1.前言
即夢AI作為字節跳動旗下的AI繪畫與視頻生成平臺,近年來不斷推出新的模型和功能,以提升用戶體驗和創作能力。
即夢AI 3.0是即夢AI的最新版本,于2025年4月發布,標志著其在中文生圖模型上的重大升級。該版本不僅在中文生圖能力上有所突破,還支持視頻生成、多模態生成等高級功能。即夢AI 3.0的視頻生成模型(視頻3.0)在動作遵循能力、鏡頭遵循能力、物理模擬和情緒表達方面有顯著提升。此外,即夢AI 3.0還支持“影視質感”效果,提供更高質量的圖像輸出.

之前也有給大家介紹過關于即夢文生圖和文生視頻。《全網首發!即夢AI+dify工作流,帶你領略AI繪畫的無限魅力!》和《dify案例分享-5 步解鎖免費即夢文生視頻工作流,輕松制作大片》隨著即夢AI模型的升級,生成的圖片和生成的視頻會有更好的效果。昨天在開源想項目上做了一下魔改目前可以實現最新的即夢3.1 模型(文生圖)、即夢-Video3.0(文生視頻)等模型了。今天就帶大家做一個基于即夢AI繪畫的免費支持文生圖和文生視頻的工作流。話不多說下面給大家看一下工作流的效果:
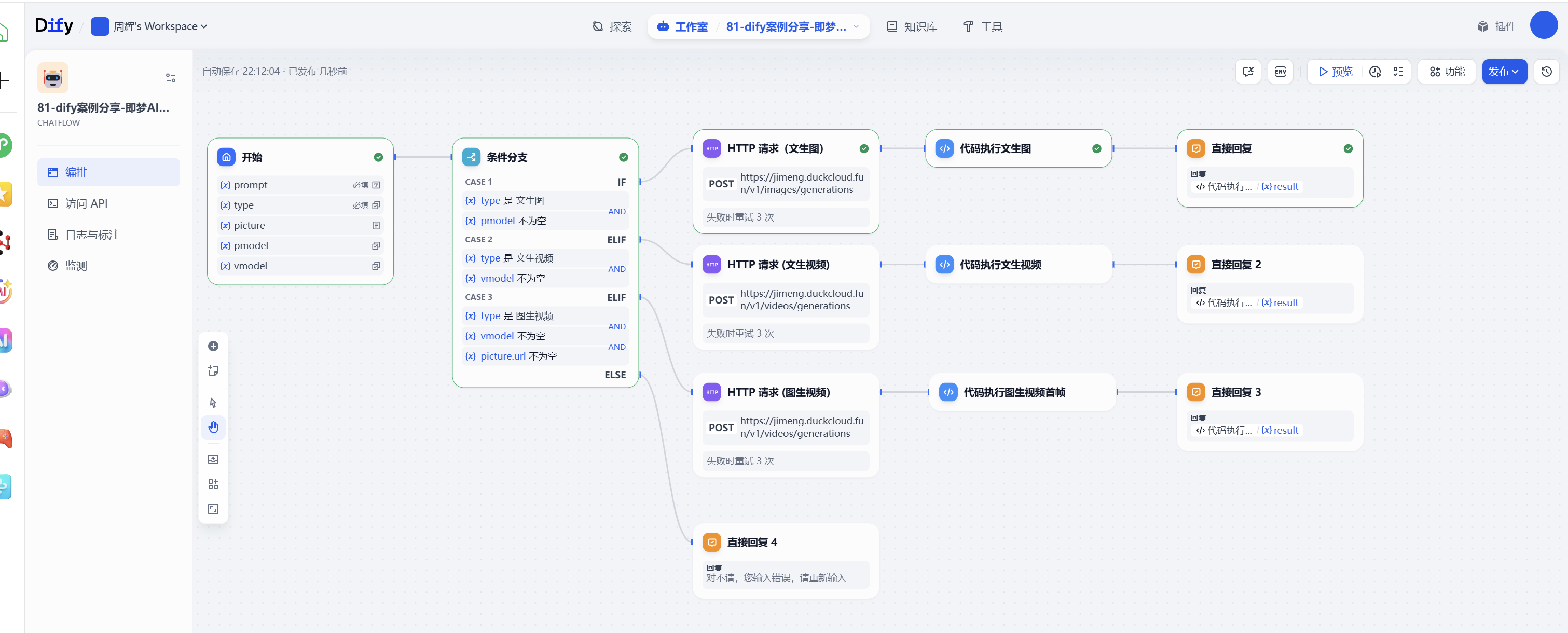
文生圖效果:
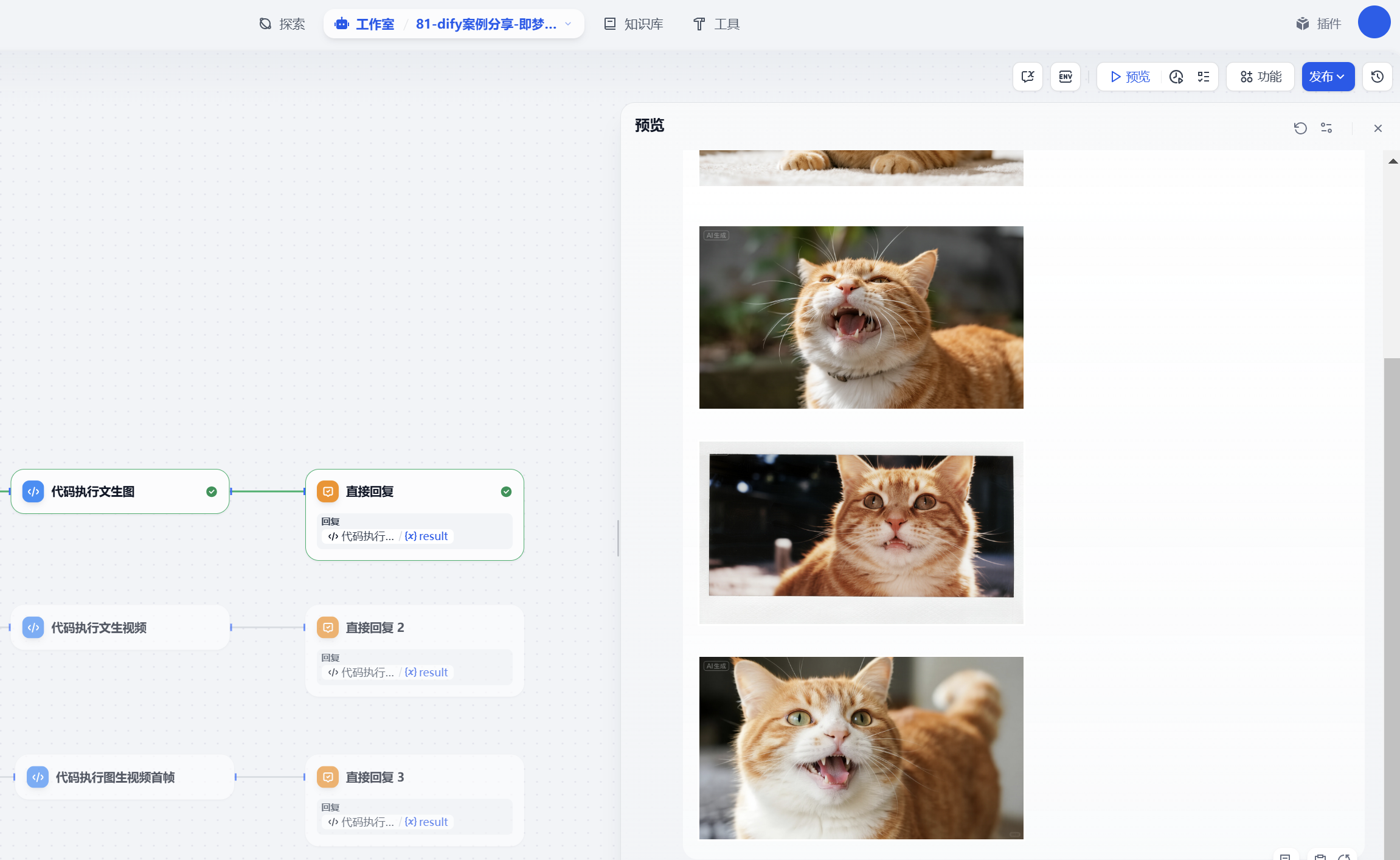
文生視頻:

圖生視頻效果
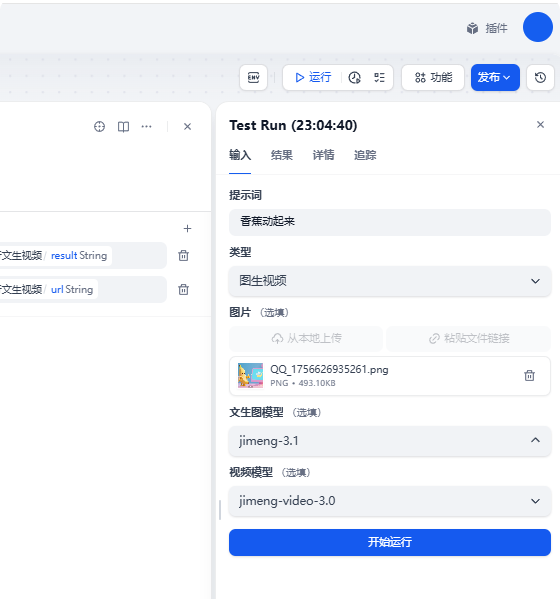
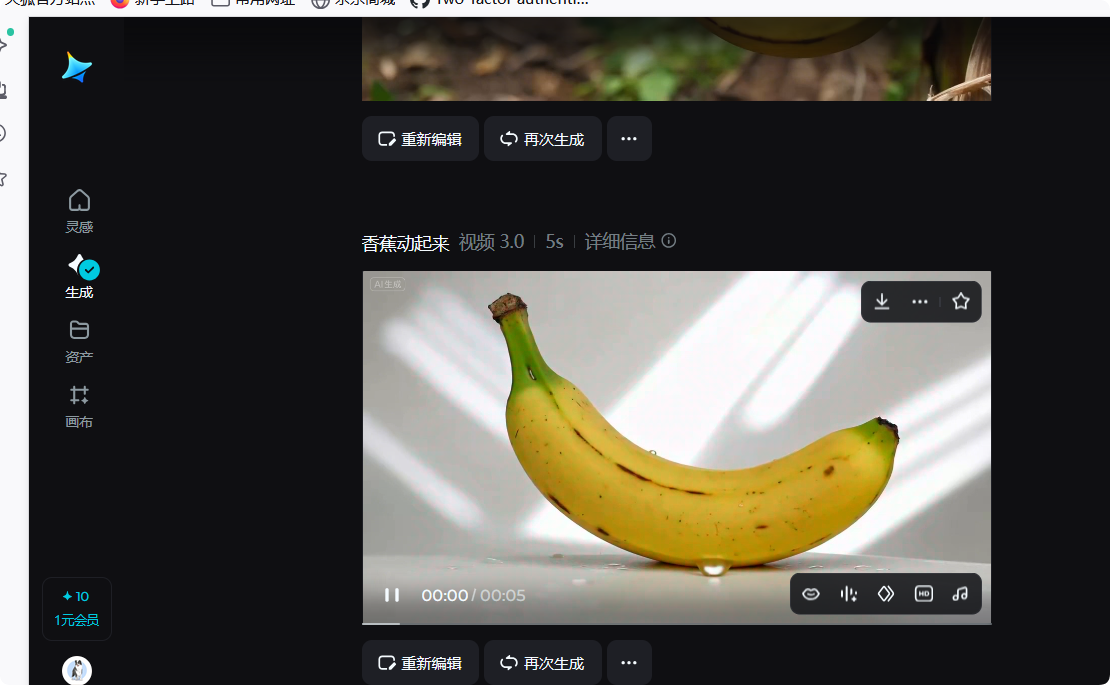
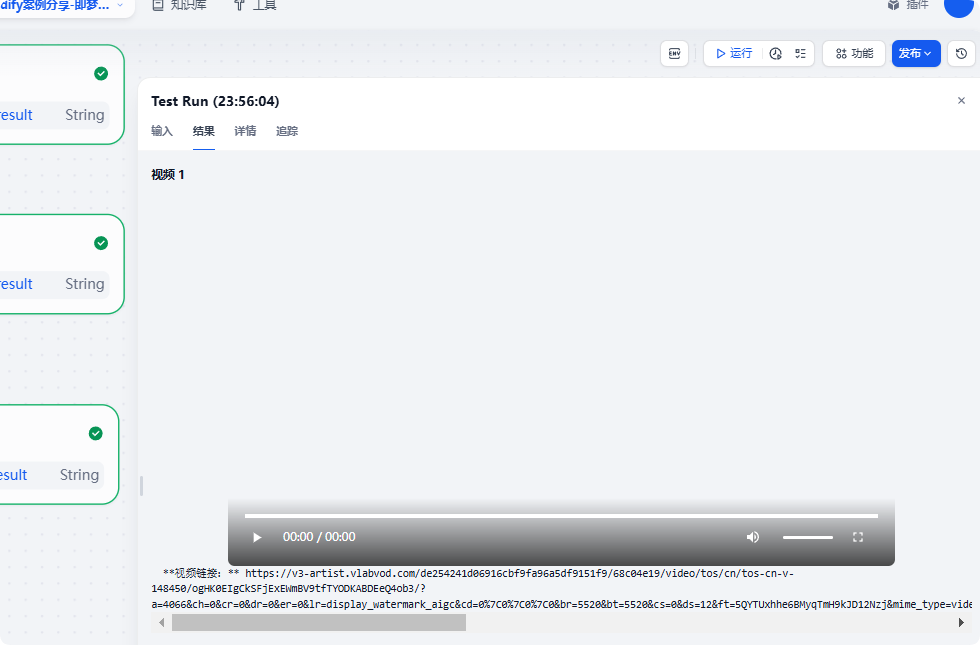
打開視頻鏈接
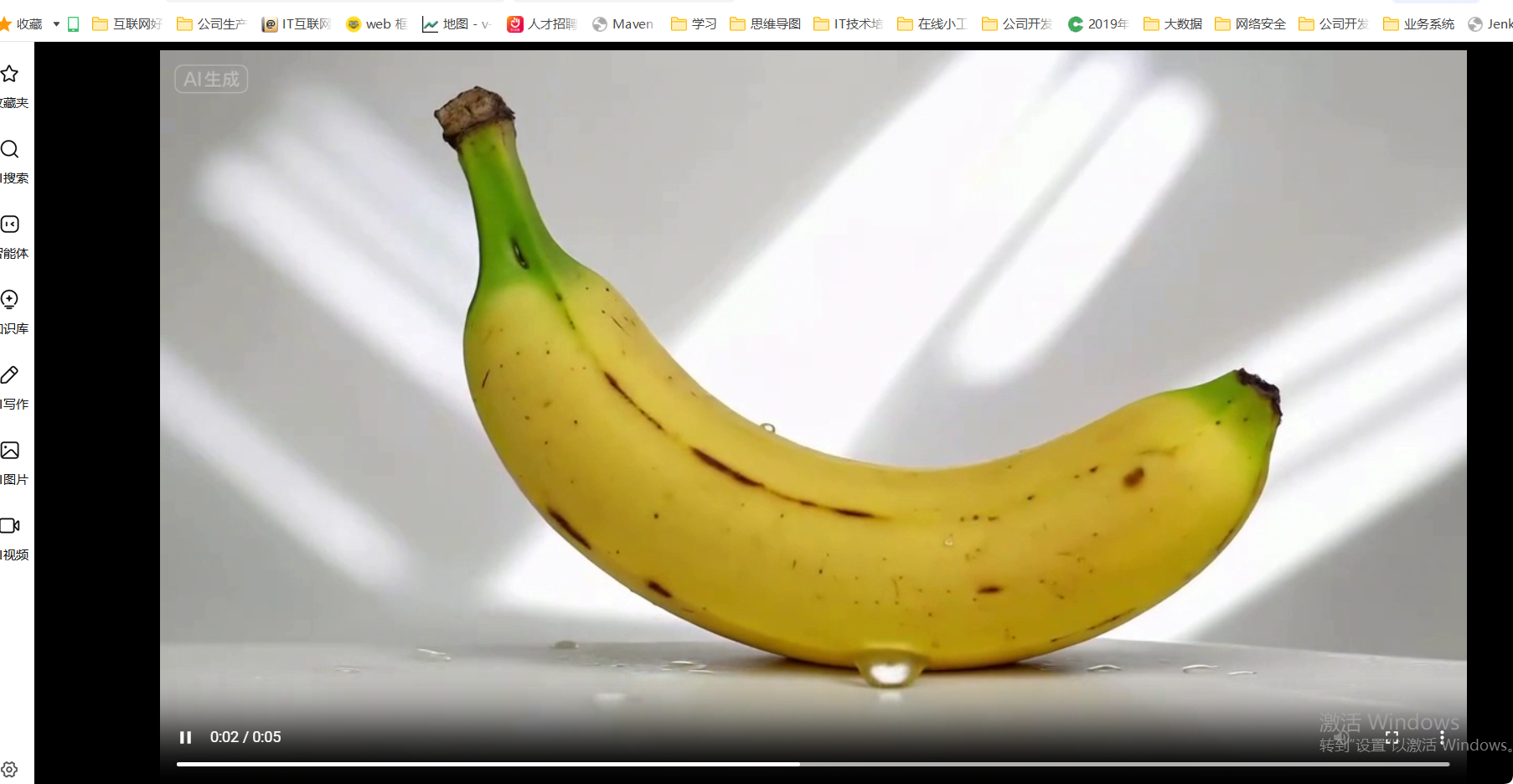
那么這樣的工作流是如何制作的呢?下面帶大家手把手做一遍。
2.工作流制作
開始
開始節點這地方設置比較簡單,就是接受用戶的提示詞-prompt
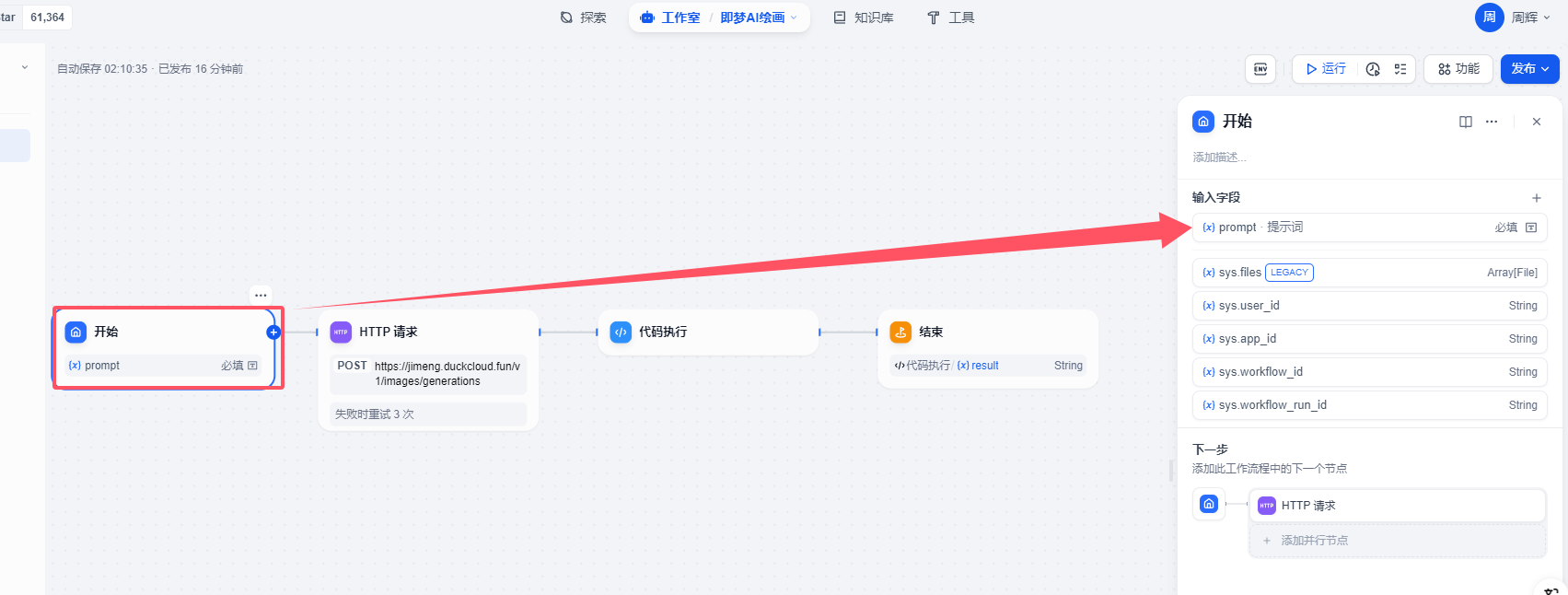
提示詞 文本輸入,這里主要是接受用戶輸入的提示詞文本信息。
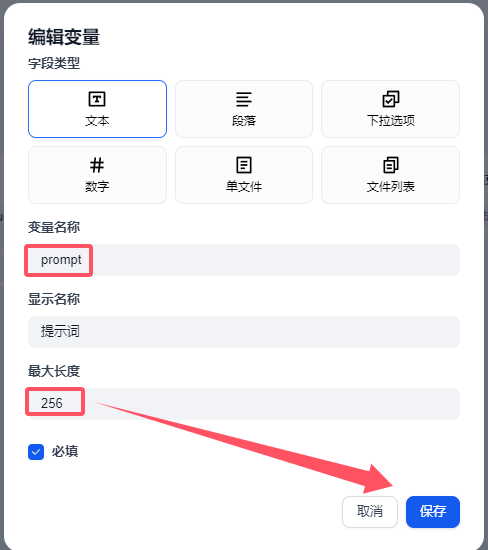
目前dify 文本輸入地方最大長度是256,這里小伙伴要注意了,如果提示詞過長會截斷的。
考慮到這個工作流支持文生圖、文生視頻,所以開始節點配置參數要比其他工作流多。主要是多了一下模型選擇,type類型等。
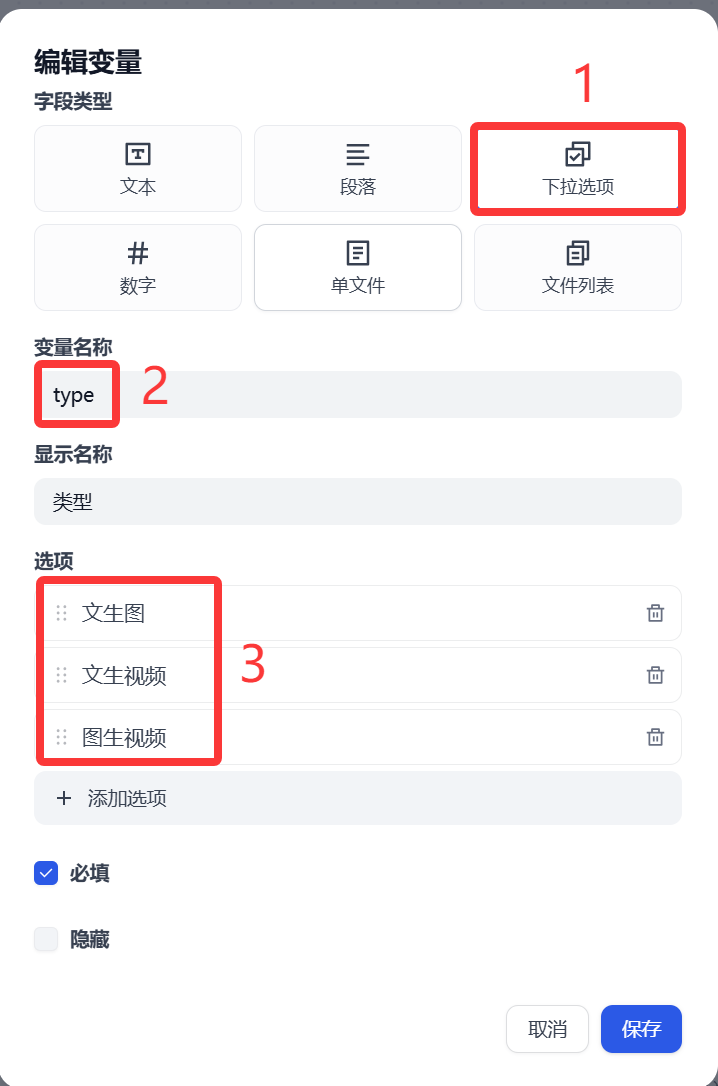
這個picture接受用戶輸入的圖片,主要是為后面圖生視頻使用。(這塊設置可選選)
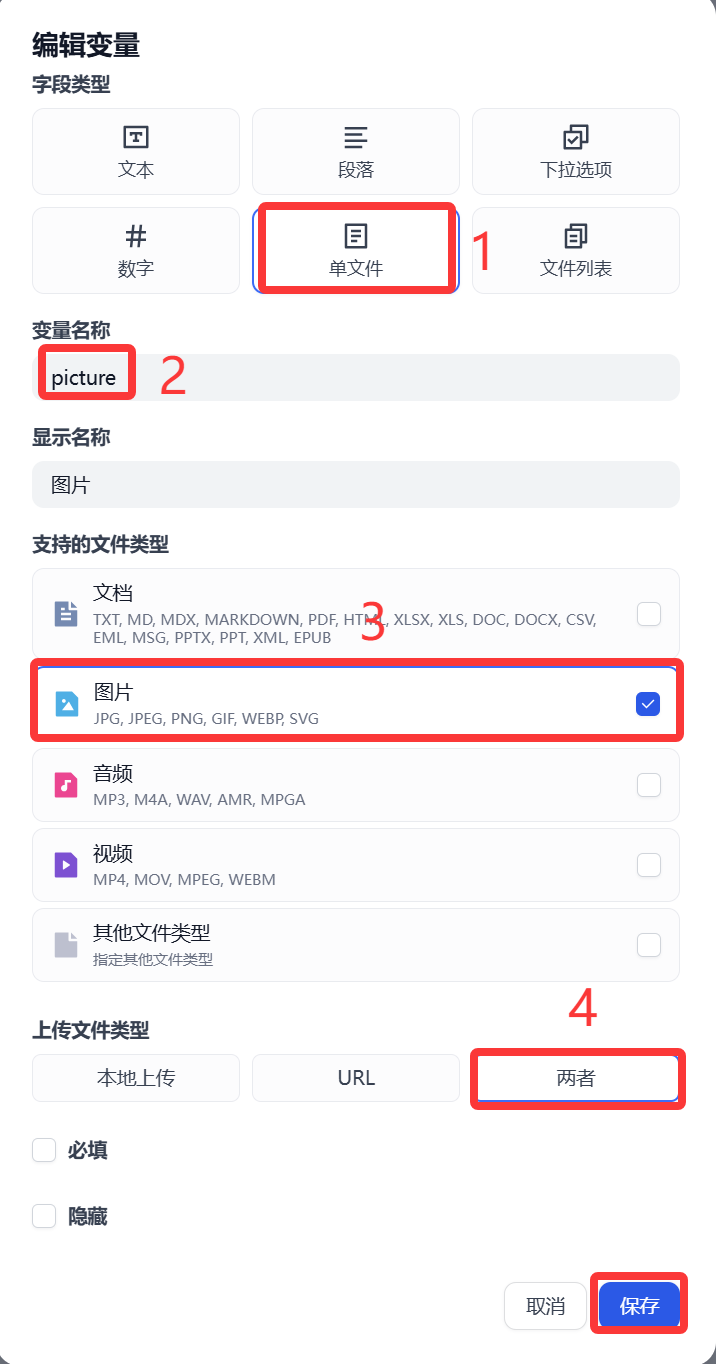
pmodel 主要是讓用戶選擇文生圖模型使用(這塊設置可選選)
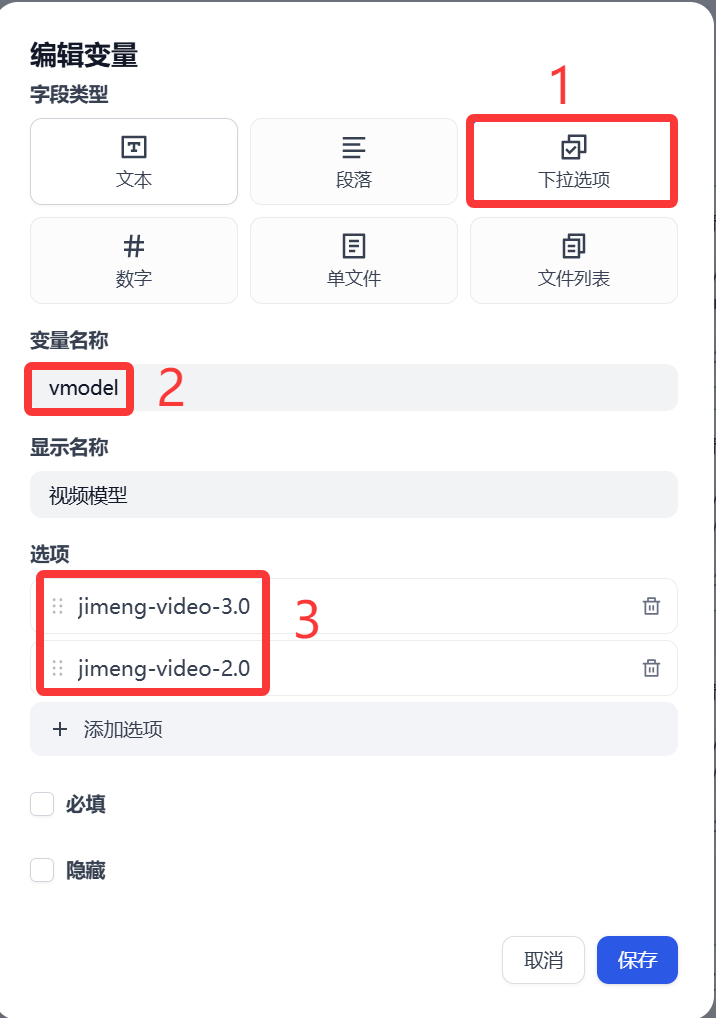
vmodel主要是讓用戶選擇文生視頻模型使用(這塊設置可選選)
以上我們就完成了開始節點的設置。
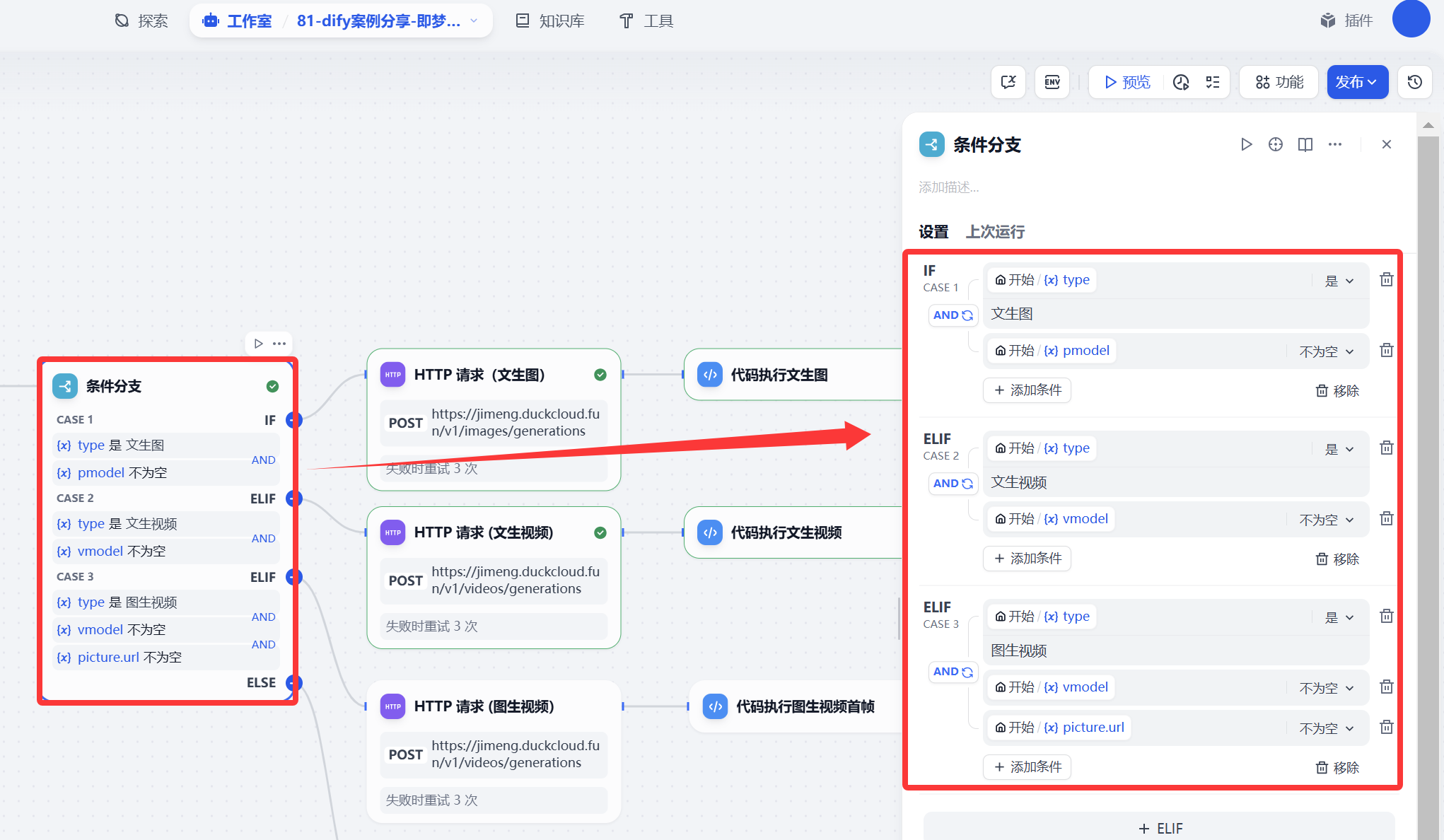
條件分支
這個條件分支主要是目的根據用戶選擇(文生圖、文生視頻、圖生視頻等流程判斷)
HTTP請求
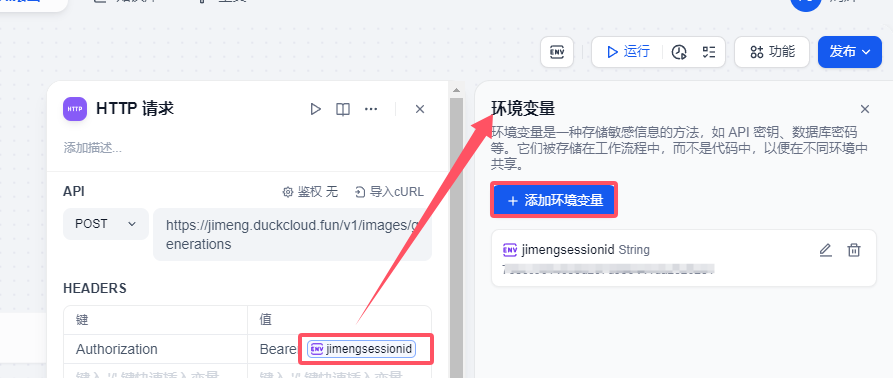
這個HTTP請求是調用一個后端一個接口服務,這個接口服務可以實現即夢AI文生圖、文生視頻、圖生視頻的逆向。大家可以使用即夢每天送的積分來使用。服務端部署這里就不做詳細展開。
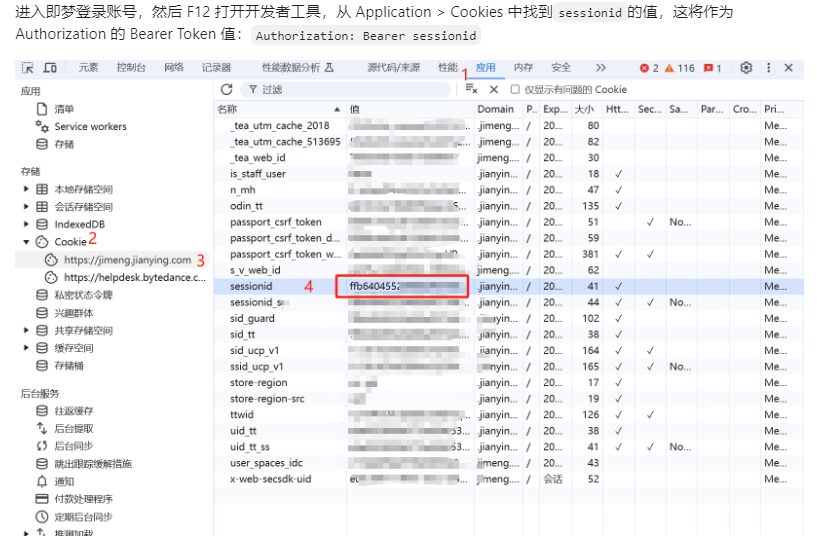
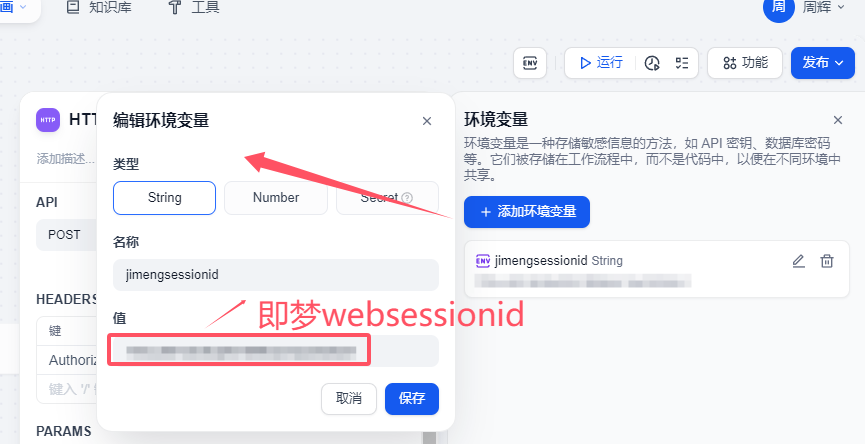
使用這個接口是需要獲取你即夢AI 平臺sessionid,這個sessionid如何獲取呢?
http請求配置
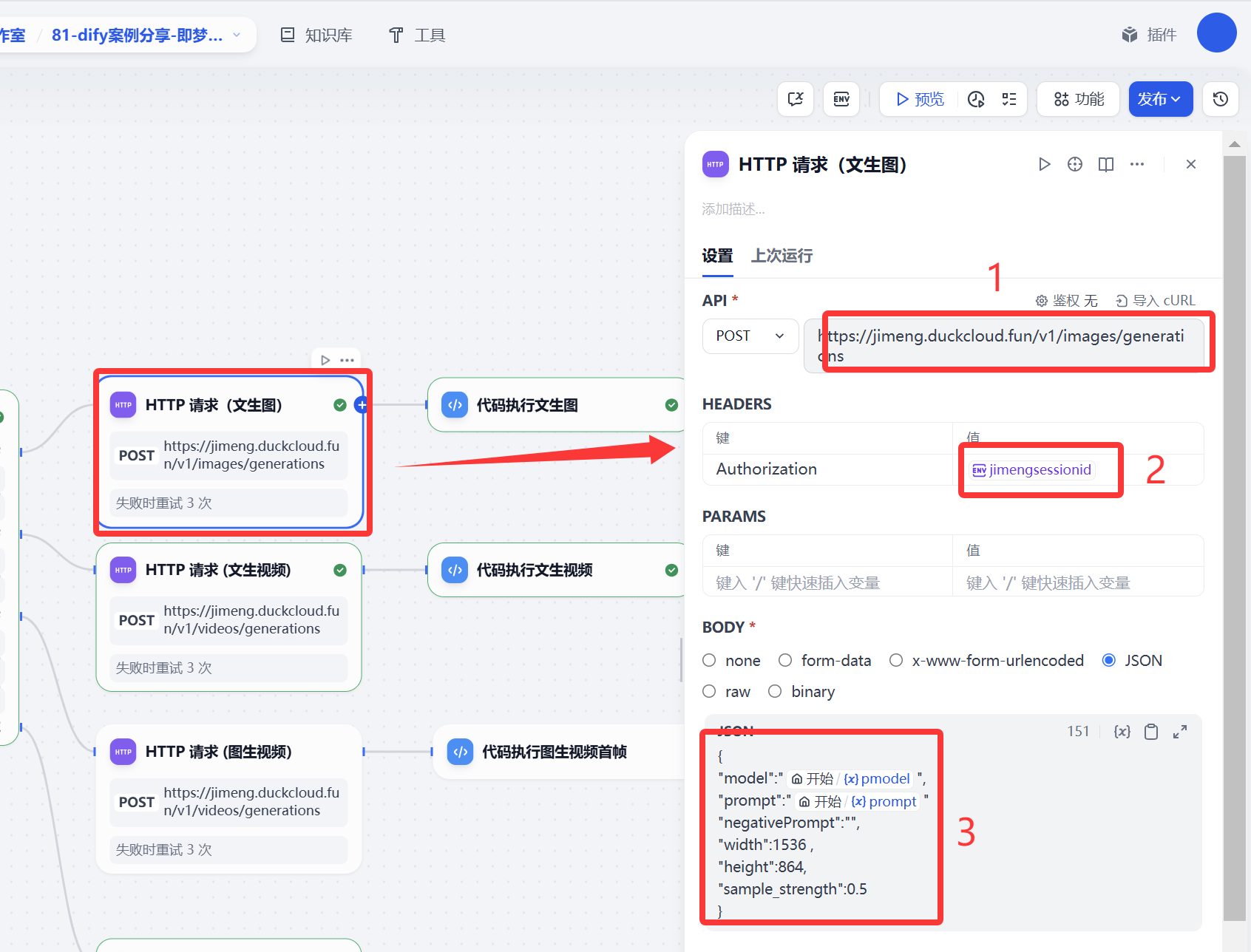
請求地址 https://jimeng.duckcloud.fun/v1/images/generations 這個是nas部署 使用cloudfare 映射的一個帶域名公網api接口地址
請求方式 post 請求
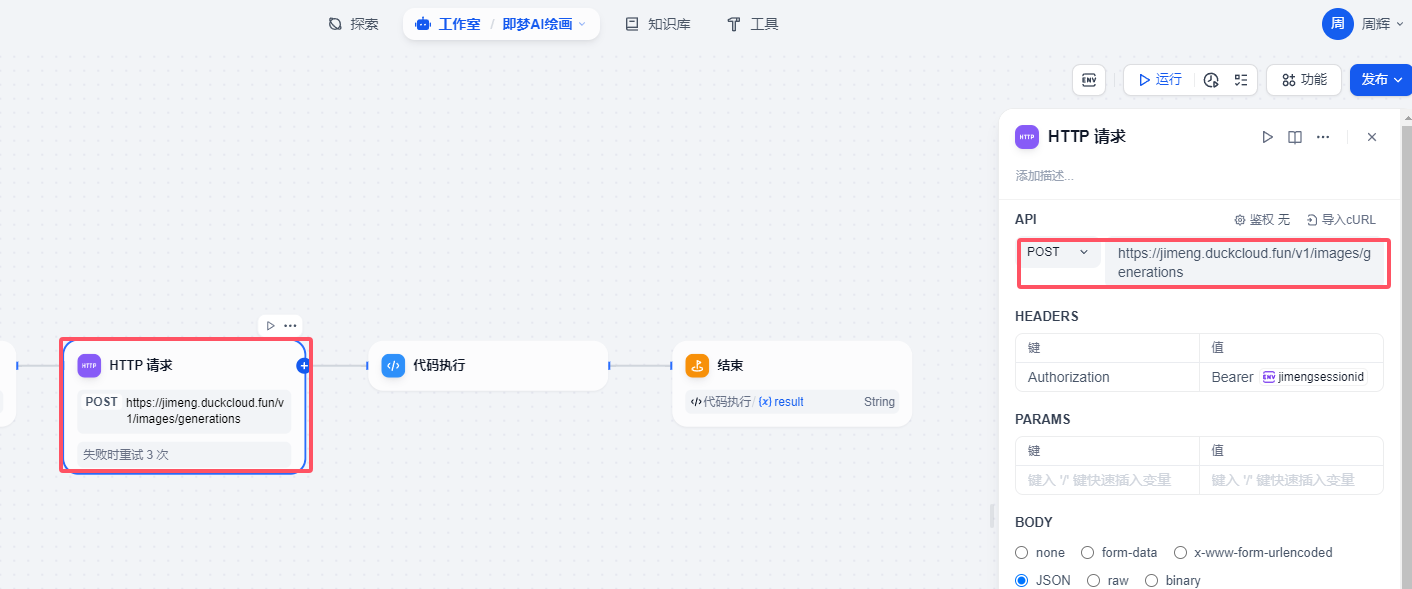
heards部署 主要是接口請求的鑒權的配置。其實你也可以理解就是調用openai接口輸入的api key 這個API 其實就是你登錄即夢web網站產生的sessionid,我這里使用到環境變量的方式來實現的。
? http 請求body部分如下:
文生圖
{
"model":"{{#1756864683426.pmodel#}}",
"prompt":"{{#1756864683426.prompt#}}"
"negativePrompt":"",
"width":1536 ,
"height":864,
"sample_strength":0.5
}
文生視頻
{
"model":"{{#1756864683426.vmodel#}}",
"prompt":"{{#1756864683426.prompt#}}"
"negativePrompt":"",
"width":1536 ,
"height":864,
"resolution": "720p"
}
圖生視頻
{
"model":"{{#1756864683426.vmodel#}}",
"prompt":"{{#1756864683426.prompt#}}"
"negativePrompt":"",
"width":1536 ,
"height":864,
"resolution": "720p",
"filePaths": ["{{#1756864683426.picture.url#}}"]
}
文生圖的接口請求地址https://jimeng.duckcloud.fun/v1/images/generations 文生視頻和圖生視頻請求地址 https://jimeng.duckcloud.fun/v1/videos/generations 其他配置基本是一樣的。這里就以文生圖截圖為案例
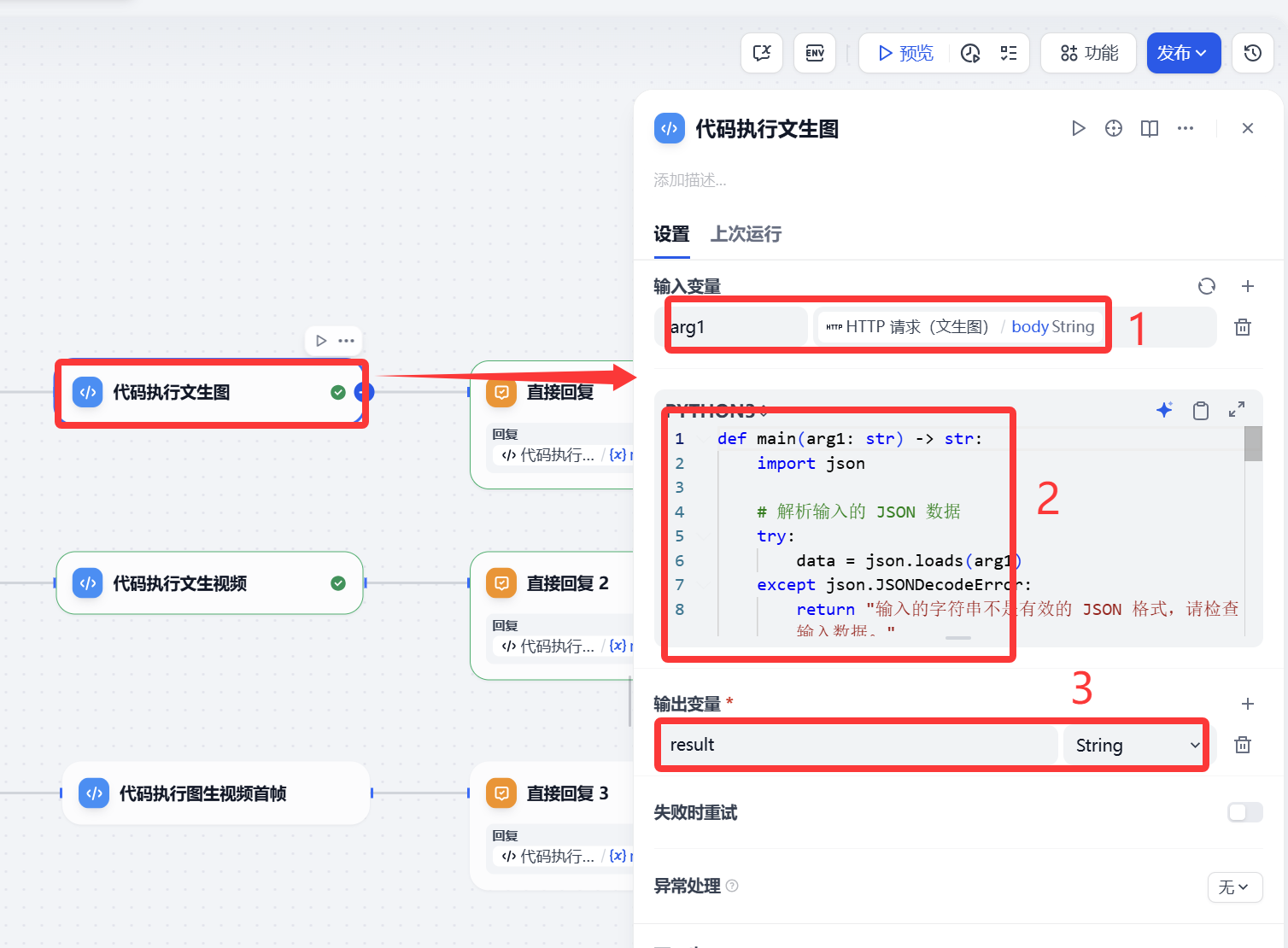
代碼執行
代碼執行的目的就是對HTTP請求返回的信息做一下處理,大體功能 是一樣。
文生圖代碼
def main(arg1: str) -> str:import json# 解析輸入的 JSON 數據try:data = json.loads(arg1)except json.JSONDecodeError:return "輸入的字符串不是有效的 JSON 格式,請檢查輸入數據。"# 確保解析后的數據包含 'data' 鍵if not isinstance(data, dict) or 'data' not in data:return "輸入的數據格式不正確,請確保輸入是一個包含 'data' 鍵的 JSON 對象。"# 獲取 'data' 鍵對應的數組數據image_data = data.get('data', [])# 確保 'data' 鍵的值是一個列表if not isinstance(image_data, list):return "輸入的數據中 'data' 鍵的值不是一個數組,請確保其值是一個 JSON 數組對象。"# 初始化結果字符串markdown_result = ""# 遍歷每條圖片數據for index, item in enumerate(image_data, start=1):# 檢查每條數據是否是字典,并且包含 'url' 字段if not isinstance(item, dict) or 'url' not in item:markdown_result += f"圖片第{index}條內容:無法提取 URL(缺少 'url' 字段)\n"continue# 提取 URL 并生成 Markdown 格式的圖片鏈接url = item['url']markdown_result += f"\n"# 返回最終的 Markdown 字符串return {"result": markdown_result}
文生視頻和圖生視頻代碼
def main(arg1: str) -> dict:import json# 解析輸入的 JSON 數據try:data = json.loads(arg1)except json.JSONDecodeError:return {"result": "輸入的字符串不是有效的 JSON 格式,請檢查輸入數據。"}# 確保解析后的數據包含 'data' 鍵if not isinstance(data, dict) or 'data' not in data:return {"result": "輸入的數據格式不正確,請確保輸入是一個包含 'data' 鍵的 JSON 對象。"}# 獲取 'data' 鍵對應的數組數據video_data = data.get('data', [])# 確保 'data' 鍵的值是一個列表if not isinstance(video_data, list):return {"result": "輸入的數據中 'data' 鍵的值不是一個數組,請確保其值是一個 JSON 數組對象。"}# 初始化結果字符串video_html = ""# 遍歷每條視頻數據for index, item in enumerate(video_data, start=1):# 檢查每條數據是否是字典,并且包含 'url' 字段if not isinstance(item, dict) or 'url' not in item:video_html += f"<p>視頻第{index}條內容:無法提取 URL(缺少 'url' 字段)</p>\n"continue# 提取 URLurl = item['url']# 生成 HTML5 video 標簽(Dify支持HTML顯示)video_html += f'''<div style="margin-bottom: 20px;"><h3>視頻 {index}</h3><video width="400" controls><source src="{url}" type="video/mp4">您的瀏覽器不支持視頻播放。</video>**視頻鏈接:** {url}</div>'''# 返回最終的視頻顯示內容return {"result": video_html}
直接回復
這個也比較簡單,主要的目的就是文生圖、文生視頻、圖生視頻返回信息給客戶展示。
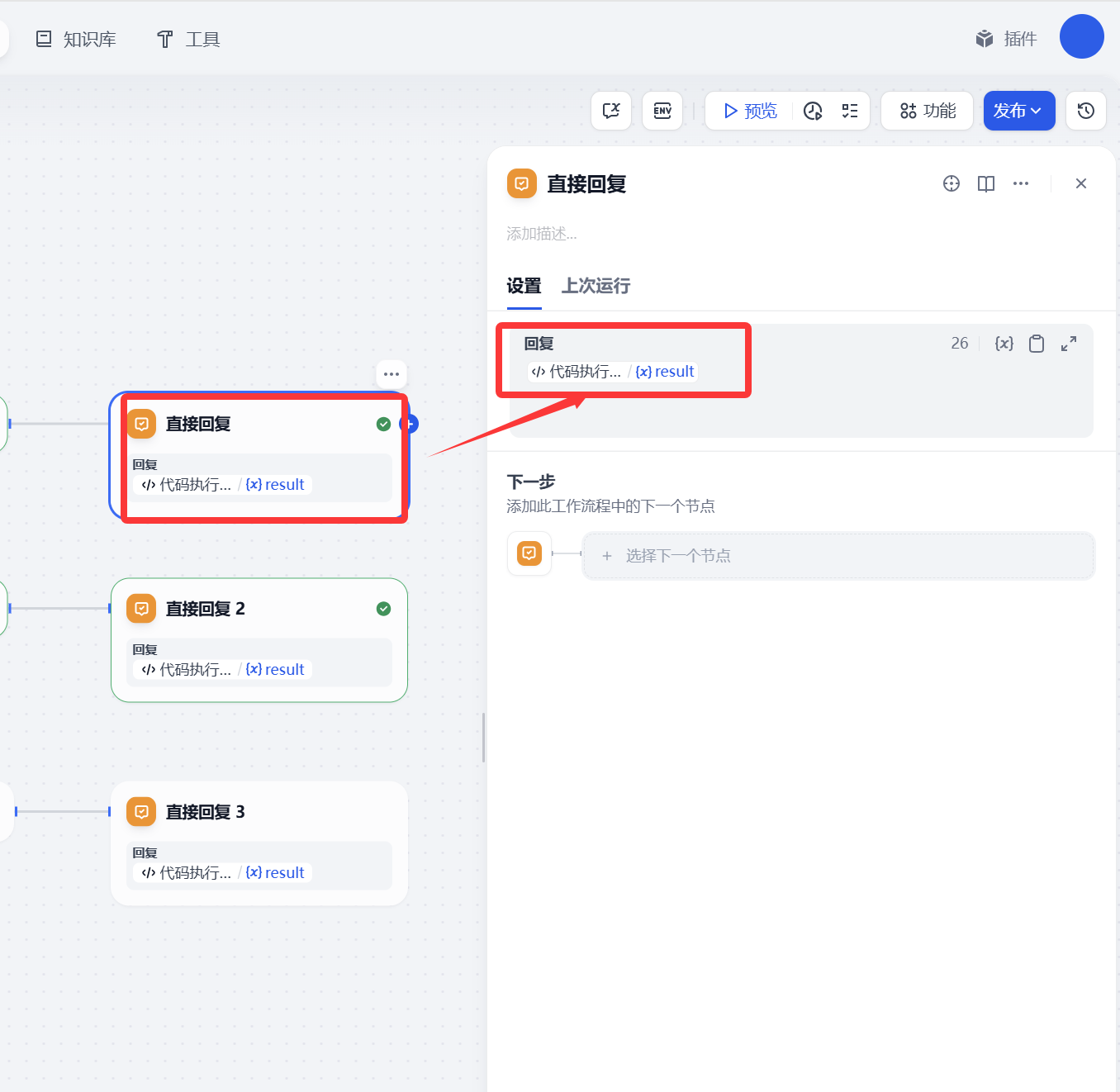
另外兩個配置和上面一樣這里就不做展開。
以上我們就完成了工作流的搭建,是不是比較簡單。
3.使用
提示詞:用戶填寫提示詞就可以了, 因為即夢AI 繪畫中文提示詞比較友好,這里就沒有用大模型做提示詞優化了。
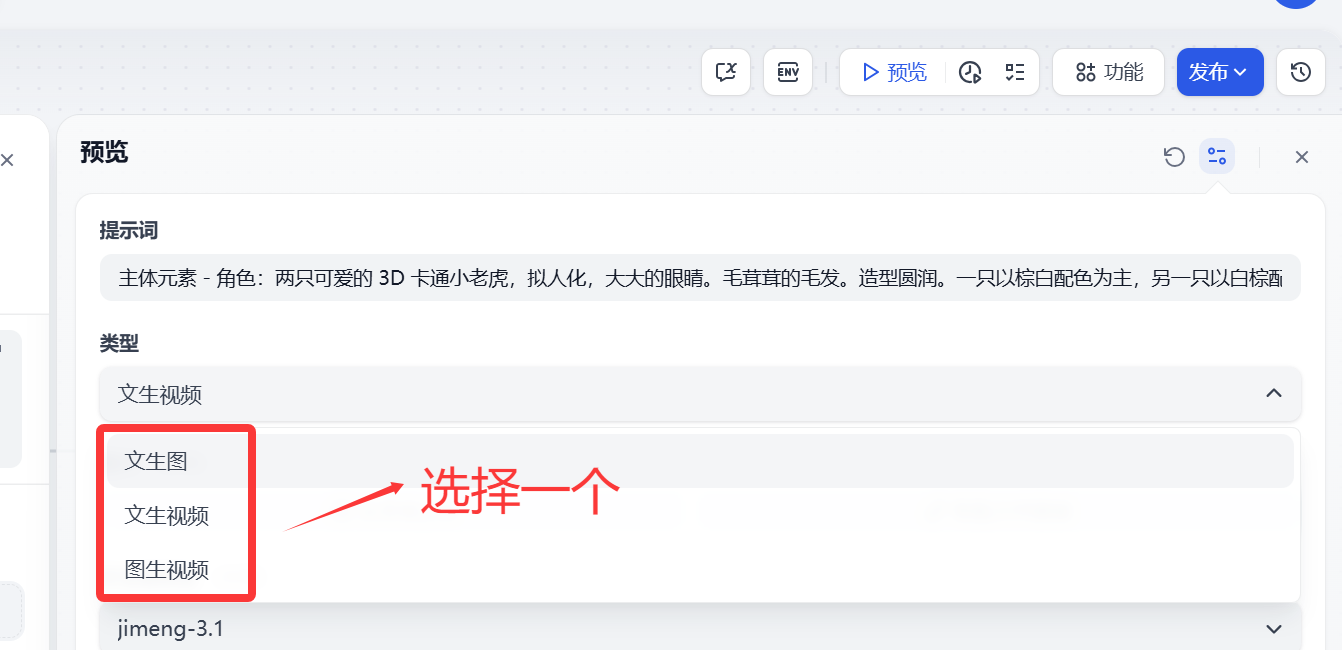
類型
這個類型下拉選項可以選擇(文生圖、文生視頻、圖生視頻)這個比較好理解,大家根據自己需要選擇一個就可以了。
圖片這里如果需要圖生圖的 就上傳,如果沒有用到這塊可以不用管。

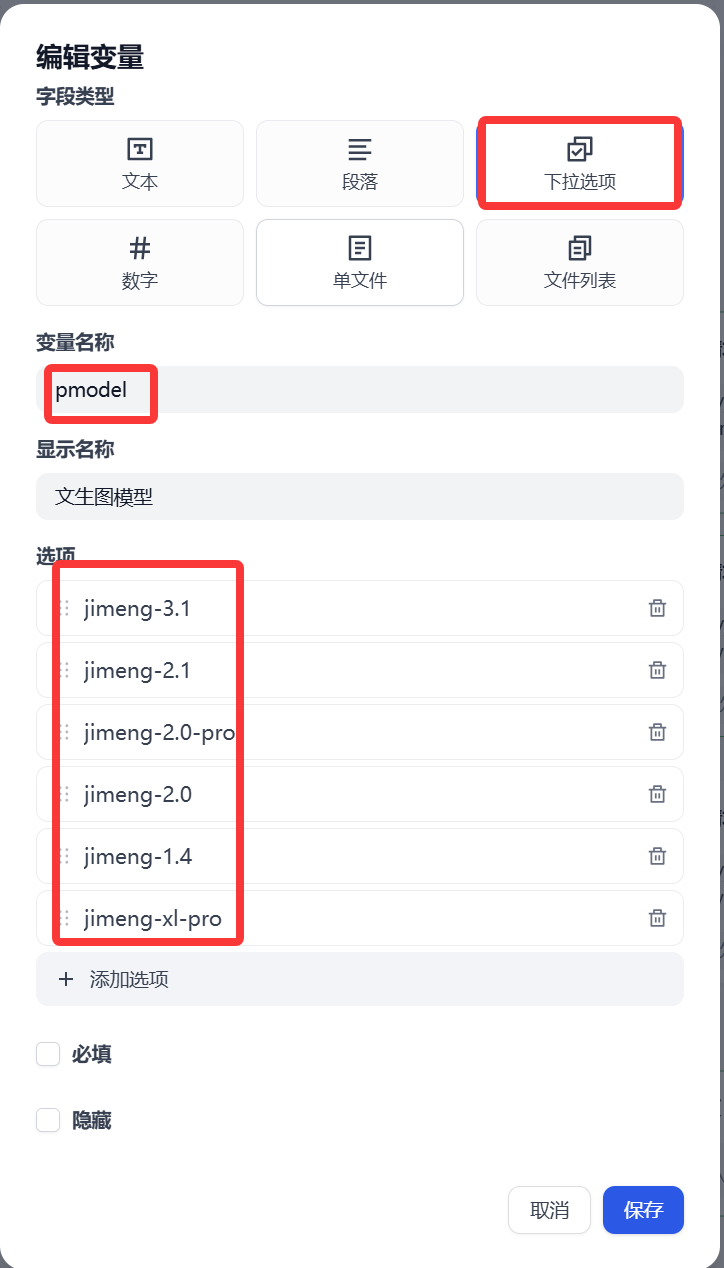
文生圖模型 提供即夢AI 平臺上主要的幾個模型(jimeng-3.1、jimeng-2.1、jimeng-2.0-pro、jimeng-2.0、jimeng-1.4、jimeng-xl-pro)
大家根據自己需要選擇模型,當然模型越新模型能力越強。默認可以選擇jimeng-3.1
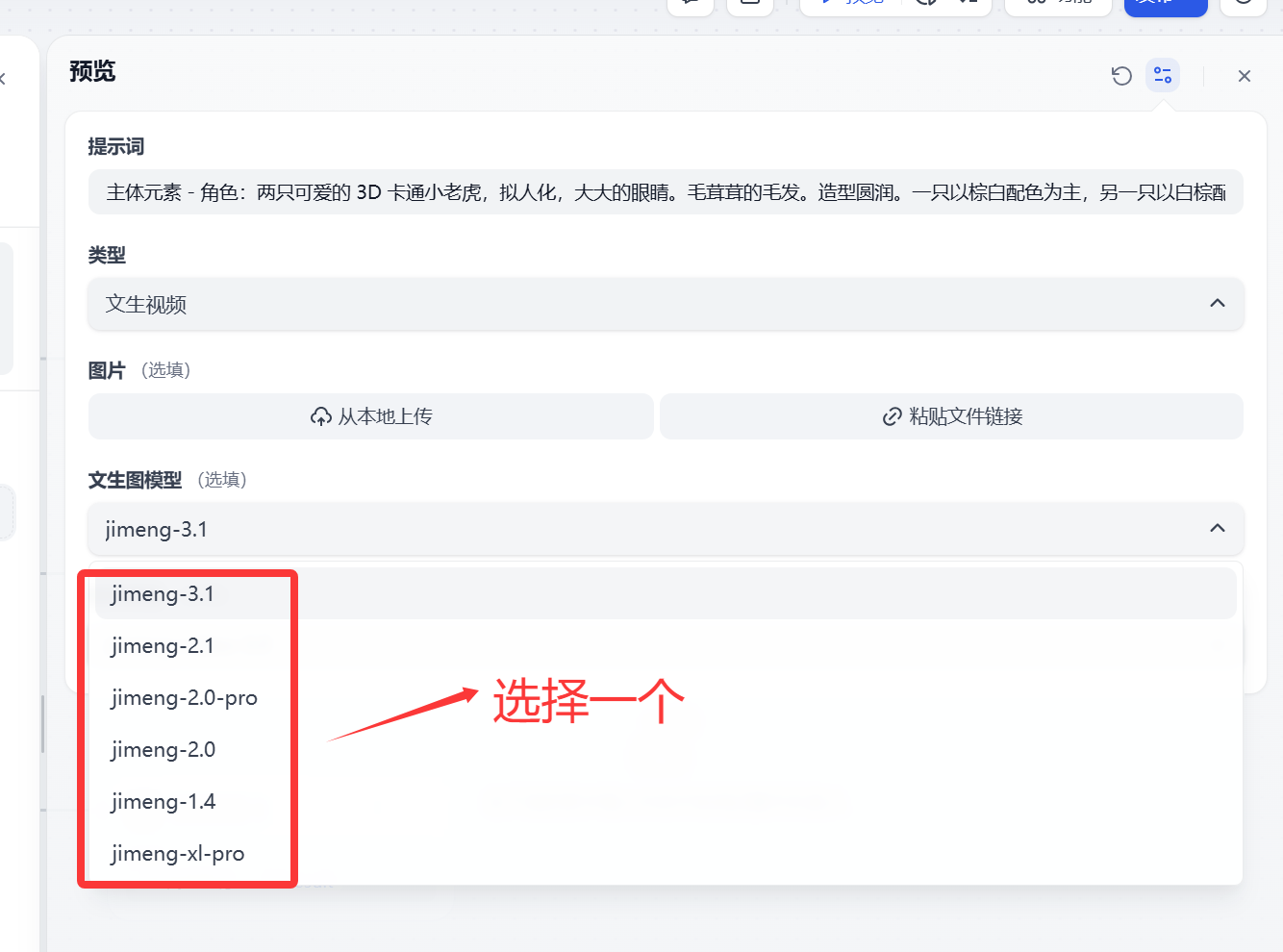
? 視頻模型 和上面類似,主要提供即夢AI 平臺上的視頻模型(jimeng-video-3.0、jimeng-video-2.0)
? 
? 這里有一個地方需要解釋下,如果大家對生成的視頻尺寸有要求,比如想要9:16 的 這里需要修改http請求的 width":1536 ,“height”:864。 我這里也有一個比較常見的配置說明:常用的文生圖、文生視頻比例提供如下三種
1:1 width:1024,height:1024
16:9 width:1536,height:864
9:16 width:864,height:1536
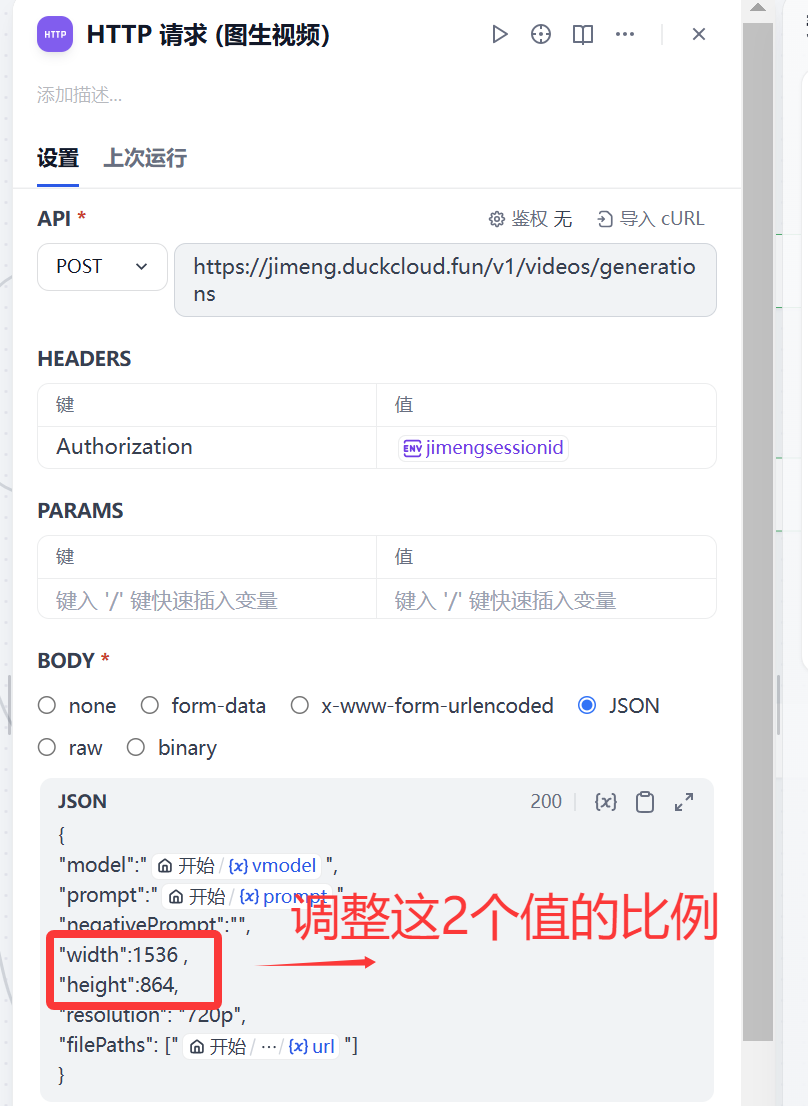
? 調整完成后 需要多工作流點擊保存并發布才能生效。
dify工作流體驗地址
工作流地址:https://dify.duckcloud.fun/chat/rx8PtSOwERUicTPx備用地址(http://14.103.204.132/chat/rx8PtSOwERUicTPx)
由于我賬號不是會員號,每天送80積分,文生圖每次消耗1積分。文生視頻消耗比較多3.0的視頻大概一次10積分,積分消耗完大家就等明天吧。
4.總結
今天主要帶大家了解并實現了基于 Dify 工作流構建即夢 AI 3.0 多模態生成系統的完整流程,該系統以即夢 AI 最新的文生圖 3.1 模型、視頻 3.0 模型為核心,結合 Dify 平臺的工作流邏輯和靈活的節點配置能力,形成了一套覆蓋文生圖、文生視頻及圖生視頻的全場景生成方案。
通過這套實踐方案,用戶能夠低成本體驗即夢 AI 的高級生成能力 —— 借助平臺每日贈送的免費積分,無需復雜的后端開發,就能快速生成具備影視質感的圖像和動作、鏡頭遵循能力優異的視頻,極大降低了 AI 創作的技術門檻和使用成本。在實際驗證中,該工作流能夠穩定響應不同類型的生成需求,無論是通過中文提示詞直接創作,還是上傳圖片進行二次視頻生成,都能產出符合預期的高質量內容,有效解決了普通用戶調用即夢最新模型流程繁瑣、專業參數配置復雜的問題。同時,工作流具備良好的擴展性 —— 小伙伴們可以基于此框架擴展更多實用功能,如短視頻平臺的批量素材生成、廣告創意的多版本快速迭代、教育場景的動態內容制作等,進一步豐富 Dify 平臺的多模態創作應用場景。
感興趣的小伙伴可以按照這份指南嘗試搭建自己的即夢 AI 生成工作流,甚至結合其他 AI 工具拓展更多創意玩法。今天的分享就到這里結束了,我們下一篇文章見。
)

Redis哨兵(Sentinel)是什么?)








 2022安裝教程與下載地址)

)
 的必會知識點匯總)




![[數據結構] ArrayList(順序表)與LinkedList(鏈表)](http://pic.xiahunao.cn/[數據結構] ArrayList(順序表)與LinkedList(鏈表))