1. ?研究背景與動機?
論文關注自動駕駛中相機僅有的多視圖3D物體檢測(camera-only multi-view 3D object detection)問題。盡管基于鳥瞰圖(BEV)的建模近年來取得顯著進展(如BEVFormer和SparseBEV等基準模型),但當前研究主要優化整體平均性能(如nuScenes數據集中的NDS和mAP指標),卻忽視了關鍵角落案例(corner cases)。其中,遮擋(occlusion)是一個關鍵挑戰:部分被遮擋的物體(如行人)在檢測中特征質量下降,導致漏檢或誤檢,這對自動駕駛安全構成嚴重威脅(例如,未能檢測到部分被遮擋的行人可能導致事故)。
論文的靈感源自人類感知系統(amodal perception)。人類能基于先驗知識(如物體類別和形狀)重構被遮擋物體的完整語義概念。類似地,論文提出通過引入視覺和語言原型作為先驗知識,來補償遮擋導致的特征損失。視覺原型基于2D圖像模板(裁剪自訓練數據),語言原型則來自類別名稱(如"pedestrian")的語義嵌入。這些原型通過相關學習(correlation learning)與基準模型融合,提升特征質量。
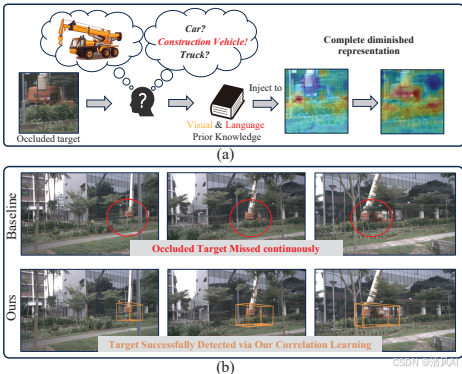
?
Figure 1直觀展示了這一動機:(a)部分說明在真實駕駛場景中,注入視覺和語言原型可以補全被遮擋物體的特征;(b)對比基準模型(如SparseBEV)與CorrBEV在檢測被遮擋物體上的差異,強調原型知識的增強作用。值得注意的是,該方法雖然針對遮擋設計,但實驗表明它也提升了其他挑戰場景(如惡劣天氣)的魯棒性。
2. ?方法細節:CorrBEV框架?
CorrBEV是一個即插即用(plug-and-play)框架,可無縫集成到現有多視圖3D檢測基準模型中(如BEVFormer和SparseBEV)。它包含三個核心組件,均通過高效的相關學習實現知識融合。
-
?Multi-modal Prototype Generator(多模態原型生成器)??:
該組件生成視覺和語言原型作為先驗知識。視覺原型基于訓練數據中的2D標注框裁剪圖像,使用預訓練模型DeViT提取特征嵌入(Pv?∈RK×N×D),并按可見性級別(visibility level)和類別聚類,形成遮擋感知的原型(Pvo?∈R(N×M)×D,N=10類別,M=4可見性級別)。語言原型則通過預訓練BERT模型將類別名稱(如"pedestrian")轉化為嵌入(Pl?∈RN×D)。文本編碼器在訓練中微調,而視覺原型離線生成以減少計算開銷。最終,原型通過廣播(broadcasting)拼接為統一的多模態原型P∈R(N×M)×D。 -
?Correlation-guided Query Learner(相關引導查詢學習器)??:
該組件將多模態原型與基準模型的特征融合,采用Siamese對象跟蹤中的深度相關(depth-wise correlation)操作,確保高效性。具體包括:- ?深度相關操作?:將原型P與主干特征Fb?通過1×1卷積融合,生成相關特征Fcorr?(公式:Fcorr?=Conv1×1?(P,Fb?))。該操作增強目標相關特征并抑制背景噪聲。
- ?目標感知查詢初始化?:基于相關特征預測置信度圖Hvis?,從中提取top-k位置嵌入作為目標感知查詢Qt?,與基準的可學習查詢Qlearn?通過交叉注意力融合(公式:Q=CrossAttn(Qlearn?,Qt?,Qt?))。
- ?雙路徑混合采樣?:3D查詢通過投影點采樣特征,同時從主干特征Fb?和相關特征Fcorr?中采樣,減輕遮擋模糊性。
整體架構如圖Figure 2所示,強調原型注入提升遮擋物體的檢測質量。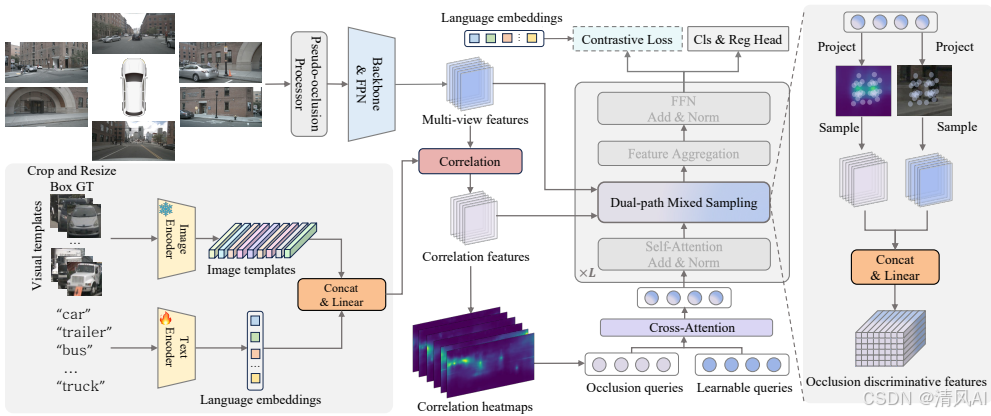
- ?Occlusion-aware Trainer(遮擋感知訓練器)??:
針對訓練不平衡(不同可見性級別的物體數量不均等),該組件優化訓練流程:- ?偽遮擋處理器(Pseudo-occlusion Processor, P2)??:在非遮擋物體(高可見性)的2D框內隨機丟棄像素(替換為區域均值),模擬遮擋以平衡數據分布。
- ?對比語義對齊(Contrastive Semantic Alignment)??:使用對比損失(contrastive loss)對齊視覺特征與語言原型,將同一類別的不同遮擋級別特征拉近到統一語義空間,增強分類準確性。
該訓練器引入零推理開銷,僅輕微增加訓練成本。
?
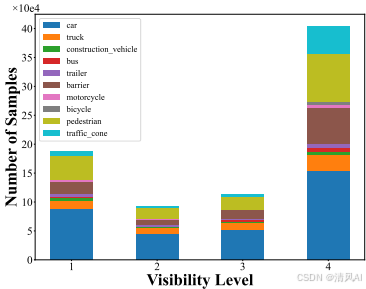
Figure 3展示了nuScenes數據集中不同可見性級別的分布,突出了遮擋級別(如Vis1: 0-40%可見性)的樣本稀缺性,解釋P2設計的必要性。?
3. ?實驗設計與結果?
論文在nuScenes數據集上進行實驗,驗證CorrBEV的有效性和泛化性。數據集包含1000個駕駛場景,標注了10個類別的140萬3D框,并劃分可見性級別(Vis1-Vis4,從低到高)。評估指標包括平均精度(mAP)、nuScenes檢測得分(NDS),以及各可見性級別的召回率(Recall)。
-
?實驗設置?:
- ?基準模型?:應用CorrBEV到BEVFormer(dense-query)和SparseBEV(sparse-query),分別稱為CorrBEVfm?和CorrBEVsp?。
- ?訓練細節?:使用8×NVIDIA RTX 3090 GPU,遵循基準模型設置(如ResNet-101骨干網絡)。
- ?評估協議?:除整體性能外,還使用RoboBEV協議評估不同角落案例(如遮擋、雪天、低光照)。
-
?整體性能結果?:
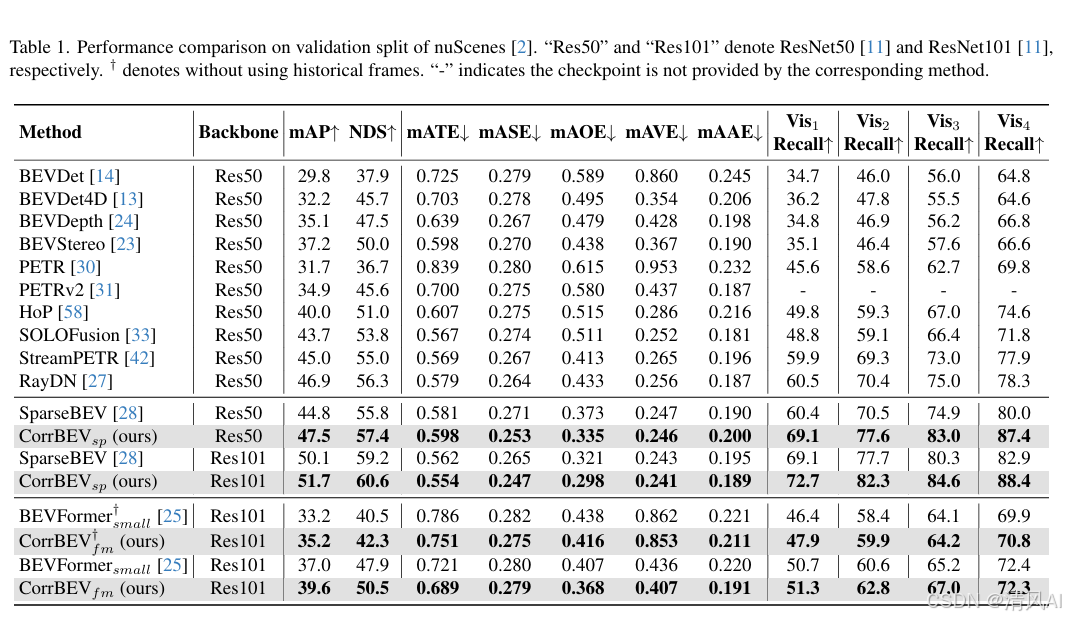
- CorrBEV顯著提升基準模型。在nuScenes驗證集上,BEVFormer提升2.6% mAP和2.6% NDS,SparseBEV提升2.7% mAP和1.6% NDS(見表1和表2)。測試集上也有類似提升(如BEVFormer提升3.6% mAP)。
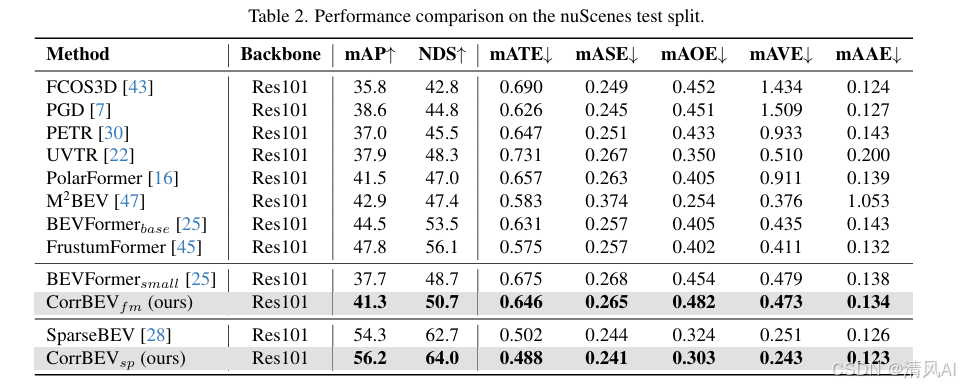
- 推理效率高:相比SparseBEV(21.7 FPS),CorrBEV僅降至18.4 FPS,訓練開銷增加7.48%(21.41 vs. 19.92 GPU-days)。
- CorrBEV顯著提升基準模型。在nuScenes驗證集上,BEVFormer提升2.6% mAP和2.6% NDS,SparseBEV提升2.7% mAP和1.6% NDS(見表1和表2)。測試集上也有類似提升(如BEVFormer提升3.6% mAP)。
-
?遮擋性能結果?:
- CorrBEV在低可見性物體(Vis1和Vis2)上提升最顯著。例如,SparseBEV在Vis1的召回率從60.4%提升至69.1%(見表1),證明原型有效補全遮擋特征。
- 有趣的是,dense-query模型(如BEVFormer)在高可見性物體上提升較小(Vis4召回率72.4% vs. 72.3%),而sparse-query模型(如SparseBEV)提升顯著(80.0% to 87.4%),說明原型對稀疏采樣更有效。
?
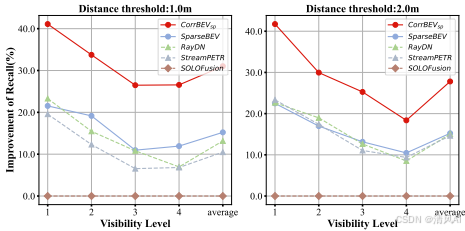
Figure 4以SOLOFusion為參考,展示了CorrBEV在召回率上的相對改進,凸顯其在遮擋條件下的優勢。
- ?其他角落案例結果?:
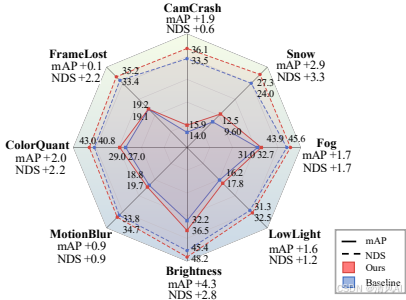
盡管針對遮擋設計,CorrBEV提升了其他挑戰場景的魯棒性(RoboBEV協議)。如圖Figure 5所示,在雪天(Snow)和顏色量化(ColorQuant)等場景下,BEVFormer基準模型有明顯提升(例如雪天場景提升顯著),證明方法能應對多種特征退化問題。
?
-
組件消融分析?:
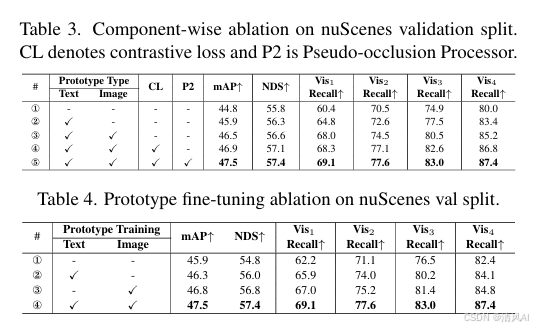
- 多模態原型:語言原型單獨提升1.1% mAP(vs. 基線),視覺原型進一步增加0.6% mAP,證明互補性。
- 訓練策略:對比損失(CL)和P2各貢獻約0.5% mAP提升(見表3)。
- 原型微調:凍結語言或視覺原型會降低性能,尤其視覺原型凍結導致mAP下降1.2%(見表4),強調微調的必要性。
-
?定性結果?:
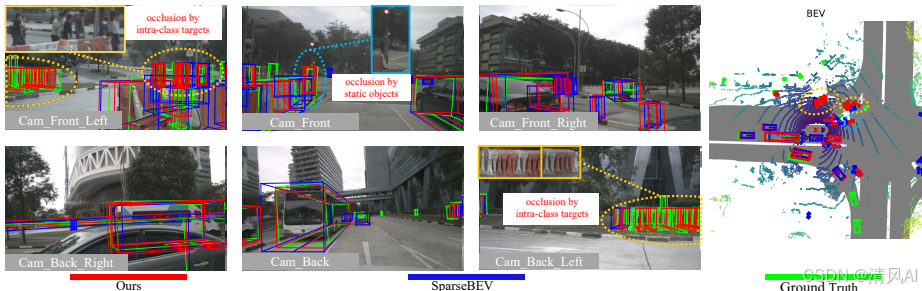
Figure 6可視化對比:在典型遮擋場景中,CorrBEV成功檢測基準模型漏檢的物體。例如,前攝像頭中,交通燈柱遮擋的行人(青色圈)被檢測出;前左和后右攝像頭中,擁擠行人和障礙物(黃色圈)檢測更準確,提升駕駛安全。
?
嵌入可視化?:
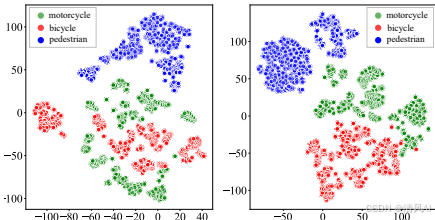
Figure 7展示t-SNE降維后的特征分布。對比損失對齊了“行人、自行車、摩托車”類別的嵌入,減少混淆(左為基線,右為CorrBEV),有利于下游跟蹤和預測任務。?
?
4. ?主要貢獻與結論?
論文的貢獻總結為四點:
- ?即插即用框架?:引入視覺和語言原型作為先驗知識,提升檢測魯棒性,尤其針對部分被遮擋物體。
- ?創新相關學習?:首次將相關學習用于多模態原型與3D檢測模型的融合,高效提升特征質量。
- ?優化訓練流程?:提出隨機像素丟棄(P2)和多模態對比對齊(CL),改善遮擋物體檢測能力。
- ?廣泛驗證?:在多個基準模型(BEVFormer、SparseBEV)上實現一致提升,并在nuScenes和RoboBEV協議中證實有效性。
結論強調,CorrBEV填補了多視圖3D檢測中遮擋處理的空白,其設計源于真實需求。實驗證明,該方法不僅提升遮擋性能,還增強整體魯棒性。論文呼吁社區更多關注BEV感知中的遮擋問題,以推動自動駕駛安全。未來工作可探索原型學習在其他感知任務的應用。
論文地址:?https://openaccess.thecvf.com/content/CVPR2025/papers/Xue_CorrBEV_Multi-View_3D_Object_Detection_by_Correlation_Learning_with_Multi-modal_CVPR_2025_paper.pdf





)





)







