【深度學習】什么是梯度裁剪(Gradient Clipping)?一張圖徹底搞懂!
在訓練深度神經網絡,尤其是 RNN、LSTM、Transformer 這類深層結構時,你是否遇到過以下情況:
-
模型 loss 突然變成 NaN;
-
梯度爆炸導致訓練中斷;
-
訓練剛開始幾步模型就“失控”了。
這些問題,很多時候都是因為——梯度過大(梯度爆炸)。而應對這個問題的常見方案之一,就是本文要講的主角:梯度裁剪(Gradient Clipping)。
一、梯度裁剪是什么?
我們先看一張圖,一圖勝千言:
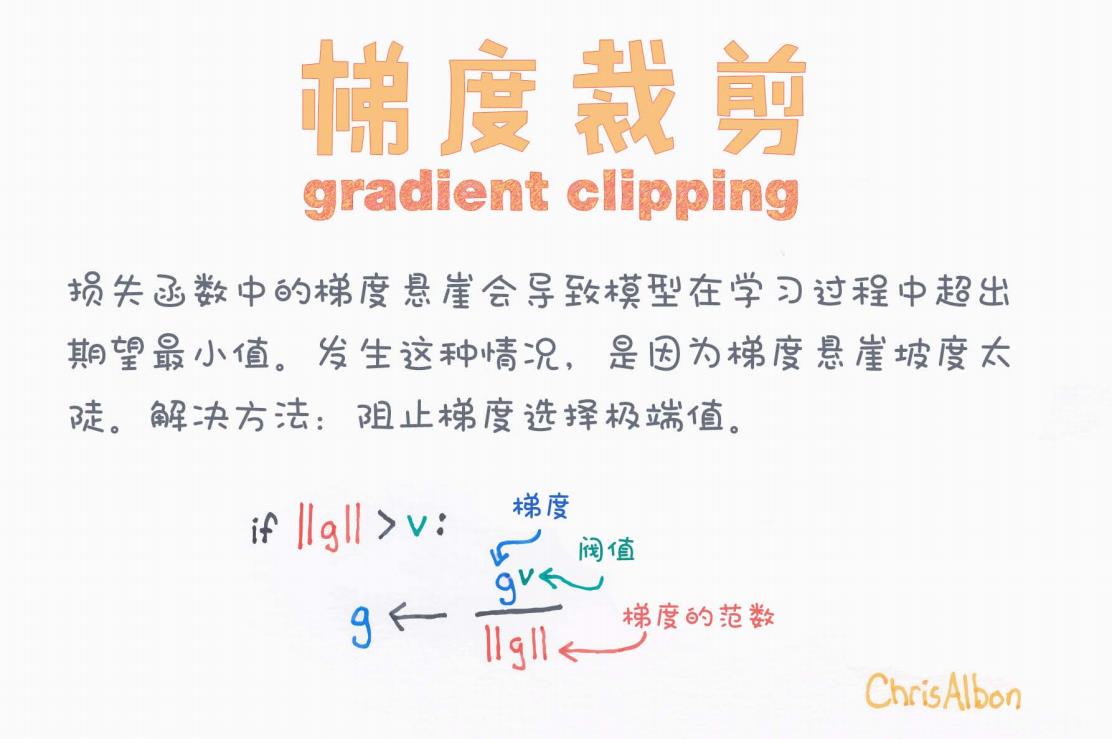
圖中文字解讀如下:
-
標題:梯度裁剪(Gradient Clipping)
-
說明文字:
損失函數中的梯度懸崖會導致模型在學習過程中超出期望最小值。發生這種情況,是因為梯度陡峭。解決方法:阻止梯度選擇極端值。
-
圖示公式:
if ‖g‖ > v:g ← (g / ‖g‖) * v意思是:
-
如果梯度的范數(即長度)大于某個閾值 v,就將梯度縮放為長度為 v 的向量。
-
這樣可以防止某些參數更新過大。
-
二、為什么需要梯度裁剪?
1. 梯度爆炸的根源
在反向傳播中,每一層的梯度是前面所有梯度的乘積。在深層網絡中,如果這些乘積的值都 > 1,最終梯度將呈指數級增長,導致所謂的梯度爆炸(Gradient Explosion)。
表現形式:
-
loss一直上升,甚至變成NaN -
參數更新過大,模型發散
-
模型無法收斂
2. 梯度裁剪的作用
梯度裁剪并不會改變梯度的方向,它只是在梯度的模(大小)超過某個閾值時,進行縮放。這就像是給模型裝了一個“剎車”系統,一旦速度過快就減速。
三、梯度裁剪的數學原理
設:
-
當前梯度為 g
-
范數為 ∥g∥
-
閾值為 v
裁剪操作如下:
也就是說:將梯度的模限制在最大值 vv 內,方向保持不變。
四、實戰中如何實現梯度裁剪?
在 PyTorch 中非常簡單:
import torch# 假設已經定義 optimizer 和 model
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
在 TensorFlow(Keras)中也可以:
optimizer = tf.keras.optimizers.Adam(clipnorm=1.0)
五、梯度裁剪 vs 梯度正則化
| 名稱 | 作用 | 是否改變方向 |
|---|---|---|
| 梯度裁剪 | 控制梯度最大值,避免爆炸 | 否 |
| L2 正則化(權重衰減) | 防止模型過擬合,限制權重大小 | 是 |
注意:梯度裁剪是為了“救訓練”,不是為了“提高精度”!
六、何時需要使用梯度裁剪?
-
訓練深度模型如 RNN、LSTM、Transformer;
-
loss 出現爆炸性增長,模型訓練不穩定;
-
使用高學習率訓練時容易出問題;
-
模型結構復雜,層數深,非線性強。
七、調參建議
| 參數 | 建議取值 | 說明 |
|---|---|---|
| clip norm | 0.1 ~ 5 | 通常從 1.0 開始嘗試,逐步調整 |
| 適用優化器 | Adam、SGD | 梯度裁剪不依賴特定優化器 |
| 使用頻率 | 每次 step 前 | 每次梯度更新前裁剪 |
八、總結
梯度裁剪是深度學習中極其實用的一種 訓練穩定性保障機制。它的作用不是提升模型能力,而是防止模型“發瘋”。在某些模型結構中(如 LSTM、GAN),它幾乎是標配操作。
一句話總結:梯度裁剪不是為了讓模型跑得快,而是為了別讓它翻車。
推薦閱讀
-
《Deep Learning》by Ian Goodfellow(第 6 章)
-
PyTorch 官方文檔:clip_grad_norm_
如果你覺得本文對你有幫助,歡迎點贊、收藏、評論~
也歡迎你分享你在訓練中使用梯度裁剪的經驗或踩過的坑!

)

















