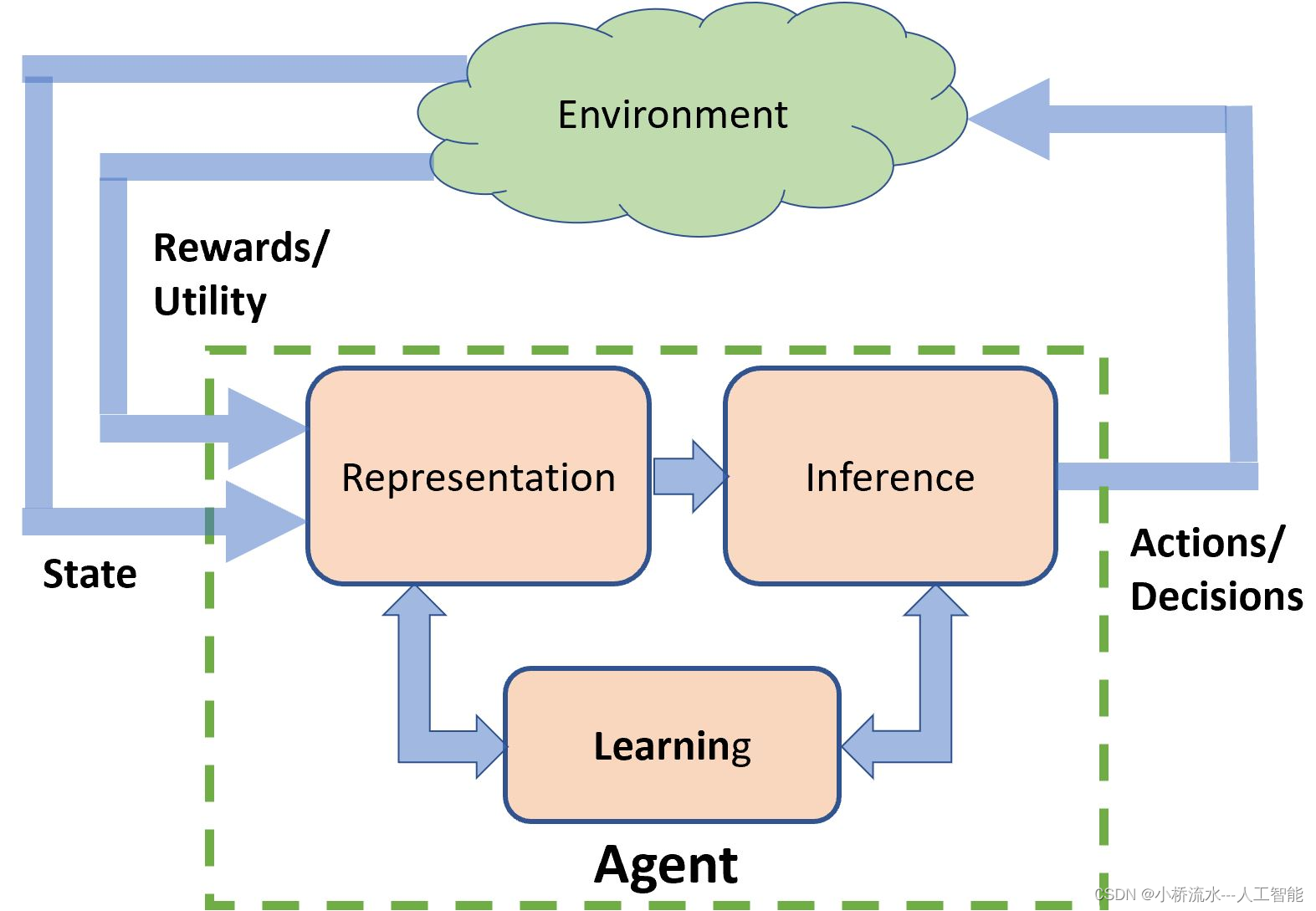
在強化學習中,Q值是一個非常核心的概念,用來表示在給定的狀態下,采取某個特定動作所期望獲得的總回報。Q值基本上是一種衡量“動作價值”的方式,即在當前狀態采取一個動作能帶來多大價值。
定義和計算
Q值通常表示為 (Q(s, a)),其中 (s) 表示環境的狀態,(a) 表示在該狀態下可能采取的動作。Q值的計算涉及到當前動作的即時獎勵以及因該動作導致的狀態轉移而獲得的未來獎勵的預期值。
具體來說,Q值可以通過以下公式計算:
Q ( s , a ) = r + γ max ? a ′ Q ( s ′ , a ′ ) Q(s, a) = r + \gamma \max_{a'} Q(s', a') Q(s,a)=r+γa′max?Q(s′,a′)
其中:
- ( r ) 是采取動作 ( a ) 時獲得的即時獎勵。
- γ \gamma γ 是折扣因子,用于調節未來獎勵的當前價值,通常取值在 0 到 1 之間。
- max ? a ′ Q ( s ′ , a ′ ) \max_{a'} Q(s', a') maxa′?Q(s′,a′) 表示在下一個狀態 ( s’ ) 可能采取的所有動作中,選擇使得Q值最大化的動作的Q值。這部分代表了未來獎勵的預期值。
Q值的作用
Q值的主要作用是幫助智能體(比如一個機器學習模型)在給定狀態下做出最優決策。通過比較在某狀態下所有可能動作的Q值,智能體可以選擇Q值最高的動作,因為這個動作預期能帶來最大的總回報。
Q學習算法
Q值的更新通常通過一種叫做Q學習的算法實現,該算法是一種無模型的強化學習算法,可以估計策略的好壞。Q學習的目標是找到使Q值最大化的策略,這樣的策略可以指導智能體在任何狀態下都能做出最佳決策。
通過不斷地與環境交互,收集獎勵信息,智能體可以不斷更新其Q值表或Q值函數(在深度強化學習中使用神經網絡來近似Q值函數),以此逐步優化其決策過程,最終學習到一個能在給定任務中表現最佳的策略。






:和def __init__(self):的區別)

)


)



)
)

---PTA實驗C++)
