在擴散模型中,逆向過程的目標是從噪聲數據逐步恢復出原始數據。本文將詳細解析逆向條件分布 q(zt?1∣zt,x)q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x})q(zt?1?∣zt?,x)的推導過程,揭示擴散模型如何通過高斯分布實現數據重建。
1. 核心問題
在擴散模型中,我們希望學習如何從含噪數據 (zt(\mathbf{z}_t(zt?) 逐步恢復原始數據 x\mathbf{x}x。直接求逆向分布 q(zt?1∣zt)q(\mathbf{z}_{t-1} \mid \mathbf{z}_t)q(zt?1?∣zt?) 是困難的,但若額外已知原始數據 x\mathbf{x}x,則條件分布 q(zt?1∣zt,x)q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x})q(zt?1?∣zt?,x)可以簡化為高斯分布。
2. 貝葉斯定理的應用
利用貝葉斯定理,將條件分布分解為:
q(zt?1∣zt,x)=q(zt∣zt?1,x)q(zt?1∣x)q(zt∣x)
q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x}) = \frac{q(\mathbf{z}_t \mid \mathbf{z}_{t-1}, \mathbf{x}) q(\mathbf{z}_{t-1} \mid \mathbf{x})}{q(\mathbf{z}_t \mid \mathbf{x})}
q(zt?1?∣zt?,x)=q(zt?∣x)q(zt?∣zt?1?,x)q(zt?1?∣x)?
關鍵簡化:
-
馬爾可夫性質:前向過程中,zt\mathbf{z}_tzt?僅依賴zt?1\mathbf{z}_{t-1}zt?1?,因此:
q(zt∣zt?1,x)=q(zt∣zt?1) q(\mathbf{z}_t \mid \mathbf{z}_{t-1}, \mathbf{x}) = q(\mathbf{z}_t \mid \mathbf{z}_{t-1}) q(zt?∣zt?1?,x)=q(zt?∣zt?1?)
此項由前向過程的定義給出(公式 20.4):
q(zt∣zt?1)=N(zt;1?βtzt?1,βtI) q(\mathbf{z}_t \mid \mathbf{z}_{t-1}) = \mathcal{N}\left(\mathbf{z}_t; \sqrt{1-\beta_t} \mathbf{z}_{t-1}, \beta_t \mathbf{I}\right) q(zt?∣zt?1?)=N(zt?;1?βt??zt?1?,βt?I) -
擴散核:q(zt?1∣x)q(\mathbf{z}_{t-1} \mid \mathbf{x})q(zt?1?∣x)是前向過程的閉式解(公式 20.6):
q(zt?1∣x)=N(zt?1;αt?1x,(1?αt?1)I) q(\mathbf{z}_{t-1} \mid \mathbf{x}) = \mathcal{N}\left(\mathbf{z}_{t-1}; \sqrt{\alpha_{t-1}} \mathbf{x}, (1-\alpha_{t-1}) \mathbf{I}\right) q(zt?1?∣x)=N(zt?1?;αt?1??x,(1?αt?1?)I)
其中αt?1=∏s=1t?1(1?βs)\alpha_{t-1} = \prod_{s=1}^{t-1} (1-\beta_s)αt?1?=∏s=1t?1?(1?βs?)。 -
分母的忽略:分母 q(zt∣x)q(\mathbf{z}_t \mid \mathbf{x})q(zt?∣x) 與zt?1\mathbf{z}_{t-1}zt?1?無關,可視為常數。
3. 高斯分布的推導
分子部分是兩個高斯分布的乘積:
q(zt∣zt?1)?q(zt?1∣x)
q(\mathbf{z}_t \mid \mathbf{z}_{t-1}) \cdot q(\mathbf{z}_{t-1} \mid \mathbf{x})
q(zt?∣zt?1?)?q(zt?1?∣x)
通過配方法(completing the square),可以合并指數項,得到一個新的高斯分布:
q(zt?1∣zt,x)=N(zt?1;mt(x,zt),σt2I)
q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x}) = \mathcal{N}\left(\mathbf{z}_{t-1}; \mathbf{m}_t(\mathbf{x}, \mathbf{z}_t), \sigma_t^2 \mathbf{I}\right)
q(zt?1?∣zt?,x)=N(zt?1?;mt?(x,zt?),σt2?I)
均值和方差的計算:
-
均值 (\mathbf{m}_t):
mt(x,zt)=αt?1βt1?αtx+1?βt(1?αt?1)1?αtzt \mathbf{m}_t(\mathbf{x}, \mathbf{z}_t) = \frac{\sqrt{\alpha_{t-1}} \beta_t}{1-\alpha_t} \mathbf{x} + \frac{\sqrt{1-\beta_t} (1-\alpha_{t-1})}{1-\alpha_t} \mathbf{z}_t mt?(x,zt?)=1?αt?αt?1??βt??x+1?αt?1?βt??(1?αt?1?)?zt?
這是原始數據x\mathbf{x}x和當前噪聲數據zt\mathbf{z}_tzt?的線性組合。 -
方差 σt2\sigma_t^2σt2?:
σt2=(1?αt?1)βt1?αt \sigma_t^2 = \frac{(1-\alpha_{t-1}) \beta_t}{1-\alpha_t} σt2?=1?αt?(1?αt?1?)βt??
僅依賴噪聲調度參數βt\beta_tβt?和累積系數αt\alpha_tαt?。
4. 直觀理解
- 給定x\mathbf{x}x的重要性:若已知原始數據x\mathbf{x}x,則從 zt\mathbf{z}_tzt?推斷 zt?1\mathbf{z}_{t-1}zt?1?是一個確定性更強的去噪問題,解為高斯分布。
- 物理意義:均值 mt\mathbf{m}_tmt?是“部分去噪”的結果,方差 σt2\sigma_t^2σt2?表示剩余的不確定性。
5. 與逆向過程的關系
實際訓練中,我們無法直接使用 x\mathbf{x}x(因需生成新數據),因此:
- 用神經網絡 pθ(zt?1∣zt)p_\theta(\mathbf{z}_{t-1} \mid \mathbf{z}_t)pθ?(zt?1?∣zt?)近似q(zt?1∣zt,x)q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x})q(zt?1?∣zt?,x)。
- 網絡通過預測均值 mt\mathbf{m}_tmt? 或噪聲 ?\boldsymbol{\epsilon}?來學習去噪。
6. 總結
- 數學本質:通過貝葉斯定理和高斯分布的性質,顯式推導出條件逆向分布的閉式解。
- 實際意義:指導神經網絡學習去噪步驟的理論基礎。
- 關鍵公式:
q(zt?1∣zt,x)=N(zt?1;mt(x,zt),σt2I) q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x}) = \mathcal{N}\left(\mathbf{z}_{t-1}; \mathbf{m}_t(\mathbf{x}, \mathbf{z}_t), \sigma_t^2 \mathbf{I}\right) q(zt?1?∣zt?,x)=N(zt?1?;mt?(x,zt?),σt2?I)
這種推導是擴散模型理論的核心,確保了從噪聲中生成數據的數學嚴謹性。
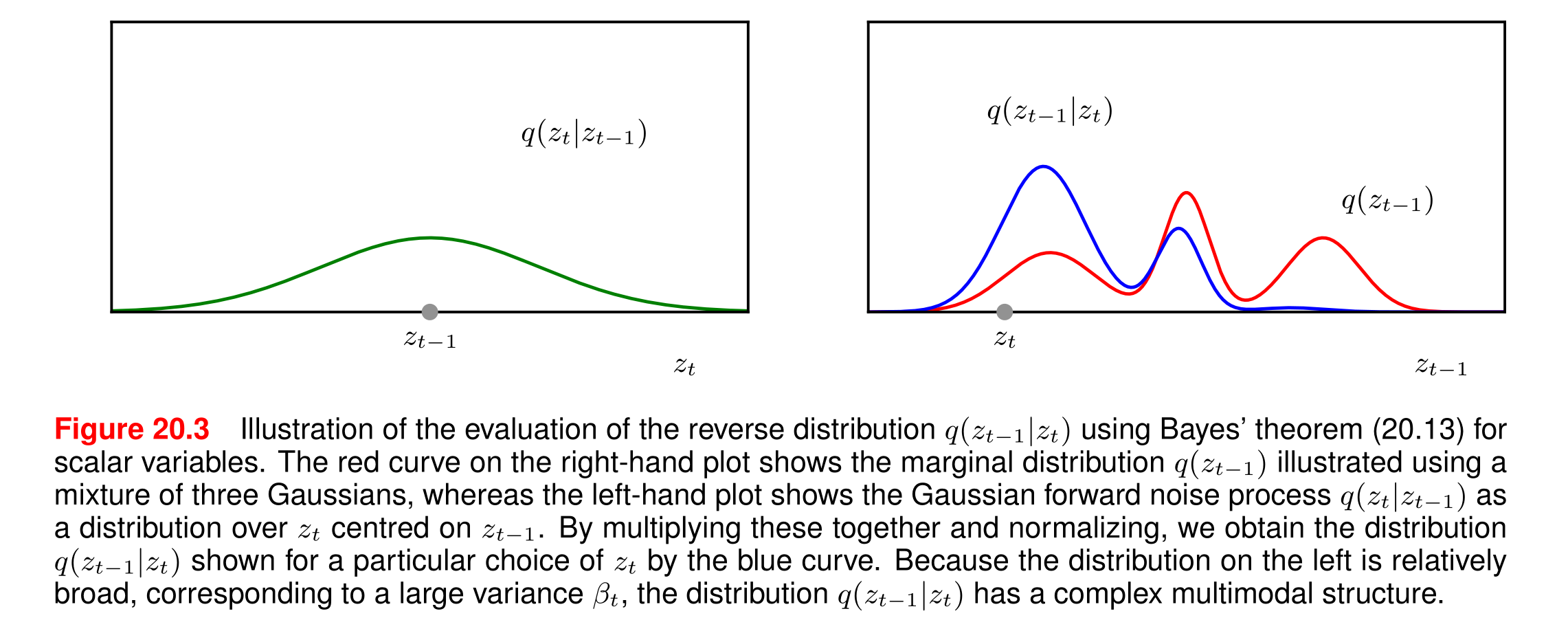
這張圖(圖20.3)展示了擴散模型中逆向分布的計算過程,以下是詳細解析:
1. 圖的組成與含義
(1) 左子圖:前向噪聲過程q(zt∣zt?1)q(z_t|z_{t-1})q(zt?∣zt?1?)
- 橫軸:噪聲數據 ztz_tzt?
- 縱軸:概率密度
- 曲線特征:以 zt?1z_{t-1}zt?1?為中心的高斯分布(鐘形曲線)
- 關鍵參數:方差βt\beta_tβt?較大 → 曲線"寬泛"(平坦)
- 物理意義:表示單步加噪時,ztz_tzt? 可能取值的范圍較大
(2) 右子圖:邊緣分布q(zt?1)q(z_{t-1})q(zt?1?)
- 橫軸:數據 zt?1z_{t-1}zt?1?
- 縱軸:概率密度
- 紅色曲線:三個高斯分布的混合(多峰結構)
- 物理意義:反映數據在t?1t-1t?1 步的整體分布(可能對應不同模態的真實數據)
(3) 藍色曲線:逆向分布q(zt?1∣zt)q(z_{t-1}|z_t)q(zt?1?∣zt?)
- 生成方式:通過貝葉斯定理將左、右子圖的分布相乘并歸一化
- 特征:復雜多峰結構(多個局部最大值)
- 物理意義:給定當前噪聲ztz_tzt?,可能對應多個潛在的 zt?1z_{t-1}zt?1?狀態
2. 關鍵句解析
“由于左側分布(對應大方差βt)相對寬泛,導致逆向分布q(zt?1∣zt)q(zt?1|zt)q(zt?1∣zt)呈現出復雜的多峰結構。”
(1) 因果關系
- 大方差 βt\beta_tβt? → 前向分布 q(zt∣zt?1)q(z_t|z_{t-1})q(zt?∣zt?1?) 平坦 → 允許 ztz_tzt? 偏離 zt?1z_{t-1}zt?1?更遠
- 結果:一個 ztz_tzt?可能由多個不同的zt?1z_{t-1}zt?1?生成 → 逆向分布出現多峰
(2) 多峰結構的含義
- 每個峰:對應一個可能的zt?1z_{t-1}zt?1? 來源
- 示例:若原始數據包含"貓"和"狗"兩類,加噪后的ztz_tzt?可能無法確定源自哪類 → 逆向分布同時保留兩種可能
(3) 數學解釋
貝葉斯定理中:
q(zt?1∣zt)∝q(zt∣zt?1)?寬泛分布?q(zt?1)?多峰分布
q(z_{t-1}|z_t) \propto \underbrace{q(z_t|z_{t-1})}_{\text{寬泛分布}} \cdot \underbrace{q(z_{t-1})}_{\text{多峰分布}}
q(zt?1?∣zt?)∝寬泛分布q(zt?∣zt?1?)???多峰分布q(zt?1?)??
- 寬泛的似然q(zt∣zt?1)q(z_t|z_{t-1})q(zt?∣zt?1?)不會壓制q(zt?1)q(z_{t-1})q(zt?1?) 的多峰性
- 最終逆向分布繼承q(zt?1)q(z_{t-1})q(zt?1?) 的多峰特征
3. 對擴散模型的意義
- 理論挑戰:多峰性說明直接計算逆向分布極其困難
- 解決方案:
- 用神經網絡pθ(zt?1∣zt)p_\theta(z_{t-1}|z_t)pθ?(zt?1?∣zt?)近似為單峰高斯
- 通過訓練使網絡學會選擇"最可能"的峰(對應高質量生成)
- 設計啟示:
- 需控制βt\beta_tβt?大小:方差過大導致多峰性增強,訓練難度增加
- 多峰性也賦予模型捕捉數據多樣性的能力
4. 實例說明
假設:
- 右子圖的三個峰對應zt?1=?1,0,1z_{t-1} = -1, 0, 1zt?1?=?1,0,1(三種潛在狀態)
- 觀測到zt=0.5z_t = 0.5zt?=0.5(左子圖中心在某個 zt?1z_{t-1}zt?1?
- 藍色曲線可能在zt?1=0z_{t-1} = 0zt?1?=0和zt?1=1z_{t-1} = 1zt?1?=1處各有一個峰
→ 說明zt=0.5z_t = 0.5zt?=0.5可能由zt?1=0z_{t-1} = 0zt?1?=0或111 加噪得到
5. 總結
該圖揭示了擴散模型中逆向過程的本質困難:
前向噪聲的隨機性(大方差)導致逆向推斷存在歧義,而模型必須通過學習解決這種歧義,才能實現高質量生成。這一現象也解釋了為什么擴散模型需要復雜的網絡結構和訓練技巧。
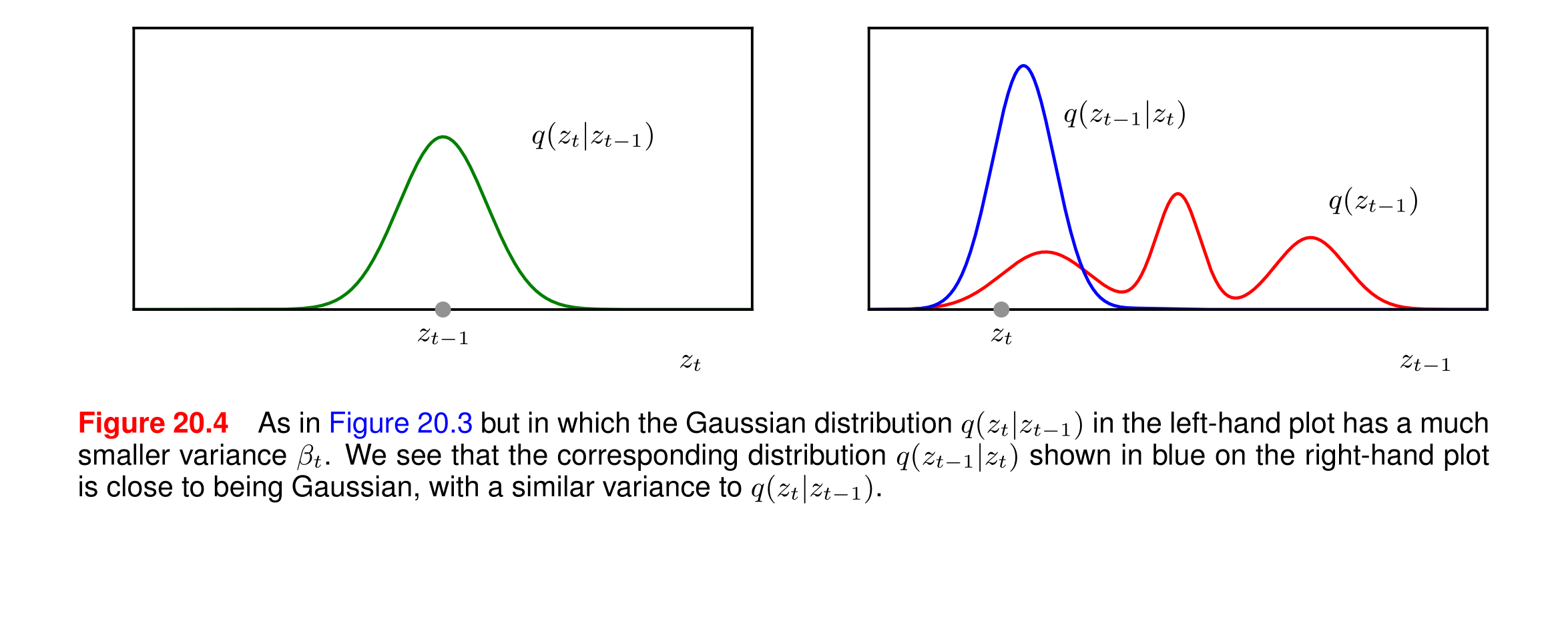
在圖20.4中,左圖展示了條件概率分布q(zt∣zt?1)q(z_t | z_{t-1})q(zt?∣zt?1?),其方差βt\beta_tβt?較小,這意味著分布更窄。右圖展示了相應的逆過程分布q(zt?1∣zt)q(z_{t-1} | z_t)q(zt?1?∣zt?)。
為什么分布更窄并不意味著變化更明顯?
-
方差與變化幅度:
- 方差是衡量數據分布的離散程度的指標。較小的方差意味著數據點更集中在均值附近。
- 在條件概率分布 q(zt∣zt?1)q(z_t | z_{t-1})q(zt?∣zt?1?)中,較小的方差表示在給定 zt?1z_{t-1}zt?1? 的情況下, ztz_tzt? 的取值更集中在某個特定值附近,即 ztz_tzt? 的變化幅度較小。
-
逆過程分布:
- 右圖中的藍色曲線 q(zt?1∣zt)q(z_{t-1} | z_t)q(zt?1?∣zt?)展示了在給定 ztz_tzt?的情況下, zt?1z_{t-1}zt?1? 的分布。
- 由于左圖中的 q(zt∣zt?1)q(z_t | z_{t-1})q(zt?∣zt?1?) 分布較窄,意味著 ztz_tzt? 的取值相對集中,因此在逆過程中, zt?1z_{t-1}zt?1? 的分布也相對集中,接近高斯分布。
-
變化幅度與學習難度:
- 分布更窄意味著在每一步變換中,潛在變量的變化幅度較小。這種微小的變化使得模型更容易學習如何逆轉這些變換,因為每一步的變換都是可預測的、穩定的。
- 如果方差較大,潛在變量的變化幅度會更大,這會增加模型學習逆過程的難度,因為每一步的變換更加不可預測。
總結
- 分布更窄(方差較小)意味著潛在變量的變化幅度較小,而不是變化更明顯。
- 這種微小的變化使得逆過程更容易學習和預測,因為每一步的變換都是相對穩定和可預測的。
- 因此,較小的方差有助于簡化模型的學習過程,但可能需要更多的步驟來達到顯著的總體變化。








)
)
操作)
)







)