1. cuda介紹
????????CUDA(Compute Unified Device Architecture,統一計算設備架構)是NVIDIA推出的一種并行計算平臺和編程模型。它允許開發者利用NVIDIA GPU的強大計算能力來加速計算密集型任務。CUDA通過提供一套專門的API和編程接口,使得開發者能夠編寫在GPU上運行的程序,從而實現大規模并行計算。
首先來看我們的 CUDA 程序代碼:
#include <stdio.h>
#include <iostream>
#include <cuda_runtime.h>
using namespace std;__global__ void hello_world(void) {printf("thread idx: %d\n", threadIdx.x);if (threadIdx.x == 0) {printf("GPU: hello_world\n");}
}int main(void) {printf("CPU: Hello world!\n");hello_world<<<1, 32>>>();cudaDeviceSynchronize();cudaError_t err = cudaGetLastError();if (err != cudaSuccess) {cerr << "CUDA error: " << cudaGetErrorString(err) << endl;} else { cout << "GPU: Hello world finished!" << endl; }cout << "CPU: Hello world finished!" << endl;return 0;
}這個程序雖然簡單,卻包含了 CUDA 編程的多個核心要素,讓我們逐一解析。?
1. CUDA 程序的特殊頭文件與命名空間?
????????CUDA(Compute Unified Device Architecture,統一計算設備架構)是NVIDIA推出的一種GPU編程組件,它是一種原生支持GPU編程的軟硬件架構。CUDA突破了過去必須通過圖形API來使用GPU計算能力的限制,使得開發者可以直接在GPU上編寫和執行通用計算程序。以下是CUDA技術棧的分層結構及其主要組成部分:
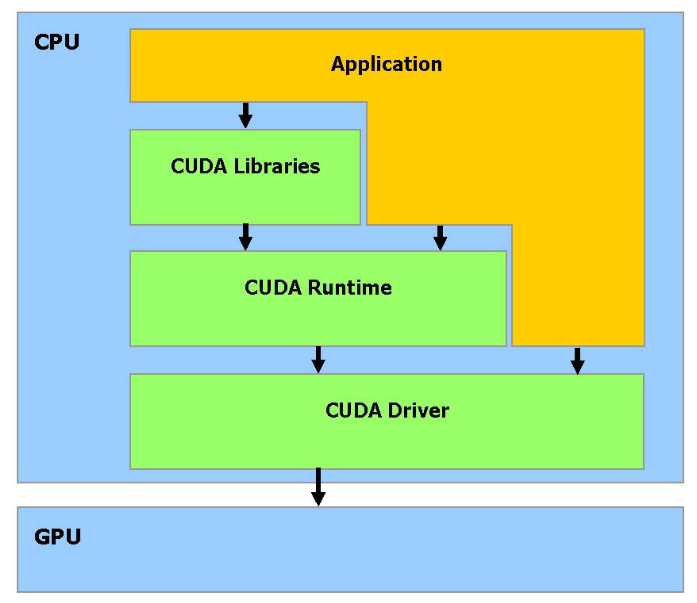
硬件驅動層(CUDA Driver)
功能:負責與GPU硬件通信,提供底層支持。
作用:作為硬件與軟件之間的橋梁,確保CUDA程序能夠正確地與GPU硬件交互。
應用編程接口(API)與運行時(Runtime)
功能:為開發者提供簡潔易用的編程接口和執行環境。
作用:簡化開發流程,使得開發者可以更高效地編寫和運行CUDA程序。
????????CUDA工具鏈中的核心組件之一,專門用于編譯含有CUDA C/C++擴展語法的源代碼文件(通常以.cu為擴展名)。編譯時需要使用nvcc hello_world.cu -o hello_world進行編譯
- #include <cuda_runtime.h>:這是 CUDA 運行時 API 的頭文件,包含了 CUDA 編程所需的各種函數聲明和數據類型定義,是 CUDA 程序必不可少的頭文件。?
- 標準 C++ 頭文件:stdio.h和iostream用于 CPU 端的輸入輸出操作,CUDA 程序可以無縫結合 C++ 標準庫使用。?
2. 核函數(Kernel Function)?
核函數是 CUDA 編程中最核心的概念,是在 GPU 上執行的函數,代碼中:?
__global__ void hello_world(void)?
- __global__:這是 CUDA 特有的函數修飾符,表明該函數是核函數。核函數有以下特點:?
- 在 CPU 上調用,在 GPU 上執行?
- 返回類型必須為 void?
- 可以通過特殊的執行配置符指定啟動的線程數量?
3. 核函數的調用方式?
核函數的調用方式與普通函數不同,需要使用特殊的執行配置符:?
hello_world<<<1, 32>>>();?<<<...>>>:這是 CUDA 特有的執行配置符,用于指定在 GPU 上啟動的線程數量和組織方式?
- 第一個參數1:表示啟動 1 個線程塊(block)?
- 第二個參數32:表示每個線程塊包含 32 個線程(thread)?
- 因此,這個配置總共在 GPU 上啟動了 1×32=32 個線程并行執行?
4. 線程的標識與索引?
在核函數中,我們可以通過threadIdx變量獲取當前線程在其所屬線程塊中的索引:?
printf("thread idx: %d\n", threadIdx.x);?
- threadIdx:是一個uint3類型的結構體,包含三個成員:x、y、z,分別表示線程在三維線程塊中的三個維度上的索引?
- 為什么設計成三維?這是因為許多實際問題(如 3D 圖形渲染、三維物理模擬等)具有天然的三維特性,三維索引可以更自然地映射這些問題?
- 在這個例子中,我們只使用了一維索引threadIdx.x,表示線程在 x 維度上的索引(范圍 0-31)?
5. CPU 與 GPU 的同步機制?
由于 CPU 和 GPU 是獨立的處理器,它們的執行是異步的。為了確保 CPU 等待 GPU 完成計算后再繼續執行,需要使用同步函數:?
cudaDeviceSynchronize();?
- 這個函數會阻塞 CPU 的執行,直到 GPU 完成所有之前提交的計算任務?
- 同步操作對于確保數據一致性和正確的執行順序非常重要?
6. CUDA 錯誤處理機制?
CUDA 操作可能會出現各種錯誤,良好的錯誤處理是編寫健壯 CUDA 程序的關鍵:?
cudaError_t err = cudaGetLastError();?if (err != cudaSuccess) {?cerr << "CUDA error: " << cudaGetErrorString(err) << endl;?}?- cudaGetLastError():獲取最近一次 CUDA 操作產生的錯誤代碼?
- cudaError_t:CUDA 錯誤類型,cudaSuccess表示操作成功?
- cudaGetErrorString():將錯誤代碼轉換為人類可讀的錯誤信息?
程序執行流程與結果分析?
當我們編譯并運行這個程序時,會得到類似以下的輸出:?
CPU: Hello world!
thread idx: 0
thread idx: 1
thread idx: 2
thread idx: 3
thread idx: 4
thread idx: 5
thread idx: 6
thread idx: 7
thread idx: 8
thread idx: 9
thread idx: 10
thread idx: 11
thread idx: 12
thread idx: 13
thread idx: 14
thread idx: 15
thread idx: 16
thread idx: 17
thread idx: 18
thread idx: 19
thread idx: 20
thread idx: 21
thread idx: 22
thread idx: 23
thread idx: 24
thread idx: 25
thread idx: 26
thread idx: 27
thread idx: 28
thread idx: 29
thread idx: 30
thread idx: 31
GPU: hello_world
GPU: Hello world finished!
CPU: Hello world finished!- 首先 CPU 輸出 "CPU: Hello world!"?
- 然后啟動 32 個 GPU 線程并行執行核函數?
- 每個線程輸出自己的索引值,其中索引為 0 的線程還會額外輸出 "GPU: hello_world"?
- 所有 GPU 線程執行完成后,CPU 輸出執行完成的信息?
需要注意的是,GPU 線程的執行順序是不確定的,因此線程索引的輸出順序可能每次運行都不同,這體現了并行計算的特性。?
2.?CUDA線程分層結構與執行模型
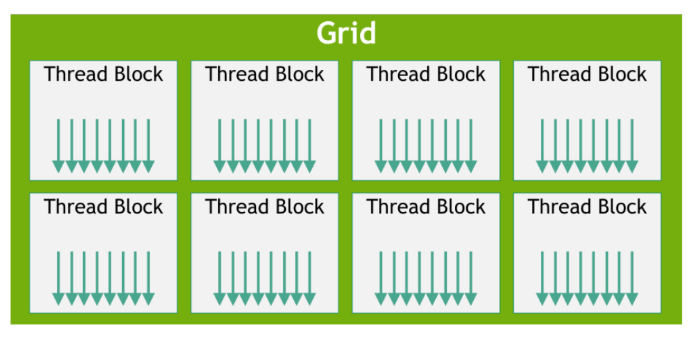
?????????在CUDA的執行模型中,線程是CUDA中最小的執行單元。多個線程可以組織成一個線程塊(Thread Block),而多個線程塊又組成一個網格(Grid)。
????????線程塊中的線程數量是有限制的,因為同一個線程塊內的所有線程必須運行在同一個流多處理器(Streaming Multiprocessor, SM)上,并共享該SM的有限資源(如寄存器、共享內存等)。
????????線程塊中的線程會以32個線程為一組進行調度(調度的時候受限于一個SM中的可用資源),這組線程被稱為線程束(Warp)。
????????線程束(Warp)是SM中最基本的執行單元。當一個線程塊被啟動后,其中的所有線程會被劃分成多個線程束,每個線程束包含32個線程。同一warp中的線程會同時執行相同的指令,但各自處理不同的數據,從而實現數據并行計算。
????????從執行模型中軟硬件的對應關系來看,我們可以清晰地看到前面介紹的三級線程分層結構:線程(Thread)→線程塊(Block)→網格(Grid)。
?示例:
#include <cstdio>
#define BLOCK_SIZE 256__global__ void vecAdd(int *A, int *B, int *C, int n) {int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n) {C[i] = A[i] + B[i];}
}int main() {int N = 10000;size_t size = N * sizeof(int);// 主機內存分配與初始化int *A = (int*)malloc(size);int *B = (int*)malloc(size);int *C = (int*)malloc(size);for (int i = 0; i < N; i++) {A[i] = i;B[i] = i * i; // 修正冪運算錯誤}// 設備內存分配int *d_A, *d_B, *d_C;cudaMalloc((void**)&d_A, size);cudaMalloc((void**)&d_B, size);cudaMalloc((void**)&d_C, size);// 主機到設備的數據拷貝cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);// 計算線程塊數量并啟動核函數int Num_Blocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;vecAdd<<<Num_Blocks, BLOCK_SIZE>>>(d_A, d_B, d_C, N);cudaDeviceSynchronize(); // 等待GPU完成計算// 設備到主機的數據拷貝(修正方向錯誤)cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);// 結果驗證for (int i = 0; i < N; i++) {if (C[i] != A[i] + B[i]) {printf("Error index: %d, Expected: %d, Got: %d.\n", i, A[i]+B[i], C[i]);}}printf("Vector addition completed successfully.\n");// 資源釋放free(A);free(B);free(C);cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);return 0;
}程序功能與整體架構?
這段代碼實現了兩個向量的逐元素加法(C [i] = A [i] + B [i]),其中:?
- 向量長度 N=10000?
- 使用 CPU 初始化輸入數據(A [i]=i,B [i]=i2)?
- 通過 GPU 并行計算實現向量加法?
- 最后在 CPU 端驗證計算結果?
程序采用了 CUDA 編程的標準流程:主機初始化→數據傳輸→GPU 計算→結果回傳→驗證釋放,這一流程是所有 CUDA 應用的基礎框架。?
核心技術點詳解?
1. CUDA 內存模型與數據傳輸?
CUDA 采用異構內存模型,CPU(主機)和 GPU(設備)擁有各自獨立的內存空間,程序中清晰體現了這一特性:
// 主機內存分配(CPU可訪問)
int *A = (int*)malloc(size);
int *B = (int*)malloc(size);
int *C = (int*)malloc(size);// 設備內存分配(僅GPU可訪問)
int *d_A, *d_B, *d_C;
cudaMalloc((void**)&d_A, size);
cudaMalloc((void**)&d_B, size);
cudaMalloc((void**)&d_C, size);- malloc:分配主機內存(Host Memory)?
- cudaMalloc:分配設備內存(Device Memory),注意其特殊的指針地址傳遞方式(void**)&d_A
數據傳輸通過cudaMemcpy實現,需要明確指定傳輸方向:?
// 主機到設備(Host → Device)
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);// 設備到主機(Device → Host)
cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);cudaMemcpy的參數遵循目標地址→源地址的順序,這是容易出錯的關鍵點,必須與傳輸方向參數匹配。?
2. 線程組織與索引計算?
CUDA 通過網格(Grid)- 線程塊(Block)- 線程(Thread) 的三級結構組織并行線程,這段代碼展示了一維線程組織的典型方式:
// 定義每個線程塊的線程數量#define BLOCK_SIZE 256// 計算所需線程塊數量int Num_Blocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;// 啟動核函數時指定線程組織方式vecAdd<<<Num_Blocks, BLOCK_SIZE>>>(d_A, d_B, d_C, N);核函數內部通過以下公式計算全局線程索引:?
int i = blockIdx.x * blockDim.x + threadIdx.x;- blockIdx.x:線程塊在網格中的索引(0 到 Num_Blocks-1)?
- blockDim.x:每個線程塊的線程數(即 BLOCK_SIZE)?
- threadIdx.x:線程在所屬線程塊中的索引(0 到 BLOCK_SIZE-1)?
這種索引計算方式是 CUDA 一維問題的標準模式,通過組合塊索引和線程索引,為每個線程分配唯一的全局索引。
3.顯存分層結構和管理(存儲模型)
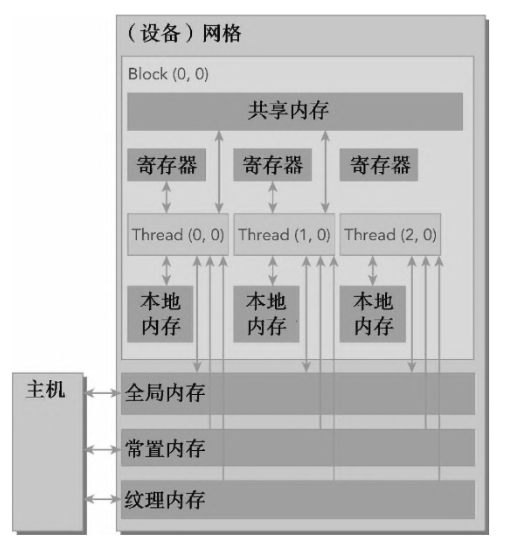
在 CUDA 編程中,寄存器、共享顯存和全局顯存是我們最常關注的三種顯存層級。它們構成了 GPU 內存層次結構的核心,在存儲容量與訪問速度方面呈現出典型的層級特性:
從容量來看:寄存器的容量最小,共享顯存次之,全局顯存擁有最大的存儲空間。
從訪問速度來看:寄存器訪問速度最快,共享顯存次之,全局顯存相對較慢。
此外,這三種內存的可見范圍(作用域)也逐級擴大:
寄存器是線程私有的內存空間,只能被當前線程訪問,通常用于存儲核函數中的臨時變量;
共享顯存由同一個線程塊內的所有線程共享,是實現線程間協作的關鍵機制;
全局顯存的作用范圍覆蓋整個設備,平時我們所說的顯卡顯存容量(如多少GB),指的就是全局顯存,它可以被所有線程訪問。
?
4.利用共享顯存優化Cuda核函數
每個流式多處理器(SM)都包含一小塊低延遲的內存池,稱為共享顯存(Shared Memory)。這塊內存被當前在該 SM 上執行的線程塊(block)中的所有線程所共享,是實現線程間高效通信與協作的關鍵資源。
與全局顯存(Global Memory)相比,共享顯存具有顯著的優勢(片上和片外的區別):其訪問延遲大約低 20~30 倍,帶寬則高出約 10 倍。因此,在并行計算中合理利用共享顯存,可以大幅提高程序的性能和效率。
示例:
歸約(Reduction)是并行計算中最基礎也最核心的操作之一,它通過將大規模數據逐步聚合為單一結果(如求和、求最值),廣泛應用于科學計算、數據分析等領域。本文將通過一段對比全局內存與共享內存歸約的 CUDA 代碼,深入解析 GPU 并行歸約的實現原理、核心技術點及性能優化邏輯。
歸約的本質是 “多對一” 的聚合操作。例如對數組[a0, a1, a2, ..., an-1]求和,串行邏輯是sum = a0 + a1 + ... + an-1,但在 GPU 上,我們可以讓多個線程同時工作:每個線程處理部分元素,通過多輪合并最終得到總和。
這段代碼實現了兩種歸約方案:
- 基于全局內存的歸約(
reduceGmem):直接操作 GPU 全局內存進行數據合并; - 基于共享內存的歸約(
reduceSmem):先將數據加載到 GPU 共享內存(更快的片上內存),再進行合并。
通過對比兩者的性能,我們能直觀理解 GPU 內存層次對程序效率的影響。
#include <iostream>
#include <cstdlib> // 用于動態內存分配
#define BLOCK_SIZE 1024 // 線程塊大小,需與歸約邏輯匹配// 方法1:基于全局內存的歸約
__global__ void reduceGmem(int *g_idata, int *g_odata, int n) {// 線程塊內索引(關鍵修正:使用塊內索引而非全局索引)unsigned int tid = threadIdx.x;// 定位當前線程塊處理的數據段起始地址int *idata = g_idata + blockIdx.x * blockDim.x;// 邊界檢查:若當前線程處理的全局索引超出數據范圍,直接返回if (blockIdx.x * blockDim.x + tid >= n)return;// 歸約階段1:1024→512(僅當塊大小≥1024時執行)if (blockDim.x >= 1024 && tid < 512) {idata[tid] += idata[tid + 512];}__syncthreads(); // 塊內同步,確保數據更新完成// 歸約階段2:512→256if (blockDim.x >= 512 && tid < 256) {idata[tid] += idata[tid + 256];}__syncthreads();// 歸約階段3:256→128if (blockDim.x >= 256 && tid < 128) {idata[tid] += idata[tid + 128];}__syncthreads();// 歸約階段4:128→64if (blockDim.x >= 128 && tid < 64) {idata[tid] += idata[tid + 64];}__syncthreads();// 最終階段:64→1(利用warp內隱式同步)if (tid < 32) {volatile int *vmem = idata; // 修正:添加int類型vmem[tid] += vmem[tid + 32];vmem[tid] += vmem[tid + 16];vmem[tid] += vmem[tid + 8];vmem[tid] += vmem[tid + 4];vmem[tid] += vmem[tid + 2];vmem[tid] += vmem[tid + 1];}// 每個線程塊的0號線程保存歸約結果if (tid == 0) {g_odata[blockIdx.x] = idata[0];}
}// 方法2:基于共享內存的歸約(補充完整邏輯)
__global__ void reduceSmem(int *g_idata, int *g_odata, int n) {__shared__ int smem[BLOCK_SIZE]; // 共享內存大小與線程塊大小一致(關鍵修正)unsigned int tid = threadIdx.x;unsigned int global_tid = blockIdx.x * blockDim.x + tid;// 1. 加載數據到共享內存(帶邊界檢查)smem[tid] = (global_tid < n) ? g_idata[global_tid] : 0;__syncthreads();// 2. 共享內存內歸約(與全局內存歸約邏輯類似,但訪問更快)if (blockDim.x >= 1024 && tid < 512) {smem[tid] += smem[tid + 512];}__syncthreads();if (blockDim.x >= 512 && tid < 256) {smem[tid] += smem[tid + 256];}__syncthreads();if (blockDim.x >= 256 && tid < 128) {smem[tid] += smem[tid + 128];}__syncthreads();if (blockDim.x >= 128 && tid < 64) {smem[tid] += smem[tid + 64];}__syncthreads();// 最終階段歸約if (tid < 32) {volatile int *vmem = smem;vmem[tid] += vmem[tid + 32];vmem[tid] += vmem[tid + 16];vmem[tid] += vmem[tid + 8];vmem[tid] += vmem[tid + 4];vmem[tid] += vmem[tid + 2];vmem[tid] += vmem[tid + 1];}// 3. 保存每個線程塊的歸約結果if (tid == 0) {g_odata[blockIdx.x] = smem[0];}
}int main() {const int N = 102400; // 數據規模int *h_data = new int[N]; // 主機內存(動態分配,避免棧溢出)// 初始化主機數據(0到N-1的累加和,用于后續驗證)for (int i = 0; i < N; i++) {h_data[i] = i;}// 設備內存分配int *d_idata, *d_odata1, *d_odata2;cudaMalloc((void**)&d_idata, sizeof(int) * N);cudaMalloc((void**)&d_odata1, sizeof(int) * ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)); // 存儲方法1的部分和cudaMalloc((void**)&d_odata2, sizeof(int) * ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)); // 存儲方法2的部分和// 主機→設備數據拷貝cudaMemcpy(d_idata, h_data, sizeof(int) * N, cudaMemcpyHostToDevice);// 計算線程塊數量int num_blocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;// 計時變量與事件cudaEvent_t start1, stop1, start2, stop2;cudaEventCreate(&start1);cudaEventCreate(&stop1);cudaEventCreate(&start2);cudaEventCreate(&stop2);// 測試基于全局內存的歸約cudaEventRecord(start1);reduceGmem<<<num_blocks, BLOCK_SIZE>>>(d_idata, d_odata1, N); // 修正:使用<<<>>>cudaEventRecord(stop1);cudaEventSynchronize(stop1); // 等待計算完成// 測試基于共享內存的歸約cudaEventRecord(start2);reduceSmem<<<num_blocks, BLOCK_SIZE>>>(d_idata, d_odata2, N); // 修正:核函數參數與名稱匹配cudaEventRecord(stop2);cudaEventSynchronize(stop2);// 計算耗時float time1, time2;cudaEventElapsedTime(&time1, start1, stop1);cudaEventElapsedTime(&time2, start2, stop2);std::cout << "reduceGmem time: " << time1 << " ms" << std::endl;std::cout << "reduceSmem time: " << time2 << " ms" << std::endl;// 資源釋放(關鍵修正:避免內存泄漏)delete[] h_data;cudaFree(d_idata);cudaFree(d_odata1);cudaFree(d_odata2);cudaEventDestroy(start1);cudaEventDestroy(stop1);cudaEventDestroy(start2);cudaEventDestroy(stop2);return 0;
}
1. 基于全局內存的歸約(reduceGmem)
__global__ void reduceGmem(int *g_idata, int *g_odata, int n) {unsigned int tid = threadIdx.x; // 塊內線程索引int *idata = g_idata + blockIdx.x * blockDim.x; // 當前塊處理的數據段// 邊界檢查:避免訪問超出數組范圍的內存if (blockIdx.x * blockDim.x + tid >= n) return;// 多階段歸約:1024→512→256→...→1if (blockDim.x >= 1024 && tid < 512) idata[tid] += idata[tid + 512];__syncthreads();if (blockDim.x >= 512 && tid < 256) idata[tid] += idata[tid + 256];__syncthreads();if (blockDim.x >= 256 && tid < 128) idata[tid] += idata[tid + 128];__syncthreads();if (blockDim.x >= 128 && tid < 64) idata[tid] += idata[tid + 64];__syncthreads();// 最終階段:利用warp內隱式同步if (tid < 32) {volatile int *vmem = idata; // 確保內存訪問不被編譯器優化vmem[tid] += vmem[tid + 32];vmem[tid] += vmem[tid + 16];vmem[tid] += vmem[tid + 8];vmem[tid] += vmem[tid + 4];vmem[tid] += vmem[tid + 2];vmem[tid] += vmem[tid + 1];}// 保存當前塊的歸約結果if (tid == 0) g_odata[blockIdx.x] = idata[0];
}關鍵設計思路:
- 數據劃分:輸入數組按線程塊大小(
BLOCK_SIZE=1024)分成多個段,每個線程塊處理一段數據,最終輸出 “部分和”(每個塊的結果)。 - 分階段合并:通過 4 輪 “二分歸約” 將 1024 個元素逐步縮減為 64 個,每輪只讓前半線程參與(如
tid < 512處理tid與tid+512的合并),確保無重復計算。 - 線程同步:每輪合并后用
__syncthreads()阻塞塊內所有線程,確保所有線程完成當前輪次后再進入下一輪(避免讀取未更新的數據)。 - Warp 優化:最后 64→1 的合并僅用前 32 個線程(一個線程束,GPU 的基本執行單元),利用 warp 內線程的隱式同步(無需
__syncthreads()),同時用volatile防止編譯器優化導致的內存訪問錯誤。
注:
__syncthreads():線程塊內的同步屏障,所有線程必須到達此函數后才能繼續執行,用于避免 “先寫后讀” 的數據沖突(如線程 A 未寫完數據,線程 B 就讀取)。volatile關鍵字:在 warp 內操作時,強制編譯器從內存而非寄存器讀取數據,確保線程能獲取到其他線程更新的最新值(warp 內線程無顯式同步,依賴硬件執行一致性)。
2. 基于共享內存的歸約(reduceSmem)
__global__ void reduceSmem(int *g_idata, int *g_odata, int n) {__shared__ int smem[BLOCK_SIZE]; // 共享內存:塊內線程共享的片上內存unsigned int tid = threadIdx.x;unsigned int global_tid = blockIdx.x * blockDim.x + tid;// 步驟1:加載數據到共享內存(帶邊界檢查)smem[tid] = (global_tid < n) ? g_idata[global_tid] : 0;__syncthreads();// 步驟2:共享內存內歸約(邏輯與全局內存一致,但訪問更快)if (blockDim.x >= 1024 && tid < 512) smem[tid] += smem[tid + 512];__syncthreads();if (blockDim.x >= 512 && tid < 256) smem[tid] += smem[tid + 256];__syncthreads();// ... 后續階段與reduceGmem相同 ...// 步驟3:保存結果if (tid == 0) g_odata[blockIdx.x] = smem[0];
}與全局內存歸約的核心差異:
- 引入共享內存:先將全局內存數據拷貝到
smem(共享內存),后續所有合并操作都在smem中進行。 - 性能優勢:共享內存是 GPU 芯片上的高速緩存(訪問延遲約為全局內存的 1/100),且支持線程塊內的低延遲數據共享,大幅減少全局內存訪問次數(全局內存是 GPU 性能瓶頸之一)。
運行程序后,通常會觀察到reduceSmem的耗時顯著低于reduceGmem,例如:
reduceGmem time: 30.91 ms
reduceSmem time: 0.018432 ms性能差異的核心原因:
- 全局內存的 “高延遲 + 低帶寬利用率”:
reduceGmem每輪合并都需要訪問全局內存,而全局內存的帶寬利用率受訪問模式限制(即使合并訪問,效率仍低于共享內存)。 - 共享內存的 “低延遲 + 高復用”:
reduceSmem僅在加載階段訪問 1 次全局內存,后續合并全在共享內存中進行,且共享內存支持線程塊內的高效數據復用。
?????????

)





)

:設計思路與實現原理(C/C++代碼實現))
 條件指令、循環結構、定義函數)






:RecyclerView 多類型布局與數據刷新實戰)
)
