參考:白話PPO訓練
成功截圖

算法組件
四大部分
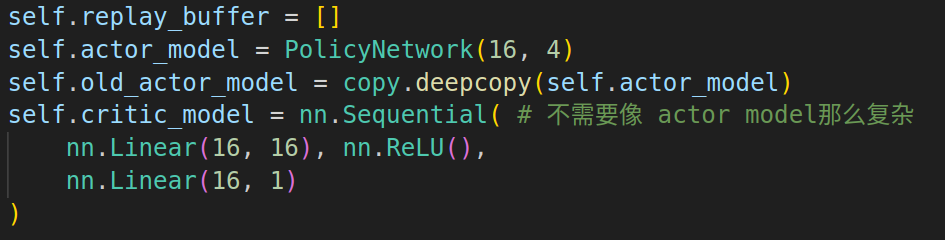
???????? 同A2C相比,PPO算法額外引入了一個old_actor_model.?
????????在PPO的訓練中,首先使用old_actor_model與環境進行交互得到經驗,然后利用一批經驗優化actor_model,最后再將actor_model的參數復制回old_actor_model
超參數
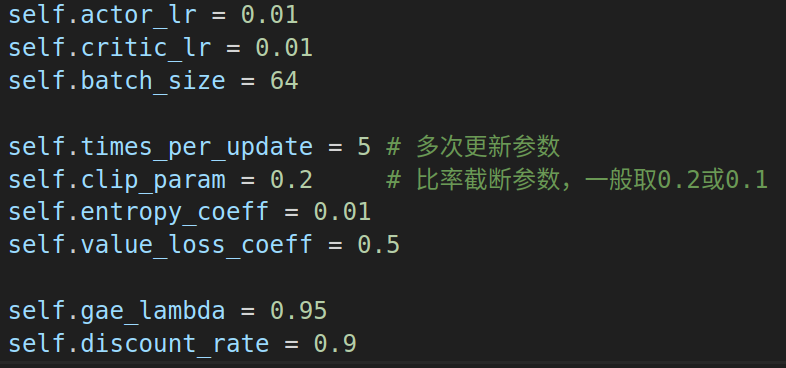
? ? ? ? 同A2C相比,PPO_clip多了兩個參數: 單批數據更新次數和截斷閾值
- times_per_update:?在收集到的一批數據上,進行多少次梯度更新。
clip_param(ε)?:?PPO裁剪目標函數中的閾值,通常取 0.1 或 0.2
訓練過程
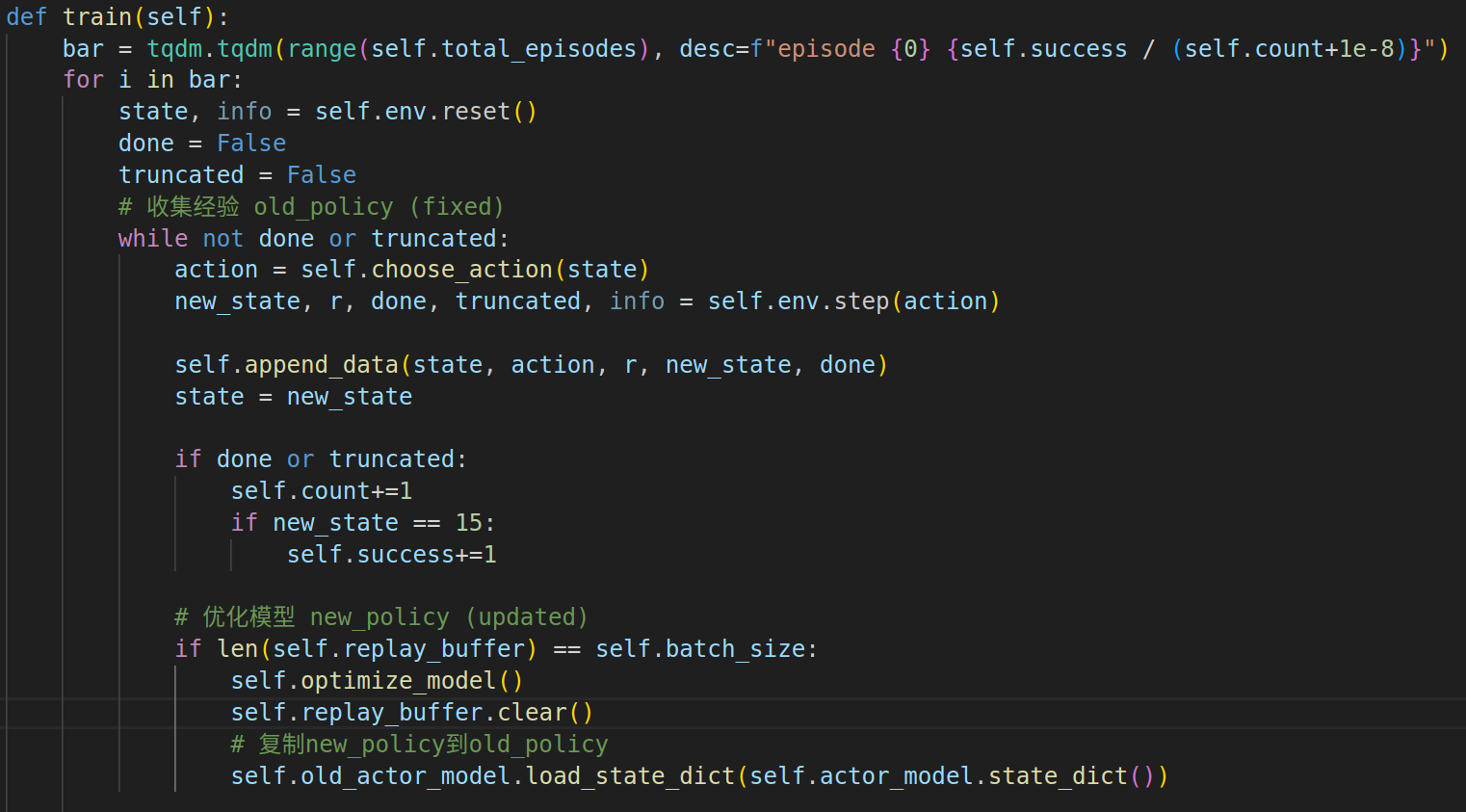
? ? ? ? 整體訓練框架同A2C, 差別在于使用old_policy采集經驗,然后優化new_policy,最后復制回old_policy.
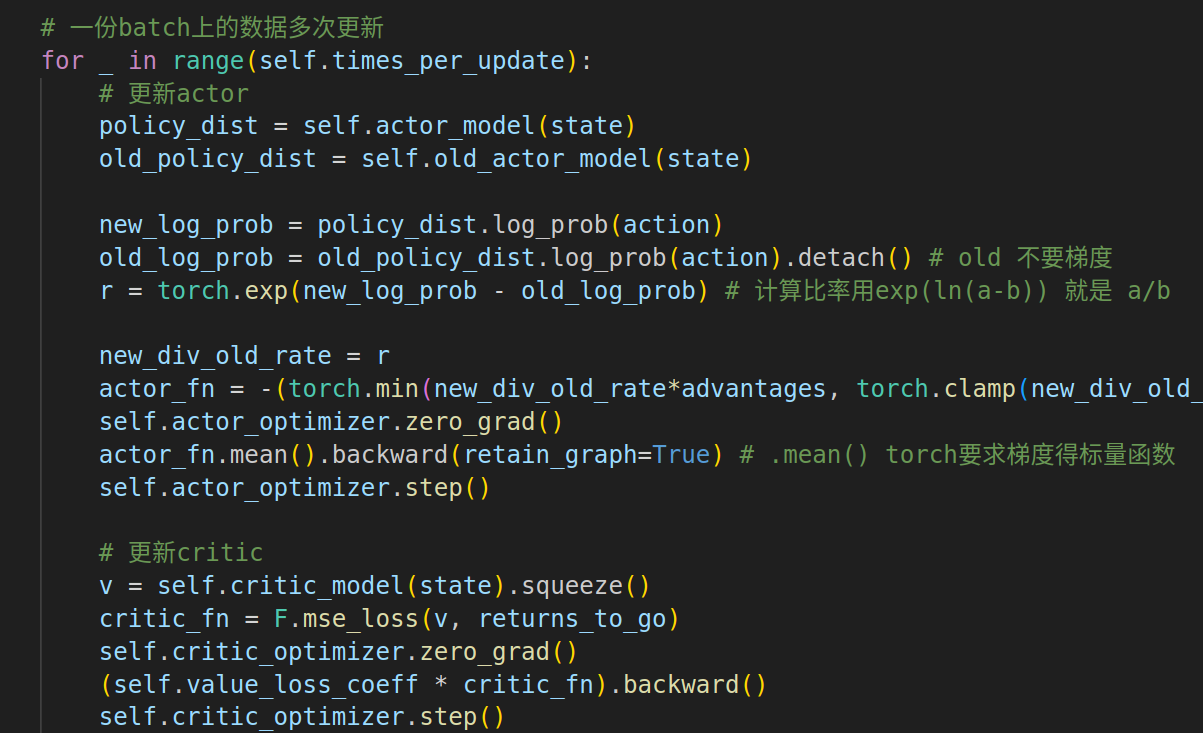
? ? ? ? PPO為了高效利用經驗數據,在一批經驗上進行多次數據更新。
目標函數
?1. critic的目標函數同A2C
?2. actor的目標函數為PPO_clip
? ? ?
完整代碼
import torch
import torch.nn as nn
from torch.nn import functional as F
import gymnasium as gym
import tqdm
from torch.distributions import Categorical
from typing import Tuple
import copyclass PolicyNetwork(nn.Module):def __init__(self, n_observations: int, n_actions: int):super(PolicyNetwork, self).__init__()self.layer1 = nn.Linear(n_observations, 32) self.layer2 = nn.Linear(32, 16) self.layer3 = nn.Linear(16, n_actions) def forward(self, x: torch.Tensor) -> Categorical: x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))action_logits = self.layer3(x)return Categorical(logits=action_logits)class PPO_clip:def __init__(self, env, total_episodes):#############超參數#############self.actor_lr = 0.01self.critic_lr = 0.01self.batch_size = 64self.times_per_update = 5 # 多次更新參數self.clip_param = 0.2 # 比率截斷參數,一般取0.2或0.1self.entropy_coeff = 0.01self.value_loss_coeff = 0.5self.gae_lambda = 0.95 self.discount_rate = 0.9 self.total_episodes = total_episodes#############PPO_clip的核心要件#############self.replay_buffer = []self.actor_model = PolicyNetwork(16, 4)self.old_actor_model = copy.deepcopy(self.actor_model)self.critic_model = nn.Sequential( # 不需要像 actor model那么復雜nn.Linear(16, 16), nn.ReLU(),nn.Linear(16, 1))############優化組件#############self.actor_optimizer = torch.optim.Adam(self.actor_model.parameters(), lr=self.actor_lr) self.critic_optimizer = torch.optim.Adam(self.critic_model.parameters(), lr=self.critic_lr)self.env = envself.count = 0self.success = 0def train(self):bar = tqdm.tqdm(range(self.total_episodes), desc=f"episode {0} {self.success / (self.count+1e-8)}") for i in bar:state, info = self.env.reset()done = Falsetruncated = False# 收集經驗 old_policy (fixed)while not done or truncated:action = self.choose_action(state)new_state, r, done, truncated, info = self.env.step(action) self.append_data(state, action, r, new_state, done)state = new_stateif done or truncated:self.count+=1if new_state == 15: self.success+=1# 優化模型 new_policy (updated)if len(self.replay_buffer) == self.batch_size:self.optimize_model()self.replay_buffer.clear()# 復制new_policy到old_policyself.old_actor_model.load_state_dict(self.actor_model.state_dict()) if i % 100 == 0:self.count = 0self.success = 0bar.set_description(f"episode {i} {self.success / (self.count+1e-8)}")def choose_action(self, state):with torch.no_grad():policy_dist = self.old_actor_model(self.state_to_input(state))action_tensor = policy_dist.sample()action = action_tensor.item()return actiondef optimize_model(self):state = torch.stack([self.state_to_input(tup[0]) for tup in self.replay_buffer[-self.batch_size:]])action = torch.IntTensor([tup[1] for tup in self.replay_buffer[-self.batch_size:]])reward = torch.FloatTensor([tup[2] for tup in self.replay_buffer[-self.batch_size:]])new_state = torch.stack([self.state_to_input(tup[3]) for tup in self.replay_buffer[-self.batch_size:]])done = torch.FloatTensor([tup[4] for tup in self.replay_buffer[-self.batch_size:]])# 以上state和new_state是二維的, 其他是一維的,即batch維with torch.no_grad():value = self.critic_model(state).squeeze()last_value = self.critic_model(new_state[:-1]).squeeze()next_value = torch.cat((value[1:], last_value))# 相比一次TD誤差, GAE效果顯著之好 advantages, returns_to_go = self.compute_gae_and_returns(reward, value, next_value, done, self.discount_rate, self.gae_lambda)# 一份batch上的數據多次更新for _ in range(self.times_per_update):# 更新actorpolicy_dist = self.actor_model(state)old_policy_dist = self.old_actor_model(state) new_log_prob = policy_dist.log_prob(action)old_log_prob = old_policy_dist.log_prob(action).detach() # old 不要梯度 r = torch.exp(new_log_prob - old_log_prob) # 計算比率用exp(ln(a)-ln(b)) 就是 a/bnew_div_old_rate = ractor_fn = -(torch.min(new_div_old_rate*advantages, torch.clamp(new_div_old_rate, 1-self.clip_param, 1+self.clip_param)*advantages) + self.entropy_coeff * policy_dist.entropy()) self.actor_optimizer.zero_grad()actor_fn.mean().backward(retain_graph=True) # .mean() torch要求梯度得標量函數self.actor_optimizer.step()# 更新criticv = self.critic_model(state).squeeze()critic_fn = F.mse_loss(v, returns_to_go)self.critic_optimizer.zero_grad()(self.value_loss_coeff * critic_fn).backward()self.critic_optimizer.step()def compute_gae_and_returns(self,rewards: torch.Tensor, values: torch.Tensor, next_values: torch.Tensor, dones: torch.Tensor, discount_rate: float, lambda_gae: float, ) -> Tuple[torch.Tensor, torch.Tensor]:advantages = torch.zeros_like(rewards)last_advantage = 0.0n_steps = len(rewards)# 計算GAEfor t in reversed(range(n_steps)):mask = 1.0 - dones[t]delta = rewards[t] + discount_rate * next_values[t] * mask - values[t] advantages[t] = delta + discount_rate * lambda_gae * last_advantage * masklast_advantage = advantages[t]# 返回給critic作為TD目標 returns_to_go = advantages + values return advantages, returns_to_godef append_data(self, state, action, r, new_state, done):self.replay_buffer.append((state, action, r, new_state, done))def state_to_input(self, state):input_dim = 16input = torch.zeros(input_dim, dtype=torch.float)input[int(state)] = 1return inputenv = gym.make("FrozenLake-v1", is_slippery=False)
policy = PPO_clip(env, 2000)
policy.train()env = gym.make("FrozenLake-v1", is_slippery=False, render_mode="human")
state, info = env.reset()
done = False
truncated = False
while True:with torch.no_grad():action=policy.choose_action(state) new_state, reward, done, truncated, info = env.step(action)state=new_stateif done or truncated:state, info = env.reset()操作)
)







)








)
線程控制:互斥與同步)