前言:隨著數字媒體技術的普及,制作和傳播視頻內容變得日益普遍。但是,視頻中由于多種因素,例如傳輸、存儲和錄制設備等,經常出現質量上的問題,如圖像模糊、噪聲干擾和低清晰度等。這類問題對用戶的體驗和觀看體驗產生了直接的負面影響,因此,視頻修復技術顯得尤為關鍵。? 其重要性不容忽視。
本文所涉及所有資源均在傳知代碼平臺可獲取
概述
????????視頻修復技術(Video Restoration Techniques,VRT)是一種利用計算機視覺和圖像處理技術來改善、修復和恢復視頻內容的方法。其主要目的是消除視頻中存在的噪聲、模糊、失真、抖動等問題,使視頻內容更清晰、更穩定,并且提高其視覺質量和觀感。其實現的作用是:
1)噪聲去除:使用去噪算法來消除視頻中的各種類型的噪聲,例如高斯噪聲、椒鹽噪聲等,以提高圖像質量和清晰度。
2)運動補償:通過分析視頻中的運動信息,利用運動估計和補償技術來減少視頻中的運動模糊,使圖像更加清晰和穩定。
3)圖像恢復:使用插值、補洞和修復算法來修復視頻中存在的缺失、損壞或者破壞的圖像部分,以恢復視頻的完整性和連貫性。
4)超分辨率重建:利用超分辨率重建技術來增加視頻的空間分辨率,從而提高圖像的清晰度和細節展現能力。
視頻修復與單一圖像修復的區別在于:前者主要關注從單一圖像中恢復丟失或損壞的信息,而后者則涉及對整個視頻序列的處理。在進行視頻修復時,需要充分考慮幀與幀之間的時間序列關系,這樣可以更有效地利用時間信息來進行修復工作。這樣的時序關聯可能包括相鄰幀間的動態運動、變動等相關信息。
關于時間信息的價值:視頻里的這些時間數據在理解和修復過程中起到了不可或缺的作用。視頻修復過程中,相鄰幀的相互聯系、動態的變動以及視頻序列的動態變化等因素都為其提供了豐富的背景信息。傳統的單一圖像修復技術不能充分利用這些時間序列信息,而視頻修復則專注于通過綜合多幀信息來提升修復的效果。
在處理多幀視頻時,我們面臨了一系列新的挑戰,包括多幀之間的對齊、在動態環境中信息的變動以及長時間序列的依賴性等問題。
為了實現更為精確和穩健的視頻修復,我們需要構建一個能夠最大化利用這些信息的機制。
VRT模型的詳細說明
VRT 模型是指視頻修復技術(Video Restoration Techniques)的模型,它是一種利用深度學習和計算機視覺技術來改善、修復和恢復視頻內容的模型。這些模型通常基于深度神經網絡,能夠學習視頻中的復雜模式和結構,并自動進行修復和增強。其整體框架如下:
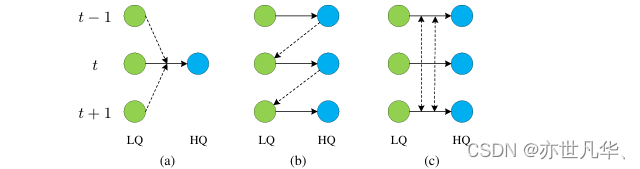
Figure 1.綠色圓圈:低質量(LQ)的輸入幀;藍色圓圈:高質量(HQ)的輸出幀。t-1,t及t+1為幀序號;虛線是用來描述不同幀融合的。
VRT的總體結構:Video Restoration Transformer(VRT)是一個致力于視頻修復任務的深度學習模型。其整體框架由多個尺度組成,每個尺度包含兩個關鍵模塊:Temporal Mutual Self Attention(TMSA)和Parallel Warping。VRT的目的是通過并行幀預測與長時序依賴建模的方法來充分利用多幀視頻信息實現高效修復。?
VRT具有多尺度結構,各尺度內含有TMSA與Parallel Warping兩模塊。該設計使模型能夠運行于不同分辨率特征,從而較好地擬合視頻序列的細節及動態變化情況。

TMSA模塊:Temporal Mutual Self Attention負責把視頻序列劃分成細小的片段,并將相互注意力應用到這些片段中,進行聯合運動估計,特征對齊以及特征融合等。同時利用自注意力機制對特征進行提取。該設計使模型可以聯合處理多幀信息,較好地解決了長時序依賴建模問題。
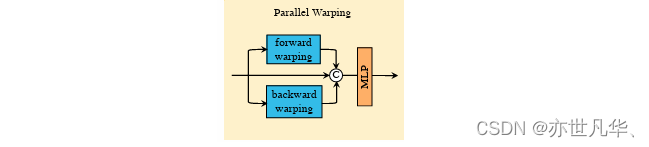
Parallel Warping模塊:Parallel Warping模塊用于通過并行特征變形從相鄰幀中進一步融合信息。它利用平行特征變形有效地將相鄰幀信息融合到當前幀中。該步驟與特征的引導變形相似,進一步提升了該模型多幀時序信息使用效率。
下圖展示了提出的Video Restoration Transformer(VRT)的框架。給定T個低質量輸入幀,VRT并行地重建T個高質量幀。它通過多尺度共同提取特征、處理對齊問題,并在不同尺度上融合時間信息。在每個尺度上,VRT具有兩種模塊:時間互相自注意力和平行變形。為了清晰起見,圖中省略了不同尺度之間的下采樣和上采樣操作。

實驗結果表現
VRT在不同視頻修復任務上的表現,如下圖所示:

不同任務表現: VRT在視頻超分辨率、視頻去模糊、視頻去噪、視頻幀插值和時空視頻超分辨率等五個任務上都進行了實驗。通過對比實驗結果,VRT展現了在各項任務中的優越性能,提供了高質量的修復效果。

性能對比: VRT與其他當前主流的視頻修復模型進行了性能對比,涵蓋了14個基準數據集。實驗結果顯示,VRT在各個數據集上都明顯優于其他模型,表現出色。尤其在某些數據集上,VRT的性能提升高達2.16dB,凸顯了其在視頻修復領域的卓越性能。
視頻修復技術(VRT)的優勢和創新點主要體現在以下幾個方面:
1. 深度學習驅動的修復模型:VRT采用深度學習技術,如卷積神經網絡(CNN)和生成對抗網絡(GAN),能夠自動學習視頻中的復雜模式和結構。相較于傳統的基于規則的方法,深度學習模型在處理視頻修復任務上表現出更高的靈活性和效果。
2. 端到端的修復過程:VRT模型通常采用端到端的修復過程,即直接從損壞或低質量的視頻幀到修復后的視頻幀,無需手動干預或多個步驟的流程。這種端到端的方式簡化了修復流程,提高了效率。
3. 多種修復技術的綜合應用:VRT模型綜合運用了多種修復技術,如噪聲去除、運動補償、圖像恢復等,能夠在多個方面改善視頻質量。通過這種綜合應用,VRT能夠更全面地處理視頻中的問題,提供更優質的修復結果。
4. 大規模訓練數據的利用:VRT模型通常使用大規模的真實視頻數據進行訓練,這些數據涵蓋了各種不同來源和類型的視頻,包括電影、電視節目、監控視頻等。通過利用這些數據,VRT模型能夠學習到更廣泛、更真實的修復模式,提升了修復效果的準確性和魯棒性。
5. 實時性能和效果的提升:隨著硬件和算法的不斷進步,現代VRT模型在實時性能和修復效果方面都取得了顯著的提升。一些優化的算法和硬件加速技術使得VRT能夠在更短的時間內完成修復任務,并且在視覺上提供更加真實和清晰的修復結果。
總的來說,視頻修復技術(VRT)利用深度學習等先進技術,結合多種修復技術,綜合應用大規模訓練數據,實現了對視頻內容的高效、自動、全面修復,為視頻產業和相關領域帶來了巨大的優勢和創新點。?VRT在不同任務上的性能提升如下圖所示:

核心代碼實現
這里給出視頻恢復(Video Restoration)模型的測試腳本,用于在測試集上評估模型的性能:
導入依賴庫和模塊:
import argparse
import cv2
import glob
import os
import torch
import requests
import numpy as np
from os import path as osp
from collections import OrderedDict
from torch.utils.data import DataLoaderfrom models.network_vrt import VRT as net
from utils import utils_image as util
from data.dataset_video_test import VideoRecurrentTestDataset, VideoTestVimeo90KDataset, \SingleVideoRecurrentTestDataset, VFI_DAVIS, VFI_UCF101, VFI_Vid4定義主函數 main():
def main():parser = argparse.ArgumentParser()# ...(解析命令行參數的設置)args = parser.parse_args()# 定義設備(使用GPU或CPU)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 準備模型model = prepare_model_dataset(args)model.eval()model = model.to(device)# ...(根據數據集類型準備測試集)# 定義保存結果的目錄save_dir = f'results/{args.task}'if args.save_result:os.makedirs(save_dir, exist_ok=True)test_results = OrderedDict()# ...(初始化用于保存評估結果的數據結構)# 遍歷測試集進行測試for idx, batch in enumerate(test_loader):# ...(加載測試數據)with torch.no_grad():output = test_video(lq, model, args)# ...(處理模型輸出,保存結果,計算評估指標)# 輸出最終評估結果# ...準備模型和數據集的函數 prepare_model_dataset(args):
def prepare_model_dataset(args):# ...(根據任務類型選擇合適的模型和數據集)return model測試視頻的函數和視頻片段的函數:
def test_video(lq, model, args):# ...(根據需求測試整個視頻或分割成多個片段進行測試)return output
def test_clip(lq, model, args):# ...(根據需求測試整個片段或分割成多個子區域進行測試)return output寫在最后
VRT通過深度學習驅動的修復模型、端到端的修復過程、多種修復技術的綜合應用、大規模訓練數據的利用以及實時性能和效果的提升,實現了對視頻內容的高效、自動、全面修復,為視頻產業和相關領域帶來了重大的優勢和創新點。
通過對VRT的全面介紹和深入解析,我們不難發現它在視頻修復領域的卓越貢獻。VRT通過并行幀預測、長時序依賴建模和多尺度設計等關鍵創新點,顯著提升了視頻修復的性能。其在多個任務上的卓越表現以及在實際應用中的廣泛潛力,使得VRT成為視頻修復領域的前沿技術。
鼓勵更多研究者深入挖掘視頻修復領域的技術挑戰,并通過VRT的經驗為該領域的未來發展做出更多貢獻。不僅如此,VRT的創新性和通用性也為深度學習在其他領域的研究提供了有益的參考,推動了整個人工智能領域的發展。
詳細復現過程的項目源碼、數據和預訓練好的模型可從該文章下方附件獲取。
【傳知科技】關注有禮???? 公眾號、抖音號、視頻號




















