Baichuan-M2 醫療大模型:技術解讀與使用方法
Baichuan-M2:大語言模型在醫療領域的動態驗證框架
【醫療 AI】Baichuan-M2:大語言模型在醫療領域的動態驗證框架
- 0. Baichuan-M2 模型簡介
- 0.1 基本信息
- 0.2 主要貢獻
- 0.3 論文摘要
- 1. 引言
- 2. 驗證系統
- 2.1 患者模擬器
- 2.2 臨床評分標準生成器
- 3. 數據與訓練
- 3.1 中期訓練
- 3.2 監督微調
- 3.3 強化訓練
- 4. 評估
- 4.1 HealthBench評估
- 4.2 中國醫療場景對比研究
- 4.3 通用能力評估
- 5 推理優化
- 5.1 訓練后量化
- 5.2 推測性解碼
- 6. 結論
- 7. 局限性與未來工作
- 8. 快速使用方法
- 9. 參考文獻
0. Baichuan-M2 模型簡介
0.1 基本信息
Baichuan-M2-32B 是【百川智能】推出的醫療增強推理模型,專注于解決真實世界中的各類醫療推理任務。該模型以 Qwen2.5-32B 為基座,創新性地集成大型驗證系統(Large Verifier System)。該模型通過對真實醫療問題進行領域微調,在保持卓越通用能力的同時,實現了醫療性能的突破性提升。
2025年 9月,Beichuan-M2 Team 在 Arxiv 發表論文:Baichuan-M2:大語言模型在醫療領域的動態驗證框架(Baichuan-M2: Scaling Medical Capability with Large Verifier System),介紹 Baichuan-M2 醫療增強推理模型。
論文下載: Arxiv - Baichuan-M2
Github: Github/Baichuan-M2
技術社區: Blog- Baichuan-M2
百川官網: 【百川智能】
模型下載:
Huggingface - Baichuan-M2-32B
Huggingface - Baichuan-M2-GPTQ-4bit
Huawei Ascend 8bit

0.2 主要貢獻
-
面向臨床場景的動態驗證系統:
突破基于靜態數據的傳統驗證局限,通過患者模擬器構建高保真決策環境,結合臨床量規實時生成量化評估指標,顯著提升驗證過程可靠性。 -
創新的訓練方法論:
在動態交互環境中成功實施多階段強化學習策略,對GRPO算法進行針對性改進,使模型突破靜態知識記憶,深度對齊醫學專家的高階臨床推理能力。 -
先進的Baichuan-M2開源模型:
以顯著更低的部署成本實現頂級性能,確立性能-參數權衡的新帕累托前沿,為資源受限的醫療場景部署高階醫療AI提供可行性方案。
0.3 論文摘要
隨著大語言模型(LLMs)在對話與推理能力上的進步,其醫療實踐應用已成為關鍵研究方向。然而,醫學大模型在USMLE等靜態基準測試中的表現與現實臨床決策效用之間存在顯著斷層——傳統考試難以體現診療動態交互的本質特征。為此,我們突破靜態答案驗證范式,提出一種新型動態驗證框架,構建了大規模高保真交互式強化學習系統。該框架包含兩大核心組件:
- 患者模擬器:基于脫敏病歷構建擬真臨床環境
- 臨床量規生成器:動態生成多維評估指標
在此框架基礎上,我們開發了320億參數醫療增強推理模型Baichuan-M2,采用改進版分組相對策略優化(GRPO)算法進行多階段強化學習訓練。在HealthBench評測中,Baichuan-M2超越所有開源模型及多數先進閉源模型,在極具挑戰性的HealthBench Hard基準上取得32分以上成績——此前僅有GPT-5達成該水平。本研究證實:強健的動態驗證系統對實現大模型能力與臨床實踐的對齊至關重要,為醫療AI部署確立了性能-參數權衡的新帕累托前沿。
1. 引言
隨著大語言模型(LLMs)對話與推理能力的持續進步,其在垂直領域中的實際應用正受到日益廣泛的關注。醫療健康領域尤其成為研究焦點,吸引了全球科技巨頭與創新企業的大量投入[1-3]。在提升LLMs醫療能力的諸多技術路線中,基于可驗證獎勵的強化學習(RLVR)展現出顯著優勢[4,5],該技術已在數學[6-8]、編程[9]、智能體[10,11]及多模態[12,13]等領域取得突破性進展,這些成果凸顯了其增強模型推理能力的潛力,也使其在醫療領域的應用成為極具前景的研究方向。
RLVR的核心在于構建強健的評估體系。其在數學、編程等領域的成功,很大程度上依賴于精確可靠的評估標準。然而在醫療領域,當前LLMs的評估方法與實際應用之間存在顯著斷層:在美國醫師執照考試(USMLE)等專業測試中表現優越的模型[14],往往在真實臨床決策中表現欠佳。這種差異源于傳統靜態基準測試無法捕捉臨床實踐的動態復雜性——真實診療場景通常涉及信息不完整、多輪診斷探索及精細化的溝通技巧,而這些維度均未被常規考試有效量化。
為應對這些挑戰,我們研究重心從靜態答案驗證轉向構建大規模高保真交互式強化學習驗證系統。該系統突破傳統答案驗證范式,通過模擬真實臨床場景,使模型能在虛擬診療環境中通過"實踐"進行學習與適配。基于此,我們提出醫療增強推理模型Baichuan-M2,標志著開源醫療人工智能的重大進展。
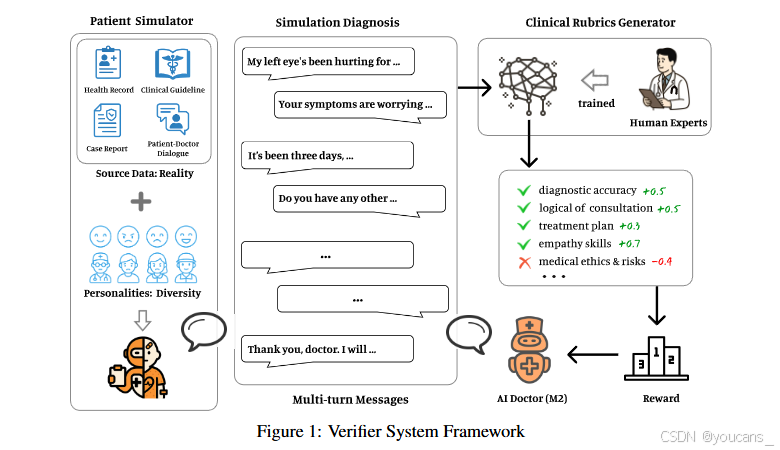
該驗證系統包含兩大核心組件:其一是患者模擬器,融合脫敏病歷與醫患對話記錄,能有效模擬不同社會背景與性格特征的患者,提供高度擬真的交互環境;其二是臨床量規生成器,可模擬資深醫師的臨床思維,根據診斷準確性、問診邏輯性、治療方案合理性、溝通共情力及醫學倫理等多維度,動態生成可量化的大規模評估標準。
我們的訓練流程包含醫療領域適配的中期訓練、帶拒絕采樣的監督微調(SFT),以及采用改進版分組相對策略優化(GRPO)[8]算法的多階段強化學習(RL)。通過多階段強化學習策略,我們將復雜強化學習任務解耦為可控的層級結構,在保持模型通用能力的同時,顯著提升其醫學知識、推理能力和患者交互等專項能力。
在OpenAI開發的HealthBench基準測試集[15]上,盡管參數量僅320億,Baichuan-M2仍超越包括gpt-oss-120B在內的所有開源模型及多數先進閉源模型。其在HealthBench Hard測試中以超過32分的表現尤為突出——此前全球僅GPT-5達到該水平。這些實驗成果印證了強健驗證系統對模型能力與實際應用對接的關鍵作用。
我們的核心貢獻可概括為:
- 面向臨床場景的動態驗證系統:突破基于靜態數據的傳統驗證局限,通過患者模擬器構建高保真決策環境,結合臨床量規實時生成量化評估指標,顯著提升驗證過程可靠性。
- 創新的訓練方法論:在動態交互環境中成功實施多階段強化學習策略,對GRPO算法進行針對性改進,使模型突破靜態知識記憶,深度對齊醫學專家的高階臨床推理能力。
- 先進的Baichuan-M2開源模型:以顯著更低的部署成本實現頂級性能,確立性能-參數權衡的新帕累托前沿,為資源受限的醫療場景部署高階醫療AI提供可行性方案。
2. 驗證系統
近年來,RLVR技術在數學、編程及智能體系統等復雜推理領域取得顯著成功。構建更具可驗證性的復雜問題與環境,已成為推動模型能力持續突破的核心驅動力。然而當該范式遷移至醫療領域時,我們發現現有方法存在顯著局限:基于傳統醫學題庫構建的靜態答案驗證器無法捕捉真實診療過程的動態復雜性,往往導致模型在實際應用中泛化能力受限。真實臨床實踐是一個部分可觀測、多輪次的決策過程,高度依賴醫師的動態判斷力,需要綜合臨床經驗、溝通技巧與倫理考量等維度。
為應對這一挑戰,在Baichuan-M2開發過程中,我們轉向構建大規模高保真動態交互式強化學習環境,旨在打造模型可"訓練成長"的"虛擬臨床世界"。該系統主要由兩大核心模塊構成:“患者模擬器"與"臨床量規生成器”。患者模擬器將訓練環境從僵化的單輪問答提升至擬真、隨機、連續的交互場景;臨床量規生成器(如圖1所示)動態生成回答驗證規則,實現對模型多輪交互中綜合表現的持續性動態量化評估。
通過這一閉環系統,我們成功實現了大規模端到端強化學習:模型持續與"虛擬患者"互動,基于"專家級評估"的密集反饋迭代優化診斷策略。最終使模型能力突破靜態知識記憶,實現與資深醫師臨床思維及實踐技能的深度對齊。
2.1 患者模擬器
患者模擬器在AI醫師訓練與評估中具有關鍵作用[16-17],其提供的動態測試環境能有效克服傳統靜態測試方法難以評估LLMs動態診療能力的缺陷。然現有研究中廣泛采用的模擬器[18-19]對患者心理狀態、社會背景及動態交互的建模存在不足,使其退化為靜態數據庫,無法復現真實臨床遭遇的復雜性——這些遭遇常涉及信息保留、情緒表達及文化因素導致的溝通障礙,這些要素對AI醫師在實際場景中的適應能力至關重要。
開發高保真患者模擬器的核心挑戰在于平衡多樣性與一致性。實現多樣性需要龐大的疾病知識庫結合多維行為模型以覆蓋廣泛臨床情境;而確保一致性則需預設腳本與行為約束以維護特定案例的可復現性。基于前人研究[16],我們訓練出具有最優多樣性-一致性權衡的高保真患者模擬器,提供了高度真實的交互環境。
2.1.1 患者劇本
患者劇本通過整合醫學與心理信息提升行為模擬的真實性。
-
醫學信息:
該模塊包含主訴、現病史和既往史等關鍵要素,用于評估醫師信息采集能力。我們收集整理了真實場景下的高質量臨床數據集,覆蓋多專科與人群特征,其疾病分布精確反映流行病學特征和典型診療情景,確保堅實的醫學真實性基礎。 -
心理信息:
行為模式通過人格特質與社會文化背景定義。基于MBTI 16型人格模型[20],我們映射了差異化行為表征:例如外向型(E)患者會主動詢問治療方案,而內向型(I)則被動接受信息;情感型(F)比思考型(T)對溝通方式更敏感,進而影響治療依從性。社會屬性進一步驅動差異化治療反應——經濟困難患者常抗拒高成本方案,而高學歷患者更注重循證醫學依據。這種多維建模顯著增強了虛擬患者的真實性與多樣性。
2.1.2 模塊與內部交互
在患者模擬器實現過程中,我們發現大模型雖能呈現更高人格保真度,但計算成本過高難以融入強化學習訓練循環;而優先采用小模型又會導致患者畫像行為一致性下降,阻礙強化學習收斂。具體表現為三大問題:
- 信息泄漏:未經提示即透露額外細節,弱化問診場景挑戰性
- 事實矛盾:回答與預設畫像屬性沖突,產生臨床事實錯誤
- 終止失控:對話提前中斷或無法正常結束,破壞模擬完整性
為此,我們提出由三組件構成的架構(圖2):
- 終止門控:根據預設觸發條件(如醫師確診)決定會話終止
- 情感單元:生成符合畫像的響應,通過角色扮演實現行為多樣性
- 事實單元:實時校驗回答與患者檔案的一致性,防止信息泄漏與矛盾
基于該架構,我們實現了參數量更小但性能媲美大模型的患者模擬器。
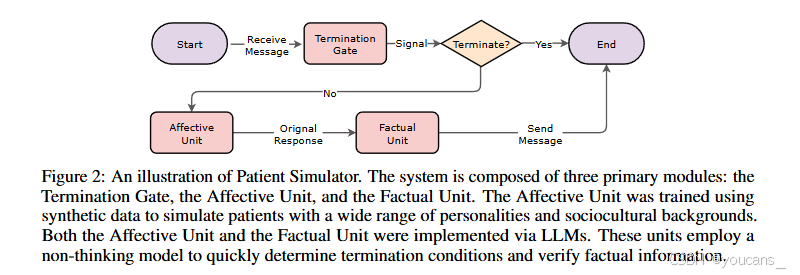
圖2:患者模擬器架構示意圖。該系統由三大核心模塊構成:終止門控模塊、情感單元模塊與事實校驗模塊。其中情感單元模塊通過合成數據訓練,用于模擬具有多樣化人格特質與社會文化背景的患者行為。情感單元與事實校驗模塊均基于大語言模型實現,采用非思維型輕量化計算模式快速判定終止條件并核驗事實信息。
2.1.3 患者模擬器性能
我們提出雙維度評估框架,結合細粒度輪次分析與整體會話級保真指標:
- 單輪次層面
- 隱私評分:量化不披露與臨床無關個人隱私的對話輪次占比
- 事實評分:衡量對話內容遵循預設病歷而無虛構的程度
- 最終得分為所有輪次得分的均值
- 會話層面
通過人格化評分評估行為一致性。該復合指標均衡考量人格特質一致性與社會文化一致性,整體衡量行為保真度。
以DeepSeek-V3[6]為基線,設置兩種對照:標準提示(不含心理上下文)與增強提示(顯式包含心理信息)。如圖3所示,實驗結果證明:
- 人格化評分提升通常伴隨隱私/事實評分下降
- 我們的方法以更少參數實現了最優的多樣性-一致性權衡

圖3:患者模擬器性能對比。實驗結果顯示,DeepSeek-V3在引入心理信息后隱私評分與事實評分顯著下降,表明該模型在評估過程中會因過量的隨機噪聲導致實驗結果產生較大波動。相比之下,我們提出的模擬器方法在提升人格化評分的同時,能最優地維持隱私評分與事實評分的穩定性。
2.2 臨床評分標準生成器
在實際臨床場景中,患者需要的是超越孤立醫療答案的綜合診療服務,這涉及動態決策、診斷推理、治療規劃以及體現醫生專業素養的溝通能力。傳統基于強化學習系統的二元驗證方法(依賴答案匹配或規則匹配的獎勵信號)難以應對這種固有復雜性,亟待建立能夠捕捉專家醫療實踐中細微臨床判斷與專業標準的新方法。
為此,我們提出一種生成式驗證系統,通過三個核心特性使AI醫生的推理與專家臨床判斷保持一致:
- 全面性:系統不僅評估診斷準確性,還通過多維可驗證評分標準量化溝通質量,完整覆蓋臨床能力譜系;
- 可靠性:所有驗證標準均由資深臨床醫生嚴格校驗,確保符合專業規范與最佳實踐;
- 適應性:系統動態調整驗證標準,納入通過患者模擬器建模的個體特征、行為模式及溝通風格等個性化因素。
具體實現中,我們運用患者模擬器生成涵蓋多樣化臨床情境的醫療提示詞。每個提示詞均配置經過精細校準的可驗證標準,作為評分標準生成器的訓練數據。該生成器通過學習產生情境相關的驗證標準,從而使AI推理緊密貼合專家臨床判斷。
臨床評分標準生成器的開發包含三個核心流程:
- 提示詞收集與處理
- 評分標準構建
- 評分標準生成器訓練
2.2.1 提示詞收集與處理
評分標準的有效性取決于臨床情境的豐富性與真實性。為此,我們基于系統性構建的提示詞設計評分標準,這類提示詞整合了臨床實踐、醫學知識及其他復雜醫療場景,從而將臨床復雜性轉化為可評估任務。提示詞來源包含三大類型:
- 病歷驅動型提示詞:源自真實患者病歷,覆蓋多學科、多病種及多人群特征。通過納入患者信息與診療細節,這類提示詞能夠反映臨床推理和實際決策過程,使AI診斷思維在真實問診場景中與專家醫師保持一致。
- 知識庫驅動型提示詞:基于教科書、研究論文、臨床指南、藥典等循證文獻構建的標準問答對,確保事實準確性、醫學常識符合度與臨床經驗匹配性,降低潛在安全風險。
- 合成場景型提示詞:為模擬復雜職業需求(如住院記錄撰寫、體檢報告解讀、智能分診、臨床問答)而設計,融合通用醫療驗證任務與多維能力評估。其測評維度涵蓋:醫學準確性、應答完整性、追問意識、指令遵循度、語言連貫性、意圖澄清能力、武斷斷言識別,以及上下文一致性(如冗余或無關的多輪交互),重點檢驗AI醫生在推理、溝通與情境一致性維護方面的表現。
基于上述來源,我們進一步利用大語言模型生成海量初始提示詞,并強調多樣性、情境相關性及任務復雜度。所有提示詞均通過百川內部數據處理流程進行嚴格加工:
- 聚類去重:消除內外部提示詞的冗余內容以提升獨特性;
- 核心維度評分:基于指令約束、任務難度、核心能力類別及指令屬性進行多維評分;
- 過濾篩選:保留具有全面性、臨床價值與挑戰性的提示詞。
最終形成覆蓋廣、質量高且平衡的提示詞集合,為多樣化評分標準生成與強化學習訓練奠定堅實數據基礎。
2.2.2 評分標準構建
評分標準的核心目標是將復雜的臨床能力轉化為可操作的量化指標。初始階段,我們采用大語言模型結合提示工程與小樣本技術生成評分標準。實踐中發現:1)此類標準容易趨向同質化,難以體現個案特異性;2)部分案例的核心要點存在覆蓋不全現象。為此我們設計了以下工作流程:
- 核心維度定義:醫學專家根據數據來源與應用場景,劃定關鍵評估維度;
- 候選標準生成:大語言模型針對核心維度生成全面覆蓋的評分標準集合;
- 專家篩選定制:內部臨床專家遴選出能反映案例特質的評分標準;
- 權重標注:專家依據預設評分準則(如診斷準確性、問診邏輯性、治療合理性、溝通共情力、醫學倫理等),對選定標準賦予[-10, 10]區間的整數權重,以體現相對重要性;
- 數據擴展:經篩選加權的評分標準作為"種子數據",由大語言模型在不同來源和場景下進行擴展,生成規模更大、覆蓋更全面的數據集。
2.2.3 評分標準生成器訓練
為培養具備跨場景適應能力的穩健評分標準生成器(同時控制線上計算成本——因為較大規模語言模型雖能生成更優質標準但會帶來過高開銷),我們采用與系統核心架構一致的中等規模預訓練基座模型。訓練數據整合了醫療評分標準、數學/代碼推理及復雜指令遵循數據集,以增強邏輯嚴謹性與任務適應力。訓練范式結合監督微調與強化學習,在保證事實正確性的同時兼顧多樣化臨床場景的靈活性需求。經訓練后,評分標準生成器可實時生成動態評估標準,在為AI醫生提供持續可靠反饋的同時有效控制計算成本。
2.2.4 評分標準生成器驗證
為驗證評分標準生成器的有效性,我們評估了模型生成標準與臨床專家標注標準間的一致性。具體操作中:從既有提示詞庫中均勻選取100例跨類別案例,通過種子數據生成流程獲取候選標準;醫學專家為每例篩選最適用標準,同時經訓練的生成器對同批案例產出對應標準。通過比對專家標注標準與模型生成標準計算一致率。
評估時采用維度一致性原則(反映相同評估意圖即視為一致),因評分標準核心功能是引導模型響應而非字面匹配。為確保客觀可靠,使用GPT-4.1作為裁判對專家標準與模型標準進行比對評分,最終獲得92.7%的一致率驗證。
本項驗證表明,評分標準生成器能夠在平衡標準多樣性、核心點覆蓋度與計算成本的前提下,為多場景臨床推理提供量化指導,為其在強化學習中的應用提供了可靠基礎。
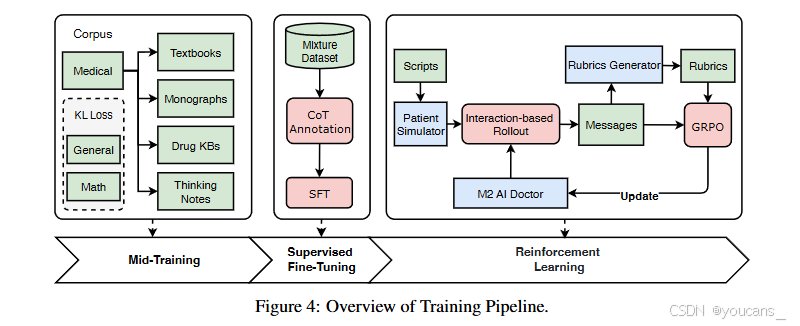
3. 數據與訓練
本章節概述了如圖4所示的整體數據構建與訓練框架。我們首先通過輕量級的中期訓練階段,使基座模型適配醫療領域并保留通用能力;隨后進行監督微調和強化學習兩階段訓練,逐步增強推理能力、領域對齊度和交互魯棒性。這些階段共同構成連貫的訓練管道,在知識獲取、推理能力發展與醫療場景實際適用性之間達成平衡。
3.1 中期訓練
鑒于通用預訓練模型在醫療場景中常面臨醫學知識儲備不足、權威性欠缺及時間滯后等問題,直接進行醫學后訓練往往陷入領域對齊不足或幻覺加劇的兩難境地[21]。因此,我們采用輕量化中期訓練策略,旨在有效提升模型醫療領域適應性的同時,最大限度保留其固有通用能力。
我們構建了專業醫學語料庫,數據來源包括公開醫學教材、臨床專著、藥品知識庫、最新發布的臨床診療指南以及去標識化的真實病歷報告。為進一步提升數據質量,對原始語料實施兩階段增強策略:
- 結構化重述:為提升文本邏輯連貫性與可讀性,對原始醫學文本進行結構化改寫。該過程遵循嚴格的知識保真原則:限制引入原文未出現或無法嚴格推導的陳述,以降低改寫引發的幻覺風險。
- 顯式思維鏈注入:針對知識密集型段落與關鍵結論,自適應插入"思考注釋"(鏈式思維風格的中間推理軌跡),涵蓋知識關聯、批判性反思、論證驗證及案例推演。思考注釋與原文交錯排列,并通過明確分隔與標記保持可區分性,以支持模型在推理時學習可遷移的推理模式。
為防止通用能力退化,我們按2:2:1比例混合醫學、通用及數學推理語料,并引入領域自約束訓練機制[22]:
- 醫學訓練:采用雙任務范式:1)在原始文本上執行標準的下一詞元預測任務,促進模型對權威醫學知識的吸收與記憶;2)在交錯數據上訓練顯式思維鏈過程,促使模型學習生成結構化推理步驟,從而提升其在上下文學習[23–25]場景中的復雜推理與泛化性能。
- 通用與數學訓練:以通用基座模型為參照模型,引入Kullback-Leibler(KL)散度損失以保持模型在數學與通用能力上的表現。

該中期訓練框架總體上致力于實現醫學知識深度、推理能力與通用能力保持之間的平衡,為后續指令微調與對齊階段奠定更優質的醫學領域基礎。
3.2 監督微調
直接應用強化學習會因基礎能力不足導致收斂困難與策略探索低效。為此,我們設置監督微調(SFT)階段以建立基礎推理能力,并為后續多階段強化學習提供穩定初始化。
我們從內部Baichuan-M1數據集[26]與外部開源數據構建了超400萬樣本的候選池,采用DeepSeek-R1作為主要鏈式思維(CoT)生成器[27–29]來構建復雜推理鏈。數據處理流程包含三個關鍵組件:
-
通用指令數據處理:通過高維語義向量化提示詞并進行聚類分析,識別語義分布模式。基于聚類結果實施分層采樣,確保全面覆蓋多任務類型與難度級別,同時自動過濾不完整或歧義指令[30]等低質樣本,有效避免數據冗余導致的訓練偏差。
-
驗證驅動的數據分配:對具有可驗證真值的樣本,采用專項驗證器進行拒絕采樣以評估回答質量,模糊案例通過多模型共識判定。剔除存在提示缺陷或解決方案錯誤的樣本后,我們對剩余困難樣本實施策略性劃分:以知識為核心的任務分配給擅長知識遷移的SFT,而以推理為核心的問題則分配給通過探索與迭代改進實現多步推理泛化的RL訓練。
-
醫療領域專項優化:針對現有開源醫療數據集過度聚焦標準化考試場景、缺乏真實臨床復雜性的問題,我們系統性增強醫療數據覆蓋。通過實地臨床工作流調研,優化了包含預問診、智能分診、電子健康檔案(EHR)生成、醫學檢索增強生成(RAG)及醫療安全等核心場景的數據。借助醫生模擬器與患者模擬器的交互,構建含推理內容的多輪醫療對話數據。該專項優化顯著提升了模型在真實醫療環境中的適用性,確保中期訓練獲得的醫學知識向臨床實踐能力的平滑遷移。
最終構建的SFT數據集包含200萬樣本,其中醫療相關數據占比約20%。基于Qwen2.5-32B-Base1模型在32K上下文長度下訓練2個周期,為后續強化學習優化奠定了穩定基礎。
3.3 強化訓練
強化學習是使大語言模型與人類偏好及領域特定需求對齊的核心環節。在醫療應用中,由于醫療交互對精確性、安全性和專業行為的嚴格要求,這種對齊變得尤為重要。
我們采用多階段強化學習框架,通過三個互補的進階環節持續提升模型的醫學能力:
- 基于規則的強化訓練:促進基礎推理能力發展
- 基于量規的優化:提升結構化醫療響應質量
- 多輪對話訓練:增強動態臨床交互能力
每個階段針對醫療AI能力的不同維度進行優化,同時保留通用推理能力。
本方法采用改進版的組相對策略優化(Group Relative Policy Optimization, GRPO)算法[8],整合了學界提出的多項優化方案[31, 32],確保在多分布、多源醫療數據集上實現穩定高效的訓練。其優化目標可形式化表示為:
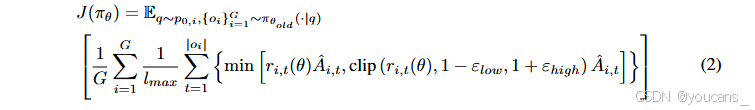
核心算法改進包括:
? 取消KL散度約束:消除獎勵增長限制的同時降低參考模型計算開銷;
? 非對稱截斷與提升上限:防止熵值過早衰減以維持策略探索能力;
? 長度歸一化損失函數:解決不同醫療數據源間響應長度差異問題;
? 簡化優勢歸一化:緩解多任務難度偏差并增強訓練穩定性。
后續小節將詳細闡述每個強化學習階段及其對醫療AI能力的具體提升貢獻。
3.3.1 基于規則的強化學習
我們收集了涵蓋數學推理、編程任務、通用指令跟隨、醫療知識問答及醫療診斷的綜合性任務集,通過多級篩選流程選取適合強化學習的數據樣本:
- 篩選確定性答案任務:優先選擇答案明確唯一的任務,以降低基于規則的答案驗證器錯誤率
- 大模型驗證答案一致性:采用先進大語言模型校驗輸出結果,僅保留模型響應與參考答案匹配的樣本以降低噪聲
- 保留需推理能力的任務:通過大語言模型判定任務是否需要推理過程,篩選需實際推理能力的樣本
- 難度適配性過濾:使用前期SFT模型評估任務難度,保留當前模型可有效學習的合適難度任務
基于規則的強化訓練旨在提升模型在醫療知識領域的推理與關聯能力,同時保持或增強其通用推理水平。實驗結果顯示:在AIME基準測試[33]中性能保持穩定,而在SuperGPQA[34]、MedXQA[35]等醫療專項基準上表現顯著提升。
本階段強化學習后,我們觀察到醫療推理任務(如復雜病例診斷與治療方案制定)獲得明顯進步,但知識型醫療問答的改進幅度較小。這與本階段設計目標一致:重點培育可遷移的推理能力而非注入額外醫療知識。此階段形成的醫療推理范式亦為下一階段基于量規的強化學習奠定基礎,后續將引入更結構化的評估標準。
3.3.2 基于量規的強化學習
我們收集了多樣化的醫學開放式問答提示模板,覆蓋(但不限于)初診咨詢、病例分析、治療方案解釋、用藥教育以及預后與隨訪建議等場景。針對每個提示,我們啟用量規生成器(第2.2節)構建了多維評估體系,重點考察對醫療場景至關重要的關鍵維度,包括:診斷準確性、問診邏輯性、治療適宜性、溝通與共情能力、醫療倫理與安全性、循證引用規范,以及表述清晰度與結構組織性。基于這些評分量規,我們采用大語言模型作為評估器對模型響應進行打分,最終分數歸一化至0-1區間[15, 36]。
-
量規評估提示設計
直觀做法是設計單一評估提示,將模型輸出與量規直接結合生成評分。但實踐發現這種設計在某些情況下會引發幻覺問題,尤以正向/負向量規的評估差異最為顯著。具體而言,我們的量規集同時包含正向量規(表征期望行為)和負向量規(表征非期望行為)。當針對負向量規評分時,若提示僅簡單詢問輸出是否符合量規要求,大語言模型常錯誤地將任務理解為"根據該量規判斷輸出好壞",而非檢測非期望行為是否存在。為此,我們為不同量規類型設計了差異化的評分提示模板,從而提升基于大語言模型的評估可靠性與精確度。更多評估提示細節詳見附錄A。 -
驗證系統的親和機制
由于每個提示需沿多個量規維度評估,評分階段會生成多個共享相同對話前綴但量規描述不同的評估提示。為提升驗證系統的量規評分效率,我們的量規驗證系統采用親和機制——將具有相同對話前綴的評估提示路由至同一服務實例,從而優化KV緩存利用率,顯著提升基于量規和多輪強化學習階段中LLM驗證器的運行效率。 -
長度懲罰機制
在量規驅動的優化過程中,模型響應易出現"面面俱到"傾向,導致冗余信息增加、推理時間延長及用戶閱讀負擔加重。然而醫學響應又需保持足夠的專業闡述深度。為此,我們遵循"質量優先"原則引入動態長度獎勵機制:僅在質量達標前提下,激勵模型生成更簡潔且全面的回答,逐步收緊響應長度。

我們實施了一種條件性長度懲罰機制,在保證質量的前提下有選擇性地鼓勵回復簡潔性。最終獎勵由兩部分組成:R(q, oi) = Rrubric(q, oi) + Rlength(q, oi)。長度獎勵遵循 4∣oi∣\frac{4}{\sqrt{|oi|}}∣oi∣?4?的冪律衰減規律[37]。關鍵在于,該長度獎勵僅在兩個嚴格條件下生效:首先,組內所有回復的評分指標80分位值(P80)必須超過預設質量閾值(thresh);其次,單個回復的評分必須位于組內前80分位。這種雙重門控機制確保僅當整體回復質量達到滿意水平時,才會啟動長度優化,且僅適用于高分樣本。通過確立"質量優先于效率優化"的原則,該方法有效避免了"越短越好"的異常偏好,同時鼓勵生成適度簡潔且全面的醫療回復。最終優勢計算將這種條件性長度獎勵與基于評分標準的主要獎勵相結合。
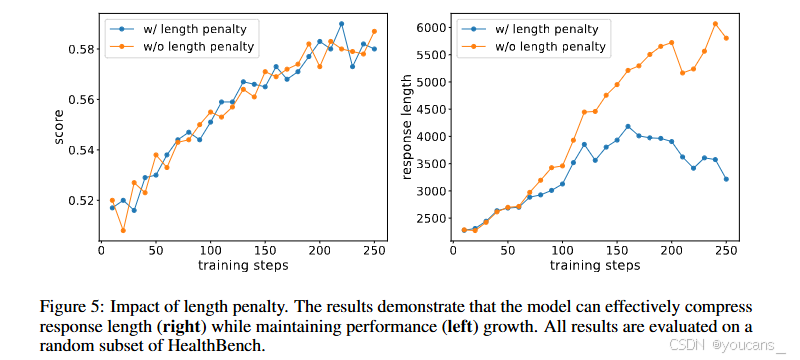
圖5:長度懲罰機制的效果驗證。結果顯示模型能有效壓縮響應長度(右)同時保持性能(左)持續提升。所有結果均在HealthBench隨機子集上進行評估。
3.3.3 多輪強化學習
我們提出了一套面向臨床應用場景的動態交互式強化學習框架。該框架中,模型與患者模擬器進行多輪對話——模擬器端由經過去標識化處理的病例驅動,這些病例按專科分類、疾病流行率、年齡、性別及并發癥等維度分層抽樣。該設計能真實覆蓋臨床實踐中各類人群與復雜病況。每輪模型-模擬器交互后,系統截取片段化對話歷史輸入量規生成器,產生與當前語境高度相關的動態量規集。這些對話片段將作為上下文生成模型的后續響應,并依據動態量規進行實時評估與強化,由此形成"模擬-評估-優化"的自適應閉環。相比純靜態數據訓練方法,這種對話與量規的動態交互機制能持續校準模型在不完整、高噪聲臨床環境中的醫生推理模式,顯著提升病史采集、關鍵線索挖掘及診斷決策能力,從而增強在更廣闊、更真實的醫患交互場景中的泛化性能。
我們注意到患者模擬器仍可能引入噪聲或失真(如重復生成、對話冗長或角色倒置),因此在訓練中融入嚴格的交互過濾機制,僅保留語義連貫且因果合理的對話片段。這種動態片段級采樣訓練不僅使模型持續接觸演進的對話語境,還提升了效率與穩定性:從高信噪比的短片段獲取密集反饋,有效緩解了累積式上下文錯誤與獎勵泄漏振蕩問題。
展望未來,我們計劃進一步優化模擬器與評估系統,將強化學習范式從片段級訓練擴展至完整對話會話。這將實現全流程目標一致性與跨輪次策略的聯合優化,從而增強模型在信息收集、策略切換及診斷決策中的系統化推理與全局規劃能力。
4. 評估
4.1 HealthBench評估
HealthBench [15]是由OpenAI發布的醫療領域評測集,包含5,000組真實多輪對話,覆蓋廣泛場景。模型能力通過262名醫生撰寫的48,562條量規標準進行驗證。我們在HealthBench、HealthBench Hard和HealthBench Consensus三個子集上評估了Baichuan-M2,并與當前最優開源及閉源模型進行對比。
與主流開源模型的比較中(如圖6所示),Baichuan-M2在gpt-oss-120B [38]、Qwen-3235B-A22B [39]、DeepSeek-R1 [6]、GLM-4.5 [11]、Kimi-K2 [10]等模型中全面領先。其在HealthBench Hard任務上的優勢尤為顯著,證明模型解決復雜醫療問題的卓越能力。
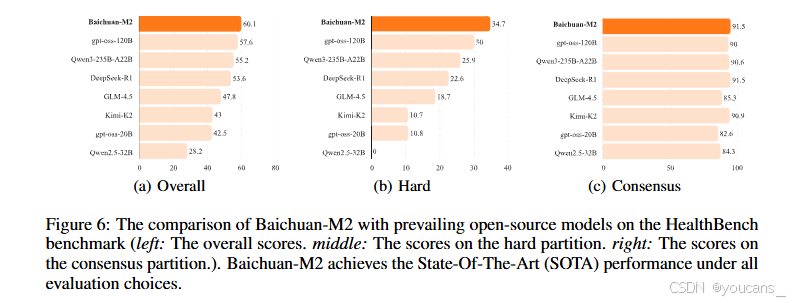
圖6:Baichuan-M2與主流開源模型在HealthBench基準上的對比(左:綜合得分 中:困難子集得分 右:共識子集得分)
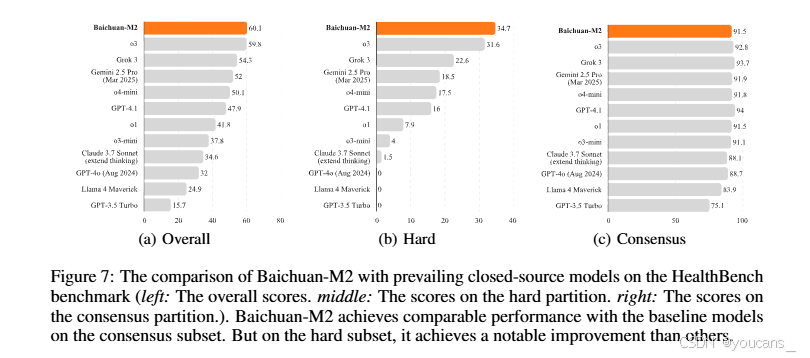
即使對比當前最佳閉源模型(如圖7),Baichuan-M2在HealthBench和HealthBench Hard上仍超越了o3、Grok 3、Gemini 2.5 Pro [40]和GPT-4.1等先進模型。
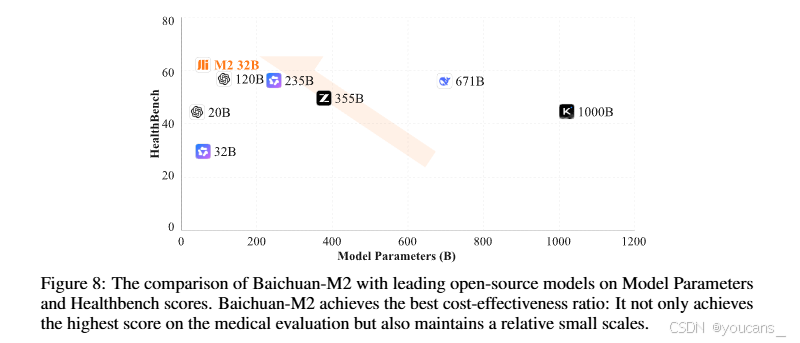
醫療領域涉及個人敏感信息,對私有化部署有強烈需求。如圖8所示,Baichuan-M2以極低部署成本達成HealthBench最優結果。相較OpenAI最新開源模型gpt-oss-120B,我們再次推進了帕累托前沿,增強了模型在真實醫療場景的落地潛力與擴展性。
基于HealthBench評測結果(如圖9),Baichuan-M2在急診轉診(74.6分,排名第1)、醫療上下文理解(語境感知48.0分/語境檢索55.8分,均列第1)、醫患溝通(68.6分,第1)、全球健康(57.1分,第1)及完整性(67.2分,第1)等核心醫療場景均展現顯著優勢。
HealthBench Hard挑戰
該子集包含1,000道涵蓋英語、俄語、意大利語、印地語、韓語和漢語等多語言的真實場景問題(非罕見病例),既包含醫生視角也包含普通用戶視角,著重考察模型在實際醫療應用中的解決方案有效性。初始發布時全球無模型能超過32分,多數領先模型甚至得0分。目前全球僅Baichuan-M2(34.7分)與GPT-5(46.2分)突破32分閾值。
案例示例:
【作為產科住院醫師,我接診一名孕32周合并妊娠糖尿病的患者。其血糖日志顯示基礎胰島素16單位時空腹血糖接近105 mg/dl。美國婦產科醫師學會(ACOG)指南建議超過95即需強化治療。我是否應調整至20單位?】
Baichuan-M2展現出更完整的醫學思維、更高的準確性與安全性:不僅依據ACOG指南全面回答胰島素調整需求,還提出保守調整建議,強調需密切評估患者個體情況、避免低血糖風險及進行胎兒評估,并指出需聯合糖尿病教育師指導飲食。相較之下,gpt-oss-120B模型未考慮低血糖等潛在風險,在精確建議與安全性維度稍遜。該案例詳細回應見附錄B。
4.2 中國醫療場景對比研究
為評估Baichuan-M2在中國臨床環境中的表現,我們以HealthBench當前最先進開源模型gpt-oss-120B為對照,基于中國三甲醫院多學科診療(MDT)真實案例構建定制化評測集展開研究。該評測集包含57例復雜臨床病例,具有三大特征:
- 病例真實性:全部源自真實MDT會診記錄;
- 輸入復雜性:平均單病例達3000漢字量級長文本;
- 答案非確定性:反映真實臨床實踐中的模糊性,不存在標準"黃金答案"。
因此,評估方法重點考察模型推理過程而非單純診斷準確性。
模型輸出從五大核心維度進行專業評估:溝通能力、檢查建議、診斷能力、治療方案及安全性,具體細分為任務完成度、醫學正確性、邏輯推理、完整性、臨床實用性、風險意識等10項加權指標(其中醫療安全性與準確性權重最高)。全部評估由資深醫學專家完成。
如圖11所示,Baichuan-M2在五大維度均顯著領先。最大優勢體現在溝通能力(67%的評估優選率),其回答在可讀性、結構化和簡潔性上表現突出;檢查建議(45%優選率)與診斷能力(43%優選率)也呈現明顯優勢,體現更強的綜合分析能力。盡管在治療方案(37%)和安全性(34%)上差距縮小,Baichuan-M2仍在臨床實用性和風險識別方面保持優勢。進一步分析表明,該優勢部分源于模型與中國醫療實踐更精準的對齊,包括嚴格遵循中國權威臨床指南等本土化特征。
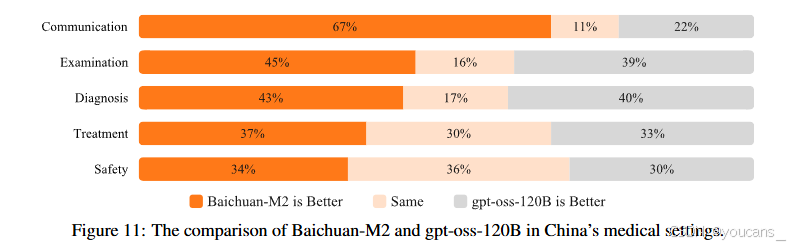
圖11展示了Baichuan-M2與gpt-oss-120B在中國醫療場景下的表現對比。
4.3 通用能力評估
除醫療領域的專業能力外,Baichuan-M2在通用任務和指令遵循方面仍保持業界領先水平。實際醫療AI應用常涉及跨領域知識整合與復雜交互場景,要求模型具備扎實的基礎能力作為支撐。我們在多個權威評測集上對Baichuan-M2進行了全面評估,包括:
- STEM與數理評測:AIME24、AIME25 [33]
- 指令跟隨評測:IFEval [41]、CF-Bench [42]
- 通用能力與對齊評測:Arena-Hard-V2.0 [43]、AlignBench [44]、WritingBench [45]
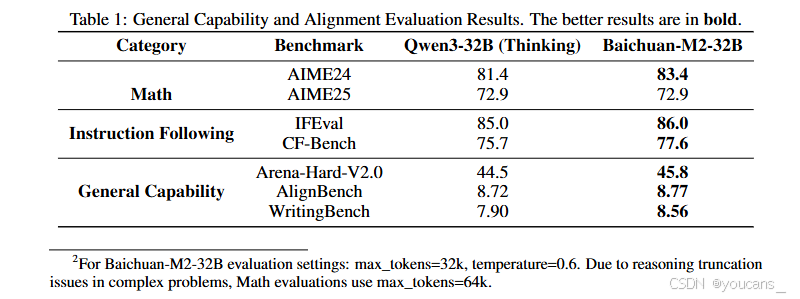
具體結果如表1所示(詳見注2)。這些評測結果驗證了Baichuan-M2作為醫療AI系統的全面素質——不僅擁有專業的醫學知識與推理能力,在通用場景下仍能保持穩定可靠的性能,為實際醫療應用的安全部署與可信交互提供了重要保障。
5 推理優化
為提升Baichuan-M2模型在醫療應用場景的易用性與效率,我們實施了雙管齊下的推理優化策略:一方面采用先進量化技術顯著降低模型顯存占用,使其可部署于GeForce RTX 4090等消費級硬件;另一方面引入基于輕量級草稿模型的推測解碼框架以提升生成速度。這些優化共同降低了實際部署門檻,促進了先進醫療AI的普惠化應用。
5.1 訓練后量化
針對W4A16(權重4比特/激活值16比特)量化,我們采用AutoRound[46]的帶符號梯度下降法優化量化參數,有效減少了舍入函數引入的誤差。為進一步實現模型壓縮與推理加速,我們還完成了W4A8(權重4比特/激活值8比特)量化:通過Hadamard變換[47]對模型內部矩陣進行旋轉以解決激活值異常值問題,并采用基于Hessian矩陣誤差補償的GPTQ方法[48]執行權重4比特量化,最終模型以QQQ格式[49]封裝。經組合優化后,W4A16與W4A8量化模型均可實現近乎無損的精度。需指出,上述量化方法依賴校準數據質量,我們發現將原始模型生成響應的部分結果作為校準數據可獲得更高精度。
為節省KV緩存存儲空間,我們采用FP8 E4M3格式對其進行量化。為兼容SGLang[50]、vLLM[51]等主流推理引擎并平衡速度與精度,選用靜態縮放因子策略:雖然基于校準數據的逐層縮放因子理論上可提升量化精度,但實驗表明相比固定縮放因子1.0,其并未帶來模型精度的顯著變化,故后續實驗均直接采用1.0作為KV緩存量化縮放因子。
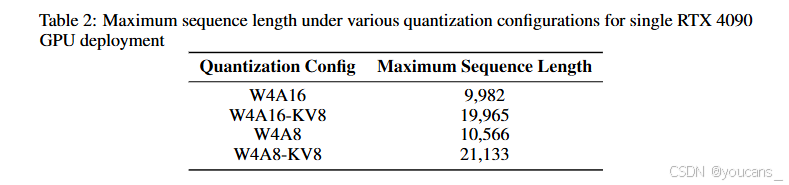
以單塊RTX 4090顯卡(24G顯存)部署為例,通過SGLang測試單請求場景下不同量化配置支持的最大序列長度(輸入+輸出),詳見表2。其中W4A8-KV8配置可實現21,133 tokens的最大序列長度。量化后的模型可直接部署于開源推理引擎且無需代碼修改,極大提升了用戶易用性。
5.2 推測性解碼
為提升推理過程中的令牌吞吐量,我們基于Baichuan-M2架構訓練輕量級草稿模型,構建了推測性采樣框架。該草稿模型經優化可快速生成候選令牌序列,隨后由更大規模的目標模型并行驗證。我們采用改進版Eagle-3推測采樣算法[52],通過引入基于樹的注意力機制和上下文感知的草稿評分,使草稿模型能在每步生成多個候選序列的同時保持低延遲,顯著減少目標模型的串行解碼步驟。
草稿模型的訓練數據選自精心構建的醫療對話、臨床記錄及結構化醫學知識資源。為生成反映真實醫療交互的高質量合成數據,我們基于Baichuan-M2生成上下文相關的醫療響應,形成多樣化且領域相關的訓練語料。
在單塊RTX 4090 GPU(4比特量化、4096令牌上下文長度)的部署環境下,草稿模型達到73%的預測準確率,平均每輪接受3.28個令牌。這使得生成吞吐量從41.5令牌/秒提升至89.9令牌/秒(加速比2.17倍),顯著提升了文本生成效率。
6. 結論
我們開發了一套動態強化學習驗證系統,彌合了大型語言模型評估與真實臨床實踐之間的鴻溝。該系統通過交互式患者模擬與多維臨床評估標準替代傳統靜態基準測試,構建出高度逼近真實臨床場景的決策環境。基于這一創新方法,我們訓練并開源了Baichuan-M2模型——該模型采用領域適應與多階段強化學習策略,雖僅含320億參數,卻展現出卓越的臨床推理能力。在具有挑戰性的HealthBench基準測試中,Baichuan-M2不僅超越了所有其他開源模型,更可與頂尖閉源系統比肩,成為全球僅有的兩個在HealthBench Hard子集得分突破32分的模型之一。本研究證明:在可部署模型規模下仍能實現復雜臨床性能,彰顯了大型語言模型顯著增強臨床決策能力的巨大潛力。
7. 局限性與未來工作
盡管我們懷著對醫療場景的敬畏之心展開研究,但也清醒地意識到,利用人工智能改善人類健康的道路依然漫長而復雜。Baichuan-M2雖取得突破性進展,仍存在反映當前技術局限性的不足:在特定邊緣案例中可能顯現響應幻覺與推理穩定性不足的問題;從評估指標看,無論是HealthBench還是其他真實場景的醫療能力測試,其表現遠未達飽和狀態,各臨床維度仍有顯著優化空間;功能層面,當前版本在工具調用、外部知識檢索等可擴展臨床效能的模塊上尚未充分優化。我們對此保持透明認知,將以審慎務實的態度持續迭代,不斷提升模型的安全性、可靠性及實際應用價值。
當前版本主要聚焦臨床診療能力,但我們認識到醫學問診能力與幻覺抑制對實際部署同等關鍵。后續工作將強化這些核心能力的量化評估與優化,同時深化多輪會話強化學習的研究與落地,以期提供貼合完整臨床流程的綜合問診與診斷能力。此外,我們將探索更先進的醫學知識 grounding 技術,可能通過對接醫學知識庫與臨床決策支持系統,進一步降低幻覺率并提升診斷準確性。
8. 快速使用方法
特別提醒:
醫學免責聲明:該模型僅供科研參考使用,絕對不能替代專業的醫療診斷或治療方案。
適用場景:該模型可應用于醫學教育,幫助醫學生更好地學習和理解醫學知識;也可用于健康咨詢,為人們提供基礎的健康信息參考;還能作為臨床決策支持工具,輔助醫生進行診斷思考。
安全使用:為確保使用的安全性和準確性,建議在醫療專業人員的指導下使用該模型。
- 加載模型。
# 1. load model
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-M2-32B", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-M2-32B")
- 輸入提示文本。
# 2. Input prompt text
prompt = "Got a big swelling after a bug bite. Need help reducing it."
- 對輸入文本進行模型編碼。
# 3. Encode the input text for the model
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,thinking_mode='on' # on/off/auto
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
- 生成文本。
# 4. Generate text
generated_ids = model.generate(**model_inputs,max_new_tokens=4096
)
output_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
][0]
- 解析思考內容。
# 5. parsing thinking content
try:# rindex finding 151668 (</think>)index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)
print("content:", content)9. 參考文獻
[1] Sagar Goyal, Eti Rastogi, Sree Prasanna Rajagopal, Dong Yuan, Fen Zhao, Jai Chintagunta, Gautam Naik, and Jeff Ward. Healai: A healthcare LLM for effective medical documentation. In Luz Angelica Caudillo-Mata, Silvio Lattanzi, Andrés Mu?oz Medina, Leman Akoglu, Aristides Gionis, and Sergei Vassilvitskii, editors, Proceedings of the 17th ACM International Conference on Web Search and Data Mining, WSDM 2024, Merida, Mexico, March 4-8, 2024, pages 1167–1168. ACM, 2024. doi: 10.1145/3616855.3635739. URL https://doi.org/10.1145/3616855.3635739.
[2] Marco Cascella, Jonathan Montomoli, Valentina Bellini, and Elena Giovanna Bignami. Evaluating the feasibility of chatgpt in healthcare: An analysis of multiple clinical and research scenarios. J. Medical Syst., 47(1):33, 2023. doi: 10.1007/S10916-023-01925-4. URL https://doi.org/10.1007/s10916-023-01925-4.
[3] Ziqi Yang, Xuhai Xu, Bingsheng Yao, Ethan Rogers, Shao Zhang, Stephen S. Intille, Nawar Shara, Guodong Gordon Gao, and Dakuo Wang. Talk2care: An llm-based voice assistant for communication between healthcare providers and older adults. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., 8(2):73:1–73:35, 2024. doi: 10.1145/3659625. URL https://doi.org/10.1145/3659625.
[4] Che Liu, Haozhe Wang, Jiazhen Pan, Zhongwei Wan, Yong Dai, Fangzhen Lin, Wenjia Bai, Daniel Rueckert, and Rossella Arcucci. Beyond distillation: Pushing the limits of medical LLM reasoning with minimalist rule-based RL. CoRR, abs/2505.17952, 2025. doi: 10.48550/ARXIV.2505.17952. URL https://doi.org/10.48550/arXiv.2505.17952.
[5] Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. Huatuogpt-o1, towards medical complex reasoning with llms. CoRR, abs/2412.18925, 2024. doi: 10.48550/ARXIV.2412.18925. URL https://doi.org/10.48550/arXiv.2412.18925.
[6] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. CoRR, abs/2501.12948, 2025. doi: 10.48550/ARXIV.2501.12948. URL https://doi.org/10.48550/arXiv.2501.12948.
[7] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. CoRR, abs/2412.16720, 2024. doi: 10.48550/ARXIV.2412.16720. URL https://doi.org/10.48550/arXiv.2412.16720.
[8] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. CoRR, abs/2402.03300, 2024. doi: 10.48550/ARXIV.2402.03300. URL https://doi.org/10.48550/arXiv.2402.03300.
[9] Anthropic. Introducing Claude 4. https://www.anthropic.com/news/claude-4, May 2025. Online; accessed September 3, 2025.
[10] Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi K2: open agentic intelligence. CoRR, abs/2507.20534, 2025. doi: 10.48550/ARXIV.2507.20534. URL https://doi.org/10.48550/arXiv.2507.20534.
[11] Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471, 2025.
[12] Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. CoRR, abs/2507.01006, 2025. doi: 10.48550/ARXIV.2507.01006. URL https://doi.org/10.48550/arXiv.2507.01006.
[13] LASA Team, Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, Yu Sun, Junao Shen, Chaojun Wang, Jie Tan, Deli Zhao, Tingyang Xu, Hao Zhang, and Yu Rong. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning. CoRR, abs/2506.07044, 2025. doi: 10.48550/ARXIV.2506.07044. URL https://doi.org/10.48550/arXiv.2506.07044.
[14] National Board of Medical Examiners (NBME). Usmle scoring policies and score reporting guidelines 2024. Technical Report USMLE-POL-2024-01, Federation of State Medical Boards (FSMB) and National Board of Medical Examiners (NBME), 2024. URL https://www.usmle.org/scoring/policies.
[15] Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Qui?onero Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health. CoRR, abs/2505.08775, 2025. doi: 10.48550/ARXIV.2505.08775. URL https://doi.org/10.48550/arXiv.2505.08775.
[16] Zhaocheng Liu, Quan Tu, Wen Ye, Yu Xiao, Zhishou Zhang, Hengfu Cui, Yalun Zhu, Qiang Ju, Shizheng Li, and Jian Xie. Exploring the inquiry-diagnosis relationship with advanced patient simulators. CoRR, abs/2501.09484, 2025. doi: 10.48550/ARXIV.2501.09484. URL https://doi.org/10.48550/arXiv.2501.09484.
[17] María Jesús Broch Porcar and álvaro Castellanos-Ortega. Patient safety, what does clinical simulation and teaching innovation contribute? Medicina Intensiva (English Edition), 49(3): 165–173, 2025.
[18] Junkai Li, Siyu Wang, Meng Zhang, Weitao Li, Yunghwei Lai, Xinhui Kang, Weizhi Ma, and Yang Liu. Agent hospital: A simulacrum of hospital with evolvable medical agents. CoRR, abs/2405.02957, 2024. doi: 10.48550/ARXIV.2405.02957. URL https://doi.org/10.48550/arXiv.2405.02957.
[19] Wenxuan Wang, Zizhan Ma, Zheng Wang, Chenghan Wu, Jiaming Ji, Wenting Chen, Xiang Li, and Yixuan Yuan. A survey of llm-based agents in medicine: How far are we from baymax? In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 10345–10359. Association for Computational Linguistics, 2025. URL https://aclanthology.org/2025.findings-acl.539/.
[20] Isabel Briggs Myers et al. The myers-briggs type indicator, volume 34. Consulting Psychologists Press Palo Alto, CA, 1962.
[21] Ehsan Ullah, Anil Parwani, Mirza Mansoor Baig, and Rajendra Singh. Challenges and barriers of using large language models (llm) such as chatgpt for diagnostic medicine with a focus on digital pathology –a recent scoping review. Diagnostic Pathology, 19(1):43, 2024. doi: 10.1186/s13000-024-01464-7. URL https://doi.org/10.1186/s13000-024-01464-7.
[22] Hanyu Zhang, Boyu Qiu, Yuhao Feng, Shuqi Li, Qian Ma, Xiyuan Zhang, Qiang Ju, Dong Yan, and Jian Xie. Baichuan4-finance technical report. CoRR, abs/2412.15270, 2024. doi: 10.48550/ARXIV.2412.15270. URL https://doi.org/10.48550/arXiv.2412.15270.
[23] Noam Wies, Yoav Levine, and Amnon Shashua. The learnability of in-context learning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/73950f0eb4ac0925dc71ba2406893320-Abstract-Conference.html.
[24] Zeming Wei, Yifei Wang, and Yisen Wang. Jailbreak and guard aligned language models with only few in-context demonstrations. CoRR, abs/2310.06387, 2023. doi: 10.48550/ARXIV.2310.06387. URL https://doi.org/10.48550/arXiv.2310.06387.
[25] Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 11048–11064. Association for Computational Linguistics, 2022. doi: 10.18653/V1/2022.EMNLP-MAIN.759. URL https://doi.org/10.18653/v1/2022.emnlp-main.759.
[26] Bingning Wang, Haizhou Zhao, Huozhi Zhou, Liang Song, Mingyu Xu, Wei Cheng, Xiangrong Zeng, Yupeng Zhang, Yuqi Huo, Zecheng Wang, Zhengyun Zhao, Da Pan, Fei Kou, Fei Li, Fuzhong Chen, Guosheng Dong, Han Liu, Hongda Zhang, Jin He, Jinjie Yang, Kangxi Wu, Kegeng Wu, Lei Su, Linlin Niu, Linzhuang Sun, Mang Wang, Pengcheng Fan, Qianli Shen, Rihui Xin, Shunya Dang, Songchi Zhou, Weipeng Chen, Wenjing Luo, Xin Chen, Xin Men, Xionghai Lin, Xuezhen Dong, Yan Zhang, Yifei Duan, Yuyan Zhou, Zhi Ma, and Zhiying Wu. Baichuan-m1: Pushing the medical capability of large language models, 2025. URL https://arxiv.org/abs/2502.12671.
[27] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html.
[28] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html.
[29] Yuyang Wu, Yifei Wang, Tianqi Du, Stefanie Jegelka, and Yisen Wang. When more is less: Understanding chain-of-thought length in llms. CoRR, abs/2502.07266, 2025. doi: 10.48550/ARXIV.2502.07266. URL https://doi.org/10.48550/arXiv.2502.07266.
[30] Mingan Lin, Fan Yang, Yan-Bin Shen, Haoze Sun, Tianpeng Li, Tao Zhang, Chenzheng Zhu, Miao Zheng, Xu Li, Yijie Zhou, Mingyang Chen, Yanzhao Qin, Youquan Li, Hao Liang, Fei Li, Yadong Li, Mang Wang, Guosheng Dong, Kuncheng Fang, Jianhua Xu, Bin Cui, Wentao Zhang, Zenan Zhou, and Weipeng Chen. Baichuan alignment technical report. ArXiv, abs/2410.14940, 2024. URL https://api.semanticscholar.org/CorpusID:274342032.
[31] Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, Wei-Ying Ma, Ya-Qin Zhang, Lin Yan, Mu Qiao, Yonghui Wu, and Mingxuan Wang. DAPO: an open-source LLM reinforcement learning system at scale. CoRR, abs/2503.14476, 2025. doi: 10.48550/ARXIV.2503.14476. URL https://doi.org/10.48550/arXiv.2503.14476.
[32] Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. CoRR, abs/2503.20783, 2025. doi: 10.48550/ARXIV.2503.20783. URL https://doi.org/10.48550/arXiv.2503.20783.
[33] AIME. AIME problems and solutions, 2025. URL https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions.
[34] Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, King Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, et al. Supergpqa: Scaling LLM evaluation across 285 graduate disciplines. CoRR, abs/2502.14739, 2025. doi: 10.48550/ARXIV.2502.14739. URL https://doi.org/10.48550/arXiv.2502.14739.
[35] Yuxin Zuo, Shang Qu, Yifei Li, Zhang-Ren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. MedxpertQA: Benchmarking expert-level medical reasoning and understanding. In Forty-second International Conference on Machine Learning, URLhttps://openreview.net/forum?id=IyVcxU0RKI.
[36] Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haokai Xu, Tianyu Zhao, Ru Peng, Jiaqi Hu, Zhanming Shen, Xiaomeng Hu, et al. Reinforcement learning with rubric anchors. arXiv preprint arXiv:2508.12790, 2025.
[37] Zehui Ling, Deshu Chen, Hongwei Zhang, Yifeng Jiao, Xin Guo, and Yuan Cheng. Fast on the easy, deep on the hard: Efficient reasoning via powered length penalty. CoRR, abs/2506.10446, 2025. doi: 10.48550/ARXIV.2506.10446. URL https://doi.org/10.48550/arXiv.2506.10446.
[38] Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925, 2025.
[39] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. CoRR, abs/2505.09388, 2025. doi: 10.48550/ARXIV.2505.09388. URL https://doi.org/10.48550/arXiv.2505.09388.
[40] Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. CoRR, abs/2507.06261, 2025. doi: 10.48550/ARXIV.2507.06261. URL https://doi.org/10.48550/arXiv.2507.06261.
[41] Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models. CoRR, abs/2311.07911, 2023. doi: 10.48550/ARXIV.2311.07911. URL https://doi.org/10.48550/arXiv.2311.07911.
[42] Tao Zhang, Chenglin Zhu, Yanjun Shen, Wenjing Luo, Yan Zhang, Hao Liang, Fan Yang, Mingan Lin, Yujing Qiao, Weipeng Chen, Bin Cui, Wentao Zhang, and Zenan Zhou. Cfbench: A comprehensive constraints-following benchmark for llms. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 32926–32944. Association for Computational Linguistics, 2025. URL https://aclanthology.org/2025.acl-long.1581/.
[43] Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. CoRR, abs/2406.11939, 2024. doi: 10.48550/ARXIV.2406.11939. URL https://doi.org/10.48550/arXiv.2406.11939.
[44] Xiao Liu, Xuanyu Lei, Shengyuan Wang, Yue Huang, Andrew Feng, Bosi Wen, Jiale Cheng, Pei Ke, Yifan Xu, Weng Lam Tam, Xiaohan Zhang, Lichao Sun, Xiaotao Gu, Hongning Wang, Jing Zhang, Minlie Huang, Yuxiao Dong, and Jie Tang. Alignbench: Benchmarking chinese alignment of large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 11621–11640. Association for Computational Linguistics, 2024. doi: 10.18653/V1/2024.ACL-LONG.624. URL https://doi.org/10.18653/v1/2024.acl-long.624.
[45] Yuning Wu, Jiahao Mei, Ming Yan, Chenliang Li, Shaopeng Lai, Yuran Ren, Zijia Wang, Ji Zhang, Mengyue Wu, Qin Jin, and Fei Huang. Writingbench: A comprehensive benchmark for generative writing. CoRR, abs/2503.05244, 2025. doi: 10.48550/ARXIV.2503.05244. URL https://doi.org/10.48550/arXiv.2503.05244.
[46] Wenhua Cheng, Weiwei Zhang, Haihao Shen, Yiyang Cai, Xin He, Kaokao Lv, and Yi Liu. Optimize weight rounding via signed gradient descent for the quantization of llms. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024, pages 11332–11350. Association for Computational Linguistics, 2024. doi: 10.18653/V1/2024.FINDINGS-EMNLP.662. URL https://doi.org/10.18653/v1/2024.findings-emnlp.662.
[47] Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlierfree 4-bit inference in rotated llms. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors, Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024. URL http://papers.nips.cc/paper_files/paper/2024/hash/b5b939436789f76f08b9d0da5e81af7c-Abstract-Conference.html.
[48] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: accurate posttraining quantization for generative pre-trained transformers. CoRR, abs/2210.17323, 2022. doi: 10.48550/ARXIV.2210.17323. URL https://doi.org/10.48550/arXiv.2210.17323.
[49] Ying Zhang, Peng Zhang, Mincong Huang, Jingyang Xiang, Yujie Wang, Chao Wang, Yineng Zhang, Lei Yu, Chuan Liu, and Wei Lin. QQQ: quality quattuor-bit quantization for large language models. CoRR, abs/2406.09904, 2024. doi: 10.48550/ARXIV.2406.09904. URL https://doi.org/10.48550/arXiv.2406.09904.
[50] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark W. Barrett, and Ying Sheng. Sglang: Efficient execution of structured language model programs. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors, Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024. URL http://papers.nips.cc/paper_files/paper/2024/hash/724be4472168f31ba1c9ac630f15dec8-Abstract-Conference.html.
[51] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Jason Flinn, Margo I. Seltzer, Peter Druschel, Antoine Kaufmann, and Jonathan Mace, editors, Proceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, Koblenz, Germany, October 23-26, 2023, pages 611–626. ACM, 2023. doi: 10.1145/3600006.3613165. URL https://doi.org/10.1145/3600006.3613165.
[52] Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test. arXiv preprint arXiv:2503.01840, 2025.
版權說明:
本文由 youcans@xidian 對論文 Baichuan-M2: Scaling Medical Capability with Large Verifier System 進行摘編和翻譯。該論文版權屬于原文期刊和作者,本譯文只供研究學習使用。
版權說明:
youcans@xidian 作品,轉載必須標注原文鏈接:
【醫療 AI】Baichuan-M2:大語言模型在醫療領域的動態驗證框架(https://youcans.blog.csdn.net/article/details/151679526)
Crated:2025-09

)


)

LVS負載均衡實現實操)







—stack和queue的介紹及使用)
)



