一、線程概念
線程概念:進程內部的一個執行流,輕量化。
觀點:進程是系統分配資源的基本單位,線程是CPU調度的基本單位。
在理解線程之前,我們在談一下虛擬地址空間。
我們都知道進程是通過頁表將虛擬地址轉化為物理地址的,對于PCB,file我們已經了解了,所以,我們主要談頁表。
虛擬地址和物理地址之間映射時,是通過字節映射的嗎?如果進程大小是4GB,那么一共就會有 4 * 1024 * 1024 * 1024個字節,如果是按照字節映射,那么頁表的大小(虛擬地址和物理地址各占4字節,其它不考慮)就是 8 * 4 * 1024 * 1024 * 1024個字節,也就是32GB,一個進程的頁表就這么大,這是不可能的。所以,肯定不是通過字節映射的。
我們都知道磁盤和物理內存之間是通過4KB進行IO的,在邏輯上我們認為物理內存也是以4KB劃分的,物理內存上4KB劃分的空間,我們把它叫做頁框或者頁幀。如何理解頁框呢?
在物理內存中會有許多這樣的4KB空間,有些空間被使用,有些未被使用…,那么OS要不要對這些空間進行管理呢?答案是要的,先描述在組織。
在OS有一個 struct page就是用來描述物理內存4KB空間的,一個4KB空間對應一個 struct page,那么對空間已經描述了,那么該怎么組織呢?只需要用一個 struct page pages[]數組來管理就可以了,對物理內存的管理就轉變為了對數組的增刪查改。
既然如此,在OS內部還需要保存物理地址這樣的概念嗎?
不需要了,這個數組中每個內存塊的大小是固定的(4KB),那么物理塊的起始地址 = 數組下標 * 4KB,申請一個物理內存塊,本質只要申請到 struct page,知道 struct page的下標,那么物理內存塊的所有地址就都知道了。
那么OS如何得知所有物理內存塊的地址呢?OS只需要得到 page數組的起始地址即可。
結論:文件,進程和物理內存之間的關系就轉化為了 file,task_struct 和 page之間的關系了。
在32位系統下,OS采用的是二級頁表,從虛擬地址轉換到物理地址,默認是沒有直接轉化到字節的。虛擬地址一共32個 bit,從左往右依次劃分10個 bit,10個 bit,12個 bit,根據CR3寄存器里存儲的頁表起始地址,使用前10個 bit用來索引一級頁表,一級頁表中存在1024個頁表項(存儲的是下一級頁表的起始地址),中間的10個 bit用來索引二級頁表,二級頁表存儲的是物理頁的起始地址,這樣就可以找到物理頁框的起始地址了,最后12個 bit用來做頁內偏移。
查頁表只需要幫我們找到要訪問的是哪一個頁框就可以了。
真正的物理地址 = 頁框起始地址 + 頁內偏移。
頁表的大小 = 4 * 1024,就是4KB的大小,每一個頁表都是4KB大小,那么二級頁表一共(1024 + 1)* 4KB的大小,對比于32GB,那可真是小太多了。
細節1:CR3寄存器保存的是當前進程頁表的基地址,物理地址。
細節2:虛擬地址高20位相同,一定是連續存放在一個頁框的,因為索引的時候訪問的都是同一個頁表的同一個位置。
細節3:如果知道任意一個虛擬地址,如何得到所處的頁框?
addr & 1111 1111 1111 1111 1111 0000 0000 0000
那如何得到 page結構體呢?page 存儲在一個結構體數組里,只需要得到數組下標就可以了,數組下標 = 頁框號 / 4KB。
細節4:進程首次加載磁盤塊的時候,OS做什么?
內存管理,申請內存就是申請 page,得到 page的數組下標,進而得到頁框的物理地址,填充頁表。
細節5:如果訪問的是 int呢?一個結構體呢?一個類變量呢?所有變量只有一個地址,開辟空間時最小字節的地址。
頁表轉換的時候,只能拿到第一個字節的地址,所以語言中存在一個類型的概念。起始地址 + 偏移量的方式就可以訪問了。
細節6:如何理解寫時拷貝?
OS內,申請和管理內存是以4KB為單位的,寫時拷貝也是以4KB為單位的,申請一個新的頁表,更改映射關系。
細節7:我們用 new,malloc申請,怎么申請的時候1,4,n字節隨意申請的呢?
new,malloc底層一定要調用系統調用(brk,mmap),只有OS才能訪問硬件,調用系統調用是有成本的,所以C,C++自己在語言層,會有自己的內存管理機制,類似STL中的空間配置器。
現在,再來理解什么是線程。
//thread線程標示符,類似于進程pid,輸出型參數
//attr,線程的屬性,通常設置為nullptr
//start_routine回調函數,函數指針類型
//arg作為回調函數的參數
//成功返回0,失敗返回錯誤碼
int pthread_create(pthread_t* thread, const pthread_attr_t* attr,
void*(*start_routine)(void*), void* arg); //創建線程,執行指定的回調函數

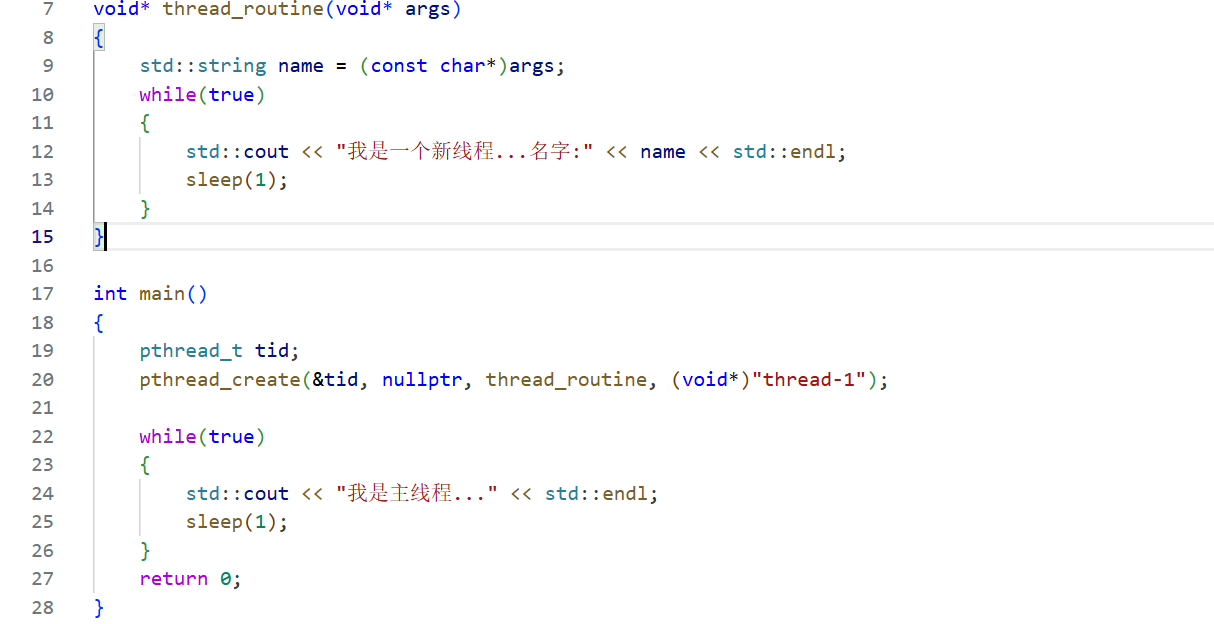


大家有沒有發現問題呢?一個單進程代碼,竟然同時讓兩個死循環跑起來了。
一個可執行程序,一個進程有一套頁表,那么,進程頁表的本質是什么?是進程看到資源的"窗口",通過虛擬地址與物理地址的映射,看到內存當中的代碼和數據。
一個進程,兩個死循環同時跑起來了,是讓不同的線程執行不同的函數,本質是讓不同的線程,通過擁有不同區域的虛擬地址,擁有不同的資源,通過函數編譯的方式,進行了進程內部的"資源劃分"。
Linux中多線程的實現:
一個進程中可以有一個執行流,那么可以有兩個,多個執行流嗎?當然是可以的。那么這些執行流(線程)也是需要被OS管理,OS需要對這些線程分配新的頁表,文件,調度算法等資源嗎?答案是不需要的,只需要給線程分配PCB就可以了,線程是進程內部的一個執行流,執行的是進程內部的一部分代碼資源,沒有必要浪費這么多的資源為線程分配新的頁表等。
Linux中,一個線程在進程內部運行,是如何運行的呢?線程在進程的虛擬地址空間中運行,線程和進程共享同一個虛擬地址,頁表等資源(體現了線程是進程內部的一個執行流)。
如何體現線程的輕量化呢?讓不同的線程訪問虛擬地址空間中的一部分資源。
那么,要如何才能做到,讓不同的線程看到自己的代碼資源呢?以代碼區為例:
讓不同的線程未來執行不同的入口函數即可(函數編譯的方式,進行進程內部資源的劃分)。
在Linux中,線程的實現是用進程模擬的,復用了進程代碼和結構。
那么,今天我們要如何理解進程和線程呢?
以前我們說 進程 = PCB + 自己的代碼和數據。可是今天進程里有許多的PCB,這要如何理解呢?
以前我們講的進程是內部只有一個執行流的進程,也叫做單線程的進程,而今天,我們需要對進程重新定義。
進程 = OS分配的所有 task_struct + 自己的代碼和數據 + 頁表、文件等資源。
所以,我們說進程是承擔分配系統資源的基本實體。
在CPU的角度,是不區分線程和進程的,它只拿著 task_struct 進行資源的調度,所以,執行流我們把它叫做輕量級進程。
線程(task_struct)自然而然就是CPU調度的基本單位了。
驗證:
ps -aL //查看所有的輕量級進程


Linux中不存在線程概念,只存在輕量級進程的概念,所以,Linux系統給用戶提供系統調用,只能提供輕量級進程的系統調用。

所有創建進程或者線程的系統調用底層都對 clone 進行了封裝。
但是這個系統調用使用起來非常麻煩,所以創建線程時需要使用pthread庫,這個庫對clone這個函數做了封裝。
CPU在獲取物理地址時其實并不是直接通過MMU查找頁表得到物理地址的,而是通過TLB(快表,其實就是緩存),如果TLB有虛擬地址到物理地址的映射就給CPU,否則就去查找頁表,在頁表中找到之后,把物理地址給CPU,同時把這條虛擬地址和物理地址的映射給TLB,進行緩存。
線程的優點:
1.創建一個新線程比創建一個新進程的代價小得多(進程需要創建PCB,虛擬地址空間,文件資源,頁表等,線程只需要創建PCB,共享進程的其它資源)。
2.與進程之間的切換相比,線程之間的切換需要OS做的工作要少很多。
. CPU內有CR3寄存器,保存的是頁表的基地址,進程間切換需要更新CR3寄存器的內容,線程間切換不需要,因為,同一個進程里所有線程擁有的是同一個頁表。
. TLB就是緩存虛擬地址和物理地址的映射關系,線程間切換TLB不需要更新(線程共享進程的虛擬地址空間),進程切換TLB需要更新。
. CPU內有一個 cache 硬件,這個硬件就是用來緩存代碼和數據的,在CPU訪問內存中的代碼和數據時,并不是不斷的進行虛擬地址到物理地址之間的映射訪問的,而是通過 cache 硬件訪問的,cache 硬件會預先加載一部分代碼和數據,線程切換時,cache 是不需要更新的,進程切換需要重新加載新的代碼和數據。
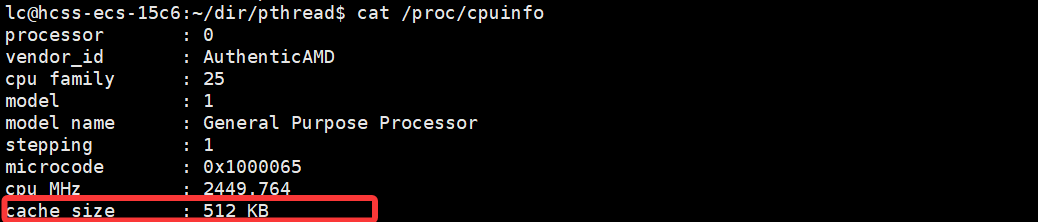
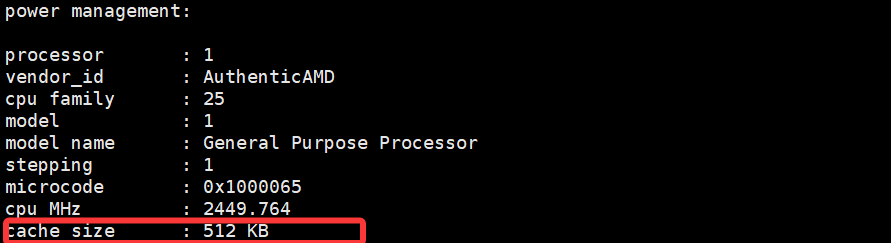
可以看到,cache 大小還是挺大的(這與系統有關,也有MB的)。
3.線程占用的資源比進程少很多(線程擁有進程的完整資源,但線程不需要重復再分配共享資源,如虛擬地址空間,頁表等,線程只需要維護少量資源,比如局部變量,函數調用,寄存器狀態)。
線程的缺點:
1.性能損失(過多的線程使用同一個處理器,增加了線程調度,而可用資源不變)。
2.健壯性降低(多個線程共享了不該共享的變量,缺乏保護)。
3.缺乏訪問控制(調用某些OS函數對整個進程造成影響)。
線程獨有的數據:
線程ID
寄存器(線程上下文數據)
棧
進程間多線程共享:
同一地址空間(代碼段,數據段...)
文件描述符表
每種信號的處理方式
當前工作目錄
用戶id,組id
寫一段程序驗證一下。

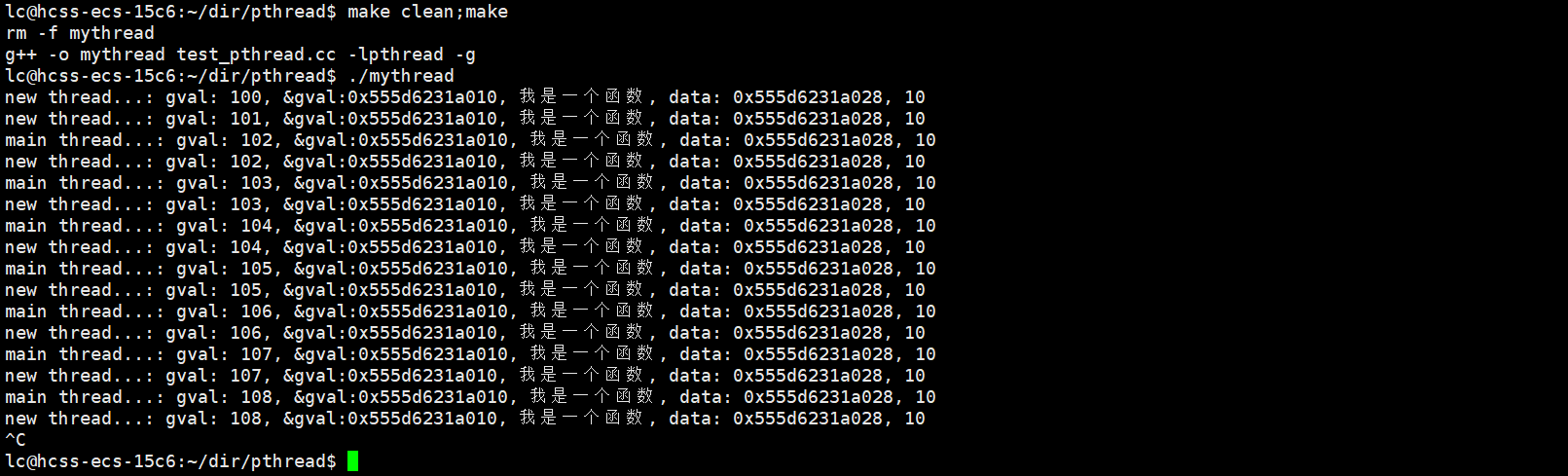
可以看到,線程之間是共享全局變量,函數和堆空間的。當然了,這只是一部分,畢竟線程是共享進程的虛擬地址空間的。
二、線程控制


主線程運行3秒后結束,新線程10秒后才終止,但是主線程一旦退出,所有的線程都退出了,表示進程終止了。
這是因為,進程創建時OS需要分配PCB等資源,那么當進程退出時,所有的資源也應該都要進行回收,所以,所有的線程都退出了。
一般情況下,主線程應該最后退出,線程也需要等待,類似進程的 wait。要對新線程進行等待,否則,也會造成類似僵尸進程的問題。
//成功返回0,失敗返回錯誤碼
//thread表明等待哪一個線程
//retval獲取新線程退出時的退出信息
//阻塞等待,main thread最后退出,自動解決新線程的內存泄漏問題(僵尸問題)
int pthread_join(pthread_t thread, void** retval);


可以看到,在多線程等待時,一旦只要有一個線程崩潰,所有的線程都崩潰了,而進程之間具有獨立性,即便是父子進程,子進程崩潰也不會影響父進程。所以說多線程的缺點是健壯性低。
線程終止:
. return
. exit


exit是用來終止進程的,變相導致所有的線程退出。
. pthread_exit
void pthread_exit(void* retval);//線程退出
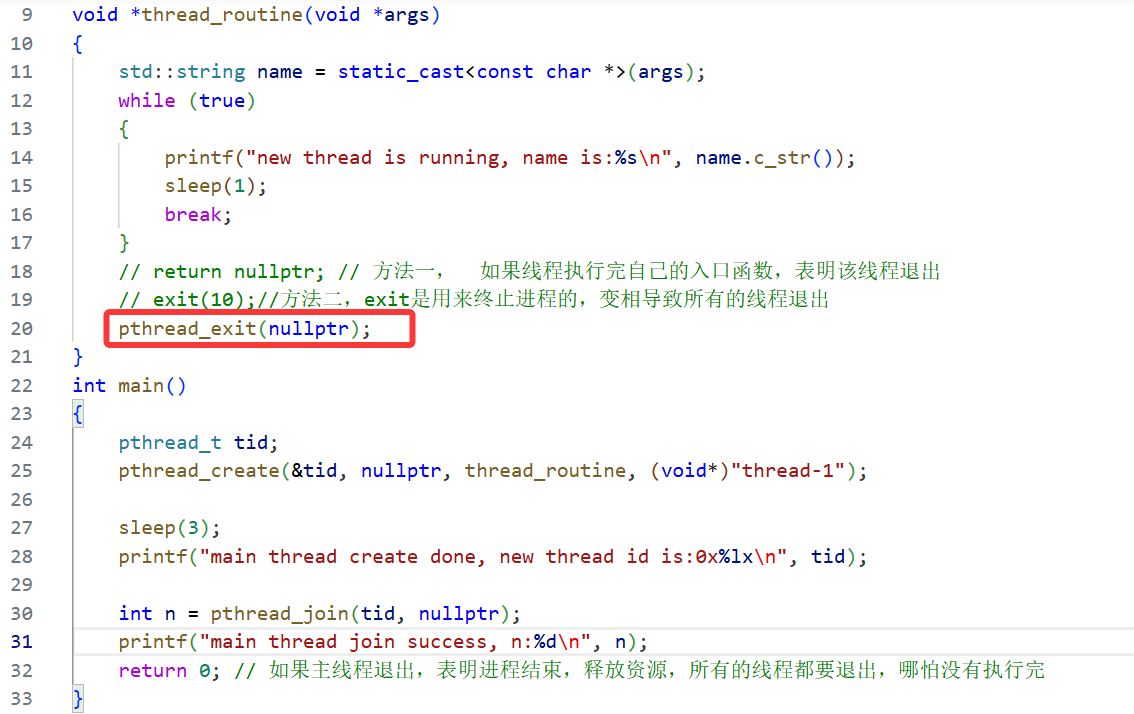

可以看到,使用系統調用退出線程,只會讓調用該函數的線程退出,不會影響到其它線程。
. pthread_cancel
//成功返回0,失敗返回非0的錯誤碼
//thread取消目標線程的線程標識符
//線程退出,退出信息設置為-1(PTHREAD_CANCELED,是一個宏值)
int pthread_cancel(pthread_t thread); //取消線程


通常用于主線程取消其它線程。
那么,線程自己可不可以取消自己呢?
先認識一個系統調用。
//返回的是調用線程的id
pthread_t pthread_self(void);


可以看到,主線程創建新線程的 tid 與新線程獲取自己的線程標識符是一樣的。
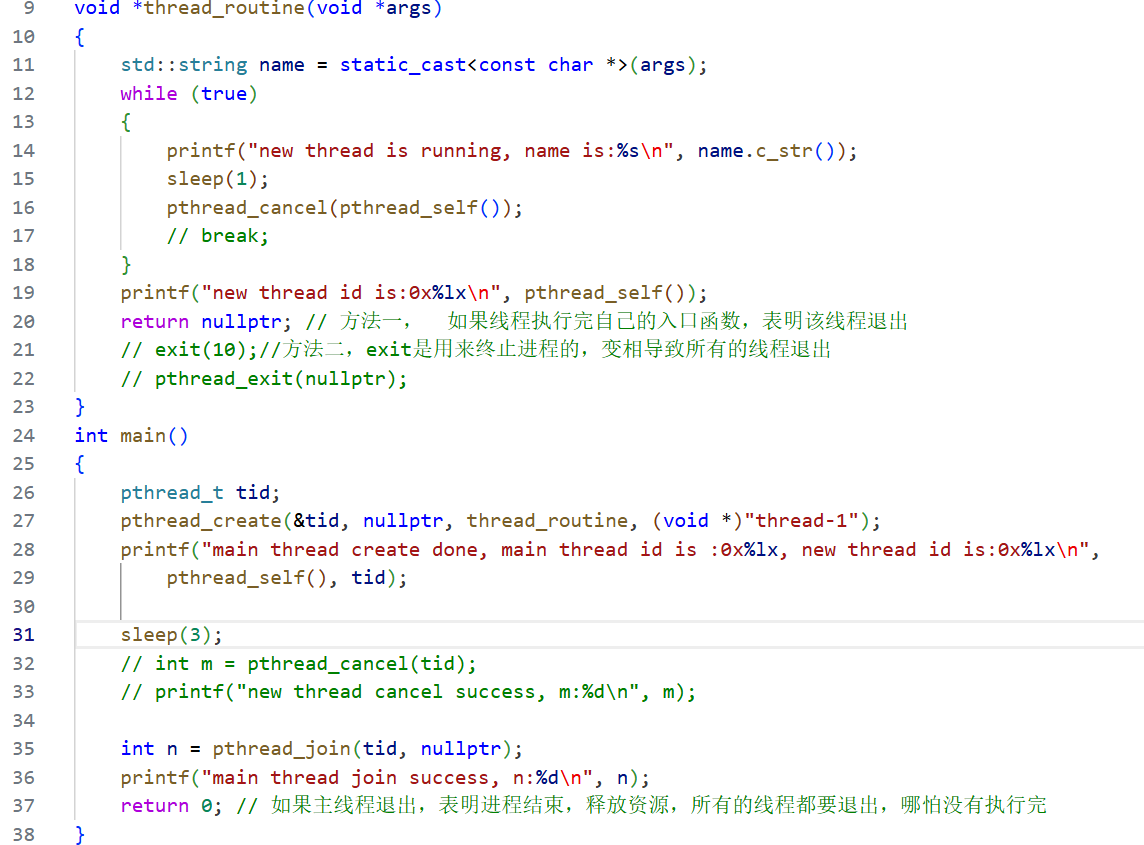

可以看到,線程自己取消自己也是可以的。但是,這里為什么會將這條語句打印兩次呢?
這是因為,pthread_cancel函數發送取消請求,對應的線程收到取消請求之后會在合適的點終止自己,不是立即終止。
最佳實踐取消線程的方法:在主線程中使用 pthread_cancel,本來就是主線程取消其它線程的。
線程的傳參和返回值問題:
前面我們介紹了 pthread_join 函數,它的第二個參數就是將線程退出時的退出信息帶出來,現在,我們就要聊聊這個參數了,它是怎么通過這個參數把線程的退出信息帶出來的,畢竟我們只是使用了兩個系統調用而已。
還記得C語言中的 fopen函數嗎,它的返回類型是 FILE*類型的文件指針。那么這個FILE是什么呢?它有在哪里?
這個前面我們是說過的,FILE是一個結構體,它在C標準庫里,fopen函數返回文件指針的時候,就必然創建了一個FILE對象,那么這個對象在哪里呢?它應該就在fopen函數內部申請的,然后通過 return 返回。
那么,在多線程這里,線程的概念是誰提供的?pthread庫提供的。
那么,將來我們可以在一個進程中創建很多線程,在多個進程中呢?就會有更多的線程,所以,線程需不需要被管理呢?那些線程在被調度,那些線程退出了?答案是需要的。
那么,就應該對線程進行先描述在組織。像進程一樣有一個結構體 struct tcb,那么,這個結構體在哪里呢?不要忘了,前面說了,線程的概念是pthread庫提供的,所以,這個結構體應該在 pthread庫里面。這個結構體中就會有線程的各種屬性。
將來線程退出時,return 將數據寫入到結構體中,主線程在等待時,將等待線程的標示符 tid傳入進去,就可以找到指定的線程了(結構體),然后通過第二個參數將結構體中的退出信息拷貝出來,不就拿到指定線程的退出信息了嗎。
分離線程
默認情況下,新創建的線程是 joinable 的,線程退出后,需要對其進行 pthread_join操作,否則,會造成類似僵尸進程的問題(資源泄露)。
如果不關心線程的返回值,我們可以告訴系統,當線程退出時,自動釋放線程資源。這個時候就不需要進行 pthread_join了。
//成功返回0,失敗返回錯誤碼
//thread分離線程的線程標示符
int pthread_detach(pthread_t thread);
分離線程可以自己分離自己,也可以是其它線程分離目標線程。


線程分離之后再去等待線程,就會出錯。
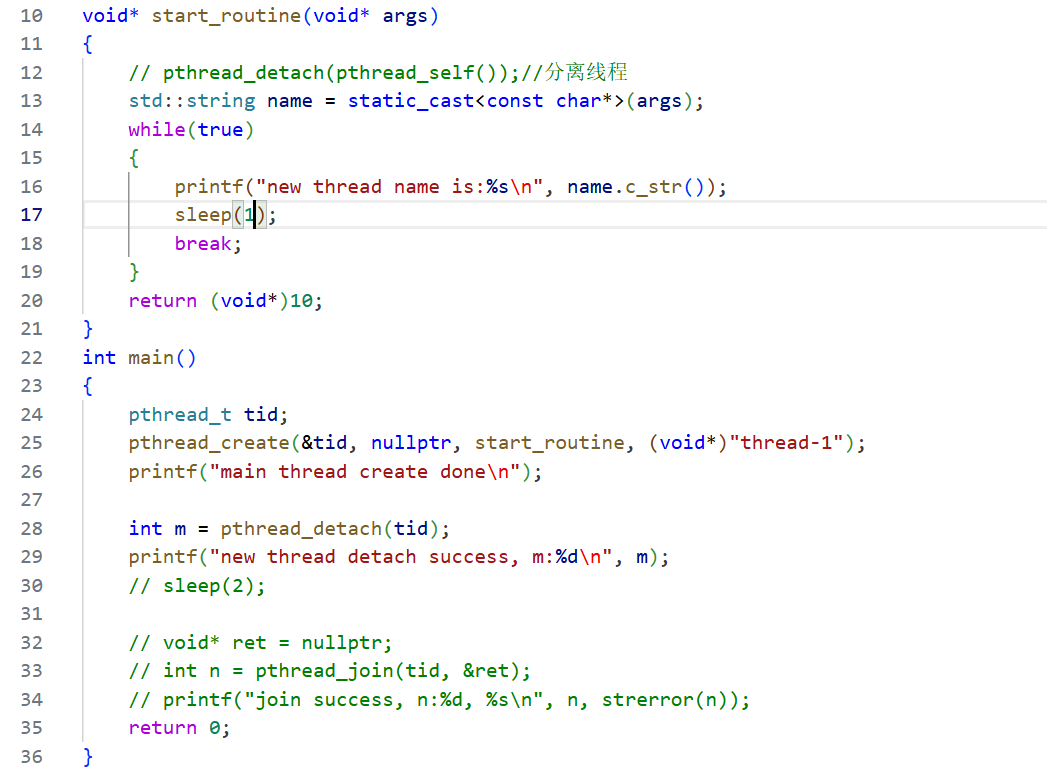

這個時候可能有人要問了,主線程把新線程分離之后,如果是主線程先退出呢。那進程都終止了,新線程不是也會終止嗎?這個問題不用擔心,因為真正的軟件都是死循環的,新線程執行完自己的代碼就會退出,主線程是最后退出的。
接下來再聊一下,pthread_cancel函數取消目標線程之后得到的退出信息。
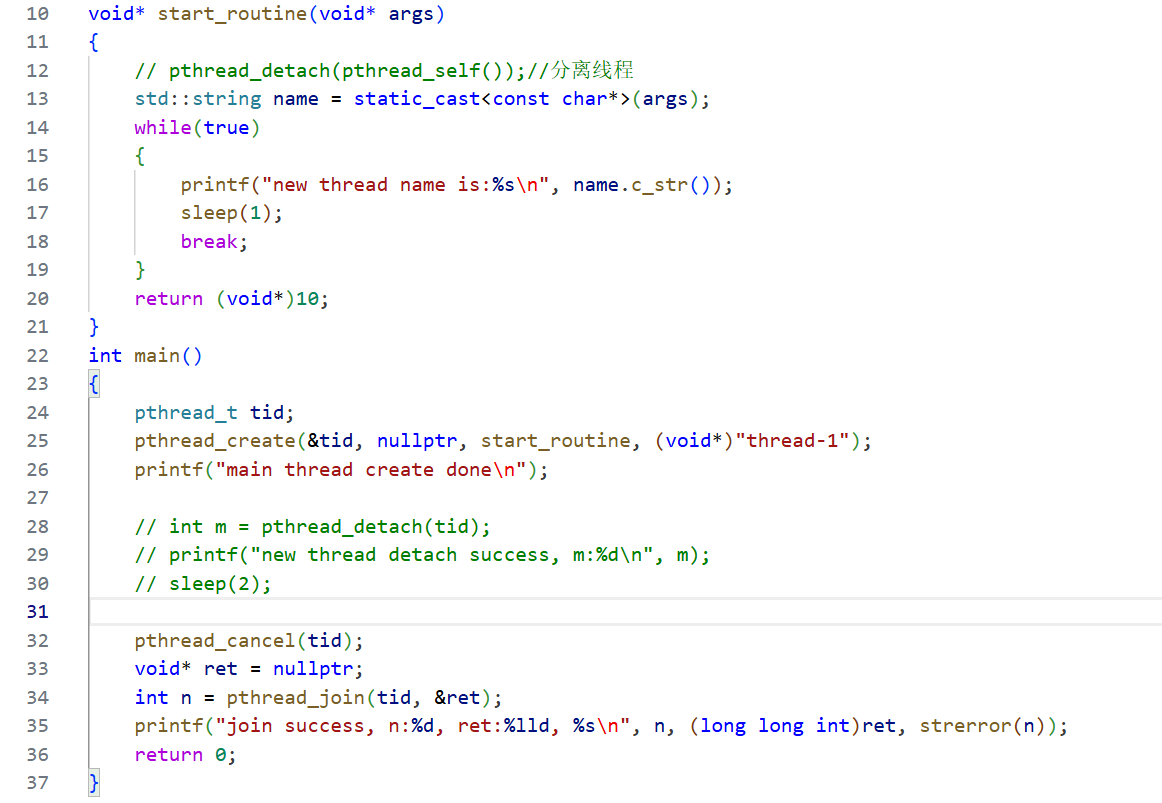

三、線程ID及虛擬地址空間布局
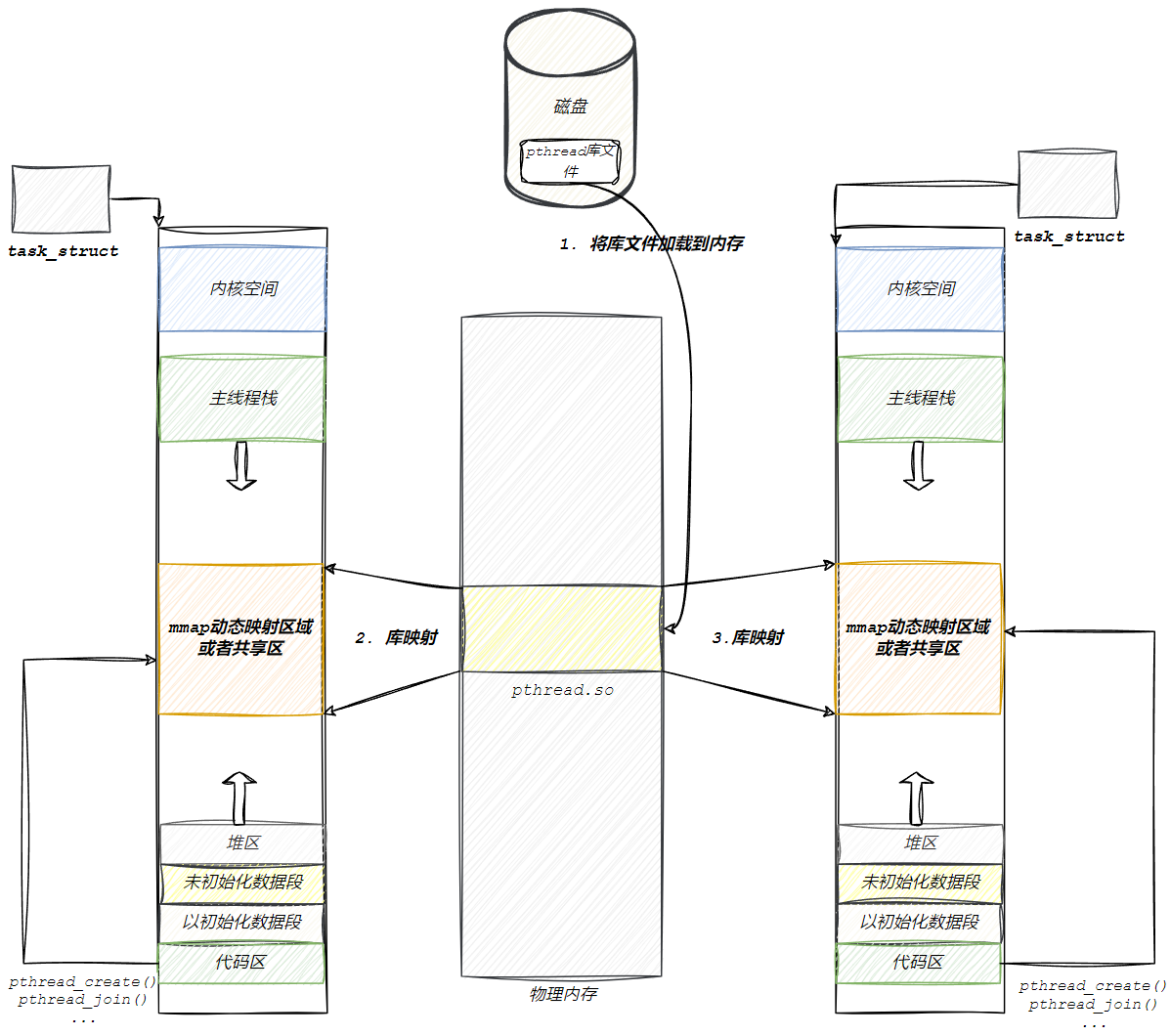
我們說過,線程是由 pthread 庫提供的,所以線程是依賴于 pthread 庫的,將來 pthread 庫也要被加載到內存里。那么,一個進程中可以有許多線程,也可以加載許多進程啊,這些進程中都會包含許多子線程,那么這些進程也是需要將 pthread 庫映射到自己的虛擬地址空間中的,調用mmap 系統調用實現的。
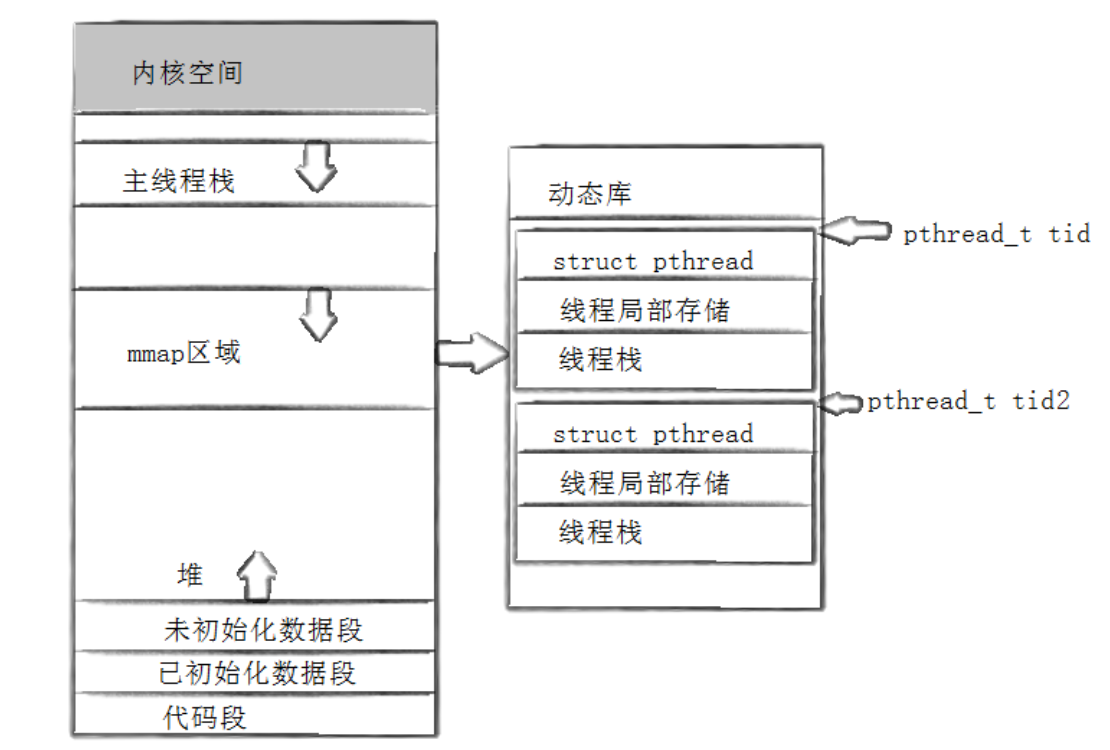
前面我們說過,線程有幾部分資源是獨占的,線程id、一組寄存器(線程的硬件上下文數據)、棧。描述線程的結構體是由 pthread庫維護的,線程棧并不是在虛擬地址空間中的棧區上的,而是在共享區上,由 pthread 庫在共享區上申請的一塊固定的內存空間,主線程的棧是在虛擬地址空間上的。
那么,什么是線程局部存儲?
前面我們說過,全局變量也是多線程之間共享的,那么如果我們要使線程之間獨自私有呢?
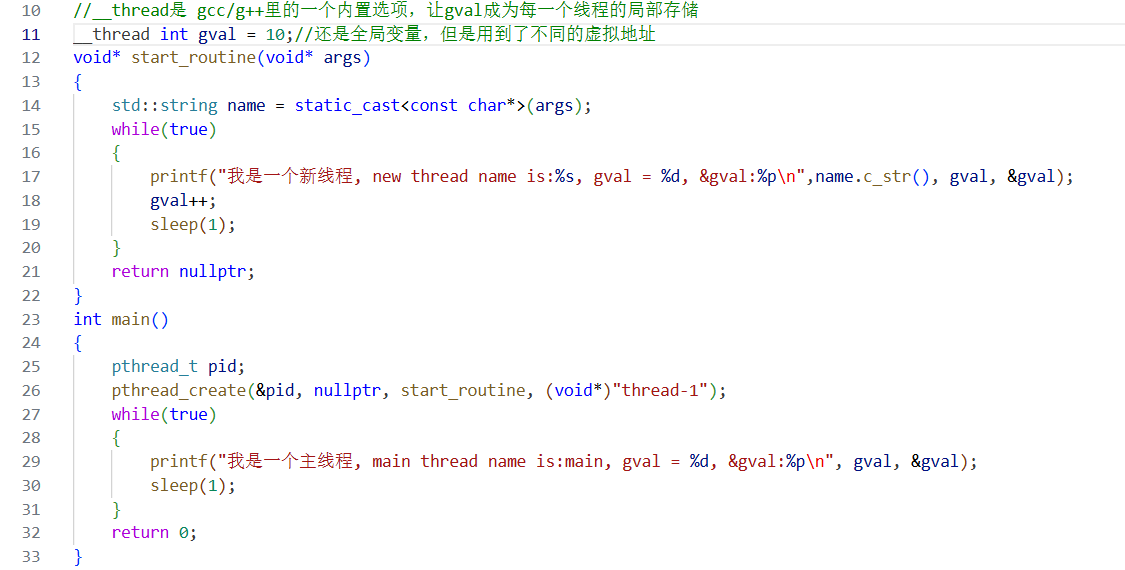
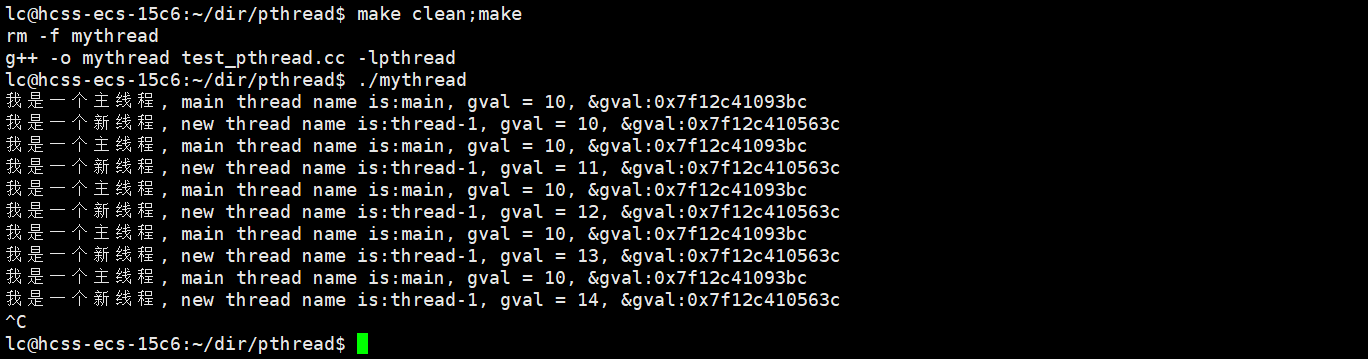
像這樣的就是線程局部存儲。
今天的內容分享就到這里了,覺得不錯的給個一鍵三連吧。
)

LVS負載均衡實現實操)







—stack和queue的介紹及使用)
)




![[C語言]常見排序算法①](http://pic.xiahunao.cn/[C語言]常見排序算法①)


