微信閉源代碼庫中的RAG代碼補全:揭秘工業級場景下的檢索增強生成技術
論文標題:A Deep Dive into Retrieval-Augmented Generation for Code Completion: Experience on WeChat
arXiv:2507.18515
A Deep Dive into Retrieval-Augmented Generation for Code Completion: Experience on WeChat
Zezhou Yang, Ting Peng, Cuiyun Gao, Chaozheng Wang, Hailiang Huang, Yuetang Deng
Comments: Accepted in ICSME 25 Industry Track
Subjects: Software Engineering (cs.SE)
一段話總結:本文對檢索增強生成(RAG)在閉源代碼庫的代碼補全中應用進行了系統研究,以微信的工業級閉源代碼庫(含1669個內部倉庫)為研究對象,構建了包含100個示例的評估基準,評估了26個參數從0.5B到671B的開源大語言模型(LLMs)。研究比較了標識符基RAG和相似性基RAG兩種方法,發現兩者在閉源代碼補全中均有效,其中相似性基RAG表現更優;BM25(詞匯檢索) 和GTE-Qwen(語義檢索) 在相似性基RAG中性能突出,且兩者結合能產生最優結果。此外,開發者調查驗證了這些發現的實際價值。
研究背景:代碼補全的“閉源困境”與RAG的破局可能
想象一下,你是一家大型科技公司的程序員,每天要在公司內部的專有代碼庫里寫代碼。這些代碼里滿是公司獨有的框架、業務邏輯和命名規則——就像只有內部員工才懂的“暗語”。這時候,你打開常用的代碼補全工具,卻發現它經常“說外行話”:要么推薦的代碼風格和公司規范格格不入,要么根本看不懂那些自定義的函數和類。
這就是閉源代碼庫面臨的現實問題。
代碼補全作為提升開發效率的“利器”,早已被證明能讓87%的專業開發者效率大增。近年來,大語言模型(LLMs)的爆發讓代碼補全能力突飛猛進,但這些模型大多是在開源代碼庫(如GitHub)上訓練的。而閉源代碼庫(如微信的內部代碼)有太多“私有信息”:自定義框架、專有業務邏輯、特殊編碼習慣,和開源代碼的“畫風”差異很大。
這就好比用學了公開教材的學生去解公司內部考題——不是能力不夠,是“水土不服”。
而檢索增強生成(RAG)技術的出現,給了破局的可能。簡單說,RAG就像給LLMs配了一個“專屬搜索引擎”:在生成代碼時,先從目標代碼庫里檢索相關的代碼片段或定義,再結合這些“上下文”生成更貼合的結果,而且不需要重新訓練模型(保護隱私,還省資源)。
但問題是:RAG在開源場景里表現不錯,在閉源場景還能用嗎?哪種RAG方法更有效?不同的“檢索方式”(比如按關鍵詞找還是按語義找)搭配起來會不會更好?這正是這篇論文要解決的問題——以微信的工業級閉源代碼庫為研究對象,一探究竟。
主要作者及單位信息
- Zezhou Yang,騰訊(廣州,中國)
- Ting Peng,騰訊(廣州,中國)
- Cuiyun Gao*(通訊作者),香港中文大學(香港,中國)
- Chaozheng Wang,香港中文大學(香港,中國)
- Hailiang Huang,騰訊(廣州,中國)
- Yuetang Deng,騰訊(廣州,中國)
創新點:這篇論文的“獨特價值”在哪里?
在RAG和代碼補全的研究熱潮中,這篇論文的創新之處尤為突出:
-
首次聚焦閉源代碼庫的系統研究:此前研究多基于開源代碼庫,而本文是首個在工業級閉源代碼庫(微信,1669個內部倉庫)中,系統評估RAG用于代碼補全的研究,填補了“閉源場景”的空白。
-
解決C++閉源項目的“數據預處理難題”:C++項目有很多“坑”——頭文件依賴復雜、自動生成代碼冗余、宏定義特殊等,論文提出了一套細粒度的預處理算法,能精準提取有效代碼片段(如函數、類定義),解決了這些工業界實際問題。
-
發現詞匯與語義檢索的“互補密碼”:通過實驗發現,基于關鍵詞的詞匯檢索(如BM25)和基于意義的語義檢索(如GTE-Qwen)結果重疊極少,結合使用能大幅提升效果,這為工業界提供了明確的技術組合方案。
-
用開發者調查驗證“實際價值”:不僅有實驗數據,還通過3位資深開發者的調查,驗證了技術在真實開發場景中的有效性,讓研究結論更具落地意義。
研究方法和思路:一步步拆解“微信閉源代碼補全實驗”
為了搞清楚RAG在閉源場景的表現,研究團隊做了一套“組合拳”實驗,步驟清晰可復制:
第一步:搭好“考場”——構建評估基準
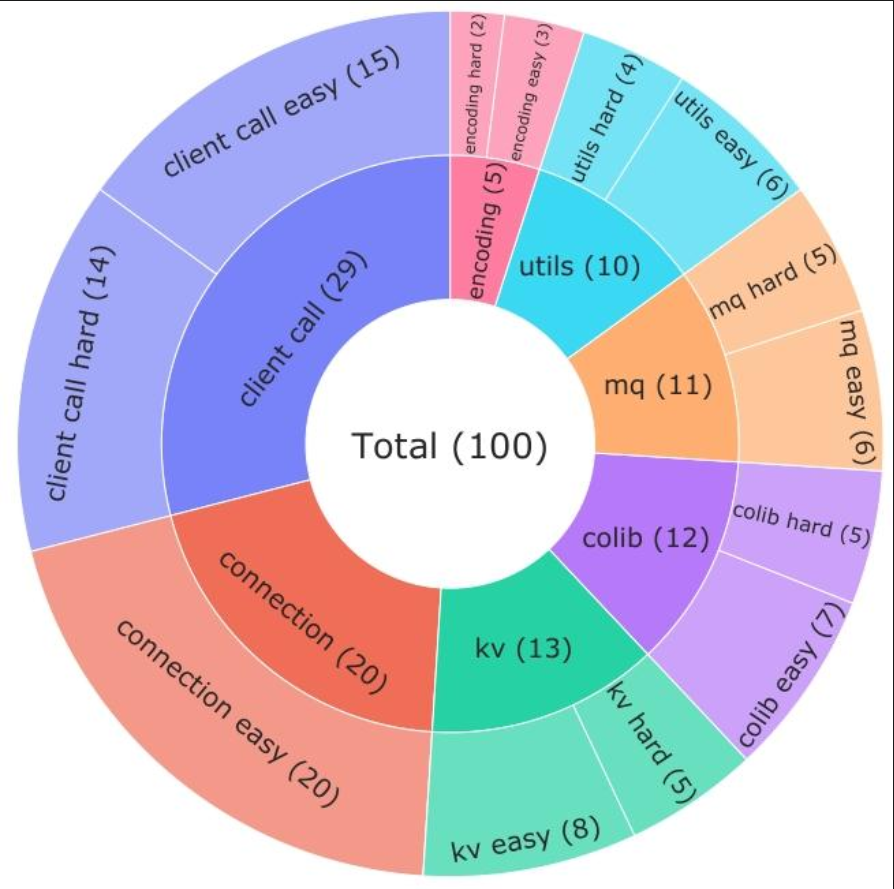
- 從微信7個核心業務領域(如遠程調用、消息隊列、工具函數等)中,精選100個真實開發場景的函數作為“考題”。
- 每個“考題”都由3位5年以上經驗的開發者手動標注:相關上下文、難度(簡單/困難),確保貼合實際開發需求。
第二步:備好“參考書”——構建檢索語料
- 收集微信1669個內部項目作為“參考書庫”,涵蓋不同業務和開發周期。
- 重點解決C++項目的4大難題:
- 文件分割:C++頭文件內容多,直接用整個文件做檢索單位太冗余,所以拆成函數、類定義等細粒度片段。
- 遞歸依賴:頭文件互相引用像“連環套”,通過遞歸處理所有依賴,避免漏信息。
- 自動生成代碼:protobuf生成的代碼沒用,直接從原始proto文件提取消息定義。
- 宏定義:把C++的宏轉換成類似函數的結構,方便檢索和理解。
第三步:測試兩種“解題思路”——實現RAG方法
- 標識符基RAG:就像查“名詞解釋”。比如代碼里出現一個陌生函數
sendMsg,就去檢索它的定義、參數、用法,讓LLMs看懂這個“暗語”再補全。 - 相似性基RAG:就像查“例題”。比如要補全一個消息隊列相關的函數,就去搜代碼庫里類似功能的函數片段,讓LLMs參考“例題”寫代碼。
第四步:用“不同學生”測試——選擇26個LLMs
- 涵蓋從0.5B到671B參數的26個開源模型,既有代碼專用模型(如Qwen-Coder、CodeLlama),也有通用模型(如Llama-3.3),全面測試RAG的適配性。
第五步:比較“不同檢索工具”——測試5種檢索技術
- 詞匯檢索:用BM25(類似關鍵詞搜索,看代碼里的詞匹配度)。
- 語義檢索:用CodeBERT、UniXcoder、CoCoSoDa、GTE-Qwen(類似“理解意思”搜索,看代碼語義相似性)。
第六步:打分標準——評估指標
- 用CodeBLEU(看代碼結構和語義相似度)和Edit Similarity(看最少改多少字符能匹配正確代碼)給補全結果打分。
主要貢獻:這些發現對工業界有多重要?
這篇論文的成果可不是“實驗室游戲”,而是能直接指導企業提升開發效率的“干貨”:
-
閉源場景下RAG真的有用:兩種RAG方法都能讓代碼補全效果提升,比如DeepSeek-V3模型用GTE-Qwen檢索后,代碼相似度指標(CodeBLEU)提升71.1%,編輯相似度提升33.3%。這意味著企業不用從頭訓練模型,用開源LLM加內部代碼庫就能提升補全效果。
-
相似性基RAG更勝一籌:比起查“名詞解釋”的標識符基RAG,查“例題”的相似性基RAG效果更好。比如Qwen2.5-Coder-1.5B用相似性基RAG,效果比標識符基高25%以上。
-
最佳“檢索組合”出爐:
- 詞匯檢索(BM25)表現穩定,不管模型大小都好用。
- 語義檢索(尤其是GTE-Qwen)在模型夠強時效果驚艷,而且特別擅長處理“不完整查詢”(比如只寫了一半的代碼)。
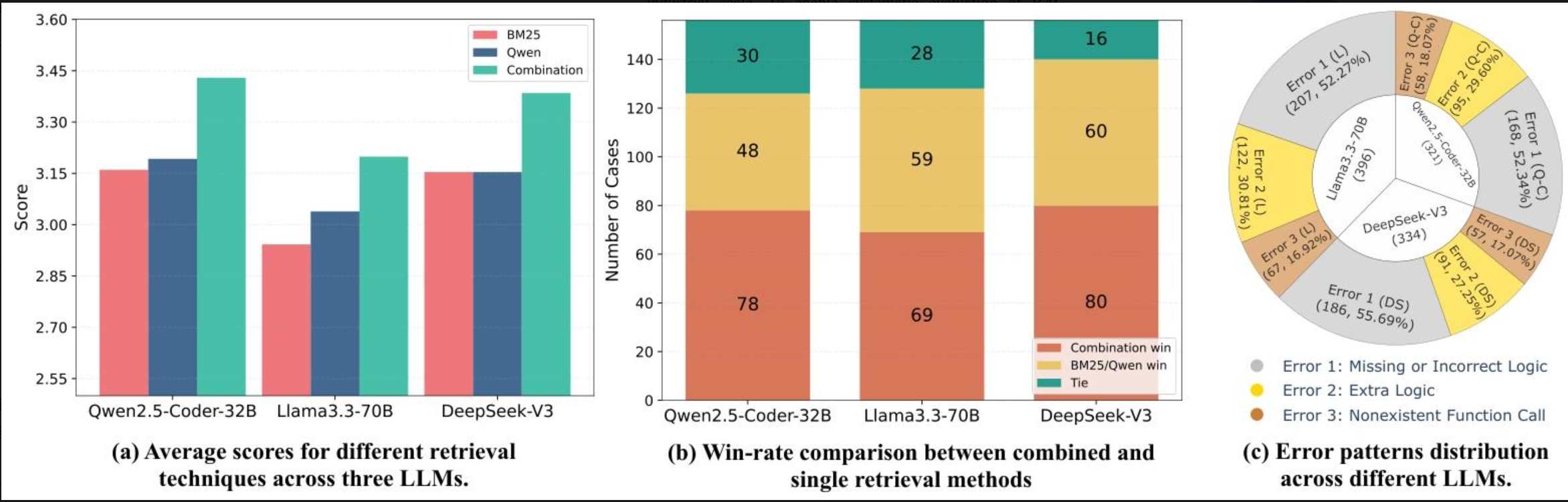
- 把BM25和GTE-Qwen結合,效果最佳(像同時用關鍵詞和語義搜資料,覆蓋更全)。比如DeepSeek-V3用這個組合,指標比單獨用提升5%~10%。
-
保護隱私還省錢:用開源LLM加RAG,不用把內部代碼給模型訓練,既保護了閉源代碼的隱私,又避免了訓練大模型的高額成本。
詳細總結:
一、研究背景與目的
- 代碼補全的重要性:代碼補全能自動預測代碼片段,顯著提升開發者效率,87%的專業開發者在工業環境中受益。
- RAG的作用:檢索增強生成(RAG)通過檢索目標代碼庫的相關上下文增強LLMs性能,無需參數更新,適用于閉源代碼庫(保護隱私、適應特定編碼風格)。
- 研究缺口:現有研究多基于開源代碼庫,閉源代碼庫因專有模式等特點存在挑戰,需系統研究RAG在閉源場景的表現。
- 研究對象:微信的閉源代碼庫(1669個內部倉庫),構建包含100個示例(7個領域)的評估基準。
二、研究方法與實驗設置
1. 數據預處理與語料構建
- 挑戰:C++項目的文件分割、遞歸依賴、自動生成代碼、宏定義等問題。
- 解決方案:提出細粒度算法,提取函數/類定義、處理遞歸依賴、轉換宏為函數結構等。
2. RAG方法
| RAG類型 | 核心思路 | 關鍵步驟 |
|---|---|---|
| 標識符基RAG | 檢索標識符的定義幫助LLMs理解邏輯 | 構建索引→提取需檢索的標識符→構建提示詞補全代碼 |
| 相似性基RAG | 提供相似代碼片段輔助補全 | 構建索引(詞匯/語義)→檢索相似代碼→構建提示詞補全代碼 |
3. 實驗細節
- LLMs:26個開源模型(0.5B-671B參數),包括代碼專用(如Qwen-Coder)和通用模型(如Llama-3.3)。
- 檢索技術:詞匯檢索(BM25)、語義檢索(CodeBERT、GTE-Qwen等)。
- 評估指標:CodeBLEU(CB,考慮代碼結構和語義)、Edit Similarity(ES,衡量編輯距離)。
三、實驗結果與分析
1. RQ1:不同RAG方法的表現
- 兩種RAG均優于基礎模型,相似性基RAG表現更優。例如,DeepSeek-V3用GTE-Qwen檢索后,CB提升71.1%,ES提升33.3%。
- 標識符基RAG中,函數定義檢索效果最佳;相似性基RAG中,BM25和GTE-Qwen表現突出。
2. RQ2:檢索技術對相似性基RAG的影響
- 詞匯檢索(BM25)在各模型中表現穩定;語義檢索效果隨模型能力提升。
- 多數技術在完整查詢中更優,但GTE-Qwen在不完整查詢(代碼補全場景)中更優。
3. RQ3:不同檢索技術的關系
- 詞匯與語義檢索結果重疊少(如BM25與GTE-Qwen在100個示例中64個完全不同),互補性強。
- 結合后效果更佳,如DeepSeek-V3用BM25+GTE-Qwen,CB達63.62,ES達75.26,優于單獨使用。
四、開發者調查與研究貢獻
- 開發者調查:BM25+GTE-Qwen的組合評分最高,約半數案例中優于單獨技術;主要錯誤為邏輯缺失或錯誤(52%)。
- 貢獻:系統研究閉源場景RAG、提出細粒度語料構建算法、驗證檢索技術互補性、開發者調查驗證實際價值。
-
關鍵問題:
-
問題:在閉源代碼補全中,標識符基RAG和相似性基RAG的核心區別是什么,哪種更有效?
答案:標識符基RAG通過檢索標識符(如函數、類)的相關定義幫助LLMs理解其邏輯和用法;相似性基RAG則檢索與當前代碼相似的實現(通過詞匯或語義技術)。實驗表明,兩種方法均有效,但相似性基RAG表現更優,例如DeepSeek-V3使用相似性基RAG(GTE-Qwen)時,CodeBLEU和Edit Similarity分別比標識符基RAG提升約42.7%和18.4%。 -
問題:不同檢索技術對相似性基RAG的影響有何差異,哪種技術更適合代碼補全場景?
答案:詞匯檢索(如BM25)在不同模型和查詢類型中表現穩定;語義檢索(如GTE-Qwen)的效果隨模型能力提升。多數技術在完整代碼片段查詢中更優,但GTE-Qwen在不完整查詢(代碼補全的典型場景)中表現最佳,例如在DeepSeek-V3中,其CodeBLEU達60.28,顯著高于其他語義檢索技術。 -
問題:詞匯檢索(如BM25)和語義檢索(如GTE-Qwen)為何能通過結合提升代碼補全效果?
答案:兩者檢索結果重疊極少(如在100個示例中,BM25與GTE-Qwen有64個完全不同的結果),說明它們捕獲代碼相似性的不同方面(詞匯層面vs語義層面),具有互補性。結合后能覆蓋更全面的信息,例如DeepSeek-V3使用BM25+GTE-Qwen時,CodeBLEU達63.62,高于單獨使用任一技術。
總結:閉源代碼補全,RAG這樣用才高效
這篇論文以微信的工業級閉源代碼庫為“試驗場”,系統回答了“RAG在閉源場景怎么用才有效”的問題:
- 解決的核心問題:填補了RAG在閉源代碼補全領域的研究空白,明確了不同方法和技術的效果。
- 關鍵結論:相似性基RAG優于標識符基,BM25(詞匯)和GTE-Qwen(語義)結合是“最優解”,且效果能被開發者實際感知(調查驗證)。
- 價值:為企業提供了一套低成本、高隱私的代碼補全優化方案——用開源LLM+內部代碼庫+RAG,就能讓代碼補全更懂“公司方言”。

![[2025CVPR-目標檢測方向] CorrBEV:多視圖3D物體檢測](http://pic.xiahunao.cn/[2025CVPR-目標檢測方向] CorrBEV:多視圖3D物體檢測)





)





)





