背景意義
研究背景與意義
隨著全球人口的不斷增長,農業生產面臨著前所未有的挑戰,尤其是在資源有限的環境中,如何提高作物的產量和質量成為了亟待解決的問題。水培技術作為一種新興的農業生產方式,因其高效的水資源利用和較少的土壤病害而受到廣泛關注。然而,水培植物同樣面臨著病害的威脅,尤其是生菜等易受病害影響的作物。因此,開發一種高效的病害檢測系統,對于保障水培植物的健康生長、提高農業生產效率具有重要的現實意義。
本研究旨在基于改進的YOLOv11模型,構建一個高效的水培植物病害檢測系統。YOLO(You Only Look Once)系列模型因其優越的實時檢測能力和高準確率而被廣泛應用于計算機視覺領域。通過對YOLOv11進行改進,結合特定的水培植物病害數據集,我們期望能夠提升模型在病害檢測任務中的性能。該數據集包含1900張圖像,涵蓋了生菜的正常生長狀態與病害狀態兩大類,能夠為模型的訓練和評估提供豐富的樣本。
在當前的農業科技背景下,利用深度學習技術進行病害檢測,不僅可以提高檢測的準確性和效率,還能夠為農民提供及時的決策支持,減少病害對作物造成的損失。此外,該系統的推廣應用將有助于推動智能農業的發展,促進可持續農業的實現。通過本研究,我們希望能夠為水培植物的病害管理提供一種新思路,助力農業生產的智能化與現代化進程
圖片效果
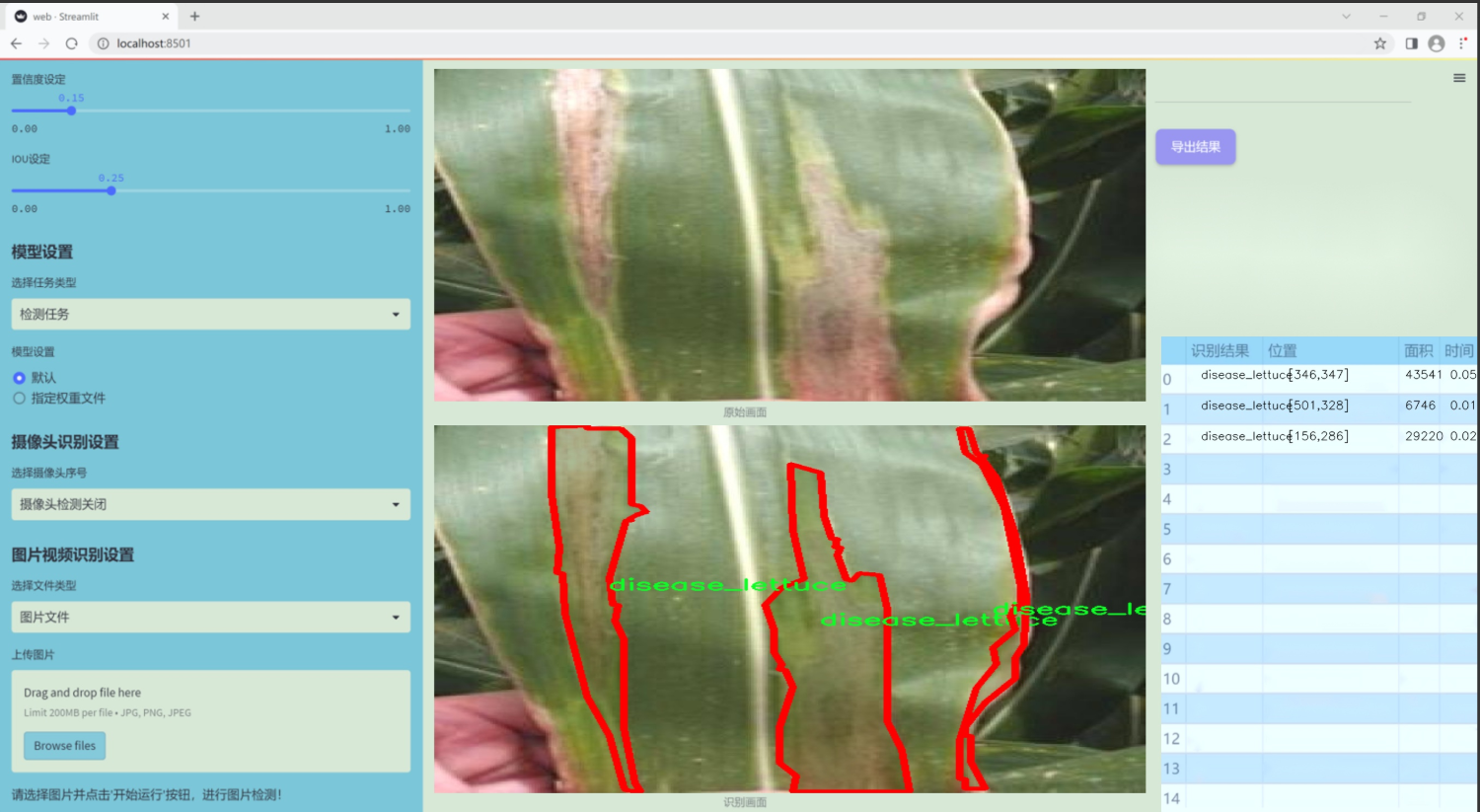
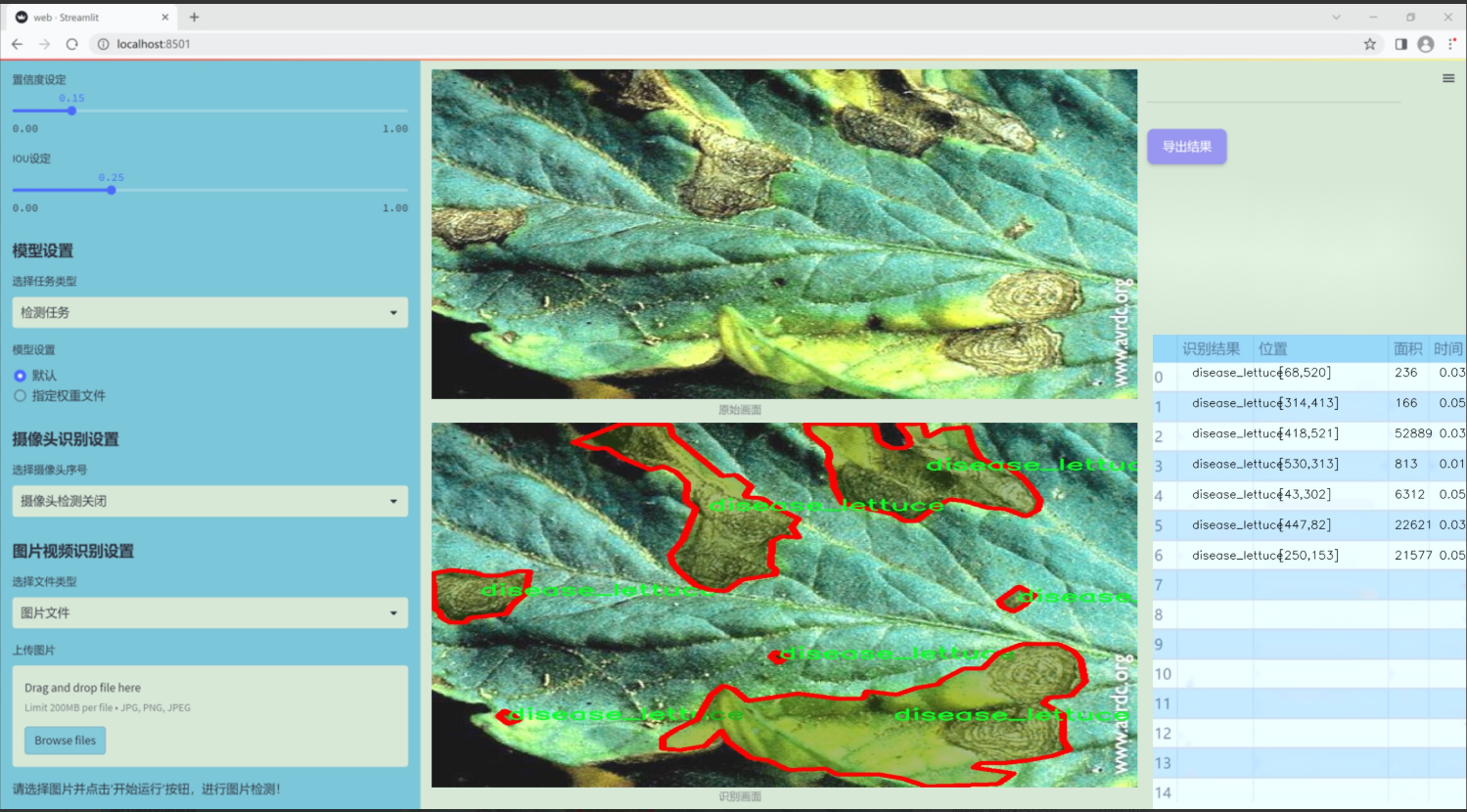
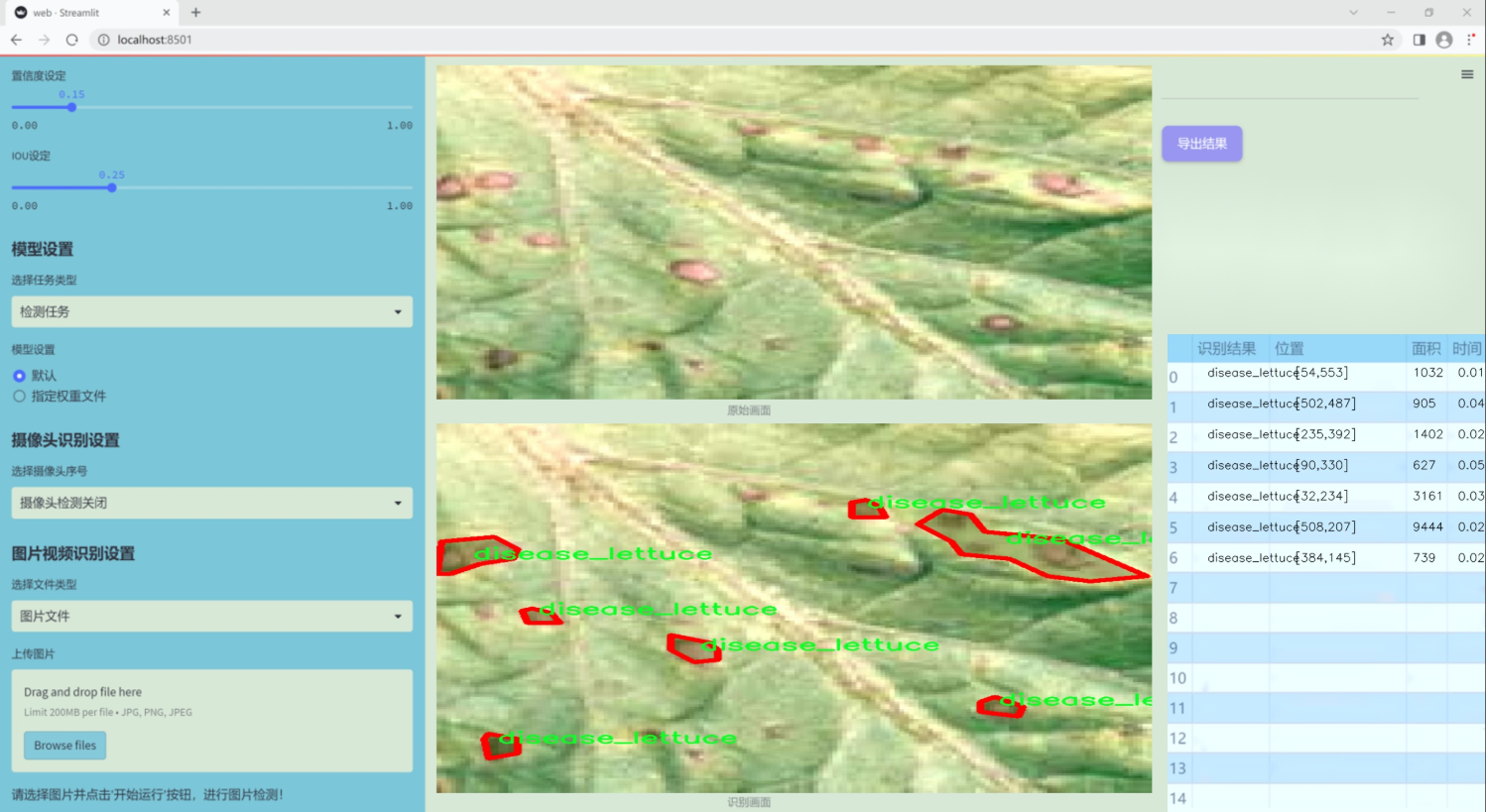
數據集信息
本項目數據集信息介紹
本項目所使用的數據集旨在支持改進YOLOv11模型在水培植物病害檢測系統中的應用,特別關注于水培生菜的健康狀況監測。數據集的主題為“aquaponic_polygan_disease_other”,專注于識別水培環境中生菜的不同狀態。該數據集包含兩個主要類別,分別為“disease_lettuce”和“normal_lettuce”,這為模型的訓練提供了清晰的目標和分類依據。
在水培農業中,生菜作為一種常見的作物,其生長健康與否直接影響到產量和品質。因此,及時識別生菜的病害情況對于農民和農業管理者而言至關重要。本數據集通過大量的圖像樣本,涵蓋了不同生長階段和環境條件下的生菜圖像,確保了數據的多樣性和代表性。每個類別的樣本均經過精心標注,以便于模型能夠準確學習到病害與正常生菜之間的特征差異。
在數據集的構建過程中,特別考慮了水培環境的特殊性,確保圖像中能夠反映出水培生菜的真實生長狀態和潛在病害表現。這種細致的標注和分類將有助于YOLOv11模型在訓練過程中有效提取特征,從而提高其在實際應用中的檢測精度和效率。通過對該數據集的深入分析和訓練,我們期望能夠開發出一種高效的病害檢測系統,幫助農民實時監控水培生菜的健康狀況,降低病害損失,提高農業生產的可持續性。


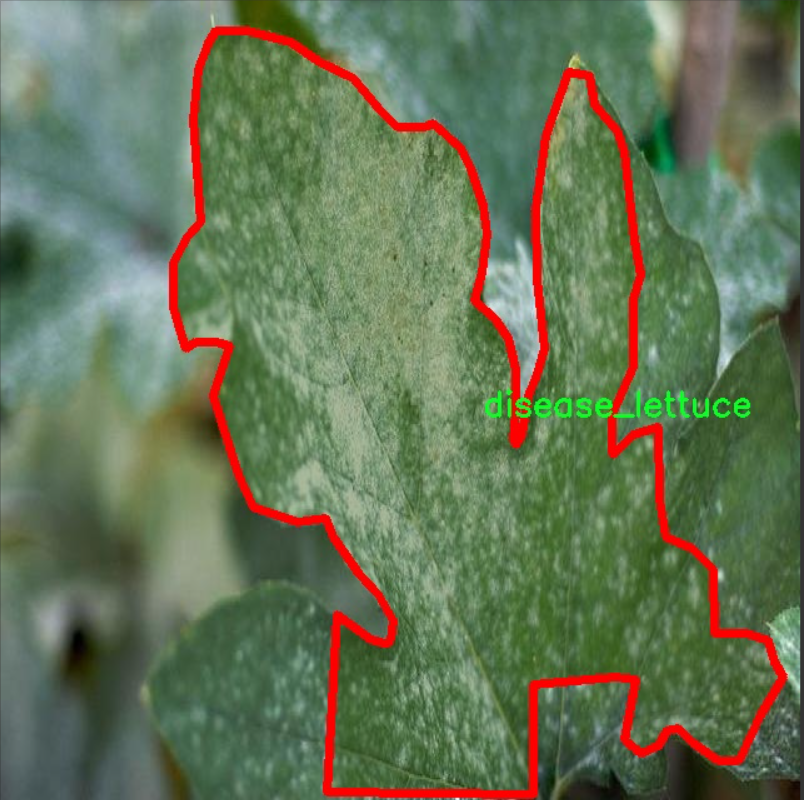


核心代碼
以下是經過簡化和注釋的核心代碼部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DyReLU(nn.Module):
“”"動態ReLU激活函數,能夠根據輸入動態調整激活值。
Args:inp (int): 輸入通道數。reduction (int): 通道壓縮比例。lambda_a (float): 動態調整參數。K2 (bool): 是否使用偏置。use_bias (bool): 是否使用偏置。use_spatial (bool): 是否使用空間注意力。init_a (list): 初始化參數a的值。init_b (list): 初始化參數b的值。
"""def __init__(self, inp, reduction=4, lambda_a=1.0, K2=True, use_bias=True, use_spatial=False,init_a=[1.0, 0.0], init_b=[0.0, 0.0]):super(DyReLU, self).__init__()self.oup = inp # 輸出通道數self.lambda_a = lambda_a * 2 # 動態調整參數self.K2 = K2 # 是否使用偏置self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自適應平均池化# 根據是否使用偏置設置exp的值self.exp = 4 if use_bias else 2 if K2 else 2 if use_bias else 1# 確定壓縮比例squeeze = inp // reduction if reduction == 4 else _make_divisible(inp // reduction, 4)# 定義全連接層self.fc = nn.Sequential(nn.Linear(inp, squeeze),nn.ReLU(inplace=True),nn.Linear(squeeze, self.oup * self.exp),h_sigmoid() # 使用h_sigmoid作為激活函數)# 如果使用空間注意力,定義相應的卷積層self.spa = nn.Sequential(nn.Conv2d(inp, 1, kernel_size=1),nn.BatchNorm2d(1),) if use_spatial else Nonedef forward(self, x):"""前向傳播函數。"""# 如果輸入是列表,分離輸入和輸出x_in = x[0] if isinstance(x, list) else xx_out = x[1] if isinstance(x, list) else xb, c, h, w = x_in.size() # 獲取輸入的尺寸y = self.avg_pool(x_in).view(b, c) # 自適應平均池化并調整形狀y = self.fc(y).view(b, self.oup * self.exp, 1, 1) # 通過全連接層并調整形狀# 根據exp的值計算輸出if self.exp == 4:a1, b1, a2, b2 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]a2 = (a2 - 0.5) * self.lambda_a + self.init_a[1]b1 = b1 - 0.5 + self.init_b[0]b2 = b2 - 0.5 + self.init_b[1]out = torch.max(x_out * a1 + b1, x_out * a2 + b2)elif self.exp == 2:a1, b1 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]b1 = b1 - 0.5 + self.init_b[0]out = x_out * a1 + b1elif self.exp == 1:a1 = ya1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]out = x_out * a1# 如果使用空間注意力,計算空間注意力并調整輸出if self.spa:ys = self.spa(x_in).view(b, -1)ys = F.softmax(ys, dim=1).view(b, 1, h, w) * h * wys = F.hardtanh(ys, 0, 3, inplace=True) / 3out = out * ysreturn out
class DyDCNv2(nn.Module):
“”"帶有歸一化層的ModulatedDeformConv2d,用于DyHead。
Args:in_channels (int): 輸入通道數。out_channels (int): 輸出通道數。stride (int | tuple[int], optional): 卷積的步幅。norm_cfg (dict, optional): 歸一化層的配置字典。
"""def __init__(self, in_channels, out_channels, stride=1, norm_cfg=dict(type='GN', num_groups=16, requires_grad=True)):super().__init__()self.with_norm = norm_cfg is not None # 是否使用歸一化bias = not self.with_norm # 如果不使用歸一化,則使用偏置self.conv = ModulatedDeformConv2d(in_channels, out_channels, 3, stride=stride, padding=1, bias=bias) # 定義可調變形卷積if self.with_norm:self.norm = build_norm_layer(norm_cfg, out_channels)[1] # 構建歸一化層def forward(self, x, offset, mask):"""前向傳播函數。"""x = self.conv(x.contiguous(), offset, mask) # 進行卷積操作if self.with_norm:x = self.norm(x) # 如果使用歸一化,則進行歸一化return x
代碼說明:
DyReLU: 這是一個動態ReLU激活函數的實現,能夠根據輸入的特征動態調整激活值。它通過自適應平均池化和全連接層來生成動態參數,并可以選擇性地使用空間注意力。
DyDCNv2: 這是一個帶有歸一化層的可調變形卷積模塊,主要用于特征提取。它根據輸入的特征圖和偏移量、掩碼進行卷積操作,并在需要時應用歸一化。
這兩個類是深度學習模型中用于特征提取和激活的核心組件,能夠增強模型的表達能力和性能。
這個程序文件 dyhead_prune.py 實現了一些深度學習中的模塊,主要用于動態頭(Dynamic Head)模型的構建,特別是在目標檢測和圖像分割等任務中。代碼使用了 PyTorch 框架,并引入了一些額外的庫,如 mmcv 和 mmengine,用于構建激活層和歸一化層。
首先,文件中定義了一個 _make_divisible 函數,該函數用于確保某個值能夠被指定的除數整除,并且不會小于最小值的 90%。這個函數在調整網絡結構時非常有用,特別是在處理通道數時。
接下來,定義了幾個激活函數的類,包括 swish、h_swish 和 h_sigmoid。這些類都繼承自 nn.Module,并實現了 forward 方法,以便在前向傳播中使用。swish 是一種新型激活函數,h_swish 和 h_sigmoid 則是高斯激活函數的變種,通常用于深度學習模型中以提高性能。
然后,定義了 DyReLU 類,這是一個動態 ReLU 激活函數的實現。該類通過自適應的方式調整激活函數的參數,以適應輸入特征的不同。構造函數中設置了一些參數,如輸入通道數、縮減比例、是否使用偏置等。forward 方法根據輸入特征計算輸出,支持不同的輸出方式,包括使用空間注意力機制。
接著,定義了 DyDCNv2 類,這是一個帶有歸一化層的可調變形卷積層。該類的構造函數接受輸入和輸出通道數、步幅以及歸一化配置,并在前向傳播中應用變形卷積和歸一化。
最后,定義了 DyHeadBlock_Prune 類,這是一個包含三種注意力機制的動態頭塊。構造函數中初始化了多個卷積層和注意力模塊。forward 方法負責計算偏移量和掩碼,并根據輸入特征的不同層次進行卷積操作,結合高、中、低層特征以生成最終的輸出。
整體來看,這個文件實現了一個復雜的動態頭結構,利用動態激活函數和可調變形卷積來增強模型的表達能力,適用于需要多尺度特征融合的深度學習任務。
10.4 CTrans.py
以下是代碼中最核心的部分,并附上詳細的中文注釋:
import torch
import torch.nn as nn
import numpy as np
from torch.nn import Dropout, Softmax, Conv2d, LayerNorm
class Channel_Embeddings(nn.Module):
“”“構建來自圖像塊和位置的嵌入”“”
def init(self, patchsize, img_size, in_channels):
super().init()
img_size = (img_size, img_size) # 將圖像大小轉換為元組
patch_size = (patchsize, patchsize) # 將補丁大小轉換為元組
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1]) # 計算補丁數量
# 使用最大池化和卷積層構建補丁嵌入self.patch_embeddings = nn.Sequential(nn.MaxPool2d(kernel_size=5, stride=5),Conv2d(in_channels=in_channels,out_channels=in_channels,kernel_size=patchsize // 5,stride=patchsize // 5))# 位置嵌入參數self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, in_channels))self.dropout = Dropout(0.1) # Dropout層,防止過擬合def forward(self, x):"""前向傳播函數"""if x is None:return Nonex = self.patch_embeddings(x) # 計算補丁嵌入x = x.flatten(2) # 將特征展平x = x.transpose(-1, -2) # 轉置以適應后續操作embeddings = x + self.position_embeddings # 添加位置嵌入embeddings = self.dropout(embeddings) # 應用Dropoutreturn embeddings
class Attention_org(nn.Module):
“”“自定義的多頭注意力機制”“”
def init(self, vis, channel_num):
super(Attention_org, self).init()
self.vis = vis # 可視化標志
self.KV_size = sum(channel_num) # 鍵值對的總大小
self.channel_num = channel_num # 通道數量
self.num_attention_heads = 4 # 注意力頭的數量
# 初始化查詢、鍵、值的線性變換self.query = nn.ModuleList([nn.Linear(c, c, bias=False) for c in channel_num])self.key = nn.Linear(self.KV_size, self.KV_size, bias=False)self.value = nn.Linear(self.KV_size, self.KV_size, bias=False)self.psi = nn.InstanceNorm2d(self.num_attention_heads) # 實例歸一化self.softmax = Softmax(dim=3) # Softmax層self.attn_dropout = Dropout(0.1) # 注意力的Dropoutself.proj_dropout = Dropout(0.1) # 投影的Dropoutdef forward(self, *embeddings):"""前向傳播函數"""multi_head_Q = [query(emb) for query, emb in zip(self.query, embeddings) if emb is not None]multi_head_K = self.key(torch.cat(embeddings, dim=2)) # 計算鍵multi_head_V = self.value(torch.cat(embeddings, dim=2)) # 計算值# 計算注意力分數attention_scores = [torch.matmul(Q, multi_head_K) / np.sqrt(self.KV_size) for Q in multi_head_Q]attention_probs = [self.softmax(self.psi(score)) for score in attention_scores]# 應用Dropoutattention_probs = [self.attn_dropout(prob) for prob in attention_probs]# 計算上下文層context_layers = [torch.matmul(prob, multi_head_V) for prob in attention_probs]# 投影輸出outputs = [self.proj_dropout(layer) for layer in context_layers]return outputs
class ChannelTransformer(nn.Module):
“”“通道變換器模型”“”
def init(self, channel_num=[64, 128, 256, 512], img_size=640, vis=False, patchSize=[40, 20, 10, 5]):
super().init()
self.embeddings = nn.ModuleList([Channel_Embeddings(patchSize[i], img_size // (2 ** (i + 2)), channel_num[i]) for i in range(len(channel_num))])
self.encoder = Encoder(vis, channel_num) # 編碼器
self.reconstruct = nn.ModuleList([Reconstruct(channel_num[i], channel_num[i], kernel_size=1, scale_factor=(patchSize[i], patchSize[i])) for i in range(len(channel_num))])
def forward(self, en):"""前向傳播函數"""embeddings = [embed(en[i]) for i, embed in enumerate(self.embeddings) if en[i] is not None]encoded = self.encoder(*embeddings) # 編碼reconstructed = [recon(enc) + en[i] for i, (recon, enc) in enumerate(zip(self.reconstruct, encoded)) if en[i] is not None]return reconstructed
代碼說明:
Channel_Embeddings:該類負責將輸入圖像轉換為補丁嵌入,并添加位置嵌入。使用最大池化和卷積層來提取特征。
Attention_org:實現了多頭注意力機制,計算輸入嵌入的注意力分數,并返回上下文層。支持可視化注意力權重。
ChannelTransformer:整個模型的核心,負責將輸入的多個通道嵌入進行編碼和重構。通過調用嵌入層和編碼器來處理輸入數據。
這個程序文件 CTrans.py 實現了一個基于通道變換器(Channel Transformer)的深度學習模型,主要用于圖像處理任務。代碼中定義了多個類,每個類實現了模型的不同組成部分。以下是對代碼的詳細說明。
首先,文件導入了一些必要的庫,包括 PyTorch、NumPy 和一些深度學習模塊。接著,定義了幾個主要的類。
Channel_Embeddings 類用于構建圖像的嵌入表示。它接收圖像的尺寸和通道數,并通過卷積和池化操作將圖像劃分為多個補丁。每個補丁會生成一個嵌入向量,并且類中還包含位置嵌入以保留空間信息。前向傳播方法將輸入圖像轉換為嵌入表示,并添加位置嵌入。
Reconstruct 類用于重建圖像。它接收嵌入向量并通過上采樣和卷積操作將其轉換回圖像的空間維度。這個類的前向傳播方法會對輸入進行變換并返回重建后的圖像。
Attention_org 類實現了多頭注意力機制。它接收多個嵌入并計算注意力權重,使用線性變換將查詢、鍵和值映射到適當的維度。通過計算注意力分數并應用 softmax 函數,類可以生成加權的上下文向量。
Mlp 類實現了一個簡單的多層感知機(MLP),用于對嵌入進行非線性變換。它包含兩個全連接層和一個激活函數(GELU),并且在每個層后都有 dropout 操作以防止過擬合。
Block_ViT 類實現了一個變換器塊,結合了注意力機制和前饋網絡。它首先對輸入進行層歸一化,然后通過注意力機制處理嵌入,最后通過 MLP 進行進一步的變換。這個類的前向傳播方法返回經過處理的嵌入和注意力權重。
Encoder 類由多個 Block_ViT 組成,負責將輸入的嵌入通過多個變換器塊進行編碼。它同樣對嵌入進行層歸一化,并在每個塊中收集注意力權重。
ChannelTransformer 類是整個模型的核心。它初始化了多個嵌入層、編碼器和重建層。前向傳播方法接收輸入的圖像,生成嵌入,經過編碼器處理后再進行重建。最終輸出的圖像是對輸入圖像的重建結果。
最后,GetIndexOutput 類用于從模型的輸出中提取特定索引的結果,方便后續處理。
總體來說,這個程序實現了一個通道變換器模型,結合了卷積、注意力機制和多層感知機等技術,適用于圖像處理任務。通過分層結構和模塊化設計,代碼具有良好的可讀性和可擴展性。
源碼文件

源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式






:『混沌工程的定義與實踐』)











學習總結-20250916)
)