大語言模型(LLMs)在多個領域的應用日益廣泛,但確保它們的行為與人類價值觀和意圖一致卻充滿挑戰。傳統對齊方法,例如基于人類反饋的強化學習(RLHF),雖取得一定進展,仍面臨諸多難題:訓練獎勵模型需準確反映人類偏好,這本身難度很大;actor-critic架構的設計和優化過程復雜;RLHF通常需要直接訪問LLM的參數,這在API基礎模型中難以實現。獲取高質量的、無偏見的反饋數據也是一大挑戰,因為數據集可能受到個別標注者觀點的影響,導致偏差。這些挑戰共同構成了LLMs對齊工作的難點。本文介紹了一種新的對齊范式——Aligner,它通過學習對齊和未對齊答案之間的修正殘差來繞過整個RLHF過程,提供了一種參數高效、資源節約的對齊解決方案。
?Aligner
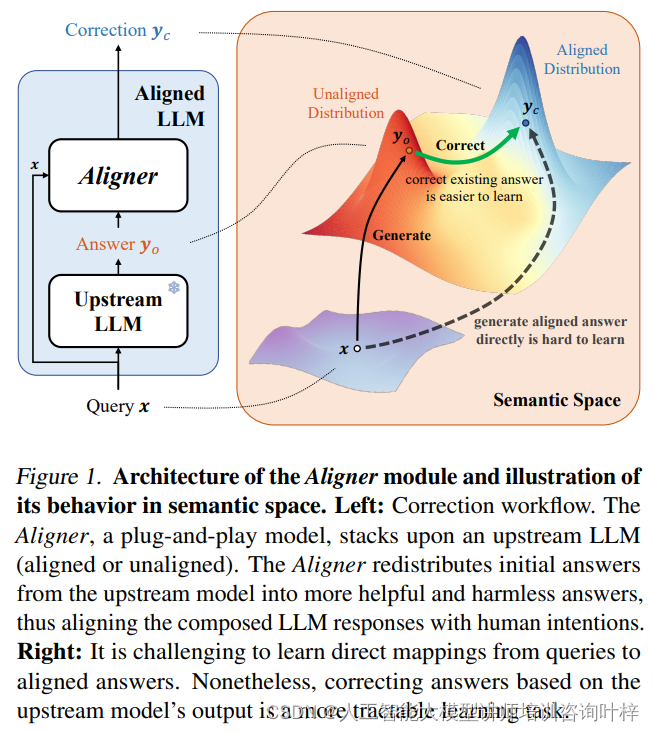
圖1展示了Aligner模塊的架構以及它在語義空間中的行為。左側展示了一個校正工作流程,其中Aligner作為一個即插即用模型,堆疊在上游的大型語言模型(LLM)之上,無論該上游模型是否已經對齊。Aligner的作用是將上游模型生成的初始答案重新分配,轉化為更加有用和無害的答案,從而使組合后的LLM響應與人類意圖保持一致。
右側的圖示說明了從查詢到對齊答案的直接映射學習是具有挑戰性的。然而,基于上游模型輸出的答案進行校正,則是一個更可行的學習任務。這意味著,Aligner通過專注于校正已有答案,而不是試圖直接生成完美對齊的答案,簡化了學習過程。這種方法利用了seq2seq模型的優勢,通過學習隱含的殘差來實現更好的對齊,而不是從頭開始學習復雜的映射。
Aligner的架構和功能類似于神經網絡中的殘差塊,它采用“復制和校正”的方法,將改進疊加在原始答案上,而不改變其基本結構。這種設計不僅保留了初始響應,同時增強了它,使其更好地符合期望的結果。通過這種方式,Aligner能夠在保持原有答案框架的基礎上,對其進行必要的調整,以提高答案的質量和安全性。
Aligner模型的核心是一種自回歸的序列到序列(seq2seq)學習方法,它通過監督學習的方式在查詢-答案-修正(Q-A-C)數據集上進行訓練。這種方法與傳統的基于人類反饋的強化學習(RLHF)相比,具有顯著的優勢。在RLHF中,通常需要多個輔助模型,包括行為者(actor)、評論家(critic)、獎勵(reward)和參考(reference)模型,這些模型的協調和訓練過程相當復雜,需要大量的計算資源。
相比之下Aligner模型的設計更為簡潔高效。它不需要依賴額外的輔助模型,因此減少了計算負擔,使得對齊過程更加高效。Aligner模型的工作原理相對直觀:它接收來自用戶的查詢以及由上游大型語言模型(LLM)生成的初始答案。基于這些輸入,Aligner模型會生成一個修正后的答案,這個答案旨在更好地符合人類的價值觀和意圖。
Aligner模型的訓練過程也相對簡單。它通過學習如何從初始答案中識別并改進不符合人類價值觀的部分,從而生成更加對齊的答案。這種方法的優勢在于,它專注于修正已有答案,而不是從頭開始生成答案,這大大降低了模型的復雜性和所需的計算資源。
Aligner模型的自回歸特性意味著它在生成修正答案時,會考慮到整個查詢和答案的上下文,從而生成更加連貫和相關的答案。這種方法不僅提高了答案的質量,還確保了答案與用戶查詢的緊密相關性。
在對Aligner模型與RLHF(基于人類反饋的強化學習)和DPO(直接偏好優化)等傳統對齊方法進行比較時,可以發現Aligner在訓練資源需求和模型可解釋性方面具有明顯的優勢:
- 從訓練資源的角度來看,Aligner模型由于其簡化的架構,不需要像RLHF和DPO那樣維護多個復雜的模型組件。RLHF方法涉及到訓練獎勵模型、actor、critic等組件,這不僅增加了模型訓練的復雜性,也顯著提高了所需的計算資源。而DPO作為一種強化學習方法,同樣需要大量的計算資源來優化策略。相比之下,Aligner-7B作為一個自回歸的seq2seq模型,即使在性能相似的情況下,也能以更少的資源消耗完成訓練。
- 隨著上游模型規模的增加,RLHF和DPO等方法所需的訓練資源會急劇上升。這是因為這些方法通常需要與模型參數直接交互,參數量的增加自然導致計算負擔的加重。然而,Aligner模型的訓練資源需求并不隨上游模型規模的變化而變化。這是因為Aligner作為一個附加模塊,它的訓練和運行不依賴于上游模型的具體參數,而是通過學習如何改進已有答案來實現對齊,因此它能夠以相對恒定的資源消耗應對不同規模的上游模型。
- Aligner模型的可解釋性也是其一大優勢。在RLHF方法中,獎勵信號往往是從人類反饋中學習得到的,這個過程可能不夠透明,使得模型的決策過程難以解釋。而Aligner模型作為一個seq2seq模型,其行為更易于理解和解釋,因為它直接在文本空間內操作,通過修改和改進已有答案來生成對齊的答案,這個過程更加直觀。
Aligner的訓練策略采用了一種創新的方法,稱為殘差修正,這種方法的核心在于利用原始答案與修正后答案之間的語義差異。這個策略首先通過部分訓練數據來初步訓練一個Aligner模型,這個過程被稱為“預熱”階段。預熱的目的是讓模型學習到一個基礎的恒等映射,即模型在這個階段學習如何保持輸入和輸出的一致性,這為后續的訓練打下了基礎。
在預熱階段之后,Aligner模型會使用完整的查詢-答案-修正(Q-A-C)數據集來進行進一步的訓練。此時,模型不再只是簡單地學習恒等映射,而是開始學習如何根據已有的答案生成改進后的修正答案。這種方法允許模型專注于答案的改進部分,而不是從頭開始生成整個答案,這提高了學習效率并減少了所需的模型容量。
殘差修正策略的一個關鍵優勢在于它允許模型在保持原有答案結構的同時,對答案進行精細化的調整。這意味著模型可以更加精確地對齊到人類價值觀和意圖,同時避免了對原始答案進行大規模的改動,這在很多情況下是有益的,因為它可以保留原始答案中仍然有效和準確的部分。
通過這種方式,Aligner模型能夠更加高效地學習如何生成與人類價值觀更加一致的答案。因為它專注于修正而不是重建,這使得模型可以更快地收斂,并且需要的訓練數據量也相對較少。這種方法在訓練大型語言模型時尤其有用,因為這些模型通常需要大量的數據和計算資源。
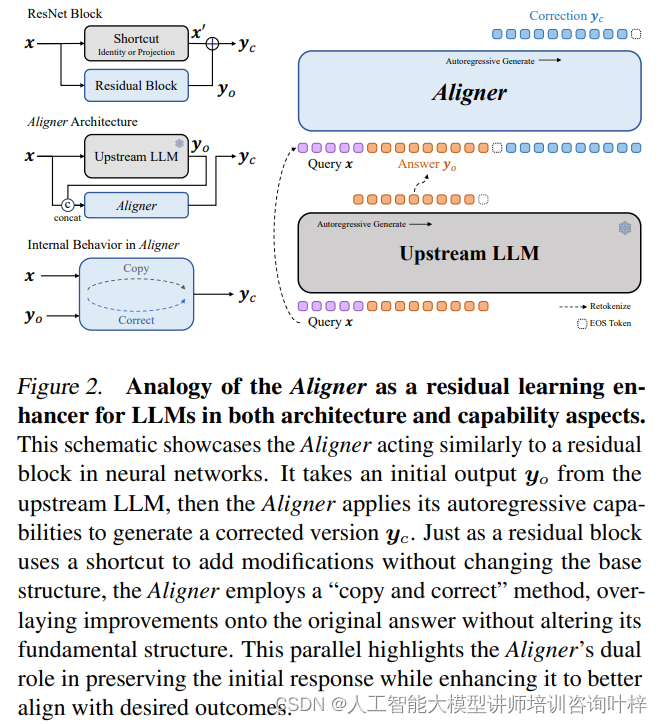
殘差修正訓練策略為Aligner模型提供了一種有效的學習機制,使其能夠以一種計算效率高且可解釋的方式來改進和對齊大型語言模型的答案。通過預熱階段的恒等映射學習和完整數據集上的殘差修正,Aligner能夠生成更加精確和有用的回答,同時保持了訓練過程的簡潔性和高效性。
通過Aligner實現的弱到強的泛化
弱到強的泛化這一概念在機器學習領域中指的是,使用一個能力較弱的模型來指導或監督一個更強模型的訓練,以此提升后者的性能。本文中的方法基于Aligner模型來實現弱到強的泛化。
這個方法涉及使用一個較小的Aligner模型,即所謂的“弱”模型,來生成對齊標簽。這些標簽隨后被用作訓練數據,用于微調一個更大規模或更強大的上游模型,也就是“強”模型。這個過程的核心優勢在于,即使是較小的模型也能夠提供有價值的反饋,幫助提升大型模型的性能。
在實踐中,弱Aligner模型首先接收到來自上游模型的輸出,然后基于這些輸出生成修正后的標簽。這些修正后的標簽捕捉到了原始輸出與期望輸出之間的差異,從而為強模型提供了改進的方向。通過這種方式,即使是較小的模型也能夠對大型模型進行有效的指導。
這種方法的一個關鍵優勢是它的可擴展性。隨著模型規模的增長,直接訓練和優化大型模型變得越來越困難,需要大量的計算資源和數據。而通過弱到強泛化,我們可以利用小型模型的靈活性和效率,來引導和優化大型模型的行為,使其更加符合人類的價值觀和意圖。
這種方法還有助于解決大型模型訓練中的一些挑戰,比如數據的標注成本和質量控制問題。通過使用小型模型來生成訓練標簽,可以減少對大量高質量標注數據的依賴,從而降低訓練成本并提高訓練過程的可操作性。
通過Aligner實現的弱到強泛化提供了一種創新的訓練策略,它允許小型模型通過生成對齊標簽來增強大型模型的性能。這種方法不僅提高了大型模型的對齊度,還通過減少對資源的依賴,提高了訓練過程的效率和可擴展性。
實驗
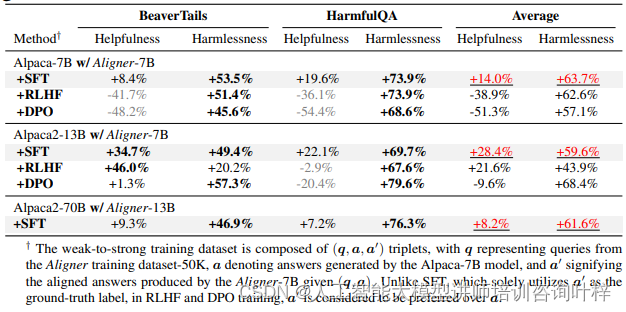
研究者選擇了兩個不同的數據集來進行評估:BeaverTails和HarmfulQA。這兩個數據集被用來檢驗Aligner在不同情境下的表現,以及它如何提升模型輸出的有用性和無害性。
實驗設置中,研究者特別關注了兩類模型:基于API的模型和開源模型。對于API基礎模型,他們選擇了GPT-4和Claude 2,這兩種模型都通過API提供服務,并且具備強大的語言處理能力。這些模型的表現將作為評估Aligner模塊效果的一個重要參考。
同時,研究者也包括了一系列開源模型,包括不同規模的Llama2模型(7B, 13B, 70B)-Chat版本、Vicuna系列(7B, 13B, 33B)以及Alpaca7B和Beaver-7B。這些模型因其開放的架構和可訪問性,為研究者提供了豐富的實驗選項。通過將Aligner模塊應用于這些模型,研究者可以觀察到Aligner在不同類型的語言模型上的表現,以及它如何幫助這些模型更好地符合人類的價值觀和意圖。
在實驗中,Aligner模塊被集成到了上述模型中,以評估其對模型輸出的影響。研究者特別關注了Aligner如何提升模型答案的有用性和無害性。有用性指的是模型輸出對用戶問題的正面幫助程度,而無害性則涉及模型輸出是否避免了可能對用戶或社會造成傷害的內容。
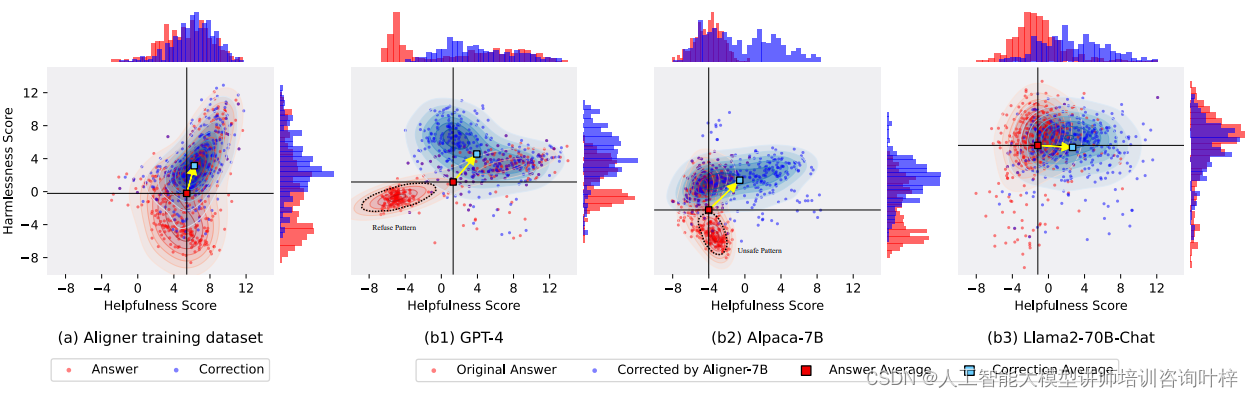
實驗結果顯示,Aligner模型作為一種有效的對齊工具,它能夠跨不同類型和規模的語言模型工作,提升模型輸出的質量和安全性。這些發現證明了Aligner模型在實際應用中的潛力,尤其是在需要提升語言模型對齊度的場景中。
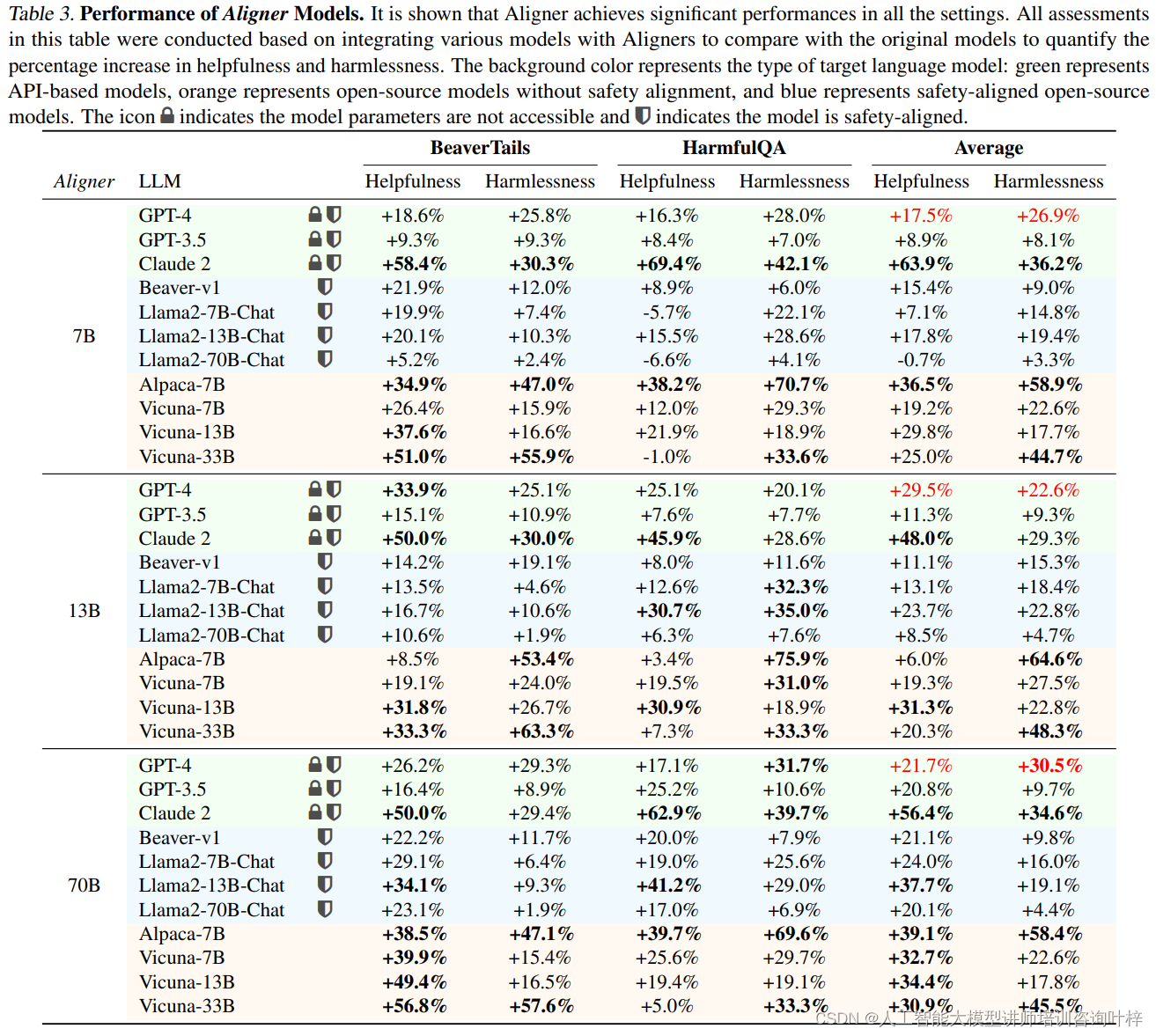
表3顯示Aligner在所有設置中都取得了顯著的效果。研究者通過將各種模型與Aligner集成,并與原始模型進行比較,來量化有用性(helpfulness)和無害性(harmlessness)的百分比提升。表格中的背景顏色代表了目標語言模型的類型:綠色代表基于API的模型,橙色代表未進行安全對齊的開源模型,藍色代表進行了安全對齊的開源模型。表格中使用了特定的圖標來指示模型參數是否可訪問,以及模型是否進行了安全對齊。
表3的評估結果是基于Aligner模型與不同上游模型的集成來進行的。這些上游模型包括了不同規模和類型的語言模型,如GPT-4、Claude 2、Llama2-7B-Chat、Vicuna-7B等。通過將Aligner模型集成到這些上游模型中,研究者能夠觀察到在有用性和無害性方面的顯著提升。例如,Aligner-7B在提升GPT-4的有用性方面提高了17.5%,在無害性方面提高了26.9%。
表3還展示了Aligner模型在不同類型的模型上的應用效果,這包括了API基礎模型和開源模型。對于API基礎模型,即使模型參數不可訪問,Aligner作為一個即插即用的模塊,也能夠顯著提升模型的性能。而對于開源模型,無論是已經進行了安全對齊的模型,還是未進行安全對齊的模型,Aligner都能夠提供性能上的增強。
研究者還進行了消融實驗。消融研究顯示,與自我改進/自我批評方法相比,Aligner在有用性和無害性方面均表現優越。此外,與RLHF/DPO/SFT等基線方法相比,Aligner在減少計算資源的同時,提供了可比或更好的改進。
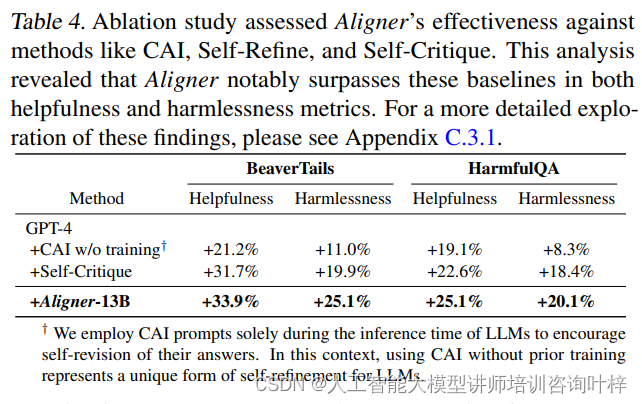
消融研究中使用了BeaverTails和HarmfulQA兩個數據集來進行評估。在這些實驗中,研究者將CAI提示僅在大型語言模型(LLMs)的推理時使用,以鼓勵模型自我修正答案。這種不經過預先訓練而直接使用CAI提示的方法,代表了一種獨特的自我完善形式。而Self-Critique方法則是讓模型自我批評,以發現并改進答案中的缺陷。
實驗結果顯示,使用CAI和Self-Critique方法時,GPT-4模型在有用性和無害性上的提升分別為+21.2%/+11.0%和+31.7%/+19.9%。然而,當使用Aligner-13B模型時,這些指標的提升更為顯著,達到了+33.9%/+25.1%和+25.1%/+20.1%。這表明Aligner模型在提升模型輸出的質量和安全性方面,具有明顯的優勢。
Aligner作為一種新興的大型語言模型對齊范式,展示了在資源效率、訓練簡便性和模型泛化能力方面的重要優勢。隨著進一步的研究和開發,Aligner有望在確保AI系統與人類價值觀和意圖一致方面發揮關鍵作用。
論文地址:https://arxiv.org/abs/2402.02416
項目地址:https://aligner2024.github.io


)
)

---PTA實驗C++)

main函數執行之前和之后的動作)




)



)
)

