paper:CVPR 2024 2403
https://arxiv.org/abs/2403.04321
code:
https://github.com/LgQu/DPT-T2I
Abstract
盡管文本到圖像生成(T2I)取得了進展,但先前的方法往往面臨文本 -圖像對齊問題,例如生成圖像中的關系混淆。現有的解決方案包括進行交叉注意力操作以實現更好的組合理解,或集成大語言模型以改進布局規劃。然而,T2I模型固有的對齊能力仍然不足。通過回顧生成式建模與判別式建模之間的聯系,我們認為 T2I模型的判別能力可能反映了其在生成過程中的文本 -圖像對齊能力。有鑒于此,我們主張增強 T2I模型的判別能力,以在生成過程中實現更精確的文本到圖像對齊。我們提出了一種基于 T2I模型構建的判別式適配器,用于在兩個具有代表性的任務上探究其判別能力,并利用判別式微調來改進其文本 -圖像對齊。作為判別式適配器的一個額外優勢,自校正機制可以在推理過程中利用判別梯度,使生成的圖像更好地與文本提示對齊。在三個基準數據集上進行的全面評估(包括分布內和分布外場景)證明了我們的方法具有卓越的生成性能。同時,與其他生成模型相比,它在兩個判別任務上達到了最先進的判別性能。
Introduction
文本到圖像生成(T2I)旨在根據給定的自由形式文本提示合成高質量且語義相關的圖像。近年來,擴散模型的快速發展激發了內容生成領域的研究熱情,使文本到圖像生成取得了重大飛躍。然而,由于組合推理能力較弱,當前的文本到圖像生成模型仍然存在文本 -圖像對齊問題,例如屬性綁定、計數錯誤和關系混淆(見圖1),尤其是在復雜的多對象生成場景中。

圖1.(a)文本 -圖像不對齊問題的示例,以及(b)我們通過增強文本到圖像(T2I)模型的判別能力來提升生成能力的動機。我們列出了 StableDiffusion v2.1 [50] 在屬性綁定、計數錯誤和關系混淆方面產生的三個錯誤生成結果。
在提升文本到圖像(T2I)模型的文本 -圖像對齊方面,有兩條研究路線取得了顯著進展。第一條路線提出在語言結構引導下對跨模態注意力激活進行干預,或進行測試時優化。 然而,這些方法嚴重依賴于操縱注意力結構的歸納偏差,通常需要具備視覺 -語言交互方面的專業知識。這種專業知識不易掌握,且缺乏靈活性。相比之下,另一條研究路線借鑒大語言模型(LLM)的語言理解和組合能力進行布局規劃,然后結合布局到圖像的模型(如GLIGEN)進行可控生成。雖然這些方法緩解了計數錯誤等對齊問題,但它們嚴重依賴中間狀態(如邊界框)來表示布局。中間狀態可能無法充分捕捉細粒度的視覺屬性,并且在這種兩階段范式中還可能累積誤差。此外,T2I模型固有的組合推理能力仍然不足。
為了解決這些問題,我們旨在通過直接激發文生圖(T2I)模型的內在組合推理能力來促進文本 -圖像對齊,而不依賴于注意力操作或中間狀態的歸納偏置。理查德·費曼(Richard Feynman)有句名言:“我無法創造的,我就無法理解。”這句話強調了理解在創造過程中的重要性。這促使我們考慮增強T2I模型的理解能力,以促進其文生圖的生成。如圖1所示,如果T2I模型能夠區分文本提示與兩幅語義略有差異的圖像之間的對齊差異,那么它們更有可能生成語義正確的圖像。
有鑒于此,我們提議通過兩項判別任務來檢驗文生圖(T2I)模型的理解能力。首先,我們在圖文匹配(ITM)[18,43]任務上探究T2I模型的判別式全局匹配能力,這是一項用于評估基礎圖文對齊的代表性任務。第二項判別任務考察T2I模型的局部定位能力。指代表達理解(REC)[68]就是一項代表性任務,它檢驗圖像內的細粒度表達 - 對象對齊情況。基于這兩項任務,我們旨在:1)探究T2I模型的判別能力,尤其是組合語義對齊能力;2)進一步提升它們的判別能力,以實現更好的文生圖效果。
為此,我們提出了一種判別式探測與調優(DPT)范式,通過兩階段過程來檢驗和改進文本到圖像(T2I)模型的文本 -圖像對齊。DPT納入了一個判別式適配器,基于 T2I模型的語義表征 [29]執行圖像 -文本匹配(ITM)和指代表達理解(REC)任務,以探測判別能力。例如,DPT可以將擴散模型 [50] 的 U-Net特征圖作為語義表征。在第二階段,DPT 通過參數高效微調(如 LoRA [24])進一步改善文本 -圖像對齊。除了適配器之外,DPT還對基礎 T2I模型進行微調,以增強其在判別和生成任務中的內在組合推理能力。作為擴展,我們提出了一種自我修正機制,利用判別式適配器基于梯度的引導信號來引導 T2I模型實現更好的對齊。我們在三個面向對齊的文本到圖像生成基準和四個 ITM及 REC基準上,在分布內和分布外設置下進行了廣泛實驗,驗證了 DPT 在增強 T2I模型的生成和判別能力方面的有效性。
這項工作的主要貢獻有三個方面:
- 我們回顧了生成式建模和判別式建模之間的關系,并提出了一種簡單而有效的范式 DPT,用于探測和改進 T2I模型的基本判別能力,以實現更好的文本到圖像生成。
- 我們提出了一個判別式適配器,以在 DPT中實現高效的探測和調優。此外,我們為 T2I模型擴展了一種由判別式適配器引導的自我修正機制,用于面向對齊的生成。
- 我們在三個文本到圖像生成數據集和四個判別式數據集上進行了廣泛實驗,顯著增強了代表性 T2I模型的生成和判別能力。
Related Work
Text-to-Image Generation. ** 在過去的幾十年里,人們在變分自編碼器、生成對抗網絡和自回歸模型方面付出了巨大努力,致力于在文本條件下生成高質量圖像。最近,由于擴散概率模型(DMs)的穩定性和可擴展性,人們對其產生了濃厚的興趣。為了進一步提高生成質量,像DALL·E2、Imagen和GLIDE等大規模模型應運而生,用于合成逼真的圖像。這項工作主要聚焦于擴散模型,尤其以開源的Stable Diffusion(SD)作為基礎模型。
Improving Text-Image Alignment. 盡管取得了令人振奮的成功,但當前的文生圖(T2I)模型仍然存在圖文不一致的問題,尤其是在需要組合推理的復雜場景中。為了引導干預穩定擴散(SD)模型的內部特征以促進高一致性生成,人們已經做出了一些開創性的努力。例如,結構擴散(StructureDiffusion)將提示解析為樹結構,并將其與交叉注意力表示相結合,以促進組合生成。“關注并激發”(Attend-and-Excite)方法操縱交叉注意力單元,使其關注所有文本主體標記,并增強注意力圖中的激活。盡管取得了顯著進展,但它們在處理包括物體缺失和屬性錯誤等問題時存在局限性,并且忽略了關系增強。另一類工作,如LayoutLLMT2I和LayoutGPT**,采用了兩階段的粗到精框架,即先生成基于邊界框的顯式中間布局,然后合成圖像。然而,這種中間布局可能不足以表示復雜場景,并且它們幾乎放棄了預訓練T2I模型的內在推理能力。在這項工作中,我們提出了一種判別式調優范式,通過激發預訓練T2I模型的判別能力來實現高一致性生成。
**Generative and Discriminative Modeling. ** 大語言模型(LLMs)的驚人進展使生成式模型能夠完成判別式任務,這促使研究人員利用基礎視覺生成模型在圖像分類、分割和圖文匹配等任務中挖掘理解能力。此外,DreamLLM統一了多模態自回歸框架中的生成和判別,并揭示了潛在的協同效應。相反,近期的一項工作探討了生成式人工智能悖論,并表明大語言模型可能實際上并不理解它們所生成的內容。據我們所知,我們是首個研究判別式微調以促進文生圖(T2I)對齊的團隊。
Method
在本節中,我們引入 DPT范式來探測并增強基礎文生圖(T2I)模型的判別能力。如圖2所示,DPT由兩個階段組成,即判別探測和判別調優,以及3.3節中的自校正機制。
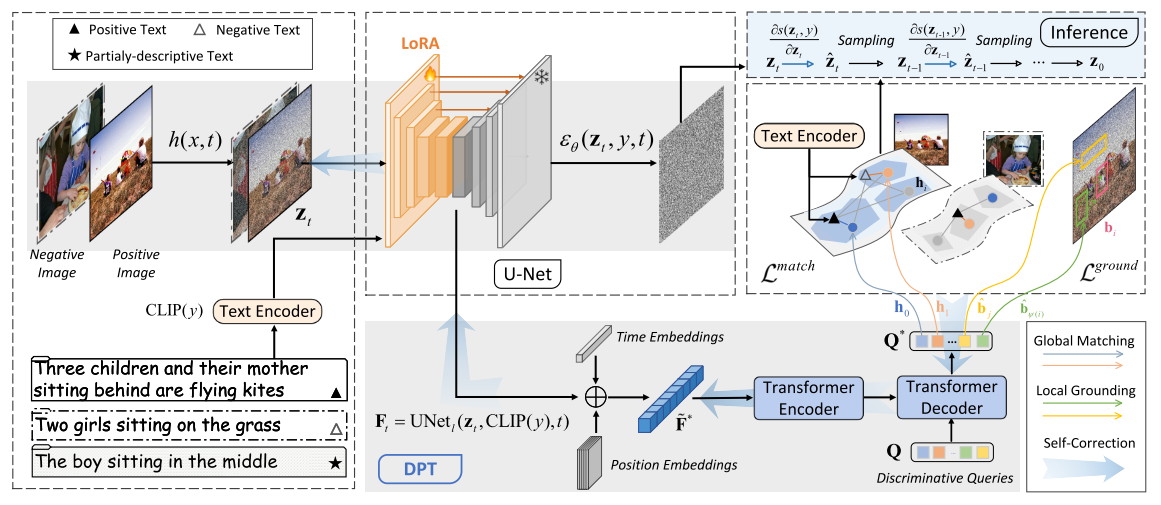
圖2.所提出的判別式探測與調優(DPT)框架的示意圖。我們首先從凍結的Stable Diffusion(SD)模型中提取語義表示,然后提出一個判別式適配器來進行判別式探測,以研究SD的全局匹配和局部定位能力。隨后,我們通過引入LoRA參數進行參數高效的判別式調優。在推理過程中,我們提出自校正機制來指導基于去噪的文本到圖像生成。
Stage 1 – Discriminative Probing
在第一階段,我們旨在開發一種探測方法,以探究“近期的文本到圖像(T2I)模型的判別能力有多強?”為此,我們首先選擇有代表性的T2I模型和語義表示,然后考慮讓T2I模型適應判別任務。
Stable Diffusion for Discriminative Probing. 考慮到StableDiffusion(SD)是開源的,并且是最強大、最受歡迎的文生圖(T2I)模型之一,我們選擇其不同版本(見第4.2節)作為代表性模型來探究其判別能力。為了使生成式擴散模型在語義上更具針對性且高效,SD [50] 在潛在低維空間中進行去噪操作。它包括變分自編碼器(VAE)[27]、CLIP的文本編碼器 [45] 和U-Net [51]。U-Net作為潛在空間中去噪分數匹配的神經網絡主干,由三部分組成,即下采樣塊、中間塊和上采樣塊。在訓練過程中,給定一個正樣本圖像 -文本對 (x,y)(x, y)(x,y),SD首先使用 VAE編碼器對圖像 xxx進行編碼,并添加噪聲 ?~N(0,1)\epsilon \sim \mathcal{N}(0,1)?~N(0,1),以獲得時間步 ttt時的潛在變量 zt=h(x,t)z_t = h(x, t)zt?=h(x,t)。此后,SD 使用 U-Net來預測所添加的噪聲,并通過最小化真實噪聲與預測噪聲之間的 L2L_2L2?損失來優化模型參數。
Semantic Representations. 利用諸如StableDiffusion(SD)這樣的文生圖(T2I)模型來執行判別任務并非易事。幸運的是,近期的研究表明,盡管擴散模型最初是為去噪或分數估計而設計的,但它們具有有意義的語義潛在空間。此外,一系列開創性的工作表明,從SD的U-Net中提取的表征對于判別任務是有效的,甚至具有優越性。受這些研究的啟發,我們考慮通過一個判別適配器,利用SD的U-Net中的語義表征來執行判別任務。
Discriminative Adapter. 我們提出了一種輕量級判別適配器,它依賴于穩定擴散(SD)的語義表示來處理判別任務。受DETR [3]的啟發,我們使用Transformer [58]結構實現了判別適配器,包括一個Transformer編碼器和一個Transformer解碼器。此外,我們采用固定數量的隨機初始化且可學習的查詢,以使該框架適應特定的判別任務。具體來說,給定采樣時間步 ttt處的噪聲隱變量 ztz_tzt? 和提示 yyy,我們首先將它們輸入到U-Net中,并從其中一個中間塊中提取一個二維特征圖 Ft∈Rh×w×dF_t \in \mathbb{R}^{h\times w\times d}Ft?∈Rh×w×d,其中 hhh、www 和 ddd分別表示高度、寬度和維度。形式上,我們通過以下公式提取 FtF_tFt?:
Ft=UNetl(zt,CLIP(y),t)F_t = \text{UNet}_l(z_t, \text{CLIP}(y), t)Ft?=UNetl?(zt?,CLIP(y),t)
其中,UNetl\text{UNet}_lUNetl?指的是在U-Net的第 lll個塊中提取特征圖的操作。隨后,我們通過加法融合將 FtF_tFt?與可學習的位置嵌入 [12] 和時間步 ttt 的嵌入 [50]相結合,然后將其展平為語義表示 F~t∈Rhw×d\tilde{F}_t \in \mathbb{R}^{hw\times d}F~t?∈Rhw×d。為簡單起見,我們在接下來的內容中將省略下標 ttt。
為了探究判別能力,我們將 F~\tilde{F}F~輸入到 Transformer編碼器 Enc(?)\text{Enc}(\cdot)Enc(?)中,然后在 Transformer解碼器 Dec(?,?)\text{Dec}(\cdot, \cdot)Dec(?,?)中使編碼器的輸出與一些可學習的查詢 Q={q1,…,qN}Q = \{q_1, \dots, q_N\}Q={q1?,…,qN?}(其中 qi∈Rdq_i \in \mathbb{R}^dqi?∈Rd)進行交互。整個過程可表示為
Q?=f(F~;Wa,Q)=Dec(Enc(F~),Q)Q^* = f(\tilde{F}; W_a, Q) = \text{Dec}(\text{Enc}(\tilde{F}), Q)Q?=f(F~;Wa?,Q)=Dec(Enc(F~),Q)其中 f(?)f(\cdot)f(?)抽象為具有參數 WaW_aWa? 和 QQQ 的判別適配器。WaW_aWa?包括編碼器和解碼器中的參數。查詢 QQQ充當視覺表征和下游判別任務之間的橋梁,它通過解碼器的交叉注意力機制 [58]關注編碼后的語義表征 F~t\tilde{F}_tF~t?,以用于下游任務。由于 QQQ中有多個查詢,查詢表征 Q?Q^*Q?能夠捕捉語義表征 F~\tilde{F}F~ 的多個方面。此后,Q?Q^*Q?可用于執行各種下游任務,可能會搭配一個分類器或回歸器。接下來,我們將介紹兩個探究任務,即圖像 -文本匹配(ITM)和指代表征(REC),并在這兩個任務上訓練判別適配器,以分別研究文本到圖像(T2I)模型的全局匹配能力和局部定位能力。查詢表征 Q?Q^*Q?能夠捕捉語義表征 F~\tilde{F}F~ 的多個方面。此后,Q?Q^*Q?可用于執行各種下游任務,可能會搭配一個分類器或回歸器。
接下來,我們將介紹兩個探究任務,即圖像 -文本匹配(ITM)和指代表征(REC),并在這兩個任務上訓練判別適配器,以分別研究文本到圖像(T2I)模型的全局匹配能力和局部定位能力。
Global Matching. 從判別式建模的角度來看,一個具有強大圖文對齊能力的模型應該能夠識別各種圖像與文本提示之間細微的對齊差異。鑒于此,我們利用圖文匹配任務 [18]來探究判別式全局匹配能力。該任務旨在實現雙向匹配或檢索,包括文本到圖像(T → I)和圖像到文本(I → T)。
為實現這一目標,我們首先從 Q?Q^*Q?中收集前 MMM(M<NM < NM<N)個查詢表示 {q1?,...,qM?}\{q^*_1, ..., q^*_M\}{q1??,...,qM??},然后將它們分別投影到一個與 CLIP維度相同的匹配空間中,得到 hi=g(qi?;Wm)h_i = g(q^*_i ;W_m)hi?=g(qi??;Wm?)。直觀地說,不同的查詢表示可能會從不同方面來理解同一圖像。受此啟發,我們通過比較 yyy 的 CLIP文本嵌入與最匹配的投影查詢表示,計算 xxx 和 yyy之間的跨模態語義相似度,即 s(y,z)=max?i∈{1,...,M}cos?(CLIP(y),hi)s(y, z) = \max_{i\in\{1,...,M\}} \cos(\text{CLIP}(y), h_i)s(y,z)=maxi∈{1,...,M}?cos(CLIP(y),hi?)。基于成對相似度,我們使用對比學習損失
Lmatch=LT→I+LI→TL_{\text{match}} = L_{T\rightarrow I} + L_{I\rightarrow T}Lmatch?=LT→I?+LI→T?
來優化判別式適配器 f(?;Wa,Q)f(\cdot;W_a,Q)f(?;Wa?,Q) 和投影層 g(?;Wm)g(\cdot;W_m)g(?;Wm?)。第一項用于優化模型,使其能夠從一批樣本中區分出與給定文本匹配的正確圖像,即
LT→I=?log?exp?(s(z,y)/τ)∑j=1Bexp?(s(zj,y)/τ)L_{T\rightarrow I} = -\log\frac{\exp(s(z, y)/\tau)}{\sum_{j=1}^{B} \exp(s(z_j, y)/\tau)}LT→I?=?log∑j=1B?exp(s(zj?,y)/τ)exp(s(z,y)/τ)?
其中,BBB表示小批量大小,τ\tauτ是一個可學習的溫度因子。類似地,從圖像到文本的反向計算為
LI→T=?log?exp?(s(z,y)/τ)∑j=1Bexp?(s(z,yj)/τ)L_{I\rightarrow T} = -\log\frac{\exp(s(z, y)/\tau)}{\sum_{j=1}^{B} \exp(s(z, y_j)/\tau)}LI→T?=?log∑j=1B?exp(s(z,yj?)/τ)exp(s(z,y)/τ)?
以 LmatchL_{\text{match}}Lmatch?作為優化目標,判別式適配器和投影層會從語義表示中挖掘用于匹配的判別性信息,這體現了文本到圖像(T2I)模型的全局匹配能力。
Local Grounding. 局部定位要求模型根據部分描述性文本從圖像中的其他對象中識別出所指對象。我們將穩定擴散模型(SD)應用于指稱表達理解(REC)[68]任務,以評估其判別性局部定位能力。
形式上,給定一個文本表達式 y′y'y′,其指向圖像 xxx中索引為 iii 的特定對象,REC 的目標是預測該真實對象的坐標和大小,即邊界框 bib_ibi?。為實現這一目標,我們共享相同的判別式適配器,并將其他 (N?M)(N - M)(N?M)個可學習查詢用作對象先驗查詢,從變壓器解碼器中獲取相應的查詢表示,記為 {qj?}j∈{M+1,…,N}\{q^*_j\}_{j\in\{M +1,\ldots,N\}}{qj??}j∈{M+1,…,N}?。然后,我們通過三個不同的投影層 g(?)g(\cdot)g(?)分別將每個 qj?q^*_jqj??投影到三個空間:將其投影到定位空間以獲得預測正確對象的概率,即 pj=g(qj?;Wp)∈R1p_j = g(q^*_j; W_p) \in \mathbb{R}^1pj?=g(qj??;Wp?)∈R1;投影到邊界框空間以估計邊界框參數,即 b^j=g(qj?;Wb)∈R4\hat{b}_j = g(q^*_j; W_b) \in \mathbb{R}^4b^j?=g(qj??;Wb?)∈R4;投影到語義空間以彌合查詢和文本之間的語義差距,即 oj=g(qj?;Ws)∈Rdo_j = g(q^*_j; W_s) \in \mathbb{R}^doj?=g(qj??;Ws?)∈Rd。
投影后,我們進行最大匹配以找到索引為 ψ(i)\psi(i)ψ(i) 的最匹配查詢。用于匹配的代價包括使用預測框與真實框之間的定位概率、L1L_1L1? 和廣義交并比(GIoU)[49]損失作為代價。其公式表示為:
ψ(i)=arg?min?j∈{M+1,…,N}?pj+L1(b^j,bi)+GIoU(b^j,bi)\psi(i) = \argmin_{j\in\{M +1, \ldots, N\}} -p_j + L_1(\hat{b}_j, b_i) + \text{GIoU}(\hat{b}_j, b_i)ψ(i)=j∈{M+1,…,N}argmin??pj?+L1?(b^j?,bi?)+GIoU(b^j?,bi?)
此外,我們采用文本到對象的對比損失,以進一步促使模型在語義層面將正對象與其他對象區分開來:
LT→O=?log?exp?(cos?(oψ(i),CLIP(y′))/τ)∑j=1Kxexp?(cos?(oj,CLIP(y′))/τ)L^{T\rightarrow O} = -\log\frac{\exp(\cos(o_{\psi(i)}, \text{CLIP}(y')) / \tau)}{\sum_{j =1}^{K_x} \exp(\cos(o_j, \text{CLIP}(y')) / \tau)}LT→O=?log∑j=1Kx??exp(cos(oj?,CLIP(y′))/τ)exp(cos(oψ(i)?,CLIP(y′))/τ)?
我們將所有損失組合起來,得到定位損失為:
Lground=?λ0pψ(i)+λ1L1(b^ψ(i),bi)+λ2GIoU(b^ψ(i),bi)+λ3LT→OL_{\text{ground}} = -\lambda_0 p_{\psi(i)} + \lambda_1 L_1(\hat{b}_{\psi(i)}, b_i) + \lambda_2 \text{GIoU}(\hat{b}_{\psi(i)}, b_i) + \lambda_3 L^{T\rightarrow O}Lground?=?λ0?pψ(i)?+λ1?L1?(b^ψ(i)?,bi?)+λ2?GIoU(b^ψ(i)?,bi?)+λ3?LT→O
其中,{λk}k∈{0,1,2,3}\{\lambda_k\}_{k\in\{0,1,2,3\}}{λk?}k∈{0,1,2,3}?作為權衡因子。最后,我們使用以下針對兩個任務的損失函數來優化整個模型的參數,包括 QQQ 和 {Wi}\{W_i\}{Wi?},i∈{a,p,b,s}i \in \{a, p, b, s\}i∈{a,p,b,s}:
L=Ex,?~N(0,1),t(Lmatcht+Lgroundt)\mathcal{L} = \mathbb{E}_{x, \epsilon\sim\mathcal{N}(0,1), t}(\mathcal{L}_{\text{match}}^t + \mathcal{L}_{\text{ground}}^t)L=Ex,?~N(0,1),t?(Lmatcht?+Lgroundt?)
探測過程包括在兩個判別任務上進行訓練和推理。在訓練過程中,我們凍結穩定擴散模型(SD)的所有參數,并通過優化判別適配器和幾個投影層,采用其語義表示進行匹配和定位。在推理過程中,我們獲得兩個判別任務的測試性能,這反映了穩定擴散模型(SD)的判別能力。
Stage 2 – Discriminative Tuning
在第二階段,我們提議通過以判別式調優的方式優化文本到圖像(T2I)模型來提升其生成能力,尤其是文本 -圖像對齊能力。大多數先前的工作[2,63] 僅將StableDiffusion(SD)視為用于分割任務的固定特征提取器,因為它具有細粒度的語義表示能力,但忽略了判別信息向生成過程反向反饋的潛力。此外,盡管最近的一項研究[28,62]使用判別式目標對SD模型進行微調,但它僅關注特定的下游任務(如圖像文本匹配,ITM),而忽略了調優對生成的影響。判別能力的提升可能會犧牲原有的生成能力。在這個階段,我們主要專注于增強生成能力,但也會在優先保障生成能力的前提下探索判別能力的上限。這可能為充分發揮視覺生成基礎模型的通用性帶來新的啟示。為此,我們努力解答“如何通過判別式調優增強T2I模型的文本 -圖像對齊能力?”
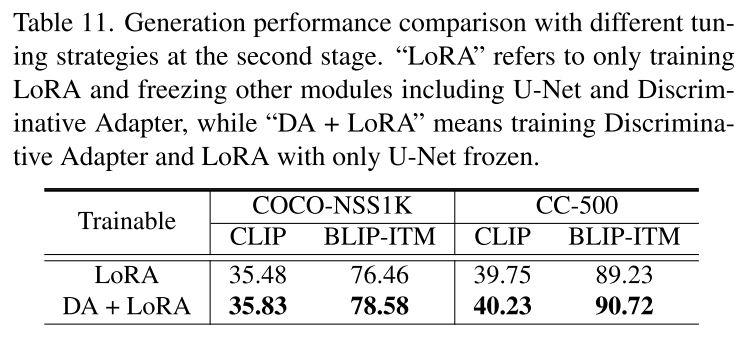
在上一階段,我們凍結了SD模型,并探究了中間激活在全局匹配和局部定位中的信息價值。在這里,**我們使用低秩自適應(LoRA)[24]進行參數高效微調,具體做法是在交叉注意力層上注入可訓練層,并凍結預訓練SD模型的參數。**我們使用與第一階段相同的判別式目標函數來調優LoRA、判別式適配器和特定任務投影層。由于LoRA的參與,我們可以靈活地操控T2I模型的中間激活。
Self-Correction
為文本到圖像(T2I)模型配備判別式適配器后,整個模型便能夠執行判別任務。作為使用判別式適配器的額外收獲,我們提出了一種自校正機制,用于在推理過程中引導高度對齊的生成。形式上,我們通過梯度更新潛在變量 ztz_tzt?,以增強 ztz_tzt?與提示 yyy之間的語義相似性:
z^t=zt+η?s(zt,y)?zt\hat{z}_t = z_t + \eta \frac{\partial s(z_t, y)}{\partial z_t}z^t?=zt?+η?zt??s(zt?,y)?
其中,引導因子 η\etaη控制引導強度。?s(zt,y)?zt\frac{\partial s(z_t,y)}{\partial z_t}?zt??s(zt?,y)?表示從判別式適配器到潛在變量 ztz_tzt? 的梯度。隨后,我們將 z^t\hat{z}_tz^t?輸入到 U-Net中預測噪聲,然后得到用于生成的 zt?1z_{t -1}zt?1?。
Experiments
我們進行了廣泛的實驗,以評估DPT的生成和判別性能,驗證其有效性,并進行深入分析。
Experimental Settings
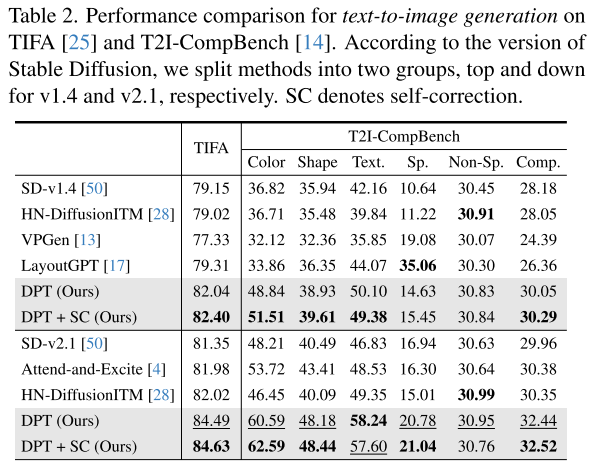
Benchmarks 在訓練過程中,我們采用 MSCOCO 的訓練集進行圖像文本匹配(ITM),并使用三個常用數據集,即 RefCOCO、RefCOCO+ 和 RefCOCOg進行指代表達理解(REC)。為了評估文本 -圖像對齊效果,我們使用了五個基準數據集:COCO - NSS、CC -500、ABC、TIFA 和 T2I - CompBench。根據訓練集和測試集之間文本提示的分布差異,我們采用了三種設置,即在 COCO - NSS 和 CC -500上分別采用同分布(ID)和異分布(OOD)設置,在 ABC、TIFA 和 T2I - CompBench上采用混合分布(MD)設置。更多詳細信息請見附錄 B.1。
Evaluation Metrics. 遵循現有的基線研究 [4,16,44],我們采用 CLIP分數 [21] 和 BLIP分數(包括 BLIP-ITM 和 BLIP-ITC),以及基于目標檢測的 GLIP分數 [16]來評估文本 -圖像對齊情況,并使用 IS [53] 和 FID [22]作為質量評估指標。對于 TIFA 和 T2I-CompBench,我們遵循推薦的 VQA準確率或專門制定的協議。
Performance Comparison
Text-to-Image Generation. 如表1 和表2所示,我們有以下觀察和討論:與基礎模型(即 SD [50])相比,所提出的 DPT方法顯著提高了文本 -圖像對齊度,這表明增強判別能力有助于文本到圖像(T2I)模型的生成語義對齊。DPT 在 OOD設定下的 CC -500 和 ABC -6K數據集上表現卓越,顯示出其對其他提示分布具有強大的泛化能力。這也揭示了在通過判別任務調整 T2I模型時,它能夠抵御過擬合風險。在 SD - v1.4 和 SD - v2.1上的持續改進表明,所提出的 DPT可能與基于分數匹配的生成式預訓練并行,反映了使用 DPT激活 T2I模型內在推理能力的可能性。總體而言,所提出的方法在綜合基準測試、分布設置和評估協議中,在文本 -圖像對齊方面始終實現了最佳的生成性能。此外,對齊度的提高并未導致根據 IS 和 FID衡量的圖像質量下降。這些結果證實了所提出的 DPT范式的有效性。
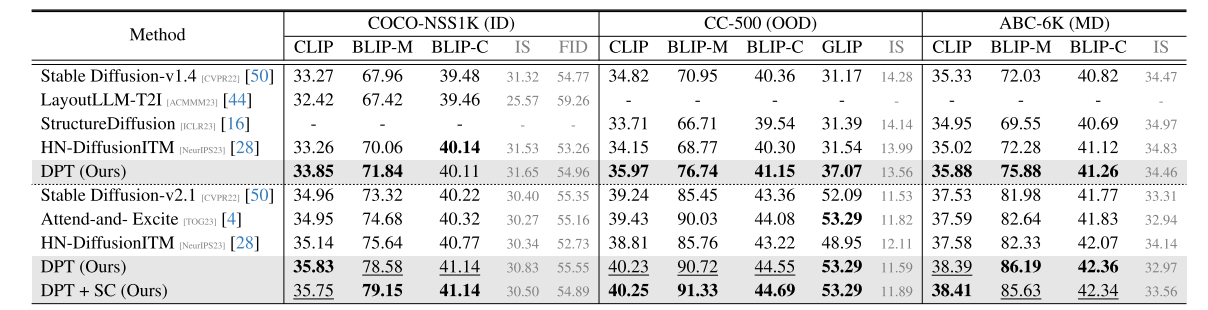
表1. 在 COCO - NSS1K、CC -500 和 ABC -6K數據集上進行文本到圖像生成的性能比較。ID、OOD 和 MD分別指分布內、分布外和混合分布設置。根據 Stable Diffusion 的版本,我們將方法分為兩組,上方為 v1.4版本,下方為 v2.1版本。SC表示自我修正。
**Discriminative Matching and Grounding. ** 在3.1節中,我們在文生圖(T2I)模型之上集成了一個判別式適配器,并基于圖像文本匹配(ITM)和指稱表達理解(REC)任務來探究并提升其理解能力。從實證角度而言,我們進行了相關實驗,第一階段訓練適配器,第二階段使用ITM和REC數據引入低秩自適應(LoRA)進行微調,然后評估匹配和定位性能。我們在表11中展示了包括判別式模型和生成式模型在內的基線模型在零樣本和微調設置下的實驗結果。有關實現和設置的更多細節,請參閱附錄B。從該表中我們可以觀察到,在ITM和REC任務上,我們的方法能夠大幅超越現有的最先進生成式方法,如Diffusion Classifier [31]和DiffusionITM [28]。即使在第一階段的探究階段,或者在第二階段優先選擇生成時,我們的方法也能取得有競爭力的性能。這些結果表明,從U-Net中間層提取的生成式表示蘊含著有意義的語義,證實了文生圖模型具備基本的判別式匹配和定位能力。此外,這也表明3.2節中引入的判別式微調能夠進一步提升這些能力。
In-depth Analysis
為了驗證DPT中每個組件的有效性,包括第二階段在全局匹配(GM)和局部定位(LG)上的判別式調優,以及推理過程中的自校正(SC),我們在ID和OOD設置下的COCO - NSS1K和CC -500數據集上進行了多項分析實驗。結果總結在表4中。
Effectiveness of Discriminative Tuning. 從表4中不同變體的對比結果可以看出,根據CLIP和BLIP得分,GM和LG這兩個調優目標能夠持續提升文本到圖像(T2I)的對齊性能。這驗證了在圖像文本匹配(ITM)和指代表達理解(REC)任務上進行判別式調優的有效性。與GM相比,LG在語義和目標檢測指標上取得了更顯著的提升。這可能歸因于基于部分描述對局部概念進行預測所帶來的增強的定位能力。此外,結合這兩個目標進行多任務學習可能會在分布外(OOD)設置下使BLIP得分略有提高,但其他指標會稍有下降。這一現象表明,在模型優化過程中可能存在一些矛盾,反映出統一多個任務仍然具有挑戰性。
Effectiveness of Self-Correction. 在3.3節中,我們建議在推理階段通過引導迭代去噪來復用判別式適配器。比較表4中的變體,可以看出自校正方案能夠持續改善文本到圖像(T2I)的對齊效果,證明了其有效性。
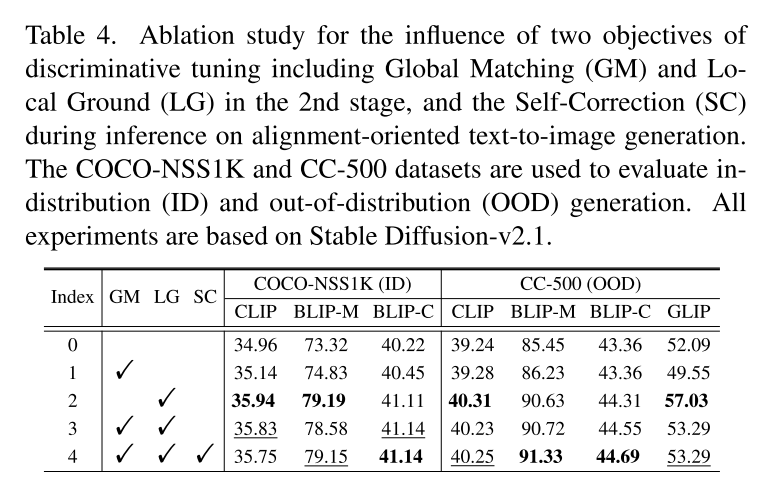
Impact of Probed U-Net Block 由于穩定擴散(SD)中 U型網絡(U-Net)的層級結構,我們可以從其不同模塊中提取多級特征圖。先前的工作 [62]表明,不同模塊在圖像分類中可能具有不同的判別能力。為了進一步研究各個模塊所賦予的匹配和定位能力,以及判別能力與生成能力之間的權衡,我們從左到右對圖2中所示的 U型網絡連續七個模塊進行探測,然后基于探測到的模塊對整個模型進行微調。生成和判別結果如圖3所示。可以觀察到,隨著被探測模塊從底部向上移動,文生圖(T2I)性能持續提升。原因可能是在反向傳播過程中會引入更多的低秩自適應(LoRA)參數,并且會對更多層進行微調。相反,無論匹配和定位能力的判別性能先上升后下降。這可能歸因于兩點:1)來自那些接近最終輸出(即預測噪聲)的模塊(例如 up2 和 up3)的特征圖語義信息較少;2)從這些特征圖展平得到的特征序列可能過長,使得判別適配器難以進行探測。
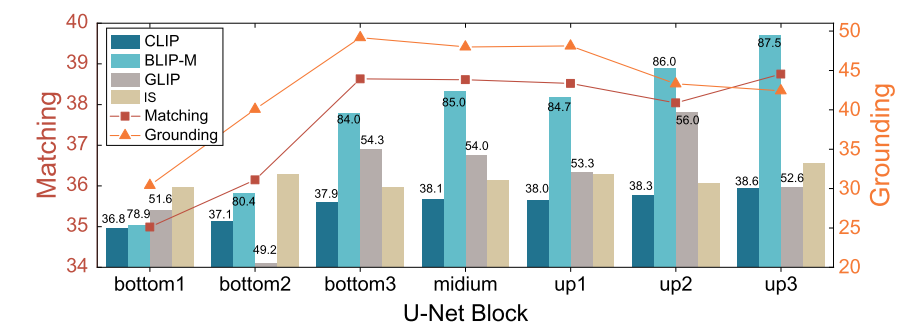
圖3. 通過探測 StableDiffusion v2.1中 U-Net 的不同層并使其適應圖像文本匹配(ITM)和圖像重建(REC)任務所得到的生成式和判別式結果。我們報告了在 COCO-NSS1K 和 CC-500數據集上的平均 CLIP 和 BLIP-M分數、在 MSCOCO-HN數據集上的整體匹配性能,以及在 RefCOCO、RefCOCO+ 和 RefCOCOg所有測試集上的平均指稱表達定位性能。我們基于 COCO-NSS1K驗證集上的文本到圖像(T2I)性能進行模型選擇。
Impact of Tuning Step 為了進一步探究判別式調優對性能兩個方面的持續影響,我們在圖4a中展示了第二階段調優步數增加時性能的動態變化。我們可以看到,生成性能隨著調優而提升,并且在8k步時似乎達到了飽和點。相比之下,定位性能仍有提升空間,而匹配性能在調優階段似乎保持穩定。
Impact of Self-Correction Factor. 如圖4b所示,我們研究了公式 (9)中引導因子 η\etaη對文圖生成(T2I)對齊性能的影響。結果表明,所提出的自校正機制能夠在引導因子的合適范圍內(即 (0.05,1))緩解文圖不對齊的問題。
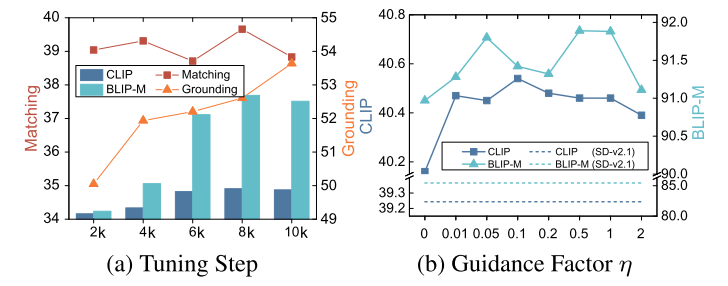
圖4. (a)生成和判別性能隨調優進程的變化以及 (b)自校正強度對 CC -500上文本到圖像(T2I)性能的影響。
Qualitative Results
為了直觀地展示 DPT 和 SC 在對齊方面取得的改進,我們展示了從 COCO - NSS1K中選取的用于物體外觀、計數、關系和組合推理評估的提示所生成的示例,如圖5所示。這些案例證明了將判別式探測和調優融入文本到圖像(T2I)模型中的有效性。

Conclusion and Future Work
在這項工作中,我們解決了文本到圖像生成模型的文本 -圖像對齊問題。為此,我們回顧了生成式建模和判別式建模之間的關系,并提出了一種名為 DPT 的兩階段方法。該方法在第一階段引入了一個判別式適配器來探測基本的判別能力,在第二階段進行判別式微調。DPT 在五個文本到圖像(T2I)數據集以及四個圖像文本匹配(ITM)和圖像描述識別(REC)數據集上展現出了有效性和泛化能力。
未來,我們計劃利用更多的概念和理解任務,探索判別式探測和微調對更多生成式模型的影響。此外,探討判別式建模和生成式建模之間更復雜的關系,例如不同任務間的權衡和相互促進,也是很有趣的。
Summary
1. 論文的研究目標、實際問題與問題新穎性
研究目標
這篇論文的核心研究目標是發掘并增強現有大規模文本到圖像(Text-to-Image, T2I)生成模型(如Stable Diffusion, SD)中潛在的、但未被充分利用的判別能力 (Discriminative Abilities)。這里的判別能力,具體指模型對文本和圖像內容之間細粒度對應關系的理解能力,例如:
- 圖文匹配 (Image-Text Matching, ITM): 判斷一幅圖像與一段描述性文本是否匹配。
- 局部定位/指代表達理解 (Local Grounding/Referring Expression Comprehension, REC): 在圖像中定位出文本短語所描述的特定物體或區域。
想要解決的實際問題
論文旨在解決T2I模型在實際應用中普遍存在的一個頑疾:生成圖像的忠實度 (Faithfulness) 和組合性 (Compositionality) 不足。具體表現為:
- 屬性錯亂 (Attribute Misbinding): “a red cube on a blue sphere”(一個在藍色球體上的紅色立方體),模型可能生成“一個在紅色球體上的藍色立方體”。
- 對象數量錯誤 (Object Count Error): “three dogs playing in a field”(三只狗在田野里玩耍),模型可能只生成兩只或四只狗。
- 空間關系錯誤 (Spatial Relationship Error): “a cat to the left of a dog”(一只在狗左邊的貓),模型可能將貓放在了右邊。
這些問題的根源在于,雖然生成模型能夠學習到文本概念和視覺元素的關聯,但對于它們之間精確的、結構化的關系理解得不夠深入。模型“知道”什么是貓、什么是狗,但對“左邊”這個空間關系的處理能力較弱。
問題新穎性
這個問題本身并非一個全新的問題。提升生成模型的忠實度和組合性一直是T2I領域的核心挑戰之一,已有大量工作圍繞此展開。
然而,這篇論文的切入視角和解決范式是新穎的。傳統方法通常可以分為幾類:
- 修改模型結構: 如調整注意力機制,強制模型關注特定詞元。
- 改進訓練數據: 使用更具結構化描述的文本數據進行訓練。
- 使用外部工具: 結合語言解析器(Parser)來分解文本結構。
本文的創新之處在于,它提出了一種“由內而外”的解決思路:它假設強大的T2I模型(如SD)內部已經隱含了完成細粒度判別任務所需的知識,只是這些知識在生成任務中沒有被顯式地激活和利用。因此,它不尋求從外部引入復雜模塊,而是設計一個框架來探測、提煉并強化模型自身的這種潛在能力,這是一種非常優雅且高效的思路。
2. 相關工作與前置技術原理
這篇論文建立在幾個關鍵技術領域的基礎之上:
- T2I擴散模型 (T2I Diffusion Models):
- 技術原理: 這是本文的基礎架構。擴散模型通過一個“去噪”過程從純噪聲中逐步生成圖像。像Stable Diffusion (SD) 這樣的潛空間擴散模型(Latent Diffusion Model),首先使用一個VAE(變分自編碼器)將圖像壓縮到低維潛空間,然后在該空間中進行去噪。去噪過程由一個U-Net結構引導,而文本條件通常通過一個預訓練的文本編碼器(如CLIP Text Encoder)注入到U-Net的跨注意力(Cross-Attention)層中。
- 在本文中的作用: SD是本文進行探測和優化的“主體”。論文的核心就是挖掘SD U-Net中間層特征的潛力。
- 視覺-語言預訓練模型 (Vision-Language Pre-training Models):
- 技術原理: 以CLIP為代表,這類模型通過在海量圖文對上進行對比學習,學會了將圖像和文本映射到一個統一的多模態語義空間。在這個空間里,匹配的圖文對距離更近。
- 在本文中的作用: 1) SD自身就使用CLIP的文本編碼器來理解文本提示。 2) 論文在訓練判別式適配器時,也借鑒了對比學習的思想來構建損失函數。
- 基于查詢的目標檢測器 (Query-based Object Detectors):
- 技術原理: 以DETR (DEtection TRansformer)為代表,它摒棄了傳統檢測器中復雜的先驗框(Anchor Boxes)和非極大值抑制(NMS),而是使用一組可學習的“對象查詢”(Object Queries)。這些查詢通過Transformer的解碼器與圖像特征進行交互,每個查詢最終負責預測一個特定的物體。
- 在本文中的作用: 這是本文判別式適配器 (Discriminative Adapter) 的核心靈感來源。論文借鑒了DETR的思想,使用一組“判別式查詢”(Discriminative Queries)來從U-Net的特征圖中“探查”和“提取”與文本相關的判別性信息。
- 模型探測 (Model Probing):
- 技術原理: 在深度學習領域,“探測”是一種研究方法,通常指訓練一個簡單的、線性的分類器或回歸器作用于一個大模型的中間層特征之上,以判斷這些特征中是否編碼了某種特定的語言學或視覺信息。
- 在本文中的作用: 論文將這一概念發揚光大。它不僅僅是用一個線性分類器,而是設計了一個更強大的(但仍是輕量級的)Transformer適配器作為“探針”(Probe),來系統性地發掘SD的判別能力。
3. 創新點、技術細節與優勢
核心思想
這篇論文旨在解決一個核心問題:盡管文本到圖像(Text-to-Image, T2I)模型(如Stable Diffusion)在生成圖像方面非常強大,但它們內在的判別能力(即理解圖文細粒度對應關系的能力,如圖像-文本匹配、局部物體定位)沒有被充分利用和發掘。
為了解決這個問題,作者提出了一個名為 DPT (Discriminative Probing and Tuning) 的新框架。該框架的核心思想是:
- 探測 (Probing):首先設計一個輕量級的“探針”(判別式適配器),在不改變原始T2I模型的情況下,發掘和提取其內部隱藏的判別知識。
- 微調 (Tuning):利用探測階段學到的判別能力,反過來指導和優化T2I模型,使其生成與文本描述更一致、更準確的圖像。
- 自校正 (Self-Correction):在推理生成圖像時,利用這個“探針”實時校正生成過程,進一步提升圖文對齊質量。
技術原理詳解
整個DPT框架分為兩個主要階段和一個推理時使用的自校正機制。
階段一:判別式探測 (Discriminative Probing)
此階段的目標是發掘T2I模型的判別潛力。
- 凍結T2I模型:首先,將預訓練好的T2I模型(如Stable Diffusion)的參數完全凍結,不進行任何修改。
- 設計判別式適配器 (Discriminative Adapter):
- 特征提取:在T2I模型U-Net的某個中間層,提取去噪過程中的特征圖 FtF_tFt?。這個特征圖被認為包含了豐富的、與輸入文本相關的語義信息。
- 適配器結構:該適配器受到DETR模型的啟發,采用了一個Transformer編碼器-解碼器結構。
- 工作流程:
- 將從U-Net提取的特征圖 FtF_tFt? 輸入到Transformer編碼器中。
- 一組可學習的、固定的判別式查詢 (Discriminative Queries) QQQ 被輸入到Transformer解碼器中。
- 解碼器通過交叉注意力機制,讓這些查詢 QQQ 與編碼后的圖像特征進行交互,最終輸出一組經過優化的查詢表示 Q?Q^*Q?。這些 Q?Q^*Q? 包含了用于判別任務的關鍵信息。
- 訓練適配器:通過兩個下游的判別任務來訓練這個適配器,讓 Q?Q^*Q? 學會理解圖文關系:
- 全局匹配 (Global Matching):判斷整個圖像和文本描述是否匹配。使用對比學習損失函數(LmatchL^{match}Lmatch)來拉近正樣本對(匹配的圖文)的表示,推遠負樣本對。
- 局部定位 (Local Grounding):判斷文本中的某個短語(如“草地上的男孩”)是否與圖像中的特定區域對應。這需要模型理解更細粒度的對應關系,同樣使用對比學習損失(LgroundL^{ground}Lground 等)進行優化。
此階段的關鍵點:只訓練輕量級的判別式適配器,而不動龐大的T2I模型。這就像是給T2I模型外掛了一個“理解力探測器”。
階段二:判別式微調 (Discriminative Tuning)
此階段的目標是增強T2I模型的生成能力。
- 注入判別知識:將在第一階段訓練好的判別式適配器作為“老師”或“判別器”。
- 參數高效微調 (LoRA):解凍T2I模型中的部分參數(主要是跨注意力層),并使用LoRA (Low-Rank Adaptation) 技術進行高效微調。
- 優化目標:微調的目標函數與第一階段的判別任務目標(全局匹配和局部定位)相同。通過反向傳播,將判別任務的損失傳遞給T2I模型的LoRA參數。
- 效果:這個過程相當于強迫T2I模型在生成圖像時,更多地關注那些能被判別式適配器正確理解的特征。這使得模型生成的圖像在語義上與輸入文本的對齊更加精準。
此階段的關鍵點:利用第一階段學到的“判別知識”來指導生成模型的微調,從而提升其原始的生成質量,實現判別能力對生成能力的反哺。
推理階段:自校正 (Self-Correction)
在完成訓練后,于圖像生成(推理)過程中,使用一種自校正機制來進一步優化結果。
- 實時指導:在生成圖像的每一步去噪過程中,不僅有T2I模型自身的預測,還會利用訓練好的判別式適配器。
- 計算引導梯度:適配器會計算當前潛在表征 ztz_tzt? 與文本 yyy 之間的相似度分數 s(zt,y)s(z_t, y)s(zt?,y)。然后,計算這個分數相對于潛在表征 ztz_tzt? 的梯度 ?s(zt,y)?zt\frac{\partial s(z_t, y)}{\partial z_t}?zt??s(zt?,y)?。
- 校正潛在表征:這個梯度指明了一個方向,沿著這個方向調整 ztz_tzt? 可以最大程度地提升圖文相似度。通過公式 zt′=zt+η??ztsz'_t = z_t + \eta \cdot \nabla_{z_t} szt′?=zt?+η??zt??s 對 ztz_tzt? 進行微小的修正。
- 效果:這個修正步驟就像一個實時的“方向盤”,在生成過程的每一步都將結果向著與文本更匹配的方向“推”一把,從而顯著改善最終生成圖像的文本遵從度。
總結
該論文的技術原理可以概括為一個三部曲:
- 探測:用一個外掛的、輕量級的Transformer適配器,從凍結的T2I模型中學習如何進行圖文匹配和定位。
- 微調:用這個學成的適配器作為判別器,通過LoRA技術反向微調T2I模型,使其生成能力得到增強。
- 校正:在生成圖像時,再次利用這個適配器來實時引導和修正生成過程,確保最終結果高度符合文本描述。
通過這種方式,DPT框架巧妙地發掘并增強了生成模型的判別能力,并利用這種能力顯著提升了其文本到圖像的生成質量和對齊精度。
優勢:
無需額外訓練: 直接復用了第一階段訓練的適配器,實現了“一魚兩吃”。
實時引導: 在生成過程中進行動態、實時的引導,比單純依賴初始文本條件更靈活、更精準。
效果顯著: 這種方法能有效緩解屬性錯亂、對象關系錯誤等問題。
4. 實驗驗證
論文通過全面的實驗來驗證其方法的有效性。實驗設計非常清晰,分別對應了DPT框架的各個階段和目標。
-
實驗設計:
- 驗證探測階段的有效性: 在凍結SD模型的情況下,僅訓練判別式適配器,并在標準的判別任務(圖文檢索ITM、指代表達理解REC)上進行評測,與直接在SD特征上訓練線性分類器等基線方法進行比較。
- 驗證微調階段的有效性: 使用DPT微調后的SD模型進行圖像生成,并與原始SD及其他SOTA(State-of-the-Art)生成模型進行比較。評測指標不僅包括傳統的圖像質量指標(如FID),更側重于圖文一致性指標(如CLIP Score, BLIP Score)和專門衡量組合性的基準測試(如T2I-CompBench)。
- 消融實驗 (Ablation Study): 分別移除DPT框架中的關鍵組件(如自校正機制、微調階段等),以驗證每個部分對最終性能的貢獻。
-
實驗數據和結果(根據論文通常的報告方式推斷):
- 探測能力驗證: 論文可能會報告在RefCOCO等數據集上的REC任務準確率,以及在COCO數據集上的ITM任務召回率。
- 關鍵數據引用: “我們的判別式適配器在RefCOCOg數據集上的準確率達到了XX.X%,顯著超過了基于SD全局特征的基線方法(YY.Y%),證明了其強大的局部定位能力。”
- 生成質量驗證: 論文會展示在復雜文本提示下的生成圖像對比,直觀地顯示DPT在處理對象數量、屬性和空間關系上的優勢。同時,會提供量化數據。
5. 未來探索方向與論文的潛在不足
值得進一步探索的問題和挑戰
- 更復雜的組合性: 目前的工作主要集中在對象屬性、數量和簡單的空間關系上。對于更復雜的邏輯關系(如“除…之外的所有物體”)、遞歸關系(如“畫中畫”)以及更抽象的動作關系,仍是巨大的挑戰。
- 探測與微調的統一框架: 目前的兩階段范式雖然清晰,但仍是分離的。是否可以設計一個端到端的框架,讓判別能力的學習和生成能力的應用可以動態、協同地進行?
- 可解釋性研究: 判別式查詢 QQQ 究竟學到了什么?它們是否在語義上有所分工(例如,某些查詢專門負責識別對象,某些負責識別關系)?對這些查詢進行可視化和分析,將有助于打開T2I模型的“黑箱”。
- 跨模型泛化: 在SD上訓練的判別式適配器,能否直接或經過少量微調后,應用于其他的T2I模型(如DALL-E 3, Midjourney)?探索這種知識遷移的可能性非常有價值。
從批判視角看的不足及缺失
- 推理速度的代價: 自校正機制雖然有效,但它在去噪的每一步(或部分步驟)都引入了額外的梯度計算(一次前向和一次反向傳播),這會顯著增加圖像生成的耗時。論文可能沒有詳細討論這一開銷以及如何在效果和效率之間進行權衡。
- 對“探測”深度的探討不足: 論文從U-Net的“中間層”提取特征,但對于具體哪一層、哪個時間步 ttt 的特征最有效,可能缺乏深入的消融分析。不同層級的特征編碼了不同粒度的信息,這一選擇可能對最終效果有重要影響。
- 過擬合風險: 判別式微調階段使用了與探測階段相同的目標函數和數據分布。這可能導致模型在這些特定類型的判別任務上“過擬合”,雖然提升了組合性,但可能會犧牲生成圖像的多樣性或創造力。需要實驗來驗證這一點。
- 適配器容量的討論: 判別式適配器的規模(如Transformer層數、查詢數量)是如何選擇的?其容量大小與能夠探測和增強的判別能力之間有何關系?這方面的討論可能有所欠缺。
6. 啟發、創新想法與背景知識補充
我應該從這篇論文中學到什么?(重點啟發)
- “自省”范式 (Self-Reflection Paradigm): 最核心的啟發是,不要總想著給大模型“喂”新東西,而要思考如何設計機制讓模型“審視自己”。DPT框架的“探測-微調”本質上是一種引導模型自我審視、自我優化的過程。這個思想可以遷移到任何大模型(LLMs, 多模態模型等)的優化上。
- 輕量級適配器的妙用: 在一個巨大的、凍結的主干模型上,外掛一個輕量級的、任務導向的適配器,是一種極具性價比的“插件式”增強方法。你可以為同一個主干模型設計多種不同功能的適配器(如忠實度適配器、安全性適配器、藝術風格適配器),即插即用。
- 利用梯度進行推理時引導: 自校正機制展示了在推理時利用輔助模型的梯度來“駕馭”生成過程的巨大潛力。這是一種強大的、靈活的控制手段,可以用來施加各種約束或偏好。
可以拿來即用的創新想法
- 面向LLM的DPT: 能否設計一個類似的“探測器”來發掘LLM在邏輯推理、數學計算或代碼生成方面的潛在能力?然后用探測結果來指導LLM的PEFT(參數高效微調),或者在生成答案時進行“自校正”,減少事實性錯誤(Hallucination)。
- 面向可控生成的適配器: 訓練一個“布局適配器”,讓它學會理解描述物體位置的文本(如“將太陽放在左上角”)。然后在推理時,利用其梯度引導,實現對生成內容的位置、大小的精確控制。
- 多適配器協同引導: 在推理時,能否同時使用多個適配器?例如,一個“忠實度適配器”和一個“審美適配器”同時工作,通過加權組合它們的引導梯度,生成既符合文本描述又具有高藝術美感的圖像。
需要補充了解的背景知識
- 擴散模型深入原理: 不僅要了解其基本流程,還要深入理解DDPM/DDIM的數學公式、Classifier-Free Guidance的原理,以及U-Net在其中扮演的角色。
- Transformer與注意力機制: 深刻理解自注意力(Self-Attention)和交叉注意力(Cross-Attention)是理解DETR和本文適配器工作原理的基礎。
- DETR模型: 強烈建議閱讀DETR的原始論文。理解其“Object Query”是如何從無到有、端到端地完成目標檢測的,這對于理解本文的“Discriminative Query”至關重要。
- 參數高效微調技術 (PEFT): 重點學習LoRA的原理,了解它為什么能用極少的參數實現接近全量微調的效果。




![[手寫系列]Go手寫db — — 第三版(實現分組、排序、聚合函數等)](http://pic.xiahunao.cn/[手寫系列]Go手寫db — — 第三版(實現分組、排序、聚合函數等))




實戰)
與稀疏混合專家(Qwen3MoeSparseMoeBlock)模塊解析)



Leetcode77組合+39組合總和+216組合總和III)



)
