節前,我們星球組織了一場算法崗技術&面試討論會,邀請了一些互聯網大廠朋友、參加社招和校招面試的同學。
針對算法崗技術趨勢、大模型落地項目經驗分享、新手如何入門算法崗、該如何準備、面試常考點分享等熱門話題進行了深入的討論。
合集:
持續火爆!!!《AIGC 面試寶典》已圈粉無數!
一、背景
最近兩年圖像生成領域受到廣泛關注,尤其是 Stable Diffusion 模型的開源,以及 DALL-E 系列模型的不斷迭代更是將這一領域帶到新的高度。
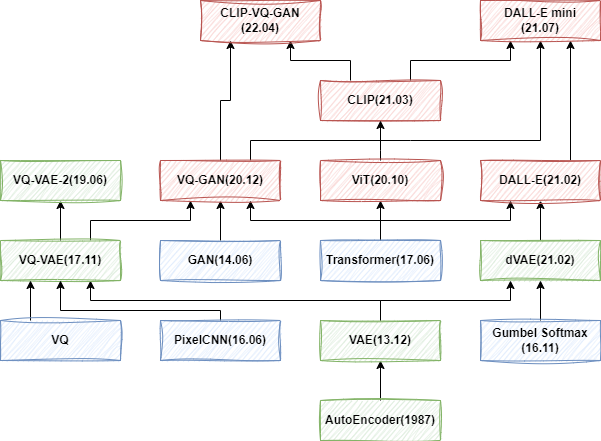
為了更好地理解 Stable Diffusion 以及 DALL-E 3 等最新的圖像生成模型,我們決定從頭開始,以了解這些模型的演化過程。在上一篇中我們簡單回顧了 VAE 系列生成模型的演進,但實際上當前大部分的文生圖模型已經轉向 Diffusion 模型。因此這個部分我們進一步介紹 Diffusion 系列模型。需要說明的是,由于篇幅原因,這里沒有具體介紹 Stable Diffusion 系列模型,以及 Google 的 Imagen 系列模型,作為本系列的下一個介紹。
二、引言
2.1. 摘要
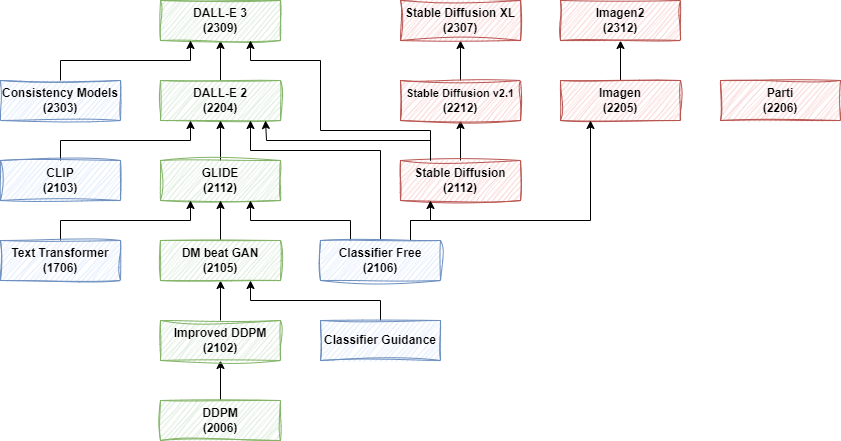
Diffusion 模型的第一篇工作是 [1503.03585] Deep Unsupervised Learning using Nonequilibrium Thermodynamics,發表于 2015 年,但是因為效果問題并沒有受到廣泛關注。直到 DDPM 的出現。如下圖所示,我們主要圍繞圖中綠色部分展開,以逐步了解 OpenAI 圖像生成模型的演進,同時也會部分介紹其應用到的 Classifier Guidance 和 Classifier Free Guidance 技術。
需要說明的是,OpenAI 早期的 Improved DDPM、DM beat GAN 和 GLIDE 相關模型還有開源實現,后續的 DALL-E 2 和 DALL-E 3 都沒有開源,甚至 DALL-E 3 的模型結構都沒有太多具體介紹。
此外,現在的文生圖模型已經變的越來越復雜,往往需要多個子模型組合使用,有些甚至使用了 5-6 個子模型。常見的有:
-
使用 CLIP 的 image decoder 和 text decoder 提取圖像、文本 embedding
-
使用 Transformer 模型對文本條件進行編碼
-
使用 U-Net 作為 Diffusion 模型用于圖像去噪生成
-
使用 Transformer 作為 Diffusion 模型,用于特征生成
-
使用 U-Net 作為上采樣模型,比如 64x64 -> 256x256,256x256 -> 1024x1024,并且往往是多級上采樣
2.2. 圖像生成評估指標
IS(Inception Score):用于評估生成圖像質量和多樣性的指標。它結合了兩個方面的考量:
-
生成圖像的真實性(真實圖像的概率,在對應類別上的概率應該盡量高)
-
生成圖像的多樣性(類別分布的熵,生成不同類別圖像應該盡量均勻)
IS 的計算方法包含兩個步驟:
-
首先,通過分類模型提取生成圖像在每個類別的概率分布。
-
然后,計算這些概率分布的 KL 散度,最終的 IS 是這些 KL 散度的指數平均值。
FID(Frechet Inception Distance):用于反應生成圖片和真實圖片之間的距離,數值越低越好。
FID 的計算方法包含兩個步驟:
-
首先,通過模型提取真實圖像和生成圖像的特征向量。
-
然后,計算這兩個特征向量分布之間的 Frechet 距離,也就是均值和協方差的 Frechet 距離。
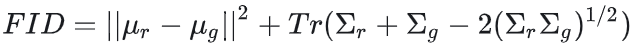
在實際使用中,通常使用 IS 來評估真實性,使用 FID 來評估多樣性。
三、Denoising Diffusion Probabilistic Models(DDPM)
3.1. DDPM 概述
擴散模型包含兩個過程:前向過程(Forward Process,也稱為擴散過程 Diffusion Process)和逆向過程(Reverse Process)。無論是前向還是逆向,都是一個馬爾科夫鏈形式(Markov Chain),其中前向過程是不斷地向圖片中添加高斯噪聲,逆向過程是不斷地去除高斯噪聲,重建圖像。對應的論文為:[2006.11239] Denoising Diffusion Probabilistic Models。
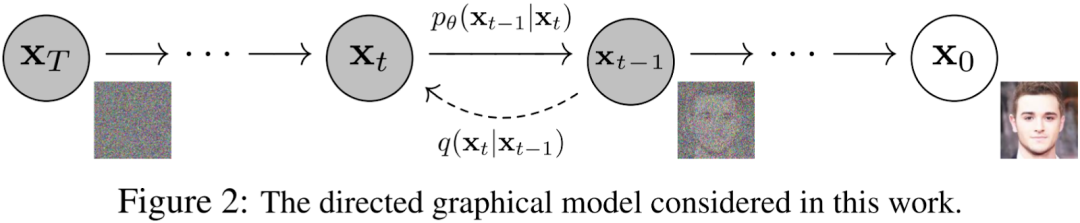
3.2. 擴散過程
如上圖 Figure 2 所示,擴散過程就是從右向左(X0 -> Xt-1 -> Xt -> XT)不斷添加高斯噪聲的過程。總共包含 T 步,其中 t-1 到 t 步的擴散可以表示為:
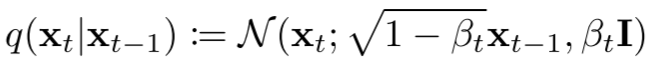
其中 βt 表示 t 步對應的方差,在論文中作者稱為 Variance Schedule,在有些工作中也稱為 Noise Schedule。βt 介于 (0, 1) 之間,并且通常會隨著 t 的增加而增大,也就是 β1 < βt-1 < βt < βT。
如下圖所示,整個擴散過程可以表示為:
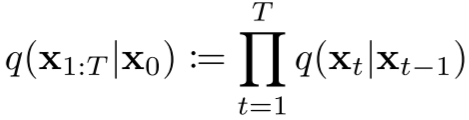
其中 q(x1:T|x0) 一般稱為近似后驗(Approximate Posterior)。此外,Variance Schedule 可以通過重參數化(Reparameterization)技術學習,也可以是固定的,DDPM 中作者采用預先定義好的線性 Variance Schedule,具體來說,β1=0.0001,βT=0.02,然后在此之間線性切分。
擴散過程的一個重要特性為:已知 x0,可以直接采樣任意時刻 t 加噪聲的圖像 xt,如下圖所示,其中,αt=1-βt:
如上所示,可以看出,任意時刻 t 的 xt 可以看做是原始圖像 x0 和隨機噪聲 ε0 的線性組合,并且組合系數的平方和為 1。同時,也就可以使用更直接的 t 定義 Variance Schedule。此外,這一特性在后續的訓練過程中非常有用。
3.3. 逆向過程
如上圖 Figure 2 所示,逆向過程就是從左向右(XT -> Xt -> Xt-1 -> X0)不斷去除高斯噪聲的過程。如果知道每一步的分布 p(xt-1|xt),那么就可以從隨機噪聲 XT 中逐漸恢復真實的圖像 X0。對應的聯合分布為:

其中第 t 步的分布 p(xt-1|xt) 為:

上述過程可以理解為,將 xt 作為輸入,預測相應高斯分布的均值和方差,再基于預測的分布進行隨機采樣,得到 xt-1,直到生成最終的圖片。
相應的可以推導出對應的均值和方差(此處不再推導,可以參考原文或者其他解讀),可以看出,此處的方差對應一個常數:


3.4. 模型訓練
最終的優化目標如下所示,表示希望模型學習到的均值 μθ(xt, t) 和后驗分布的均值 μt(xt, x0) 一致:
不過 DDPM 論文中說明相比預測均值,預測噪聲更加方便(有了噪聲之后直接減去噪聲即可實現去噪的目的),因此進一步得到最終的優化目標(包括重參數化等):

其中,εθ 表示需要擬合的模型。
DDPM 對應的優化目標很簡單,相應的訓練過程也很簡單,如下所示:
-
隨機選擇一個 batch 的訓練樣本
-
為 batch 中的每一個樣本都隨機生成一個步數 t(不同樣本相互獨立)
-
針對每個樣本都隨機產生一個噪聲 ε
-
輸入網絡計算損失
-
第 5 步括號內第 1 項就是前面說的擴散過程(加噪,直接在樣本 x0 的基礎上加,獲得 xt,不用迭代 t 步,效率更高)
-
損失為:生成的隨機噪聲與模型預測噪聲的差值
-
重復 1-4,直到收斂

3.5. 圖像生成
完成模型訓練之后就可以將其用于圖像生成,具體過程如下所示:
-
隨機產生一個噪聲 XT
-
令 t = T,…,1 逐步迭代
-
如果 t>1 則隨機采樣一個噪聲 z,如果 t=1,也就是最后一步,z=0
-
使用模型預測噪聲(對應紅框)
-
Xt 減去預測的噪聲
-
添加噪聲(對應藍框),這一部分可以參考 [1503.03585] Deep Unsupervised Learning using Nonequilibrium Thermodynamics P12。
-
結束迭代,返回結果 X0

3.6. 代碼實現
官方代碼倉庫為 GitHub - hojonathanho/diffusion: Denoising Diffusion Probabilistic Models,使用 TensorFlow 實現。
首先會使用 sinusoidal embedding 對時刻 t 進行編碼:

其模型采用 U-Net 結構:
-
時刻 t 的 embedding 會先經過兩個 Dense 層,然后在每一個 resnet_block 中與 h 相加(類似 position embedding,黑色部分)
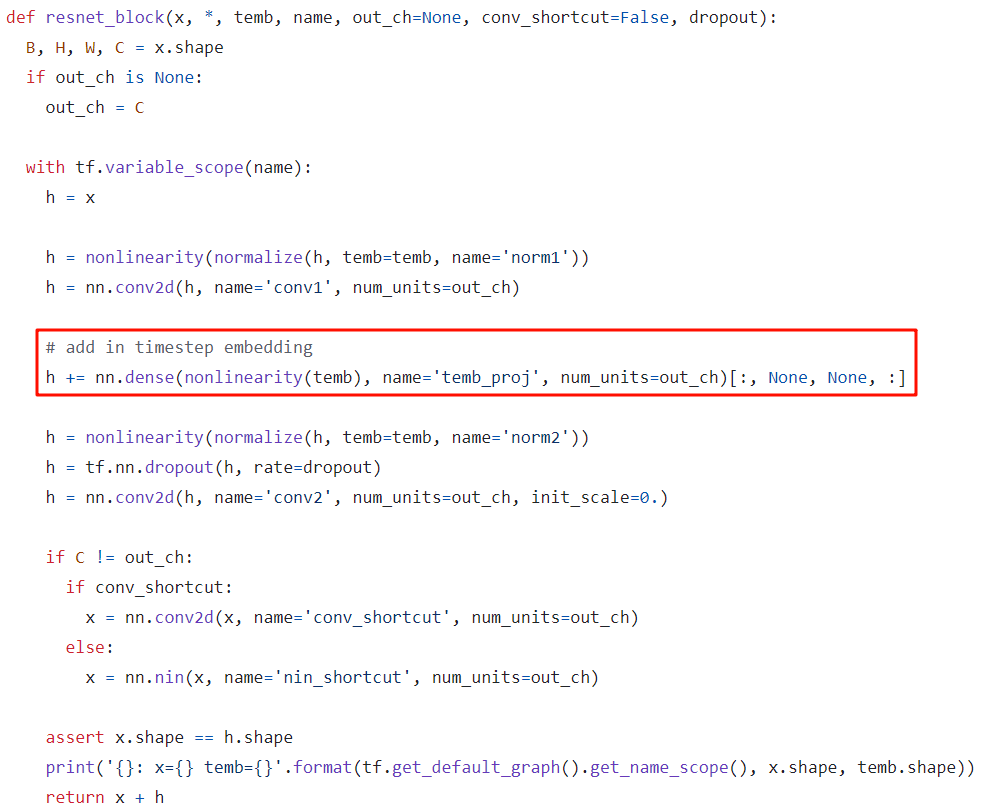
-
和常規 U-Net 一樣,在 Downsampling 和 Upsampling 中還會通過 Skip Connection 連接(下圖中藍色部分)
-
在部分 Stage 間還會引入 Attention Block(下圖綠色部分)
如下所示為采樣生成過程:
四、Improved DDPM(IDDPM)
4.1. IDDPM 概述
IDDPM 對應的論文為:[2102.09672] Improved Denoising Diffusion Probabilistic Models,對應的代碼庫為:GitHub - openai/improved-diffusion: Release for Improved Denoising Diffusion Probabilistic Models。這是 OpenAI 的工作,其相比 DDPM 的主要改進包括:加入可學習的方差,調整了加噪方式。
4.2. 可學習方差
如下圖所示,在 DDPM 中,作者將方差設置為常數,并且實驗發現在兩種極端情況下獲得了相似的結果。

而 IDDPM 中,作者認為其生成效果差不多,并不代表對對數似然沒有影響,并通過實驗進行了一些驗證,也同時提出了可學習的方差(模型會額外輸出一個向量 v,用于預測方差):

并把其加入到損失中,對應 λ=0.001,主要是避免 Lvlb 對 Lsimple 影響太大:

其中,Lvlb 表示變分下界損失(variational lower bound),如下所示:

4.3. 加噪方案
IDDPM 作者認為 DDPM 的加噪方式會導致早期階段加噪過快,因此提出了 cosine schedule 的加噪方式,公式如下所示:

如下圖 Figure 3 和 Figure 5 所示,本文的 cosine schedule 加噪(Figure 3 下部分)更加緩慢:


4.4. 減少梯度噪聲
IDDPM 的作者發現優化 Lvlb 比較困難,可能是因為梯度噪聲比較大,因此采用了重要性采樣方案,如下圖 Figure 6 所示為相應的對比實驗,綠色為加了重要性采樣后的損失,穩定了很多:

五、Diffusion Model Beat GANs
5.1. 概述
這也是 OpenAI 的工作,對應的論文為:[2105.05233] Diffusion Models Beat GANs on Image Synthesis。對應的代碼庫為:GitHub - openai/guided-diffusion。
本文的工作主要有兩點:
-
驗證了無條件圖像生成中不同模型結構對效果的影響,進行了大量的消融實驗。
-
引入 classifier guidance 來提升生成質量。
5.2. 模型結構改進
對模型結構的修改主要由以下幾個方面:
-
保持模型大小不變,增加深度,降低寬度
-
增加 Attention 頭的數量
-
不只是在 16x16 分比率使用 Attention,在 32x32 和 8x8 也使用
-
在上采樣和下采樣激活時使用 BigGAN 的 residual block
-
在 residual connection 中采用 1/sqrt(2) 的縮放
如下圖 Table 1 所示為不同配置的影響,可以看出,使用更多的 Attention 頭、在多個分辨率使用 Attention 以及采用 BigGAN 的 residual block 獲得了最好的結果:

5.3. Classifier Guidance
在 GAN 的有條件生成中,通常會將圖像的類別標簽作為條件,來引導獲得更好的生成效果。受此啟發,作者設計了將類別信息引入擴散模型進行圖像生成的算法。為了避免引入類別信息導致有新的類別還需重新訓練擴散模型,作者采用了解耦類別信息的方式,也就是額外訓練一個分類模型,并使用其引導生成過程。
如下圖 Table 4 所示為有無條件、有無類別引導的結果:

5.4. Upsampling Diffusion Model
本文中,作者同樣訓練了上采樣擴散模型,分別將分辨率從 64x64 擴展到 256x256,以及從 128x128 擴展到 512x512,具體模型配置如下所示:

5.5. 結果
如下圖 Table 5 所示,作者對比了本文方案的效果與之前模型的效果,其效果已經超越之前效果很好的 StyleGAN2,這也是本文標題的來源,此外,作者把本文的模型稱作 ADM,在后續的工作中也會使用:

六、Classifier Free Guidance
6.1. 概述
在 Diffusion Model Beat GANs 中使用了 Classifier Guidance 的方式,其需要額外訓練一個分類模型,相應的代價比較高。隨后越來越多的工作開始采用 Classifier Free Guidance 的方式。主要工作來自兩篇論文:[2106.15282] Cascaded Diffusion Models for High Fidelity Image Generation 和 [2207.12598] Classifier-Free Diffusion Guidance。OpenAI 后續的工作也開始采用 Classifier Free 的方案,比如 Glide 和 DALL-E 2 等模型。
6.2.方法
Classifier Guidance 方式存在以下幾個問題:
-
需要額外訓練一個分類器,使生成模型的訓練 Pipeline 更加復雜。
-
分類器必須在噪聲數據上進行訓練,也就無法使用預訓練好的分類器。
-
需要在采樣期間將分數估計值和分類器梯度混合在一起,其可能是欺騙性的提高了基于分類器的指標,比如 FID 和 IS。
Classifier Free Guidance 的核心思想為:不是沿著圖像分類器的梯度方向進行采樣,而是聯合訓練有條件擴散模型和無條件擴散模型,并將它們的分數估計值混合在一起,通過調整混合權重,可以實現與 Classifier Guidance 類似的 FID 和 IS 之間的平衡。
訓練過程中如下圖所示,隨機的移除條件,也就相當于無條件生成(通常有條件生成和無條件生成都是同一個模型,或者說共享模型權重):

如下圖所示,生成過程中同時使用有條件和無條件生成,并使用權重 w 來控制兩者的強度:
-
w 越大,有條件生成作用越大,圖像越真實(IS 分數越高)
-
w 越小,無條件生成作用越大,圖像多樣性越好(FID 分數越低)

6.3.示例
如下圖 Table 1 所示,w 越小,FID 分數越低,也就是多樣性越好,w 越大,IS 越高,也就是質量越高:

如下圖 Figure 1 所示,左側為無條件生成,右側為 w=3.0 的有條件生成,可以看出右側相似性比較高,也就是多樣性差點,但是質量更高:

七、GLIDE
7.1. 概述
本文中,作者將 Diffusion 模型應用于文本條件圖像生成,并比較了兩種不同的引導策略:CLIP Guidance 和 Classifier Free Guidance。評估發現,人類更喜歡 Classifier Free 的方式,因為其生成的圖像真實性更高,并且與描述更貼切。基于此,作者訓練了一個 3.5B 的文本條件 Diffusion 模型(使用了 Classifier Free Guidance)。此外,作者發現,經過微調可以很方便的將模型應用于圖像修復(inpainting),以及文本驅動的圖像編輯(editing)。
對應的論文為:[2112.10741] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models。
對應的代碼庫為:GitHub - openai/glide-text2im: GLIDE: a diffusion-based text-conditional image synthesis model。
7.2. 模型結構
GLIDE 主要包含兩個子模型:
-
文本條件+擴散模型(3.5B)
-
Text encoding Transformer(1.2B,24 個 residual block,width 2048)。
-
擴散模型(64x64 分辨率,2.3B),采用 Diffusion Model Beat GANs 中的 ADM(Ablated Diffusion Model), width 擴展到 512 channels,并在此基礎上擴展了文本條件信息。
-
文本條件+上采樣模型(1.5B)
-
和上一步類似的 Text Transformer 模型,不過 width 從 2048 降低到 1024
-
上采樣模型同樣來自 ADM-U(分辨率從 64x64 擴展到 256x256,channel 從 192 擴展到 384)
首先將文本經過 Tokenizer,轉換為 K 個 Token 序列,然后輸入 Text Transformer 模型,得到 K 個 embedding 向量,這些向量有兩個用途:
-
最后一個 Token embedding 用作 ADM 模型的 class embedding。
-
所有 Token embedding 經過一個投影層后輸入擴散模型的每一個 Attention 層,與 Attention 層的上下文拼接到一起。
7.3. Classifier Free Guidance
與 Classifier Free 中的類別引導類似,作者在訓練中會隨機的令文本條件為空。在采樣生成時,模型輸出可以沿著有條件方向進一步外推,而遠離無條件方向,如下所示,其中 s 為引導尺度因子(s >= 1):

Classifier Free 方案有兩個好處,首先,其允許單個模型在引導期間利用自己的知識,而不用額外訓練一個小的分類模型。此外,對于難以用分類器預測的信息(如,文本)進行條件處理時,可以簡化引導。
7.4. 訓練和推理
作者采用和 DALL-E 完全相同的數據來訓練本文的模型。訓練 base 模型時 batch size 為 2048,訓練了 2.5M 個 step;訓練上采樣模型時 batch size 為 512,訓練了 1.6M step。訓練代價與 DALL-E 相當。
未優化模型的推理代價很高,在 A100 GPU 上生成一個圖像要將近 15 秒,比相關的 GAN 模型慢了很多。
7.5. 示例
如下圖所示為一些示例,可以看出 GLIDE 生成的結果更加真實,質量更高:

八、DALL-E 2
8.1. 概述
在 GLIDE 中嘗試了文本引導圖像生成,取得了不錯的結果。在本文中,作者充分利用強大的 CLIP 模型,提出了一個兩階段圖像生成模型:
-
Prior:給定文本描述,生成 CLIP 圖像嵌入的先驗模型
-
Decoder:以圖像嵌入為條件生成圖像的模型
實驗表明,顯式的生成圖像嵌入可以在圖片真實性和文本描述相關性損失最小的情況下提高生成圖像的多樣性。Decoder 以圖像嵌入作為條件,可以產生各種圖像變體,同時保留其語義和風格,只改變非必要的細節。此外,CLIP 的聯合嵌入空間能夠以 0-shot 的方式實現文本引導圖像編輯。
對應的論文為:[2204.06125] Hierarchical Text-Conditional Image Generation with CLIP Latents。
DALL-E 2 的模型并沒有開源,不過開源社區的工作者參考論文的介紹復現了一個實現,對應的代碼庫為:GitHub - lucidrains/DALLE2-pytorch: Implementation of DALL-E 2, OpenAI’s updated text-to-image synthesis neural network, in Pytorch
8.2. 方法
整體的模型結構如下圖 Figure 2 所示:
-
img encoder:對應 CLIP 模型的 image encoder,給定圖像,并生成圖像 embedding zi,這個 embedding zi 在訓練中用于 prior 生成的 target,也就是訓練中 prior 生成的 embedding 要與 CLIP img encoder 生成的 embedding 盡量相似。訓練中 img encoder 保持凍結,推理生成階段不再需要 img encoder。
-
text encoder:用于在訓練階段和圖像生成階段對文本進行編碼,生成 embedding zt,作為 prior 的輸入。訓練和推理階段都需要 text encoder,并且始終保持凍結。
-
prior:用于從文本 embedding zt 生成圖像 embedding zi。
-
decoder:用于從圖像 embedding zi 生成最終圖像(文本條件為可選項)。

8.3. Decoder
作者同樣使用擴散模型來生成圖像,并將 Prior 生成的圖像 embedding zi 作為條件,同樣也可以選擇性地把文本描述作為條件。
此處的 Decoder 實際是 GLIDE 模型的變體,具體來說,將 zi 投影并添加到現有的時間步長 embedding 中,并將 zi 投影到 4 個額外的上下文 Token 中,這些 Token 會拼接到 GLIDE 文本 encoder 的輸出 Token embedding 序列中。作者保留了 GLIDE 模型中的文本條件通路,假設它可以讓擴散模型學習 CLIP 無法捕獲的自然語言知識,但發現其幾乎沒有幫助。
作者同樣使用了 Classifier Free Guidance 技術,具體來說,在訓練期間,10% 的時間將 CLIP 嵌入隨機設置為 0,50% 的時間隨機丟棄文本描述。
為了生成高分辨率圖像,作者同樣訓練了兩個上采樣擴散模型,一個將圖像從 64x64 上采樣到 256x256,另一個進一步將圖像從 256x256 上采樣到 1024x1024。為了提高上采樣模型的魯棒性,在訓練過程中會隨機破壞條件生成圖像。具體來說,在第一個上采樣階段,使用高斯模糊,在第二個上采樣階段,使用更多樣的 BSR 退化。為了降低訓練代價并提高數值穩定性,作者遵循 [2112.10752] Stable Diffusion 的方式,隨機裁剪一個 1/4 目標大小的圖像進行訓練,由于模型中只包含空間卷積(沒有 Attention 層),因此可以在推理階段直接生成目標大小的圖像,也很容易推廣到更高分辨率的圖像。此外,作者發現使用文本描述作為上采樣模型的條件并沒有什么幫助,因此使用了無條件、無引導的 ADMNets(和 GLIDE 一樣,來自 Diffusion Model Beat GAN)。
8.4. Prior
Prior 用于從文本 embedding zt 生成圖像 embedding zi。作者探索了兩種類型的 Prior 模型:
-
Autoregressive(AR)prior:類似 DALL-E 的方式,CLIP 圖像 embedding zi 被轉換為離散編碼序列,然后以文本描述 y 為條件自回歸生成圖像。
-
Diffusion prior:直接把圖像 embedding zi 作為目標,以文本描述 y 作為條件訓練高斯擴散模型。
除了文本描述 y 之外,也可以直接使用文本 embedding zt 作為 prior 的條件。為了提高采樣質量,作者在兩種 prior 中同樣采用了 Classifier Free Guidance 技術,也就是訓練期間的 10% 時間會隨機丟棄文本條件信息。
為了更高效的訓練和采樣 AR prior,作者通過主成分分析(PCA)來降低 CLIP 圖像 embedding zi 的維度。這是因為作者發現,當使用 SAM 訓練 CLIP 時,CLIP 表示空間的秩急劇下降,同時略微提升了評估指標。因此,作者僅保留 1024 個主成分中的 319 個也能幾乎保留全部信息。在應用 PCA 之后,作者進一步將 319 個 Token embedding 量化到 1024 個離散桶中,并使用帶有因果注意力掩碼的 Transformer 模型預測 Token 序列,這樣在推理期間可以將待預測 Token 減少 3 倍,并提高訓練穩定性。
對于擴散 prior,作者訓練了一個帶有因果編碼的 Decoder-only Transformer 模型(可能是因為要去噪的是圖像 embedding,可以表示為 Token 序列,而不是圖像本身,因此沒有采用 U-Net),其輸入序列包含以下幾個:
-
encoded text:編碼后的文本。
-
CLIP text embedding:CLIP 模型輸出的文本 embedding zt。
-
diffusion timestep embedding:時間步長對應的 embedding。
-
noised CLIP image embedding:其實也就是與輸出 shape 相同的隨機噪聲。
-
final embedding:類似 [CLS] Token embedding,包含前面的全部信息,可以用于去噪后的 CLIP image embedding zi。
為了提升采樣階段的生成質量,作者會同時生成兩個圖像 embedding zi,然后選擇一個與 zt 內積更大的(相似性更高)。同時,與 DDPM 中的結論(預測器用于預測噪聲,然后減去噪聲得到去噪圖像)不同,作者發現直接預測去噪圖像能夠獲得更好的效果。
8.5. 訓練
對于 CLIP 模型,作者采用了 ViT-H/16 的 image encoder,圖像分辨率為 256x256,包含 32 個 Transformer block,寬度為 1280。text encoder 也是 Transformer 模型,包含因果掩碼,共 24 個 Transformer block,寬度為 1024。訓練 encoder 時,作者使用相同的采樣率從 OpenAI CLIP 和 DALL-E 數據集(總共大約包含 650M 圖像)中采樣。訓練 prior、decoder 和 upsamplers 時僅使用了 DALL-E 數據集(包含大約 250M 圖像)。
Decoder 模型是 3.5B 的 GLIDE 模型,具有相同的結構和不同的超參數。對于上采樣 upsamplers 模型,則采用了 ADMNet 結構,第一階段采用 cosine noising schedule,也采用了高斯模糊(kernel size 3,sigma 0.6)。在第二階段,采用 linear noising schedule,應用了 BSR 退化。兩個階段都未使用 Attention。為了減少推理時間,作者采用了 DDIM,并手動調整 step 數目,對于 256x256 模型,steps 為 27,對于 1024x1024 模型,steps 為 15。
對應的超參如下所示:

8.6. 應用場景
如下圖 Figure 3 所示,可以根據輸入圖片生成大量風格類似圖片,并且保持主要元素相同,不太關鍵的信息各不相同:

如下圖 Figure 4 所示,可以用于圖像內插,輸入兩張圖像,生成跨兩幅圖像內容的圖像:

如下圖 Figure 5 所示,出來圖像和圖像內插外,還可以實現圖像和文本間的內插:

8.7. 局限性
如下圖 Figure 15 所示,模型還比較難將物體和屬性結合起來,可能會混淆不同物體的顏色(最左側提示為 “生成一個紅色方塊在藍色方塊之上”),此外也可能無法更好的重建相對的大小關系(作者猜測有可能是使用了 CLIP 模型的緣故):

如下圖 Figure 16 所示,作者同樣發現模型不能很好的在圖像上生成正確的文本(可能是因為 BPE 文本編碼的問題):

如下圖 Figure 17 所示,模型可能無法生成復雜的、包含很多細節的圖片:

九、DALL-E 3
9.1. 概述
DALL-E 3 是 OpenAI 新的文生圖模型,作者發現傳統的文生圖模型難以遵循詳細的圖像描述,并且經常出現忽略單詞或混淆提示的語義,作者猜測可能是訓練集中的噪聲或者不準確的圖像描述導致的。因此,作者首先訓練了一個圖像描述器,然后生成了一系列高度描述性的圖像描述,之后將其用于文生圖模型訓練,其大大提高了文生圖的指令跟隨能力。
但是,本文中關于模型結構、具體訓練方案的介紹卻非常少,也完全沒有提供開源實現。對應的論文為:Improving Image Generation with Better Captions。
如下圖所示為一個示例,其指令遵循能力確實很強大:

9.2. Image Captioner 模型
2023 年出現了很多大型多模態模型(LMM),其中最常見的任務就是圖像描述,常用的方式為通過 CLIP 類型的 image encoder 將圖像編碼為 Token embedding,然后輸入到 LLM decoder 中生成圖像描述,也獲得了不錯的效果。本文中,作者借鑒 Google [2205.01917] CoCa: Contrastive Captioners are Image-Text Foundation Models 的思路,創建了一個詳細的圖像描述生成模型。
CoCa 模型的思路比較簡單,在 CLIP 模型的基礎上額外增加一個 Multimodal Text Decoder,訓練中除了 CLIP 的對比損失(Contrastive Loss)外,也相應增加了描述損失(Captioning Loss)。

如下圖所示為 CoCA 模型的配置,至于 OpenAI 訓練的 Captioner 模型配置并沒有具體介紹:

9.3. Image Captioner 微調
為了改善圖像生成描述的質量,作者進一步對模型進行了微調,包括兩個方案:
-
短描述生成:作者首先構建了一個小型數據集,其中僅描述圖像中的主體,然后在這個數據集上微調上一步預訓練的 Captioner。
-
詳細描述生成:作者同樣構建了一個小型數據集,不過除了描述圖像的主體外,還會描述周圍環境、背景、圖像中的文本、樣式、顏色等。并再次微調 Captioner 模型。
如下圖所示為相應的結果,其中 Alt Text 為 Ground Truth,SSC 為短描述生成結果,DSC 為詳細描述生成結果。

9.4. Image Captioner 評估
作者進一步驗證了詳細描述對模型指令跟隨能力的影響。作者采用 CLIP score 作為評估標準,也就是使用 CLIP 分別提取圖像和文本描述的 embedding,然后計算相似性得分。如下圖所示,左側為使用 Ground Truth 文本訓練模型的效果,右側為混合了詳細描述后訓練的評估結果,可以看出 CLIP score 得到明顯改善:

那么混合多少的 Ground Truth 和詳細文本描述比較合理呢?作者進一步實驗驗證,發現混合 95% 的詳細文本描述獲得了最好的效果:

9.5. DALL-E 3 指令跟隨評估
作者進一步評估了不同模型的指令遵循能力(不涉及圖像質量),如下圖 Table 1 所示,DALL-E 3 獲得了最好的效果,并且提升非常明顯:

9.6. 模型結構
作者只在附錄中用很小的篇幅介紹了 DALL-E 3 的部分模型組件,包括 Image decoder 和 latent decoder。
如下圖所示,其 image decoder 參考了 Stable Diffusion 的實現,采用 3 階段的 latent diffusion 模型。
-
其 VAE 和 Stable Diffusion 一樣,都是 8x 的下采樣,訓練的圖像分辨率為 256x256,會生成 32x32 的隱向量。
-
時間步長條件:采用 GroupNorm,并學習了 scale 和 bias。
-
文本條件:使用 T5 XXL 作為 text encoder,然后將輸出的 embedding 和 xfnet 進行 Cross Attention。在 OpenAI 的 Paper 中并沒有找到 xfnet 相關介紹,不過在 GLIDE 的開源代碼里確實有 xf model。

如下圖所示,作者同樣訓練了一個 latent decoder,可以用來提升圖像細節,比如文本和人臉。其同樣是參考 Stable Diffusion 的實現。不過這個 diffusion decoder 采用的是 DDPM 中描述的空間卷積 U-Net,此外,也基于 [2303.01469] Consistency Models 的蒸餾策略將去噪步數降低到 2 步,極大降低推理代價。

十、參考鏈接(Reference)
-
https://arxiv.org/abs/2208.11970
-
https://keras.io/examples/generative/ddim/#diffusion-schedule
-
https://zhuanlan.zhihu.com/p/563661713
-
https://www.assemblyai.com/blog/how-dall-e-2-actually-works/
-
https://arxiv.org/abs/1503.03585
-
https://arxiv.org/abs/2006.11239
-
https://github.com/hojonathanho/diffusion
-
https://arxiv.org/abs/2102.09672
-
https://github.com/openai/improved-diffusion
-
https://arxiv.org/abs/2105.05233
-
https://github.com/openai/guided-diffusion
-
https://arxiv.org/abs/2106.15282
-
https://arxiv.org/abs/2207.12598
-
https://arxiv.org/abs/2112.10741
-
https://github.com/openai/glide-text2im
-
https://arxiv.org/abs/2204.06125
-
https://github.com/lucidrains/DALLE2-pytorch
-
https://arxiv.org/abs/2112.10752
-
https://cdn.openai.com/papers/dall-e-3.pdf
-
https://arxiv.org/abs/2205.01917








【非常適合初學者】)
代理互聯網服務提供商多賬戶使用案例)
)


: boost搜索引擎)


)


