文章目錄
- 1.為什么要分庫分表
- 2.分庫分表有哪些中間件,不同的中間件都有什么優點和缺點?
- 3.分庫分表的方式(水平分庫,垂直分庫,水平分表,垂直分表)
- 3.1 水平分庫
- 3.2 垂直分庫
- 3.3 水平分表
- 3.4 垂直分表
- 4.分庫分表帶來的問題
- 4.1 事務一致性問題
- 4.2 跨節點關聯查詢
- 4.3 跨節點分頁、排序函數
- 4.4 主鍵避重
- 5.現在有一個未分庫分表的系統,未來要分庫分表, 如何設計才可以讓系統從未分庫分表動態切換到分庫分表上?
- 6.如何設計可以動態擴容縮容的分庫分表方案?
- 7.如何實現 mysql 的讀寫分離?MySQL 主從復制原理的是啥?
- 如何評估分庫數量
- 分庫分表之后,id 主鍵如何處理?(分布式ID)
- 分表要停服嘛?不停服怎么做?
- 分庫分表后的分頁問題
- order by,group by等聚合函數問題
- MySQL分區
- Sharding-JDBC
- Sharding-JDBC基礎入門
- Sharding-JDBC作用
- 分片規則配置
- 流程分析
- Sharding-JDBC集成方式
1.為什么要分庫分表
(1)為什么要分庫
①問題背景:
在業務量劇增的情況下:
a.磁盤容量被撐爆;
b.數據庫的連接數有限,高并發場景下,會出現too many connections報錯。
②好處:
a.解決了單庫大數據,高并發的性能瓶頸;
b.降低單機硬件資源的瓶頸。
(2)為什么要分表
①問題背景:
a.單表數據量太大,做了很多優化仍然無法提升效率
b.索引一般是B+樹存儲結構,B+樹高度增高,查詢會過慢
②好處
a.優化單一表數據量過大而產生的性能問題
b.避免IO爭搶并減少鎖表的幾率
2.分庫分表有哪些中間件,不同的中間件都有什么優點和缺點?
(1)目前流行的分庫分表中間件比較多:
Sharding-JDBC
cobar
Mycat
Atlas
TDDL(淘寶)
vitess
(2)不同的中間件都有什么優點和缺點
①sharding-jdbc:優點:不用部署,運維成本低; 缺點:耦合度高,各個系統都依賴sharding-jdbc,系統升級困難
②mycat:優點:耦合度低,系統升級容易 缺點:需要部署,運維成本高
3.分庫分表的方式(水平分庫,垂直分庫,水平分表,垂直分表)
3.1 水平分庫
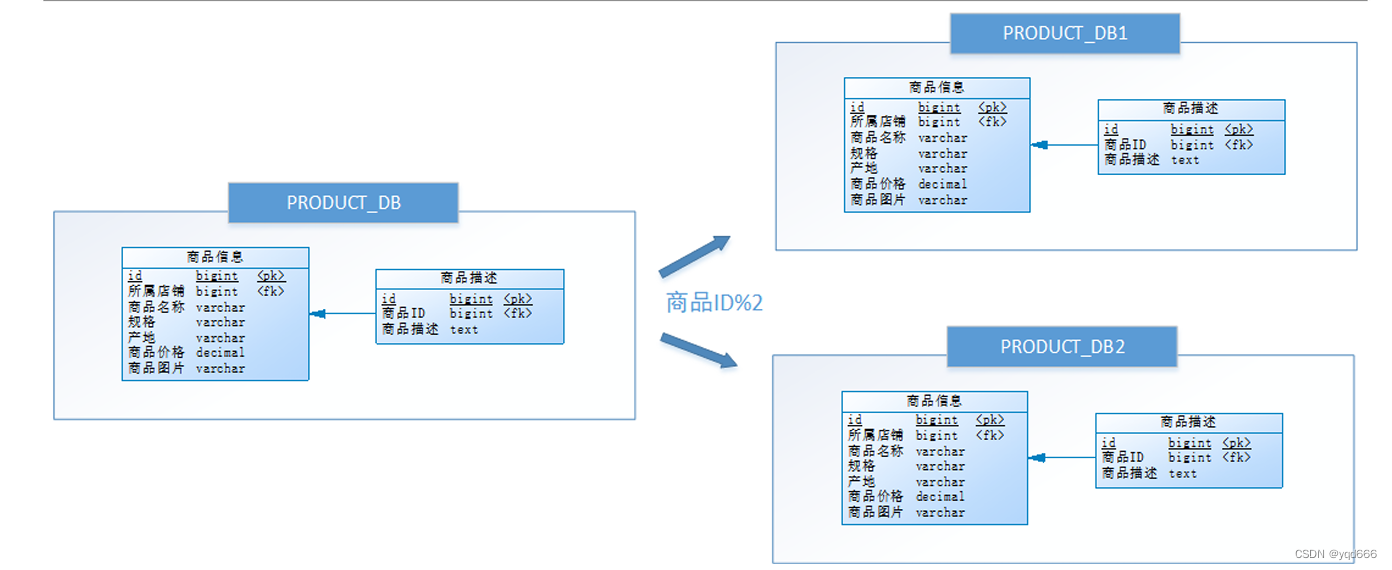
(1)水平分庫是什么?
把同一個表的數據按一定規則拆到不同的數據庫中,每個庫可以放在不同的服務器上。
(2)例子:將店鋪ID為單數的和店鋪ID為雙數的商品信息分別放在兩個庫中
3.2 垂直分庫
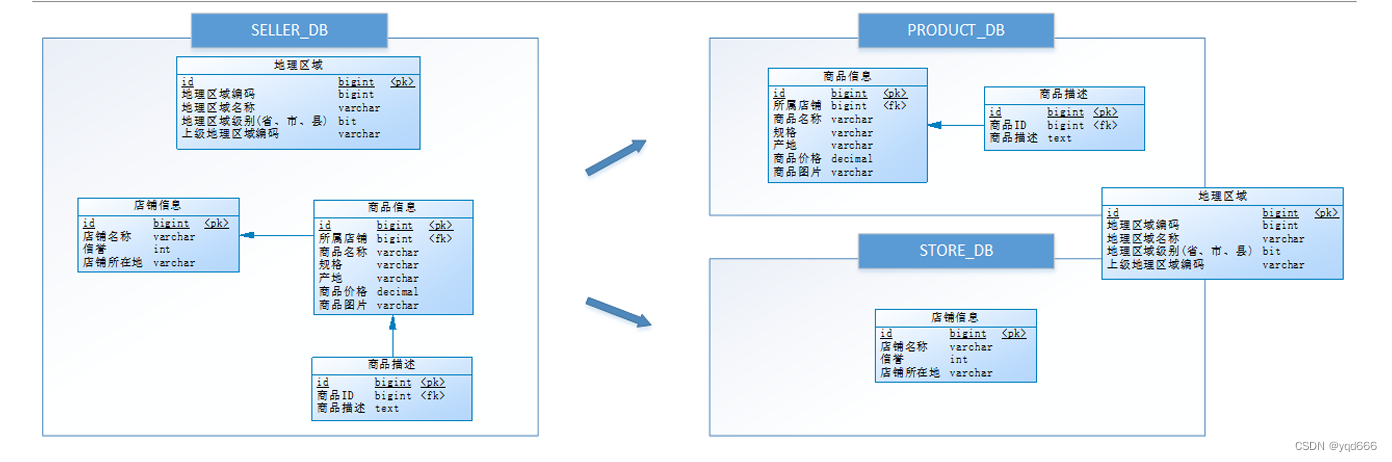
(1)垂直分庫是什么?
將表按業務分類,然后分布在不同數據庫,并且可以將這些數據庫部署在不同服務器上,從而達到多個服務器共同分攤壓力的效果
(2)例子:由于商品信息與商品描述業務耦合度較高,因此一起被存放在PRODUCT_DB(商品庫);而店鋪信息相對獨立,因此單獨被存放在STORE_DB(店鋪庫)。
3.3 水平分表
(1)水平分表是什么?
是在同一個數據庫內,把同一個表的數據按一定規則拆到多個表中
3.4 垂直分表
(1)垂直分表是什么?
將一個表按照字段分成多表,每個表存儲其中一部分字段。
(2)通常我們按以下原則進行垂直拆分:
①把不常用的字段單獨放在一張表;
②把text,blob等大字段拆分出來放在附表中;
③經常組合查詢的列放在一張表中;
4.分庫分表帶來的問題
4.1 事務一致性問題
由于分庫分表把數據分布在不同庫甚至不同服務器,不可避免會帶來分布式事務問題。
4.2 跨節點關聯查詢
(1)在沒有分庫前,我們檢索商品時可以通過以下SQL對店鋪信息進行關聯查詢
SELECT p.*,r.[地理區域名稱],s.[店鋪名稱],s.[信譽]FROM [商品信息] p
LEFT JOIN [地理區域] r ON p.[產地] = r.[地理區域編碼]LEFT JOIN [店鋪信息] s ON p.id = s.[所屬店鋪]WHERE...ORDER BY...LIMIT...
(2)但垂直分庫后[商品信息]和[店鋪信息]不在一個數據庫,甚至不在一臺服務器,無法進行關聯查詢。可將原關聯查詢分為兩次查詢,第一次查詢的結果集中找出關聯數據id,然后根據id發起第二次請求得到關聯數據,最后將獲得到的數據進行拼裝。
4.3 跨節點分頁、排序函數
跨節點多庫進行查詢時,limit分頁、order by排序等問題,就變得比較復雜了。需要先在不同的分片節點中將數據進行排序并返回,然后將不同分片返回的結果集進行匯總和再次排序。
4.4 主鍵避重
在分庫分表環境中,由于表中數據同時存在不同數據庫中,主鍵值使用的自增長將無法使用,某個分區數據庫生成的ID無法保證全局唯一。因此需要單獨設計全局主鍵,以避免跨庫主鍵重復問題。
5.現在有一個未分庫分表的系統,未來要分庫分表, 如何設計才可以讓系統從未分庫分表動態切換到分庫分表上?
簡單來說,就是在線上系統里面,之前所有寫庫的地方,增刪改操作,都除了對老庫增
刪改,都加上對新庫的增刪改,這就是所謂雙寫,同時寫倆庫,老庫和新庫。
然后系統部署之后,新庫數據差太遠,用之前說的導數工具,跑起來讀老庫數據寫新
庫,寫的時候要根據 gmt_modified 這類字段判斷這條數據最后修改的時間,除非是讀出來
的數據在新庫里沒有,或者是比新庫的數據新才會寫。
接著導萬一輪之后,有可能數據還是存在不一致,那么就程序自動做一輪校驗,比對
新老庫每個表的每條數據,接著如果有不一樣的,就針對那些不一樣的,從老庫讀數據再次
寫。反復循環,直到兩個庫每個表的數據都完全一致為止。
接著當數據完全一致了,就 ok 了,基于僅僅使用分庫分表的最新代碼,重新部署一次,
不就僅僅基于分庫分表在操作了么,還沒有幾個小時的停機時間,很穩。所以現在基本玩兒
數據遷移之類的,都是這么干了。
6.如何設計可以動態擴容縮容的分庫分表方案?
一開始上來就是 32 個庫,每個庫 32 個表,1024 張表
我可以告訴各位同學說,這個分法,第一,基本上國內的互聯網肯定都是夠用了,第
二,無論是并發支撐還是數據量支撐都沒問題, 每個庫正常承載的寫入并發量是 1000,那么
32 個庫就可以承載 32 * 1000 = 32000 的寫并發,如果每個庫承載 1500 的寫并發,32 * 1500
= 48000 的寫并發,接近 5 萬/s 的寫入并發,前面再加一個 MQ,削峰,每秒寫入 MQ 8 萬
條數據,每秒消費 5 萬條數據。
有些除非是國內排名非常靠前的這些公司,他們的最核心的系統的數據庫,可能會出
現幾百臺數據庫的這么一個規模,128 個庫,256 個庫,512 個庫 1024 張表,假設每個表放
500 萬數據,在 MySQL 里可以放 50 億條數據 每秒的 5 萬寫并發,總共 50 億條數據,對于
國內大部分的互聯網公司來說,其實一般來說都夠了 談分庫分表的擴容,第一次分庫分表,
就一次性給他分個夠,32 個庫,1024 張表,可能對大部分的中小型互聯網公司來說,已經
可以支撐好幾年了 一個實踐是利用 32 * 32 來分庫分表,即分為 32 個庫,每個庫里一個表
分為 32 張表。一共就是 1024 張表。根據某個 id 先根據 32 取模路由到庫,再根據 32 取模
路由到庫里的表。
剛開始的時候,這個庫可能就是邏輯庫,建在一個數據庫上的,就是一個 mysql 服務器
可能建了 n 個庫,比如 16 個庫。后面如果要拆分,就是不斷在庫和 mysql 服務器之間做遷
移就可以了。然后系統配合改一下配置即可。
7.如何實現 mysql 的讀寫分離?MySQL 主從復制原理的是啥?
(1)如何實現 mysql 的讀寫分離?
基于主從復制架構,一個主庫寫,多個從庫讀
(2)MySQL 主從復制原理:
①主庫將變更寫入binlog日志
②從庫連接到主庫,通過IO線程將主庫binlog日志拷貝到本地,寫入到中繼日志中
③從庫有一個sql線程會從中繼日志讀取binlog,相當于在本地再執行一遍SQL
(3)存在兩個問題:
①主庫是并行執行,從庫是串行執行,有概率出現剛寫入主庫的數據是讀不到的
②主庫突然宕機,恰好數據還沒同步到從庫,造成數據丟失
(4)解決:
①并行復制,解決主從同步延時問題:從庫開啟多個線程并行讀取日志
②半同步復制,解決主庫數據丟失問題:主庫接收到從庫ack后才認為操作成功
如何評估分庫數量
(1)對于MySQL來說的話,一般單庫超過5千萬記錄,DB的壓力就非常大了。所以分庫數量多少,需要看單庫處理記錄能力有關。
(2)如果分庫數量少,達不到分散存儲和減輕DB性能壓力的目的;如果分庫的數量多,對于跨多個庫的訪問,應用程序需要訪問多個庫。
(3)一般是建議分4~10個庫,我們公司的企業客戶信息,就分了10個庫
分庫分表之后,id 主鍵如何處理?(分布式ID)
(1)使用UUID或者雪花算法,
(2)好處:基于本地生成,不基于數據庫
(3)缺點:太長,作為主鍵性能太差;UUID不具有有序性,會造成B+樹有過多的隨機寫操作,頻繁修改樹結構,從而導致性能下降
分表要停服嘛?不停服怎么做?
不用停服,主要分五個步驟:
(1)編寫代理層,加個開關(控制訪問新的DAO還是老的DAO,或者是都訪問),灰度期間,還是訪問老的DAO。
(2)開啟雙寫,既在舊表新增和修改,也在新表新增和修改。日志或者臨時表記下新表ID起始值,舊表中小于這個值的數據就是存量數據,這批數據就是要遷移的。
(3)通過腳本把舊表的存量數據寫入新表。
(4)停讀舊表改讀新表,此時新表已經承載了所有讀寫業務,但是這時候不要立刻停寫舊表,需要保持雙寫一段時間。
(5)當讀寫新表一段時間之后,如果沒有業務問題,就可以停寫舊表啦
簡單回答:
1.加開關,控制訪問老的dao還是新的dao,或者都訪問,灰度期間還是訪問老的
2.開啟雙寫,舊表和新表都進行新增和修改,日志記錄新表id起始值,舊表中小于這個值就是要遷移的
3.通過腳本把舊表數據寫入新表
4.停讀舊表改讀新表,此時不要立刻停寫舊表,需要保持一段時間
5.當讀寫新表一段時間,如果業務沒有問題,就可以停寫新表了
分庫分表后的分頁問題
(1)在各個數據庫節點查到對應結果,在代碼端匯聚再分頁。優點是業務無損,精準返回所需數據;缺點:返回過多數據,增大網絡傳輸
(2)業務妥協,不允許跳頁查詢
order by,group by等聚合函數問題
跨節點的count,order by,group by以及聚合函數等問題,都是一類的問題,它們一般都需要基于全部數據集合進行計算。可以分別在各個節點上得到結果后,再在應用程序端進行合并。
MySQL分區
(1)分區和分表相似,都是按照規則分解表。不同在于分表將大表分解為若干個獨立的實體表,而分區是將數據分段劃分在多個位置存放,分區后,表還是一張表,但數據分散到各個分散的位置了。
(2)但是分區通常比較不建議使用,因為在mysql規范中寫到對分區表的缺點:分區表對分區鍵有嚴格要求;分區表在表變大后,執?行DDL、SHARDING、單表恢復等都變得更加困難。因此禁止使用分區表,并建議業務端手動SHARDING。
Sharding-JDBC
Sharding-JDBC基礎入門
Sharding-JDBC作用
Sharding-JDBC的核心功能為數據分片和讀寫分離,通過Sharding-JDBC,應用可以透明的使用jdbc訪問已經分庫分表、讀寫分離的多個數據源,而不用關心數據源的數量以及數據如何分布。
分片規則配置
分片規則配置是sharding-jdbc進行對分庫分表操作的重要依據,配置內容包括:數據源、主鍵生成策略、分片策略等
(1)首先定義數據源m1,并對m1進行實際的參數配置。
(2)指定t_order表的數據分布情況,他分布在m1.t_order_1,m1.t_order_2
(3)指定t_order表的主鍵生成策略為SNOWFLAKE,SNOWFLAKE是一種分布式自增算法,保證id全局唯一
(4)定義t_order分片策略,order_id為偶數的數據落在t_order_1,為奇數的落在t_order_2,分表策略的表達式為
t_order_$->{order_id % 2 + 1}
# 以下是分片規則配置
# 定義數據源
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = root
# 指定t_order表的數據分布情況,配置數據節點
spring.shardingsphere.sharding.tables.t_order.actual‐data‐nodes = m1.t_order_$‐>{1..2}
# 指定t_order表的主鍵生成策略為SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key‐generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key‐generator.type=SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片鍵和分片算法
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.sharding‐column = order_id
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.algorithm‐expression =
t_order_$‐>{order_id % 2 + 1}
流程分析
(1)解析sql,獲取片鍵值,在本例中是order_id
(2)Sharding-JDBC通過規則配置 t_order_$->{order_id % 2 + 1},知道了當order_id為偶數時,應該往t_order_1表插數據,為奇數時,往t_order_2插數據。
(3)于是Sharding-JDBC根據order_id的值改寫sql語句,改寫后的SQL語句是真實所要執行的SQL語句。
(4)執行改寫后的真實sql語句
(5)將所有真正執行sql的結果進行匯總合并,返回。
Sharding-JDBC集成方式
(1)Spring Boot Yaml 配置
server:port: 56081servlet:context‐path: /sharding‐jdbc‐simple‐demospring:application:name: sharding‐jdbc‐simple‐demohttp:encoding:enabled: truecharset: utf‐8force: truemain:allow‐bean‐definition‐overriding: trueshardingsphere:datasource:names: m1m1:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/order_db?useUnicode=trueusername: rootpassword: mysqlsharding:tables:t_order:actualDataNodes: m1.t_order_$‐>{1..2}tableStrategy:inline:shardingColumn: order_idalgorithmExpression: t_order_$‐>{order_id % 2 + 1}keyGenerator:type: SNOWFLAKEcolumn: order_idprops:sql:show: truemybatis:configuration:map‐underscore‐to‐camel‐case: trueswagger:enable: true
(2)Java 配置類
@Configurationpublic class ShardingJdbcConfig {// 定義數據源Map<String, DataSource> createDataSourceMap() {DruidDataSource dataSource1 = new DruidDataSource();dataSource1.setDriverClassName("com.mysql.jdbc.Driver");dataSource1.setUrl("jdbc:mysql://localhost:3306/order_db?useUnicode=true");dataSource1.setUsername("root");dataSource1.setPassword("root");Map<String, DataSource> result = new HashMap<>();result.put("m1", dataSource1);return result;}// 定義主鍵生成策略private static KeyGeneratorConfiguration getKeyGeneratorConfiguration() {KeyGeneratorConfiguration result = new
KeyGeneratorConfiguration("SNOWFLAKE","order_id");return result;}// 定義t_order表的分片策略TableRuleConfiguration getOrderTableRuleConfiguration() {TableRuleConfiguration result = new TableRuleConfiguration("t_order","m1.t_order_$‐>{1..2}");result.setTableShardingStrategyConfig(new
InlineShardingStrategyConfiguration("order_id", "t_order_$‐>{order_id % 2 + 1}"));result.setKeyGeneratorConfig(getKeyGeneratorConfiguration());return result;}// 定義sharding‐Jdbc數據源@BeanDataSource getShardingDataSource() throws SQLException {ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());//spring.shardingsphere.props.sql.show = trueProperties properties = new Properties();properties.put("sql.show","true");return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig,properties);}}
(3)Spring Boot properties配置
# 定義數據源
spring.shardingsphere.datasource.names = m1spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = root # 指定t_order表的主鍵生成策略為SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key‐generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key‐generator.type=SNOWFLAKE# 指定t_order表的數據分布情況
spring.shardingsphere.sharding.tables.t_order.actual‐data‐nodes = m1.t_order_$‐>{1..2}# 指定t_order表的分表策略
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.sharding‐column = order_id
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.algorithm‐expression = t_order_$‐>{order_id % 2 + 1}










:和def __init__(self):的區別)

)


)



)