1 Redis 簡介
1.1 Redis 是什么?
-
Redis 全稱 Remote Dictionary Server(遠程字典服務),是一個開源的高性能 Key-Value 數據庫;
-
官網:Redis - The Real-time Data Platform;
-
引用官網上的?個問答,帶你重新了解一下 Redis:

Redis 與其他鍵值存儲有何不同?
- 在鍵值數據庫領域,Redis 有著不同的發展路徑,其值可以包含更復雜的數據類型,并且針對這些數據類型定義了原子操作。Redis 的數據類型與基礎數據結構緊密相關,會直接向程序員暴露這些數據類型,沒有額外的抽象層。
- Redis 是一種基于內存但可持久化到磁盤的數據庫,因此它體現了一種不同的權衡:實現了極高的讀寫速度,但存在數據集不能超過內存大小的限制。內存數據庫的另一個優勢是,復雜數據結構在內存中的表示,與磁盤上的相同數據結構相比,操作起來要簡單得多,所以 Redis 可以用很少的內部復雜度實現很多功能。同時,兩種磁盤存儲格式(RDB 和 AOF)不需要支持隨機訪問,因此它們很緊湊,并且始終以只追加的方式生成(即使是 AOF 日志輪轉也是只追加操作,因為新版本是從內存中的數據副本生成的)。然而,與傳統的磁盤存儲系統相比,這種設計也帶來了不同的挑戰。由于內存是主要的數據表示形式,Redis 的操作必須謹慎處理,以確保磁盤上始終有數據集的更新版本。
-
官方定位:Redis 作用被定位為三個方面,即 Cache(緩存)、Database(數據庫)、Vector Search(向量搜索)。
1.2 2024年的Redis是什么樣的?
- 2023 年之前 Redis 是純粹的開源數據庫,近兩年來,它從單純的緩存產品,逐漸發展成一整套生態服務;
- Redis 產品:
- Redis Cloud:基于 AWS、Azure 等公有云的云服務,提供完整企業服務,還包含企業級收費產品 Redis Enterprise;
- Redis Enterprise Software:企業級軟件產品;
- Redis Enterprise for Kubernetes:面向 Kubernetes 環境的企業級產品;
- Redis Insight:Redis 官方推出的圖形化客戶端,用于 Redis 服務的安裝與管理,也可在 Redis Cloud 上直接使用,替代了以往的第三方客戶端;
- Redis OSS and Stack:在功能層面,形成了 Redis OSS(更完善的開源服務體系)和 Redis Stack(基于 Redis OSS 打造,用于 Redis Cloud 提供服務,在 Redis OSS 功能基礎上提供諸多高級擴展功能)兩套服務體系。
2 Redis 是單線程還是多線程?
-
整體來看,Redis 的整體線程模型可以簡單解釋為客戶端多線程,服務端單線程;
-
客戶端多線程:Redis 為了能夠與更多的客戶端進行連接,使用多線程來維護與客戶端的 Socket 連接。在
redis.conf中就有?個參數maxclients維護了最大客戶端連接數;# Redis is mostly single threaded, however there are certain threaded # operations such as UNLINK, slow I/O accesses and other things that are # performed on side threads. # # Now it is also possible to handle Redis clients socket reads and writes # in different I/O threads. Since especially writing is so slow, normally # Redis users use pipelining in order to speed up the Redis performances per # core, and spawn multiple instances in order to scale more. Using I/O # threads it is possible to easily speedup two times Redis without resorting # to pipelining nor sharding of the instance. # # By default threading is disabled, we suggest enabling it only in machines # that have at least 4 or more cores, leaving at least one spare core. # Using more than 8 threads is unlikely to help much. We also recommend using # threaded I/O only if you actually have performance problems, with Redis # instances being able to use a quite big percentage of CPU time, otherwise # there is no point in using this feature. # # So for instance if you have a four cores boxes, try to use 2 or 3 I/O # threads, if you have a 8 cores, try to use 6 threads. In order to # enable I/O threads use the following configuration directive: # # io-threads 4# Set the max number of connected clients at the same time. By default # this limit is set to 10000 clients, however if the Redis server is not # able to configure the process file limit to allow for the specified limit # the max number of allowed clients is set to the current file limit # minus 32 (as Redis reserves a few file descriptors for internal uses). # # Once the limit is reached Redis will close all the new connections sending # an error 'max number of clients reached'. # # IMPORTANT: When Redis Cluster is used, the max number of connections is also # shared with the cluster bus: every node in the cluster will use two # connections, one incoming and another outgoing. It is important to size the # limit accordingly in case of very large clusters. # # maxclients 10000Redis 主要采用單線程架構,但存在某些多線程操作,例如 UNLINK 命令、緩慢的 I/O 訪問以及其他在輔助線程中執行的任務。
現在還可以通過不同的 I/O 線程處理 Redis 客戶端套接字的讀取與寫入。由于寫入操作尤其緩慢,通常 Redis 用戶會采用管道技術(pipelining)來提升單核的 Redis 性能,并通過啟動多個實例來實現擴展。使用 I/O 線程技術,無需借助管道或實例分片即可輕松實現兩倍的性能提升。
默認情況下多線程處于禁用狀態,我們建議僅在至少擁有 4 個或更多核心的機器上啟用,并確保至少保留一個空閑核心。使用超過 8 個線程通常帶來的提升有限。我們同時建議僅在確實遇到性能問題時啟用多線程 I/O——即當 Redis 實例已占用較高 CPU 時間占比時,否則啟用此功能并無實際意義。
舉例而言:若您的設備為四核架構,可嘗試使用 2 至 3 個 I/O 線程;若為八核架構,可嘗試使用 6 個線程。如需啟用 I/O 線程,請使用以下配置指令:
io-threads 4
設置同一時間最大客戶端連接數。默認情況下該限制設為 10000 個客戶端,但如果 Redis 服務器無法將進程文件限制配置為滿足指定數值時,實際允許的最大客戶端數將調整為當前文件限制數減 32(因 Redis 需保留部分文件描述符供內部使用)。
當達到連接數上限后,Redis 將拒絕新連接并返回“達到最大客戶端數”錯誤信息。
重要提示:當使用 Redis 集群時,最大連接數同樣適用于集群總線——集群中的每個節點會使用兩個連接:一個入站連接和一個出站連接。在超大規模集群中,請務必據此相應調整連接數限制。
maxclients 10000
-
服務端單線程:
-
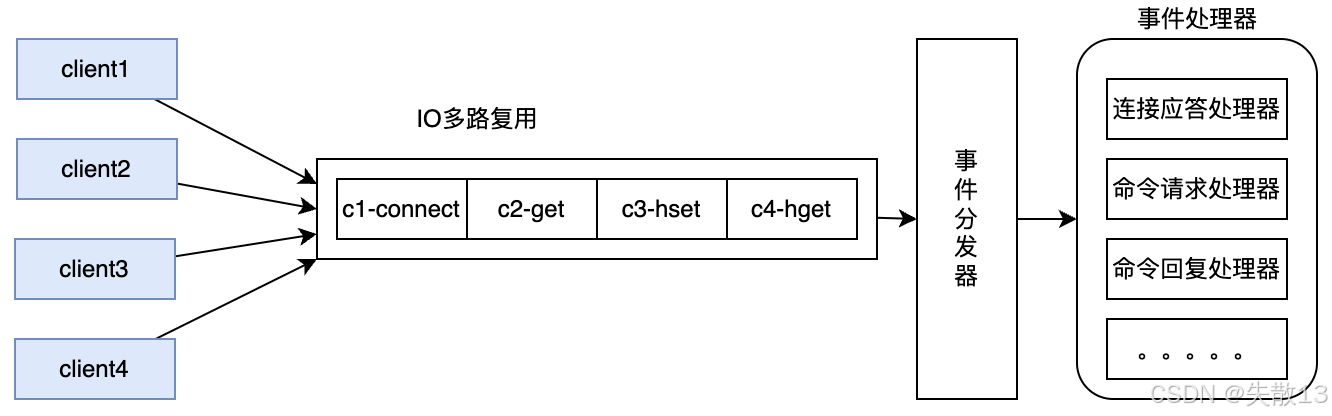
在服務端,Redis 響應網絡 IO 和鍵值對讀寫的請求,則是由單個主線程完成的。Redis 基于
epoll實現了 I/O 多路復用,這就可以讓?個主線程同時響應多個客戶端 Socket 連接的請求; -
在這種線程模型下,Redis 將客戶端多個并發的請求轉成了串行的執行方式。因此,在 Redis 中,完全不用考慮類似 MySQL 的臟讀、幻讀、不可重復讀等并發問題。同時,串行化線程模型結合 Redis 基于內存工作的極高性能,使其成為解決諸多并發問題的有力工具;
-
-
版本演進帶來的線程模型變化
-
Redis 4.X 以前:采用純單線程模型;
-
Redis 5.x 及之后:進行了大的核心代碼重構,使用一種全新的多線程機制以提升后臺工作效率。像持久化(如 RDB、AOF 重寫)、集群數據同步等較費時的操作,以及 FLUSHALL(可通過
FLUSHALL [ASYNC | SYNC]選擇異步或同步執行)這類操作,都由額外線程執行,避免了對主線程的影響;
-
-
Redis 為什么要使用全新的多線程機制呢?
- 現代 CPU 多為多核架構,若 Redis 一直用單線程,就無法發揮多核 CPU 的性能優勢,且耗時操作會影響主線程;
- 不過,Redis 為保持快速,多線程推進很謹慎,核心線程仍保持單線程模型,因為對于現代 Redis,CPU 通常不是性能瓶頸,性能瓶頸多為內存和網絡;
- 另外,Redis 的這種核心線程以單線程為主的機制,還可減少線程上下文切換的性能消耗,若核心線程改為多線程并發執行,會帶來資源競爭,大幅增加業務復雜性,影響執行效率;
-
總結:
- 對于現在的 Redis,并不是簡單的單線程或多線程,而是一種混合線程模型,核心邏輯始終保持單線程,多線程僅用于輔助功能;
- 核心流程始終保持單線程:Redis的鍵值對讀寫、命令執行(如GET/SET)等核心操作,無論哪個版本,始終由單個主線程串行執行。這也是 Redis 避免并發安全問題、保持高性能的關鍵——不需要加鎖,也沒有線程切換開銷;
- **多線程僅用于輔助功能:**版本演進中引入的多線程,從未觸及核心命令執行邏輯,而是負責:
- 網絡I/O的讀寫(Redis 6.0+可配置I/O多線程);
- 耗時的后臺操作(如RDB生成、AOF重寫、UNLINK異步刪除);
- 集群數據同步等非核心流程。
3 Redis 如何保證指令原子性
-
Redis 對于核心的讀寫鍵值操作是單線程處理的。當多個客戶端同時發起讀寫請求時,Redis 會讓這些請求排隊串行執行。但要注意,這種串行執行是針對多個客戶端之間的請求而言,Redis 并沒有像 MySQL 那樣,專門去保證單個客戶端自身操作的原子性;
-
來看一個例子:
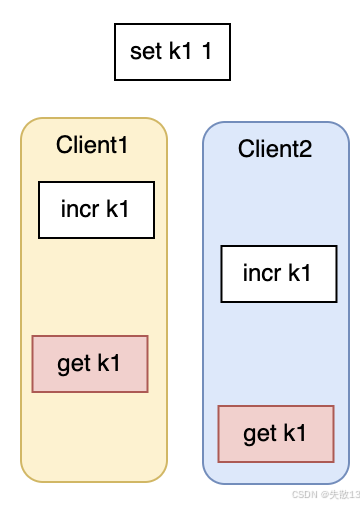
- 初始有
set k1 1操作將k1的值設為 1; - 然后
Client1和Client2都執行incr k1(incr是將鍵值加 1 的操作),之后又都執行get k1獲取k1的值; - 由于 Redis 單線程處理多個客戶端請求,
Client1和Client2的incr k1操作會串行執行,但因為沒有針對單個客戶端操作的原子性保障,最終get k1得到的值可能不符合預期(比如可能不是預期的 3,具體結果取決于兩個incr操作的執行順序等因素);
- 初始有
-
如何控制 Redis 指令的原子性是一個需要關注的問題。在不同的業務場景下,Redis 提供了不同的解決思路,我們需要根據項目實際情況靈活選擇合適的方式來保證指令執行的原子性,以滿足業務需求。
3.1 復合指令
- Redis 內部提供了諸多復合指令,這類指令看似是一個指令,但實際上能完成多個指令的工作;
- 例如:
MSET(用于同時設置多個鍵值對)HMSET(用于同時設置哈希表中的多個字段值)GETSET(先獲取鍵的舊值,再設置新值)SETNX(只有鍵不存在時才設置值)SETEX(設置鍵值的同時指定過期時間)等
- 這些復合指令能夠很好地保持原子性,也就是說,這些復合指令的執行過程是不可分割的,在執行過程中不會被其他客戶端的指令插入或打斷,從而保證了操作的完整性和一致性。
3.2 Redis 事務
3.2.1 簡介
-
官網:Transactions | Docs;
-
基本命令:
MULTI(開啟事務)、EXEC(執行事務)、DISCARD(放棄事務)、WATCH(監聽某個或多個 key,若 key 被修改,事務執行會失敗)、UNWATCH(去掉監聽,僅在當前客戶端有效); -
例:在 Redis 命令行中執行
MULTI set k2 2 incr k2 get k2 EXEC DISCARD -
但是,Redis 的事務和 MySQL 的事務,是不是同?回事呢?看下面這個例子:
MULTI set k2 2 incr k2 get k2 lpop k2 # lpop指令是針對List的操作,此處針對String類型的k2操作,肯定會報錯 incr k2 get k2 EXEC- 結果雖然會報錯:
WRONGTYPE Operation against a key holding the wrong kind of value; - 但是這行錯誤的指令并沒有讓整個事務回滾,甚至后面的指令都沒有受到影響;
- 所以:Redis 事務并不像數據庫事務那樣保證事務中的指令一起成功或一起失敗。Redis 事務的作用,僅僅只是保證事務中的原子操作是?起執行,而不會在執行過程中被其他指令加塞;
事實上,在執行
MULTI開啟事務后,后續輸入的指令,都會返回 QUEUED,表示 Redis 將這些操作排好了隊,等到EXEC后一起執行。 - 結果雖然會報錯:
3.2.2 Watch 機制
-
Redis 通過這個機制保證在事務執行前,被監聽的 key 不被修改。若執行事務前 key 被修改,事務會執行失敗;
-
看下面的例子:
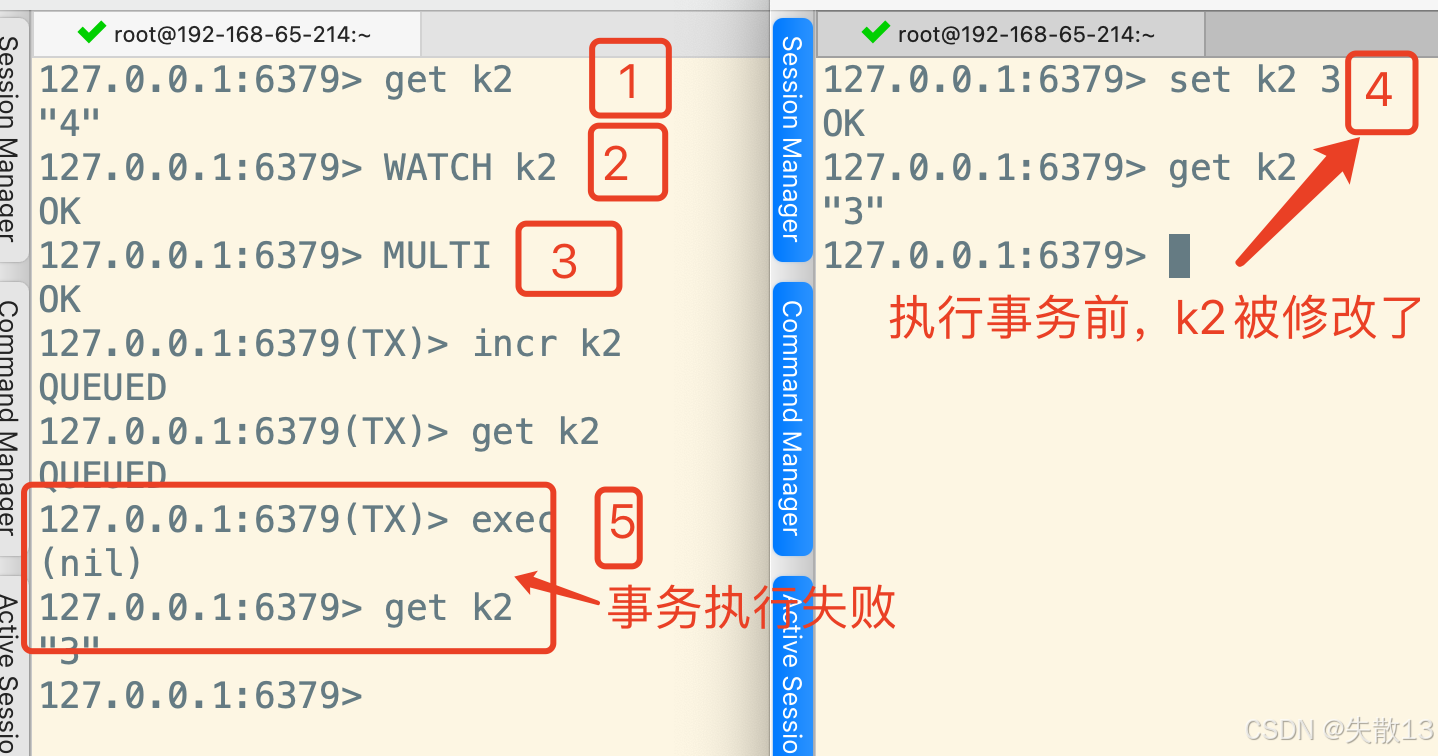
- 左側客戶端先獲取
k2的值,然后用WATCH k2監聽k2,接著開啟事務(MULTI),在事務里對k2進行自增(incr k2)和獲取操作,最后執行事務(EXEC); - 右側客戶端在左側客戶端執行事務前,修改了
k2的值(set k2 3); - 當左側客戶端執行
EXEC時,因為k2被右側客戶端修改了,所以事務執行失敗(返回(nil));
- 左側客戶端先獲取
-
可以用
UNWATCH命令取消對 key 的監聽,但它只在當前客戶端有效;- 左側客戶端同樣先獲取
k2、WATCH k2、開啟事務并進行操作; - 右側客戶端執行
UNWATCH,然后修改k2的值(set k2 3); - 左側客戶端執行
EXEC時,事務還是失敗了。這是因為UNWATCH是在右側客戶端執行的,而UNWATCH只在當前客戶端有效,所以右側的UNWATCH無法取消左側客戶端對k2的監聽,左側客戶端對k2的監聽仍然存在,k2被修改后事務就失敗了; - 只有在左側客戶端步驟 3(
MULTI之前)執行UNWATCH,才能取消左側客戶端對k2的監聽,讓后續事務可能執行成功;在右側客戶端執行UNWATCH是無效的;
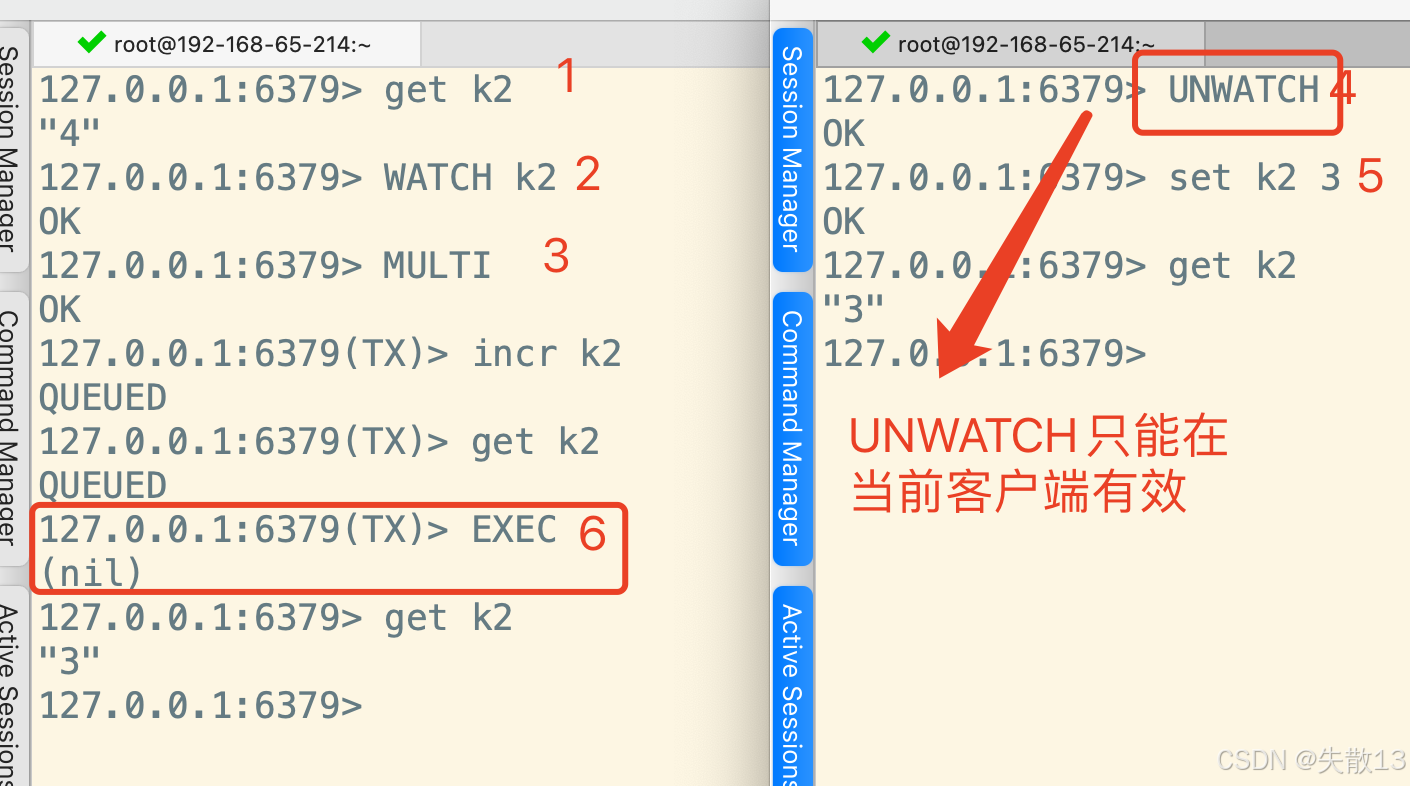
- 左側客戶端同樣先獲取
3.2.3 Redis 事務失敗如何回滾
- Redis 中的事務回滾,不是回滾數據,而是回滾操作;
- 若事務在
EXEC執行前失敗(如指令錯誤、參數不對),整個事務的操作都不會執行; - 若事務在
EXEC執行后失敗(如操作的 key 類型不對),事務中的其他操作會正常執行,不受影響。
3.3.3 事務執行過程中出現失敗了怎么辦?
- 只要客戶端執行了
EXEC指令,即便之后客戶端連接斷開,事務也會一直進行下去; EXEC執行后,Redis 先將事務操作記錄到 AOF 文件,再執行操作。若 Reids 服務出現異常(如崩潰、被 kill),可能導致 AOF 記錄與數據不符。此時需用redis - check - aof工具修復 AOF 文件,移除不完整事務操作記錄,使服務能正常啟動。
3.3 Pipeline
-
官網:Redis pipelining | Docs;
-
Pipeline 是 Redis 提供的一種機制,能讓客戶端把多個命令打包,一次性發送給服務器,服務器執行后再將結果批量返回給客戶端。這種方式適合大批量數據快速寫入 Redis 的場景;
-
通過
redis - cli -- pipe相關指令可使用該功能,-- pipe - timeout還能設置管道模式下的超時時間; -
使用案例
-
先在 Linux 上編輯一個 txt 文件,里面包含一系列 Redis 指令;
-
然后通過
cat command.txt | redis - cli - a 密碼 -- pipe這樣的命令,讓 Redis 執行文件里的所有指令;
-
-
核心作用:優化 RTT
-
RTT(Round - Trip Time,往返時間)指客戶端發送指令到服務器,再到服務器返回結果給客戶端的時間消耗;
-
沒有 Pipeline 時,每個命令都要經歷一次 RTT,頻繁發指令的話,RTT 消耗會很可觀;
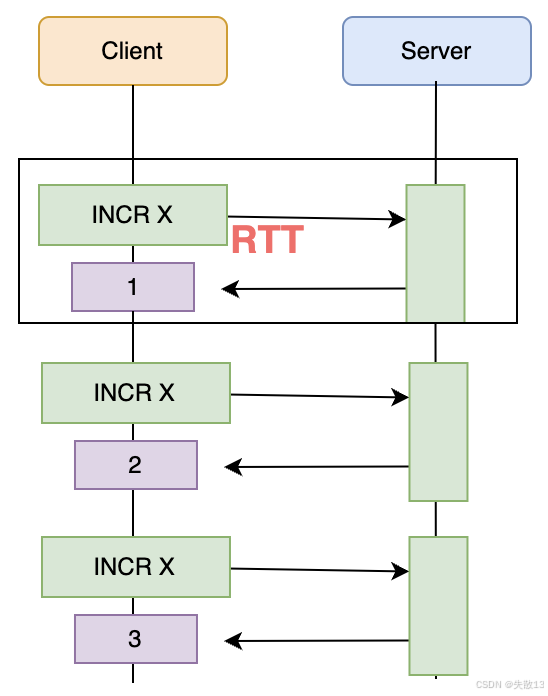
-
有 Pipeline 時,多個命令打包發送,只需少量的 RTT(甚至一次),大大減少了因多次網絡往返帶來的時間開銷,提升了執行效率;
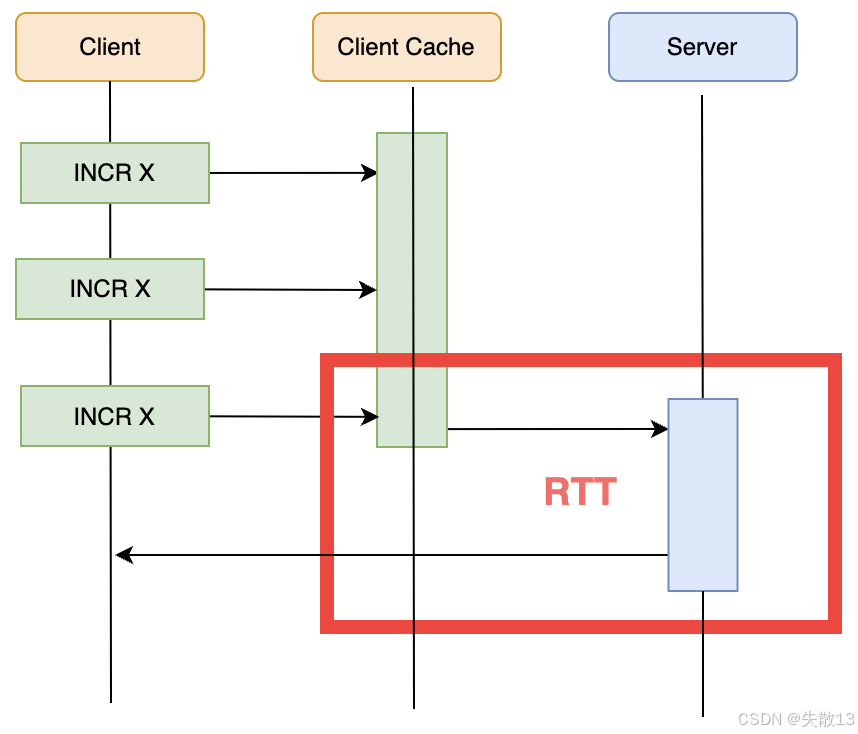
-
-
注意點
-
原子性:Redis 的事務(Transaction)是原子性的,但 Pipeline 不具備原子性。Pipeline 只是把多條命令批量發送導服務端,這些命令最終可能會被其他客戶端的指令“加塞”(不過這種概率通常較小),所以不建議在 Pipeline 中進行復雜的數據操作,因為數據一致性難以保證;
-
客戶端阻塞與資源占用:
- Pipeline 執行時,會阻塞當前客戶端,直到服務器返回所有結果;
- 如果 Pipeline 中封裝過多指令,一方面客戶端阻塞時間會太長;另一方面,服務器要回復這個“繁忙”的客戶端,會占用很多內存;
-
適用場景:Pipeline 適合在非熱點時段進行數據調整任務,這樣既利用了它提升效率的優勢,又能避免在熱點時段因客戶端阻塞、服務器內存占用過多等問題,對正常業務造成影響。
-
3.4 Lua 腳本
- Redis 的事務和 Pipeline 機制在解決指令原子性等問題上有局限,且只能對現有指令拼湊,無法添加更多自定義復雜邏輯。而 Lua 腳本能彌補這些不足,所以 Redis 支持 Lua,且從 2.6.0 版本就開始支持,Redis 7.x 版本支持的 Lua 語言是 5.1 版本。
3.4.1 簡介
-
Lua 是一種小巧的腳本語言,具備參數類型、作用域、函數等高級語言特性,語法簡單,熟悉 Java 等語言的開發者能輕松上手;
如果對 Lua 原生的語法感興趣,推薦?個參考?站:LuatOS 文檔。這個網站可以直接在線調試 Lua;
-
Lua 語言最大的特點是他的線程模型是單線程的模式。這使得 Lua 天生就非常適合?些單線程模型的中間件。比如 Redis、Nginx 等都非常適合接入 Lua 語言進行功能定制。所以,在 Redis 中執行一段 Lua 腳本,這個過程天然就是原子性的。
3.4.2 Redis 中執行 Lua 的方式
-
Redis 對 Lua 語言的 API 介紹參考官網:Redis Lua API reference | Docs;
-
通過
EVAL指令執行 Lua 腳本,語法為EVAL script numkeys [key key ...] [arg arg ...]-
script:要執行的 Lua 腳本程序,會被運行在 Redis 服務器上下文中; -
numkeys:指定鍵名參數的個數; -
key [key ...]:腳本中用到的 Redis 鍵,可在 Lua 中通過全局變量KEYS數組(以 1 為基址)訪問,如KEYS[1]、KEYS[2]等; -
arg [arg ...]:非鍵名的附加參數,可在 Lua 中通過全局變量ARGV數組訪問,如ARGV[1]、ARGV[2]等;
-
-
例:返回一個包含 4 個元素的數組
EVAL "return {KEYS[1], KEYS[2], ARGV[1], ARGV[2]}" 2 key1 key2 first secondKEYS[1]:第一個鍵名參數KEYS[2]:第二個鍵名參數ARGV[1]:第一個附加參數ARGV[2]:第二個附加參數2:numkeys參數,表示后續有 2 個鍵名參數(key1和key2);key1 key2:鍵名參數(通過 Lua 中的KEYS數組訪問);first second:非鍵名的附加參數(通過 Lua 中的ARGV數組訪問);
-
在 Lua 腳本中可使用
redis.call函數調用 Redis 命令,例:redis.call('get', KEYS[1]) # 獲取鍵值 redis.call('set', KEYS[1], 10) # 設置鍵值 -
使用 Lua 的注意點:
-
避免死循環和耗時運算:若 Lua 腳本中出現死循環或耗時運算,Redis 會阻塞,不再接受其他命令。不過 Redis 有配置參數控制 Lua 腳本的最長執行時間(默認 5 秒),超過時長 Redis 會返回
BUSY錯誤,避免一直阻塞;################ NON-DETERMINISTIC LONG BLOCKING COMMANDS ###################### Maximum time in milliseconds for EVAL scripts, functions and in some cases # modules' commands before Redis can start processing or rejecting other clients. # # If the maximum execution time is reached Redis will start to reply to most # commands with a BUSY error. # # In this state Redis will only allow a handful of commands to be executed. # For instance, SCRIPT KILL, FUNCTION KILL, SHUTDOWN NOSAVE and possibly some # module specific 'allow-busy' commands. # # SCRIPT KILL and FUNCTION KILL will only be able to stop a script that did not # yet call any write commands, so SHUTDOWN NOSAVE may be the only way to stop # the server in the case a write command was already issued by the script when # the user doesn't want to wait for the natural termination of the script. # # The default is 5 seconds. It is possible to set it to 0 or a negative value # to disable this mechanism (uninterrupted execution). Note that in the past # this config had a different name, which is now an alias, so both of these do # the same: # lua-time-limit 5000 # busy-reply-threshold 5000################ 非確定性長阻塞命令 #####################
對于 EVAL 腳本、函數以及某些情況下模塊命令的最長執行時間(毫秒),超過該時限后 Redis 將開始處理或拒絕其他客戶端請求。
當達到最大執行時間時,Redis 將開始對大多數命令返回 BUSY 錯誤響應。
在此狀態下,Redis 僅允許執行少量特定命令。
例如:SCRIPT KILL(終止腳本)、FUNCTION KILL(終止函數)、SHUTDOWN NOSAVE(強制關閉)以及某些模塊特定的’allow-busy’(允許繁忙狀態執行)命令。
SCRIPT KILL 和 FUNCTION KILL 僅能終止尚未執行任何寫入命令的腳本,因此當腳本已執行寫入命令且用戶不愿等待腳本自然終止時,SHUTDOWN NOSAVE 可能是停止服務器的唯一方式。
默認限制為 5 秒。可設置為 0 或負值以禁用此機制(實現無中斷執行)。請注意,該配置舊名稱現已作為別名保留,因此以下兩種配置方式等效:
lua-time-limit 5000
busy-reply-threshold 5000
-
盡量使用只讀腳本:只讀腳本是 Redis 7 新增的,通過
EVAL_RO觸發,腳本上要加只讀標志,且不允許執行修改數據庫的操作,還可隨時用SCRIPT_KILL命令停止。使用只讀腳本,一方面能限制部分用戶操作;另一方面,只讀腳本通常可轉移到備份節點執行,減輕 Redis 主節點壓力; -
熱點腳本緩存到服務端:可將熱點 Lua 腳本緩存到 Redis 服務端,提升執行效率;
# 將 Lua 腳本 "return 'Immabe a cached script'" 加載到 Redis 服務器中 redis> SCRIPT LOAD "return 'Immabe a cached script'" # 返回一個 SHA1 哈希值 c664a3bf70bd1d45c4284ffebb65a6f2299bfc9f "c664a3bf70bd1d45c4284ffebb65a6f2299bfc9f" # 使用之前生成的 SHA1 哈希值來執行緩存的腳本,0 表示腳本不需要任何鍵(KEY)參數 redis> EVALSHA c664a3bf70bd1d45c4284ffebb65a6f2299bfc9f 0 # 返回腳本執行結果 "Immabe a cached script"
-
3.5 Redis Function
-
簡介:
- 如果你覺得開發 Lua 腳本有點困難,那么在 Redis 7 之后,提供了另外?種讓程序員解脫的方法:Redis Function;
- Redis Function 是 Redis 7 及以后版本提供的功能,能將一些功能聲明為統一的函數,提前加載到 Redis 服務端(可由熟悉 Redis 的管理員加載)。客戶端可直接調用這些函數,無需再開發函數的具體實現;
- 它的一大優勢是在 Function 中可以嵌套調用其他 Function,更利于代碼復用,而 Lua 腳本難以實現這樣的復用;
-
例:
-
首先在服務器上新增一個
mylib.lua文件,在文件中定義函數。該文件的第一行必須寫:#!lua name=mylib,用于指定函數的命名空間,這不是注釋,且這一步不能少。文件內容如下:- 定義了
my_hset函數,該函數接收keys和args參數; - 獲取第一個鍵名
hash,調用redis.call('TIME')獲取時間,然后調用HSET命令,設置哈希表的_last_modified_字段為當前時間,再設置其他由args傳遞的字段; - 最后用
redis.register_function('my_hset', my_hset)注冊函數;
#!lua name=myliblocal function my_hset(keys, args)local hash = keys[1]local time = redis.call('TIME')[1]return redis.call('HSET', hash, '_last_modified_', time, unpack(args)) endredis.register_function('my_hset', my_hset) - 定義了
-
然后使用 Redis 客戶端,通過
cat mylib.lua | redis-cli -a 123qweasd -- FUNCTION LOAD REPLACE命令,將這個函數加載到 Redis 中; -
加載后,其他客戶端就可以直接調用這個函數,調用方式和 Lua 腳本類似,比如
FCALL my_hset 1 myhash myfield "some value",其中1是鍵名參數的個數,myhash是鍵名,myfield和"some value"是參數;
-
-
Function 注意點
-
只讀調用:Function 同樣可以進行只讀調用;
-
集群使用:如果在集群中使用 Function,目前版本需要在各個節點都手動加載一次,Redis 不會在集群中進行 Function 同步;
-
服務端緩存:Function 是要在服務端緩存的,所以不建議使用太多太大的 Function,否則會占用過多服務端資源;
-
管理指令:Function 和 Script 一樣,也有一系列的管理指令,可使用
help @scripting指令自行了解。
-
3.6 總結
- 以上介紹的各種機制,其實都是 Redis 改變指令執行順序的方式。在這幾種?具中,Lua 腳本通常會是項目中用得最多的方式。在很多追求極致性能的高并發場景,Lua 腳本都會擔任很重要的角色。但是其他的各種方式也需要有了解,這樣在面臨真實的業務場景時,才有更多的方案可以選擇。
4 Redis 中的 Bigkey 問題
-
Bigkey 指占用空間非常大的鍵。比如一個 List 類型的鍵包含 200 萬個元素,或者一個 String 類型的鍵存儲了一篇文章這樣大量的數據;
-
基于 Redis 以單線程為主的核心工作機制,Bigkey 非常容易造成 Redis 服務阻塞。因為 Redis 單線程處理命令時,操作 Bigkey(如讀取、刪除等)會耗費大量時間,在此期間,其他命令會被阻塞,無法得到及時處理,進而影響整個 Redis 服務的性能;
-
在 Redis 客戶端指令中,提供了兩個擴展參數來幫助快速發現 Bigkey:
-
--bigkeys:用于抽樣 Redis 鍵,尋找包含大量元素(具有高復雜性)的鍵; -
--memkeys:用于抽樣 Redis 鍵,尋找占用大量內存的鍵;
-
-
對于 BigKey 的處理,后續會介紹。
5 總結
-
Redis 整體是多線程的,但后臺執行指令的核心線程是單線程,整個線程模型以單線程為主。這就導致不同客戶端的各種指令需要依次排隊執行,并非并行處理;
-
Redis 這種以單線程為主的線程模型,相比其他中間件,結構非常簡單。這使得 Redis 處理線程并發問題時,更加簡單高效。在很多復雜業務場景下,Redis 能成為進行線程并發控制的良好工具。
-
單線程模型的局限性與應對
-
局限性:單線程模型本身不利于發揮多線程的并發優勢,而 Redis 的應用場景又通常和高性能深度綁定;
-
應對方式:在使用 Redis 時,要時刻思考指令的執行方式,選擇合理的指令執行方式,這樣才能最大限度發揮 Redis 高性能的優勢,避免因線程模型的局限而影響性能。同時,這也說明 Redis 并非沒有線程并發問題,合理的指令執行方式至關重要。
-






)

Redis哨兵(Sentinel)是什么?)








 2022安裝教程與下載地址)

)