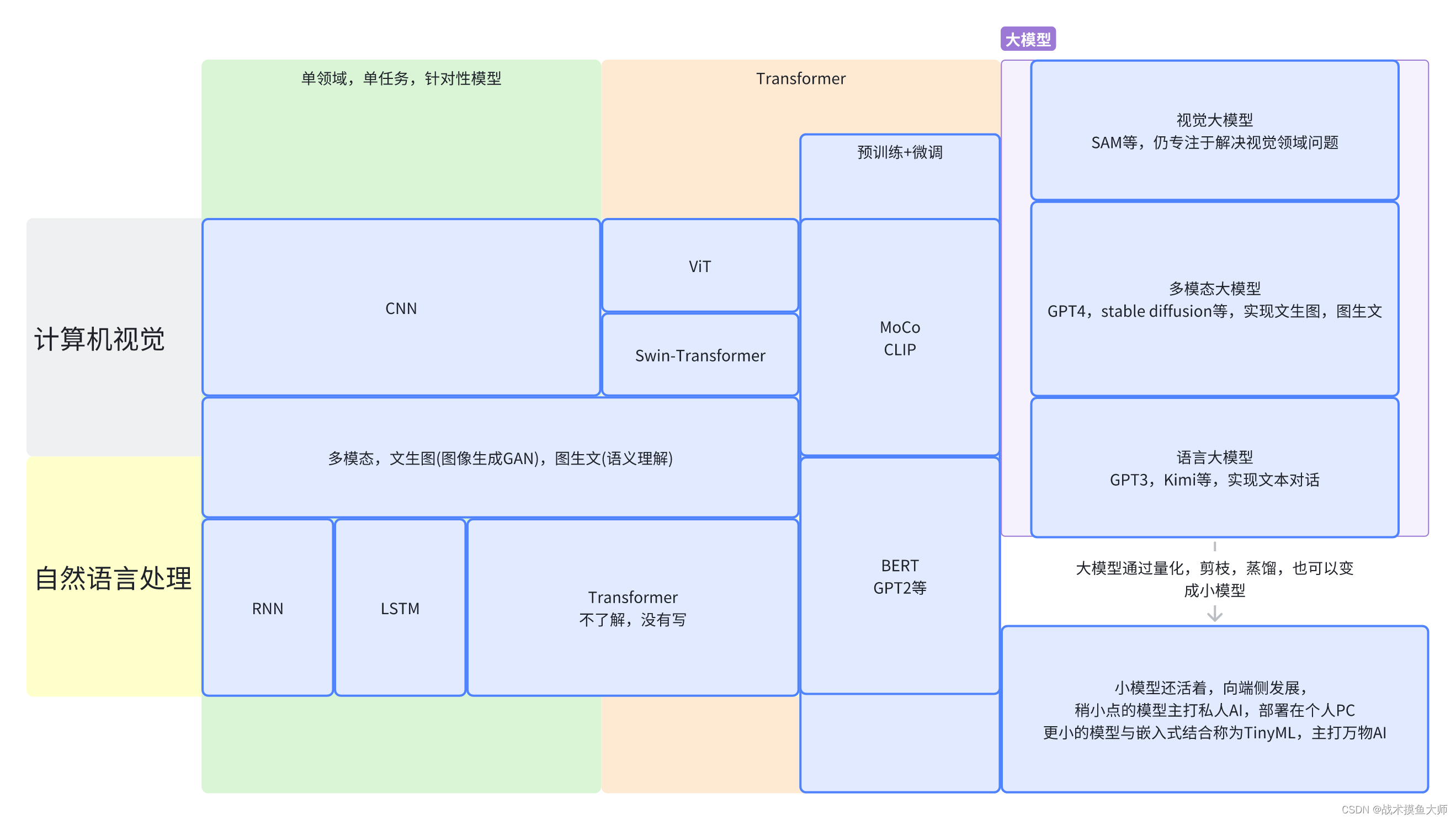
單任務/單領域模型
深度學習最早的研究集中在針對單個領域或者單個任務設計相應的模型。
對于CV計算機視覺領域,最常用的模型是CNN卷積模型。其中針對計算機視覺中的不同具體任務例如分類任務,目標檢測任務,圖像分割任務,以CNN作為骨干backbone,加上不同的前后處理以及一些輔助層,來達到針對不同任務的更好效果。
對于NLP自然語言處理領域,最常用的模型起初是RNN,后續發展有LSTM,Transformer等。這個方向了解不多,具體自行百度。
Transformer:統一架構
Transformer起源于NLP領域,后面人們發現在CV領域Transformer也能用,甚至效果比CNN還要好,使得CV和NLP兩個領域的模型架構得到統一,為多模態和大模型打下基礎。
Transformer最廣為人知的就是它的自注意力機制,要了解為什么創新出了這個機制,還要從RNN談起。
在NLP領域,第一代模型范式就是RNN,循環神經網絡。循環神經網絡原理比較簡單,RNN中的節點接受兩個輸入:上個節點的輸出以及本次輸入對應的詞向量:
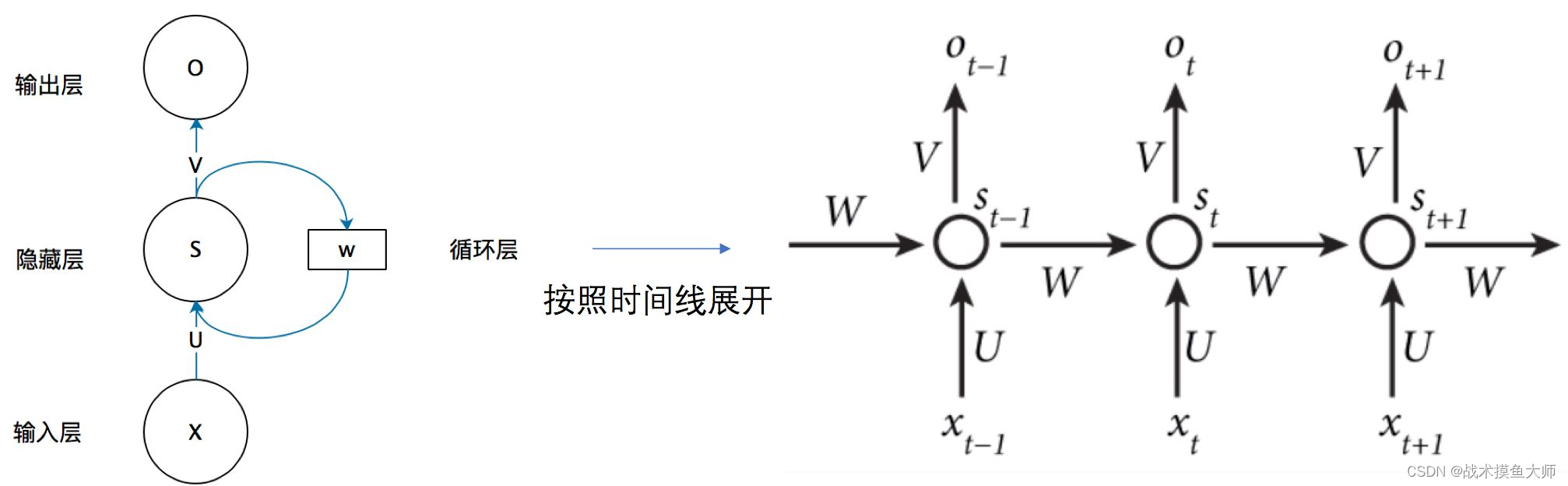
但是RNN缺點也很明顯,不斷地將輸出再次輸入,這種方法雖然可以關聯到上文所包含的信息,但是只能關聯到附近的上文信息,較遠的上文信息對當下影響較小,而且容易出現梯度消失的問題。所以RNN在90年以后就很少用了,取而代之的是它的兩個改進:LSTM長短時記憶網絡和GRU門控循環網絡。
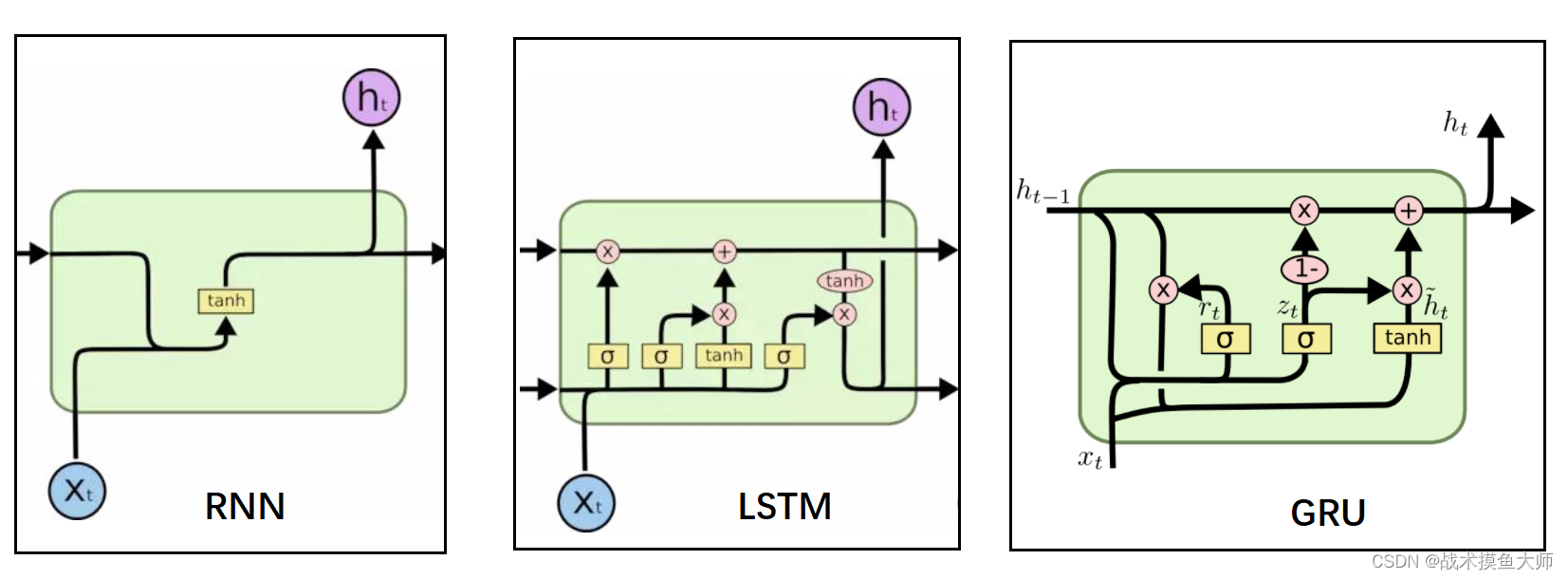
但是二者也只是緩解了RNN的問題,并沒有從根本上解決,后面又推出了seq2seq結構,依舊是縫縫補補。再后面計算機視覺中90年代提出的注意力機制,被Google mind團隊應用在RNN上來做圖像分類后,有學者把注意力機制從CV領域拿到了NLP領域來做機器翻譯,Attention-based RNN。在這之后才到transformer的興起,也就是那句“Attention is all your need”。

transformer簡而言之即:將輸入向量化,然后通過encoder編碼層編碼,再經過decoder解碼層進行解碼得到結果。
encoder的作用是理解和提取輸入文本中的相關信息以及上下文的信息。解碼器的任務是解碼器則根據編碼器的輸出和先前生成的部分序列來生成輸出序列。
注意,由于解碼器需要根據先前生成部分的內容來生成輸出序列中的下一部分,所以具有自回歸的效果,這是encoder沒有的,這個特性后面要提到。
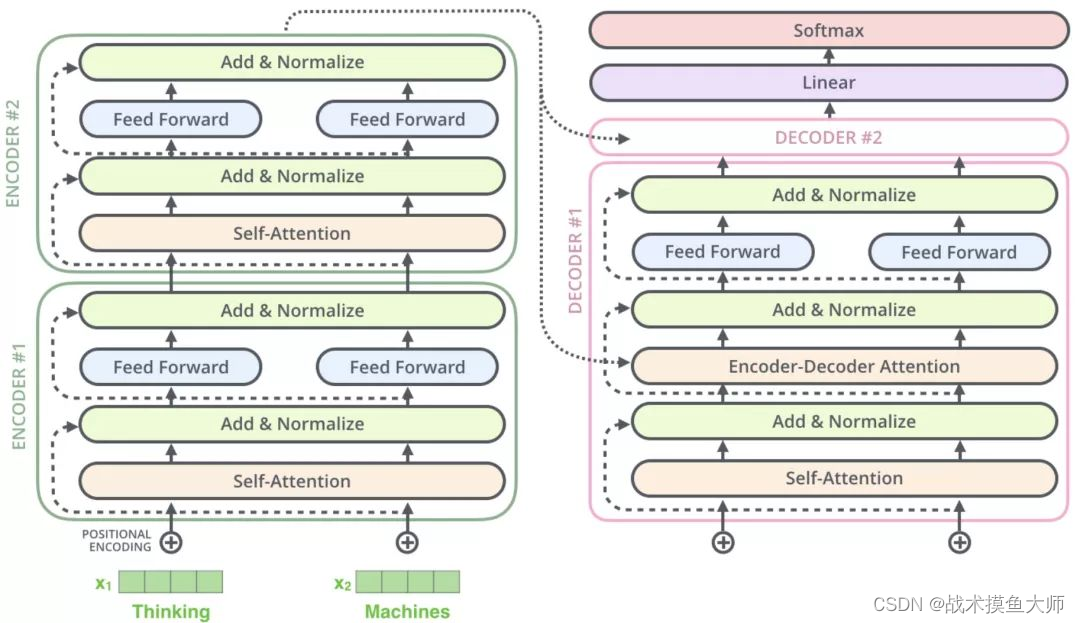
這篇文章寫的非常清晰明了,通俗易懂,我就不再班門弄斧了,大家可以直接看這篇文章。
一些細節問題的講解
ViT:視覺領域的Transformer
Vit李沐大神團隊出的講解非常好:ViT講解
自注意力和transformer自從提出沒多久就有人用在了計算機視覺領域,但是因為如果直接將圖像拉長成一個數組,數據復雜度太高,所以提出了stand-alone attention和axial attention等折中方案,分別是將局部窗口輸入給transformer和將圖像劃分為兩個維度,分別進行transformer
ViT基本使用了Transformer的原結構,沒有什么大的改動。圖像數據shape一般都是 C × H × W C\times H \times W C×H×W的,Transformer接受的數據是二維的,所以需要將三維的數據reformat為二維的,原文給出的方法是將圖像分為 m × n m\times n m×n個patch,每個patch的尺寸為 H m × W n × C \frac{H}{m} \times \frac{W}{n}\times C mH?×nW?×C的,將patch拉長為長度為 H m × W n × C \frac{H}{m} \times \frac{W}{n}\times C mH?×nW?×C的一維數組,這樣圖像就變成了 [ m × n , H m × W n × C ] [m \times n,\frac{H}{m} \times \frac{W}{n}\times C] [m×n,mH?×nW?×C]的二維數組,原文是將一個224*224的圖像分為了 14 × 14 14\times 14 14×14個patch,每個patch的尺寸為 16 × 16 16\times 16 16×16,輸入數據為 196 × 768 196\times 768 196×768。從圖像到patch的這個過程,可以直接簡單分割,也可以使用768個 16 × 16 × 3 16\times 16 \times 3 16×16×3的卷積核提取,得到的結果是是 14 × 14 × 768 14\times 14\times 768 14×14×768的數據,再將其reformat一下得到 196 × 768 196\times 768 196×768。
原文提到Transformer相較于CNN缺少兩個歸納偏置,locality和平移等變性
歸納偏置即:從網絡結構中就預先存在的偏置,是一種先驗知識,所以稱為歸納偏置。
locality:潛在的位置信息
平移等變性:f(g(x)) = g(f(x)),先做卷積還是先做平移效果是一樣的。
所以要么使用更大的數據集進行訓練。
在得到 196 × 768 196\times 768 196×768大小的圖像patch序列后,還需要再concat上一個 1 × 768 1\times 768 1×768大小class embedding,用于存儲分類結果,形成一個 197 × 768 197\times 768 197×768大小的tensor,再之后還需要添加上一個position embedding,position embedding是一個 197 × 768 197\times 768 197×768的表,直接add到原tensor上,得到最終輸入transformer的tensor。
至于ViT的網絡結構,跟Transformer是一樣的,只不過把Norm層提前到了multi-head attention前面

decoder的作用是進行序列生成,分類的ViT不需要decoder block,只需要encoder即可。
Transformer大模型類型
Transformer的結構是encoder-decoder模式(編碼器-解碼器)模式,decoder和encoder相比,多了encoder-decoder注意力機制部分,也就是上面transformer架構圖中decoder中多的一個環節,將encoder的輸出和decoder自注意力輸出作為輸入的注意力部分。
基于transformer的大模型根據encoder,decoder的搭配不同分為三種技術路線。目前大部分大模型都是decoder-only路線的。
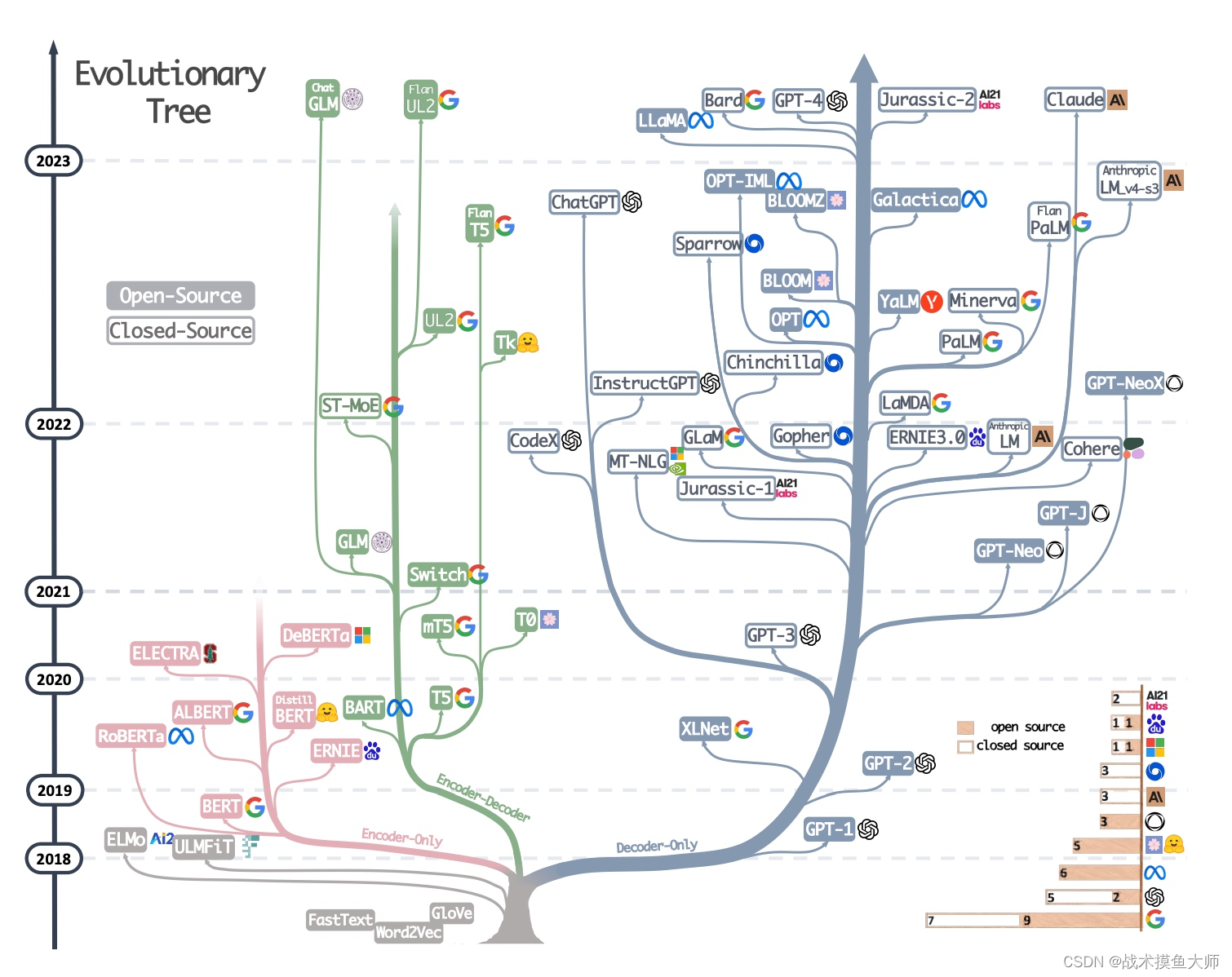
圖片來自論文
encoder-only[基本不再使用]
只有encoder的大模型,例子是Bert。
在 Transformer 模型中,編碼器負責理解和提取輸入文本中的相關信息。這個過程通常涉及到處理文本的序列化形式,例如單詞或字符,并且用自注意力機制(Self-Attention)來理解文本中的上下文關系。
encoder-only模型使用MLM(Masked Language Modeling)方法進行訓練,即:將語料中的一部分遮住,讓模型預測出被遮住的部分,這種訓練方式使得encoder-only模型對于文本分類和情感分析這種理解類的任務效果較好。
BERT中還用到了next-sentence prediction task訓練方式,該方式主要是訓練模型理解上下文語義關系的能力
encoder-decoder[較少使用]
同時有encoder和decoder的大模型,代表作有:T5,清華的GLM(General Language Model Pretraining with Autoregressive Blank Infilling)
因為具有decoderblock部分,所以相較于encoder-only模型,這種模型的文本生成能力要更強一些,比較適合做一些生成序列和輸入序列強相關的人物,例如翻譯,生成的句子和原句強相關。
encoder-decoder的變體:Prefix-decoder架構
decoder-only[主流]
只有decoder部分的大模型,代表作有:ChatGPT,LLAMA
上文我們提到decoder中有一個部分是編碼器-解碼器注意力機制部分,那只有decoder,這個部分怎么辦呢?
又分為Causal Decoder架構(因果解碼器架構)和 Prefix Decoder架構(前綴解碼器架構)
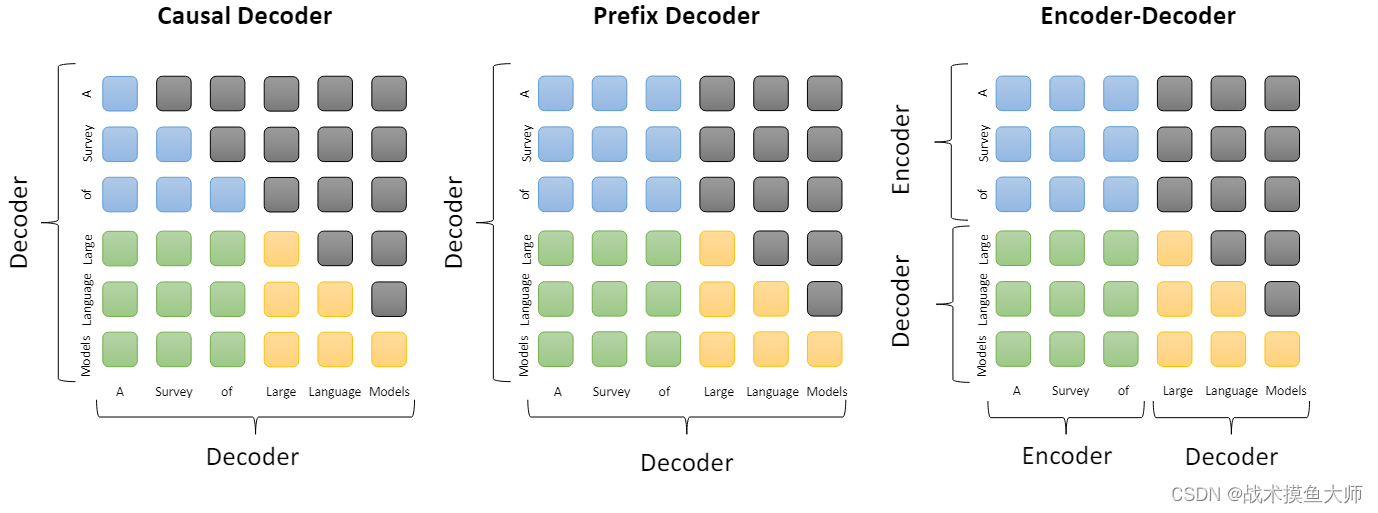
圖片來源自論文:A survey of Large Language Models
藍色是指前綴部分的mask,綠色是前綴和目標token之間的mask,黃色是指目標token之間的mask
簡而言之就是表示是否能產生關聯,能否讀取到該token的信息
不同架構,第一個區別是encoder和decoder組合不同,第二個區別是mask的設計不同。
像對于encoder-decoder架構而言,他的mask可以理解為:encoder的token之間是相互可以關聯的,decoder可以關聯所有的encoder的token,也可以關聯在自己前面的token。
對于causal decoder架構的mask,decoder的token只能關聯到前面的token,對于自己后面的token無法產生聯系,ChatGPT就是使用這這架構,
Prefix decoder架構跟上面的因果解碼器架構相比的特點是將前綴部分的注意力機制改成了雙向注意力機制,目標token間還是使用單項token,這就跟encoder很像了,實際上這種架構也是有encoder的,只不過和前綴的decoder是公用一套參數的,所以既可以說是deocder-only,也可以說成是encoder-decoder。代表作是GLM。
為什么大家都用decoder-only路線?
以下答案是依據該問題下的答案總結的
- 對于文本生成類任務效果比較好
- 相較于encoder-decoder路線,計算量小
- decoder-only的泛化性能更好,依據論文原因有很多
- 雙向attention[也就是不進行mask,當下token可以接受到所有token的影響]有可能導致低秩問題,反而削弱了模型的表達能力。
- decoder-only模型接受到的信息更少,訓練難度更高,在數據充足時,經過訓練,可以有更好的表征信息。
- decoder-only的架構相比encoder-decoder在In-Context的學習上會更有優勢,因為前者的prompt可以更加直接地作用于decoder每一層的參數,微調信號更強。依據
配套技術
歸一化
早期:LayerNorm
為了提高LN的訓練速度,提出了RMSNorm
為了穩定深度transformer模型訓練,提出了DeepNorm
三種歸一化位置方案:post-LN,pre-LN,sandwich-LN
優化器
常用優化器為Adam 優化器和 AdamW 優化器
微調技術
指令微調(instruction tuning)和對齊微調(alignment tuning)。前一種方法旨在增強(或解鎖) LLM 的能力,而后一種方法旨在將 LLM 的行為與人類的價 值觀或偏好對齊。
上下文學習ICL
為了使大模型能夠在不進行梯度更新的情況下完成新的任務。
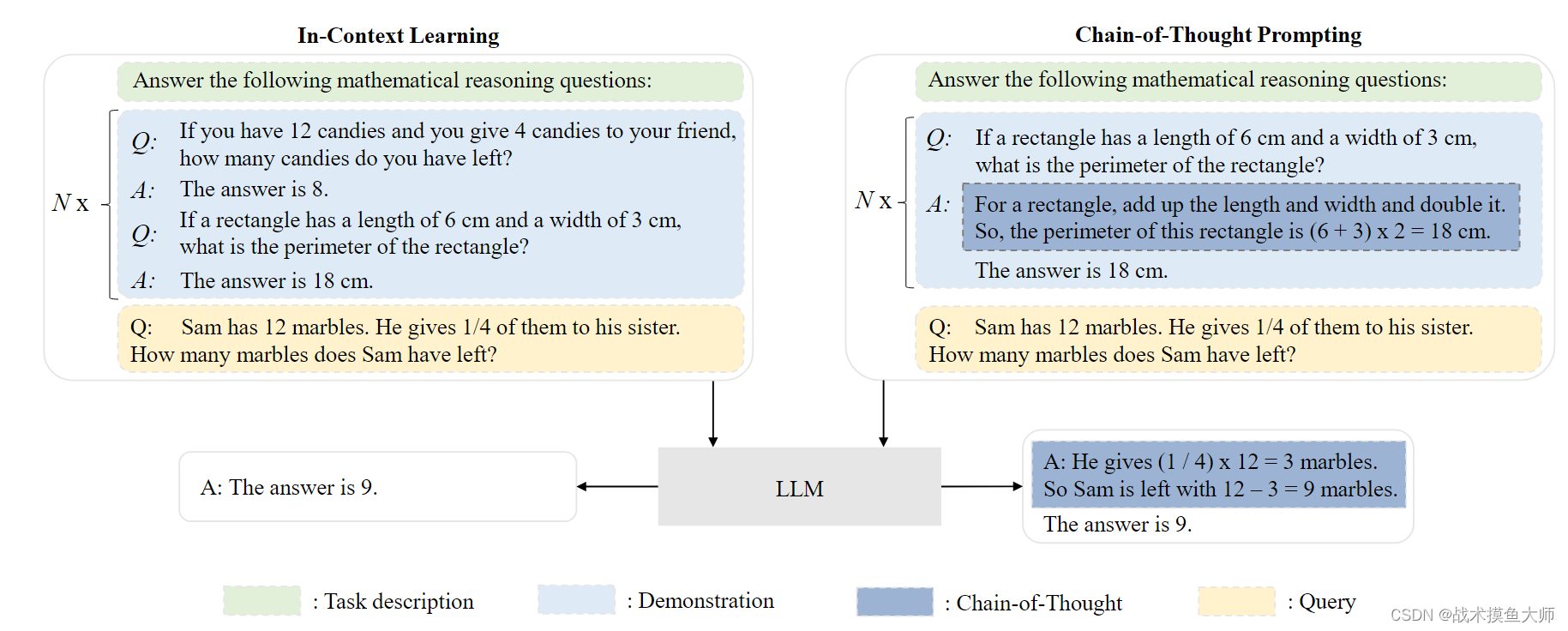
思維鏈CoT技術
思維鏈(Chain-of-Thought,CoT)是一種改進的提示策略,旨在提高 LLM 在復雜推理任務中的性能,例如算術推理,常識推理和符號推理。不同于 ICL 中僅使用輸入輸出對來構造提示,CoT 將可以導出最終輸出 的中間推理步驟納入提示中。通常情況下,CoT 可以在小樣本(few-shot)和零樣本(zero[1]shot)設置這兩種主要設置下與 ICL 一起使用。
參考文獻:
[1] A Survey of Large Language Models[J].
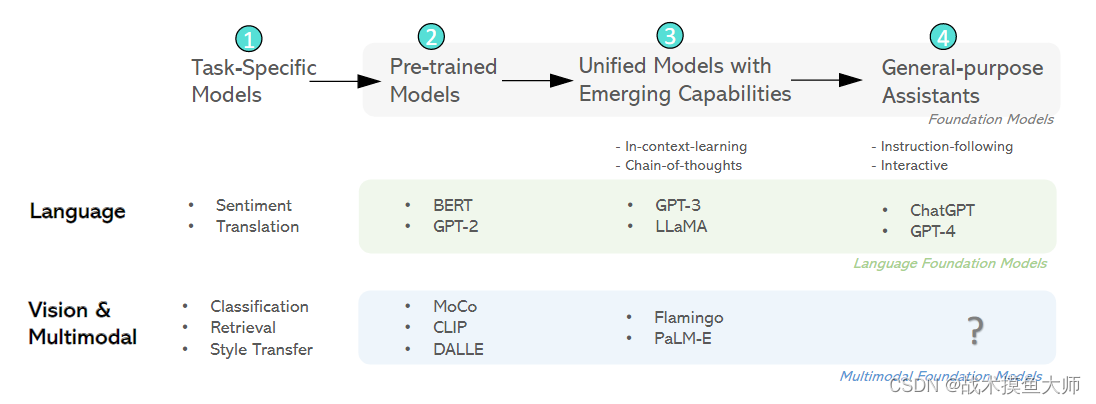
[2] Multimodal Foundation Models: From Specialists to General-Purpose Assistants[J].
[3] https://jalammar.github.io/illustrated-transformer/
)


















