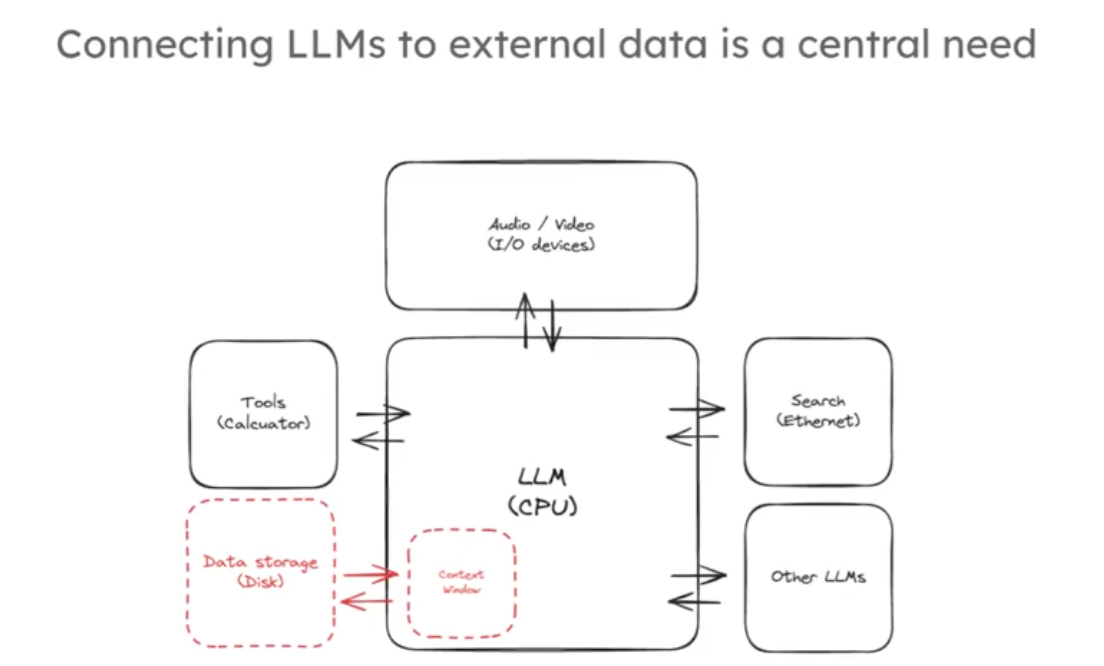
RAG 的主要動機 大模型訓練的時候雖然使用了龐大的世界數據,但是并沒有涵蓋用戶關心的所有數據,
其預訓練令牌(token)數量雖大但相對這些數據仍有限。另外大模型輸入的上下文窗口越來越大,從幾千個token到幾萬個token,這相當于幾十幾百頁內容,但是遇到你有幾個G的文獻資料你還是不能完全用上下文輸入大模型來找到你想要的內容。大模型就像是新型操作系統的核心,將核心與各種各樣的大量的外部鏈接起來,是這個新興的操作系統發展中的一個非常核心的能力,如下圖:
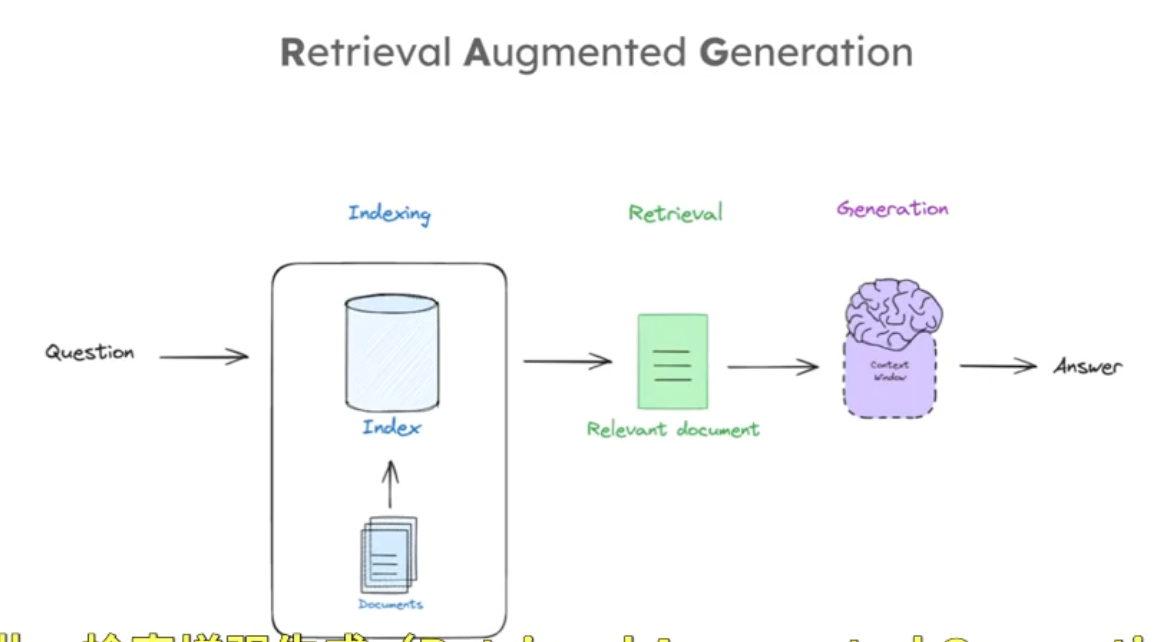
RAG(Retrieval Augmented Generation)是實現這一目標的通用范式,RAG管道組成的三個部分通常包括:索引、檢索、生成三個部分。這三個階段,索引是對外部文檔進行處理以便根據查詢輕松檢索;檢索是根據輸入查詢獲取相關文檔;生成是將檢索到的文檔喂給 LLM 以產生基于這些文檔的答案,如下圖:
以下是一個RAG過程的簡單流程
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_openai import ChatOpenAI
import os# 先驗證環境變量是否加載成功
ali_api_key = os.getenv("DASHSCOPE_API_KEY")
print(ali_api_key)
llm = ChatOpenAI(model="qwen-max-latest",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",openai_api_key = ali_api_key,temperature = 0,
)#respons = llm.invoke("你是誰,能幫我解決什么問題")
#print(respons.content)
# 確保正確初始化 embedding 模型
embedding_model = DashScopeEmbeddings(model="text-embedding-v4",dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") # 顯式傳遞 API 密鑰
)#### INDEXING ##### Load Documents
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),requests_kwargs={"headers": {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}}
)
docs = loader.load()
# Split
from langchain_chroma import Chroma
# 初始化 RecursiveCharacterTextSplitter 實例
# chunk_size=1000 表示每個文本塊的最大字符數為 1000
# chunk_overlap=200 表示相鄰文本塊之間重疊的字符數為 200,這有助于保持上下文的連貫性
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)# 調用 text_splitter 的 split_documents 方法,將文檔列表 docs 分割成多個較小的文本塊
# 分割后的文本塊存儲在 splits 列表中
splits = text_splitter.split_documents(docs)# 創建空集合
# 初始化 Chroma 向量數據庫實例,使用 embedding_model 作為嵌入函數
# 嵌入函數用于將文本轉換為向量表示,以便在向量數據庫中存儲和檢索
vectorstore = Chroma(embedding_function=embedding_model)# 手動分批次添加文檔(每次最多10個)
# 使用 for 循環和 range 函數,以 10 為步長遍歷 splits 列表
for i in range(0, len(splits), 10):# 從 splits 列表中截取當前批次的文檔,每次最多 10 個batch = splits[i:i+10]# 調用 vectorstore 的 add_documents 方法,將當前批次的文檔添加到向量數據庫中vectorstore.add_documents(documents=batch)# 調用 vectorstore 的 as_retriever 方法,將向量數據庫轉換為檢索器
# 檢索器可以根據輸入的查詢向量,從向量數據庫中檢索出相關的文檔
retriever = vectorstore.as_retriever()
# Prompt
prompt = hub.pull("rlm/rag-prompt")
print(prompt)# Post-processing
# 定義一個名為 format_docs 的函數,用于對文檔列表進行后處理
# 參數 docs 是一個包含文檔對象的列表,每個文檔對象應有 page_content 屬性
def format_docs(docs):# 使用生成器表達式遍歷 docs 列表中的每個文檔對象,獲取其 page_content 屬性# 然后使用 \n\n 作為分隔符將所有文檔的內容連接成一個字符串并返回return "\n\n".join(doc.page_content for doc in docs)# Chain
# 構建一個可運行的鏈式結構 rag_chain,用于執行問答任務
rag_chain = (# 構建一個字典,包含兩個鍵值對# "context" 鍵對應的值是一個鏈式操作,先通過 retriever 檢索相關文檔,# 再將檢索到的文檔列表傳遞給 format_docs 函數進行格式化# "question" 鍵對應的值是 RunnablePassthrough(),表示直接傳遞輸入的問題{"context": retriever | format_docs, "question": RunnablePassthrough()}# 將上述字典作為輸入傳遞給 prompt,生成提示信息| prompt# 將生成的提示信息傳遞給大語言模型 llm,獲取模型的回答| llm# 使用 StrOutputParser() 對大語言模型的輸出進行解析,提取純文本內容| StrOutputParser()
)# Question
# 調用 rag_chain 的 invoke 方法,傳入問題 "What is Task Decomposition?"
# 執行整個問答流程,最終返回關于 "任務分解是什么" 的答案
rag_chain.invoke("What is Task Decomposition?")
實際上圍繞著索引、檢索和生成這三個組件,衍生出很多有趣的方法和技巧,如下圖:
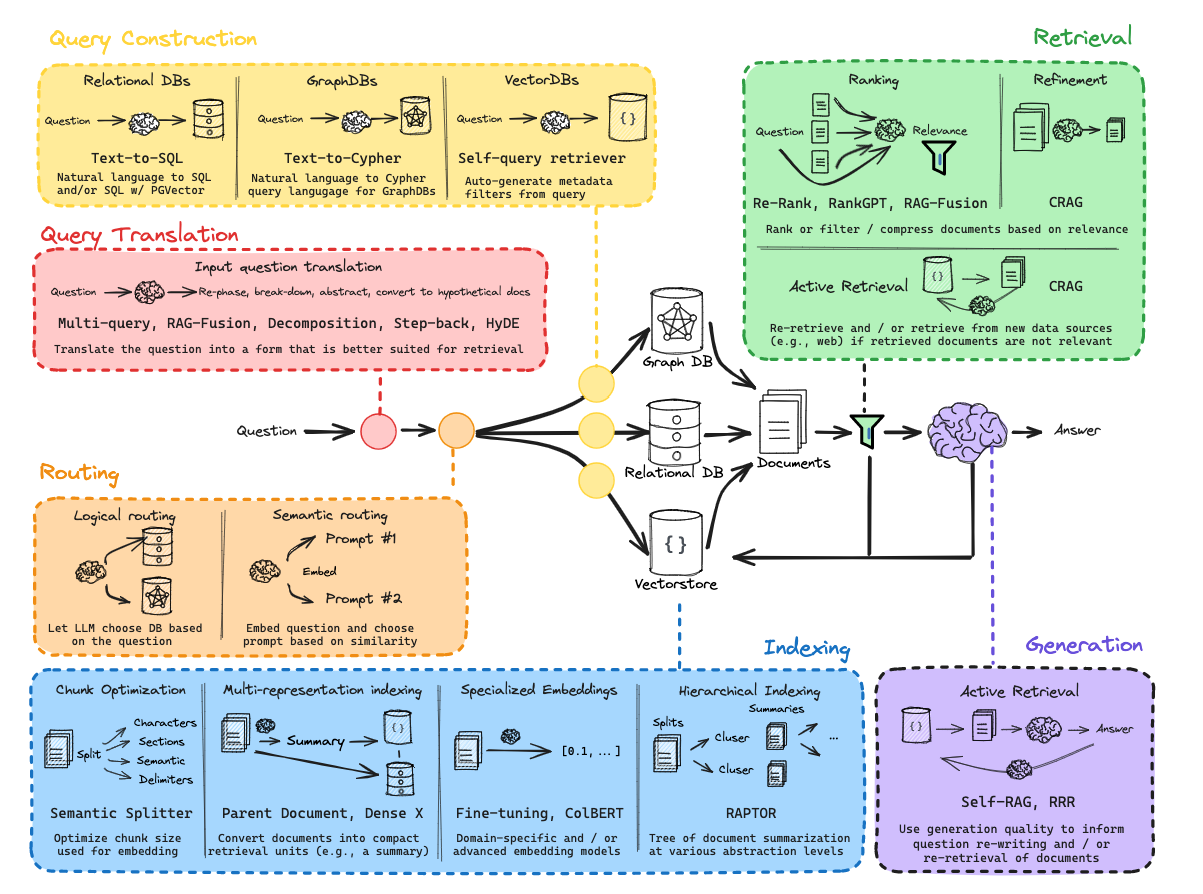
首先我們先從檢索器開始,索引是 RAG(檢索增強生成)系統堆棧管道的核心環節之一,指將外部文檔(如網頁、論文、本地文件等)進行處理(如分割、轉換為數值向量等),使其轉化為可被高效檢索的形式,并存儲起來的過程。其核心是將非結構化的文本信息轉化為結構化、可計算的格式(如向量),為后續檢索做準備。
索引的作用
1.適配檢索需求:外部文檔通常是原始文本,直接用于檢索效率極低。索引通過分割文檔(因嵌入模型上下文窗口有限)、將文本轉換為向量(捕捉語義信息)等操作,使文檔能被快速匹配和檢索。
2.支撐語義匹配:索引過程中,文檔會被嵌入為固定長度的向量(如視頻中提到的 1536 維向量),這些向量編碼了文本的語義含義,便于通過余弦相似性等數值方法與問題向量進行比較,從而找到相關文檔。
3.連接外部知識與檢索器:索引將外部文檔 “加載” 到向量存儲中,并與原始文檔關聯,為檢索器提供可查詢的 “知識庫”,使檢索器能基于輸入問題精準定位相關信息。
索引與檢索器的關系
索引是檢索器的 “前置依賴”,二者是 “準備” 與 “使用” 的關系:
- 索引為檢索器提供數據基礎:索引處理后的文檔(以向量形式存儲)是檢索器的核心數據源。沒有索引,檢索器無法高效獲取和匹配外部文檔。
- 檢索器依賴索引實現功能:檢索器的核心任務是根據輸入問題,從索引后的向量存儲中找到最相關的文檔片段。它通過將問題也轉換為向量,與索引中的文檔向量進行數值比較(如余弦相似性),完成 “檢索相關文檔” 的過程
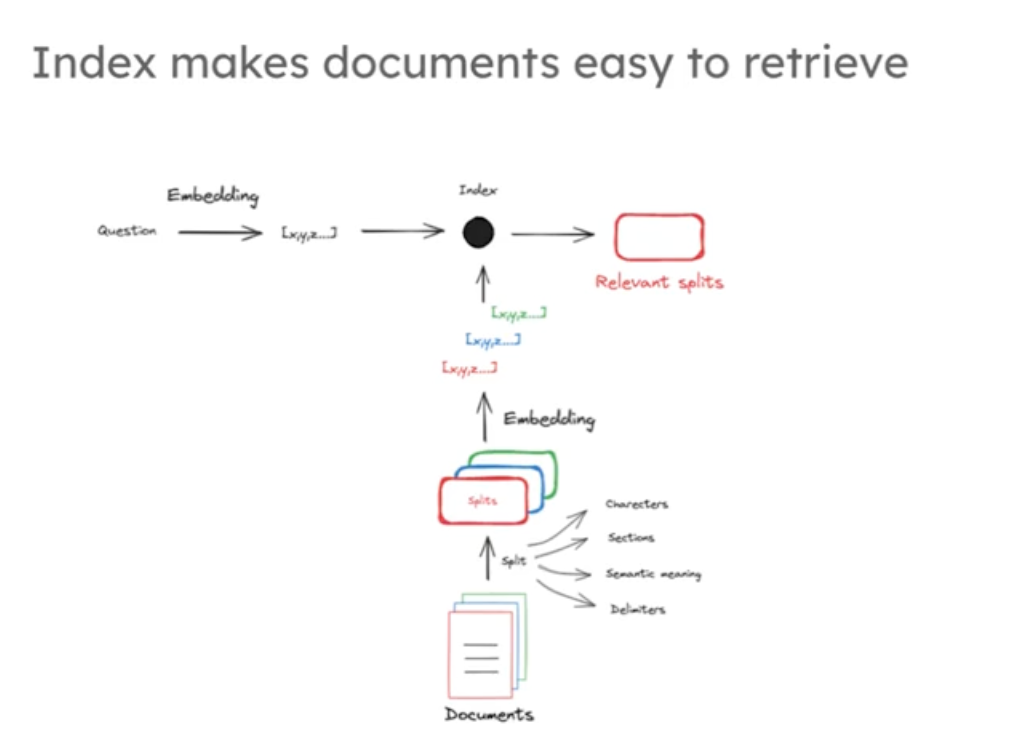
首先要對文檔進行數值表示,建立文檔與問題的關系通常使用文檔的數值表示,因為對于計算機來說向量(數字)容易比較,相對隨意文本更便于處理。
文檔壓縮為數值表示的方法有哪些:多年來有多種方法將文本文檔壓縮為可輕松搜索的數值表示,
1,谷歌等公司開發的統計方法,通過查看單詞頻率構建稀疏向量,向量位置對應大詞匯表,值代表單詞出現次數,因詞匯表龐大而稀疏;
2,還有較新的機器學習嵌入方法,將文檔構建為壓縮的固定長度表示,有強大的對應搜索方法。
由于嵌入模型有受限的上下文窗口輸入,所以通常將大文檔分割成小部分來輸入限制,每個分割部分通過嵌入模型轉化為向量作為文檔的數值表示,然后通將向量和原始文檔的片段鏈接一起存儲在我們的向量存儲中,一般是向量數據庫比如chroma,Faiss等數據庫,其中向量作為做為索引存儲的。
如下圖:
index過程代碼
# Documents
question = "What kinds of pets do I like?"
document = "My favorite pet is a cat."
import tiktoken
#返回文本字符串中的 token 數量。
def num_tokens_from_string(string: str, encoding_name: str) -> int:"""Returns the number of tokens in a text string."""encoding = tiktoken.get_encoding(encoding_name)num_tokens = len(encoding.encode(string))return num_tokens
# 調用 num_tokens_from_string 函數,計算變量 question 中的文本使用 "cl100k_base" 編碼后的 token 數量
num_tokens_from_string(question, "cl100k_base")from langchain_community.embeddings import DashScopeEmbeddings
# 確保正確初始化 embedding 模型
embd = DashScopeEmbeddings(model="text-embedding-v4",dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") # 顯式傳遞 API 密鑰
)
query_result = embd.embed_query(question)
document_result = embd.embed_query(document)#文本轉向量
len(query_result)import numpy as npdef cosine_similarity(vec1, vec2):"""計算兩個向量之間的余弦相似度。余弦相似度是通過計算兩個向量的夾角余弦值來評估它們的方向相似性。取值范圍在 -1 到 1 之間,值越接近 1 表示兩個向量越相似,值越接近 -1 表示兩個向量越不相似,值為 0 表示兩個向量正交。參數:vec1 (array-like): 第一個輸入向量。vec2 (array-like): 第二個輸入向量。返回:float: 兩個向量的余弦相似度。"""# 計算兩個向量的點積dot_product = np.dot(vec1, vec2)# 計算第一個向量的 L2 范數(歐幾里得范數)norm_vec1 = np.linalg.norm(vec1)# 計算第二個向量的 L2 范數(歐幾里得范數)norm_vec2 = np.linalg.norm(vec2)# 計算并返回余弦相似度return dot_product / (norm_vec1 * norm_vec2)
# 調用 cosine_similarity 函數計算 query_result 和 document_result 兩個向量的余弦相似度
similarity = cosine_similarity(query_result, document_result)
# 打印計算得到的余弦相似度
print("Cosine Similarity:", similarity)#### INDEXING ##### Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),
)
blog_docs = loader.load()# Split
# 從 langchain 庫中導入 RecursiveCharacterTextSplitter 類
# 該類用于將文本遞歸地按字符分割成較小的塊
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(# 每個文本塊的最大 token 數量為 300chunk_size=300, # 相鄰文本塊之間重疊的 token 數量為 50,這有助于保持上下文的連貫性chunk_overlap=50)# Make splits
# 調用 text_splitter 實例的 split_documents 方法
# 對 blog_docs 中的文檔進行分割,返回分割后的文本塊列表
splits = text_splitter.split_documents(blog_docs)from langchain_community.embeddings import DashScopeEmbeddings
from langchain_chroma import Chroma# 確保正確初始化 embedding 模型
embd = DashScopeEmbeddings(model="text-embedding-v4",dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") # 顯式傳遞 API 密鑰
)
# vectorstore = Chroma.from_documents(documents=splits,
# embedding=embd)
# # 調用 vectorstore 的 as_retriever 方法,將向量數據庫轉換為檢索器
# # 檢索器可以根據輸入的查詢向量,從向量數據庫中檢索出相關的文檔
# retriever = vectorstore.as_retriever()
# 創建空的 Chroma 向量庫
vectorstore = Chroma(embedding_function=embd)
# 手動分批次添加文檔,每次最多 10 個
for i in range(0, len(splits), 10):batch = splits[i:i + 10]vectorstore.add_documents(documents=batch)# 調用 vectorstore 的 as_retriever 方法,將向量數據庫轉換為檢索器
# 檢索器可以根據輸入的查詢向量,從向量數據庫中檢索出相關的文檔
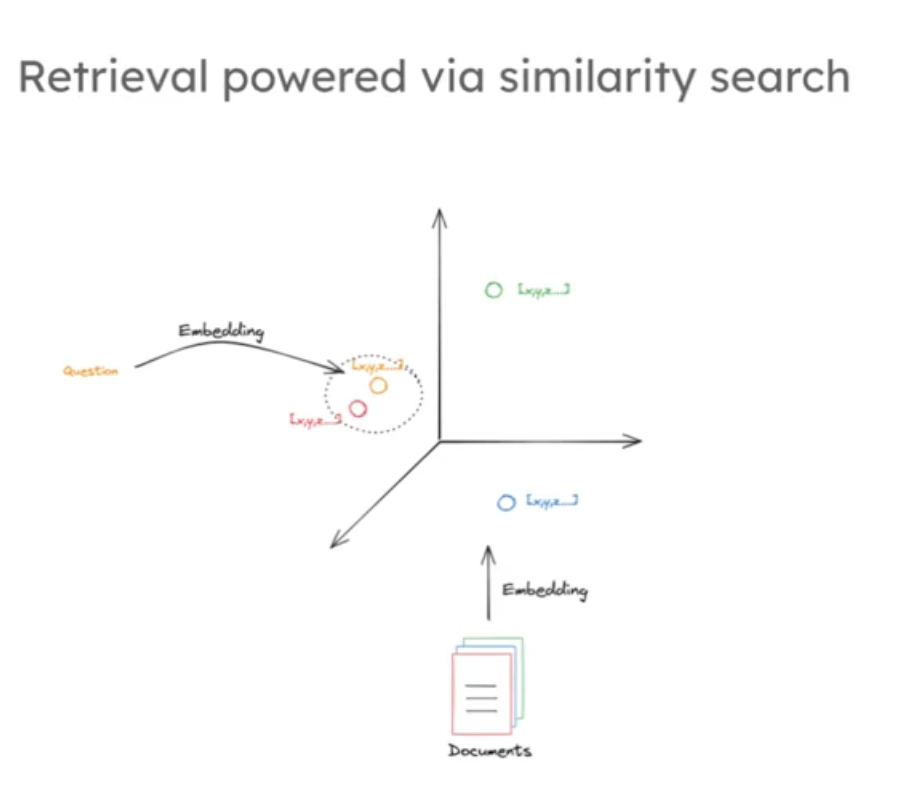
retriever = vectorstore.as_retriever()當給出一個同樣經過嵌入處理的問題時,索引會執行相似性搜索,并返回與該問題相似的文檔片段。我們可以想象這些向量有三個維度,每個文檔片段處理的文檔都被映射到三維空間的某個點上,這些點的位置是由不同的文本語義決定的,位于空間中相似位置的文檔,其包含的語義也是相似的,這是許多現代向量存儲中搜索與檢索的基石。同樣的將問題嵌入后進行搜索,就和圍繞問題開展局部領域搜索一樣如下圖中黃點是問題,周圍的紅點是我們的目標文檔。
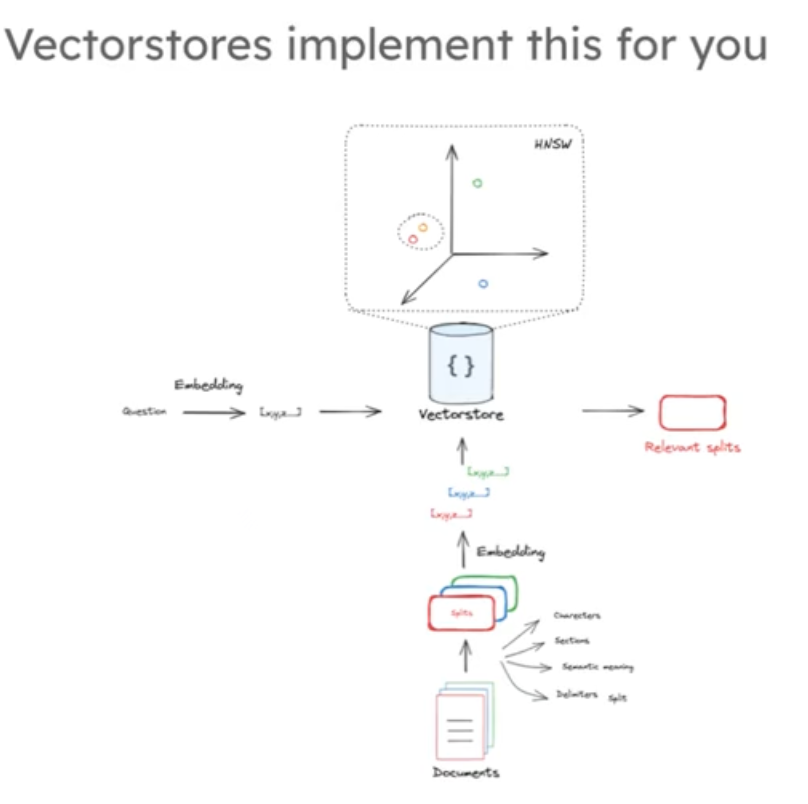
總之,從文檔切片到文本嵌入向量化保存到數據庫,然后再將問題嵌入向量后進行搜索,獲取我們需要的一個或者多個我們需要的文檔片段,這是一個完整的流程如下圖:
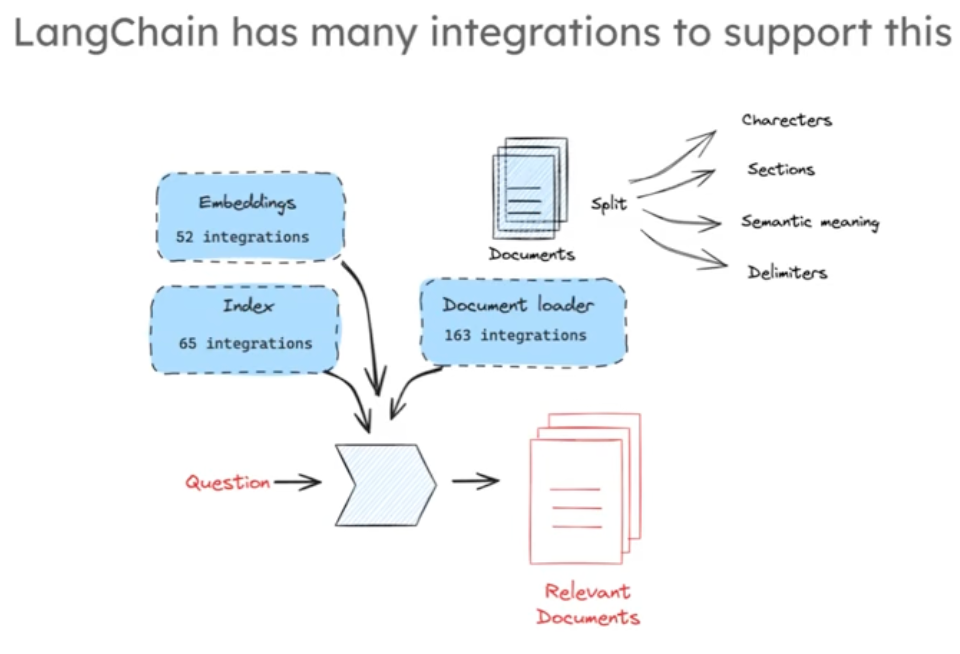
langchain中我們可以找到很多不同的嵌入模型,多樣的索引方式,豐富的文檔加載器和分割器,我們可以自由組合測試不同的索引和檢測方法,來完成這一過程
Retrievel 索引代碼
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# vectorstore = Chroma.from_documents(documents=splits,
# embedding=embd)
vectorstore = Chroma(embedding_function=embd)
# 手動分批次添加文檔,每次最多 10 個
for i in range(0, len(splits), 10):batch = splits[i:i + 10]vectorstore.add_documents(documents=batch)#參數k決定了檢索過程中要獲取的最近鄰的數量
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# docs = retriever.get_relevant_documents("What is Task Decomposition?")
docs = retriever.invoke("What is Task Decomposition?")
print(docs)
len(docs)Generation:
接下來我們討論生成回答的過程
當我們使用KNN,或者k鄰近算法從空間索引中尋找到問題相關的文檔片段后,我們將這些文檔片段整合到大模型的上下文窗口中,從而讓大模型生成我們需要的答案,如下圖:generation:
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate# Prompt
template = """Answer the question based only on the following context:
{context}Question: {question}
"""prompt = ChatPromptTemplate.from_template(template)
prompt# Chain
chain = prompt | llm# Run 用于生成回答內容
chain.invoke({"context":docs,"question":"What is Task Decomposition?"})from langchain import hub
prompt_hub_rag = hub.pull("rlm/rag-prompt")
prompt_hub_rag
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
#創建一個基于檢索增強生成(RAG)的鏈式處理流程
# RAG 結合了檢索和生成模型的能力,利用外部知識源來回答問題
rag_chain = (# 使用字典來組織輸入數據# "context" 鍵對應的值為 retriever,意味著將輸入問題通過檢索器獲取相關上下文# "question" 鍵對應的值為 RunnablePassthrough(),表示直接傳遞輸入的問題{"context": retriever, "question": RunnablePassthrough()}# 將組織好的輸入數據(包含上下文和問題)傳遞給提示模板 prompt# prompt 會根據上下文和問題生成適合大語言模型輸入的提示文本| prompt
# 將生成好的提示文本傳遞給大語言模型 llm 進行推理,得到模型的輸出| llm
# 使用 StrOutputParser() 對大語言模型的輸出進行解析# 該解析器會將模型的輸出轉換為字符串類型| StrOutputParser()
)rag_chain.invoke("What is Task Decomposition?")


(通過php內置服務器運行php文件))









)
)
操作)
)



