問題
link: https://leetgpu.com/challenges/vector-addition
Implement a program that performs element-wise addition of two vectors containing 32-bit floating point numbers on a GPU. The program should take two input vectors of equal length and produce a single output vector containing their sum.
Implementation Requirements
External libraries are not permitted
The solve function signature must remain unchanged
The final result must be stored in vector C
解決思路
CUDA使用了SIMT的方法來分配不同線程,也就是對于每個細分后的thread,指令都不一樣。這就要我們首先要給并行的函數確定一下他們自己在GPU的什么位置。即要確定thread、block的數量。 對此有如下基礎知識:
- thread: 一個CUDA的并行程序會被以許多個thread來執行。
- block: 數個thread會被群組成一個block,同一個block中的thread可以同步,也可以通過shared memory進行通信。
- grid: 多個block則會再構成grid。
解釋一下(來源于: https://zhuanlan.zhihu.com/p/123170285):
一個CUDA core可以執行一個thread,一個SM的CUDA core會分成幾個warp(即CUDA core在SM中分組),由warp scheduler負責調度。盡管warp中的線程從同一程序地址,但可能具有不同的行為,比如分支結構,因為GPU規定warp中所有線程在同一周期執行相同的指令,warp發散會導致性能下降。一個SM同時并發的warp是有限的,因為資源限制,SM要為每個線程塊分配共享內存,而也要為每個線程束中的線程分配獨立的寄存器,所以SM的配置會影響其所支持的線程塊和warp并發數量。
一個warp中的線程必然在同一個block中, 如果block所含線程數目不是warp大小的整數倍,那么多出的那些thread所在的warp中,會剩余一些inactive的thread,也就是說,即使湊不夠warp整數倍的thread,硬件也會為warp湊足,只不過那些thread是inactive狀態,需要注意的是,即使這部分thread是inactive的,也會消耗SM資源。 由于warp的大小一般為32,所以block所含的thread的大小一般要設置為32的倍數。
由于一個warp (warp(線程束)是最基本的執行單元) 包含32個并行thread,所以thread的數量應該設置成32的整數倍,一般為256。線程塊大小需平衡并行效率和資源限制(如寄存器、共享內存等),一般設置為 ??threadsPerBlock = 256?? 每個線程塊包含256個線程。
CUDA的軟硬件:
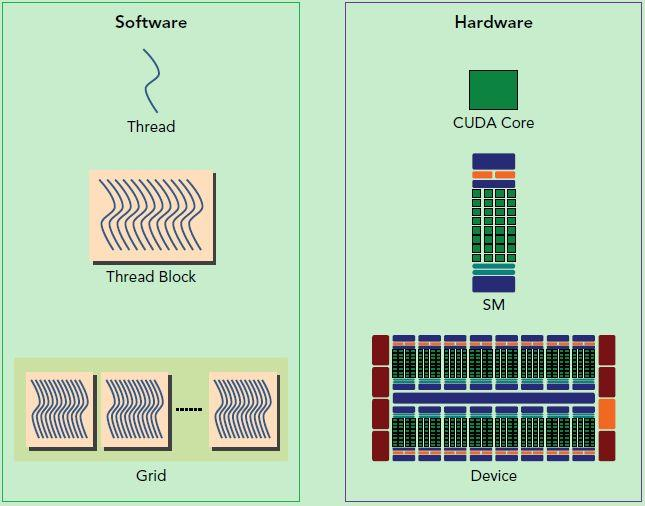
CUDA的軟件劃分。
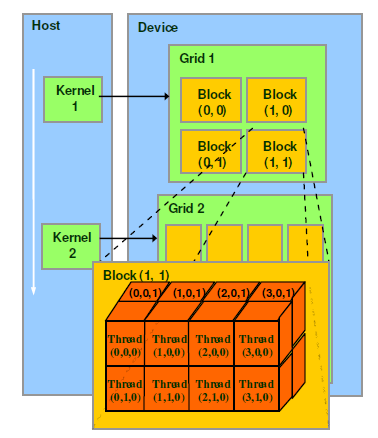
每個grid的block數量可以由下面的公式計算獲得.
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
該公式通過向上取整確保所有 N個元素都有對應的線程處理:
- ??分子部分??:N + threadsPerBlock - 1通過添加 threadsPerBlock - 1實現向上取整。
- 分母部分??:除以 threadsPerBlock得到所需的線程塊數量
聲明函數
vector_add<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, N);
由于是單一維度的vector,所以只需要用到blockIdx、blockDim和threadIdx的第一維度(x)。后面的二維問題再說y維度。CUDA中每一個線程都有一個唯一的標識ID即threadIdx,這個ID隨著Grid和Block的劃分方式的不同而變化:
int idx=blockIdx.x*blockDim.x+threadIdx.x;
答案
__global__ void vector_add(const float* A, const float* B, float* C, int N) {int idx=blockIdx.x*blockDim.x+threadIdx.x;if (idx < N) {C[idx] = A[idx] + B[idx]; // 逐元素相加}
}


:打開潘多拉魔盒的數字幽靈)




)










7.26)
)