本文主要講解C++語言的入門知識,包括命名空間、C++的輸入與輸出、缺省參數以及函數重載。
目錄
1? C++的第一個程序
2? 命名空間
1) 命名空間存在的意義
2) 命名空間的定義
3) 命名空間的使用
3? C++的輸出與輸入
1) C++中的輸出
?2) C++中的輸入
4? 缺省參數
1) 缺省參數的定義
2) 缺省參數的使用
5? 函數重載
1) 函數重載所解決的問題
2) 函數重載的條件
6? 總結
1? C++的第一個程序
? ? ? ? C++語言是兼容C語言的,所以C語言的程序在C++語言的程序中依然適用,比如輸出"hello world":
#include<stdio.h>int main()
{printf("hello world\n");return 0;
}所以用C語言定義的文件只需要將后綴由 .c 變為?.cpp,那么這個文件就會由C語言變到了C++語言。雖然在C++文件中,C語言也可以兼容,但是C++語言有自己的一套輸入輸出。在C++語言中,輸出"hello world"應該這樣輸出:
#include<iostream>using namespace std;int main()
{cout << "hello world" << endl;return 0;
}相信大家一上來學習C++語言,肯定是看不懂這段代碼的,接下來我們依次來講解。
2? 命名空間
1) 命名空間存在的意義
? ? ? ? 在 C 語言中,函數都是存在全局域的,然后如果在全局再定義一個同名變量,那么其是會發生命名沖突的,進而就會報錯。如:
#include<stdio.h>
#include<stdlib.h>int rand = 10;int main()
{//編譯報錯:"rand"重定義printf("%d\n", rand);return 0;
}在上面的程序中,首先包含了一個 stdlib.h 頭文件,然后頭文件里有一個 rand() 函數,包含了之后會將頭文件的內容全部展開在全局域里面,之后又在全局定義了一個全局變量 rand,此時全局域有一個 rand() 函數,又有一個 rand 變量,此時就發生了命名沖突,printf 函數里面的 rand 不知道是全局變量還是函數,所以是會編譯報錯的。
? ? ? ? C++ 中為了解決命名沖突的問題,引入了一個命名空間的概念,命名空間上本質是定義出了一個獨立的命名空間域,此域與全局域和局部域相互獨立,不同域里面是可以定義相同名字的變量和函數的,此時就不會發生命名沖突了。
2) 命名空間的定義
? ? ? ? 定義一個命名空間需要一個關鍵字 namespace,定義命名空間如下:
namespace 命名空間名
{}首先加一個命名空間關鍵字 namespace,然后在后面加上想要定義的名字,后面跟一對{},然后就可以在里面定義函數或者變量了,如在 L 命名空間里定義一個 rand 變量:
namespace L
{int rand = 10;
}命名空間存在的本質就是為了產生一個新的域,使其與全局域和局部域進行區分。此時 rand 變量就會存在在 L 命名空間里面,那么就不會與全局域中的 rand() 函數起沖突了,所以以下代碼是可以編譯通過的:
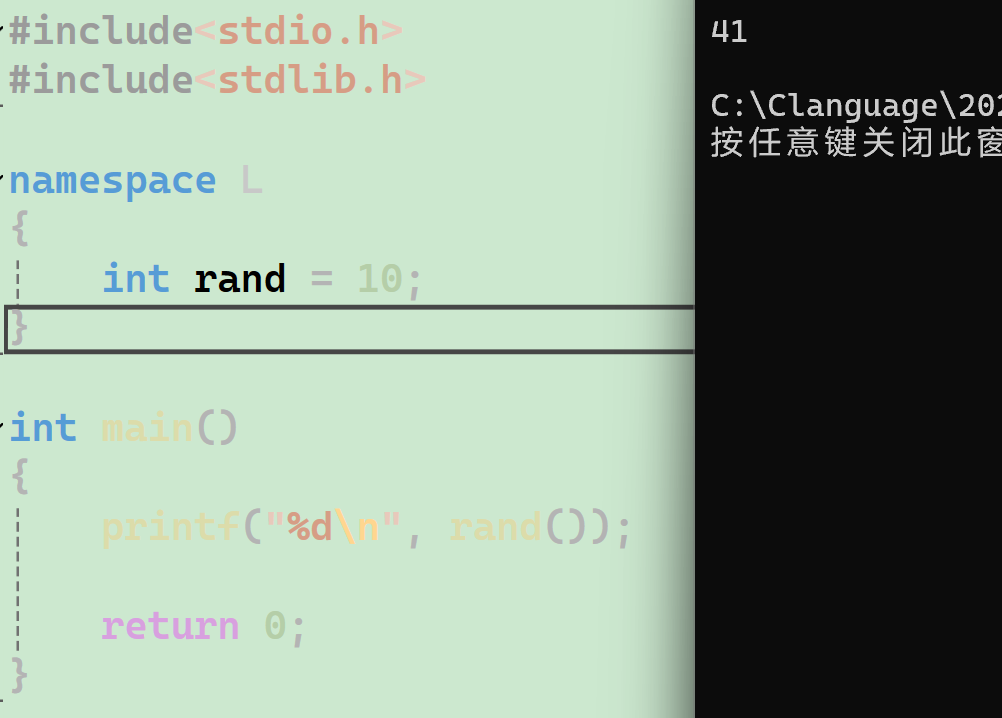
#include<stdio.h>
#include<stdlib.h>namespace L
{int rand = 10;
}int main()
{printf("%d\n", rand());return 0;
}運行結果:
定義命名空間時,需要有幾個注意事項:
(1) C++中共有4個域:全局域、局部域、命名空間域、類域。域影響的是一個變量或者函數的查找規則(在C語言中默認現在局部域查找,局部域查找不到,再去全局域查找),所以命名就不會沖突了。但是全局域和局部域還會影響變量的生命周期(局部域里的變量出了函數就銷毀了),命名空間域和類域不會影響生命周期。
(2) namespace 只能定義在全局,也可以嵌套定義。
(3) C++ 標準庫都放在一個名叫 std 的命名空間中。
(4) 如果想要訪問命名空間中的變量或者函數,需要一個操作符? ::(域訪問限定符)。
(5)?不同文件的相同命名空間里的變量和函數會合并到一個命名空間中。
(4) 域訪問限定符:?
#include<stdio.h>
#include<stdlib.h>namespace L
{int rand = 10;int Add(int x, int y){return x + y;}struct Node{struct Node* next;int data;};
}int main()
{printf("%d\n", rand());//突破命名空間域訪問,需要加::printf("%d\n", L::rand);printf("%d\n", L::Add(1, 2));//訪問命名空間域中的類型是在名字前面加上::,而不是在類型前加上::struct L::Node* node = (struct L::Node*)malloc(sizeof(struct L::Node));return 0;
}如果在 namespace 里面有自定義類型的話,是需要在名字前面加上 :: 的,而不是在 struct 前加 :: 的,因為命名空間限定的是名字,并不是類型(其實這里的Node就可以是類型了,只不過這里不叫結構體了,而是類,在類與對象章節會進行講解)。
(2)? ?namespace 只能定義在全局,且可以嵌套定義
#include<stdio.h>
#include<stdlib.h>//命名空間可以嵌套定義
namespace L
{namespace T{int rand = 1;int Add(int x, int y){return x + y;}}
}int main()
{//訪問的時候要依次突破命名空間域printf("%d\n", L::T::rand);printf("%d\n", L::T::Add(1, 2));return 0;
}3) 命名空間的使用
命名空間的使用共有三種方式:
a. 直接展開所有命名空間,需要使用 using?關鍵字,如:using namespace std。
b. 只將命名空間中的某個成員展開,也需要使用 using 關鍵字,比如展開 L 命名空間中的 rand 變量:using L::rand。
c. 指定命名空間訪問,如使用 L 中的 rand 變量,L::rand。
當然,3種使用方式有好有壞,?平常練習的時候可以使用第一種方式,在項目中不推薦使用第一種方式,因為展開的所有的命名空間,就相當于將命名空間中的所有函數與變量暴露在全局,所以是非常容易出現命名沖突的;對于第二種方式,項目中經常訪問的不存在沖突的成員推薦使用這種方式;在項目中最推薦使用的就是第三種方式了,第三種方式是最不會出現命名沖突的。
#include<stdio.h>namespace L
{int a = 0;int b = 10;
}void Test01()
{//指定命名空間訪問printf("%d\n", L::a);
}//展開某個命名空間成員
using L::a;
void Test02()
{printf("%d\n", a);
}//展開所有命名空間
using namespace L;
void Test03()
{printf("%d\n", b);
}int main()
{Test01();Test02();Test03();return 0;
}在上面那段代碼里面,首先展開了 L 中的 a 成員,在后面又展開了 L 整個命名空間,這樣看來,應該引入了兩次 a 變量,是會發生命名沖突的,但是編譯器是會對這種情況做特殊處理的,對于重復引入同一個變量的情況,是不會報錯的。
3? C++的輸出與輸入
在講解C++的輸入與輸出之前,我們先來簡單了解一下 iostream 庫以及 endl 函數。
iostream庫:
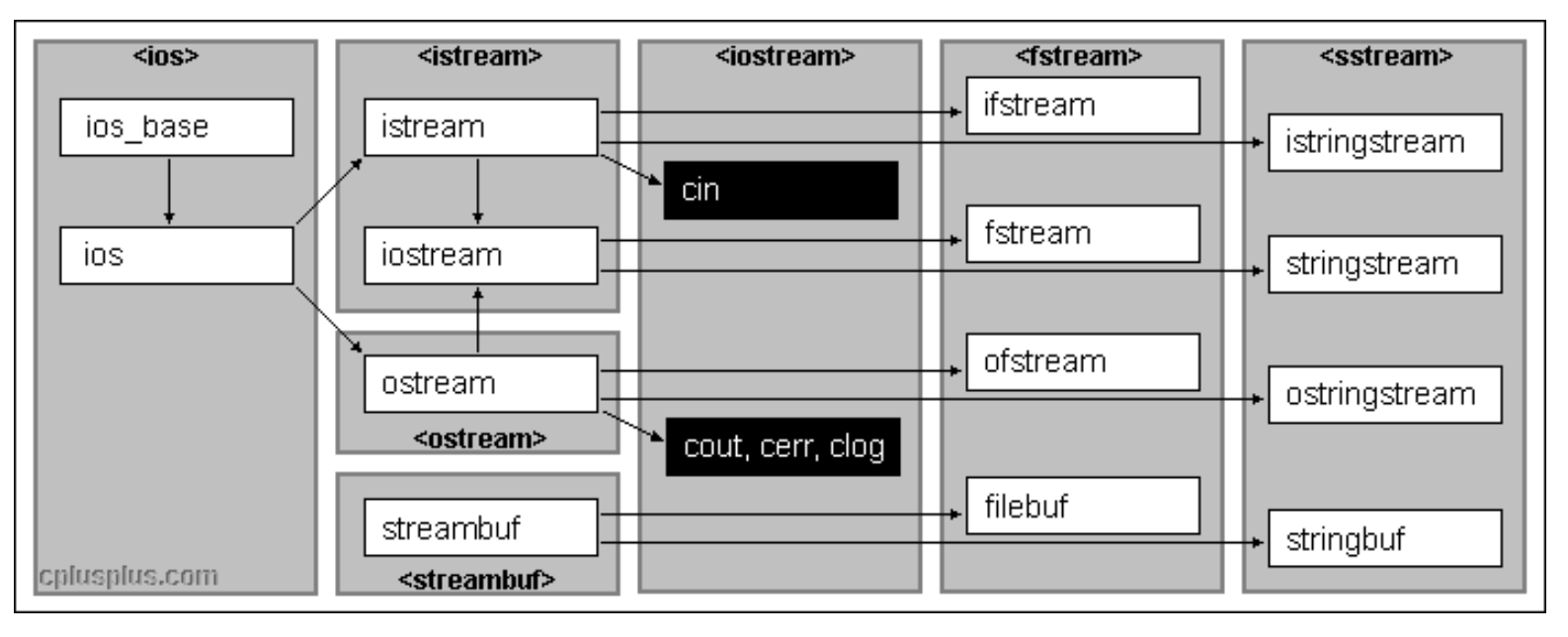
iostream 是Input Output Stream(標準輸入輸出流庫)的縮寫,其中涉及了許多知識,包括繼承等等,不過現在我們只需要了解 cin 和 cout 即可。
? ? ? ? 通過上圖,我們可以看到 iostream 中包含 cin、cout、cerr、clog,cin 來源于 isream,cout 來源于 ostream(其實 istream 和 ostream 是C++標準庫中定義的類,cin 和 cout 是這兩個類的對象),cin 主要用于輸入,cout 主要用于輸出。
endl 函數:
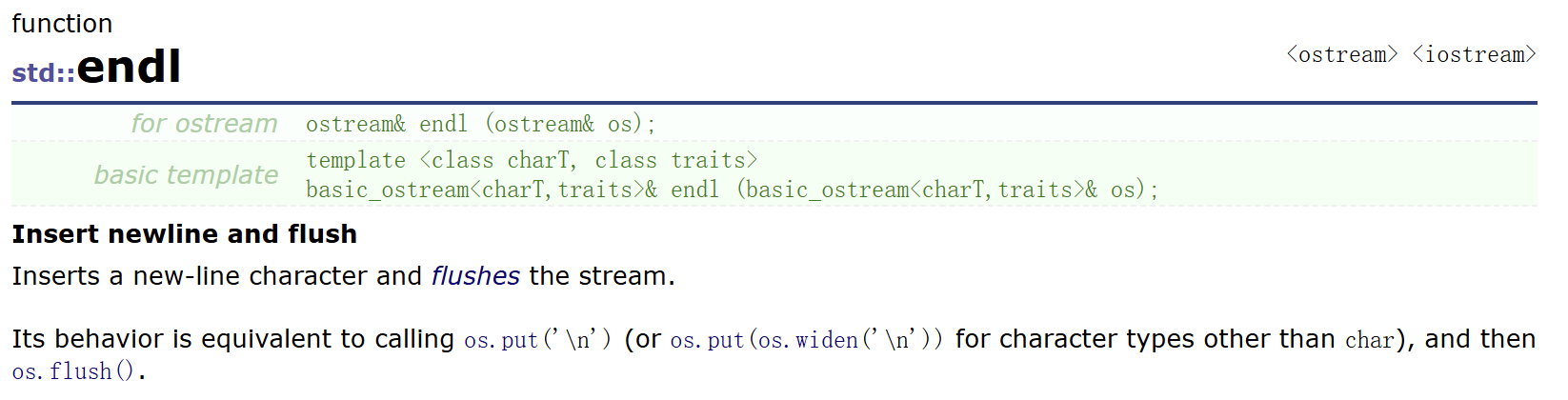
通過上圖可以看到,endl 其實是一個函數,其參數是一個 ostream類型對象,返回值也是一個 ostream 類型的引用(這里看不懂沒關系,等學完引用與類和對象后自然就懂了);再通過下面的解釋,可以看到其行為就等于調用了ostream類?os 對象的 put 函數,實際上就相當于輸出了一個 '\n' 字符,也就是執行了一個換行。所以在C++中如果想要換行,我們一般不會使用 '\n' 轉義字符,而會使用 endl 函數來執行換行操作。
1) C++中的輸出
? ? ? ? 在上面了解了 iostream 庫與 endl 之后,我們知道了輸出需要用到一個 ostream 類的對象 cout,所以在使用 cout 之前,我們需要先包含一個頭文件 iostream,也就是引入 iostream 這個類,使得我們可以使用這個類實例化的一個對象 cout。在輸出之前,我們還需要了解一個運算符叫做流插入運算符:<<。這個運算符的作用可以形象化的理解為會將要輸出的對象流入 cout 中,然后 cout 幫你把對象打印在屏幕上。比如輸出完 "hello world" 之后打印一個換行:
#include<iostream>using namespace std;int main()
{cout << "hello world";cout << endl;return 0;
}這里有一個需要注意的點,就是C++中的標準庫都被封在了 std 的命名空間里面,要想使用C++中類和對象是需要展開命名空間 std 的,當然你也可以指定命名空間訪問或者展開具體成員:
#include<iostream>//指定命名空間
int main()
{std::cout << "hello world";std::cout << std::endl;return 0;
}//展開具體成員
using std::cout;
using std::endl;
int main()
{cout << "hello world";cout << endl;return 0;
}? ? ? ? ? 但是C++中的 cout 與C語言中的 printf 最大的區別,也是我認為 cout 更加好用的一點是:cout 不用指定占位符,且可以連續輸出不同的類型的對象(本質是函數重載,后面講解完函數重載會更好理解)。如:
#include<iostream>using namespace std;int main()
{int x = 1;double y = 2.2;char ch = 'x';cout << "hello world" << ' ' << x << ' ' << y << ' ' << ch << endl;return 0;
}運行結果:
hello world 1 2.2 x?2) C++中的輸入
? ? ? ? C++ 中的輸入需要用到 istream 類的對象 cin,同樣的在使用之間需要包含頭文件 iostream 與展開命名空間 std、指定命名空間或者展開具體成員。與 cout 類似,在使用 cin 時,需要用到流提取操作符:>>,這個運算符可以形象化的理解為將屏幕中輸入的值先交給 cin,cin 再通過 >> 將數據流入變量中,所以這里不需要對變量取地址的。同樣,cin 也支持連續輸入,如:
#include<iostream>using namespace std;int main()
{int x;double y;char ch;cin >> x >> y >> ch;cout << x << ' ' << y << ' ' << ch << endl;return 0;
} 運行結果:
輸入:1 2.2 x
輸出:1 2.2 x? ? ? ? cin 還可與 scanf 函數一樣判斷是否輸入結束,但是 scanf 是通過返回值來判斷的,如果讀取成功,會返回讀取成功的占位符個數,如果讀取失敗會返回 EOF,而 cin 是通過一個 operator bool() 的重載函數來實現的(這里可能難以理解,等后面仔細講解完 iostream 類之后會比較容易理解),用法就是當讀取成功時會返回 true,讀取失敗會返回 false。如:
#include<iostream>using namespace std;int main()
{int x = 0;while (cin >> x){cout << x << ' ';}return 0;
}運行結果:
輸入:1 2 3 4 ctrl + z
輸出:1 2 3 44? 缺省參數
1) 缺省參數的定義
? ? ? ? 缺省參數也叫做默認參數,是在定義或者聲明的時候給的參數的默認值。如果在調用參數的時候,不傳遞實參的話,就會默認使用缺省值,如果傳遞實參的話,就會使用傳遞的實參。
? ? ? ? 缺省參數分為全缺省與半缺省參數。全缺省就是所有的形參都給缺省值,半缺省就是部分形參給缺省值。
2) 缺省參數的使用
在參數中給默認參數的時候,需要遵循以下語法規則:
(1) 缺省參數必須從右向左連續缺省,不能跳躍給缺省值。
(2) 調用帶缺省參數的函數,必須從左向右依次給實參,不能跳躍傳參。
(3) 函數聲明與定義分離時,只能在聲明給缺省值,不能在定義給缺省值。
全缺省與半缺省:?
#include<iostream>using namespace std;//缺省參數只能從右向左連續缺省
//半缺省
void Func1(int a, int b = 10, int c = 20)
{cout << a << ' ' << b << ' ' << c << endl;
}//全缺省
void Func2(int a = 10, int b = 20, int c = 30)
{cout << a << ' ' << b << ' ' << c << endl;
}int main()
{//不傳參時默認使用缺省值Func1(10);Func2();//傳參只能由左向右依次傳參,不能跳躍傳參//錯誤的//Func1(10, , 20);//正確的Func1(10, 20);return 0;
}運行結果:
輸出:
10 10 20
10 20 30
10 20 20
?聲明與定義分離,只能在聲明時給缺省值:
#include<iostream>using namespace std;//只能在聲明時給缺省值
void Func(int a = 10, int b = 20, int c = 30);//定義不能給
void Func(int a, int b, int c)
{cout << a << ' ' << b << ' ' << c << endl;
} int main()
{ Func();return 0;
}運行結果:
輸出:10 20 305? 函數重載
? ? ? ? 函數重載是C++語言中一個特別重要的語法,在以后的講解的類和對象以及STL中經常使用。
1) 函數重載所解決的問題
? ? ? ? 在 C語言中,同一作用域里是不能定義同名函數的,如要實現交換函數:
#include<stdio.h>void swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}void swap(double* x, double* y)
{double tmp = *x;*x = *y;*y = tmp;
}int main()
{int x = 10, y = 20;swap(&x, &y);double a = 1.1, double b = 2.2;swap(&a, &b);return 0;
}這種情況在C語言里是會報錯的,但是在C++里面就不會報錯了,函數重載就是為了解決同名函數的問題。
2) 函數重載的條件
? ? ? ? 兩個函數如果想要構成函數重載,只需要一個條件,那就是兩個函數參數不同,可以是參數個數不同或者類型不同。如:
#include<iostream>using namespace std;//1. 函數參數類型不同構成函數重載
int Add(int x, int y)
{cout << "Add(int x, int y)" << endl;return x + y;
}double Add(double x, double y)
{cout << "Add(double x, double y)" << endl;return x + y;
}//2. 函數參數個數不同構成函數重載
int Add(int x, int y, int z)
{cout << "Add(int x, int y, int z)" << endl;return x + y + z;
}//3. 函數參數類型順序不同構成函數重載
void func(int x, double y)
{cout << "func(int x, double y)" << endl;
}void func(double x, int y)
{cout << "func(double x, int y)" << endl;
}int main()
{cout << Add(1, 2) << endl;cout << Add(1.1, 2.2) << endl;cout << Add(1, 2, 3) << endl;func(1, 2.2);func(2.2, 1);return 0;
}運行結果:
輸出:
Add(int x, int y)
3
Add(double x, double y)
3.3
Add(int x, int y, int z)
6
func(int x, double y)
func(double x, int y)? ? ? ? 函數重載,之所以能夠構成函數重載,本質原因就是因為編譯器能夠通過參數去調用對應的函數,因而表現出了多態行為,所以不會因為命名相同而發生調用沖突。所以返回值不同是不構成函數重載的,因為編譯器不知道去調用哪個函數:
#include<iostream>using namespace std;//函數返回值不同不構成函數重載
void func()
{cout << "void func()" << endl;
}int func()
{cout << "int func()" << endl;
}int main()
{//編譯器不知道去調用哪個函數func();return 0;
}?有了函數重載的相關知識,大家看下面這兩個函數構不構成函數重載呢?
#include<iostream>using namespace std;void func()
{cout << "func()" << endl;
}void func(int a = 10)
{cout << "func(int a = 10)" << endl;
}int main()
{func(1);func();return 0;
}其實是構成函數重載的,因為兩個 func 的參數個數不同,也就是參數不同,所以是可以構成函數重載的。但是有一個致命的缺陷,就是如果調用的是無參版本的 func 函數,編譯器就會不知道去調用哪一個,因而會發生報錯,這里的報錯并不是因為函數重載的語法錯誤,而是因為編譯器不知道去調用哪一個函數。
? ? ? ? 但是遇到這種情況,我們一般都會選擇使用下面有缺省值的版本,因為寫上面那個函數,就是為了無參也能調用函數,而下面那個函數因為有缺省值,所以無參也是可以調用的,而且還有缺省值,所以會選擇下面的版本。
6? 總結
? ? ? ? 以上我們講解了C++中的一些基礎的語法知識,雖然不是很難,但是是后面學習類和對象以及STL的基礎,所以一定要認真學習,熟練掌握。當然我們也會結合后面具體的使用場景來繼續加深對這些語法知識的理解。
)

![[論文閱讀] 人工智能 + 軟件工程 | 微信閉源代碼庫中的RAG代碼補全:揭秘工業級場景下的檢索增強生成技術](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | 微信閉源代碼庫中的RAG代碼補全:揭秘工業級場景下的檢索增強生成技術)

![[2025CVPR-目標檢測方向] CorrBEV:多視圖3D物體檢測](http://pic.xiahunao.cn/[2025CVPR-目標檢測方向] CorrBEV:多視圖3D物體檢測)





)





)


