Week 1
1.1 K-means?
Cluster centroid
- K-means 是無監督學習中聚類算法的一種,核心在于更新聚類質心;
- 首先將每個點分配給幾個聚類質心,取決于那些點離哪個質心更近;然后將幾個聚類質心移動到分配給他的所有點的平均值,不斷重復,直到沒有點更改類別;
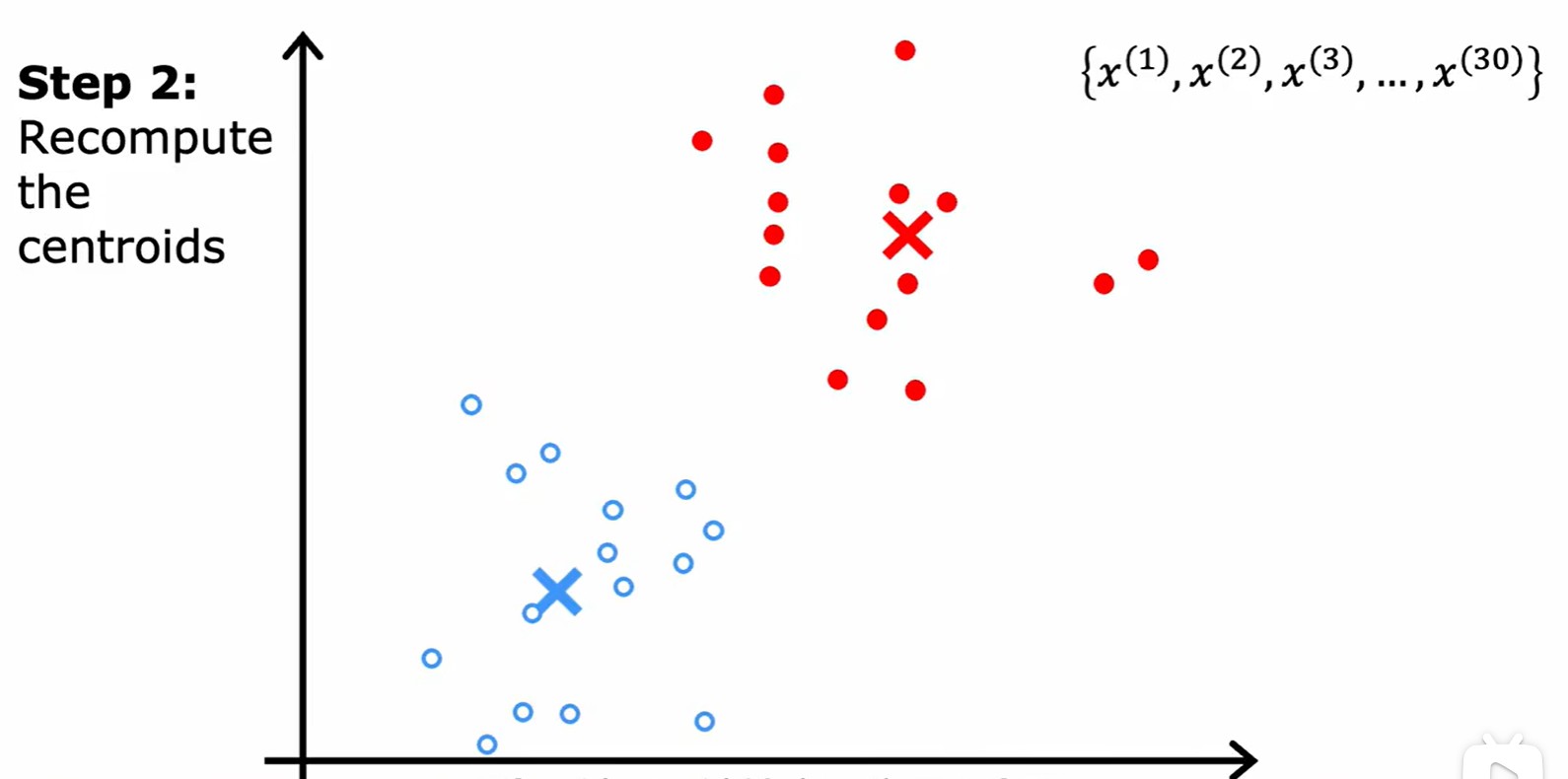
K-means algorithm
- 如果一個簇里面沒有點分配給他,最常見的方法就是消除一個簇;
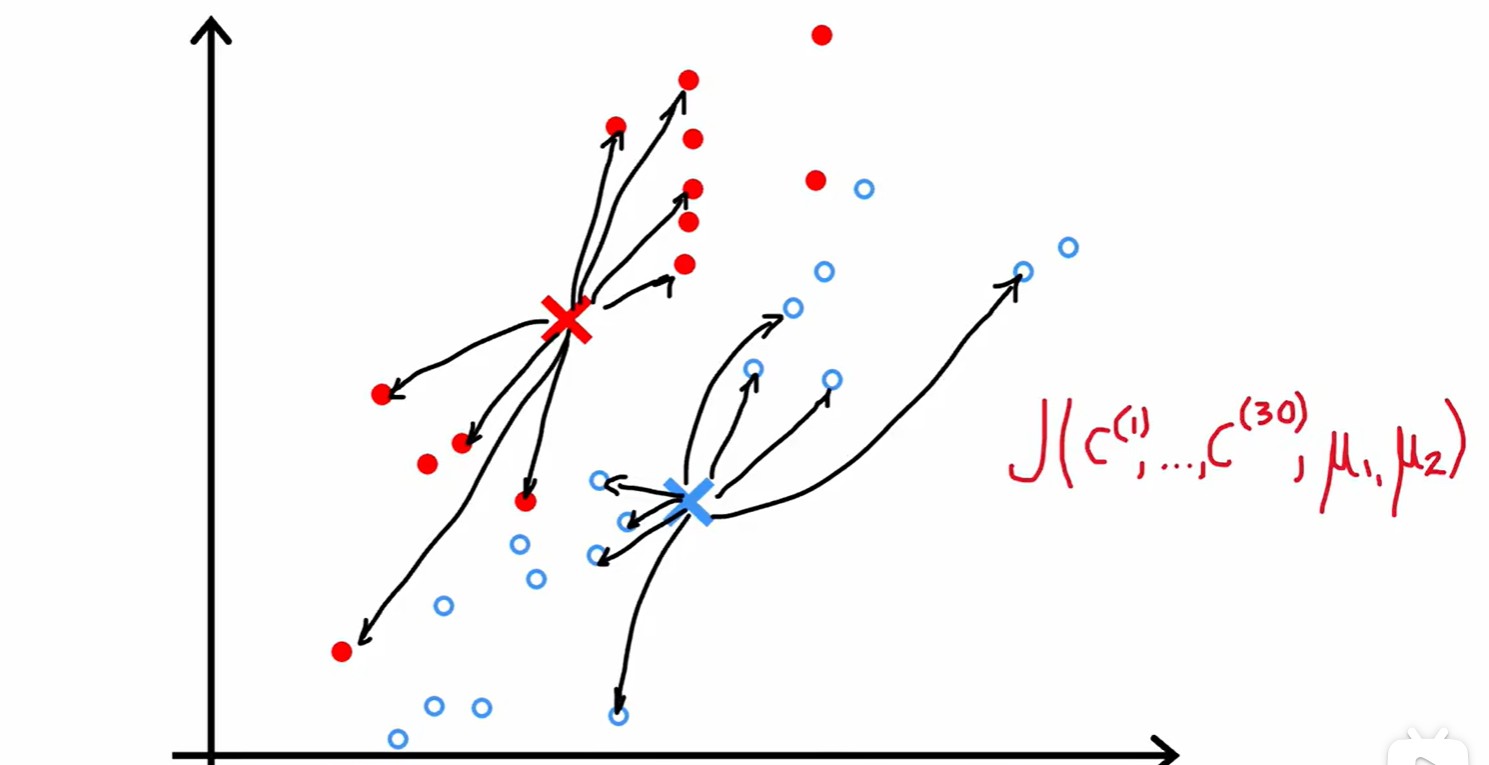
- 總的來說,減少?cost 的兩步:就近分配中心點,中心點移動到平均點;
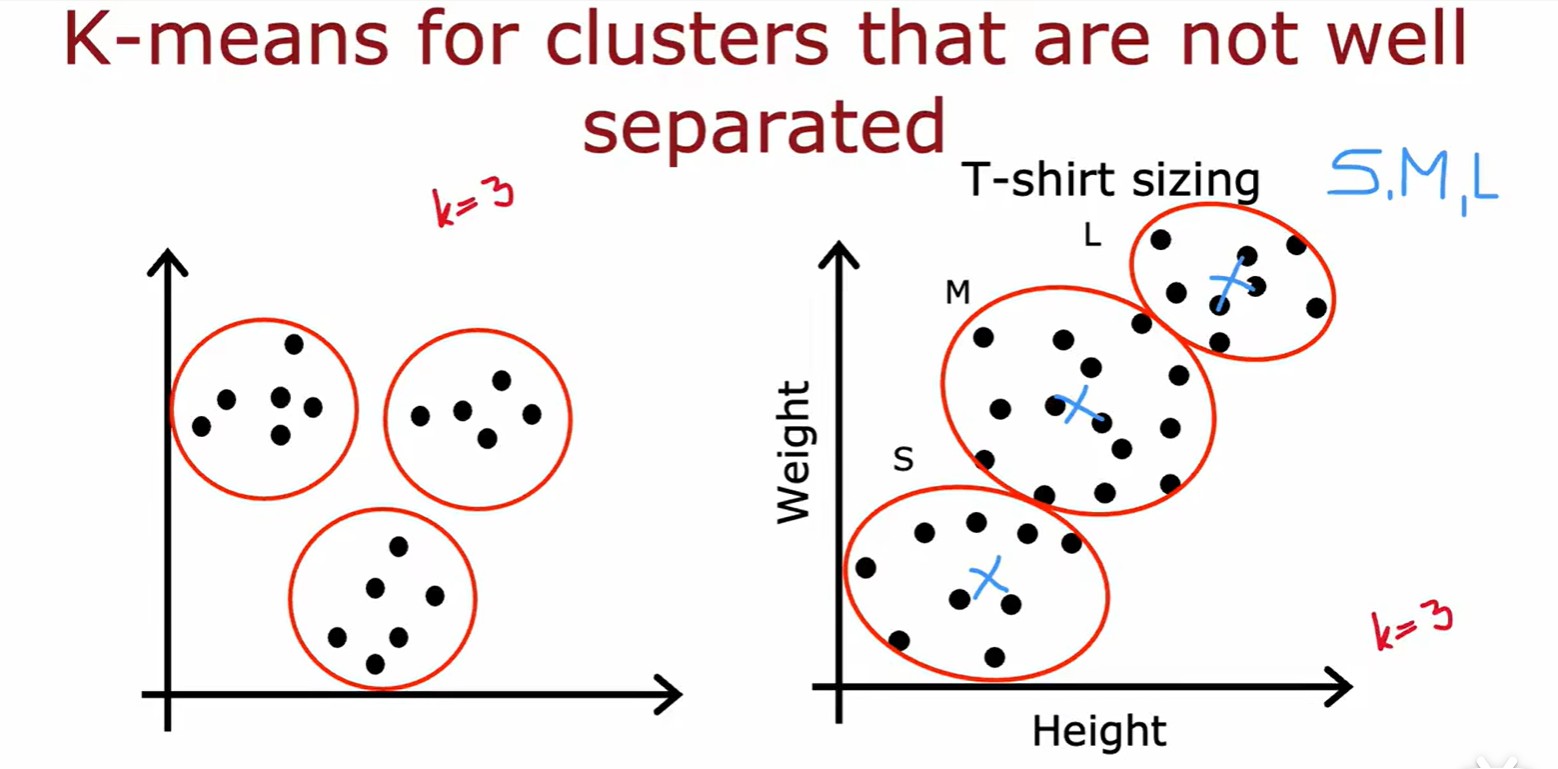
- 對于沒有很好分離的樣本族群:
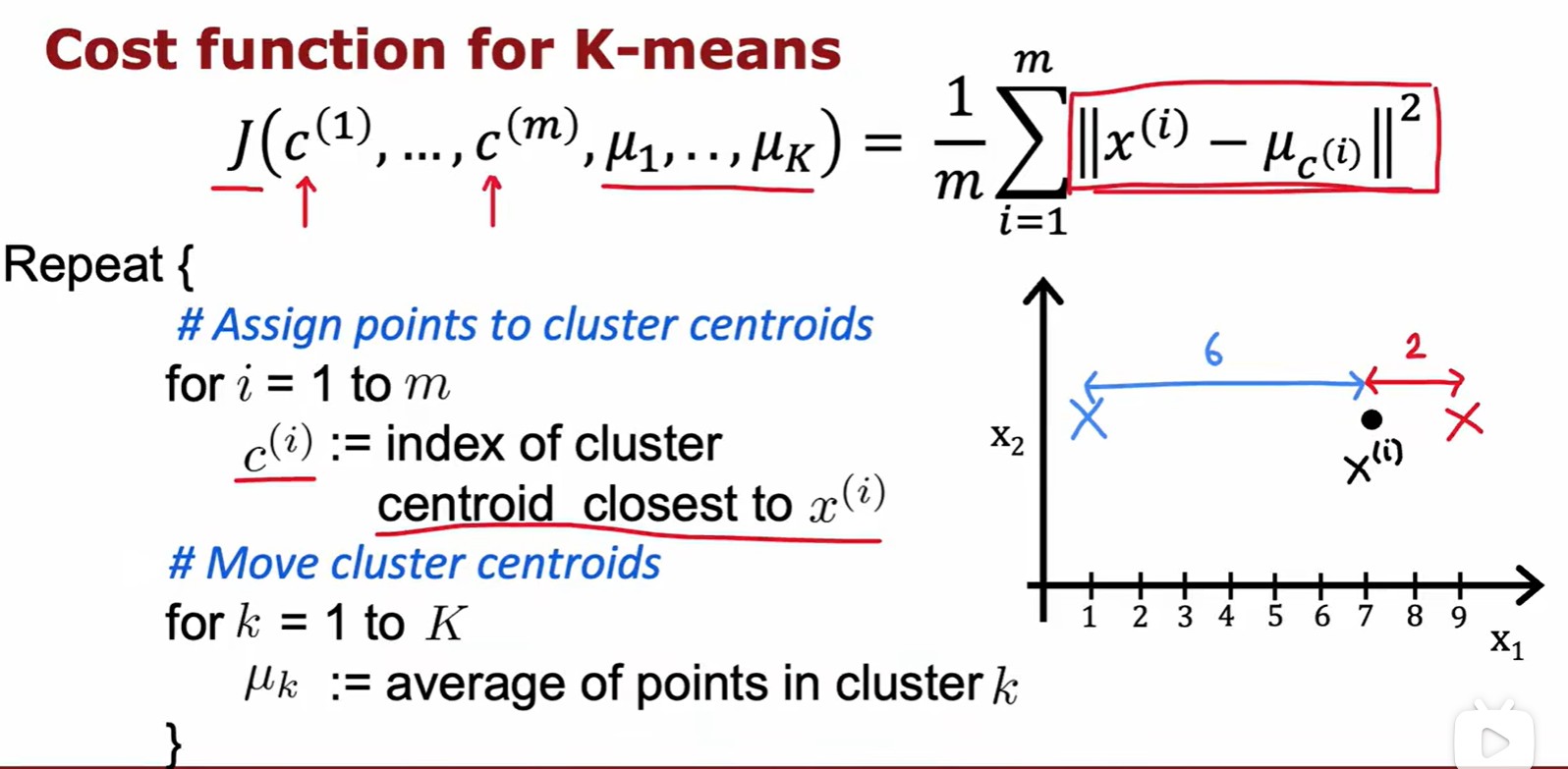
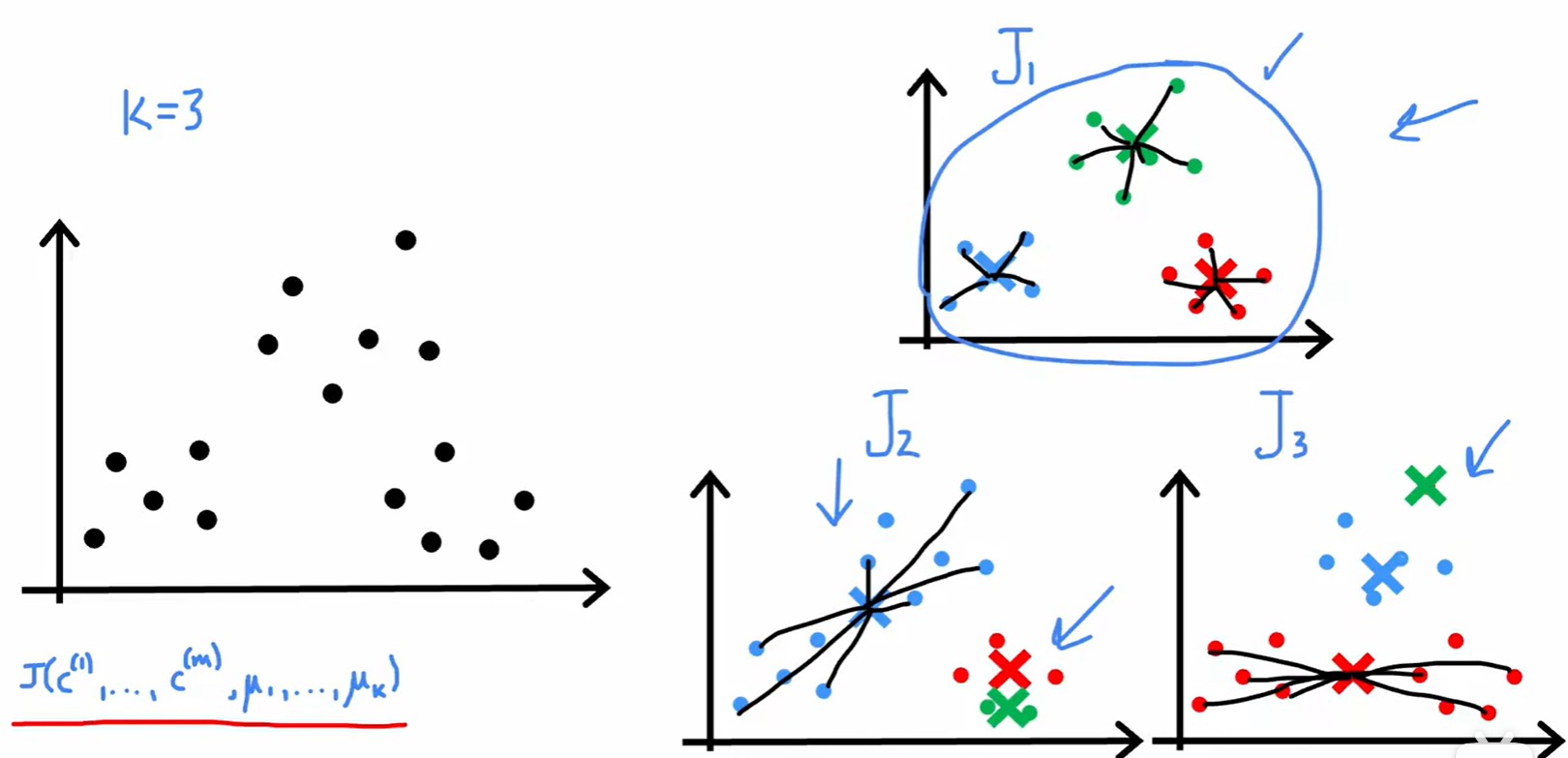
Optimization objective
?指的每個點,
?指的每個點被分配給的簇,
?是簇質心位置,
?指?
- 損失 J = 每個數據到其最近質心的距離平方的平均值;

- 這個損失函數還有一個別名:失真函數(distortion funtion);
Initializing K-means
- 更常見的初始化質心位置的方法:將質心分配到幾個訓練數據的位置上;
- 在經過多次的隨機初始化后,選取 J 最低的初始化方式;

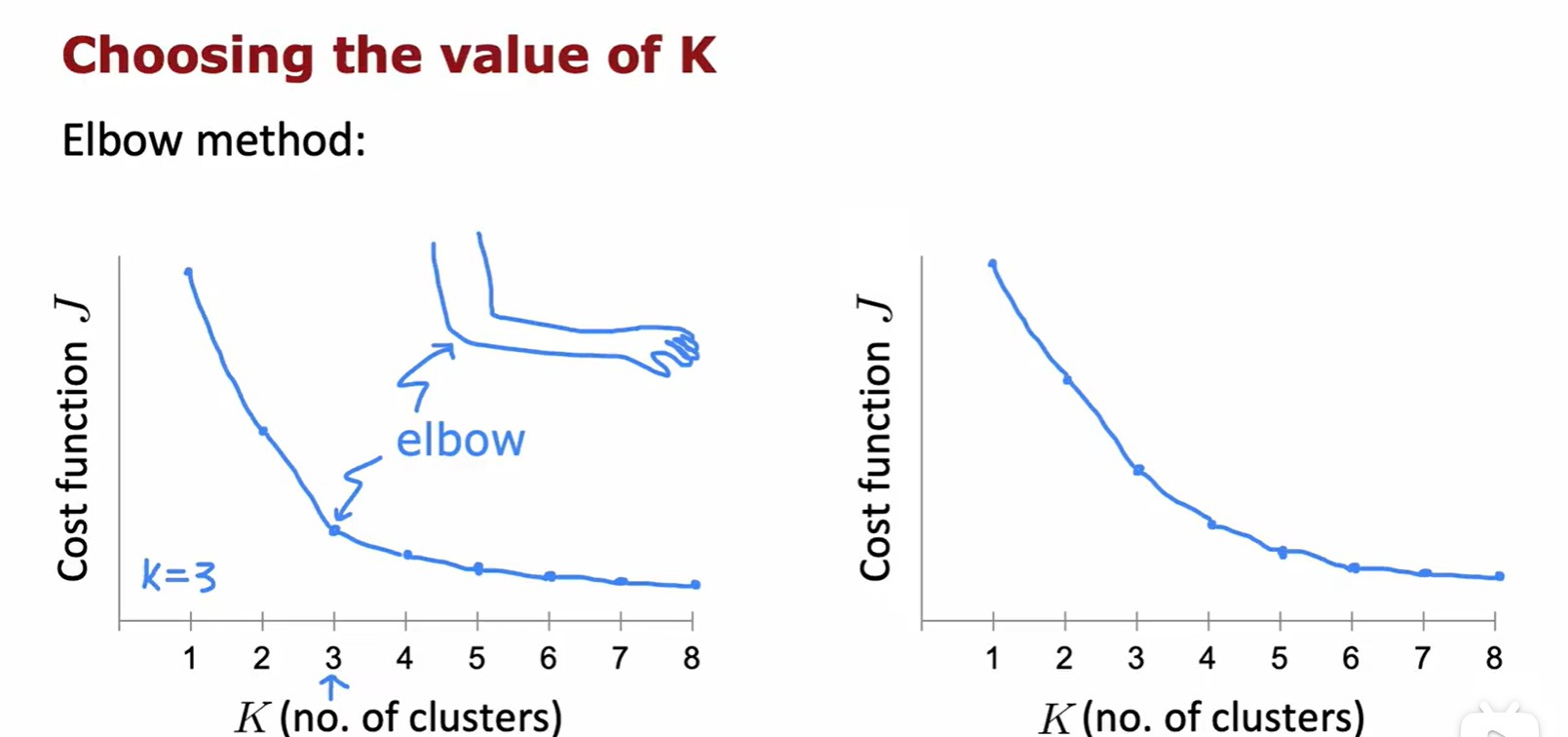
Choosing the value of K
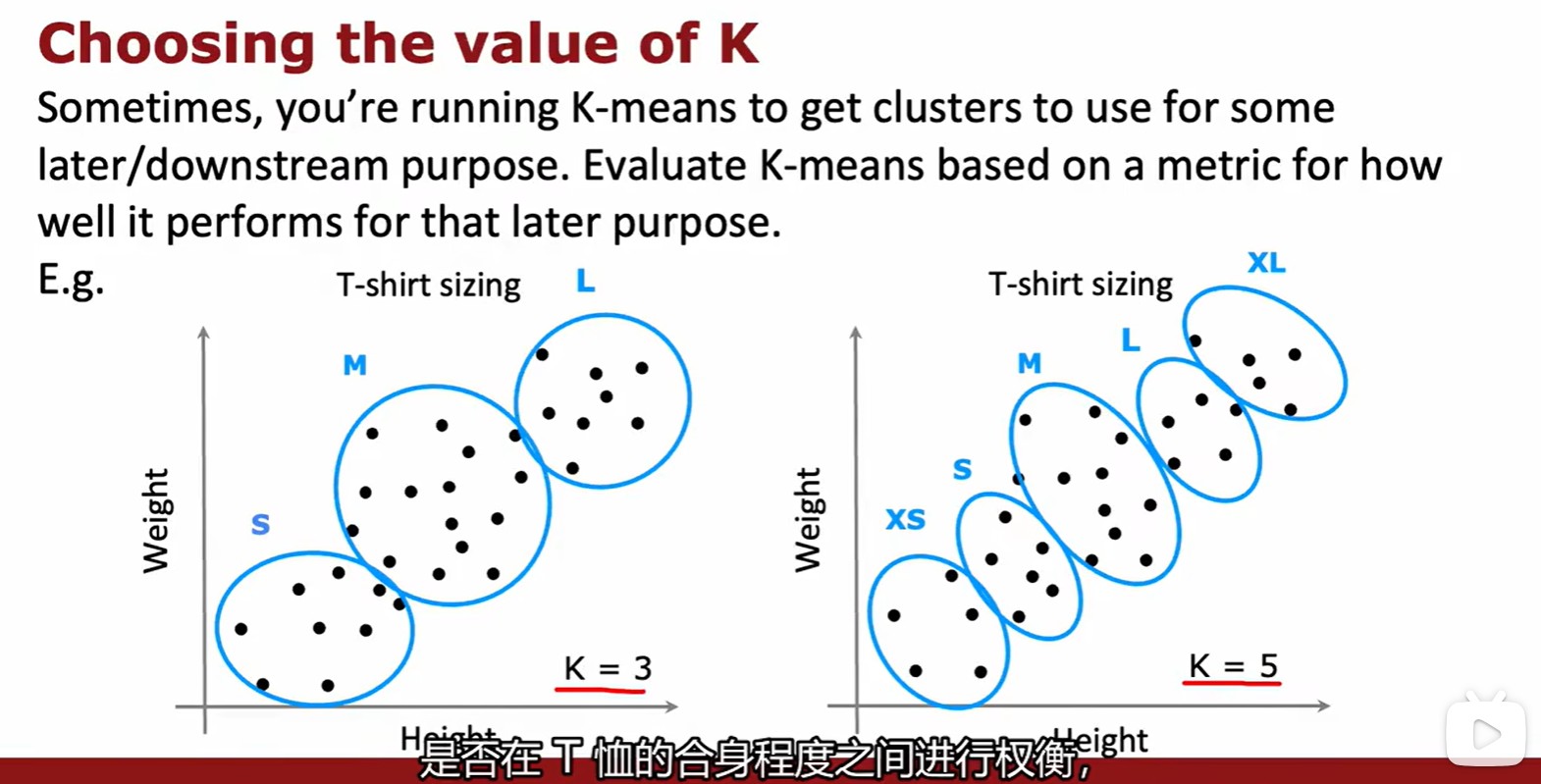
- 如何選擇聚類的數量 K,需要平衡 K 與 J 的關系,但是一般不會為了降低 J 而增加 K;
- 最合適的選擇還是和實際情況相結合:
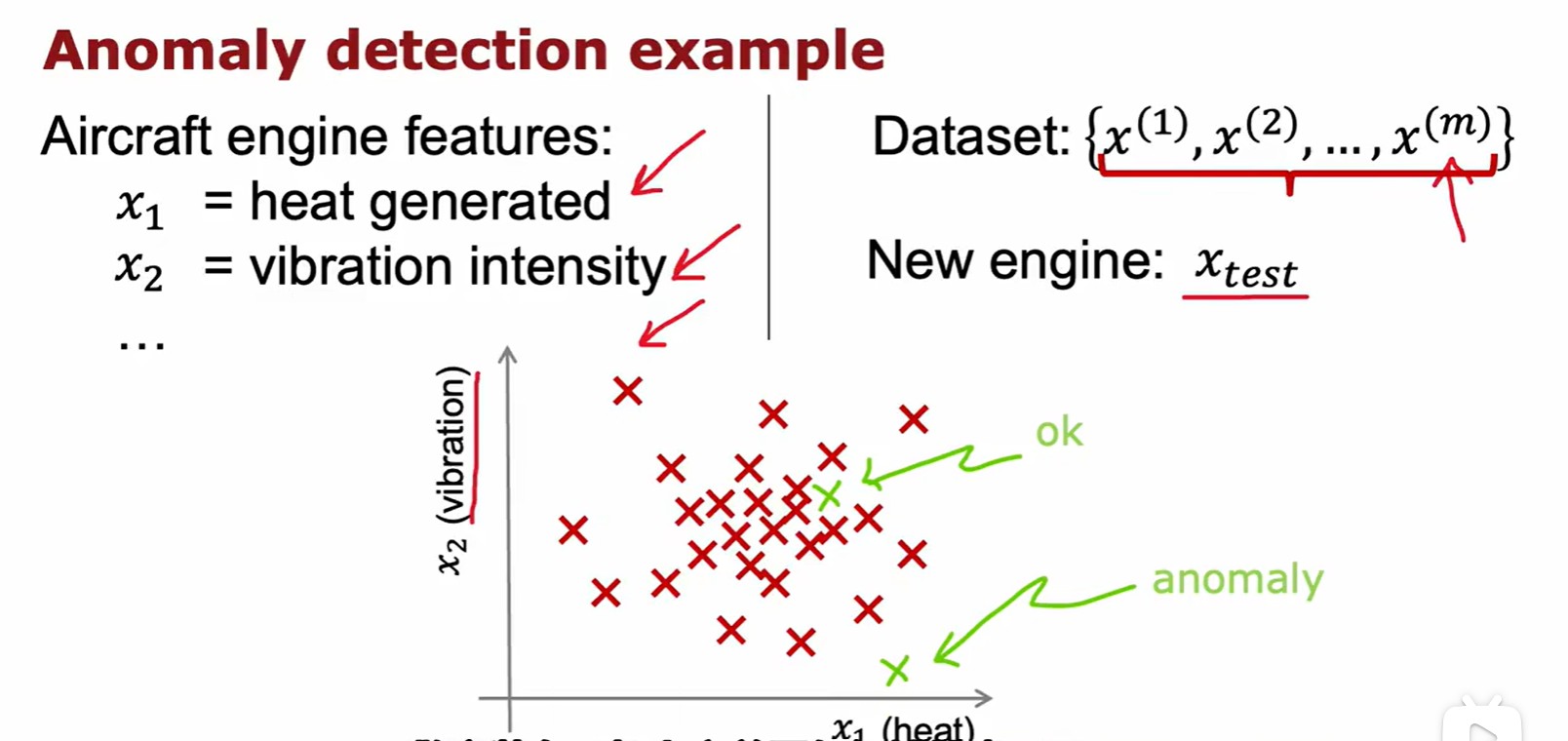
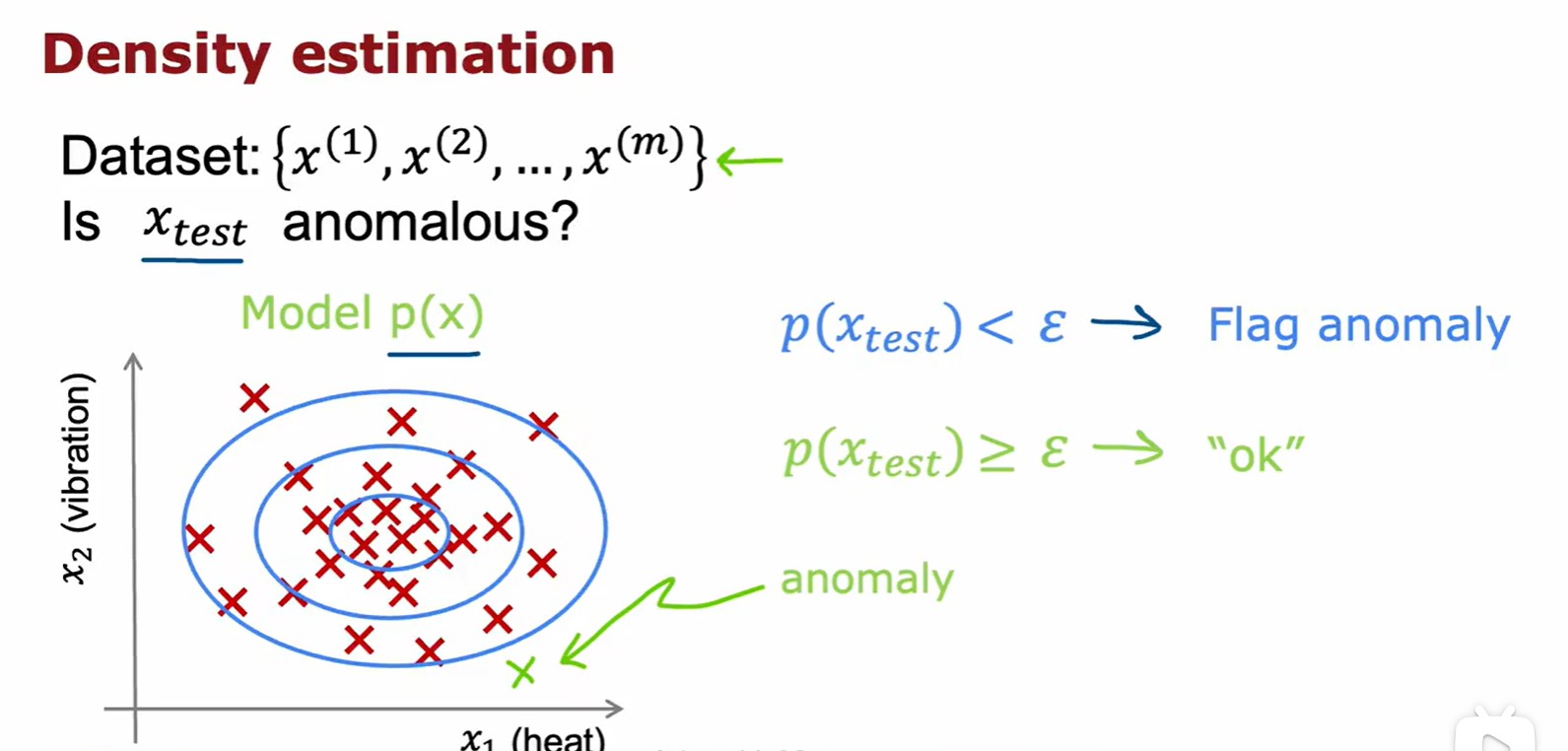
1.2 Anomaly Detection
Example and Solution
- 這里記錄的數據為飛機引擎溫度與振動強度,越接近密集區的數據越正常,越偏離越異常;
- 一種最常見的方法是密度估計:
Gaussion/Normal Distribution
- 正態分布:
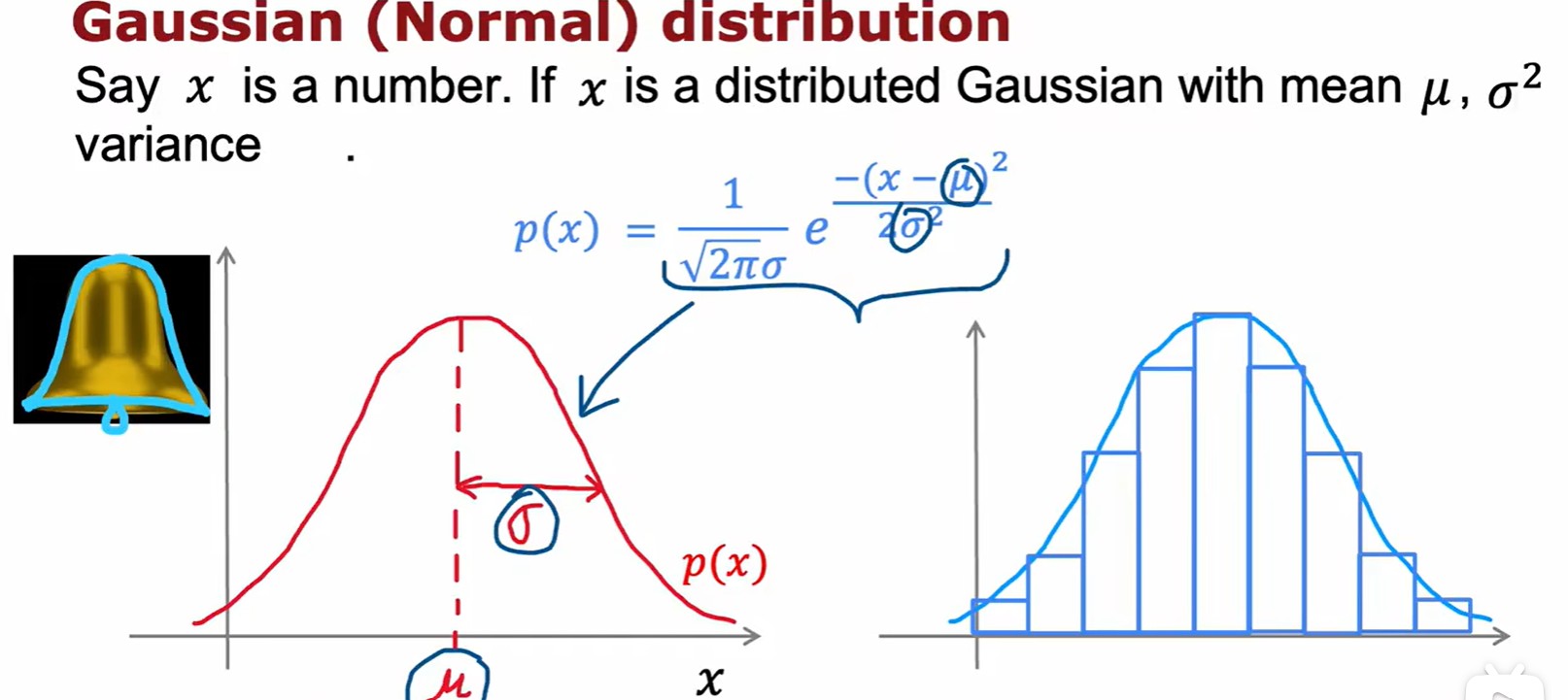
- 越接近中間的數據越正常:
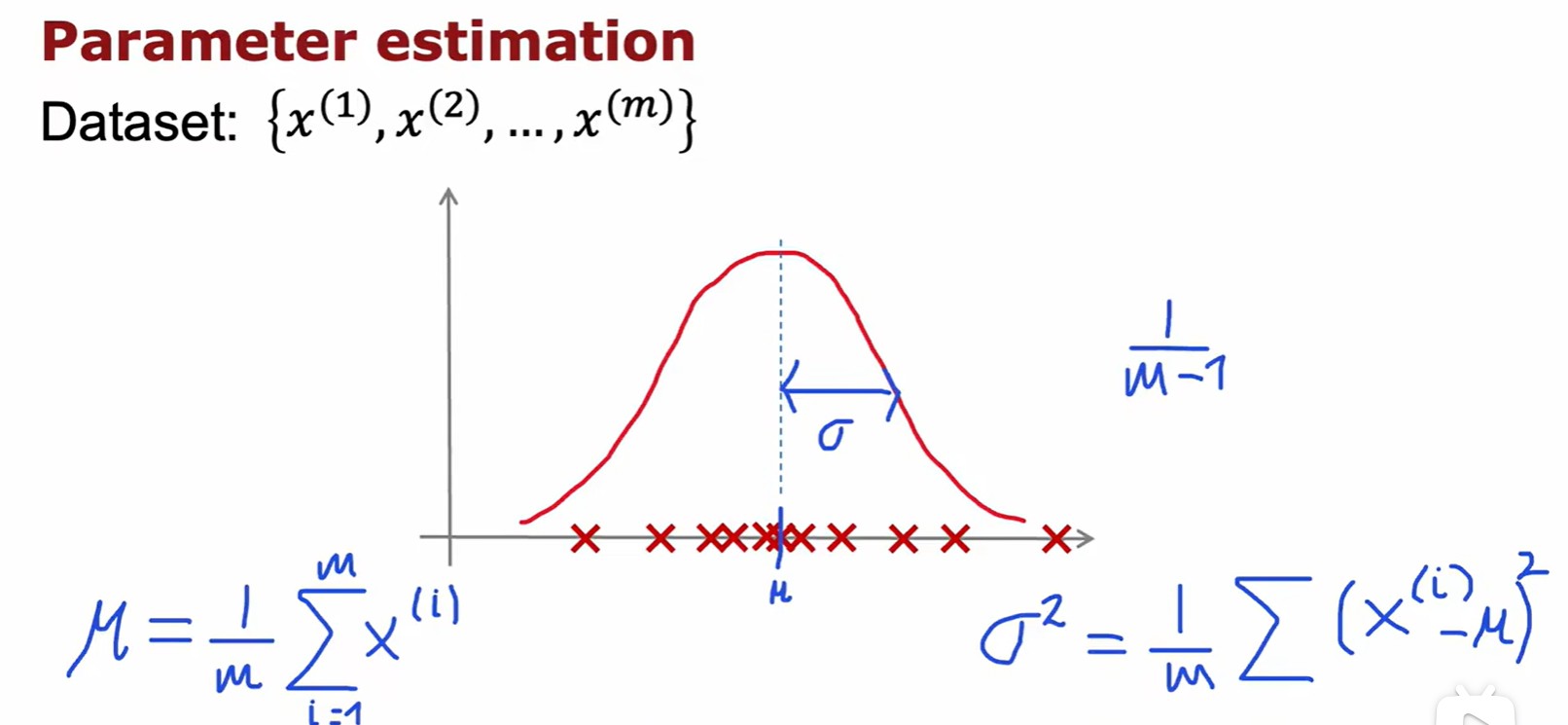
Algorithm
- 概率密度函數不表示概率,但是概率密度函數的值可以表示取這個值附近的點的概率;
- 計算每個特征的概率密度,然后累乘,最后比較;

- 二維的正態分布如果是獨立的,那么聯合概率分布就等于兩個相乘;
- 將計算出的概率密度與預先設定好的?
?相比較,如果小于它,則為異常;
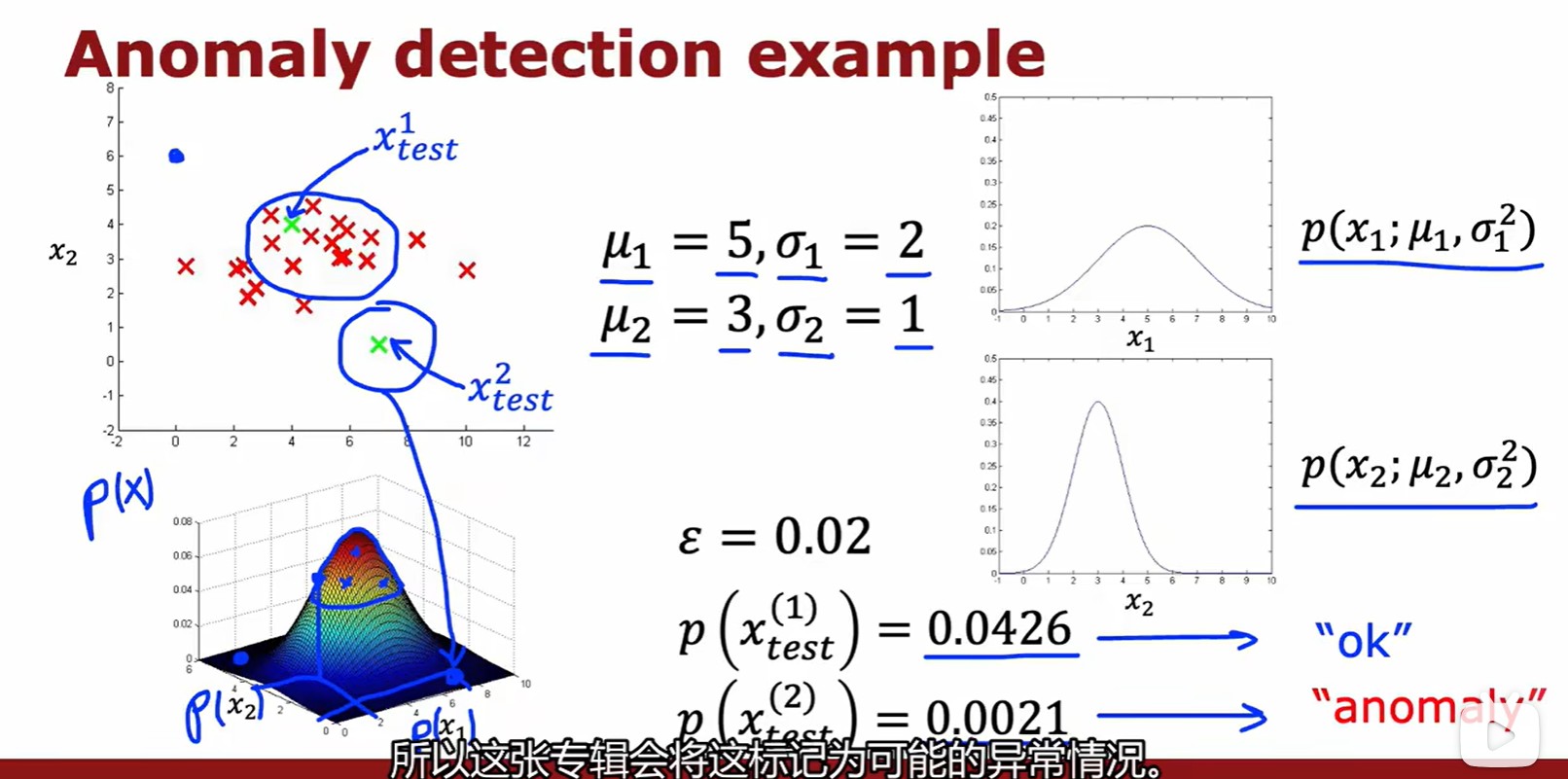
Evaluating system
- 評估系統:設立交叉驗證集和測試集,或者只保留交叉驗證集,訓練集不包含異常數據;
- 相當于用無標注的訓練集訓練出一個特定均值和方差的正態分布,并默認兩端的極值是不正常的。再通過測試集來調整閾值,使得閾值之上的都是正常的,閾值之外的都是不正常的。

- 利用交叉驗證集和傾斜數據集里的F1 score計算出最合適的?

Compared with supervised learning
- 異常檢測面對未知異常情況,監督學習面對已知異常的所有可能;
- 本質區別:一個反向排除,一個正向學習;
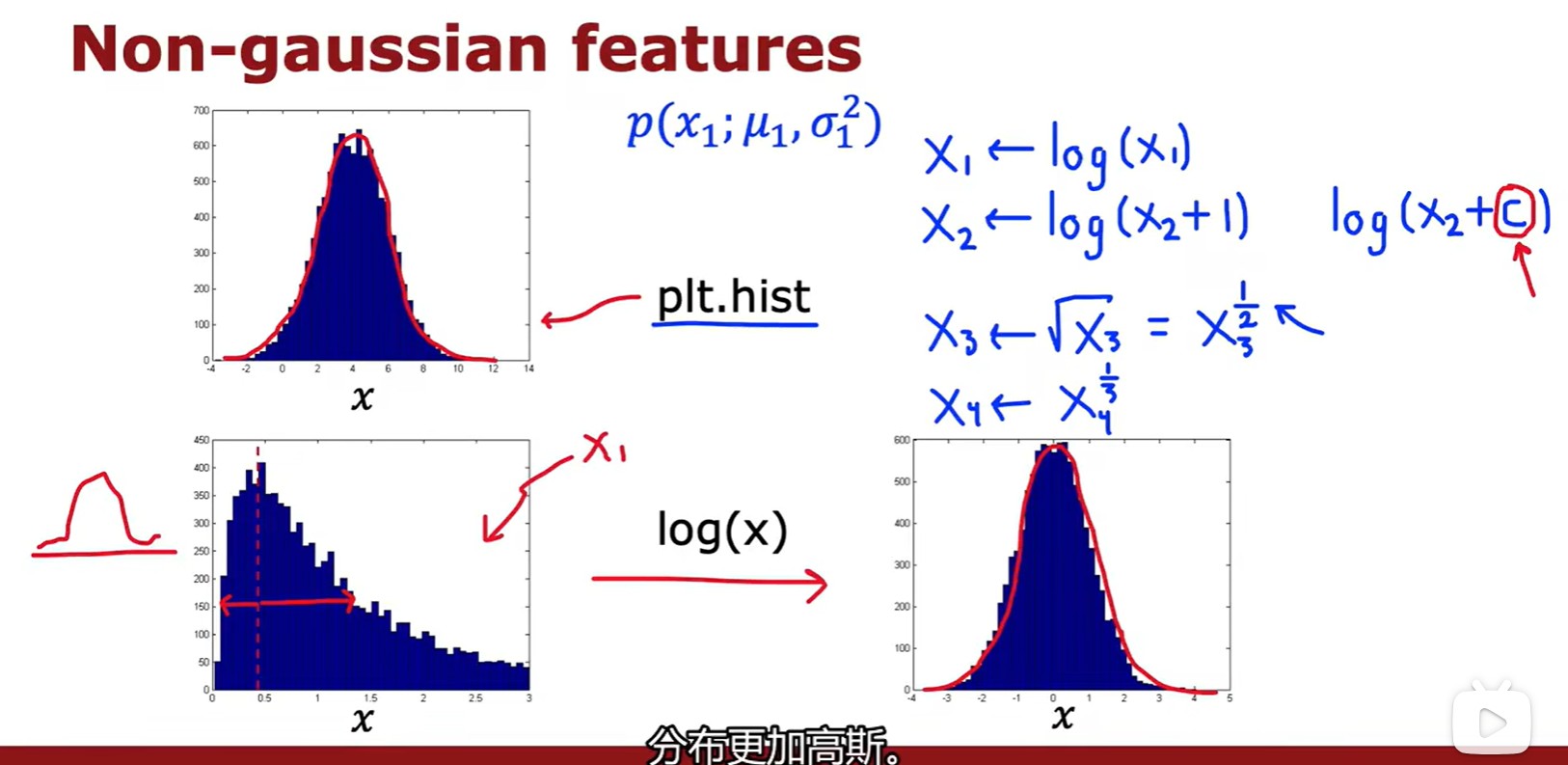
Choosing featrues
- 選擇更接近高斯分布的特征集,或者將其轉化為類似高斯分布的特征集;
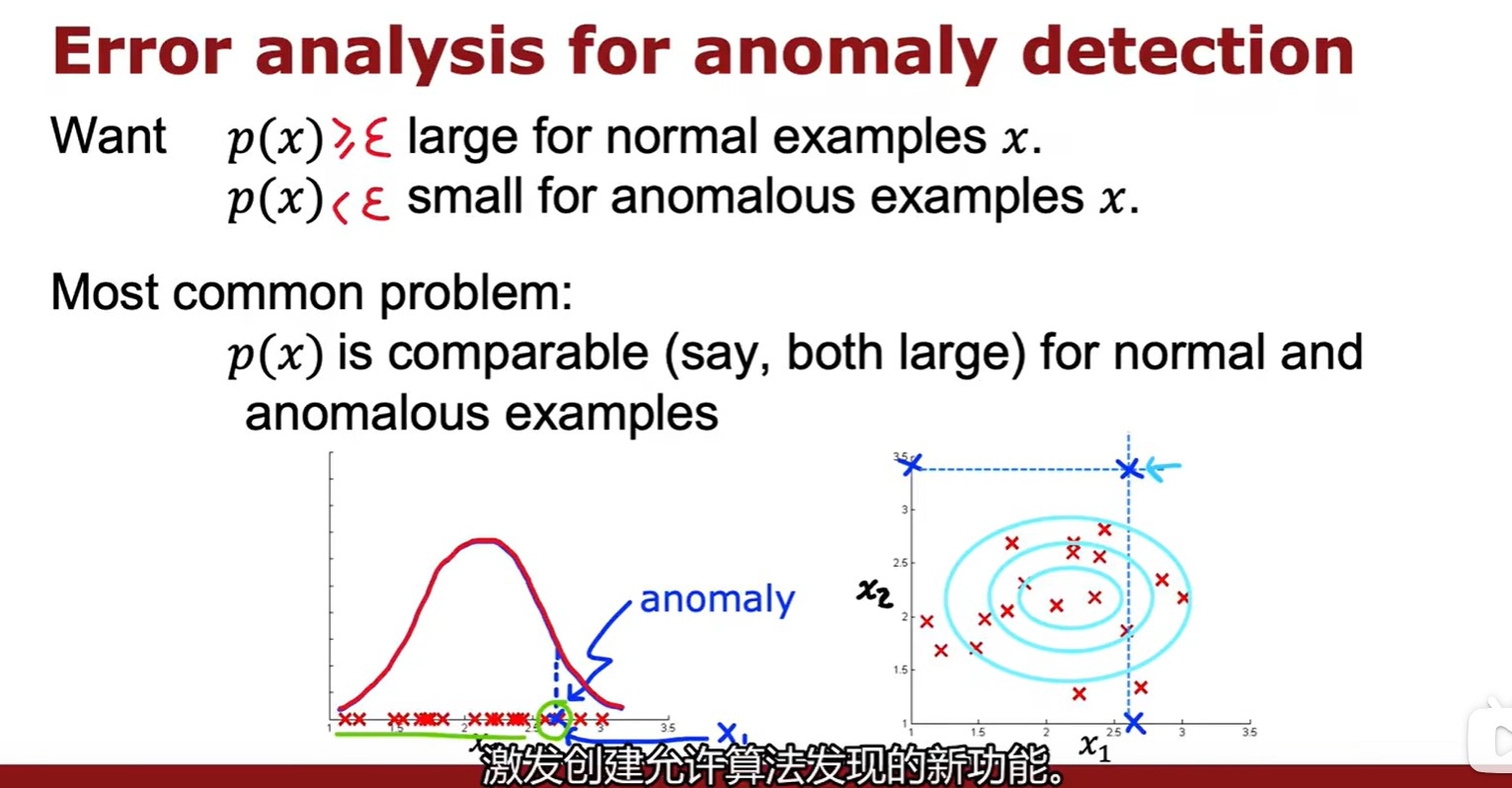
- 如果已有特征無法分辨該數據是否異常(計算得出是異常,但與其他示例又十分接近),則試圖找出是什么讓我認為是一個異常,由此識別出新特征;
- 組合原有特征合成新的特征:

Week 2
2.1 Recommender System
Making recommendations
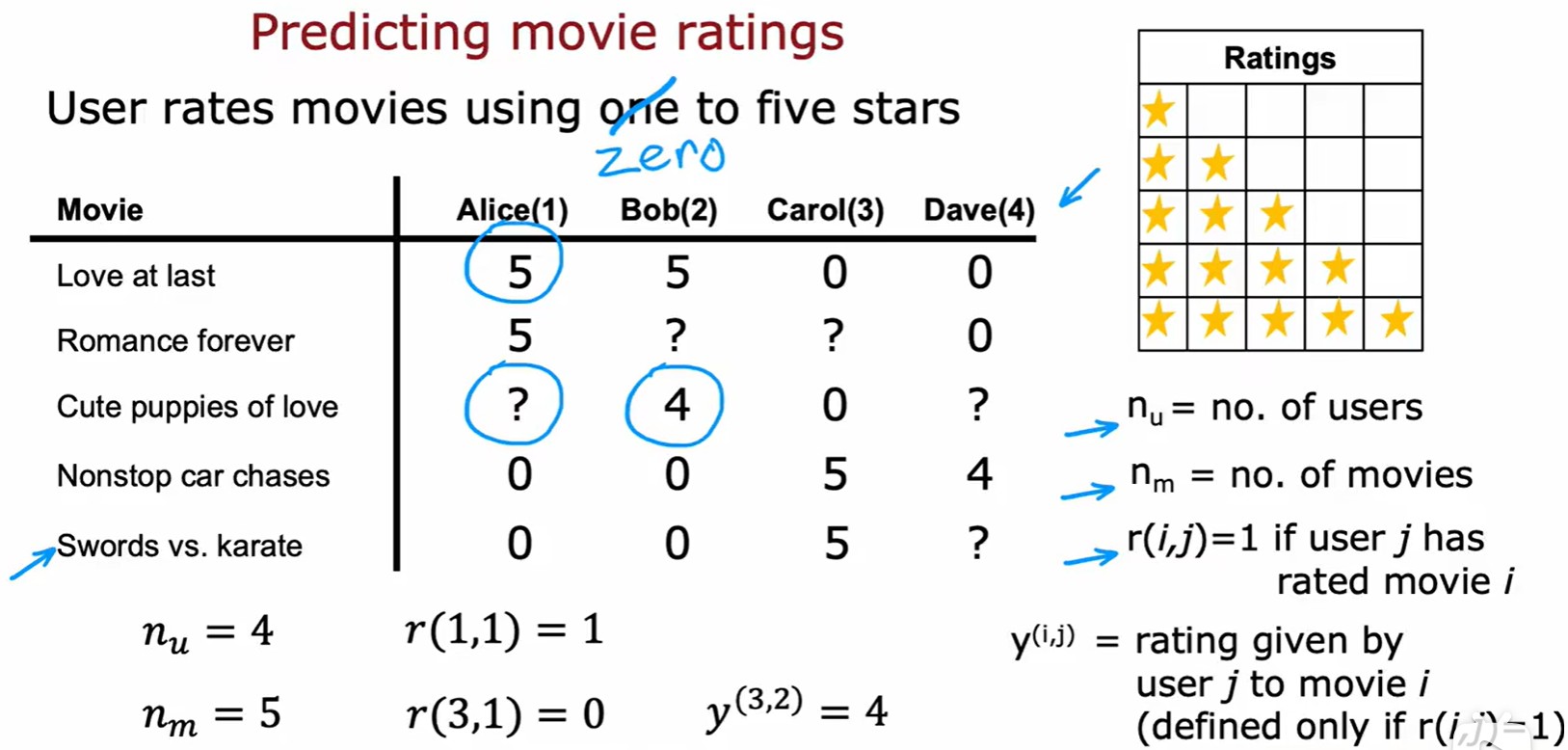
- 電影評分:r(i, j) 表示用戶 j 是否對電影 i 進行評分,y(i, j) 表示用戶 j 對電影 i 的評分;
?為用戶數,
?為電影數;
Using featrues
- n 為特征數,這里為每個用戶構建一個線性模型:
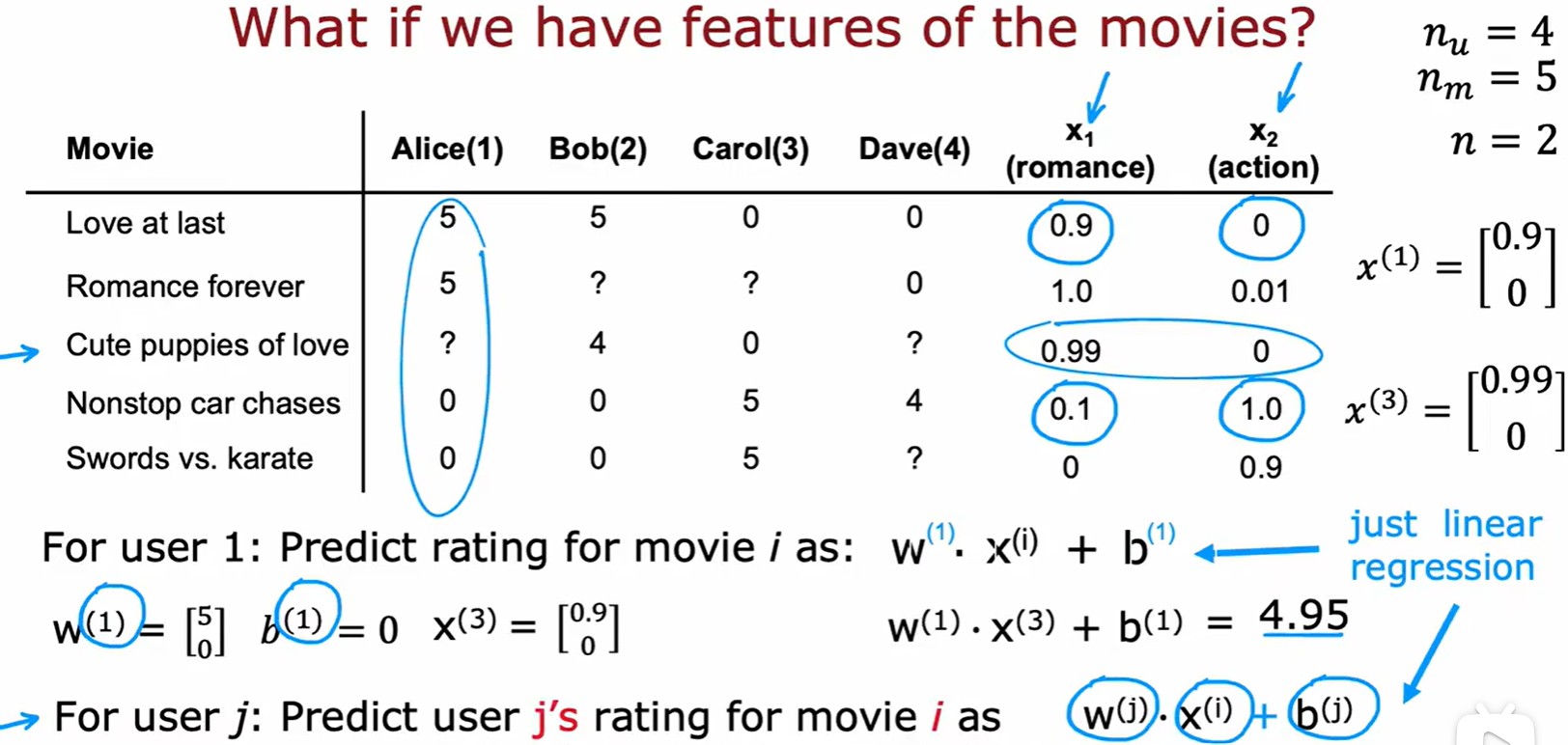
?表示用戶 j 有評分的電影數量,注意這里求和的是 r = 1 的用戶,就是有評分的數據;;
- 計算損失:

Collaborative filtering algorithm?
- 協同過濾算法:特征向量未知,但是參數 w, b 已知;
- 也就是說我們可以通過用戶對電影的評分然后計算出參數 w 和 b。然后計算出 w 和 b 后,就可以通過數據來預測對未知電影特征進行評分;
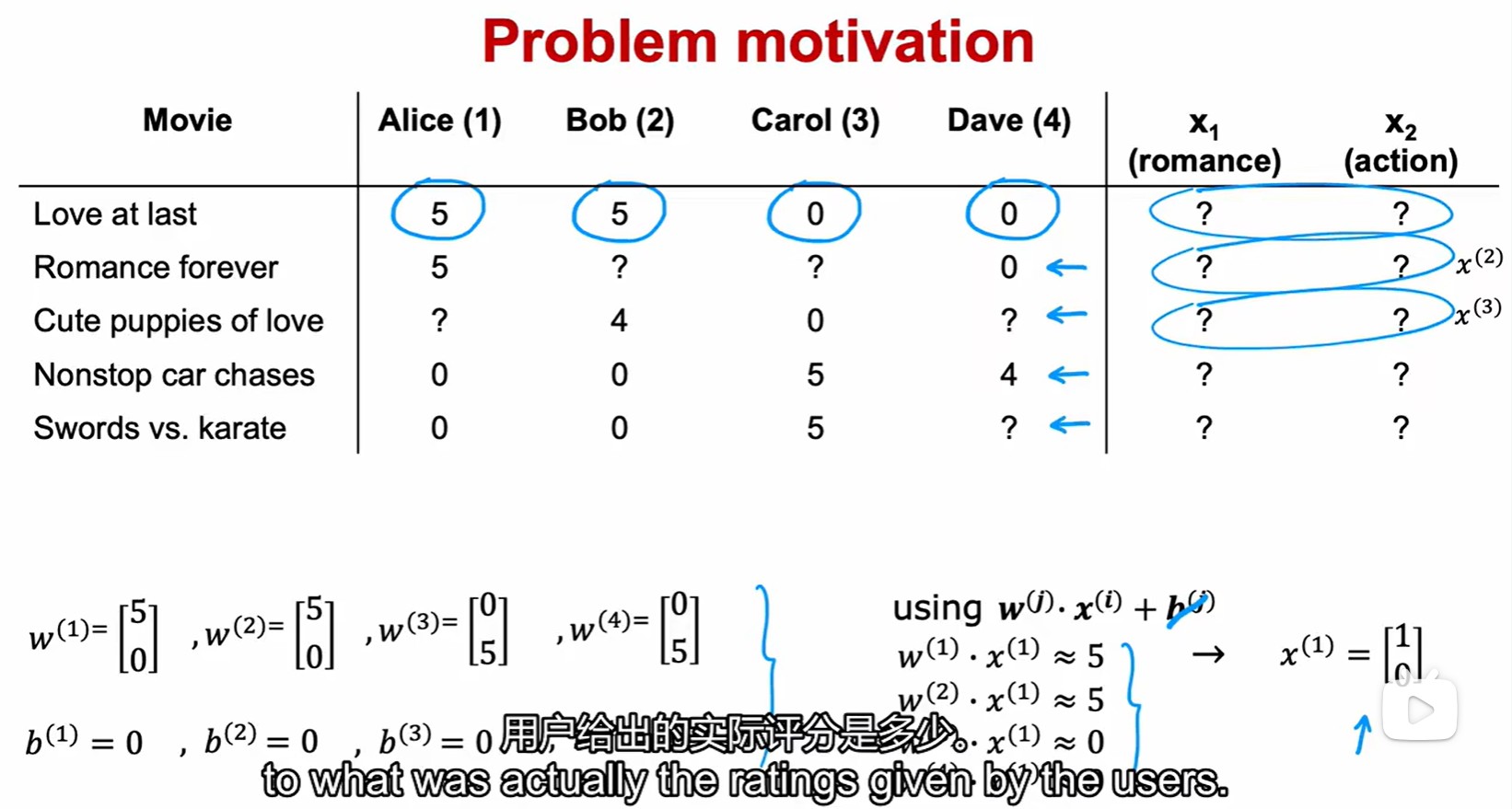
- 計算損失:注意這里的正則化是用 x 而不是 w;
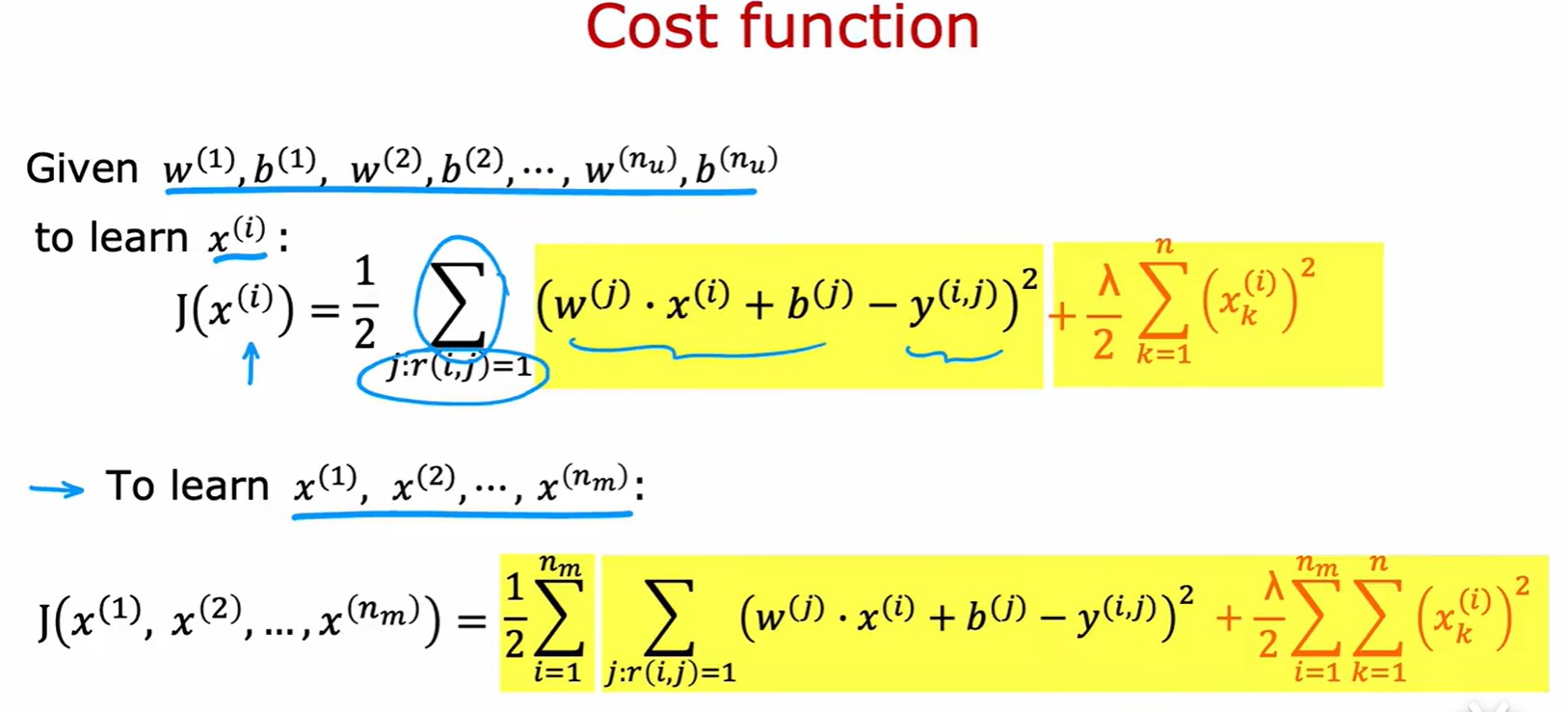
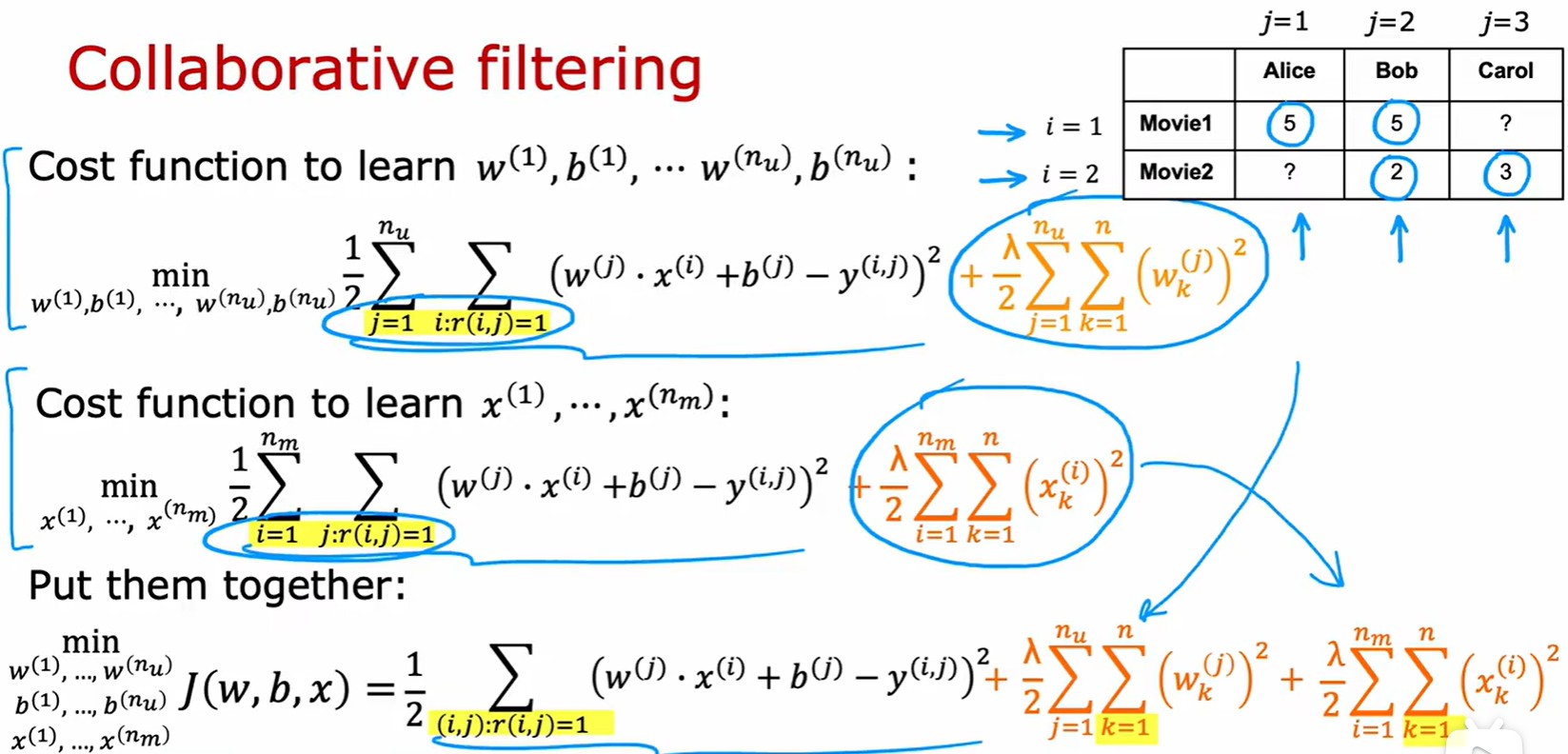
- 結合兩個損失公式,得到總體成本函數(類似線性回歸,但是包含三個變量):
- 這里的求和項只是變了一種形式而已。第一個表示先對列求和,在對行求和。第二個則表示先對行求和,再對列求和。最后這個再形式上化簡了,沒有行和列的概念。直接對每個(i,j)對求和;
Binary labels
- 二進制標簽應用:1代表看到了且參與,0代表看到了但是未參與,?代表沒有看到;

- 計算損失(類似 logistic 回歸,只是包含三個參數):

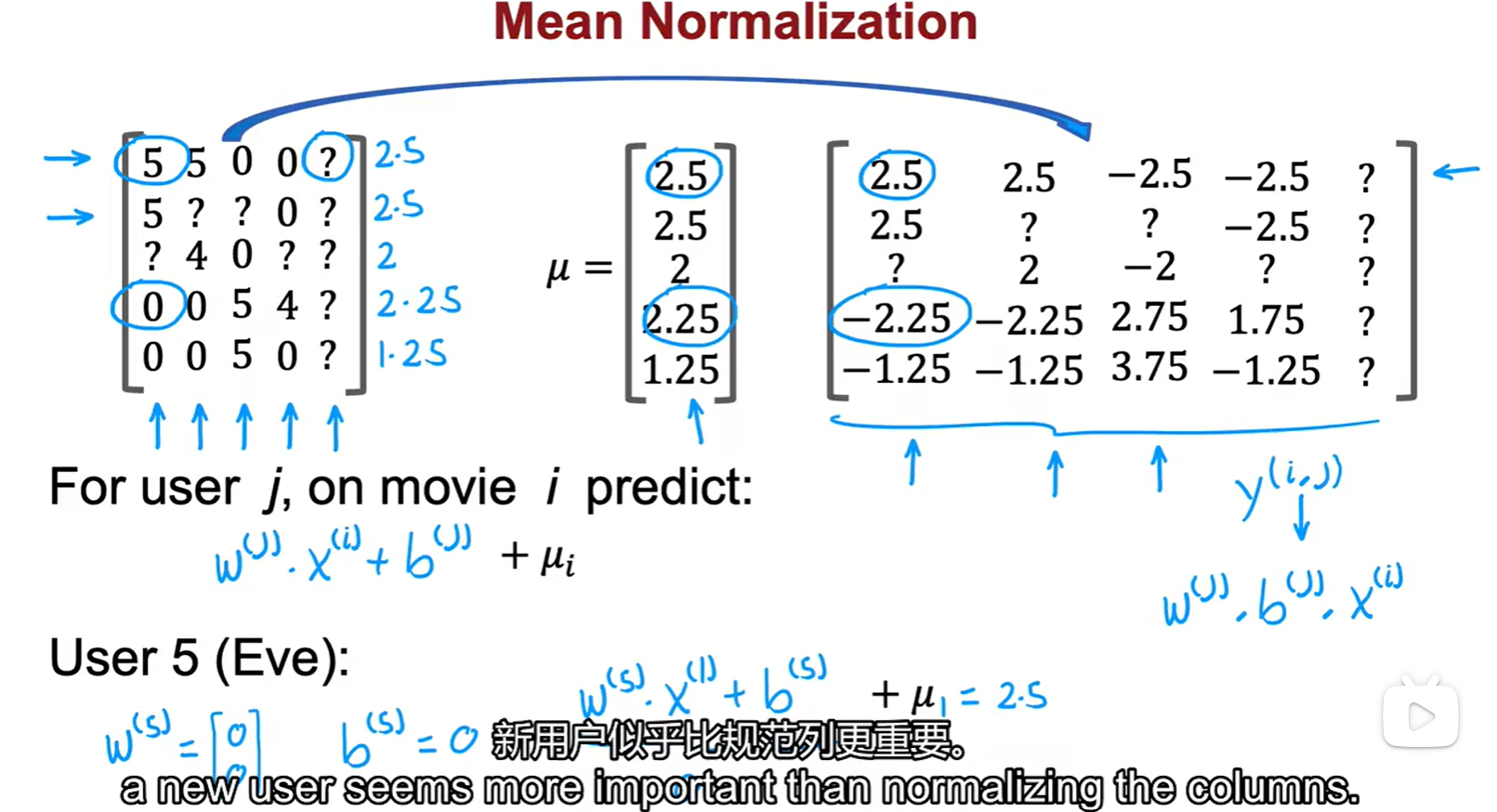
2.2 Mean Normalization
- 均值歸一化:一個新用戶,沒有任何信息,但是我們不能不給TA推東西,所以要靠取均值來進行冷啟動;這里做的是行歸一化,參數初始化為 0;
- 行歸一是對于新用戶的預測更加合理,列歸一是對于新電影的預測更加合理;
2.3 Finding related terms
- 通過計算兩個特征向量間的差平方和,從而判斷兩者是否相似:

Cold start
- 協同過濾的限制:1.冷啟動問題(初始數據不足)2.難以利用其他信息;

2.4 Content-based filtering
Compared with Collborative filtering
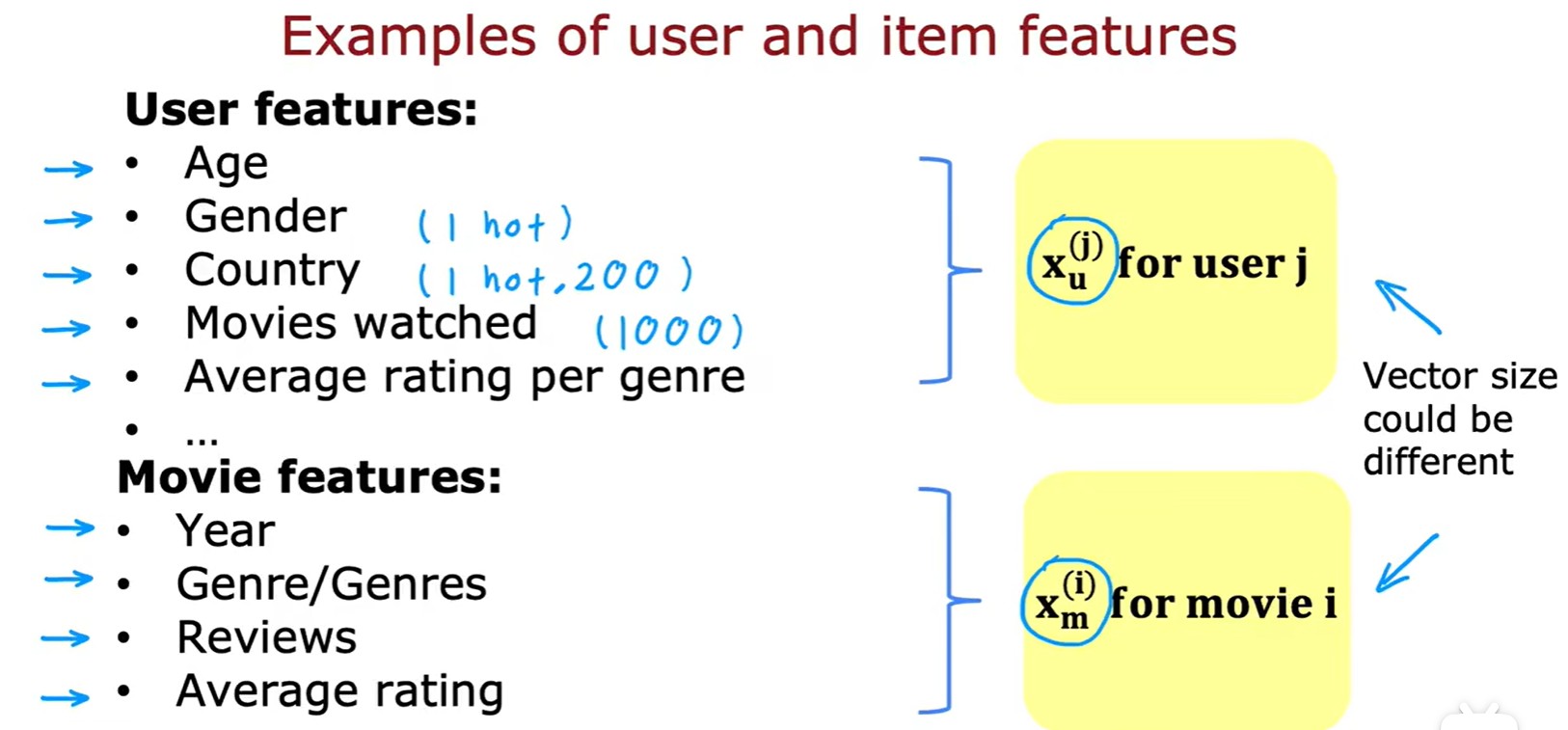
- 基于內容過濾:通過用戶和電影的特征,計算兩者間的匹配度;

?和?
?分別代表用戶,電影的特征向量:
Learning to match
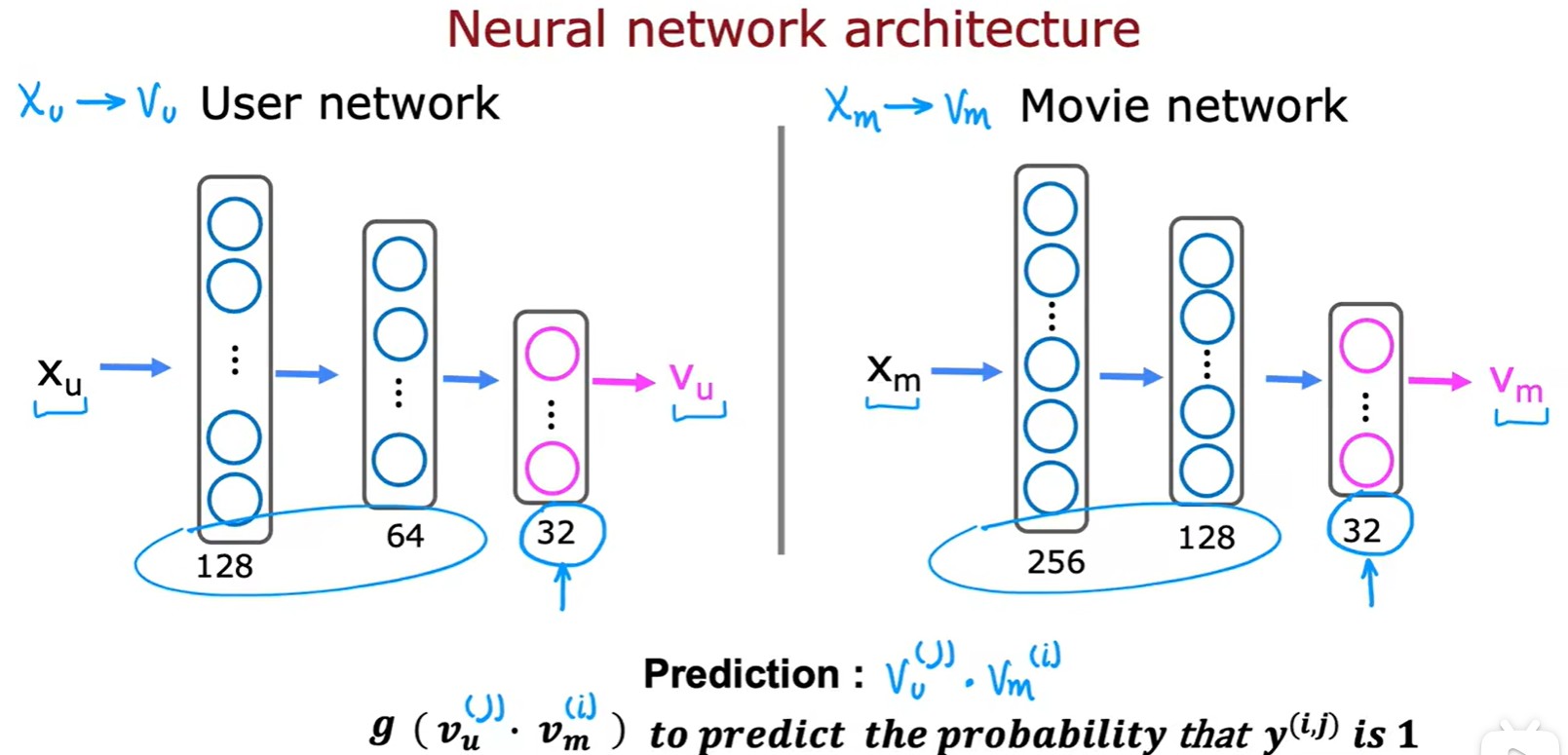
- 通過?
?和?
,并且兩者大小需要相同,然后進行點積計算得到用戶對某電影的預估分數:

Neural network?
- 利用神經網絡將特征向量變換為?
- 計算損失:
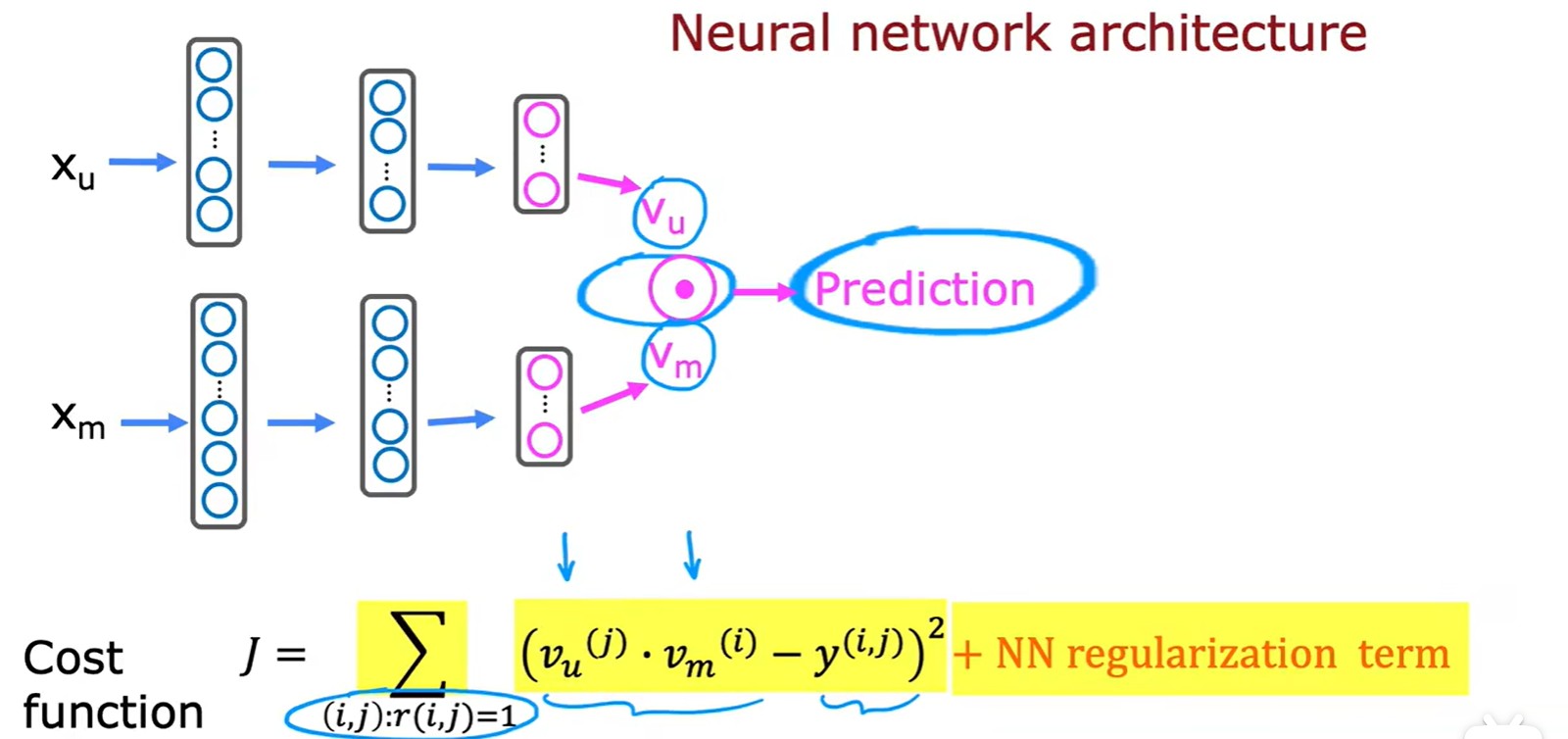
- 還可以利用這個方法區找到相似電影:

2.5 Large catalogue
Retrieval
- 第一步是檢索:按照計算出的最相似的電影、常看題材的Top10、總榜單Top20,并且刪除已經看過的,可以先得到一個粗略的較大列表;

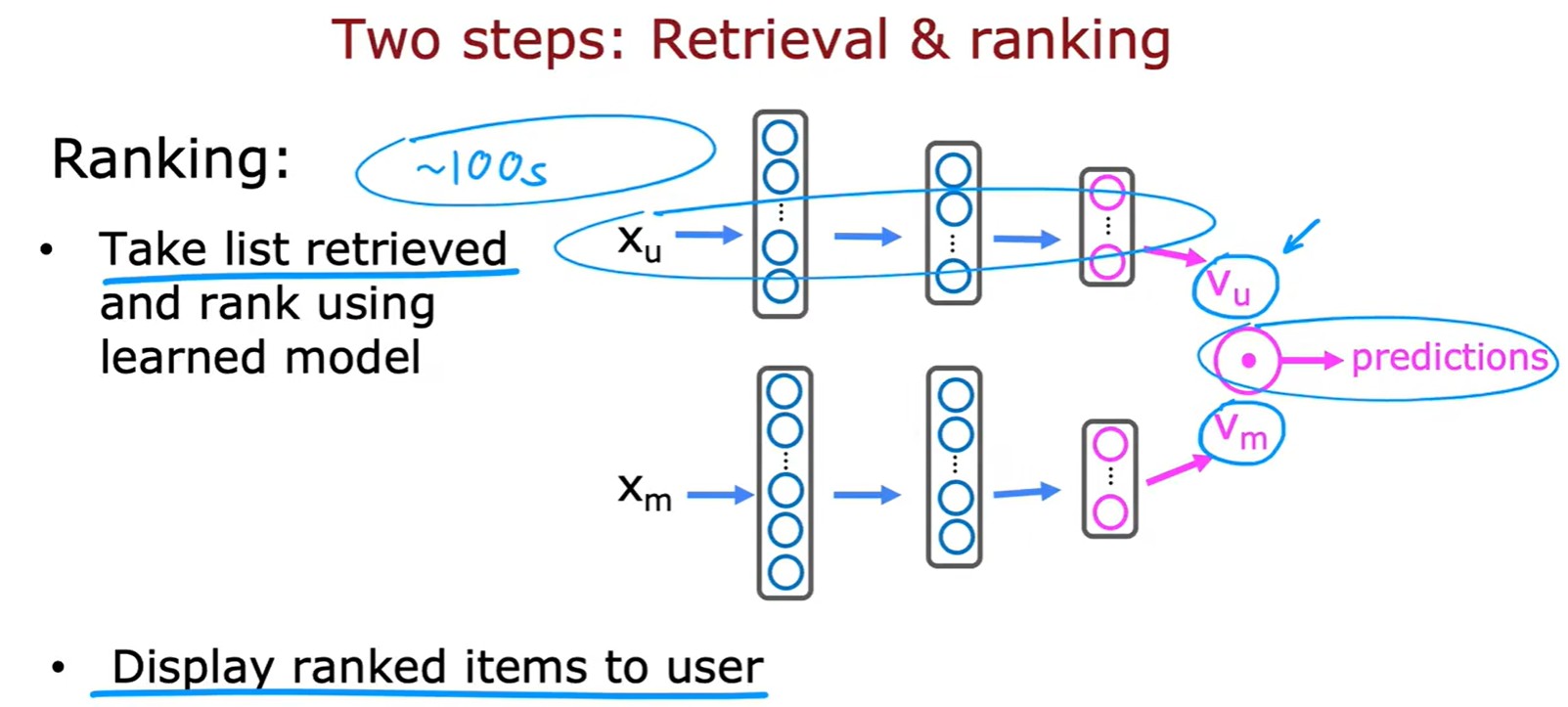
Ranking
- 第二步:將檢索的電影帶入模型計算預測分數,按照分數進行排名推薦;
Week 3
3.1 Reinforcement Learning
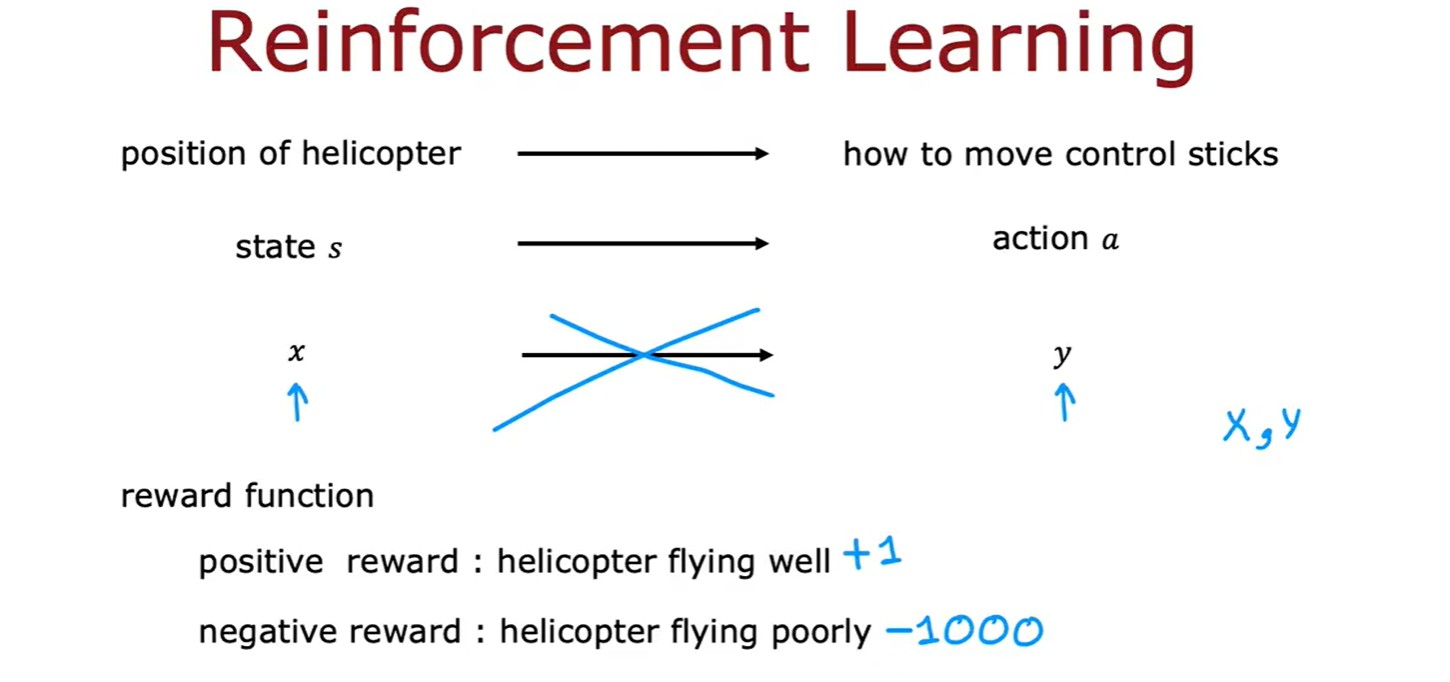
- 強化學習:核心在于指定一個獎勵函數,告訴它什么時候做得好,什么時候做的不好,算法的工作是自動找出如何選擇好的動作;
Mars Rover Example
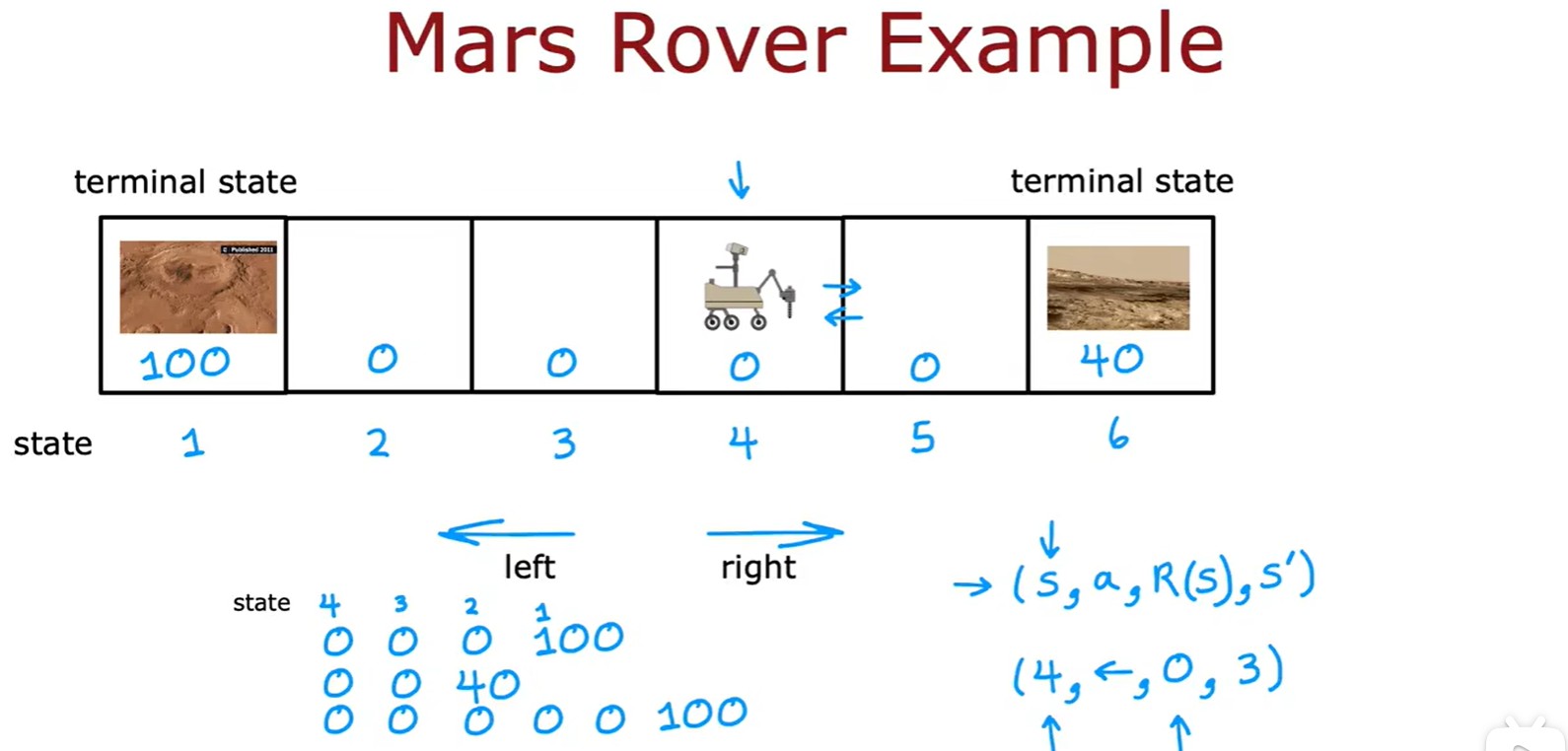
- 火星探測器:這里的(s,a,R(s),s')表示(狀態,動作,當前狀態的獎勵,下一個狀態);
Return
- 強化學習的回報:每走一步都要乘以一個折扣因子,由此計算回報;
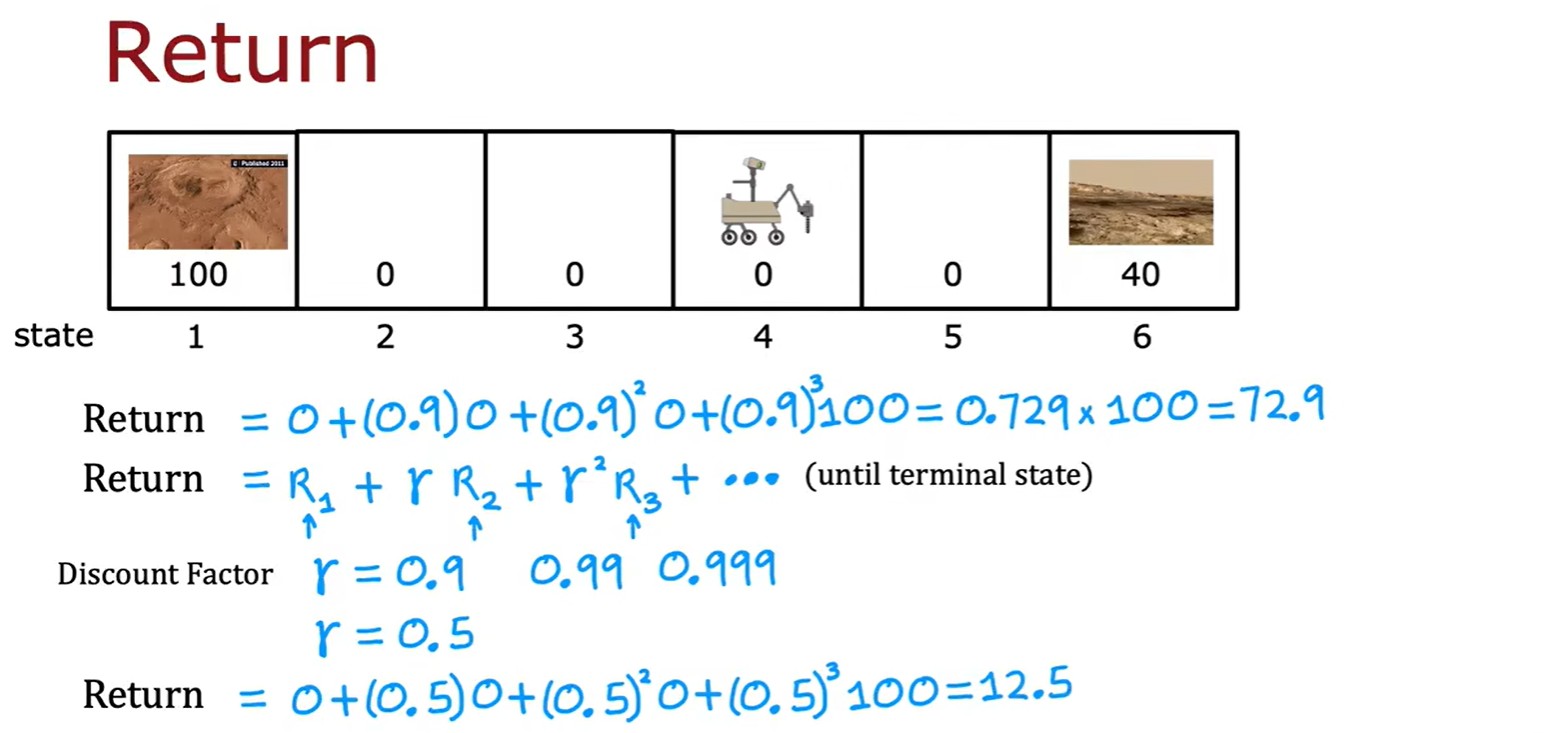
- 這里是幾種不同的選擇:一直向左、右,還有根據計算結果選擇方向;

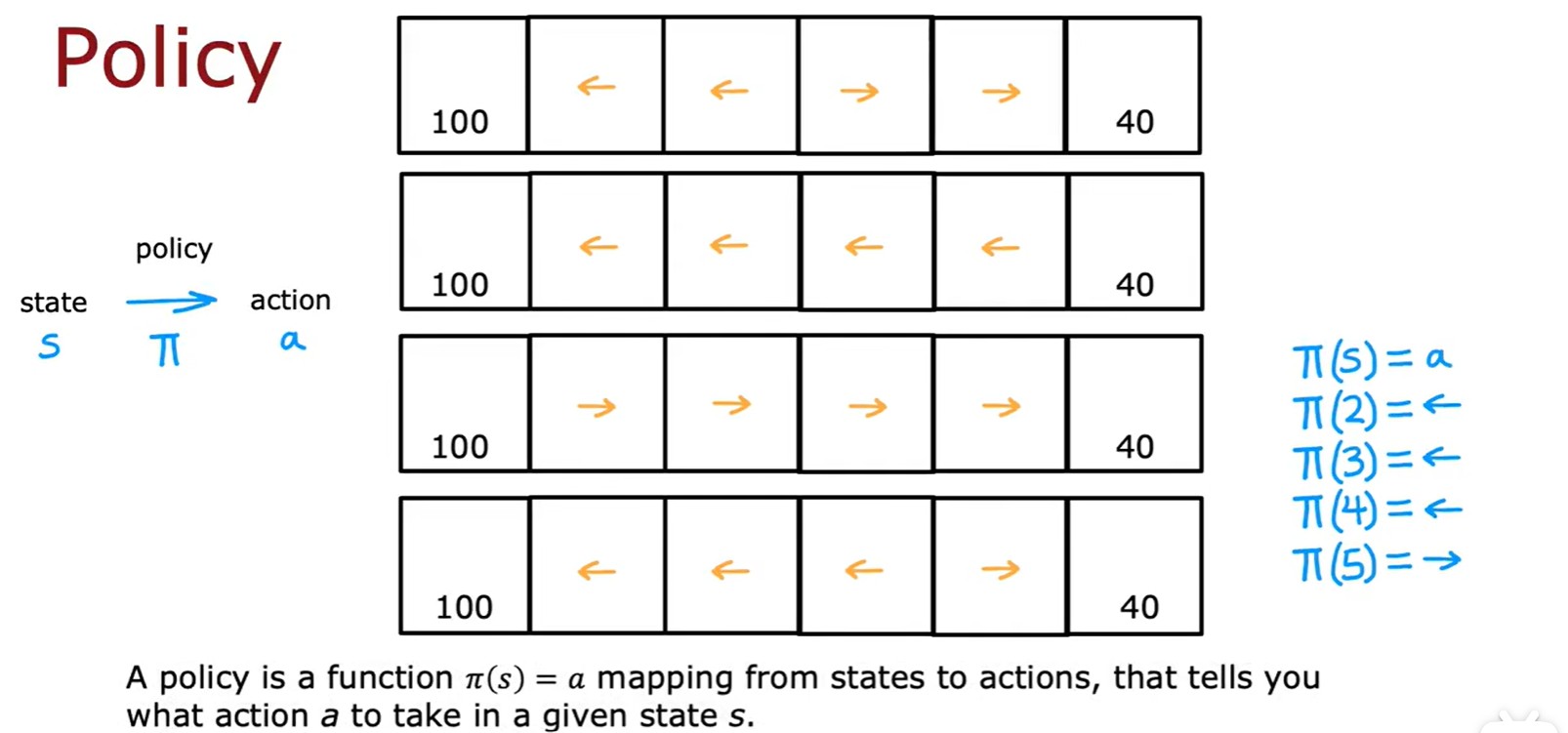
Policy
- 強化學習中的策略:
?表示在 s 處的行動是 a;
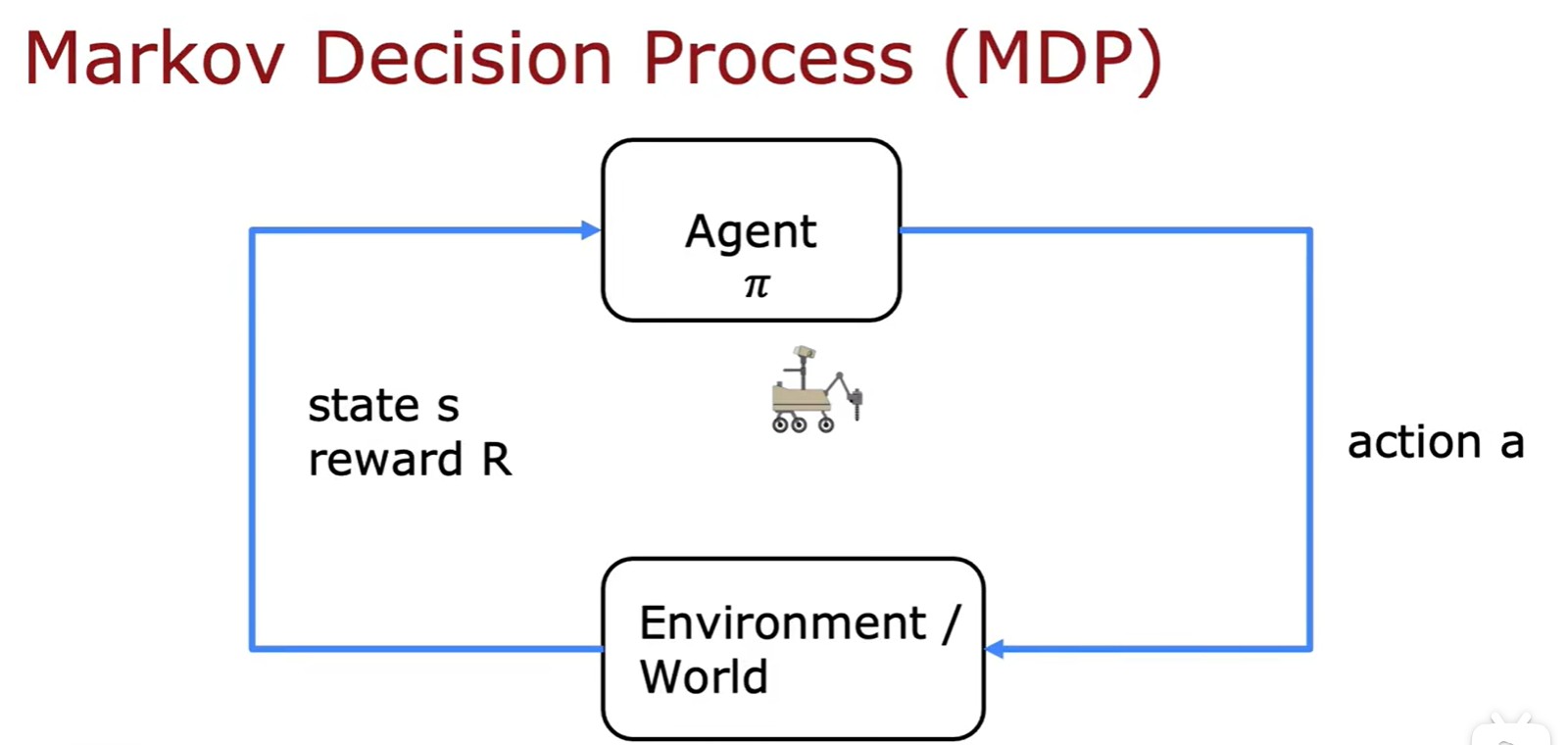
Markov Decision Process
- 馬爾科夫決策過程:未來只取決于你現在在哪里,而不管你是怎么到這里的;
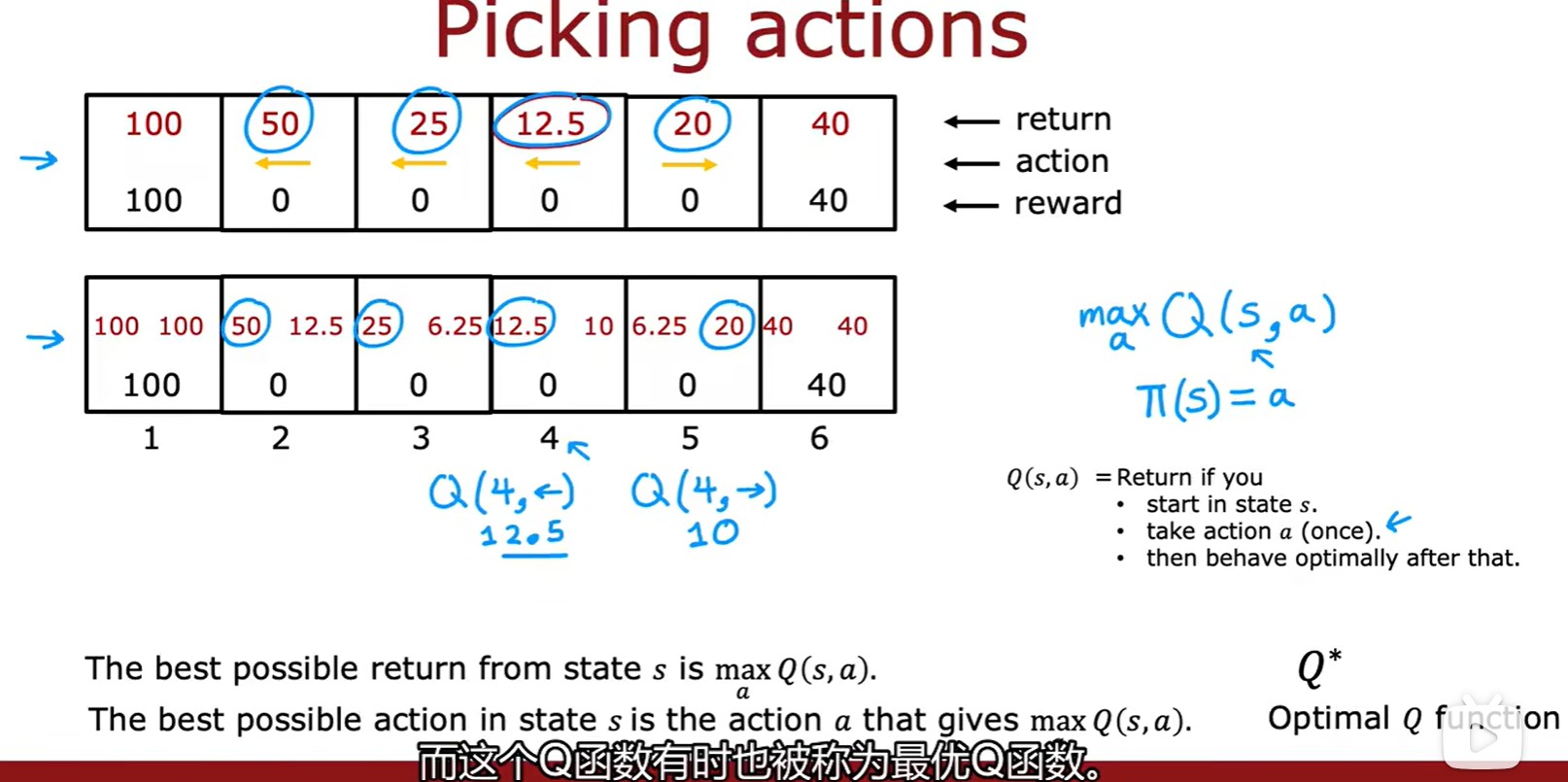
3.2 State-action value function
- 狀態 - 動作價值函數:Q(s,a)表示在 s 處做出動作 a 得到的回報;
- 注意這里第一個計算的是先向右一步,再掉頭的策略;

Picking actions
- 如何采取行動:需要選擇?Q 函數最大的策略;
Bellman Equation
- 貝爾曼方程:原理就是遞歸方程,注意終端狀態下計算沒有第二項;

3.3 Continuous State?
- 連續狀態空間應用:

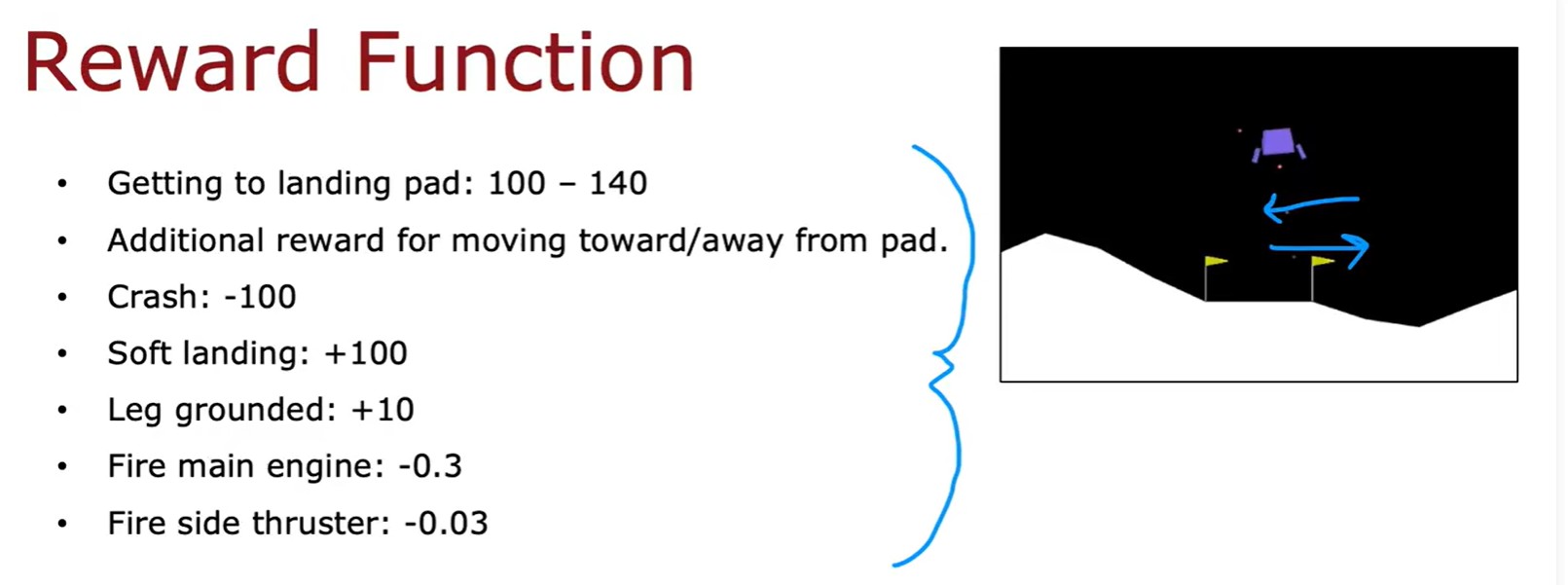
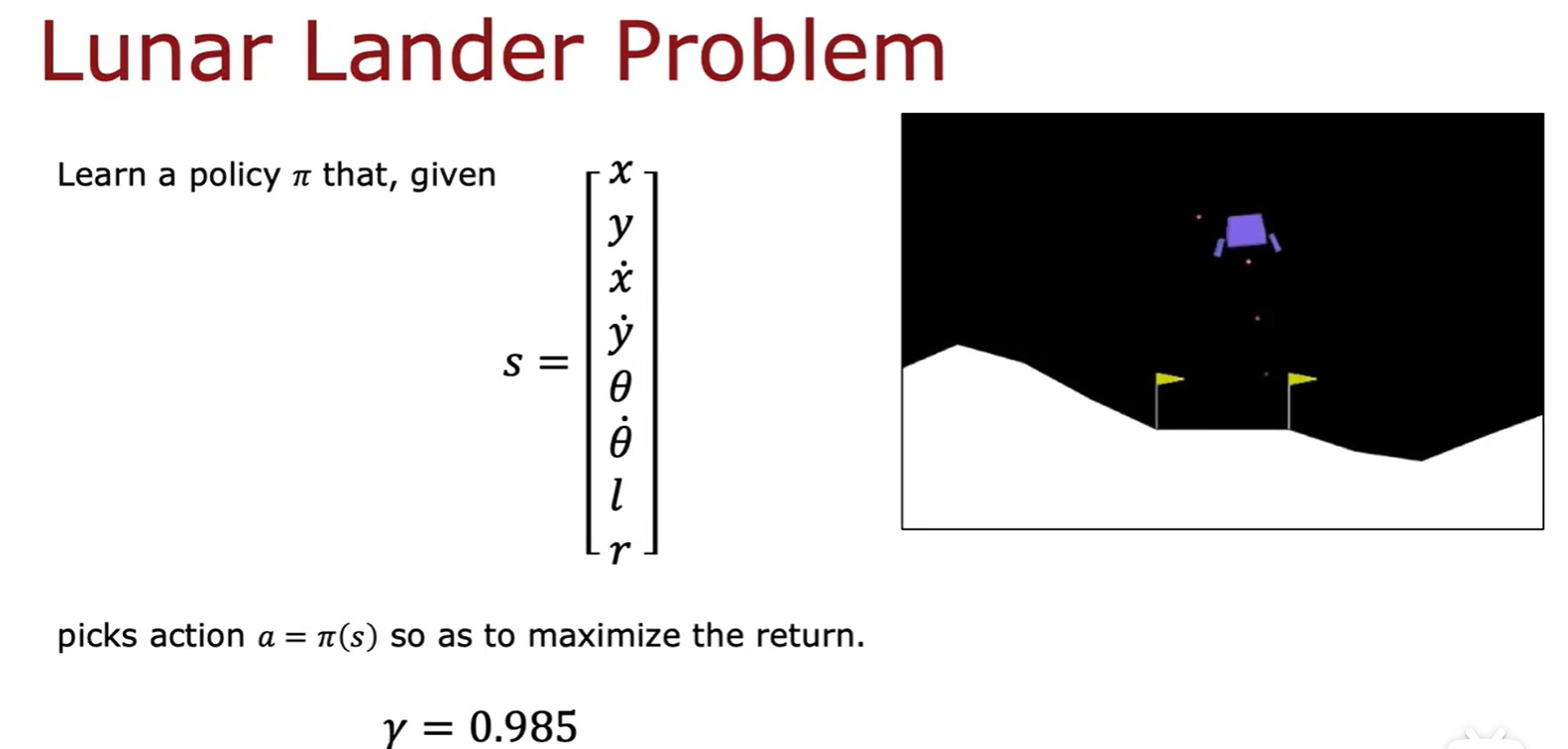
Lunar Lander Problem
- 登月器問題 - 獎勵函數:
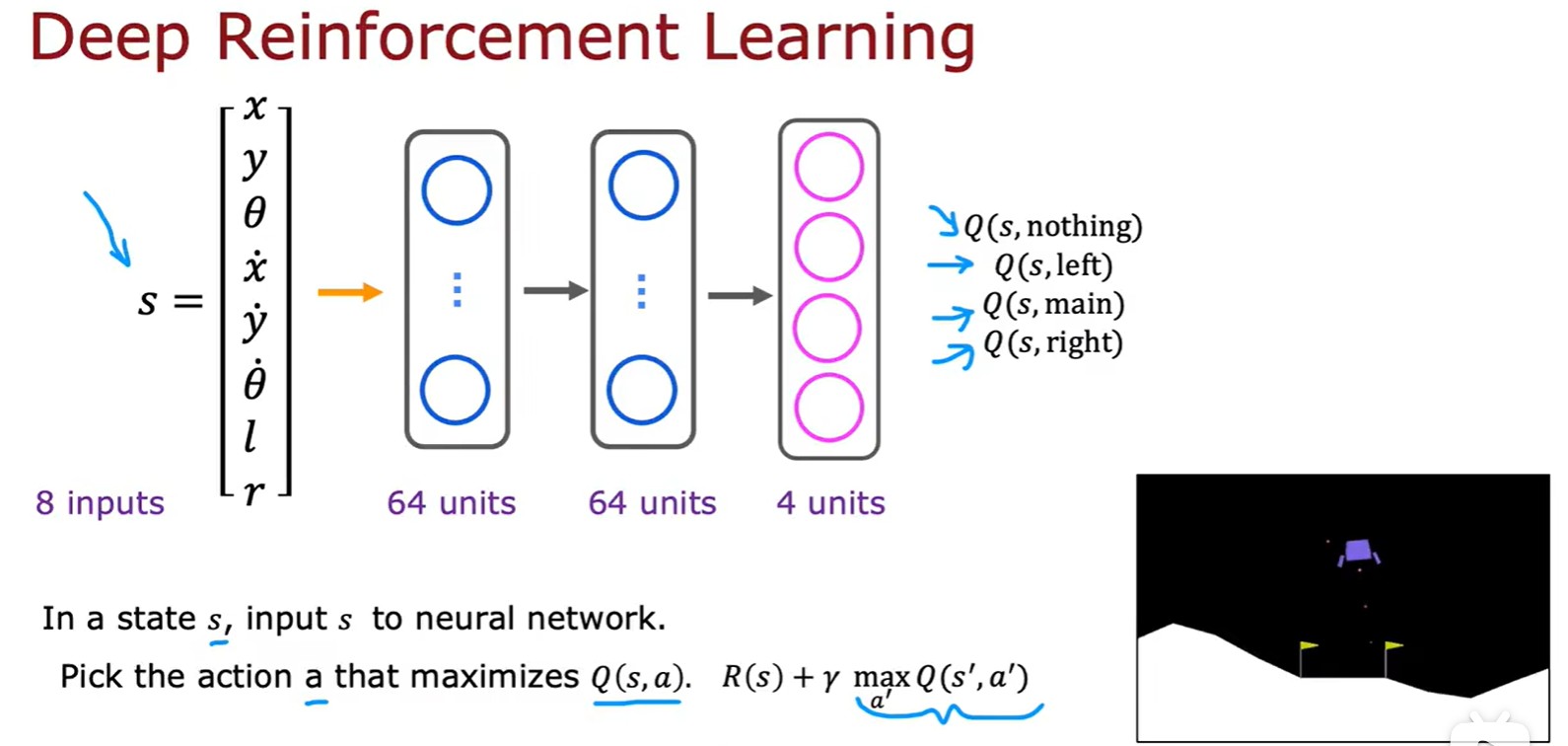
Algorithm
- DQN算法(Deep Q-Network):

- 算法改進:輸出值設為 4 個,方便選擇最大值;
Epsilon??- greedy policy










 IntelliJ Idea 常用快捷鍵(Mac))


)





)
