MQ分類
Acitvemq
kafka
優點:性能好,吞吐量高百萬級,分布式,消息有序
缺點:單機超過64分區,cpu會飆高,消費失敗不支持重試 ,
Rocket
阿里的mq產品
優點:單機吞吐量也很高10w級,分布式,可做到消息9丟失
缺點:支持的客戶端語言不錯
RabbitMQ
優點:高并發,吞吐量萬級,基于AMQP(高級消息隊列協議),支持多語言
缺點:商業版收費
MQ選擇 :
Kafka :日志采集首選kafka ,適合大量數據的場景
ROcket :適合可靠性高的場景,電商等
RabbitMQ :性能時效 微妙級,數據量沒有太大可以使用,功能比較完備
RabbitMQ是什么
RabbitMQ是一個開源的消息代理和隊列服務器,用來通過普通協議在不同的應用之間共享數據(跨平臺跨語言)。RabbitMQ是使用Erlang語言編寫,并且基于AMQP協議實現。
AMQP協議
AMQP(Advanced Message Queuing Protocol)是一種開放標準的消息隊列協議,它定義了消息的傳遞格式、消息模型和交互協議,用于在應用程序之間可靠地傳遞消息。
下面是AMQP協議的一些關鍵特點和核心概念:
消息模型:
生產者(Producer):發送消息的應用程序。
消費者(Consumer):接收和處理消息的應用程序。
代理(Broker):負責消息的路由和傳遞的中間件組件。
消息傳遞:
消息(Message):AMQP協議中的基本單元,包含消息頭和消息體。消息頭包括元數據信息,如消息ID、時間戳、優先級等。消息體則包含實際的數據。
隊列(Queue):用于存儲消息的容器。消費者從隊列中接收消息,生產者將消息發送到隊列中。
交換器(Exchange):接收生產者發送的消息,并將其路由到一個或多個隊列。交換器根據預定義的規則(路由鍵)將消息發送給相應的隊列。
綁定(Binding):將隊列和交換器關聯起來,定義了消息從交換器到隊列的路由規則。
路由模型:
直連交換器(Direct Exchange):根據消息的路由鍵將消息發送到與之完全匹配的隊列。
主題交換器(Topic Exchange):根據消息的路由鍵模式將消息發送到與之匹配的隊列。路由鍵可以使用通配符進行匹配。
扇形交換器(Fanout Exchange):將消息廣播到與之綁定的所有隊列,忽略路由鍵。
可靠性和事務:
消息確認機制:AMQP支持生產者確認機制,生產者可以等待來自代理的消息確認,確保消息已被成功接收和處理。
事務支持:AMQP支持事務機制,生產者可以將一組消息放在一個事務中發送,保證這些消息要么全部成功發布,要么全部回滾。
RabbitMQ的優勢:
**可靠性(Reliablity):**使用了一些機制來保證可靠性,比如持久化、傳輸確認、發布確認。
**靈活的路由(Flexible Routing):**在消息進入隊列之前,通過Exchange來路由消息。對于典型的路由功能,Rabbit已經提供了一些內置的Exchange來實現。針對更復雜的路由功能,可以將多個Exchange綁定在一起,也通過插件機制實現自己的Exchange。
**消息集群(Clustering):**多個RabbitMQ服務器可以組成一個集群,形成一個邏輯Broker。
**高可用(Highly Avaliable Queues):**隊列可以在集群中的機器上進行鏡像,使得在部分節點出問題的情況下隊列仍然可用。
多種協議(Multi-protocol):支持多種消息隊列協議,如STOMP、MQTT等。
多種語言客戶端(Many Clients):幾乎支持所有常用語言,比如Java、.NET、Ruby等。
管理界面(Management UI):提供了易用的用戶界面,使得用戶可以監控和管理消息Broker的許多方面。
跟蹤機制(Tracing):如果消息異常,RabbitMQ提供了消息的跟蹤機制,使用者可以找出發生了什么。
插件機制(Plugin System):提供了許多插件,來從多方面進行擴展,也可以編輯自己的插件。
RabbitMQ 對比 Kafka
1. 設計目標:
Kafka:Kafka是一個分布式的、高吞吐量的發布/訂閱消息系統,旨在處理大規模的實時數據流。它特別適合用于日志處理、指標收集、流處理等場景。
RabbitMQ:RabbitMQ是一個開源的、可靠的企業級消息隊列系統,旨在支持各種消息傳遞模式,如點對點、發布/訂閱、請求/響應等。它適用于異步通信、任務隊列、事件驅動等應用。
2. 架構:
- Kafka:Kafka采用分布式、分區、復制的架構。消息以主題(topics)的形式進行組織,每個主題可以分為多個分區(partitions),并且每個分區可以有多個副本(replicas)。Kafka的消息存儲采用持久化日志(log)的方式,允許高效的順序讀寫。
- RabbitMQ:RabbitMQ基于AMQP(Advanced Message Queuing Protocol)協議,采用中心化的架構。消息發送者將消息發送到交換器(exchange),交換器根據規則將消息路由到隊列(queue),消息接收者從隊列中接收消息。RabbitMQ支持多種消息傳遞模式,通過不同的交換器類型(如直連交換器、主題交換器、扇形交換器等)來實現。
3. 可用性和可靠性:
- Kafka**:Kafka通過分區和副本機制提供了高可用性和容錯性。每個分區都有一個主副本(leader)和多個副本(follower),當主副本發生故障時,可以從副本中選舉出新的主副本。此外,Kafka還支持數據復制和持久化,確保消息不會丟失**。
- RabbitMQ:RabbitMQ通過消息確認機制和持久化存儲來保證消息的可靠性。發送者可以通過等待接收到確認消息來確保消息已經成功發送到隊列中,并且可以將消息標記為持久化,以防止消息在服務器故障時丟失。
4. 性能:
**- Kafka:Kafka的設計目標之一是高吞吐量和低延遲。**它通過順序寫磁盤、零拷貝技術和批量壓縮等方式來提高性能,并且能夠處理大規模的消息流。
- RabbitMQ:RabbitMQ的性能較Kafka略低,但對于大多數應用場景來說已經足夠。它使用內存緩沖區來提高性能,并且支持消息預取和持久化等機制。
5. 生態:
- Kafka:Kafka擁有豐富的生態系統,廣泛應用于大數據領域。它與Hadoop、Spark等工具集成緊密,可用于數據管道、流處理、日志收集等場景。
- RabbitMQ:RabbitMQ也有一定的生態系統,適用于各種企業應用。它提供了多種語言的客戶端庫,并且易于與其他系統集成,可用于任務分發、事件驅動、微服務架構等。
6.應用場景
ps(Kafka和RabbitMQ的使用場景并不是互斥的,有些場景可能兩者都可以勝任。選擇合適的消息傳遞系統應該根據具體的需求、系統架構和團隊技術棧來進行評估和決策。)
kafka的使用場景:
數據流處理:Kafka適用于處理大規模的實時數據流。它可以接收和傳輸大量的數據,支持高吞吐量和低延遲。這使得Kafka在大數據處理、流式數據分析和實時監控等領域非常有用。
**日志收集和聚合:**Kafka的持久化日志特性使其成為一個理想的日志收集和聚合工具。它可以接收來自多個源的日志數據,并將其傳遞給日志處理系統,如ELK(Elasticsearch, Logstash, Kibana)堆棧,用于存儲、索引和分析日志。
RabbitMQ的使用場景:
異步任務處理:**RabbitMQ是一個可靠的消息隊列系統,適合用于處理異步任務。**應用程序可以將任務發布到RabbitMQ中,然后由消費者異步地處理任務。這樣可以有效地解耦和分離任務處理邏輯,提高系統的可伸縮性和可靠性。
**事件驅動架構:**RabbitMQ支持各種消息傳遞模式,如直連、主題和扇形交換器,以及消息路由和過濾等功能。這使得RabbitMQ成為構建事件驅動架構的理想選擇,應用程序可以通過發布和訂閱事件來實現松耦合的系統集成和通信。
**系統之間的數據同步:**RabbitMQ可以用作系統之間的數據同步工具。當一個系統產生數據更新時,可以將更新事件發布到RabbitMQ,然后其他系統訂閱這些事件并進行相應的數據同步操作。這種方式可以確保數據的一致性和可靠性。
RabbitMQ結構
四大核心 :生產者、 消費者、交換機、隊列

生產者發送消息流程:
1、生產者和Broker建立TCP連接。
2、生產者和Broker建立通道。
3、生產者通過通道消息發送給Broker,由Exchange將消息進行轉發。
4、Exchange將消息轉發到指定的Queue(隊列)
消費者接收消息流程:
1、消費者和Broker建立TCP連接
2、消費者和Broker建立通道
3、消費者監聽指定的Queue(隊列)
4、當有消息到達Queue時Broker默認將消息推送給消費者。
5、消費者接收到消息。
6、ack回復
RabbitMq 各組件功能
Broker:標識消息隊列服務器實體.
Virtual Host:虛擬主機。標識一批交換機、消息隊列和相關對象。虛擬主機是共享相同的身份認證和加密環境的獨立服務器域。每個Broker有多個vhost,每個vhost相互隔離
**RabbitMQ服務器,**擁有自己的隊列、交換器、綁定和權限機制。vhost是AMQP概念的基礎,必須在鏈接時指定,RabbitMQ默認的vhost是 /
Exchange:交換器,用來接收生產者發送的消息并將這些消息路由給服務器中的隊列。
Queue:消息隊列,用來保存消息直到發送給消費者。它是消息的容器,也是消息的終點。一個消息可投入一個或多個隊列。消息一直在隊列里面,等待消費者連接到這個隊列將其取走。
Banding:綁定,用于消息隊列和交換機之間的關聯。一個綁定就是基于路由鍵將交換機和消息隊列連接起來的路由規則,所以可以將交換器理解成一個由綁定構成的路由表。
Channel:信道,多路復用連接中的一條獨立的雙向數據流通道。信道是建立在真實的TCP連接內地虛擬鏈接,AMQP命令都是通過信道發出去的,不管是發布消息、訂閱隊列還是接收消息,這些動作都是通過信道完成。因為對于操作系統來說,建立和銷毀TCP都是非常昂貴的開銷,所以引入了信道的概念,以復用一條TCP連接。
Connection:網絡連接,比如一個TCP連接。
Publisher:生產者,也是一個向交換器發布消息的客戶端應用程序。
Consumer:消費者,表示一個從一個消息隊列中取得消息的客戶端應用程序。
Message:消息,消息是不具名的,它是由消息頭和消息體組成。消息體是不透明的,而消息頭則是由一系列的可選屬性組成,這些屬性包括routing-key(路由鍵)、priority(優先級)、delivery-mode(消息可能需要持久性存儲[消息的路由模式])等
RabbitMQ交換機
rabbitMQ有 四種類型的交換機:direct、fanout、topic、headers
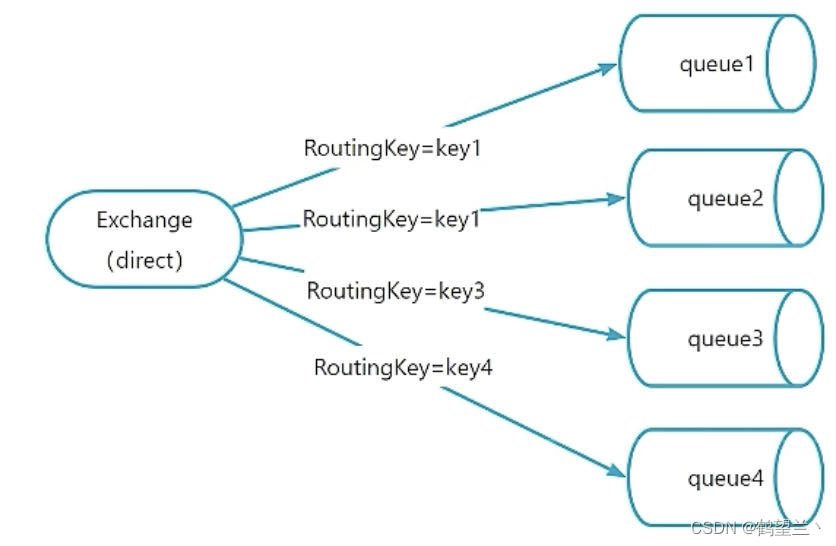
direct
路由鍵與隊列名完全匹配交換機, 此種類型交換機,通過RoutingKey路由鍵將交換機和隊列進行綁定,消息被發送到exchange時,需要根據消息的RoutingKey進行匹配
只將消息發送到完全匹配到此RoutingKey的隊列
比如:如果一個隊列綁定到交換機要求路由鍵為轉發 key 則不會轉發 key.1〞 。
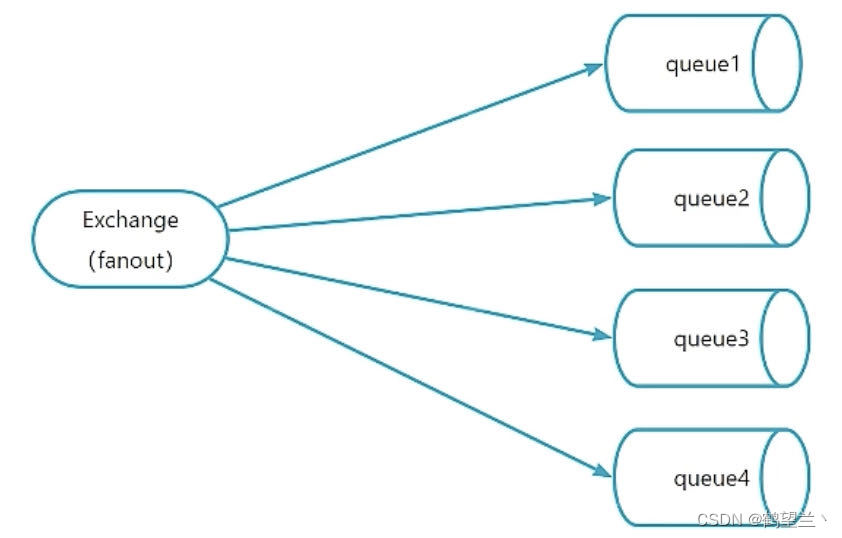
fanout
扇出類型交換機,此種交換機,會將消息分發給所有綁定了此交換機的隊列,此時RountingKey參數無效
Fanout類型交換機下發送一條,無論RoutingKey,queue1.queue2,queue3,queue4都可以收到消息
topic
主題類型交換機 :和direct類似,也是通過RountingKey匹配 ,但是 topic 是模糊匹配
1: topic中 將RountingKey 通過 “.” 來分為多個部分
2: “*”代表一個部分
3: “#” 代表0個或多個部分 (如果綁定的 路由鍵為 # 時,則接受所有消息,因為路由鍵所有都匹配)
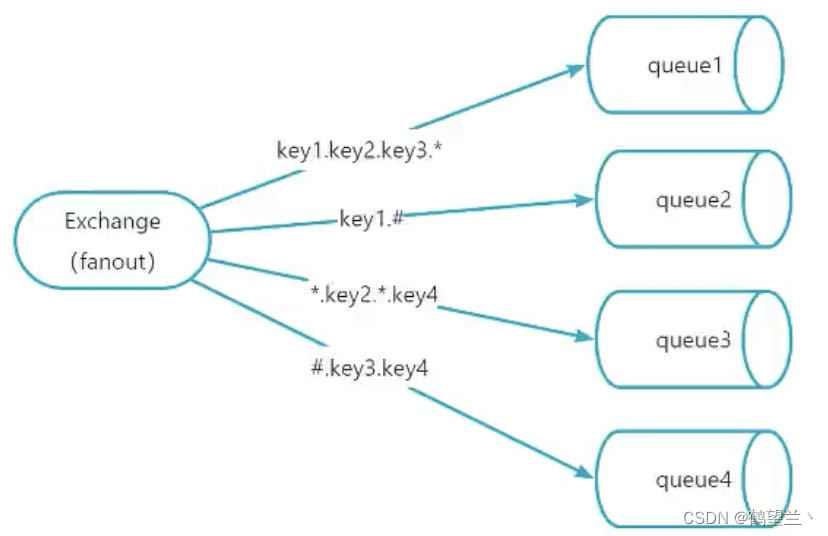
上圖中 :發送 key1.key2.key3.key4 則 queue 1 2 3 4 都可以匹配到
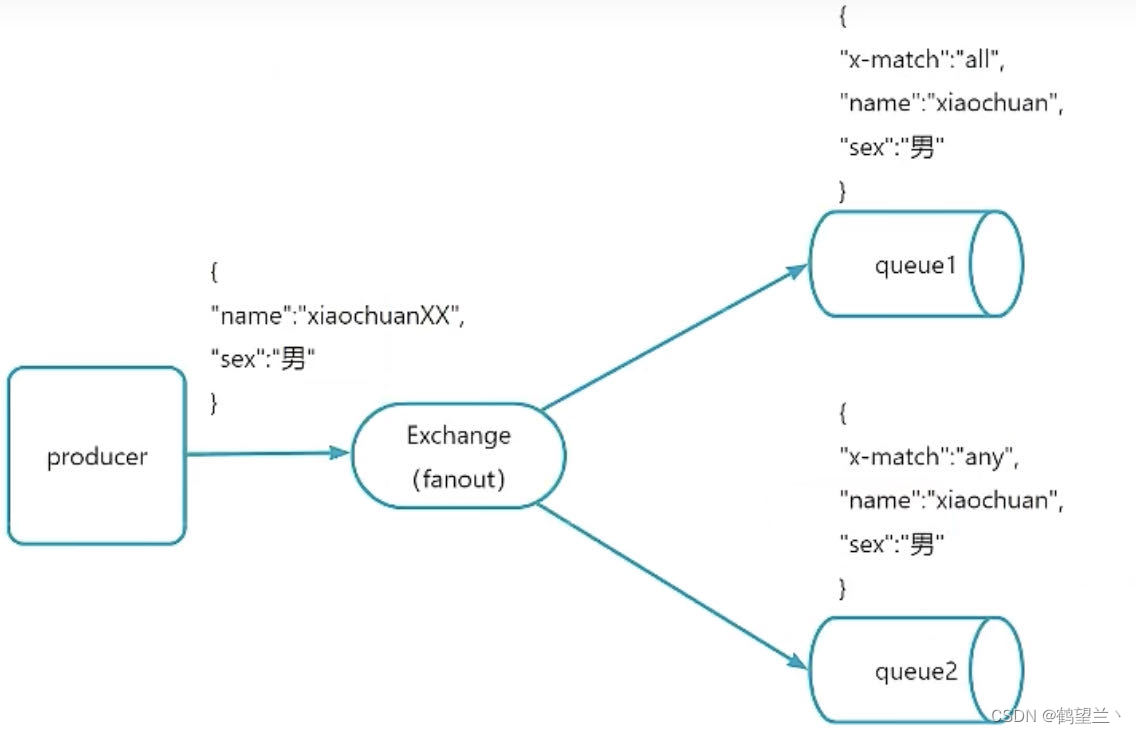
headers
header 匹配AMQP 消息的header 而不是路由鍵,此外 header和direct完全一只,但性能差很多
消費方指定 的 header中必須要有一個 x-match 鍵
x -match 鍵值 有兩個 :
x-match = all :所有的鍵值對都匹配才能接收到消息
x-match = any 任意鍵值對匹配就能接受到消息
Rabbit消息確認機制
生產者息確認機制
生產者通過 再 rabbit服務器上注冊 回調函數 來實現消息確認機制
當消息被生產者成功發送到 RabbitMQ 服務器并得到確認或未確認時,RabbitMQ 服務器將觸發確認回調。
在 RabbitMQ 中,確認回調通常是通過注冊一個回調函數來實現的。一旦生產者成功將消息發送到 RabbitMQ 服務器并收到確認或未確認的響應,RabbitMQ 服務器將調用已注冊的確認回調函數。
消費者消息確認機制
和生產者的消息確認機制不同,因為消息接收本來就是在監聽消息,符合條件的消息就會消費下來。
所以,消息接收的確認機制主要存在三種模式:
1、自動確認, 這也是默認的消息確認情況。 AcknowledgeMode.NONE
RabbitMQ成功將消息發出(即將消息成功寫入TCP Socket)中立即認為本次投遞已經被正確處理,不管消費者端是否成功處理本次投遞。
所以這種情況如果消費端消費邏輯拋出異常,也就是消費端沒有處理成功這條消息,那么就相當于丟失了消息。
一般這種情況我們都是使用try catch捕捉異常后,打印日志用于追蹤數據,這樣找出對應數據再做后續處理。
2、根據情況確認, 這個不做介紹
3、手動確認 ,
這個比較關鍵,也是我們配置接收消息確認機制時,多數選擇的模式。
消費者收到消息后**,手動調用basic.ack/basic.nack/basic.reject后**,RabbitMQ收到這些消息后,才認為本次投遞成功。
basic.ack用于肯定確認
basic.nack用于否定確認(注意:這是AMQP 0-9-1的RabbitMQ擴展)
basic.reject用于否定確認,但與basic.nack相比有一個限制:一次只能拒絕單條消息
消費者端以上的3``個方法都表示消息已經被正確投遞,但是basic.ack表示消息已經被正確處理。
RabbitMQ持久化
持久化消息:
消息的持久化需要滿足兩個條件:消息本身必須是持久化的,且消息所在的隊列必須是持久化的。
在發布消息時,通過將消息的 **delivery_mode 屬性設置為 2 來標記消息為持久化消息。**這個屬性告訴 RabbitMQ 服務器將消息寫入磁盤而不僅僅是存儲在內存中。
請注意,將消息標記為持久化并不能完全保證消息不會丟失。它只是確保在 RabbitMQ 服務器重啟后,消息能夠從磁盤中恢復。如果需要更高級別的消息可靠性保證,可以使用發布確認機制。
持久化隊列:
隊列的持久化需要在創建隊列時指定 durable 參數為 true。
當一個持久化隊列被創建時,RabbitMQ 服務器會將隊列的元數據(包括隊列的名稱、持久化標記等)存儲在磁盤上,以便在服務器重啟后能夠恢復隊列。
請注意,如果一個隊列已經被聲明為持久化隊列,那么后續對該隊列的操作也必須使用相同的參數,否則會引發錯誤。
交換機和綁定的持久化:
交換機和綁定的持久化與隊列的持久化類似。在創建交換機和綁定時,可以通過將參數 durable 設置為 true 來指定它們為持久化的。
持久化的交換機和綁定將在 RabbitMQ 服務器重啟后重新創建,以便恢復與持久化隊列之間的關系。
持久化日志文件:
RabbitMQ 使用持久化日志文件(transaction log)來記錄消息和元數據的變化。該日志文件存儲在磁盤上,并用于在服務器重啟后恢復消息和隊列的狀態。
持久化日志文件記錄了消息的發布、路由和傳遞過程,以及隊列和交換機的創建、綁定和刪除操作。
RabbitMQ 使用 **Write-Ahead Log(WAL)技術來確保持久化日志的可靠性,并將寫入磁盤的順序操作緩沖在內存中,**以提高性能。
WAL 索引:
RabbitMQ 使用 WAL 索引來提供快速的持久化日志訪問和檢索。 索引與持久化日志文件分開存儲
**索引用于追蹤消息的位置和偏移量,**以便在需要時快速定位和讀取特定的日志記錄。
**WAL 索引通常是基于 B+ 樹或其他高效的數據結構實現的,**以支持快速的插入、查找和范圍查詢操作。
索引通常包括日志記錄的偏移量、消息的標識符(如消息 ID 或交換機/隊列名稱)、記錄類型等信息。這些信息被用于在恢復時正確地解析和處理持久化日志文件。
恢復過程:
在 RabbitMQ 服務器啟動時,它會讀取存儲在磁盤上的持久化日志文件,并使用索引來重建消息和隊列的狀態。
通過讀取持久化日志文件中的日志記錄,并根據索引信息進行解析和處理,RabbitMQ 服務器可以恢復消息的發布、路由和傳遞過程,以及隊列和交換機的創建、綁定和刪除操作。
恢復過程中的索引可以加速日志文件的讀取和定位,從而提高恢復的性能和效率
RabbitMQ集群
集群優點:
消費者或生產者 在某個節點崩潰的情況下繼續運行
增加節點可以使我們的MQ 處理更多的消息,承載更多的業務量
搭建集群方式
1 從已經搭建好的RabbitMQ 中 克隆出兩臺機器
2 修改克隆機器的IP地址
3 修改三臺機器的 hostname(比如:node1,node2,node3)修改完重啟
4 修改三臺機器 host 文件
5 把第一個節點的cookie文件復制到另外兩臺機器上 ,確保公用同一個cookie
6 啟動RabbitMq服務,啟動Erlang虛擬機, RabbitMQ應用
鏡像隊列
雖然集群共享隊列,但默認情況下,消息只會被路由到某個符合條件的隊列,不會同步到其他節點,會有消息丟失的風險
隊列鏡像:鏡像隊列是主隊列的副本,分布在不同節點上,,消息就會被拷貝到處于同一個鏡像分組的所有隊列上
- Name:policy 的名稱
- Appliy to:指定該策略用于交換器還是隊列,或是兩者
- Pattern:一個用來匹配隊列或交換器的匹配模式(正則表達式)
- priority:可選參數,指定策略的優先級
- Definition:鏡像定義,包括三個部分 ha-mode, ha-params, ha-sync-modeha-mode:指明鏡像隊列的模式,有效值為 all/exactly/nodes
all:表示在集群中所有的節點上進行鏡像
exactly:表示在指定個數的節點上進行鏡像,節點的個數由 ha-params 指定
nodes:表示在指定的節點上進行鏡像,節點名稱通過 ha-params 指定ha-params:設置鏡像隊列的參數,根據 ha-mode 的取值,該 ha-params 的設置值有所不同。如果 ha-mode 為 all,則不使用該參數;如果 ha-mode 為 exactly,則為數字;如果 ha-mode 為 nodes,則為字符串列表。ha-sync-mode:進行隊列中消息的同步方式,有效值為 automatic(自動方式)和 manual(手動方式)。
slave 升級為 master
鏡像隊列 master 出現故障時,最老的 slave 會被提升為新的 master。如果新提升為 master 的這個副本與原有的 master 并未完成數據的同步,那么就會出現數據的丟失,
RabbitMQ 提供了ha-promote-on-shutdown,ha-promote-on-failure兩個參數讓用戶決策是保證隊列的可用性,還是保證隊列的一致性;
兩個參數分別控制正常關閉、異常故障情況下 slave 是否提升為 master
when-synced:從節點與主節點完成數據同步,才會被提升為主節點
always:無論什么情況下從節點都將被提升為主節




:和def __init__(self):的區別)

)


)



)
)

---PTA實驗C++)

main函數執行之前和之后的動作)
