文章目錄
- 紅黑樹
- 應用場景
- 跳表
- 使用場景
- B+樹
- 使用場景
毫無疑問數據結構是復雜的,讓人頭大的,大學時唯一掛科的就是數據結構,上學時不用心,不曉得自己的職業生涯要一直被數據結構支配。
或多或少,面試抱佛腳時,數據結構都會背一背刷一刷,HashMap的紅黑樹,Redis的跳表一個個都跑不了。
當回歸日常時,學習及理解數據結構真的有什么收益嗎
舉個例子,最近看到IO多路復用的時候,說到select,poll與epoll對比時
有兩個點
1.epoll通過維護一個鏈表來記錄就緒事件,無需遍歷所有文件描述符來獲取所有就緒事件,而是通過事件通知機制,將就緒事件添加到鏈表中,epoll_wait()函數獲取所有就緒事件。
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...);
listen(s, ...)int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //將所有需要監聽的socket添加到epfd中while(1) {int n = epoll_wait(...);for(接收到數據的socket){//處理}
}
2.epoll通過紅黑樹來維護所有文件描述符。
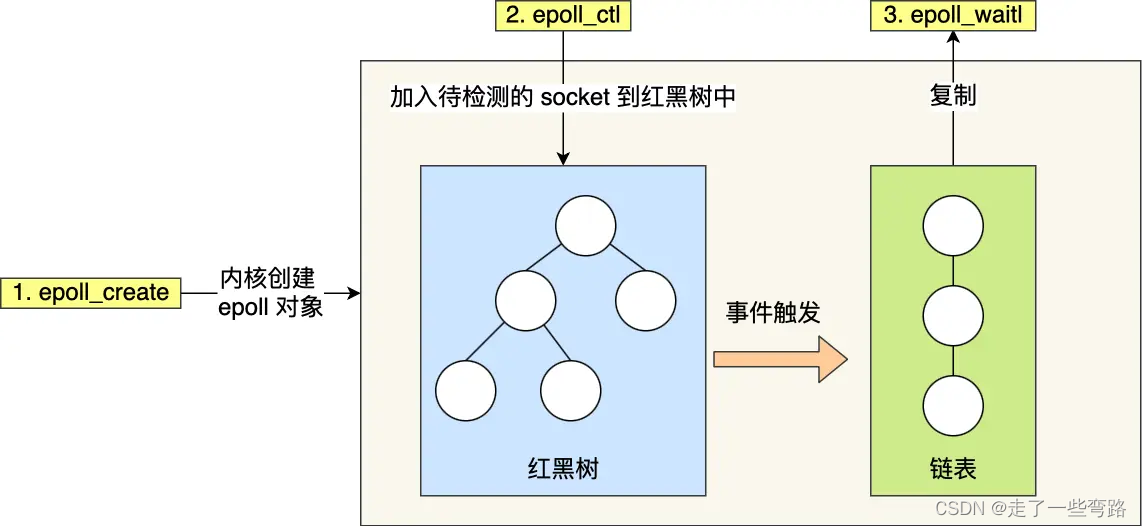
當我看到第2點時,反應是居然是你,真的有你,可算再次遇到你了,除了HashMap中,終于又和你體會到了鋪面而來的重逢喜悅感,另外帶著一種原來你真的挺有用的欣慰感。
紅黑樹、B+樹以及跳表這三個數據結構,之前在我心目中,地位是一樣的,需要面試的時候,對于他們我口若懸河,頭頭是道,而日常開發就是,對不起,我們好像不太認識。
紅黑樹HashMap,B+樹MySQL索引,跳表Redis跳表,我幾乎快要把他們畫等號了,背后的原理,為什么是這樣的,卻從來都想不起再去深究。
隨著開發的生涯越走越遠,我很欣慰自己沒有原地踏步,那么為什么呢?
紅黑樹
紅黑樹不算是嚴格的二叉平衡查找樹,標準的二叉平衡查找樹父子上下節點的高度最大不會超過1,為了維護這個平衡,當新增或者刪除數據時,標準的平衡二叉查找樹需要耗費更多的資源,不可避免需要進行多次旋轉。
紅黑樹使得二叉查找樹能保持大體的平衡,不至于退化成鏈表,又不至于頻繁的轉換操作,在與平衡二叉樹的時間復雜度相差不大的情況下,保證每次插入最多只需要三次旋轉就能達到平衡,實現起來也更為簡單。
紅黑樹在二叉查找樹的基礎上增加了著色和相關的性質使得紅黑樹相對平衡,從而保證了紅黑樹的查找、插入、刪除的時間復雜度最壞為O(log n)。所以紅黑樹適用于搜索,插入,刪除操作較多的情況。
應用場景
紅黑樹常用于存儲內存中的有序數據,增刪很快,內存存儲不涉及 I/O 操作。
- HashMap
- IO多路復用-epoll
- Linux公平調度器
跳表
1.對有序列表查詢性能的優化。
2.跳表的基本思想是將有序鏈表分層,每個節點在不同層中擁有不同數量的前向指針。上層鏈表是下層鏈表的子集,且上層鏈表中的元素順序與下層鏈表一致。
3.通過增加指針和添加層級的方式,跳表可以實現對數級別的查找效率。
4.實現簡單
原以為除了Redis ZSet中,也不會再見到跳表了,直到看到LevelDB時,了解到其Memtable中使用的也是跳表實現。
使用場景
- Redis zset
- LevelDB底層數據結構
B+樹
號稱為文件系統而生的數據結構。
多路平衡二叉樹,選用B+樹最大的理由,我理解是樹的高度,高度,還是tm的高度。
B+樹只需要3層就能存儲大約2kw的數據,定位一個數據,也就是頁大的讀取IO次數,最多3,4次,換成紅黑樹或者跳表,大概需要10倍左右;
對于文件系統、數據庫的場景,需要從磁盤讀取數據,IO的耗費相對于內存來說是不可接受的。
使用場景
B+ 樹在處理磁盤I/O、范圍查詢和大數據量管理方面優勢明顯
- 數據庫:MySQL innodb索引,PostgreSQL索引,Oracle索引等基本主流的數據庫
- 文件系統:NTFS、ReiserFS、大名鼎鼎的HDFS等文件系統
: boost搜索引擎)


)







)
真題解析#中國電子學會#全國青少年軟件編程等級考試)


)


Negative Test)
