[手寫系列]Go手寫db — — 第三版
第一版文章地址:https://blog.csdn.net/weixin_45565886/article/details/147839627
第二版文章地址:https://blog.csdn.net/weixin_45565886/article/details/150869791
🏠整體項目Github地址:https://github.com/ziyifast/ZiyiDB- 🚀請大家多多支持,也歡迎大家star??和共同維護這個項目~
序言:只要接觸過后端開發,必不可少會使用到關系型數據庫,比如:MySQL、Oracle等,那么我們經常使用的字段默認值、以及聚合函數底層是如何實現的呢?本文會給大家提供一些思路,實現相關功能。
主要介紹如何在 ZiyiDB之前的基礎上,實現更多新功能,給大家提供實現數據庫的簡單思路,以及數據庫底層實現的流程,后續更多功能,大家可以參考著實現。
一、功能列表
- 默認值支持(DEFAULT 關鍵字)
- 聚合函數支持(COUNT, SUM, AVG, MAX, MIN)
- Group by分組能力
- Order by 排序能力
二、實現細節
1. 默認值實現
設計思路
默認值是數據庫中一個重要的數據完整性特性。當插入數據時,如果沒有為某列提供值,數據庫會自動使用該列的默認值。
在 ZiyiDB 中,默認值的實現需要考慮以下幾點:
- 語法解析:在 CREATE TABLE 語句中識別 DEFAULT 關鍵字和默認值
- 存儲:在表結構中保存每列的默認值
- 執行:在 INSERT 語句中應用默認值
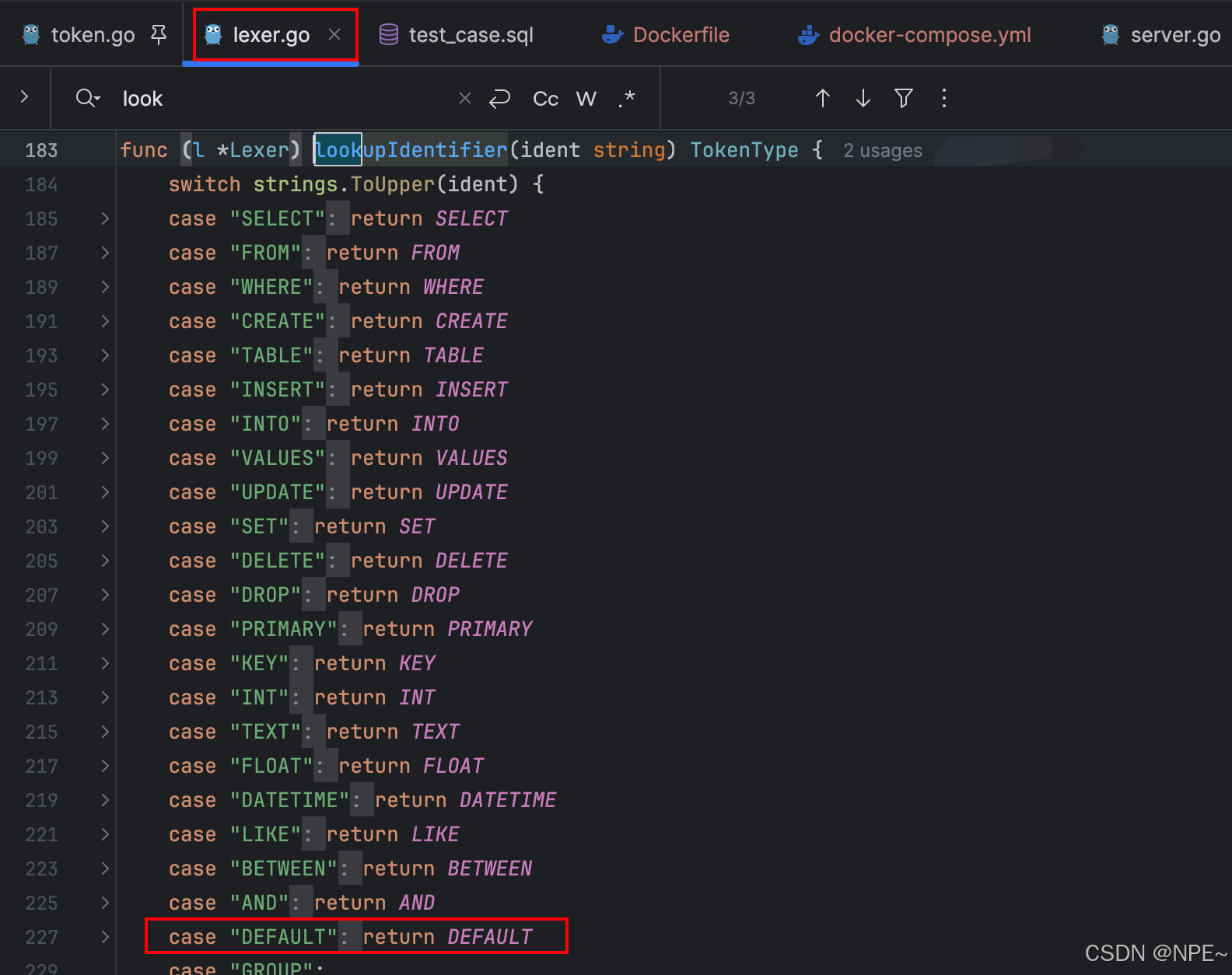
1.在lexer/token.go中新增default字符,然后在lexer/lexer.go的lookupIdentifier方法中新增對于default的case語句,用于匹配識別用戶輸入的SQL
token.go:

lexer.go:
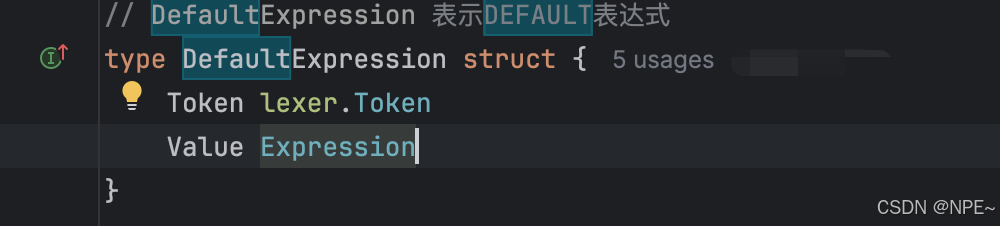
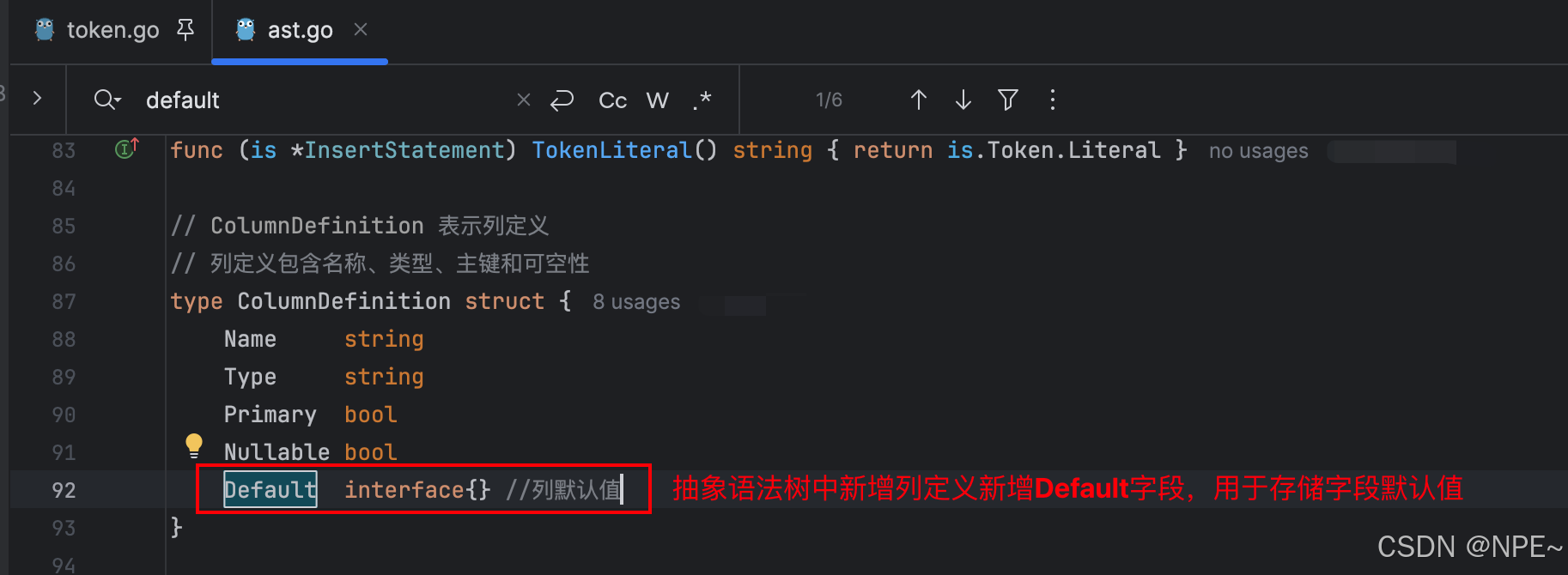
2. internal/ast/ast.go抽象語法樹中新增DefaultExpression,同時列定義中新增默認值字段,用于存儲列的默認值
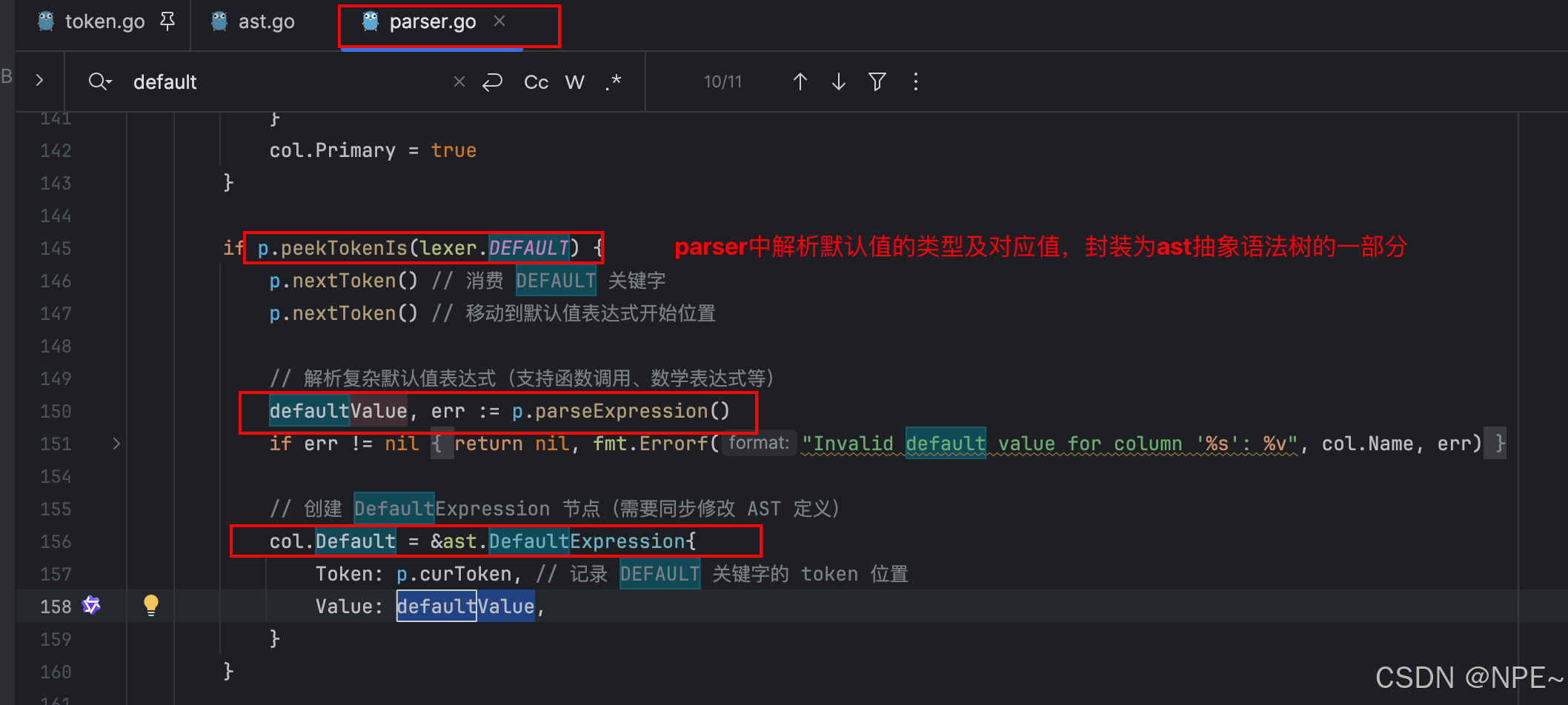
3. parser中的parseCreateTableStatement函數新增對create SQL中默認值的讀取和封裝,解析用戶輸入SQL中的字段默認值類型和value
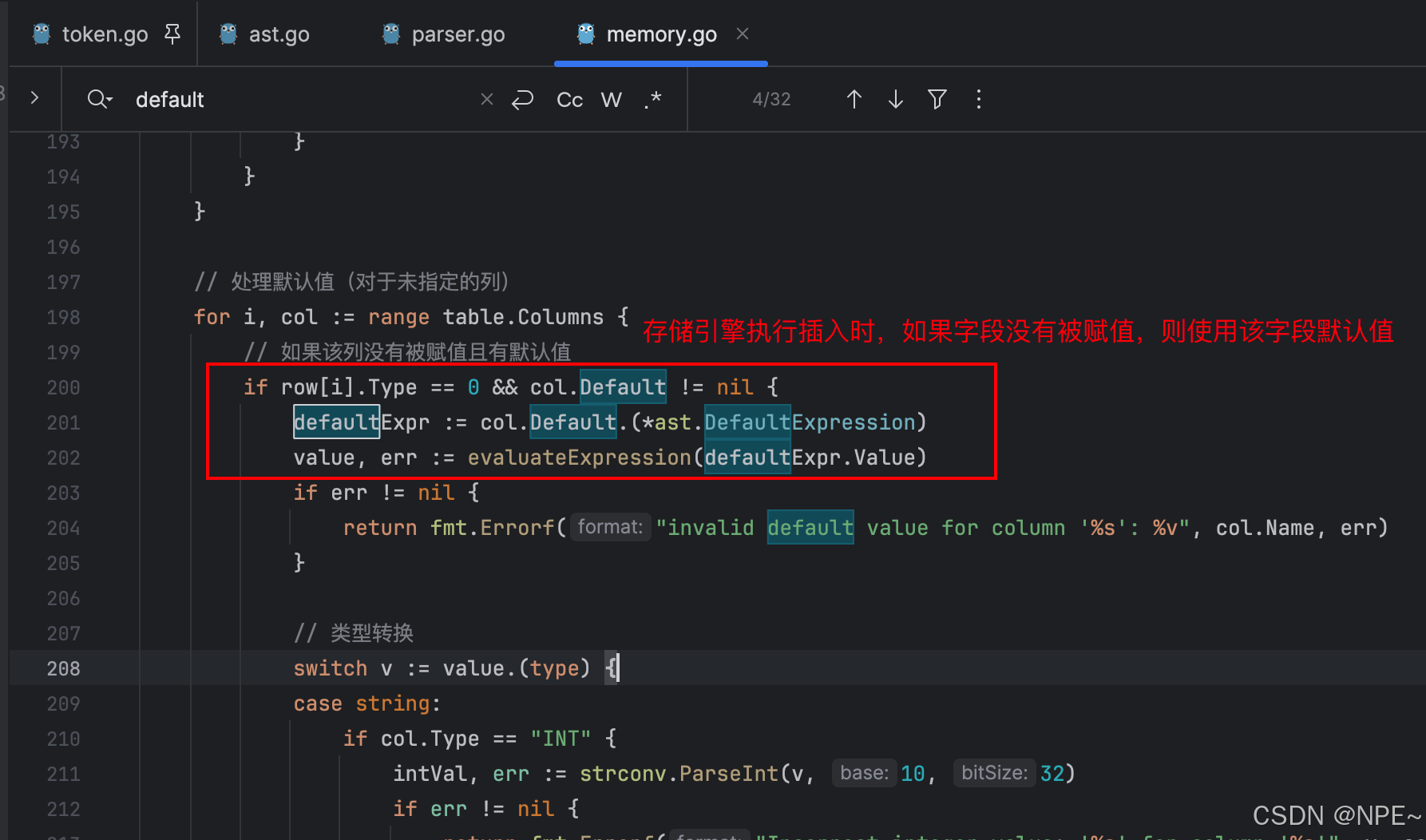
4. internal/storage/memory.go 存儲引擎處理Insert方法時,新增對默認值的處理。
代碼實現
1.語法解析層(Parser)
在 internal/parser/parser.go 中,parseCreateTableStatement 方法被增強以支持默認值:
// parseCreateTableStatement 解析CREATE TABLE語句
func (p *Parser) parseCreateTableStatement() (*ast.CreateTableStatement, error) {stmt := &ast.CreateTableStatement{Token: p.curToken}// ... 其他代碼// 解析列定義for !p.peekTokenIs(lexer.RPAREN) {p.nextToken()if !p.curTokenIs(lexer.IDENT) {return nil, fmt.Errorf("You have an error in your SQL syntax; check the manual that corresponds to your db server version for the right syntax to use near '%s'", p.curToken.Literal)}col := ast.ColumnDefinition{Name: p.curToken.Literal,}if !p.expectPeek(lexer.INT) &&!p.expectPeek(lexer.TEXT) &&!p.expectPeek(lexer.FLOAT) &&!p.expectPeek(lexer.DATETIME) {return nil, fmt.Errorf("You have an error in your SQL syntax; check the manual that corresponds to your db server version for the right syntax to use near '%s'", p.peekToken.Literal)}col.Type = string(p.curToken.Type)if p.peekTokenIs(lexer.PRIMARY) {p.nextToken()if !p.expectPeek(lexer.KEY) {return nil, fmt.Errorf("You have an error in your SQL syntax; check the manual that corresponds to your db server version for the right syntax to use near '%s'", p.peekToken.Literal)}col.Primary = true}if p.peekTokenIs(lexer.DEFAULT) {p.nextToken() // 消費 DEFAULT 關鍵字p.nextToken() // 移動到默認值表達式開始位置// 解析復雜默認值表達式(支持函數調用、數學表達式等)defaultValue, err := p.parseExpression()if err != nil {return nil, fmt.Errorf("Invalid default value for column '%s': %v", col.Name, err)}// 創建 DefaultExpression 節點col.Default = &ast.DefaultExpression{Token: p.curToken,Value: defaultValue,}}stmt.Columns = append(stmt.Columns, col)if p.peekTokenIs(lexer.COMMA) {p.nextToken()}}// ... 其他代碼
}
2.AST 定義
在 internal/ast/ast.go 中,我們添加了 DefaultExpression 類型來表示默認值:
// DefaultExpression 表示DEFAULT表達式
type DefaultExpression struct {Token lexer.TokenValue Expression
}func (de *DefaultExpression) expressionNode() {}
func (de *DefaultExpression) TokenLiteral() string { return de.Token.Literal }
同時,ColumnDefinition 結構也被更新以包含默認值:
// ColumnDefinition 表示列定義
type ColumnDefinition struct {Name stringType stringPrimary boolNullable boolDefault interface{} //列默認值
}
3.存儲引擎實現
在 internal/storage/memory.go 中,Insert 方法被增強以支持默認值:
// Insert 插入數據
func (b *MemoryBackend) Insert(stmt *ast.InsertStatement) error {table, exists := b.tables[stmt.TableName]if !exists {return fmt.Errorf("Table '%s' doesn't exist", stmt.TableName)}// 構建列名到表列索引的映射colIndexMap := make(map[string]int)for idx, col := range table.Columns {colIndexMap[col.Name] = idx}// 初始化行數據(長度為表的總列數)row := make([]ast.Cell, len(table.Columns))// 處理插入列列表(用戶顯式指定的列或隱式全列)var insertCols []*ast.Identifier//用戶SQL需要插入的列名、值的映射userColMap := make(map[string]ast.Expression)if len(stmt.Columns) > 0 {insertCols = stmt.Columnsfor i, col := range stmt.Columns {userColMap[col.Token.Literal] = stmt.Values[i]}} else {// 未指定列時默認使用表的所有列insertCols = make([]*ast.Identifier, len(table.Columns))for i, col := range table.Columns {insertCols[i] = &ast.Identifier{Value: col.Name}userColMap[col.Name] = stmt.Values[i]}}// 檢查值數量與指定列數量是否匹配if len(stmt.Values) != len(insertCols) {return fmt.Errorf("Column count doesn't match value count at row 1 (got %d, want %d)", len(stmt.Values), len(insertCols))}// 轉換值// 填充行數據(處理用戶值或默認值)for i, tableCol := range table.Columns {// 優先使用用戶提供的值,否則使用默認值var expr ast.Expressionexpr = userColMap[tableCol.Name]if expr == nil && tableCol.Default != nil {expr = tableCol.Default.(*ast.DefaultExpression).Value}//獲取當前列名colName := table.Columns[i].NametableColIdx, ok := colIndexMap[colName]if !ok {return fmt.Errorf("Unknown column '%s' in INSERT statement", colName)}// 轉換值類型value, err := evaluateExpression(expr)if err != nil {return fmt.Errorf("invalid value for column '%s': %v", colName, err)}// 類型轉換switch v := value.(type) {case string:if tableCol.Type == "INT" {intVal, err := strconv.ParseInt(v, 10, 32)if err != nil {return fmt.Errorf("Incorrect integer value: '%s' for column '%s'", v, tableCol.Name)}row[tableColIdx] = ast.Cell{Type: ast.CellTypeInt, IntValue: int32(intVal)}} else {row[tableColIdx] = ast.Cell{Type: ast.CellTypeText, TextValue: v}}case int32:row[tableColIdx] = ast.Cell{Type: ast.CellTypeInt, IntValue: v}case float32:row[tableColIdx] = ast.Cell{Type: ast.CellTypeFloat, FloatValue: v}case time.Time:row[tableColIdx] = ast.Cell{Type: ast.CellTypeDateTime, TimeValue: v.Format("2006-01-02 15:04:05")}default:return fmt.Errorf("Unsupported value type: %T for column '%s'", value, tableCol.Name)}}// ... 其他代碼
}
測試
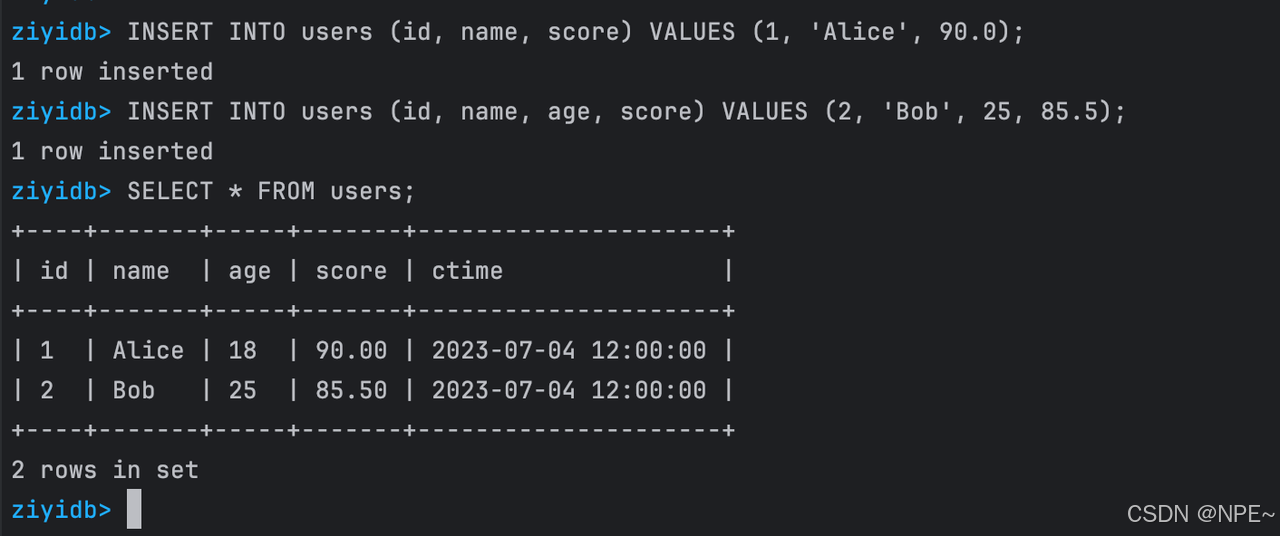
測試SQL:
-- 創建帶默認值的表
CREATE TABLE users (id INT PRIMARY KEY,name TEXT,age INT DEFAULT 18,score FLOAT,ctime DATETIME DEFAULT '2023-07-04 12:00:00'
);-- 插入部分列數據(未指定的列將使用默認值)
INSERT INTO users (id, name, score) VALUES (1, 'Alice', 90.0);
INSERT INTO users (id, name, age, score) VALUES (2, 'Bob', 25, 85.5);-- 查詢數據驗證默認值
SELECT * FROM users;
效果:
2. 聚合函數實現
設計思路
聚合函數是 SQL 中用于對一組值執行計算并返回單個值的函數。在 ZiyiDB 中,我們實現了以下聚合函數:
- COUNT:計算行數
- SUM:計算數值列的總和
- AVG:計算數值列的平均值
- MAX:找出列中的最大值
- MIN:找出列中的最小值
聚合函數的實現需要考慮以下幾點:
語法解析:在 SELECT 語句中識別函數調用
執行邏輯:在存儲引擎中計算聚合結果
結果返回:以統一的格式返回結果
這里以count聚合函數為例,其他聚合函數同理
- internal/ast/ast.go中新增FunctionCall函數調用類型,用于后續執行函數調用,比如count、max等聚合函數

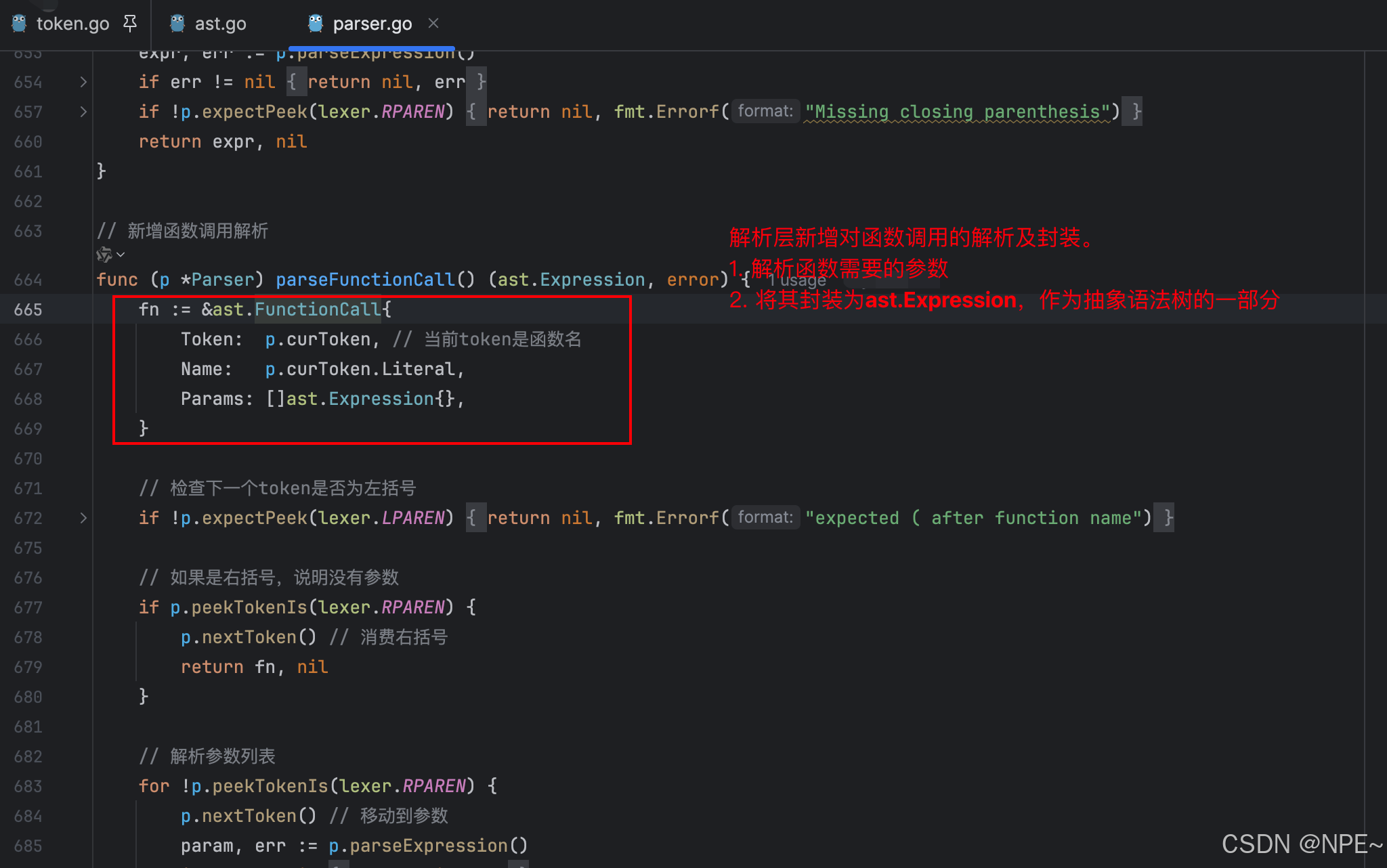
- internal/parser/parser.go中新增對函數類型的解析和封裝
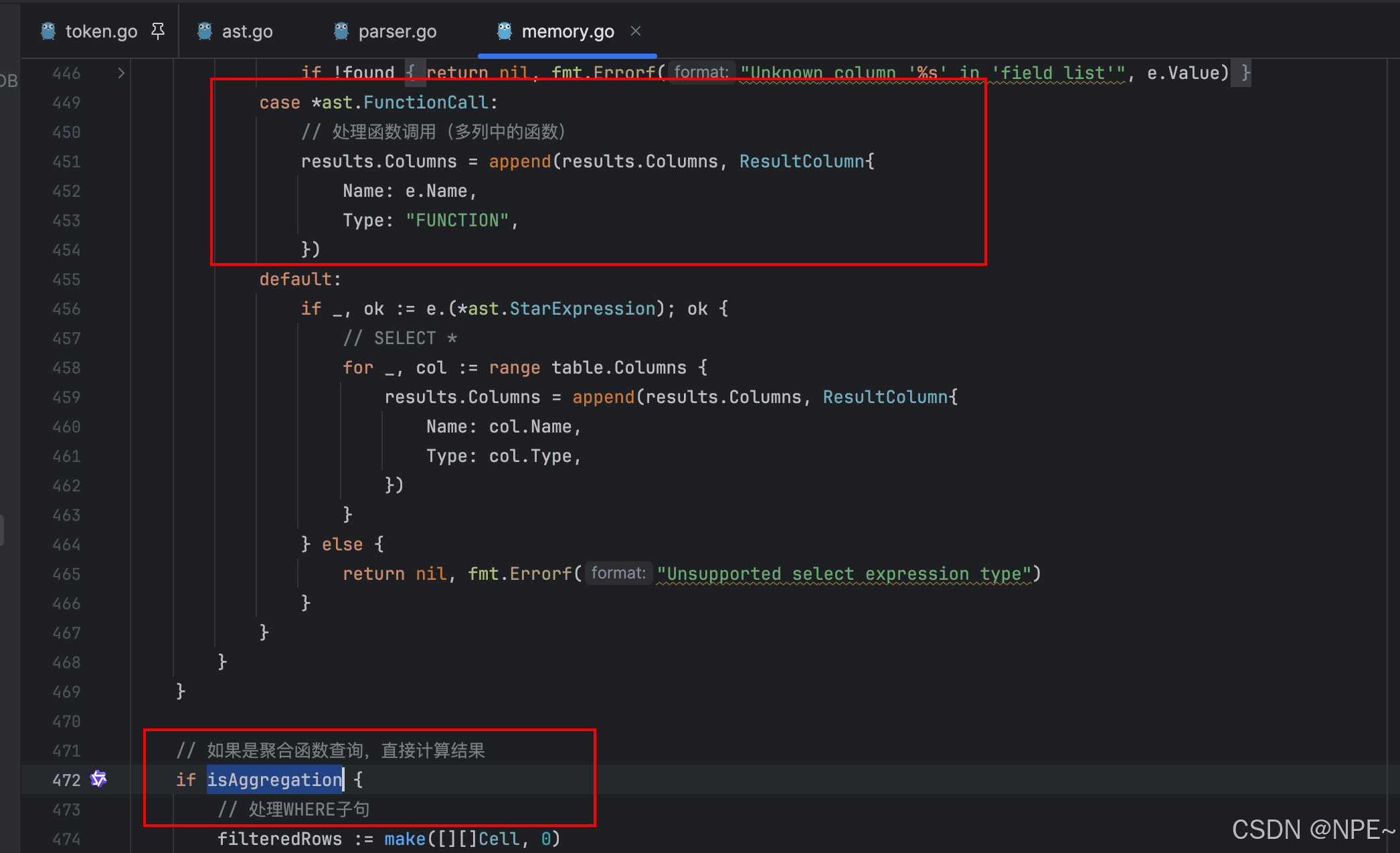
- internal/storage/memory.go存儲引擎Select方法中新增對聚合函數的判斷
同時memory.go中添加calculateFunctionResults方法,實現對函數的執行和底層實現

代碼實現
- 語法解析層(Parser)
在 internal/parser/parser.go 中,我們增強了 parseSelectStatement 方法來支持函數調用:
// parseSelectStatement 解析SELECT語句
func (p *Parser) parseSelectStatement() (*ast.SelectStatement, error) {stmt := &ast.SelectStatement{Token: p.curToken}// 解析選擇列表for !p.peekTokenIs(lexer.FROM) {p.nextToken()if p.curToken.Type == lexer.ASTERISK {stmt.Fields = append(stmt.Fields, &ast.StarExpression{})break}expr, err := p.parseExpression()if err != nil {return nil, err}stmt.Fields = append(stmt.Fields, expr)if p.peekTokenIs(lexer.COMMA) {p.nextToken()}}// ... 其他代碼
}
parseExpression 方法也進行了增強,以支持函數調用的解析:
// parseExpression 解析表達式
func (p *Parser) parseExpression() (ast.Expression, error) {switch p.curToken.Type {// ... 其他情況case lexer.IDENT:if p.peekTokenIs(lexer.LPAREN) {return p.parseFunctionCall()}return &ast.Identifier{Token: p.curToken,Value: p.curToken.Literal,}, nil// ...}
}// parseFunctionCall 解析函數調用
func (p *Parser) parseFunctionCall() (ast.Expression, error) {fn := &ast.FunctionCall{Token: p.curToken,Name: p.curToken.Literal,Params: []ast.Expression{},}// 檢查下一個token是否為左括號if !p.expectPeek(lexer.LPAREN) {return nil, fmt.Errorf("expected ( after function name")}// 如果是右括號,說明沒有參數if p.peekTokenIs(lexer.RPAREN) {p.nextToken()return fn, nil}// 解析參數列表for !p.peekTokenIs(lexer.RPAREN) {p.nextToken()param, err := p.parseExpression()if err != nil {return nil, err}fn.Params = append(fn.Params, param)if p.peekTokenIs(lexer.COMMA) {p.nextToken()} else if !p.peekTokenIs(lexer.RPAREN) {return nil, fmt.Errorf("expected comma or closing parenthesis in function call")}}if !p.expectPeek(lexer.RPAREN) {return nil, fmt.Errorf("Missing closing parenthesis for function call")}return fn, nil
}
- AST 定義
在 internal/ast/ast.go 中,我們添加了 FunctionCall 類型來表示函數調用:
// FunctionCall 表示函數調用
type FunctionCall struct {Token lexer.TokenName stringParams []Expression
}func (fc *FunctionCall) expressionNode() {}
func (fc *FunctionCall) TokenLiteral() string { return fc.Token.Literal }
- 存儲引擎實現
在 internal/storage/memory.go 中,Select 方法被增強以支持聚合函數:
// Select 查詢數據
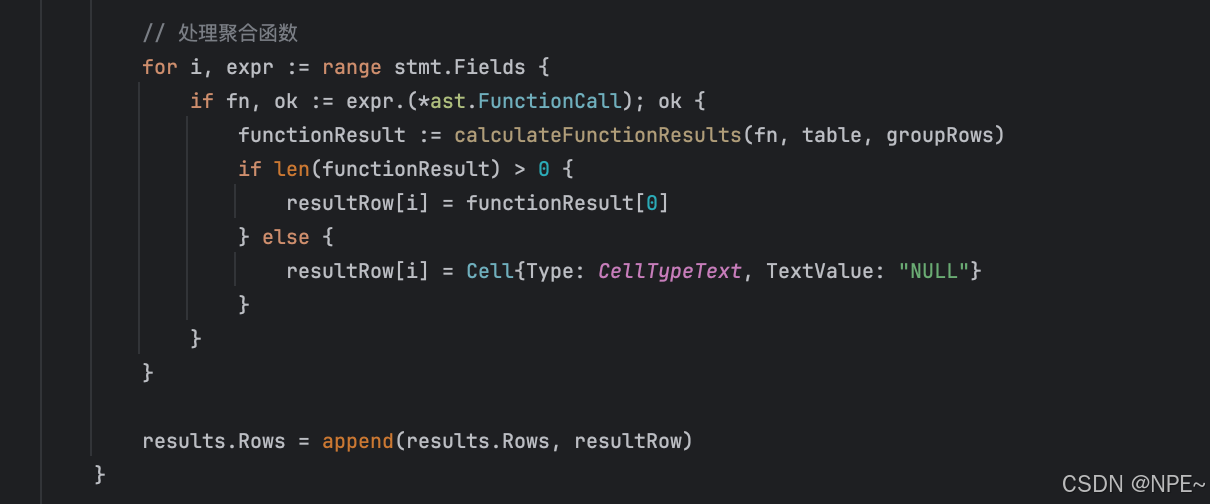
func (b *MemoryBackend) Select(stmt *ast.SelectStatement) (*ast.Results, error) {table, exists := b.tables[stmt.TableName]if !exists {return nil, fmt.Errorf("Table '%s' doesn't exist", stmt.TableName)}results := &ast.Results{Columns: make([]ast.ResultColumn, 0),Rows: make([][]ast.Cell, 0),}// 檢查是否為聚合函數查詢isAggregation := falsevar aggregateFunc *ast.FunctionCall// 處理select列表if len(stmt.Fields) == 1 {// 檢查是否為 SELECT *if _, ok := stmt.Fields[0].(*ast.StarExpression); ok {// SELECT *for _, col := range table.Columns {results.Columns = append(results.Columns, ast.ResultColumn{Name: col.Name,Type: col.Type,})}} else if fn, ok := stmt.Fields[0].(*ast.FunctionCall); ok {// 處理函數調用isAggregation = trueaggregateFunc = fnresults.Columns = append(results.Columns, ast.ResultColumn{Name: fn.Name,Type: "FUNCTION",})}// ... 其他情況}// ... 其他情況// 如果是聚合函數查詢,直接計算結果if isAggregation {// 處理WHERE子句filteredRows := make([][]ast.Cell, 0)for _, row := range table.Rows {if stmt.Where != nil {match, err := evaluateWhereCondition(stmt.Where, row, table.Columns)if err != nil {return nil, err}if !match {continue}}filteredRows = append(filteredRows, row)}functionResult := calculateFunctionResults(aggregateFunc, table, filteredRows)results.Rows = [][]ast.Cell{functionResult}return results, nil}// ... 非聚合函數的處理
}
每個聚合函數都有對應的計算方法:
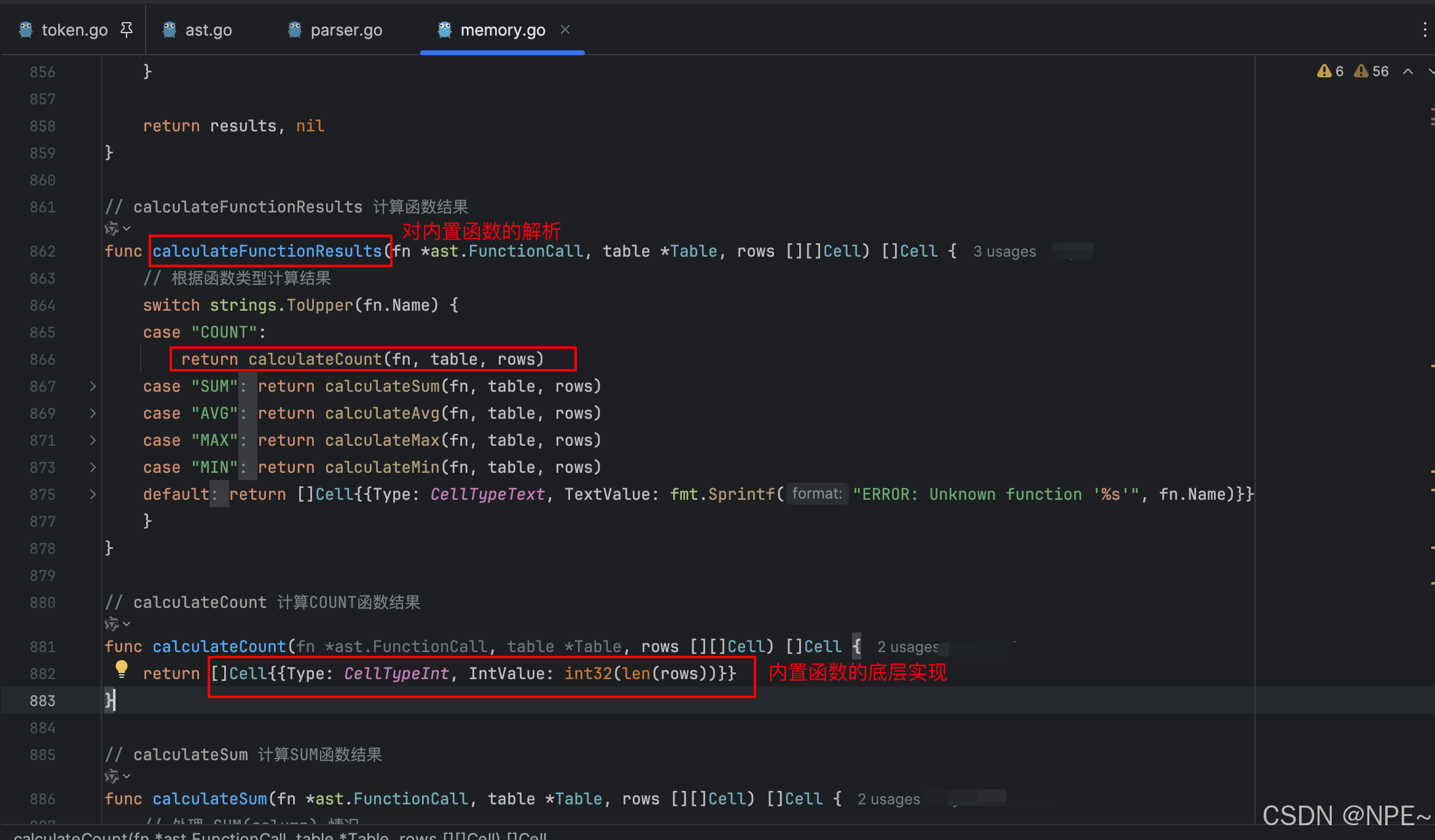
// calculateFunctionResults 計算函數結果
func calculateFunctionResults(fn *ast.FunctionCall, table *Table, rows [][]ast.Cell) []ast.Cell {// 根據函數類型計算結果switch strings.ToUpper(fn.Name) {case "COUNT":return calculateCount(fn, table, rows)case "SUM":return calculateSum(fn, table, rows)case "AVG":return calculateAvg(fn, table, rows)case "MAX":return calculateMax(fn, table, rows)case "MIN":return calculateMin(fn, table, rows)default:return []ast.Cell{{Type: ast.CellTypeText, TextValue: fmt.Sprintf("ERROR: Unknown function '%s'", fn.Name)}}}
}// calculateCount 計算COUNT函數結果
func calculateCount(fn *ast.FunctionCall, table *Table, rows [][]ast.Cell) []ast.Cell {return []ast.Cell{{Type: ast.CellTypeInt, IntValue: int32(len(rows))}}
}// calculateSum 計算SUM函數結果
func calculateSum(fn *ast.FunctionCall, table *Table, rows [][]ast.Cell) []ast.Cell {// 處理 SUM(column) 情況if len(fn.Params) != 1 {return []ast.Cell{{Type: ast.CellTypeText, TextValue: "ERROR: SUM function requires exactly one parameter"}}}var columnName string// 檢查參數類型switch param := fn.Params[0].(type) {case *ast.Identifier:columnName = param.Valuedefault:return []ast.Cell{{Type: ast.CellTypeText, TextValue: fmt.Sprintf("ERROR: SUM function requires a column name, got %T", param)}}}// 查找列索引colIndex := -1for i, col := range table.Columns {if col.Name == columnName {colIndex = ibreak}}if colIndex == -1 {return []ast.Cell{{Type: ast.CellTypeText, TextValue: fmt.Sprintf("ERROR: Unknown column '%s'", columnName)}}}// 計算SUM值var sumInt int32 = 0var sumFloat float32 = 0.0hasFloat := falsefor _, row := range rows {cell := row[colIndex]switch cell.Type {case ast.CellTypeInt:sumInt += cell.IntValuecase ast.CellTypeFloat:// 如果之前有整數,需要轉換為浮點數if !hasFloat {sumFloat = float32(sumInt)hasFloat = true}sumFloat += cell.FloatValue}}// 返回結果if hasFloat {return []ast.Cell{{Type: ast.CellTypeFloat, FloatValue: sumFloat}}}return []ast.Cell{{Type: ast.CellTypeInt, IntValue: sumInt}}
}
// ... 其他聚合函數的實現
測試
測試SQL:
-- 創建測試表
CREATE TABLE users (id INT PRIMARY KEY, name TEXT, age INT);-- 插入測試數據
INSERT INTO users VALUES (1, 'Alice', 20);
INSERT INTO users VALUES (2, 'Bob', 25);
INSERT INTO users VALUES (3, 'Charlie', 30);-- 使用聚合函數
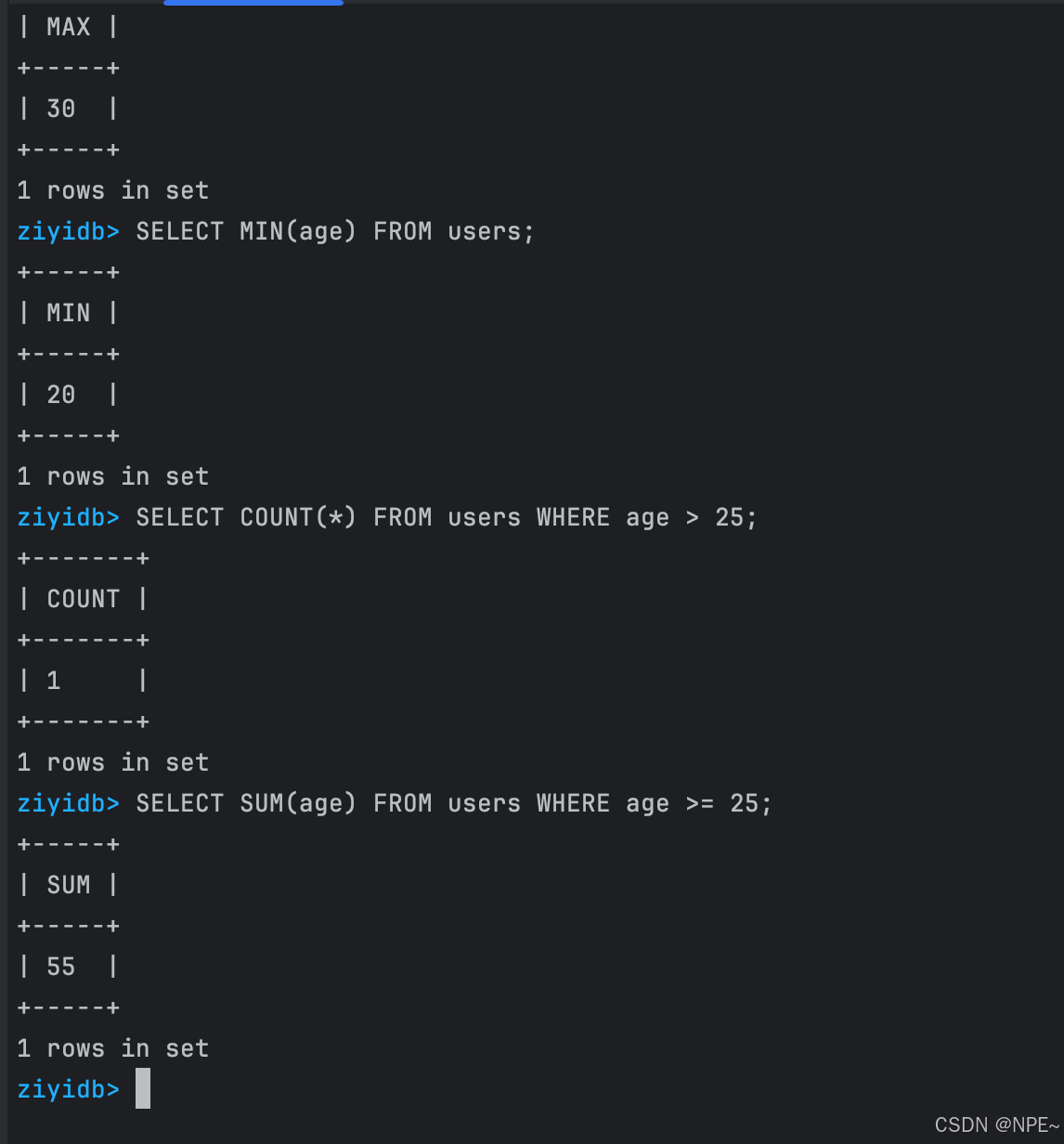
SELECT COUNT(*) FROM users;
SELECT SUM(age) FROM users;
SELECT AVG(age) FROM users;
SELECT MAX(age) FROM users;
SELECT MIN(age) FROM users;-- 帶WHERE條件的聚合函數
SELECT COUNT(*) FROM users WHERE age > 25;
SELECT SUM(age) FROM users WHERE age >= 25;
效果:
3. group by 實現
設計思路
1.語法解析:
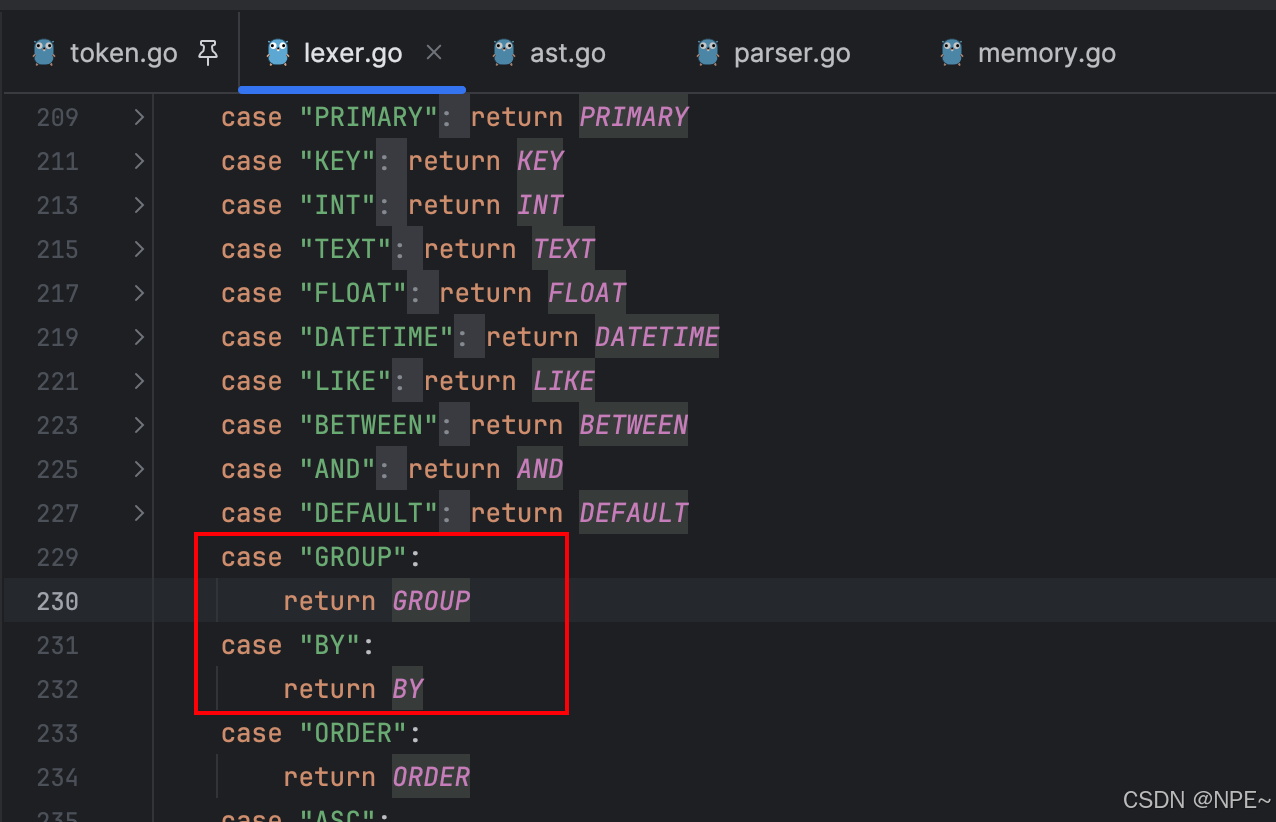
首先在internal/lexer/token.go中新增group by關鍵字
 然后在internal/lexer/lexer.go詞法分析器的lookupIdentifier方法中新增對group by關鍵字的識別
然后在internal/lexer/lexer.go詞法分析器的lookupIdentifier方法中新增對group by關鍵字的識別
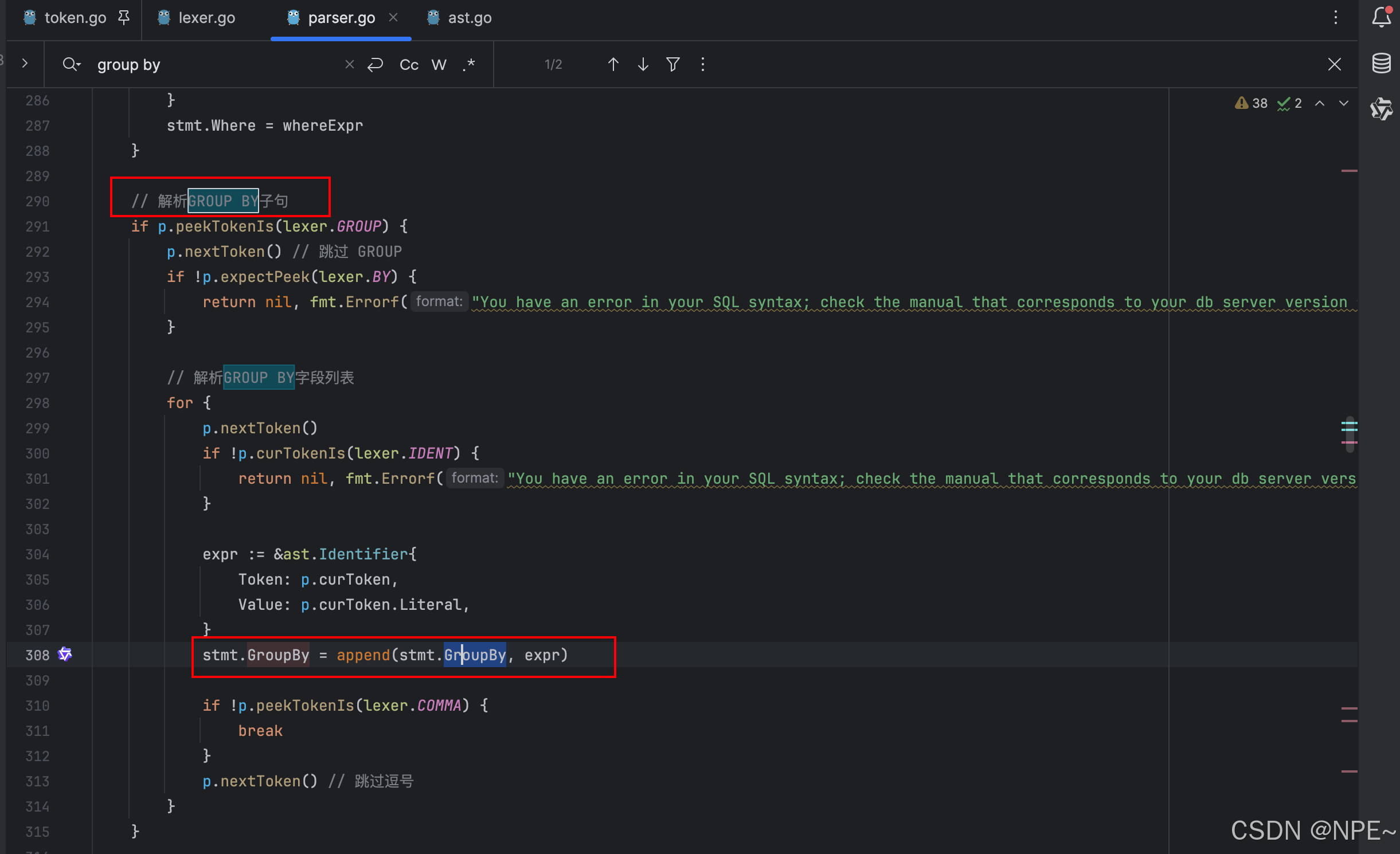
接下來在internal/parser/parser.go詞法分析器中的parseSelectStatement方法中添加 GROUP 和 BY 關鍵字的解析,將其解析并封裝為ast的一部分
在 internal/ast/ast.go 中添加 GroupBy 字段到 SelectStatement 結構體
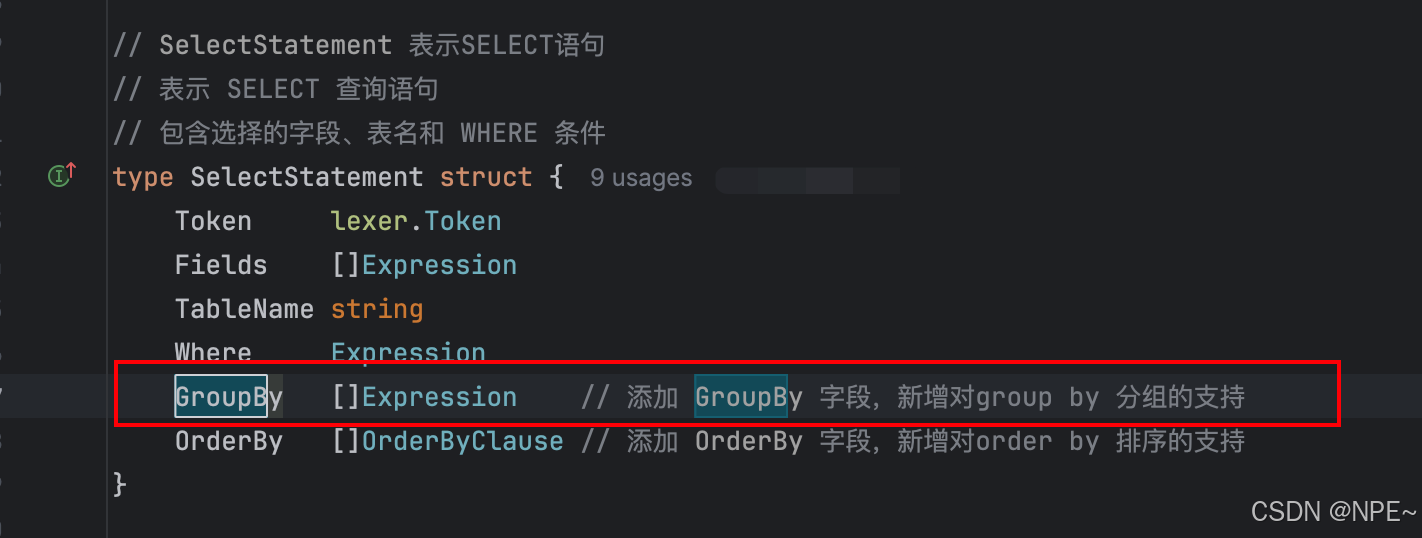
2. 執行引擎:
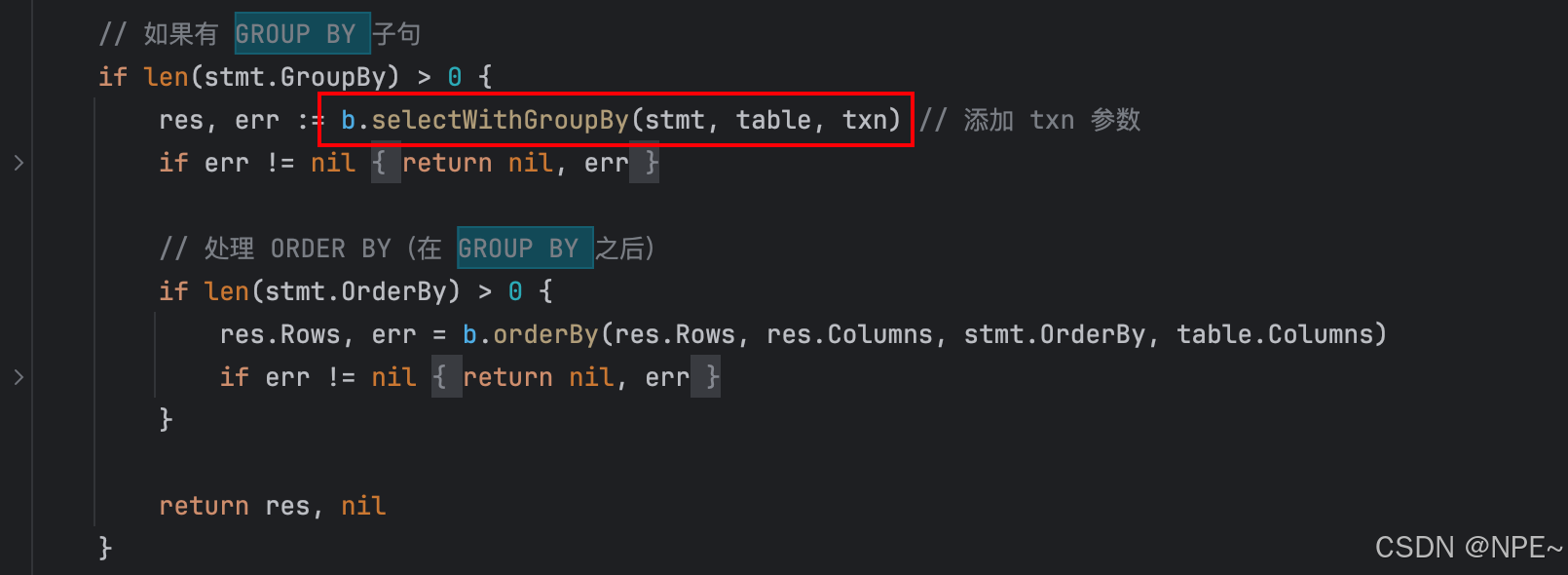
首先在internal/storage/memory.go存儲引擎中的Select方法實現對分組邏輯的調用
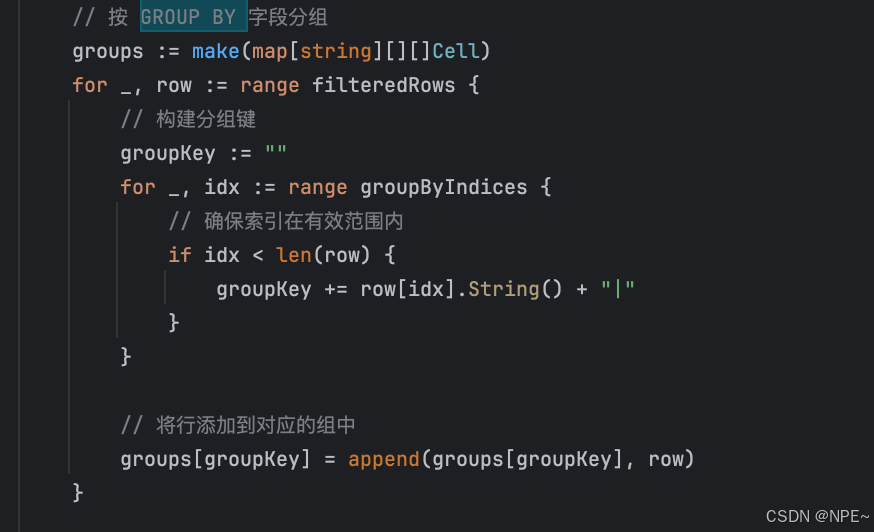
接著selectWithGroupBy方法,實現底層分組原理,按指定列對數據進行分組
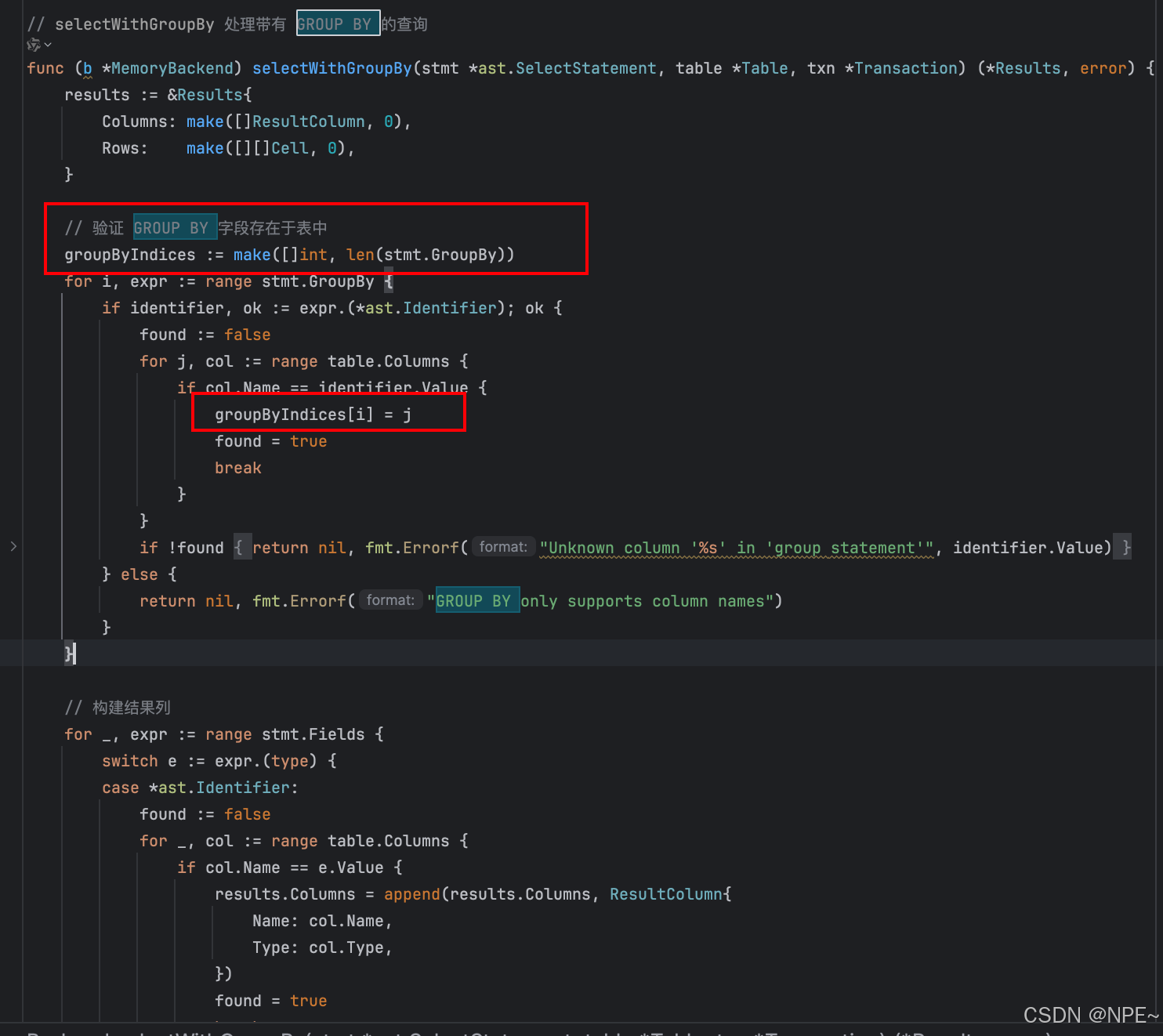
3. internal/storage/memory.go中的selectWithGroupBy對聚合函數進行處理,確保查詢結果列是聚合函數列或者分組列
代碼實現
- 在詞法分析器中添加新的關鍵字
// internal/lexer/token.go
const (// ... 其他關鍵字GROUP TokenType = "GROUP"BY TokenType = "BY"
)// internal/lexer/lexer.go
func (l *Lexer) lookupIdentifier(ident string) TokenType {switch strings.ToUpper(ident) {// ... 其他關鍵字case "GROUP":return GROUPcase "BY":return BYdefault:return IDENT}
}
- 在 AST 中添加新的結構體以支持 GROUP BY
// internal/ast/ast.go// SelectStatement 表示SELECT語句
type SelectStatement struct {Token lexer.TokenFields []ExpressionTableName stringWhere ExpressionGroupBy []Expression // 添加 GroupBy 字段
}
- 在語法分析器中添加對 GROUP BY 子句的解析
// internal/parser/parser.go// parseSelectStatement 解析SELECT語句
func (p *Parser) parseSelectStatement() (*ast.SelectStatement, error) {stmt := &ast.SelectStatement{Token: p.curToken}// ... 解析選擇列表和 FROM 子句 ...// 解析WHERE子句if p.peekTokenIs(lexer.WHERE) {p.nextToken()whereExpr, err := p.parseWhereClause()if err != nil {return nil, err}stmt.Where = whereExpr}// 解析GROUP BY子句if p.peekTokenIs(lexer.GROUP) {p.nextToken() // 跳過 GROUPif !p.expectPeek(lexer.BY) {return nil, fmt.Errorf("expected BY after GROUP")}// 解析GROUP BY字段列表for {p.nextToken()if !p.curTokenIs(lexer.IDENT) {return nil, fmt.Errorf("expected identifier in GROUP BY clause")}expr := &ast.Identifier{Token: p.curToken,Value: p.curToken.Literal,}stmt.GroupBy = append(stmt.GroupBy, expr)if !p.peekTokenIs(lexer.COMMA) {break}p.nextToken() // 跳過逗號}}return stmt, nil
}
- 在存儲引擎中實現 GROUP BY 的執行邏輯
// internal/storage/memory.go// Select 查詢數據
func (b *MemoryBackend) Select(stmt *ast.SelectStatement) (*Results, error) {table, exists := b.tables[stmt.TableName]if !exists {return nil, fmt.Errorf("Table '%s' doesn't exist", stmt.TableName)}// 如果有 GROUP BY 子句if len(stmt.GroupBy) > 0 {return b.selectWithGroupBy(stmt, table)}// ... 原有的查詢邏輯 ...
}// selectWithGroupBy 處理帶有 GROUP BY 的查詢
func (b *MemoryBackend) selectWithGroupBy(stmt *ast.SelectStatement, table *Table) (*Results, error) {results := &Results{Columns: make([]ResultColumn, 0),Rows: make([][]Cell, 0),}// 驗證 GROUP BY 字段存在于表中groupByIndices := make([]int, len(stmt.GroupBy))for i, expr := range stmt.GroupBy {if identifier, ok := expr.(*ast.Identifier); ok {found := falsefor j, col := range table.Columns {if col.Name == identifier.Value {groupByIndices[i] = jfound = truebreak}}if !found {return nil, fmt.Errorf("Unknown column '%s' in 'group statement'", identifier.Value)}} else {return nil, fmt.Errorf("GROUP BY only supports column names")}}// 構建結果列for _, expr := range stmt.Fields {switch e := expr.(type) {case *ast.Identifier:found := falsefor _, col := range table.Columns {if col.Name == e.Value {results.Columns = append(results.Columns, ResultColumn{Name: col.Name,Type: col.Type,})found = truebreak}}if !found {return nil, fmt.Errorf("Unknown column '%s' in 'field list'", e.Value)}case *ast.FunctionCall:results.Columns = append(results.Columns, ResultColumn{Name: e.Name,Type: "FUNCTION",})case *ast.StarExpression:for _, col := range table.Columns {results.Columns = append(results.Columns, ResultColumn{Name: col.Name,Type: col.Type,})}default:return nil, fmt.Errorf("Unsupported select expression type")}}// 處理WHERE子句filteredRows := make([][]Cell, 0)for _, row := range table.Rows {if stmt.Where != nil {match, err := evaluateWhereCondition(stmt.Where, row, table.Columns)if err != nil {return nil, err}if !match {continue}}filteredRows = append(filteredRows, row)}// 按 GROUP BY 字段分組groups := make(map[string][][]Cell)for _, row := range filteredRows {// 構建分組鍵groupKey := ""for _, idx := range groupByIndices {groupKey += row[idx].String() + "|"}// 將行添加到對應的組中groups[groupKey] = append(groups[groupKey], row)}// 為每個組計算結果for _, groupRows := range groups {if len(groupRows) == 0 {continue}resultRow := make([]Cell, len(results.Columns))colIndex := 0// 處理非聚合字段(GROUP BY 字段)for _, expr := range stmt.Fields {if identifier, ok := expr.(*ast.Identifier); ok {// 檢查是否為 GROUP BY 字段isGroupByField := falsefor _, groupByExpr := range stmt.GroupBy {if groupByIdent, ok := groupByExpr.(*ast.Identifier); ok {if groupByIdent.Value == identifier.Value {isGroupByField = truebreak}}}if isGroupByField {// 對于 GROUP BY 字段,取第一個值(所有行應該相同)for k, tableCol := range table.Columns {if tableCol.Name == identifier.Value {resultRow[colIndex] = groupRows[0][k]break}}}colIndex++}}// 處理聚合函數for i, expr := range stmt.Fields {if fn, ok := expr.(*ast.FunctionCall); ok {functionResult := calculateFunctionResults(fn, table, groupRows)resultRow[i] = functionResult[0]}}results.Rows = append(results.Rows, resultRow)}return results, nil
}
測試
測試SQL:
CREATE TABLE sales (id INT PRIMARY KEY, product TEXT, category TEXT, amount FLOAT);
INSERT INTO sales VALUES (1, 'Apple', 'Fruit', 10.5);
INSERT INTO sales VALUES (2, 'Banana', 'Fruit', 8.0);
INSERT INTO sales VALUES (3, 'Carrot', 'Vegetable', 5.2);
INSERT INTO sales VALUES (4, 'Broccoli', 'Vegetable', 7.3);
INSERT INTO sales VALUES (5, 'Orange', 'Fruit', 9.8);
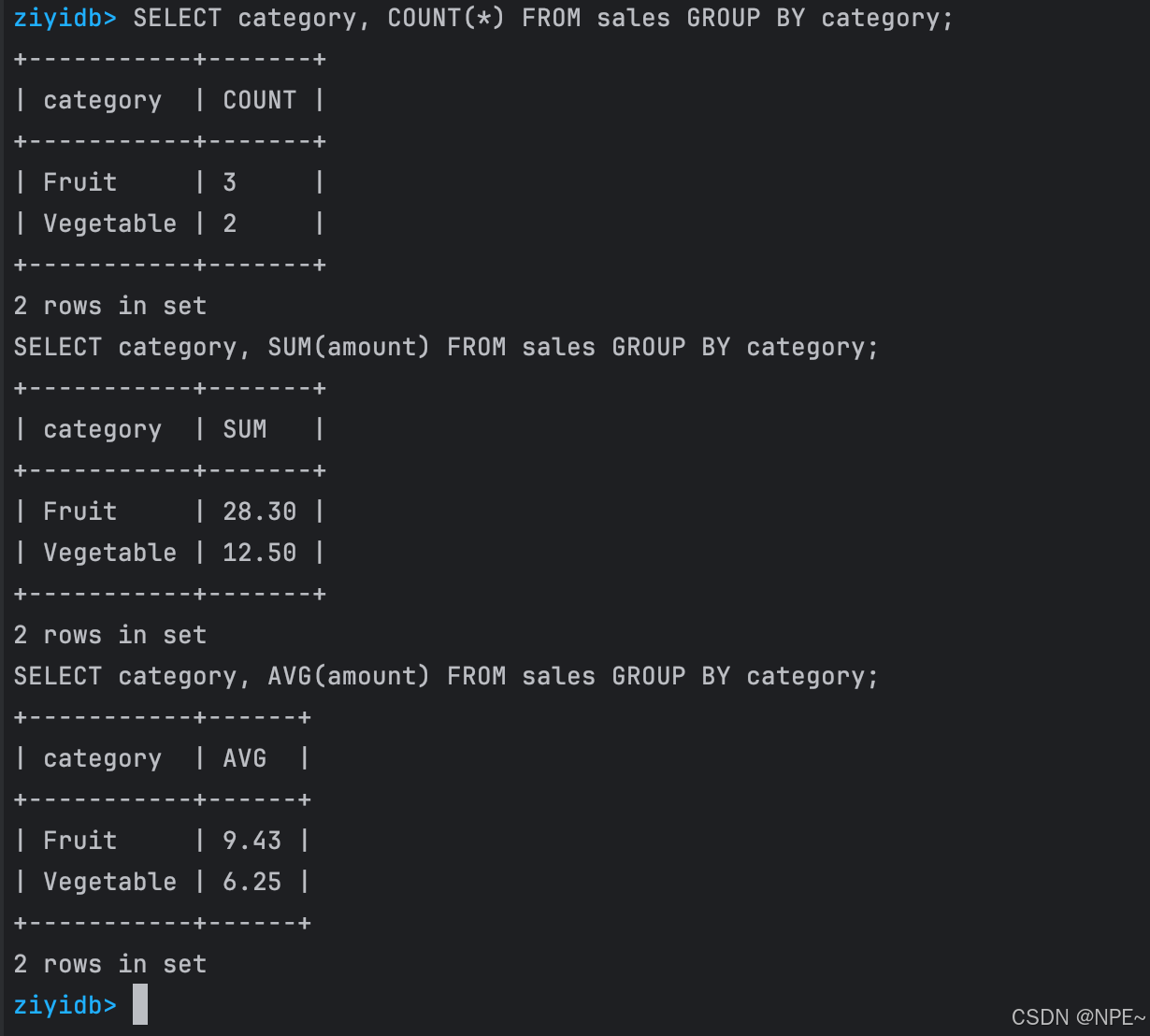
SELECT category, COUNT(*) FROM sales GROUP BY category;
SELECT category, SUM(amount) FROM sales GROUP BY category;
SELECT category, AVG(amount) FROM sales GROUP BY category;
效果:
4. order by 實現
設計思路
與group by實現基本一致
1.語法解析:
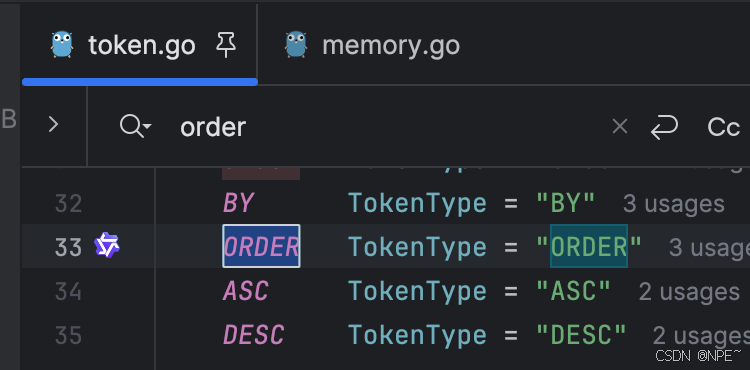
在詞法分析器中添加 ORDER、BY、ASC 和 DESC 關鍵字
- internal/lexer/token.go:
- internal/lexer/lexer.go的lookupIdentifier方法:

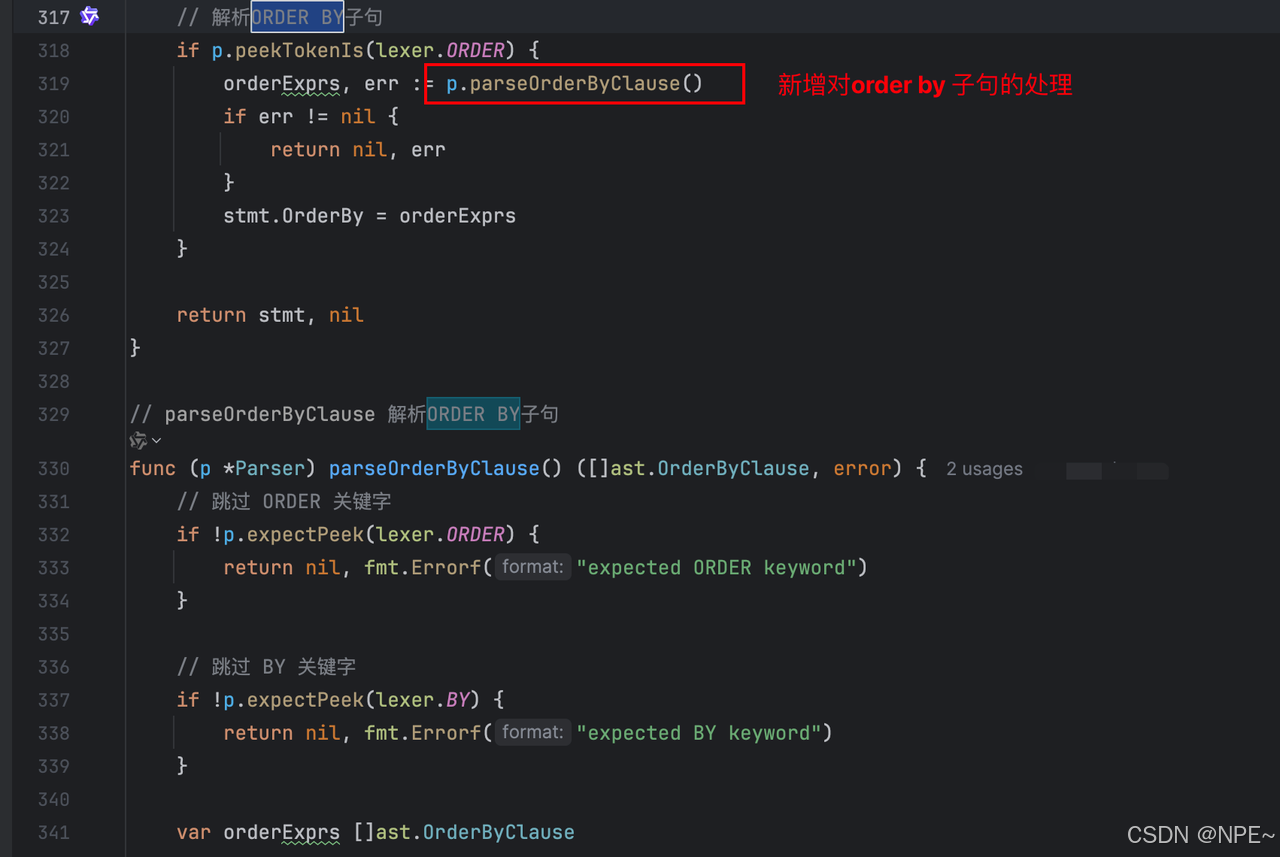
在語法分析器中解析 ORDER BY 子句:
在 internal/ast/ast.go中添加 OrderBy 字段到 SelectStatement 結構體
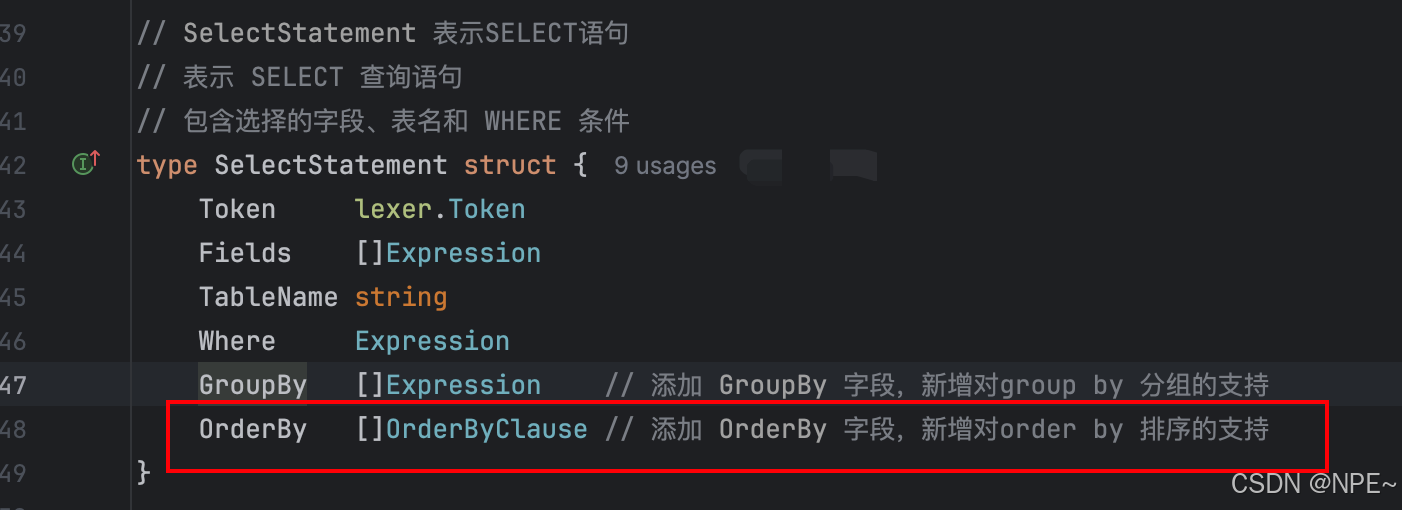
2.執行引擎:
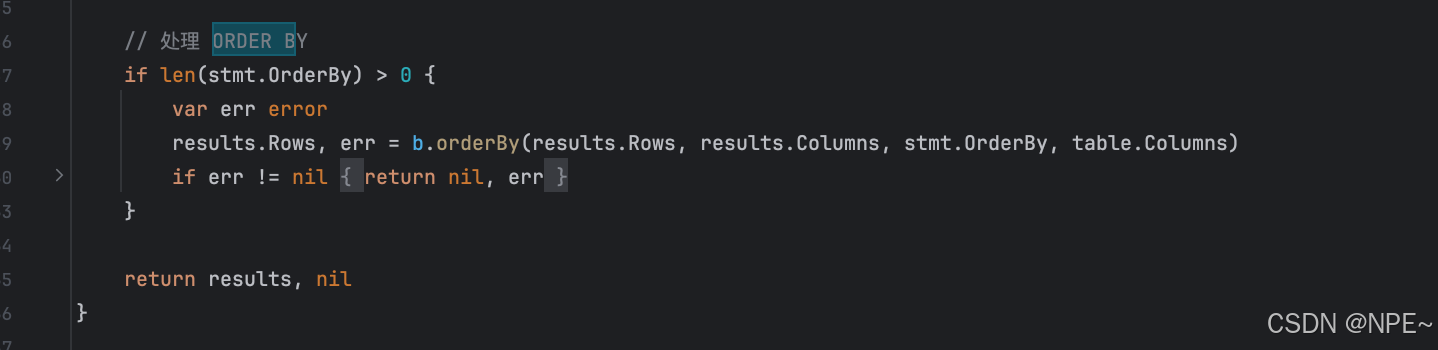
在internal/storage/memory.go存儲引擎的Select方法中實現對order by的解析調用:
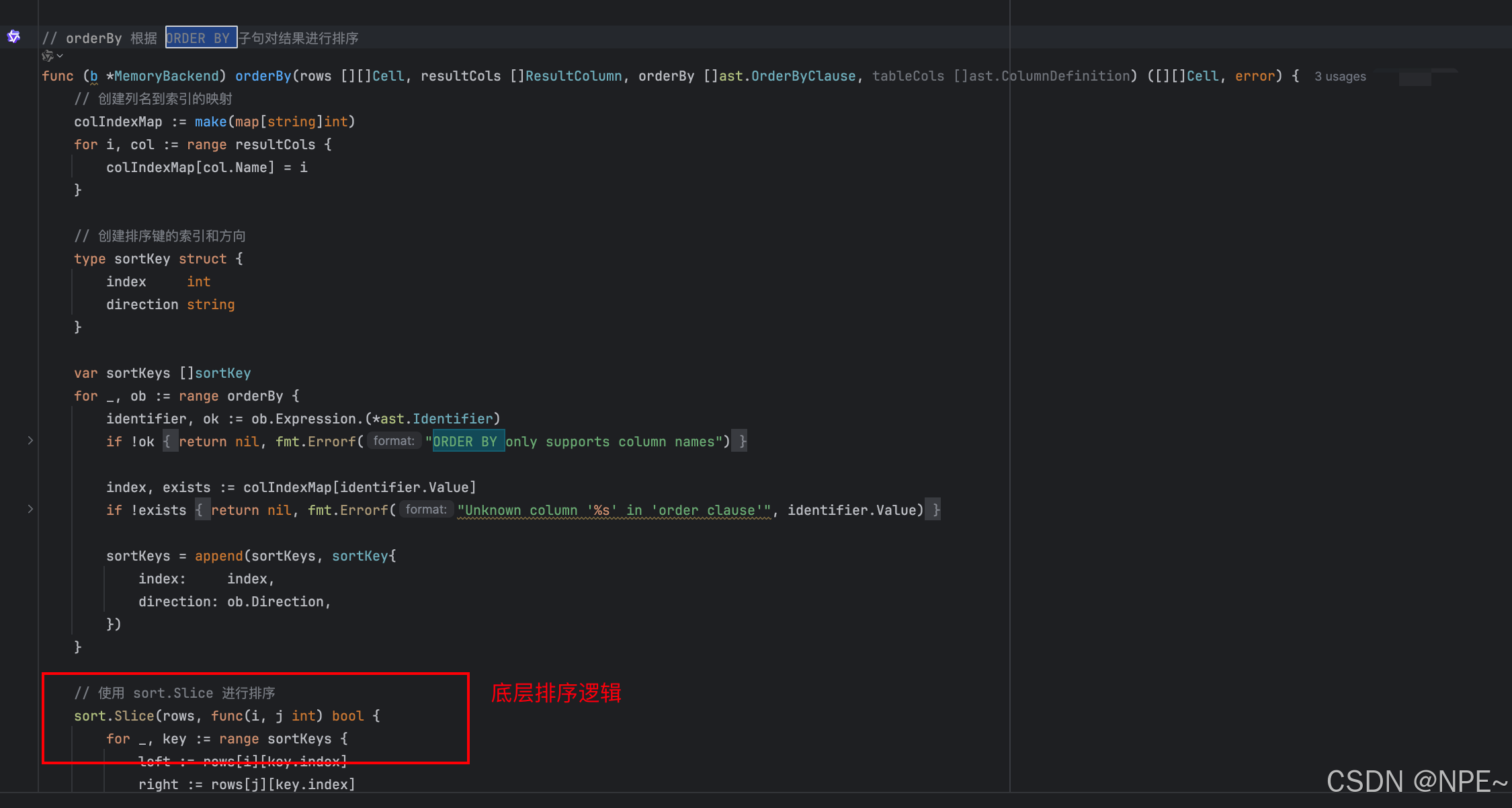
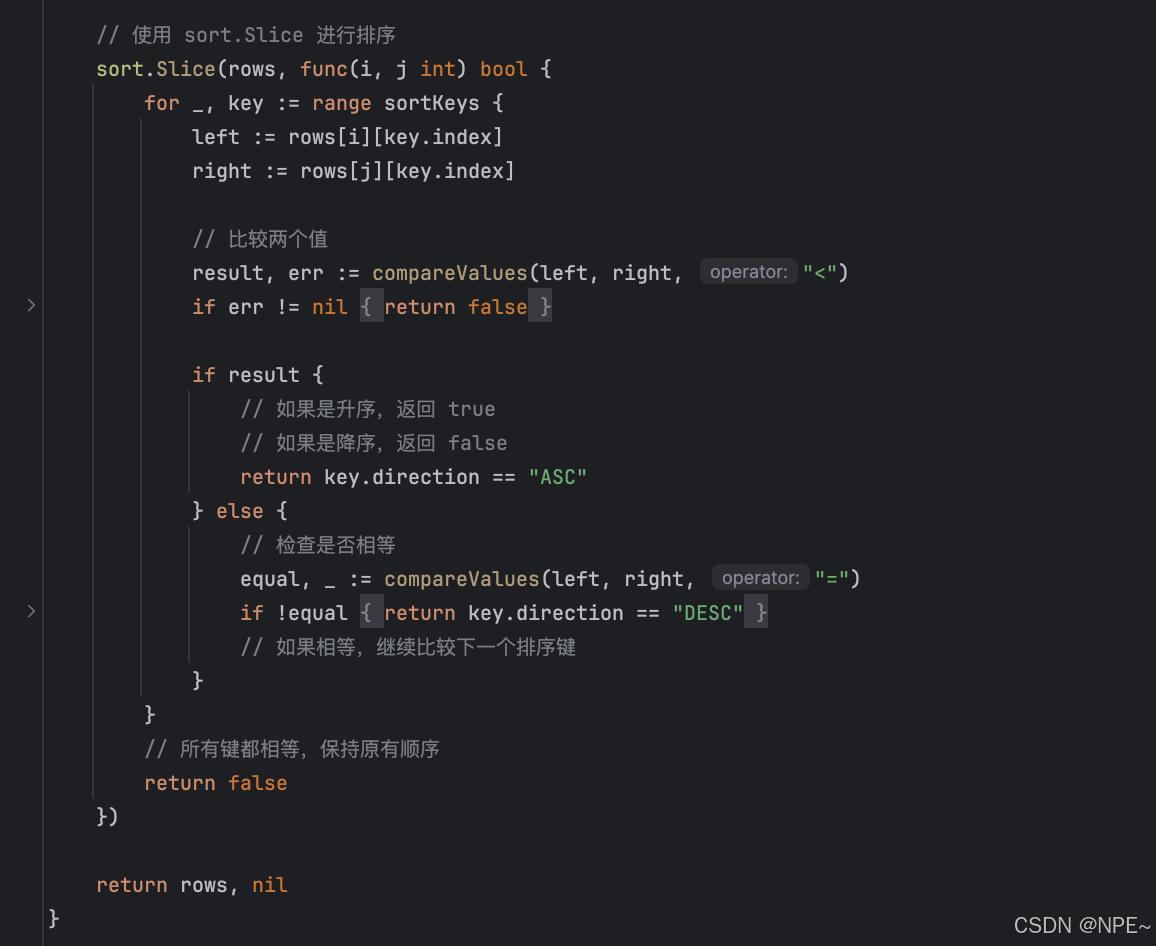
同時實現排序邏輯,使用 Go 標準庫的 sort.Slice 進行排序同時實現自定義比較函數以支持不同數據類型的比較:
代碼實現
- 在詞法分析器中添加新的關鍵字
// internal/lexer/token.go
const (// ... 其他關鍵字ORDER TokenType = "ORDER"ASC TokenType = "ASC"DESC TokenType = "DESC"
)// internal/lexer/lexer.go
func (l *Lexer) lookupIdentifier(ident string) TokenType {switch strings.ToUpper(ident) {// ... 其他關鍵字case "ORDER":return ORDERcase "ASC":return ASCcase "DESC":return DESCdefault:return IDENT}
}
- 在 AST 中添加新的結構體以支持 ORDER BY
// internal/ast/ast.go// SelectStatement 表示SELECT語句
type SelectStatement struct {Token lexer.TokenFields []ExpressionTableName stringWhere ExpressionOrderBy []OrderByClause // 添加 OrderBy 字段
}// OrderByClause 表示 ORDER BY 子句中的排序項
type OrderByClause struct {Expression ExpressionDirection string // "ASC" 或 "DESC"
}
- 在語法分析器中添加對 ORDER BY 子句的解析
// internal/parser/parser.go// parseSelectStatement 解析SELECT語句
func (p *Parser) parseSelectStatement() (*ast.SelectStatement, error) {stmt := &ast.SelectStatement{Token: p.curToken}// ... 解析選擇列表、FROM 子句和 WHERE 子句 ...// 解析GROUP BY子句(如果有的話)if p.peekTokenIs(lexer.GROUP) {// ... GROUP BY 解析邏輯 ...}// 解析ORDER BY子句if p.peekTokenIs(lexer.ORDER) {orderExprs, err := p.parseOrderByClause()if err != nil {return nil, err}stmt.OrderBy = orderExprs}return stmt, nil
}// parseOrderByClause 解析ORDER BY子句
func (p *Parser) parseOrderByClause() ([]ast.OrderByClause, error) {// 跳過 ORDER 關鍵字if !p.expectPeek(lexer.ORDER) {return nil, fmt.Errorf("expected ORDER keyword")}// 跳過 BY 關鍵字if !p.expectPeek(lexer.BY) {return nil, fmt.Errorf("expected BY keyword")}var orderExprs []ast.OrderByClausefor {p.nextToken()// 解析表達式(列名)if !p.curTokenIs(lexer.IDENT) {return nil, fmt.Errorf("expected identifier in ORDER BY clause")}expr := &ast.Identifier{Token: p.curToken,Value: p.curToken.Literal,}orderClause := ast.OrderByClause{Expression: expr,Direction: "ASC", // 默認升序}// 檢查是否有 ASC 或 DESCif p.peekTokenIs(lexer.ASC) || p.peekTokenIs(lexer.DESC) {p.nextToken()orderClause.Direction = p.curToken.Literal}orderExprs = append(orderExprs, orderClause)// 如果沒有逗號,說明結束了if !p.peekTokenIs(lexer.COMMA) {break}p.nextToken() // 跳過逗號}return orderExprs, nil
}
- 在存儲引擎中實現 ORDER BY 的執行邏輯
// internal/storage/memory.go// Select 查詢數據
func (b *MemoryBackend) Select(stmt *ast.SelectStatement) (*Results, error) {// ... 原有的查詢邏輯 ...// 處理 ORDER BYif len(stmt.OrderBy) > 0 {var err errorresults.Rows, err = b.orderBy(results.Rows, results.Columns, stmt.OrderBy, table.Columns)if err != nil {return nil, err}}return results, nil
}// orderBy 根據 ORDER BY 子句對結果進行排序
func (b *MemoryBackend) orderBy(rows [][]Cell, resultCols []ResultColumn, orderBy []ast.OrderByClause, tableCols []ast.ColumnDefinition) ([][]Cell, error) {// 創建列名到索引的映射colIndexMap := make(map[string]int)for i, col := range resultCols {colIndexMap[col.Name] = i}// 創建排序鍵的索引和方向type sortKey struct {index intdirection string}var sortKeys []sortKeyfor _, ob := range orderBy {identifier, ok := ob.Expression.(*ast.Identifier)if !ok {return nil, fmt.Errorf("ORDER BY only supports column names")}index, exists := colIndexMap[identifier.Value]if !exists {return nil, fmt.Errorf("Unknown column '%s' in 'order clause'", identifier.Value)}sortKeys = append(sortKeys, sortKey{index: index,direction: ob.Direction,})}// 使用 sort.Slice 進行排序sort.Slice(rows, func(i, j int) bool {for _, key := range sortKeys {left := rows[i][key.index]right := rows[j][key.index]// 比較兩個值result, err := compareValues(left, right, "<")if err != nil {// 如果比較出錯,保持原有順序return false}if result {// 如果是升序,返回 true// 如果是降序,返回 falsereturn key.direction == "ASC"} else {// 檢查是否相等equal, _ := compareValues(left, right, "=")if !equal {// 如果是降序,返回 true// 如果是升序,返回 falsereturn key.direction == "DESC"}// 如果相等,繼續比較下一個排序鍵}}// 所有鍵都相等,保持原有順序return false})return rows, nil
}
測試
測試SQL:
CREATE TABLE sales (id INT PRIMARY KEY, product TEXT, category TEXT, amount FLOAT);
INSERT INTO sales VALUES (1, 'Apple', 'Fruit', 10.5);
INSERT INTO sales VALUES (2, 'Banana', 'Fruit', 8.0);
INSERT INTO sales VALUES (3, 'Carrot', 'Vegetable', 5.2);
INSERT INTO sales VALUES (4, 'Broccoli', 'Vegetable', 7.3);
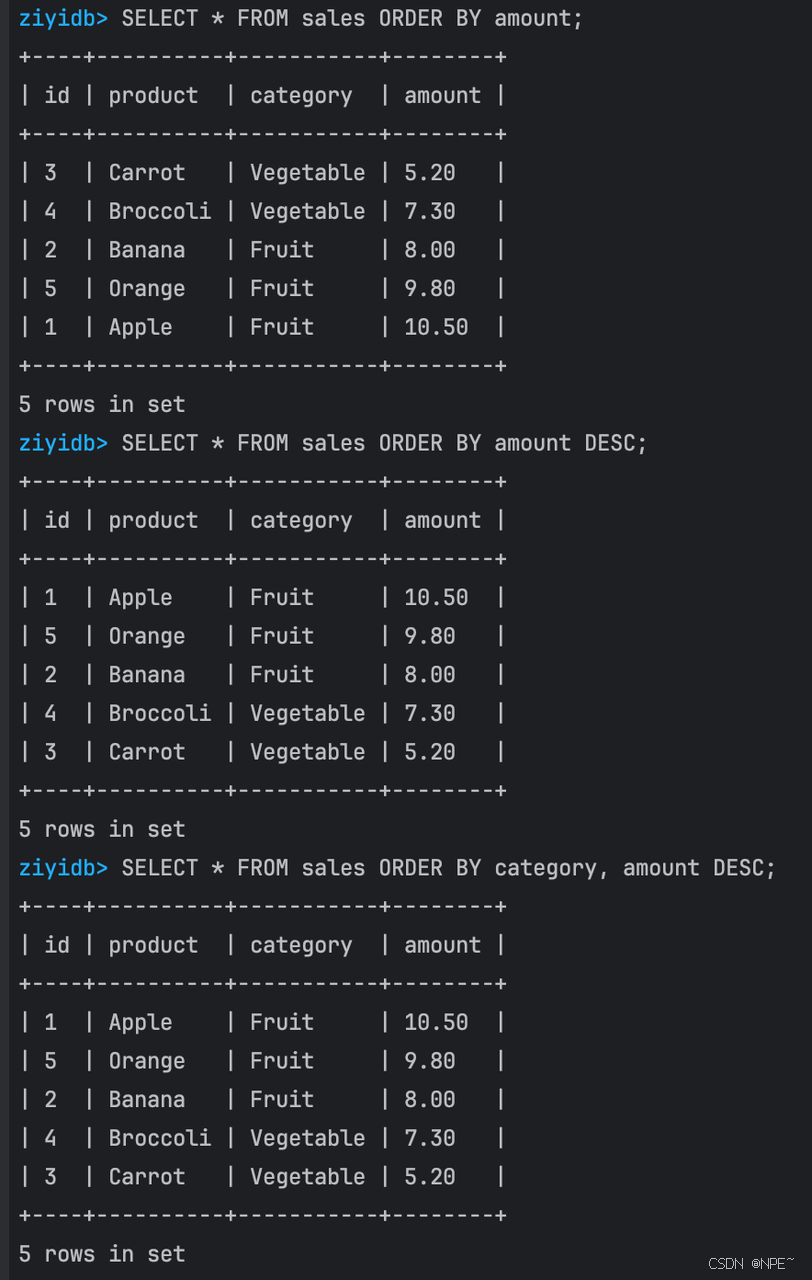
INSERT INTO sales VALUES (5, 'Orange', 'Fruit', 9.8);SELECT * FROM sales ORDER BY amount;
SELECT * FROM sales ORDER BY amount DESC;
SELECT * FROM sales ORDER BY category, amount DESC;
效果:




實戰)
與稀疏混合專家(Qwen3MoeSparseMoeBlock)模塊解析)



Leetcode77組合+39組合總和+216組合總和III)



)




 Redis哨兵如何與客戶端進行交互?)
)