數據預處理
- 引入
- 一.配置java , hadoop , maven的window本機環境變量
- 1.配置
- 2.測試是否配置成功
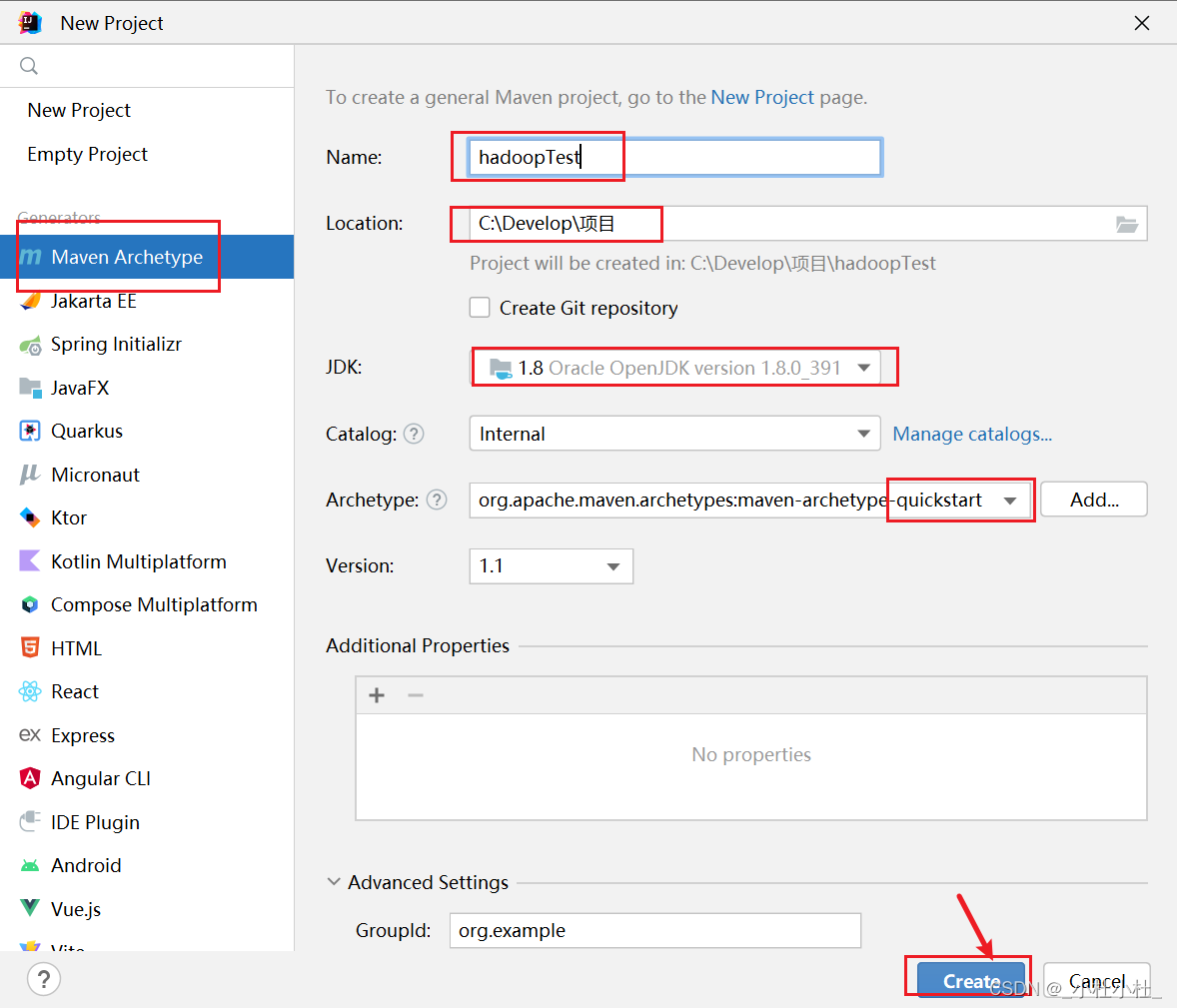
- 二.創建一個Maven項目
- 三.導入hadoop依賴
- 四.數據清洗
- 1.數據清洗的java代碼
- 2.查看數據清洗后的輸出結果
引入
做數據預處理 需要具備的條件 : java,hadoop,maven環境以及idea軟件
一.配置java , hadoop , maven的window本機環境變量
1.配置
- 本機的設置/高級系統設置/環境變量
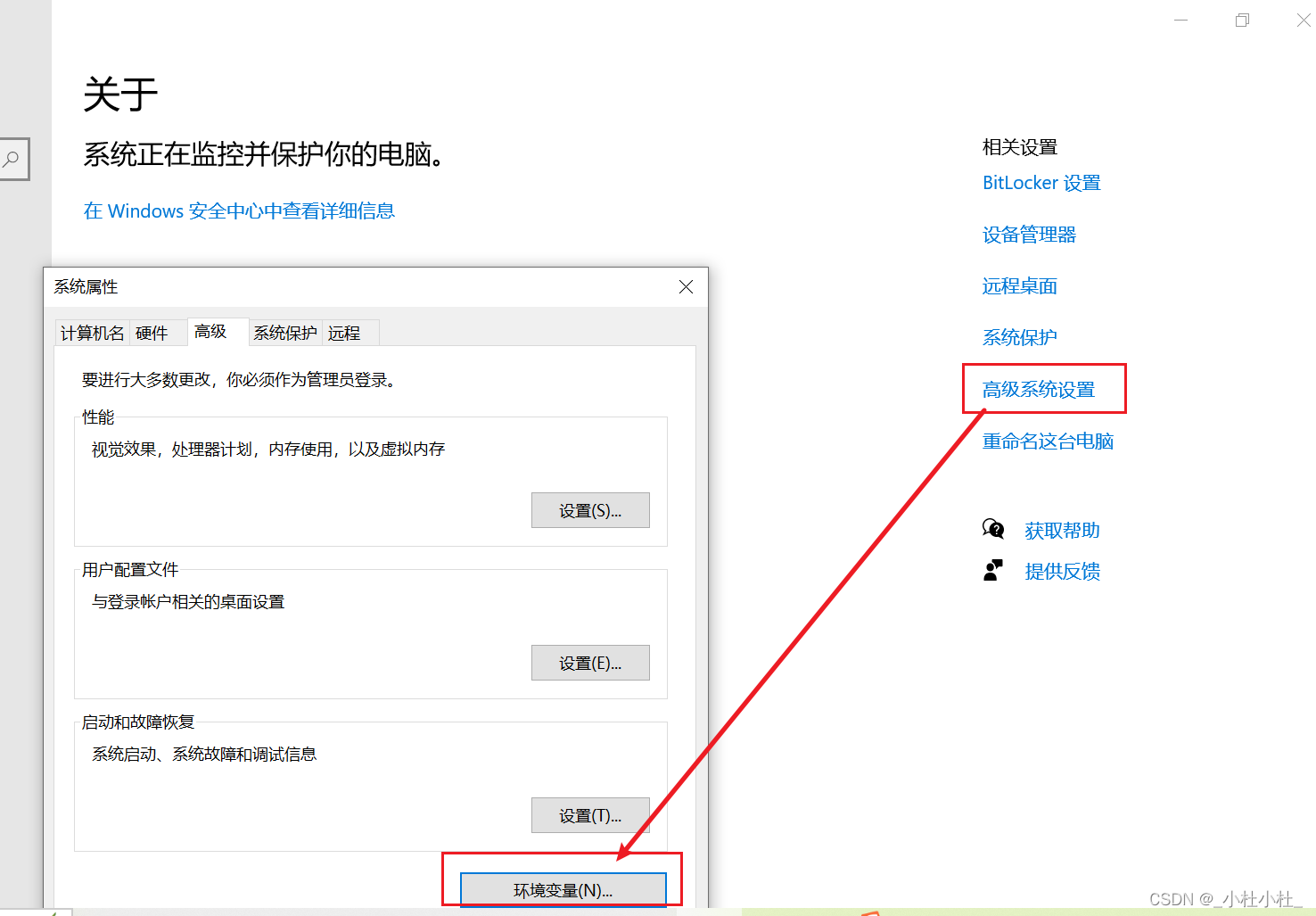
- 在系統變量中配置文件的路徑
- 我是在用戶變量和系統變量中都做配置了
- 用戶變量和系統變量的區別是什么呢?
環境變量包括了用戶變量和系統變量
它倆的關系簡言之就是 系統變量包括用戶變量 , 也就是 , 如果你配置了系統變量 , 那么其配置在用戶變量中也是有效的
而我們都知道 , 一個系統可以同時有多個用戶 , 所以用戶變量是只在當前用戶環境下有效的
一般,在沒有特殊要求的情況下,只配置系統變量就夠了
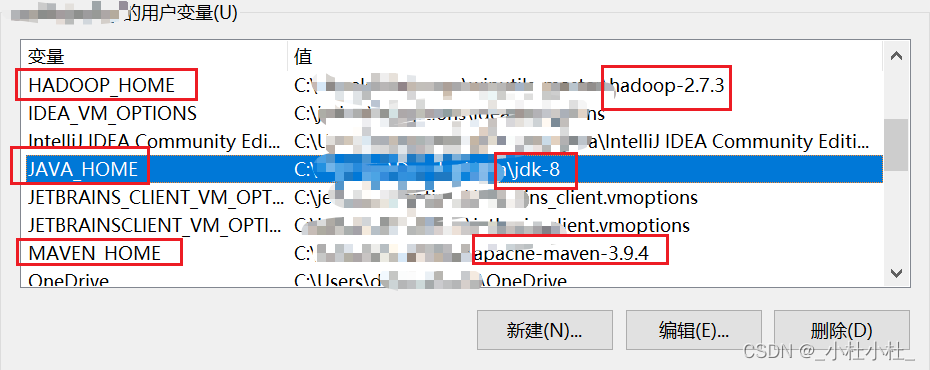
例如我的maven文件的路徑如下 :
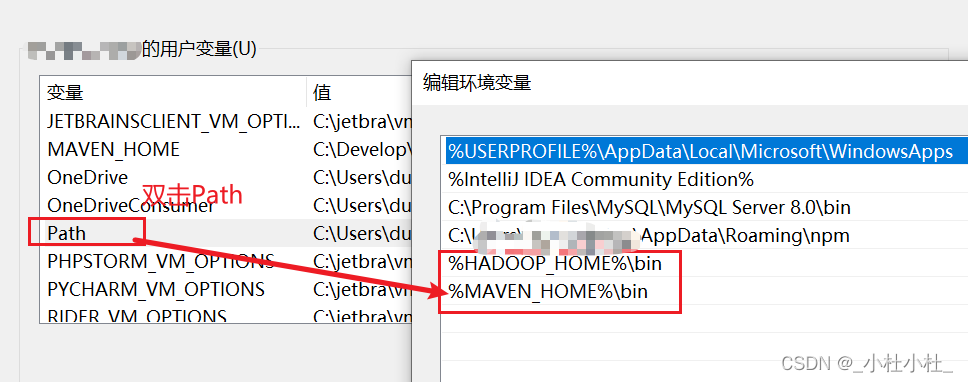
雙擊Path
新建
輸入 : %HADOOP_HOME%\bin 這個格式的(注意名稱與上面配置路徑的名稱相同即可)
下圖只有hadoop和maven的
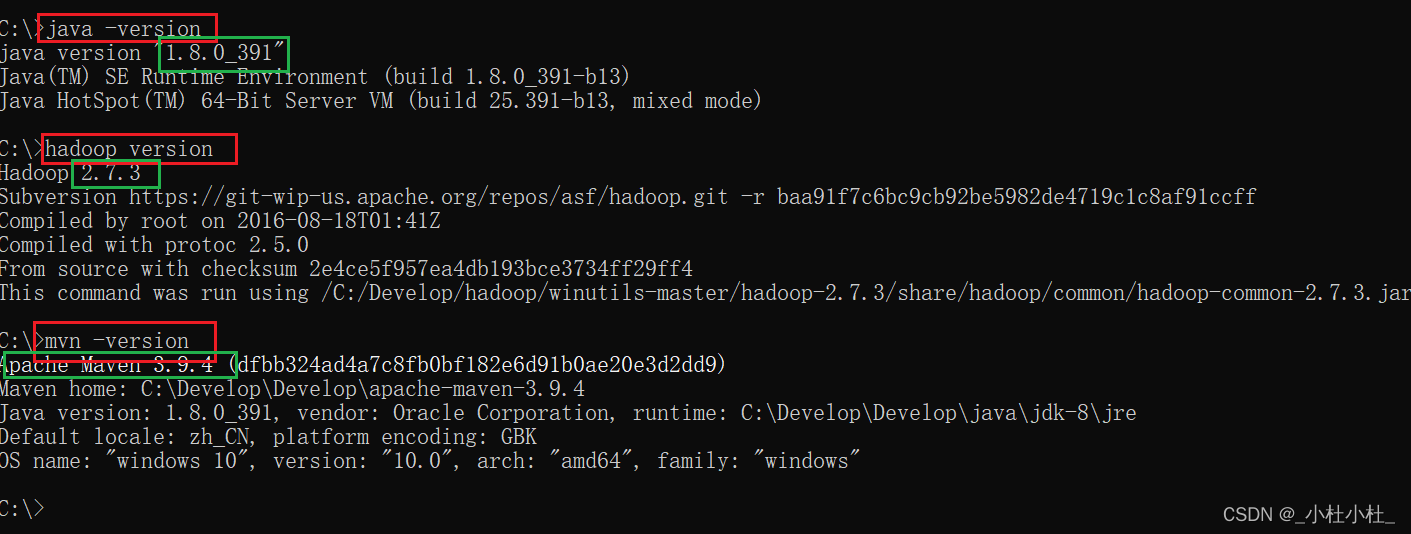
2.測試是否配置成功
win+R 輸入 cmd
輸入下面命令 , 有版本號顯示 , 則說明環境配置成功
java -version
hadoop version
mvn -version
二.創建一個Maven項目
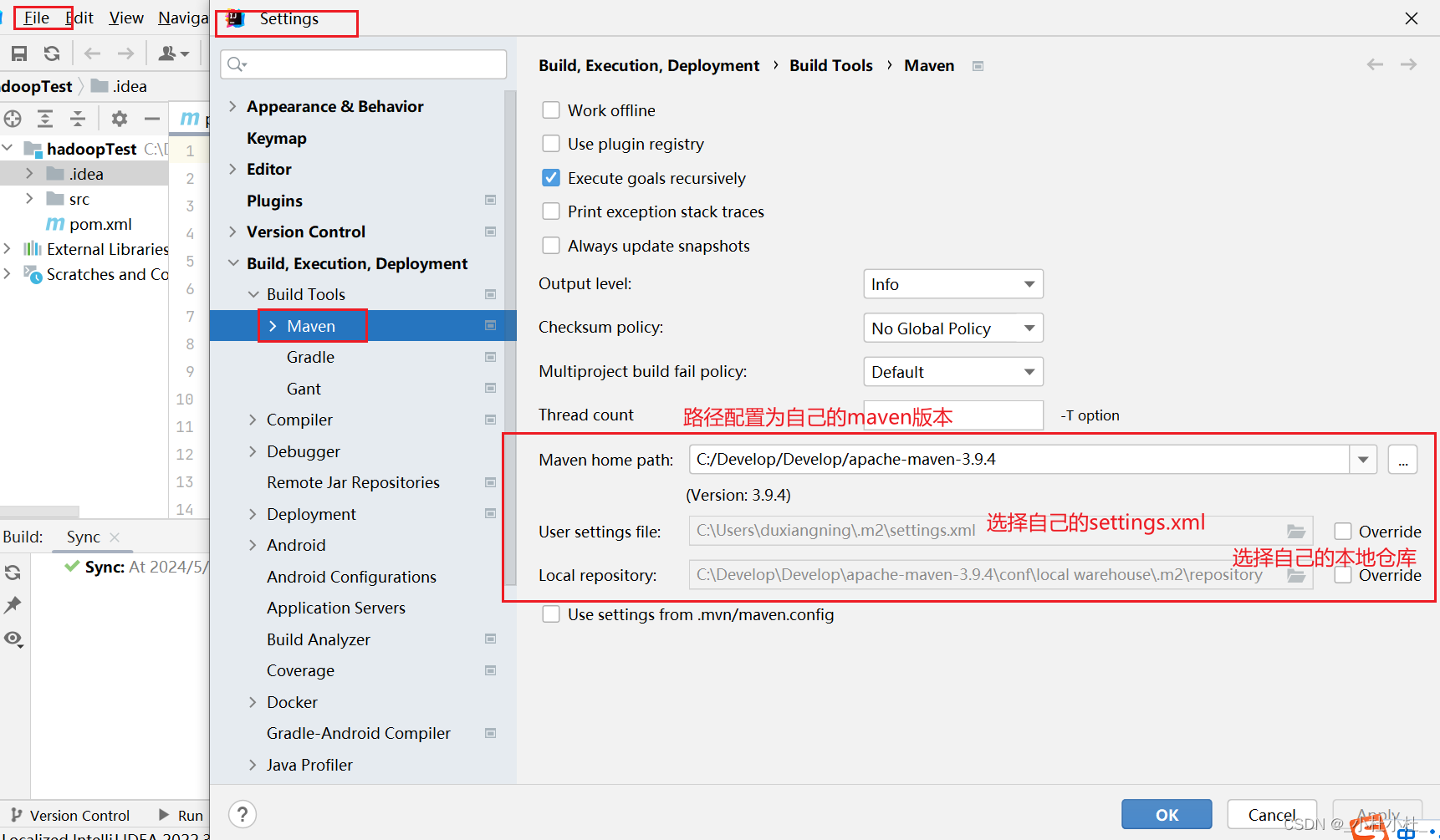
三.導入hadoop依賴
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.3</version>
</dependency>
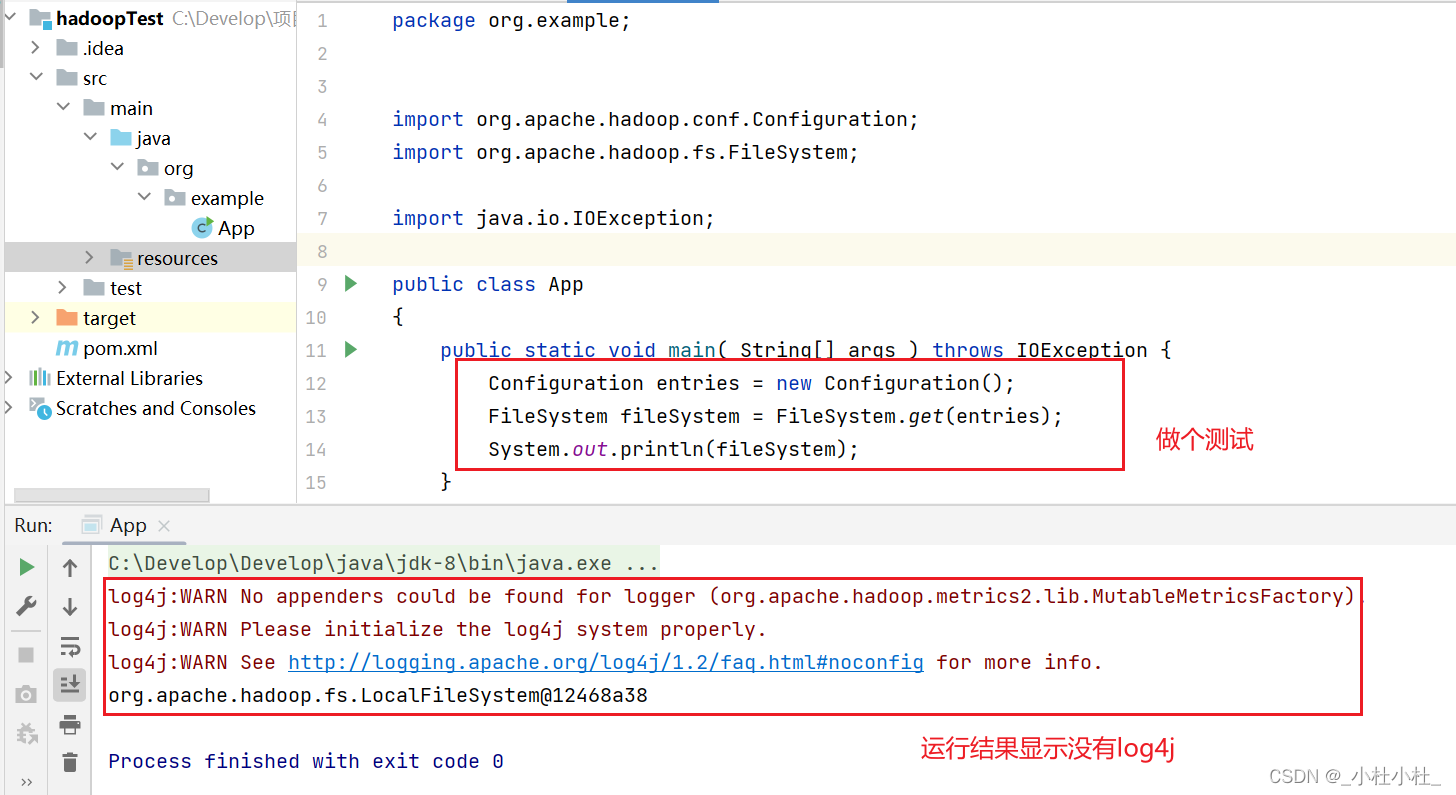
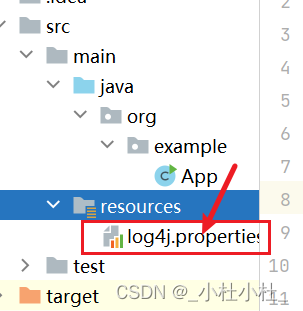
把剛剛環境配置的hadoop文件中的hadoop/etc/hadoop/log4j.propertities文件移動到resources中
四.數據清洗
在 /usr/data文件下創建一個新文件夾log(用來存儲日志文件)
[root@hadoop ~]# cd /usr/
[root@hadoop usr]# ls
bin data etc games include lib lib64 libexec local sbin share soft src tmp
[root@hadoop usr]# cd data/
[root@hadoop data]# ls
student.txt
[root@hadoop data]# mkdir log
[root@hadoop data]# ls
log student.txt
[root@hadoop data]# cd log/
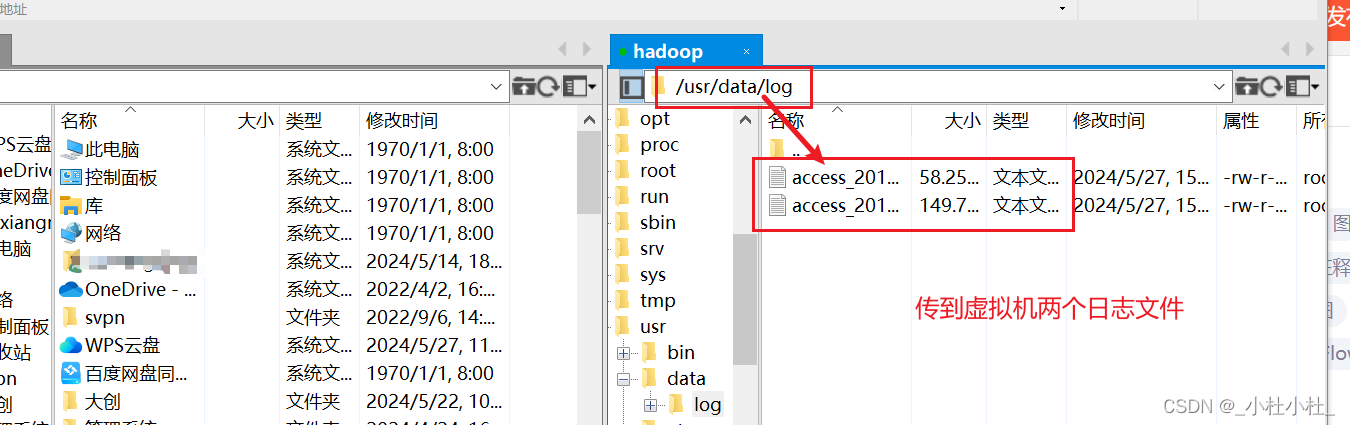
[root@hadoop log]# ls
access_2013_05_30.log access_2013_05_31.log
[root@hadoop log]# hdfs dfs -put access_2013_05_30.log / //上傳到hdfs中
1.數據清洗的java代碼
//日志解析類
package com.stu.log;import sun.rmi.runtime.Log;import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.Locale;/*** 日志解析類*/
public class LogParser {public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH);// yyyyMMddHHmmsspublic static final SimpleDateFormat dateformat1 = new SimpleDateFormat("yyyyMMddHHmmss");// 解析英文時間字符串private Date parseDateFormat(String string){Date parse = null;try {parse = FORMAT.parse(string);} catch (ParseException e) {e.printStackTrace();}return parse;}/*** 解析日志的行記錄* @param line* @return*/public String[] parse(String line){String s = parseIp(line);String s1 = parseTime(line);String s2 = parseURL(line);String s3 = parseStatus(line);String s4 = parseTraffic(line);return new String[]{s,s1,s2,s3,s4};}private String parseTraffic(String line){String trim = line.substring(line.lastIndexOf("\"") + 1).trim();String traffic = trim.split(" ")[1];return traffic;}private String parseStatus(String line){String substring = line.substring(line.lastIndexOf("\"") + 1).trim();String status = substring.split(" ")[0];return status;}private String parseURL(String line){int i = line.indexOf("\"");int i1 = line.lastIndexOf("\"");String substring = line.substring(i + 1, i1);return substring;}private String parseTime(String line){int i = line.indexOf("[");int i1 = line.indexOf("+0800");String trim = line.substring(i + 1, i1).trim();Date date = parseDateFormat(trim);return dateformat1.format(date);}private String parseIp(String line){String trim = line.split("- -")[0].trim();return trim;}}map和reduce
package com.stu.log;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class LogMapper extends Mapper<LongWritable,Text,LongWritable, Text> {private LogParser lp = new LogParser();private Text outPutValue = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String[] parse = lp.parse(value.toString());// Step1. 過濾掉靜態資源訪問請求if(parse[2].startsWith("GET /static/") || parse[2].startsWith("GET /uc_server")){return;}// Step2. 過濾掉開頭為GET 和 POSTif(parse[2].startsWith("GET /")){parse[2] = parse[2].substring("GET /".length());}else if(parse[2].startsWith("POST /")){parse[2] = parse[2].substring("POST /".length());}// Step3 過濾掉http協議if(parse[2].endsWith(" HTTP/1.1")){parse[2] = parse[2].substring(0,parse[2].length() - " HTTP/1.1".length());}outPutValue.set(parse[0] + "\t"+ parse[1] +"\t"+parse[2]);context.write(key,outPutValue);}
}class LogReducer extends Reducer<LongWritable, Text,Text, NullWritable>{@Overrideprotected void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {context.write(values.iterator().next(),NullWritable.get());}
}job
job類的代碼需要做如下修改 :
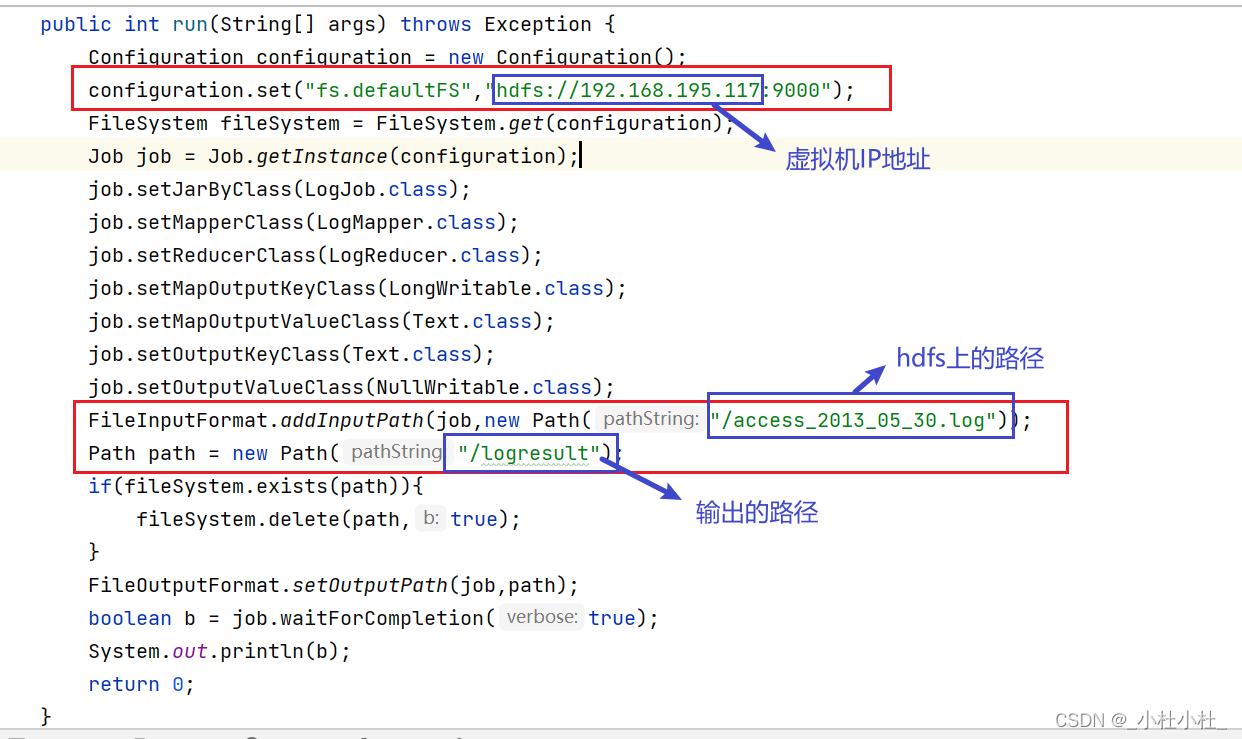
package com.stu.log;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;public class LogJob extends Configured implements Tool {public static void main(String[] args) {try {new LogJob().run(args);} catch (Exception e) {e.printStackTrace();}}public int run(String[] args) throws Exception {Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(configuration);Job job = Job.getInstance(configuration);job.setJarByClass(LogJob.class);job.setMapperClass(LogMapper.class);job.setReducerClass(LogReducer.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Text.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.addInputPath(job,new Path(args[0]));Path path = new Path(args[1]);if(fileSystem.exists(path)){fileSystem.delete(path,true);}FileOutputFormat.setOutputPath(job,path);boolean b = job.waitForCompletion(true);System.out.println(b);return 0;}
}2.查看數據清洗后的輸出結果
[root@hadoop log]# hdfs dfs -cat /logresult/part-r-00000 | head -100 //通過管道查看100條數據(清洗過的)





數據處理)




【中等 前綴和數組+動態規劃 Java/Go/PHP/C++】)
)







)