定義損失函數并以此訓練和評估模型
存儲模型可以只存儲state_dict或模型參數,每當需要部署經過訓練的模型時,創建模型的對象并從文件中加載參數,這是 Pytorch 創建者推薦的方法。
目錄
模型的存儲、加載
模型的部署
模型的存儲、加載
承接上文,完成模型的訓練后,需要將訓練的參數存儲在文件中,以供部署和使用。
#定義路徑
path2weights="./models/weights.pt"
#將state_dict存儲到文件
torch.save(model.state_dict(), path2weights)為了從文件中加載模型參數,定義一個 Net 的對象類并加載state_dict
#定義隨機初始權重模型
_model = Net()
#加載文件中的state_dict
weights=torch.load(path2weights)
#賦予權重
_model.load_state_dict(weights)加載成功如下?
![]()
模型的部署
將模型加載到內存中后,可以將新數據傳遞給模型
import matplotlib.pyplot as plt
#抽取一個n=10張量
n=10
x= x_val[n]
y=y_val[n]
print(x.shape)
plt.imshow(x.numpy()[0],cmap="gray")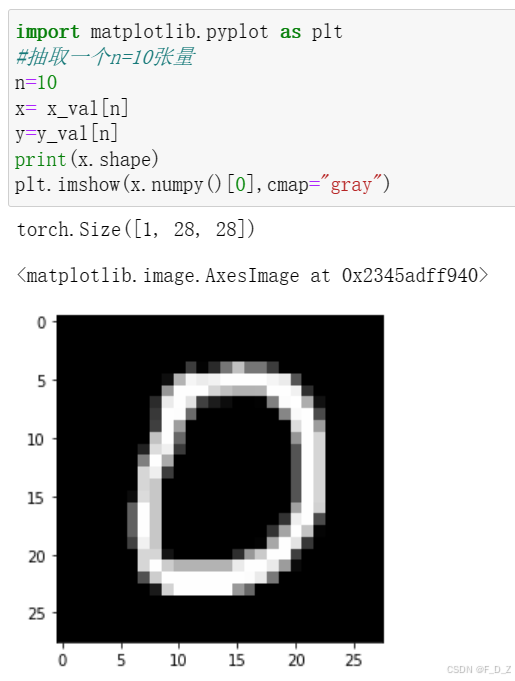
對張量進行預處理
#將維度擴展為 1*C*H*W
x= x.unsqueeze(0)
#轉換為torch.float32格式
x=x.type(torch.float)得到模型預測?
#獲取模型輸出
output=_model(x)
#獲取預測結果
pred = output.argmax(dim=1, keepdim=True)
print (pred.item(),y.item())?








)

![[論文閱讀] 人工智能 + 軟件工程 | 微信閉源代碼庫中的RAG代碼補全:揭秘工業級場景下的檢索增強生成技術](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | 微信閉源代碼庫中的RAG代碼補全:揭秘工業級場景下的檢索增強生成技術)

![[2025CVPR-目標檢測方向] CorrBEV:多視圖3D物體檢測](http://pic.xiahunao.cn/[2025CVPR-目標檢測方向] CorrBEV:多視圖3D物體檢測)





)
