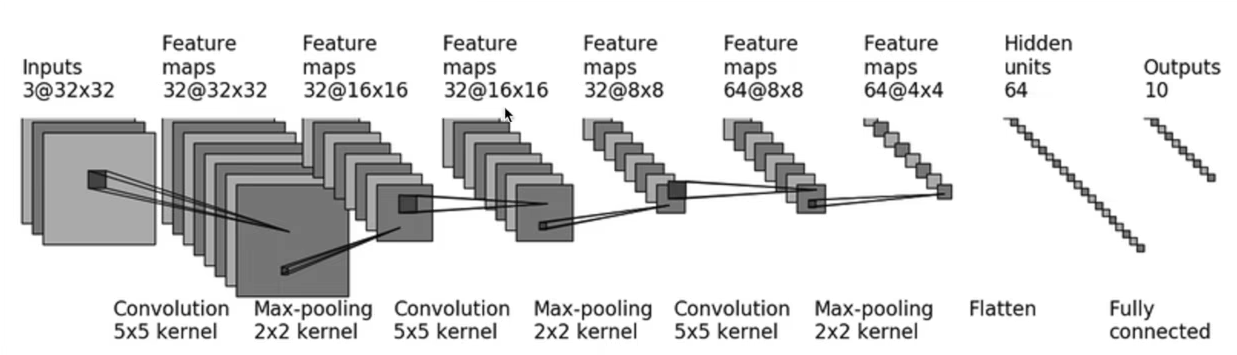
這個小項目的模型同樣是使用的 CIFAR10 數據集,模型仍是是下面這個圖:
任務是在 pycharm 中完成的。項目目錄為:
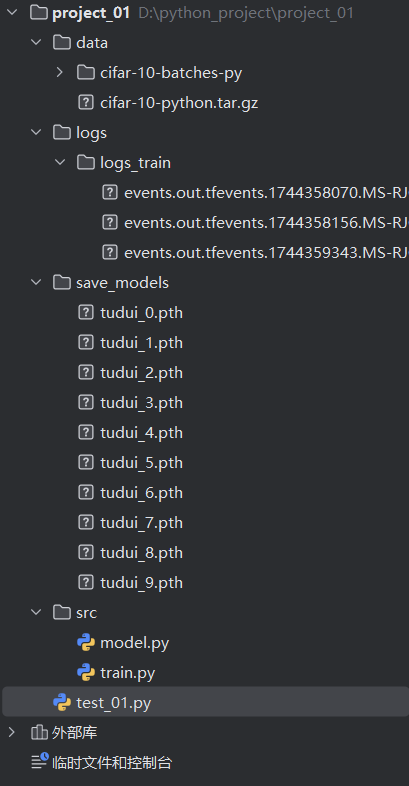
文件 model.py 為:
import torch
from torch import nn# 搭建神經網絡
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x# 測試模型
if __name__ == '__main__':tudui = Tudui()input = torch.ones((64,3,32,32))output = tudui(input)print(output.shape)文件 train.py 為:
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriterfrom model import *import torchvision
from torch import nn
from torch.utils.data import DataLoader# 準備數據集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True,transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False,transform=torchvision.transforms.ToTensor(), download=True)# Length 長度
train_data_size = len(train_data)
test_data_size = len(test_data)# 如果train_data_size=10,訓練數據集的長度為:10
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))# 利用 DataLoader 來加載數據集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型
tudui = Tudui()# 損失函數
loss_fn = nn.CrossEntropyLoss()# 優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)# 設置訓練網絡的一些參數
# 記錄訓練輪數
total_train_step = 0
# 記錄測試輪數
total_test_step = 0
# 訓練的輪數
epoch = 10# 添加 tensorboard
writer = SummaryWriter("../logs/logs_train")for i in range(epoch):print("----- 第 {} 輪訓練開始 -----".format(i+1))# 訓練步驟開始tudui.train() # 當網絡中存在 Dropout、BatchNorm層時,這行代碼和下面的tudui.eval()是一定要的,如果沒有這些特殊層,這兩句代碼要不要都行for data in train_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)# 優化器優化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("訓練輪數:{}, 訓練次數:{}, Loss: {}".format(i+1, total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 測試步驟開始tudui.eval() # 當網絡中存在 Dropout、BatchNorm層時,這行代碼和下面的tudui.train()是一定要的,如果沒有這些特殊層,這兩句代碼要不要都行total_test_loss = 0total_accuracy = 0 # 在測試集上的分類精度with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整體測試集上的Loss: {}".format(total_test_loss))print("整體測試集上的正確率: {}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)total_test_step = total_test_step + 1torch.save(tudui, "../save_models/tudui_{}.pth".format(i))print("模型已保存")writer.close()'''
如何查看tensorboard
在終端命令窗口使用以下命令打開所在的環境:conda activate my_pytorch_1如果上面命令失敗,則先初始化conda,使用以下命令:conda init隨后關閉終端重啟,再次執行conda activate my_pytorch_1來打開環境
在當前環境下打開tensorboard,執行:tensorboard --logdir=logs_train
完成后將得到的鏈接復制到瀏覽器即可'''
十三、如何將上述模型轉到 GPU 上進行訓練
1、方法一
將模型在GPU上訓練代碼修改步驟:
找出程序中的:模型、數據、損失函數,在其后加上 .cuda()?
將模型轉到gpu上:
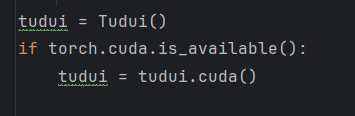
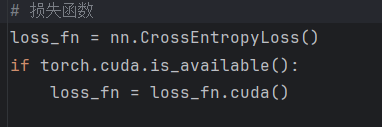
將損失函數轉到gpu上:
將訓練集數據轉到gpu上:

將測試集數據轉到gpu上:
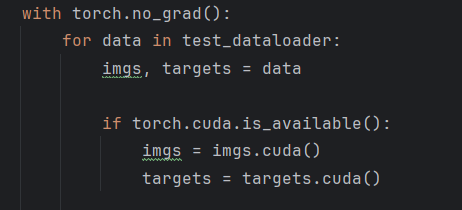
修改后的程序為(可適合gpu訓練):
# 本文件在 train.py 的基礎上做了修改(方法一),以適應模型在gpu上進行訓練。import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriterimport torchvision
from torch import nn
from torch.utils.data import DataLoader# 準備數據集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True,transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False,transform=torchvision.transforms.ToTensor(), download=True)# Length 長度
train_data_size = len(train_data)
test_data_size = len(test_data)# 如果train_data_size=10,訓練數據集的長度為:10
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))# 利用 DataLoader 來加載數據集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x
tudui = Tudui()
if torch.cuda.is_available():tudui = tudui.cuda()# 損失函數
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():loss_fn = loss_fn.cuda()# 優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)# 設置訓練網絡的一些參數
# 記錄訓練輪數
total_train_step = 0
# 記錄測試輪數
total_test_step = 0
# 訓練的輪數
epoch = 10# 添加 tensorboard
writer = SummaryWriter("../logs/logs_train")for i in range(epoch):print("----- 第 {} 輪訓練開始 -----".format(i+1))# 訓練步驟開始tudui.train() # 當網絡中存在 Dropout、BatchNorm層時,這行代碼和下面的tudui.eval()是一定要的,如果沒有這些特殊層,這兩句代碼要不要都行for data in train_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = tudui(imgs)loss = loss_fn(outputs, targets)# 優化器優化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("訓練輪數:{}, 訓練次數:{}, Loss: {}".format(i+1, total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 測試步驟開始tudui.eval() # 當網絡中存在 Dropout、BatchNorm層時,這行代碼和下面的tudui.train()是一定要的,如果沒有這些特殊層,這兩句代碼要不要都行total_test_loss = 0total_accuracy = 0 # 在測試集上的分類精度with torch.no_grad():for data in test_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = tudui(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整體測試集上的Loss: {}".format(total_test_loss))print("整體測試集上的正確率: {}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)total_test_step = total_test_step + 1torch.save(tudui, "../save_models/tudui_{}.pth".format(i))print("模型已保存")writer.close()'''
如何查看tensorboard
在終端命令窗口使用以下命令打開所在的環境:conda activate my_pytorch_1如果上面命令失敗,則先初始化conda,使用以下命令:conda init隨后關閉終端重啟,再次執行conda activate my_pytorch_1來打開環境
在當前環境下打開tensorboard,執行:tensorboard --logdir=logs_train
完成后將得到的鏈接復制到瀏覽器即可'''2、方法二
使用 to.(device) 來實現將程序放到 gpu 上,首先進行定義設備。
修改步驟為:
首先在文件開通定義使用的設備:
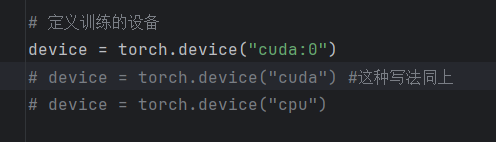
將模型轉到gpu上:
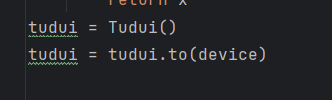
將損失函數轉到gpu上:
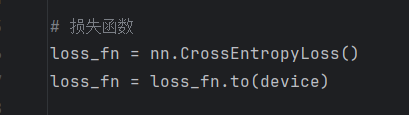
將訓練集數據轉到gpu上:
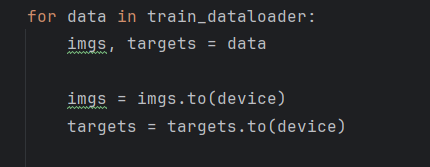
將測試集數據轉到gpu上:
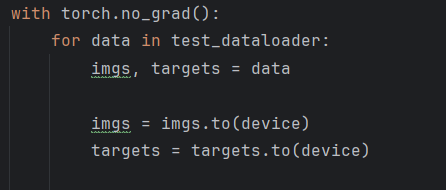
修改后的程序為(可適合gpu訓練):
# 本文件在 train.py 的基礎上做了修改(方法二),以適應模型在gpu上進行訓練。import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriterimport torchvision
from torch import nn
from torch.utils.data import DataLoader# 定義訓練的設備
device = torch.device("cuda:0")
# device = torch.device("cuda") #這種寫法同上
# device = torch.device("cpu")# 準備數據集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True,transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False,transform=torchvision.transforms.ToTensor(), download=True)# Length 長度
train_data_size = len(train_data)
test_data_size = len(test_data)# 如果train_data_size=10,訓練數據集的長度為:10
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))# 利用 DataLoader 來加載數據集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x
tudui = Tudui()
tudui = tudui.to(device)# 損失函數
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)# 優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)# 設置訓練網絡的一些參數
# 記錄訓練輪數
total_train_step = 0
# 記錄測試輪數
total_test_step = 0
# 訓練的輪數
epoch = 10# 添加 tensorboard
writer = SummaryWriter("../logs/logs_train")for i in range(epoch):print("----- 第 {} 輪訓練開始 -----".format(i+1))# 訓練步驟開始tudui.train() # 當網絡中存在 Dropout、BatchNorm層時,這行代碼和下面的tudui.eval()是一定要的,如果沒有這些特殊層,這兩句代碼要不要都行for data in train_dataloader:imgs, targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = tudui(imgs)loss = loss_fn(outputs, targets)# 優化器優化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("訓練輪數:{}, 訓練次數:{}, Loss: {}".format(i+1, total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 測試步驟開始tudui.eval() # 當網絡中存在 Dropout、BatchNorm層時,這行代碼和下面的tudui.train()是一定要的,如果沒有這些特殊層,這兩句代碼要不要都行total_test_loss = 0total_accuracy = 0 # 在測試集上的分類精度with torch.no_grad():for data in test_dataloader:imgs, targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = tudui(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整體測試集上的Loss: {}".format(total_test_loss))print("整體測試集上的正確率: {}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)total_test_step = total_test_step + 1torch.save(tudui, "../save_models/tudui_{}.pth".format(i))print("模型已保存")writer.close()'''
如何查看tensorboard
在終端命令窗口使用以下命令打開所在的環境:conda activate my_pytorch_1如果上面命令失敗,則先初始化conda,使用以下命令:conda init隨后關閉終端重啟,再次執行conda activate my_pytorch_1來打開環境
在當前環境下打開tensorboard,執行:tensorboard --logdir=logs_train
完成后將得到的鏈接復制到瀏覽器即可'''
十四、模型驗證流程
這部分的目標是使用訓練好并保存好的模型對樣本進行預測,代碼如下(在test.py文件中):
import torchfrom model import *
import torchvision
from PIL import Imageimage_path = "../imgs/bird.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),torchvision.transforms.ToTensor()
])image = transform(image)
print(image.shape)model = torch.load("../save_models/tudui_9.pth", weights_only=False)
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():output = model(image)
print(output)print(output.argmax(1))'''
知道了預測的序號如何查看它具體屬于哪一類呢?
其實在數據集中(是一個類),其中有一個屬性,其中包含著序號與具體類別的對應信息。
下面是查看數據集中這個屬性的方法:
在train.py中在訓練集數據下面好后打上斷點,比如說打在第14行下載測試集數據那一行,
然后打開調試過程,在調試界面可以查看變量,查看train_data數據集,
其中有一個 class_to_idx 屬性,其中包含著具體類別與索引號的對應關系
'''


如何在Spring Boot中集成Dubbo?)







![線代[13]|線性代數題37道以及數學分析題3道(多圖預警)](http://pic.xiahunao.cn/線代[13]|線性代數題37道以及數學分析題3道(多圖預警))
圖像濾波-----雙邊濾波函數bilateralFilter())



大學校園網綜合項目設計)

)

