1. 項目背景
開源大模型如LLaMA,Qwen,Baichuan等主要都是使用通用數據進行訓練而來,其對于不同下游的使用場景和垂直領域的效果有待進一步提升,衍生出了微調訓練相關的需求,包含預訓練(pt),指令微調(sft),基于人工反饋的對齊(rlhf)等全鏈路。但大模型訓練對于顯存和算力的要求較高,同時也需要下游開發者對大模型本身的技術有一定了解,具有一定的門檻。
LLaMA-Factory項目的目標是整合主流的各種高效訓練微調技術,適配市場主流開源模型,形成一個功能豐富,適配性好的訓練框架。項目提供了多個高層次抽象的調用接口,包含多階段訓練,推理測試,benchmark評測,API Server等,使開發者開箱即用。同時借鑒 Stable Diffsion WebUI相關,本項目提供了基于gradio的網頁版工作臺,方便初學者可以迅速上手操作,開發出自己的第一個模型。
2. 本教程目標
以Meta-Llama-3-8B-Instruct 模型 和 Linux + RTX 4090 24GB環境,LoRA+sft訓練階段為例子,幫助開發者迅速瀏覽和實踐本項目會涉及到的常見若干個功能,包括:
-
原始模型直接推理
-
自定義數據集構建
-
基于LoRA的sft指令微調
-
動態合并LoRA的推理
-
批量預測和訓練效果評估
-
LoRA模型合并導出
-
一站式webui board的使用
-
API Server的啟動與調用
-
大模型主流評測 benchmark
本教程大部分內容都可以通過LLaMA-Factory下的 README.md, data/README.md,examples文件夾下的示例腳本得到,遇到問題請先閱讀項目原始相關資料。
關于全參訓練,flash-attention加速, deepspeed,rlhf,多模態模型訓練等更高階feature的使用,后續會有額外的教程來介紹。
3. 前置準備
訓練順利運行需要包含4個必備條件:
-
機器本身的硬件和驅動支持(包含顯卡驅動,網絡環境等)
-
本項目及相關依賴的python庫的正確安裝(包含CUDA, Pytorch等)
-
目標訓練模型文件的正確下載
-
訓練數據集的正確構造和配置
3.1 硬件環境校驗
顯卡驅動和CUDA的安裝,網絡教程很多,不在本教程范圍以內
使用以下命令做最簡單的校驗
nvidia-smi預期輸出如圖,顯示GPU當前狀態和配置信息

那多大的模型用什么訓練方式需要多大的GPU呢,可參考 https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#hardware-requirement
新手建議是3090和4090起步,可以比較容易地訓練比較主流的入門級別大模型 7B和8B版本。

3.2 CUDA和Pytorch環境校驗
請參考項目的readme進行安裝
https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#dependence-installation
2024年51期間系統版本有較大升級,2024-05-06 號的安裝版本命令如下,請注意conda環境的激活。
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e .[metrics]安裝后使用以下命令做簡單的正確性校驗
校驗1
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__預期輸出如圖
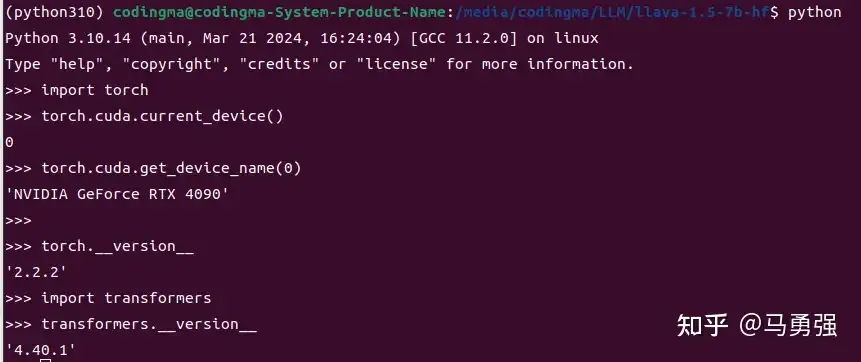
如果識別不到可用的GPU,則說明環境準備還有問題,需要先進行處理,才能往后進行。
校驗2
同時對本庫的基礎安裝做一下校驗,輸入以下命令獲取訓練相關的參數指導, 否則說明庫還沒有安裝成功
llamafactory-cli train -h3.3 模型下載與可用性校驗
項目支持通過模型名稱直接從huggingface 和modelscope下載模型,但這樣不容易對模型文件進行統一管理,所以這里筆者建議使用手動下載,然后后續使用時使用絕對路徑來控制使用哪個模型。
以Meta-Llama-3-8B-Instruct為例,通過huggingface 下載(可能需要先提交申請通過)
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instructmodelscope 下載(適合中國大陸網絡環境)
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git或者
#模型下載
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct')按網友反饋,由于網絡環境等原因,文件下載后往往會存在文件不完整的很多情況,下載后需要先做一下校驗,校驗分為兩部分,第一先檢查一下文件大小和文件數量是否正確,和原始的huggingface顯示的做一下肉眼對比
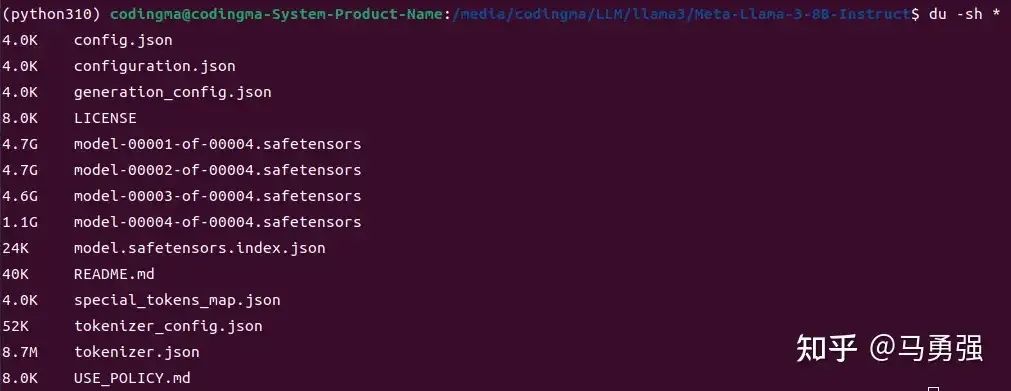
第二步是跑一下官方readme里提供的原始推理demo,驗證模型文件的正確性和transformers庫等軟件的可用
import transformers
import torch # 切換為你下載的模型文件目錄, 這里的demo是Llama-3-8B-Instruct
# 如果是其他模型,比如qwen,chatglm,請使用其對應的官方demo
model_id = "/media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct" pipeline = transformers.pipeline( "text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto",
) messages = [ {"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"}, {"role": "user", "content": "Who are you?"},
] prompt = pipeline.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True
) terminators = [ pipeline.tokenizer.eos_token_id, pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
] outputs = pipeline( prompt, max_new_tokens=256, eos_token_id=terminators, do_sample=True, temperature=0.6, top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])3.4 數據集部分放到后面一起說明
4. 原始模型直接推理
在進行后續的環節之前,我們先使用推理模式,先驗證一下LLaMA-Factory的推理部分是否正常。LLaMA-Factory 帶了基于gradio開發的ChatBot推理頁面, 幫助做模型效果的人工測試。在LLaMA-Factory 目錄下執行以下命令
本腳本參數參考自 LLaMA-Factory/examples/inference/llama3.yaml at main · hiyouga/LLaMA-Factory
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --template llama3CUDA_VISIBLE_DEVICES=0 是指定了當前程序使用第0張卡,是指定全局變量的作用, 也可以不使用
llamafactory-cli webchat \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --template llama3需要注意的是,本次及后續所有的程序的入口都是 llamafactory-cli, 通過不同的參數控制現在是實現什么功能,比如現在是想使用網頁版本直接推理,所以第一個參數設置為webchat, 所有的可選項包括
| 動作參數枚舉 | 參數說明 |
|---|---|
| version | 顯示版本信息 |
| train | 命令行版本訓練 |
| chat | 命令行版本推理chat |
| export | 模型合并和導出 |
| api | 啟動API server,供接口調用 |
| eval | 使用mmlu等標準數據集做評測 |
| webchat | 前端版本純推理的chat頁面 |
| webui | 啟動LlamaBoard前端頁面,包含可視化訓練,預測,chat,模型合并多個子頁面 |
另外兩個關鍵參數解釋如下,后續的基本所有環節都會繼續使用這兩個參數
| 參數名稱 | 參數說明 |
|---|---|
| model_name_or_path | 參數的名稱(huggingface或者modelscope上的標準定義,如“meta-llama/Meta-Llama-3-8B-Instruct”), 或者是本地下載的絕對路徑,如/media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct |
| template | 模型問答時所使用的prompt模板,不同模型不同,請參考https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#supported-models 獲取不同模型的模板定義,否則會回答結果會很奇怪或導致重復生成等現象的出現。chat 版本的模型基本都需要指定,比如Meta-Llama-3-8B-Instruct的template 就是 llama3 |
當然你也可以提前把相關的參數存在yaml文件里,比如LLaMA-Factory/examples/inference/llama3.yaml at main · hiyouga/LLaMA-Factory, 本地位置是 examples/inference/llama3.yaml ,內容如下
model_name_or_path: /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct
template: llama3這樣就可以通過如下命令啟動,其效果跟上面是一樣的,但是更方便管理
llamafactory-cli webchat examples/inference/llama3.yaml效果如圖,可通過 http://localhost:7860/ 進行訪問
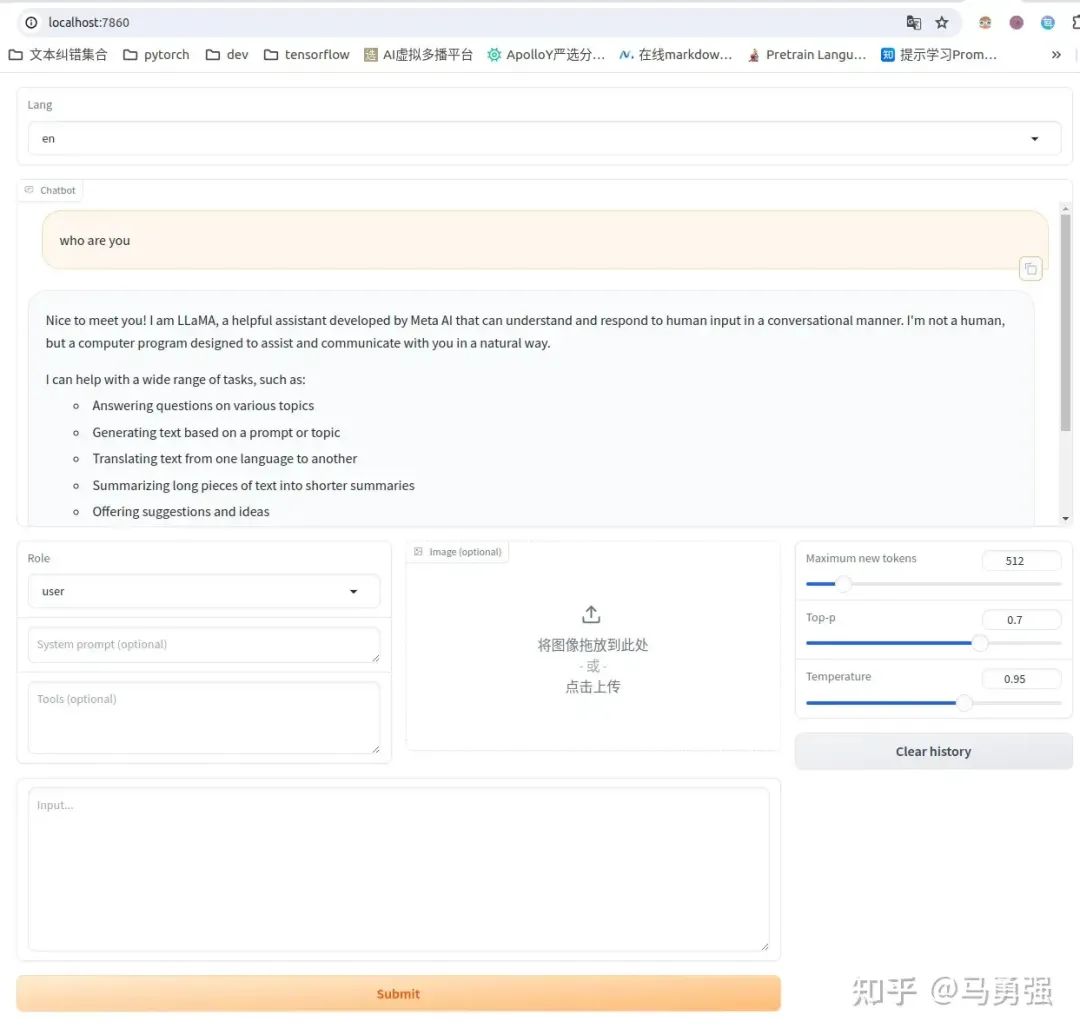
注意:這里的localhost:7860 指的是程序啟動機器自身的7860端口,云上的用戶可能無法通過本地的筆記本電腦直接訪問,需要找云廠商獲取域名和端口號的一些配置關系進行配置
比如阿里云用戶需要做一下如下環境變量的配置才能正常運行gradio,然后再通過阿里云給的域名映射訪問
export GRADIO_ROOT_PATH=/${JUPYTER_NAME}/proxy/7860/5. 自定義數據集構建
數據集的格式要求在不同的階段是不同的,本教程以sft階段的數據集需求,將以系統自帶的identity數據集和將自定義的一個商品文案生成數據集為例,介紹數據集的使用。更多詳情可以在https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md 中找到相關解釋。
系統目前支持 alpaca 和sharegpt兩種數據格式,以alpaca為例,整個數據集是一個json對象的list,具體數據格式為
[ { "instruction": "用戶指令(必填)", "input": "用戶輸入(選填)", "output": "模型回答(必填)", "system": "系統提示詞(選填)", "history": [ ["第一輪指令(選填)", "第一輪回答(選填)"], ["第二輪指令(選填)", "第二輪回答(選填)"] ] }
]例子比如單輪(alpaca_data_zh_51k.json 中的例子, 數據集在data/dataset_info.json中注冊為alpaca_zh)
{ "instruction": "寫一個有效的比較語句", "input": "籃球和足球", "output": "籃球和足球都是受歡迎的運動。"
}和多輪 (oaast_sft_zh.json 中的例子, 數據集在data/dataset_info.json中注冊為oaast_sft_zh)
{ "instruction": "謝謝", "input": "", "output": "不用謝! 很高興我提供的信息能夠幫助到你! 如果還有什么其他問題也可以向我提問。", "history": [ [ "請你給我寫一個面試準備計劃,我想要去面試微軟的程序員崗位", "首先,你可以去微軟官網尋找招聘信息并申請面試。\n其次,您可以在社交媒體平臺尋找微軟公司對程序員的面試問題,并做好準備。\n最后,您可以自己對面試過程進行模擬,熟悉話題并減少緊張感。\n我希望你能面試成功。" ] ]
}所以我們訓練的數據最好也轉換成這種格式,然后在 data/dataset_info.json中進行注冊(如果不做字段名稱轉換,則需要在注冊的時候在 columns字段中做兩個數據的映射配置)
接下來,我們使用兩個具體的例子來說明數據集的使用
第一個是系統自帶的identity.json數據集(已默認在data/dataset_info.json 注冊為identity),對應文件已經在data目錄下,我們通過操作系統的文本編輯器的替換功能,可以替換其中的NAME 和 AUTHOR ,換成我們需要的內容。
替換前
{ "instruction": "Who are you?", "input": "", "output": "I am NAME, an AI assistant developed by AUTHOR. How can I assist you today?"
}替換后
{ "instruction": "Who are you?", "input": "", "output": "I am PonyBot, an AI assistant developed by LLaMA Factory. How can I assist you today?"
}第二個是一個商品文案生成數據集,原始鏈接為https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
原始格式如下,很明顯,訓練目標是輸入content (也就是prompt), 輸出 summary (對應response)
{ "content": "類型#褲*版型#寬松*風格#性感*圖案#線條*褲型#闊腿褲", "summary": "寬松的闊腿褲這兩年真的吸粉不少,明星時尚達人的心頭愛。畢竟好穿時尚,誰都能穿出腿長2米的效果寬松的褲腿,當然是遮肉小能手啊。上身隨性自然不拘束,面料親膚舒適貼身體驗感棒棒噠。系帶部分增加設計看點,還讓單品的設計感更強。腿部線條若隱若現的,性感撩人。顏色敲溫柔的,與褲子本身所呈現的風格有點反差萌。"
}想將該自定義數據集放到我們的系統中使用,則需要進行如下兩步操作
-
復制該數據集到 data目錄下
-
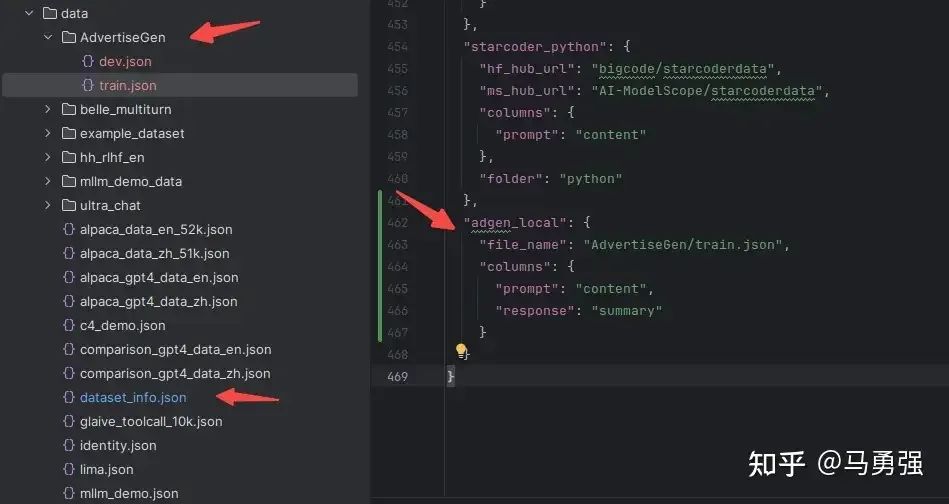
修改 data/dataset_info.json 新加內容完成注冊, 該注冊同時完成了3件事
-
自定義數據集的名稱為adgen_local,后續訓練的時候就使用這個名稱來找到該數據集
-
指定了數據集具體文件位置
-
定義了原數據集的輸入輸出和我們所需要的格式之間的映射關系
6. 基于LoRA的sft指令微調
在準備好數據集之后,我們就可以開始準備訓練了,我們的目標就是讓原來的LLaMA3模型能夠學會我們定義的“你是誰”,同時學會我們希望的商品文案的一些生成。
這里我們先使用命令行版本來做訓練,從命令行更容易學習相關的原理。
本腳本參數改編自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/lora_single_gpu/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage sft \ --do_train \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --dataset alpaca_gpt4_zh,identity,adgen_local \ --dataset_dir ./data \ --template llama3 \ --finetuning_type lora \ --lora_target q_proj,v_proj \ --output_dir ./saves/LLaMA3-8B/lora/sft \ --overwrite_cache \ --overwrite_output_dir \ --cutoff_len 1024 \ --preprocessing_num_workers 16 \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --logging_steps 50 \ --warmup_steps 20 \ --save_steps 100 \ --eval_steps 50 \ --evaluation_strategy steps \ --load_best_model_at_end \ --learning_rate 5e-5 \ --num_train_epochs 5.0 \ --max_samples 1000 \ --val_size 0.1 \ --plot_loss \ --fp16關于參數的完整列表和解釋可以通過如下命令來獲取
llamafactory-cli train -h這里我對部分關鍵的參數做一下解釋,model_name_or_path 和template 上文已解釋
| 參數名稱 | 參數說明 |
|---|---|
| stage | 當前訓練的階段,枚舉值,有“sft”,“pt”,“rw”,"ppo"等,代表了訓練的不同階段,這里我們是有監督指令微調,所以是sft |
| do_train | 是否是訓練模式 |
| dataset | 使用的數據集列表,所有字段都需要按上文在data_info.json里注冊,多個數據集用","分隔 |
| dataset_dir | 數據集所在目錄,這里是 data,也就是項目自帶的data目錄 |
| finetuning_type | 微調訓練的類型,枚舉值,有"lora",“full”,"freeze"等,這里使用lora |
| lora_target | 如果finetuning_type是lora,那訓練的參數目標的定義,這個不同模型不同,請到https://github.com/hiyouga/LLaMA-Factory/tree/main?tab=readme-ov-file#supported-models 獲取 不同模型的 可支持module, 比如llama3 默認是 q_proj,v_proj |
| output_dir | 訓練結果保存的位置 |
| cutoff_len | 訓練數據集的長度截斷 |
| per_device_train_batch_size | 每個設備上的batch size,最小是1,如果GPU 顯存夠大,可以適當增加 |
| fp16 | 使用半精度混合精度訓練 |
| max_samples | 每個數據集采樣多少數據 |
| val_size | 隨機從數據集中抽取多少比例的數據作為驗證集 |
| 注意:精度相關的參數還有bf16 和pure_bf16,但是要注意有的老顯卡,比如V100就無法支持bf16,會導致程序報錯或者其他錯誤 |
|---|
訓練過程中,系統會按照logging_steps的參數設置,定時輸出訓練日志,包含當前loss,訓練進度等

訓練完后就可以在設置的output_dir下看到如下內容,主要包含3部分
-
adapter開頭的就是 LoRA保存的結果了,后續用于模型推理融合
-
training_loss 和trainer_log等記錄了訓練的過程指標
-
其他是訓練當時各種參數的備份
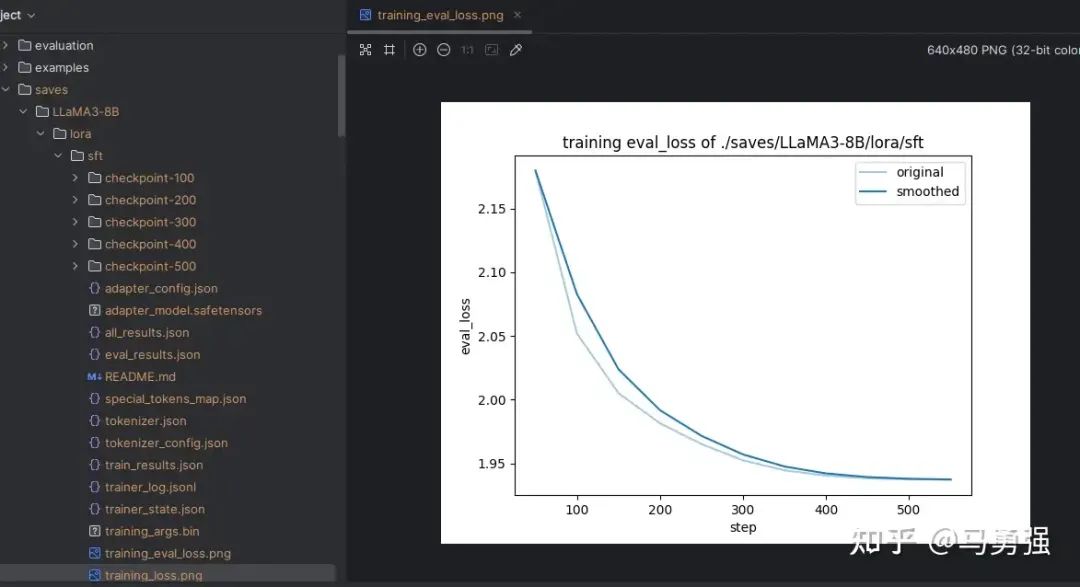
關于loss是什么等,這塊不在本教程討論內容范圍之內,只需要記住loss在 正常情況下會隨著訓練的時間慢慢變小,最后需要下降到1以下的位置才會有一個比較好的效果,可以作為訓練效果的一個中間指標。
7. 動態合并LoRA的推理
本腳本參數改編自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/inference/llama3_lora_sft.yaml
當基于LoRA的訓練進程結束后,我們如果想做一下動態驗證,在網頁端里與新模型對話,與步驟4的原始模型直接推理相比,唯一的區別是需要通過finetuning_type參數告訴系統,我們使用了LoRA訓練,然后將LoRA的模型位置通過 adapter_name_or_path參數即可。
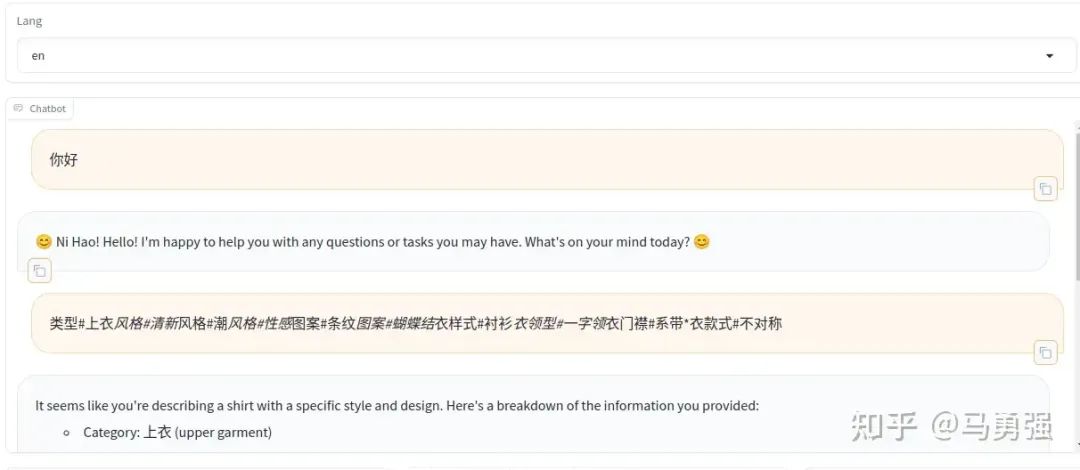
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora效果如下,可以看到,模型整個已經在學習了新的數據知識,學習了新的身份認知和商品文案生成的格式。

作為對比,如果刪除LoRA相關參數,只使用原始模型重新啟動測試,可以看到模型還是按照通用的一種回答。
如果不方便使用webui來做交互,使用命令行來做交互,同樣也是可以的。
本腳本改編自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/inference/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora效果如下

8. 批量預測和訓練效果評估
當然上文中的人工交互測試,會偏感性,那有沒有辦法批量地預測一批數據,然后使用自動化的bleu和 rouge等常用的文本生成指標來做評估。指標計算會使用如下3個庫,請先做一下pip安裝
pip install jieba
pip install rouge-chinese
pip install nltk本腳本參數改編自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/lora_single_gpu/llama3_lora_predict.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage sft \ --do_predict \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --dataset alpaca_gpt4_zh,identity,adgen_local \ --dataset_dir ./data \ --template llama3 \ --finetuning_type lora \ --output_dir ./saves/LLaMA3-8B/lora/predict \ --overwrite_cache \ --overwrite_output_dir \ --cutoff_len 1024 \ --preprocessing_num_workers 16 \ --per_device_eval_batch_size 1 \ --max_samples 20 \ --predict_with_generate與訓練腳本主要的參數區別如下兩個
| 參數名稱 | 參數說明 |
|---|---|
| do_predict | 現在是預測模式 |
| predict_with_generate | 現在用于生成文本 |
| max_samples | 每個數據集采樣多少用于預測對比 |
最后會在output_dir下看到如下內容
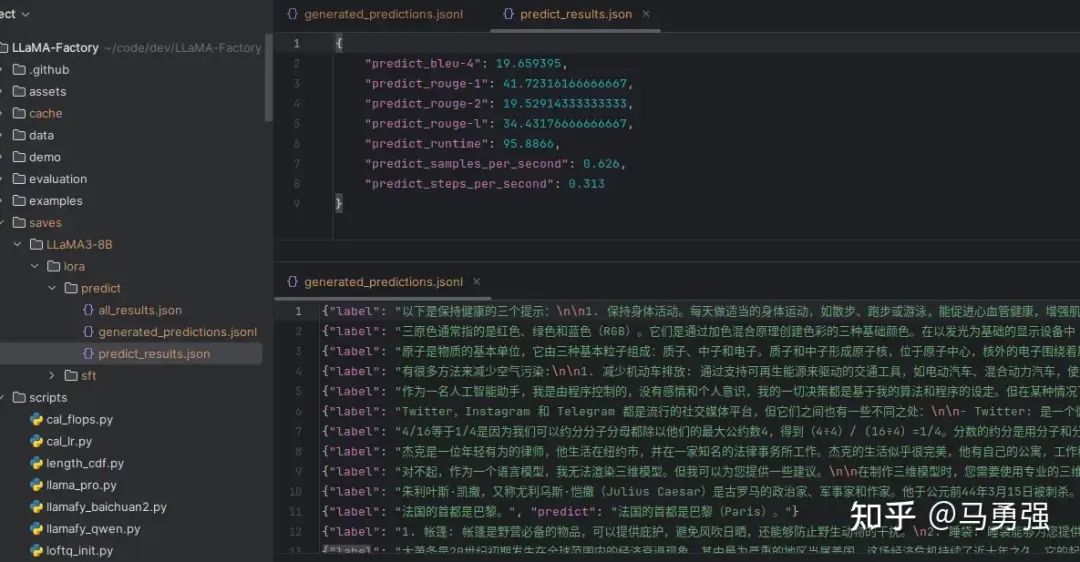
其中 generated_predictions.jsonl 文件 輸出了要預測的數據集的原始label和模型predict的結果
predict_results.json給出了原始label和模型predict的結果,用自動計算的指標數據
這里給相關的指標做一下進一步的解釋
| 指標 | 含義 |
|---|---|
| BLEU-4 | BLEU(Bilingual Evaluation Understudy)是一種常用的用于評估機器翻譯質量的指標。BLEU-4 表示四元語法 BLEU 分數,它衡量模型生成文本與參考文本之間的 n-gram 匹配程度,其中 n=4。值越高表示生成的文本與參考文本越相似,最大值為 100。 |
| predict_rouge-1 和 predict_rouge-2 | ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一種用于評估自動摘要和文本生成模型性能的指標。ROUGE-1 表示一元 ROUGE 分數,ROUGE-2 表示二元 ROUGE 分數,分別衡量模型生成文本與參考文本之間的單個詞和雙詞序列的匹配程度。值越高表示生成的文本與參考文本越相似,最大值為 100。 |
| predict_rouge-l | ROUGE-L 衡量模型生成文本與參考文本之間最長公共子序列(Longest Common Subsequence)的匹配程度。值越高表示生成的文本與參考文本越相似,最大值為 100。 |
| predict_runtime | 預測運行時間,表示模型生成一批樣本所花費的總時間。單位通常為秒。 |
| predict_samples_per_second | 每秒生成的樣本數量,表示模型每秒鐘能夠生成的樣本數量。通常用于評估模型的推理速度。 |
| predict_steps_per_second | 每秒執行的步驟數量,表示模型每秒鐘能夠執行的步驟數量。對于生成模型,一般指的是每秒鐘執行生成操作的次數。 |
9. LoRA模型合并導出
如果想把訓練的LoRA和原始的大模型進行融合,輸出一個完整的模型文件的話,可以使用如下命令。合并后的模型可以自由地像使用原始的模型一樣應用到其他下游環節,當然也可以遞歸地繼續用于訓練。
本腳本參數改編自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/merge_lora/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora \ --export_dir megred-model-path \ --export_size 2 \ --export_device cpu \ --export_legacy_format False10. 一站式webui board的使用
到這里,恭喜你完成了LLaMA-Efficent-Tuning訓練框架的基礎使用,那還有什么內容是沒有介紹的呢?還有很多!這里介紹一個在提升交互體驗上有重要作用的功能, 支持模型訓練全鏈路的一站式WebUI board。一個好的產品離不開好的交互,Stable Diffusion的大放異彩的重要原因除了強大的內容輸出效果,就是它有一個好的WebUI。這個board將訓練大模型主要的鏈路和操作都在一個頁面中進行了整合,所有參數都可以可視化地編輯和操作
通過以下命令啟動
| 注意:目前webui版本只支持單機單卡,如果是多卡請使用命令行版本 |
|---|
llamafactory-cli webui如圖所示,上述的多個不同的大功能模塊都通過不同的tab進行了整合,提供了一站式的操作體驗。
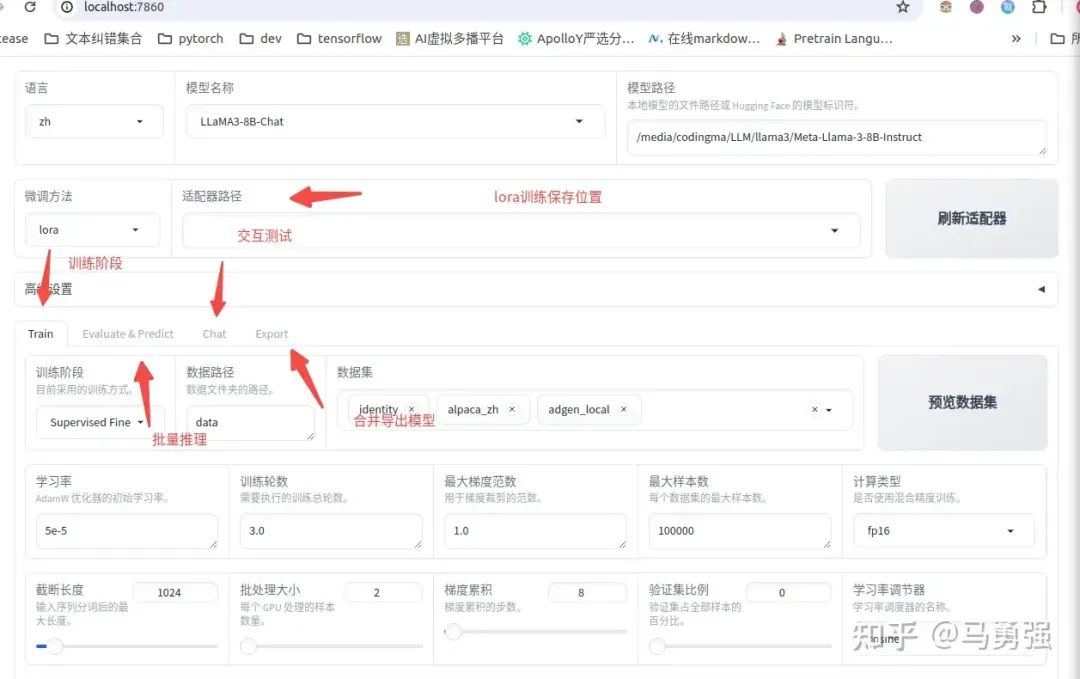
當各種參數配置好后,在train頁面,可以通過預覽命令功能,將訓練腳本導出,用于支持多gpu訓練
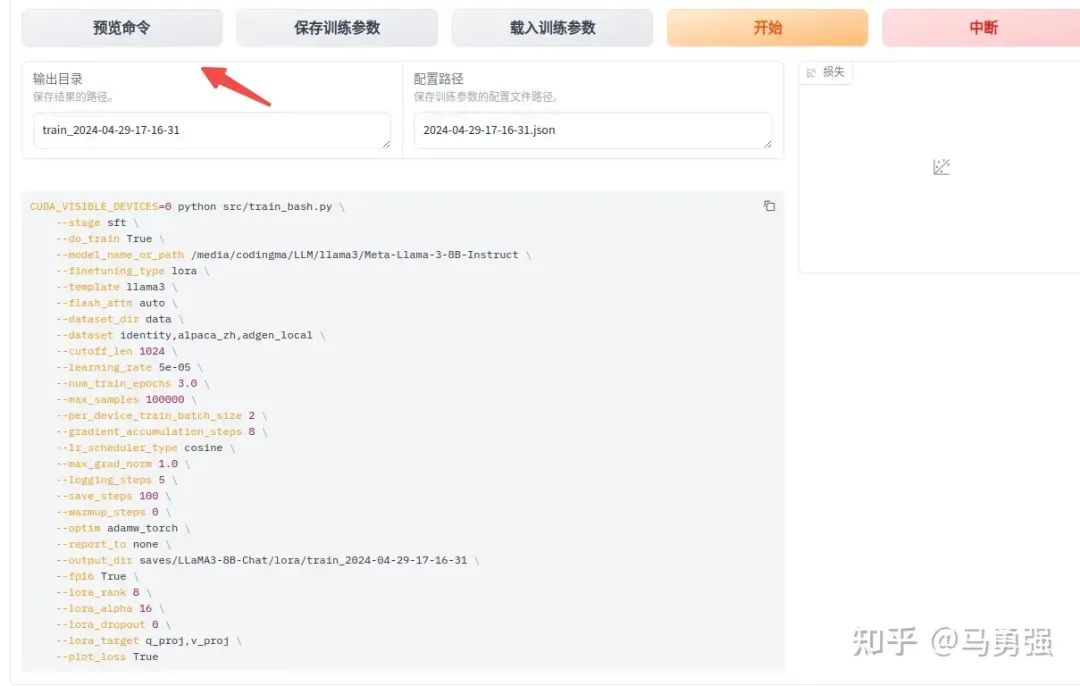
點擊開始按鈕, 即可開始訓練,網頁端和服務器端會同步輸出相關的日志結果
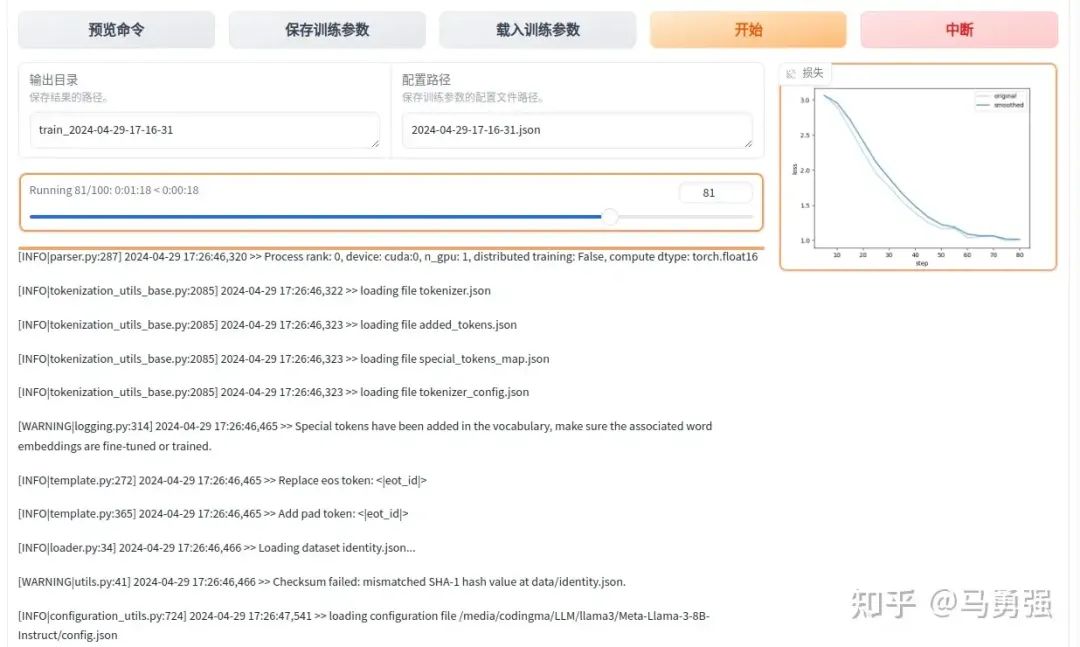
訓練完畢后, 點擊“刷新適配器”,即可找到該模型歷史上使用webui訓練的LoRA模型文件,后續再訓練或者執行chat的時候,即會將此LoRA一起加載。

11. API Server的啟動與調用
訓練好后,可能部分同學會想將模型的能力形成一個可訪問的網絡接口,通過API 來調用,接入到langchian或者其他下游業務中,項目也自帶了這部分能力。
API 實現的標準是參考了OpenAI的相關接口協議,基于uvicorn服務框架進行開發, 使用如下的方式啟動
本腳本改編自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/inference/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora項目也支持了基于vllm 的推理后端,但是這里由于一些限制,需要提前將LoRA 模型進行merge,使用merge后的完整版模型目錄或者訓練前的模型原始目錄都可。
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \ --model_name_or_path megred-model-path \ --template llama3 \ --infer_backend vllm \ --vllm_enforce_eager服務啟動后,即可按照openai 的API 進行遠程訪問,主要的區別就是替換 其中的base_url,指向所部署的機器url和端口號即可。
12. 進階-大模型主流評測 benchmark
雖然大部分同學的主流需求是定制一個下游的垂直模型,但是在部分場景下,也可能有同學會使用本項目來做更高要求的模型訓練,用于大模型刷榜單等,比如用于評測mmlu等任務。當然這類評測同樣可以用于評估大模型二次微調之后,對于原來的通用知識的泛化能力是否有所下降。(因為一個好的微調,盡量是在具備垂直領域知識的同時,也保留了原始的通用能力)
本項目提供了mmlu,cmmlu, ceval三個常見數據集的自動評測腳本,按如下方式進行調用即可。
本腳本改編自 LLaMA-Factory/examples/lora_single_gpu/llama3_lora_eval.yaml at main · hiyouga/LLaMA-Factory
如果是chat版本的模型
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--template llama3 \
--task mmlu \
--split validation \
--lang en \
--n_shot 5 \
--batch_size 1輸出如下, 具體任務的指標定義請參考mmlu,cmmlu, ceval等任務原始的相關資料, 和llama3的官方報告基本一致
Average: 63.64 STEM: 50.83
Social Sciences: 76.31 Humanities: 56.63 Other: 73.31如果是base版本的模型,template改為fewshot即可
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B \
--template fewshot \
--task mmlu \
--split validation \
--lang en \
--n_shot 5 \
--batch_size 1零基礎入門AI大模型
由于新崗位的生產效率,要優于被取代崗位的生產效率,所以實際上整個社會的生產效率是提升的。
但是具體到個人,只能說是:
“最先掌握AI的人,將會比較晚掌握AI的人有競爭優勢”。
這句話,放在計算機、互聯網、移動互聯網的開局時期,都是一樣的道理。
我在一線互聯網企業工作十余年里,指導過不少同行后輩。幫助很多人得到了學習和成長。
我意識到有很多經驗和知識值得分享給大家,也可以通過我們的能力和經驗解答大家在人工智能學習中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。但苦于知識傳播途徑有限,很多互聯網行業朋友無法獲得正確的資料得到學習提升,故此將并將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。
需要的可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】


第一階段: 從大模型系統設計入手,講解大模型的主要方法;
第二階段: 在通過大模型提示詞工程從Prompts角度入手更好發揮模型的作用;
第三階段: 大模型平臺應用開發借助阿里云PAI平臺構建電商領域虛擬試衣系統;
第四階段: 大模型知識庫應用開發以LangChain框架為例,構建物流行業咨詢智能問答系統;
第五階段: 大模型微調開發借助以大健康、新零售、新媒體領域構建適合當前領域大模型;
第六階段: 以SD多模態大模型為主,搭建了文生圖小程序案例;
第七階段: 以大模型平臺應用與開發為主,通過星火大模型,文心大模型等成熟大模型構建大模型行業應用。

👉學會后的收獲:👈
? 基于大模型全棧工程實現(前端、后端、產品經理、設計、數據分析等),通過這門課可獲得不同能力;
? 能夠利用大模型解決相關實際項目需求: 大數據時代,越來越多的企業和機構需要處理海量數據,利用大模型技術可以更好地處理這些數據,提高數據分析和決策的準確性。因此,掌握大模型應用開發技能,可以讓程序員更好地應對實際項目需求;
? 基于大模型和企業數據AI應用開發,實現大模型理論、掌握GPU算力、硬件、LangChain開發框架和項目實戰技能, 學會Fine-tuning垂直訓練大模型(數據準備、數據蒸餾、大模型部署)一站式掌握;
? 能夠完成時下熱門大模型垂直領域模型訓練能力,提高程序員的編碼能力: 大模型應用開發需要掌握機器學習算法、深度學習框架等技術,這些技術的掌握可以提高程序員的編碼能力和分析能力,讓程序員更加熟練地編寫高質量的代碼。

1.AI大模型學習路線圖
2.100套AI大模型商業化落地方案
3.100集大模型視頻教程
4.200本大模型PDF書籍
5.LLM面試題合集
6.AI產品經理資源合集
這份完整版的學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】

)


—— 吃透泛型機制,筑牢 Java 類型安全防線)


(2))


:角色、用戶及項目管理實踐)





)


